12-数据进入RL前经历了什么

12-数据进入RL前经历了什么

anzhsoft
发布于 2026-07-01 21:10:15
发布于 2026-07-01 21:10:15
上一篇把 reward 从“一个分数函数”拆成了系统接口。这一篇继续往上游走:reward manager 为什么能拿到 data_source、reward_model.ground_truth和 extra_info?rollout 为什么能拿到正确的 prompt、工具和多模态输入?答案在数据进入 RL 前的契约。
本文的核心判断是:数据入口不是“读 parquet 然后训练”。在 verl 里,样本先经过文件加载、字段保留、chat template 长度检查、collate、DataProto 包装,再由 rollout request 生成 input_ids/attention_mask/position_ids。如果这个阶段的字段合同错了,后面常常表现为 reward 错、rollout 错或训练不稳定。
先看整体入口图。读这张图时注意:dataset 阶段保留的是 row 级语义,真正的训练张量主要在 rollout/tokenization 后形成。
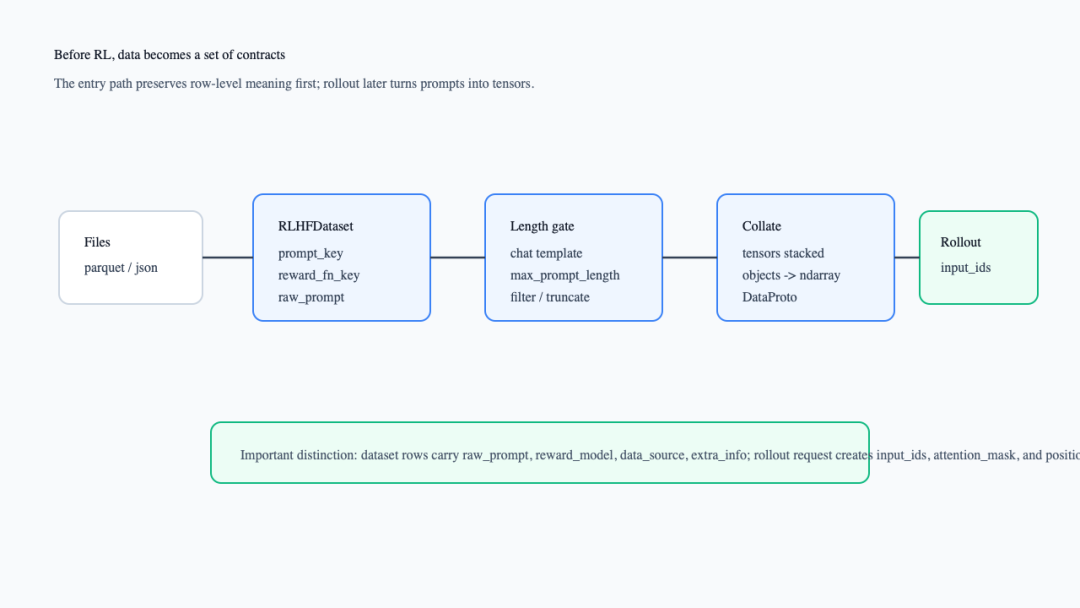
数据进入 RL 前的入口流水线
这张图对应两个入口:RayPPOTrainer._create_dataloader()会用 create_rl_dataset()构造 train/val dataset,并用默认 collate_fn创建 dataloader(verl/trainer/ppo/ray_trainer.py:320-355);create_rl_dataset()再根据配置选择 dataset class 并实例化(verl/trainer/main_ppo.py:314-341)。
1. 配置先定义数据合同
数据配置里,train_files和 val_files可以指向 parquet;prompt_key默认是 prompt,reward_fn_key默认是 data_source;max_prompt_length、max_response_length、train_batch_size决定后续 rollout 与训练的基本边界(verl/trainer/config/data/legacy_data.yaml:7-42)。
还有几个字段很容易被低估。return_raw_input_ids用于 reward model chat template 与 policy 不同时保留原始输入;return_raw_chat默认打开;filter_overlong_prompts、filter_overlong_prompts_workers和 truncation决定超长 prompt 的处理策略;image_key/video_key/audio_key和 return_multi_modal_inputs决定多模态字段如何进入后续处理(verl/trainer/config/data/legacy_data.yaml:53-116)。
RLHFDataset初始化时会把这些配置读成对象字段:prompt_key、多模态 key、max_prompt_length、return_raw_chat、truncation、filter_overlong_prompts、apply_chat_template_kwargs、tool schemas、return_multi_modal_inputs等都会被保留下来(verl/utils/dataset/rl_dataset.py:71-153)。它的文件读取逻辑支持 parquet、json 和 jsonl,并把多份数据 concat 成一个 HuggingFace Dataset(verl/utils/dataset/rl_dataset.py:159-179)。
2. 一个样本不是只有 tensor
RLHFDataset.__getitem__()的关键动作不是立即生成完整训练张量,而是把 prompt构造成 raw_prompt,删除原始 image/video/audio 列,加一个 dummy_tensor,并确保 extra_info、tools_kwargs、interaction_kwargs等对象字段存在(verl/utils/dataset/rl_dataset.py:368-393)。这个 dummy_tensor是为了让 DataProto 的 tensor batch 不为空,真正的 prompt tokenization 会在 rollout 相关路径里完成。
下面这张图把一个样本拆成 tensor 与非 tensor 两条线。它补的是:reward 所需字段、工具字段和多模态对象不是 tensor,但必须跟着 batch 走。
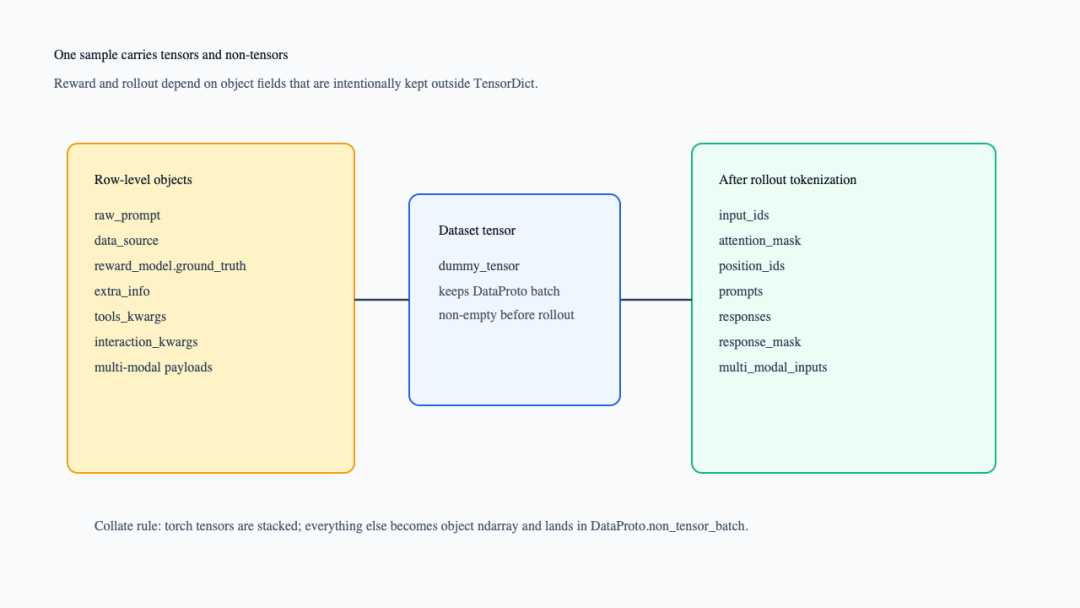
样本字段合同:tensor 与非 tensor
默认 collate_fn会把 torch tensor stack 起来,把非 tensor 字段转成 object ndarray(verl/utils/dataset/rl_dataset.py:40-68)。DataProto.from_single_dict()也会把 torch Tensor 放到 batch,把 numpy ndarray 放到 non_tensor_batch;from_dict()还会校验 tensor batch size,并把非 ndarray 对象转成 object ndarray(verl/protocol.py:479-543)。这就是后面 reward manager 能读取 data_source、reward_model、extra_info的原因。
3. prompt length 要在 chat template 后检查
超长 prompt 的判断不能只看原始字符串长度。maybe_filter_out_long_prompts()在启用 filter_overlong_prompts时,会先构造 messages;如果有 processor,就调用 processor 的 apply_chat_template(),再结合 image/video/audio 构造 processor inputs 来计算长度;如果没有 processor,就调用 tokenizer 的 apply_chat_template(tokenize=True)。最后只保留 doc2len(doc) <= max_prompt_length的样本(verl/utils/dataset/rl_dataset.py:192-270)。
下面这张图强调的是“格式化之后再判断长度”。它和第一张流水线互补:文件里短不等于模板后短,尤其有工具 schema 和多模态输入时。
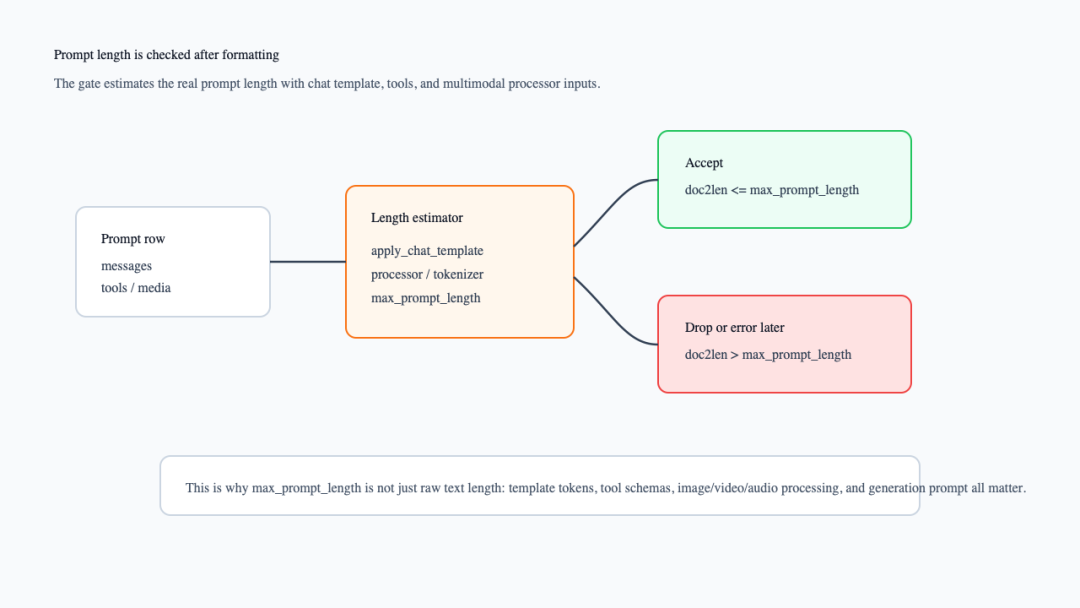
prompt length gate 在 chat template 后生效
rollout request 侧也会再次面对这个问题。schemas.py中如果 input_ids/attention_mask/position_ids还不存在,会调用 _handle_apply_chat_template(..., add_generation_prompt=True, tokenize=True, return_dict=True)生成它们;如果生成后的 prompt 超过 max_prompt_len,当前代码路径会记录 warning,提醒 prompt 在加 tools 和模板后超过限制(verl/workers/rollout/schemas.py:145-214)。所以工程上最好在 dataset 侧就把长度合同处理干净,而不是把异常留到 rollout 阶段。
4. 多模态字段和 reward 字段走不同通道
多模态样本还多一层转换。_build_messages()会把 prompt 文本中的 <image>、<video>、<audio>占位符替换成 processor 需要的结构化 content,并检查占位符数量与实际媒体数量一致(verl/utils/dataset/rl_dataset.py:296-366)。_process_multi_modal_info()会根据结构化 messages 抽取 image/video/audio,供 processor 计算输入(verl/utils/dataset/rl_dataset.py:447-468)。
下面这张图把多模态通道和 reward 通道分开。看图时注意:它们都会从 dataset row 出发,但一个服务 rollout/tokenizer,一个服务 reward manager。
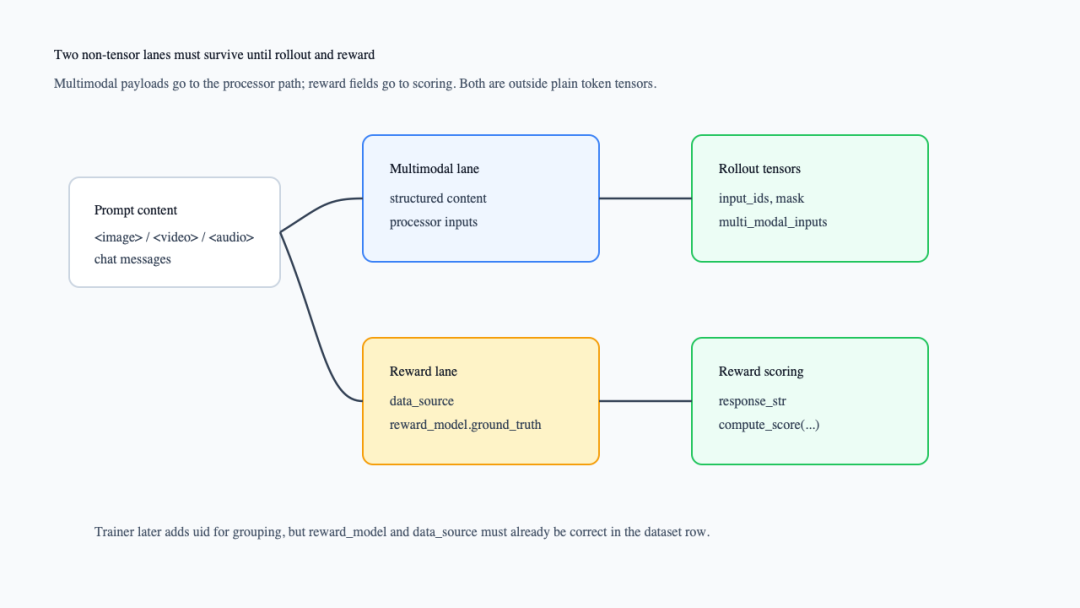
多模态通道与 reward 字段通道
rollout request 会把 chat template 后的结果拆成 input_ids、attention_mask、multi_modal_inputs和 position_ids(verl/workers/rollout/schemas.py:145-214,verl/workers/rollout/schemas.py:246-279)。HuggingFace rollout 随后消费 input_ids、attention_mask、position_ids做生成,并返回 prompts、responses、完整 input_ids、新的 mask 和 position ids(verl/workers/rollout/hf_rollout.py:96-169)。
reward 通道则要保留 data_source、reward_model、extra_info和 uid。_get_gen_batch()会只保留这些 reward keys,把其他不需要给 generation 的非 tensor 字段弹掉(verl/trainer/ppo/ray_trainer.py:488-499)。主循环还会给 batch 添加 uid,供 GRPO 等按 prompt 分组(verl/trainer/ppo/ray_trainer.py:1343-1350)。如果 batch 里有多模态输入,trainer 还会从 multi_modal_inputs里收集 image sequence length 信息(verl/trainer/ppo/ray_trainer.py:1416-1425)。
小结:数据入口决定后面 reward 和 rollout 是否可信
第 11 篇说明 reward 不是一个 float 函数;第 12 篇补上它的上游:reward 能不能算对,取决于 dataset 是否给出了正确的 data_source、reward_model.ground_truth和 extra_info。rollout 能不能生成正确 response,则取决于 raw_prompt、chat template、tool schema、多模态输入和长度门槛是否一致。
把第二组到这里串起来:
数据字段合同
-> reward 形成 token_level_scores
-> KL / advantage / loss 聚合改变训练信号
-> clip / entropy / actor KL loss 限制 actor 更新
这也给后面的系统文章留下桥:当数据、reward 和算法合同都成立后,真正的瓶颈会继续向 controller、rollout engine、weight sync 和生产 train/serve 系统移动。
本文源码索引
verl/trainer/ppo/ray_trainer.py:320-355:trainer 创建 dataset、sampler 和 dataloader 的入口。verl/trainer/main_ppo.py:314-341:create_rl_dataset()如何选择并实例化 dataset class。verl/trainer/config/data/legacy_data.yaml:7-42:训练/验证文件、prompt/reward 字段和长度配置。verl/trainer/config/data/legacy_data.yaml:53-116:raw ids/chat、超长 prompt、多模态字段和 chat template 参数配置。verl/utils/dataset/rl_dataset.py:71-153:RLHFDataset初始化时读取的数据合同。verl/utils/dataset/rl_dataset.py:159-179:parquet/json/jsonl 的加载和 dataset concat。verl/utils/dataset/rl_dataset.py:192-270:filter_overlong_prompts如何用 chat template、processor 和 tokenizer 估算长度。verl/utils/dataset/rl_dataset.py:296-393:多模态占位符替换、raw_prompt、dummy_tensor和 extra fields。verl/utils/dataset/rl_dataset.py:447-468:image/video/audio 信息抽取。verl/utils/dataset/rl_dataset.py:40-68:默认collate_fn如何区分 tensor 和 object 字段。verl/protocol.py:479-543:DataProto如何拆分 tensor batch 与 non_tensor_batch。verl/workers/rollout/schemas.py:145-214:rollout request 如何生成 tokenized prompt、mask、position ids 和 multimodal inputs。verl/workers/rollout/schemas.py:246-279:chat template 和 processor/tokenizer 的具体调用入口。verl/workers/rollout/hf_rollout.py:96-169:HuggingFace rollout 如何消费 prompt tensors 并返回 responses。verl/trainer/ppo/ray_trainer.py:488-499:generation batch 保留 reward 相关非 tensor 字段。verl/trainer/ppo/ray_trainer.py:1343-1350:trainer 为 batch 添加uid。verl/trainer/ppo/ray_trainer.py:1416-1425:多模态 image sequence length 信息进入 trainer meta_info。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号