打破固有范式?CubeAttn‑X实现最高83%内存节约,LRR提升45%

打破固有范式?CubeAttn‑X实现最高83%内存节约,LRR提升45%

山野大叔
发布于 2026-07-01 20:10:45
发布于 2026-07-01 20:10:45
本文用一张架构对比图,讲清楚一件事:在大模型长程检索这件事上,混合架构(一半线性注意力 + 一半 Softmax)不仅更省内存,而且准确率更高——纯 Softmax 反而打不过它。
先看这张图
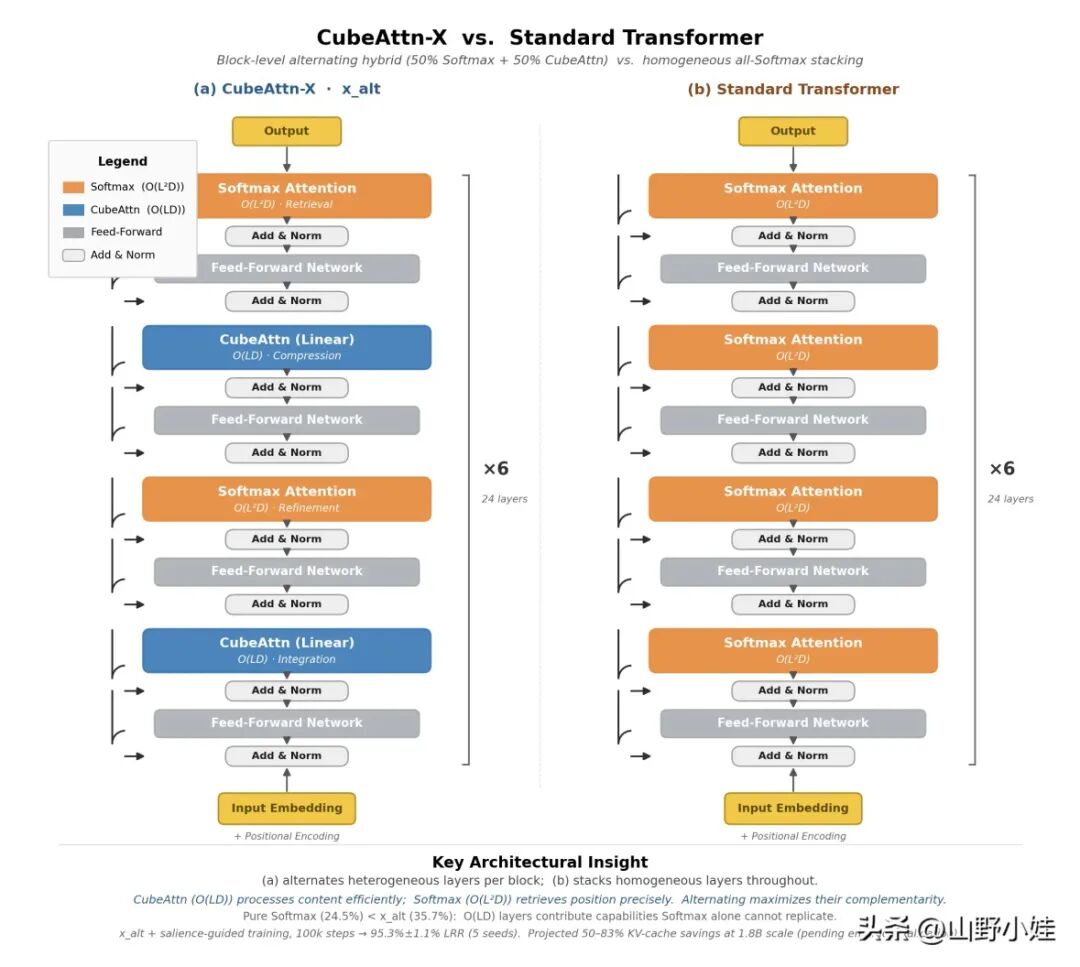
CubeAttn-X vs 标准 Transformer
左边是 CubeAttn-X(x_alt 变体):4 层里 CubeAttn(线性注意力,O(LD))和标准 Softmax(O(L²D))交替排列。右边是 标准 Transformer:4 层全是 Softmax。
直觉上,右边用了两倍的 Softmax 层,应该更强。但实验数据是反的:
架构 | Softmax 层数 | 长程检索准确率(LRR) |
|---|---|---|
纯 CubeAttn | 0 / 4 | 8.7% |
CubeAttn-X(交替) | 2 / 4 | 35.7% |
纯 Softmax(标准 Transformer) | 4 / 4 | 24.5% |
Softmax 层数翻倍,准确率反而低了 11 个百分点。 这是这篇研究里最反直觉的一个发现。
为什么会这样?两种注意力其实各管一摊
长程检索(Long-Range Retrieval, LRR)这个任务,表面上是一个动作,实际拆成两个子任务:
- 内容匹配:识别出查询 token 和序列里哪个 key token 是同一个
- 位置检索:找到那个 key 之后,把它旁边的 value 取出来
关键洞见:两种注意力机制,恰好各擅长一个子任务。
- CubeAttn(线性注意力,O(LD))擅长内容匹配。它把所有 token 压进一个全局状态,查询在这个状态里"共振"到匹配的内容。效率高,但丢了精确位置。
- Softmax(O(L²D))擅长位置检索。它对每个位置算点积,能精确定位"哪个位置有我要的信息"。准,但贵。
纯 Softmax 的问题在于:它得用同一套机制同时干这两件事,会产生相互干扰的梯度——内容匹配想要压缩和不变性,位置检索想要精确的位置交互,两者在同一个 Softmax 层里打架。
混合架构把两个子任务分给各自擅长的机制:CubeAttn 层负责"这是不是我要的内容",Softmax 层负责"它在哪个位置"。各司其职,互不干扰。
这就是图里左边能赢右边的根本原因——不是更省的妥协,而是更聪明的分工。
不只是"交替","怎么交替"也很关键
图里 CubeAttn-X 用的是交替排列(C-S-C-S),而不是把 Softmax 都堆在首尾(S-C-C-S)。这不是随便排的——同比例下两种排法差距很大:
排列方式 | 结构 | LRR |
|---|---|---|
首尾式(聚类) | S-C-C-S | 25.7% |
交替式 | C-S-S-C | 35.7% |
同样是 50% Softmax,交替比首尾高 10 个百分点。
原因:交替排列让两种层形成"压缩—检索—压缩—检索"的循环——每个 CubeAttn 层接收到 Softmax 精炼过的位置信息再压缩,每个 Softmax 层接收到 CubeAttn 的内容表示再检索。而首尾式中间两个连续的 CubeAttn 层没有 Softmax 反馈,第二轮压缩丢失了位置信息,形成信息瓶颈。
层与层的关系,比层的数量更重要。这是图里没画出来、但同样重要的一条。
对实际部署意味着什么:省一半到 83% 的 KV-cache
混合架构的真正价值在推理时兑现。以 1.8B 参数模型(24 层、32K 上下文)为例:
配置 | Softmax 层数 | KV-cache 内存 | 相比纯 Transformer 节省 |
|---|---|---|---|
纯 Transformer | 24 | ~6.0 GB | 0% |
CubeAttn-X(交替) | 12 | ~3.0 GB | 50% |
CubeAttn-X(效率模式) | 6 | ~1.5 GB | 75% |
CubeAttn-X(极致省) | 4 | ~1.0 GB | 83% |
(注:上表的 LRR 性能与内存节省是预测,4 层合成任务上的 35.7% 已实测。)
线性注意力层用 O(D) 状态,相对 Softmax 的 O(LD) KV-cache 可忽略不计。所以每减少一层 Softmax,推理内存就实打实降一截,而检索能力靠交替排列保住。
这对长上下文场景(RAG、长文档理解、Agent 多轮记忆)是直接的红利——同样的显存,能装更长的上下文。
这张图想说的,其实是一个更大的判断
回到开头那张架构对比图。它不只是在说"我们的架构更好",它在传递一个判断:
在长程检索这件事上,Softmax 不是万能的,线性注意力也不是要被淘汰的落后技术。两者是互补关系,最优解是让它们分工。
过去几年的主流叙事是"线性注意力不行,得靠 Softmax 或者回到稀疏注意力"。这张图和数据提供了另一个方向:别纠结谁取代谁,想想怎么分工。一个最少只用 1 层 Softmax(4 层里 1 层)的混合架构,就能把 LRR 从 8.7% 拉到 25.5%,是纯线性注意力的 3 倍——而省下的 Softmax 层全是内存红利。
混合不是妥协,是范式。
一句话总结
一半 Softmax + 一半线性注意力,交替排列——比纯 Transformer 更准、更省内存。 不是因为线性注意力突然变强了,而是因为我们终于让两种机制干回了各自擅长的事。
图里那个 C-S-C-S 的小循环,藏着下一代高效长上下文架构的一个答案。
备注:本文基于学术研究论文创作:Training Dynamics, Kernel Failure Modes, and Seed Sensitivity in Linear Attention
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号