图谱skill Hyper-Extract:一条命令,把文档变成知识图谱

图谱skill Hyper-Extract:一条命令,把文档变成知识图谱

山行AI
发布于 2026-06-24 21:23:26
发布于 2026-06-24 21:23:26
前言
Hyper-Extract Logo
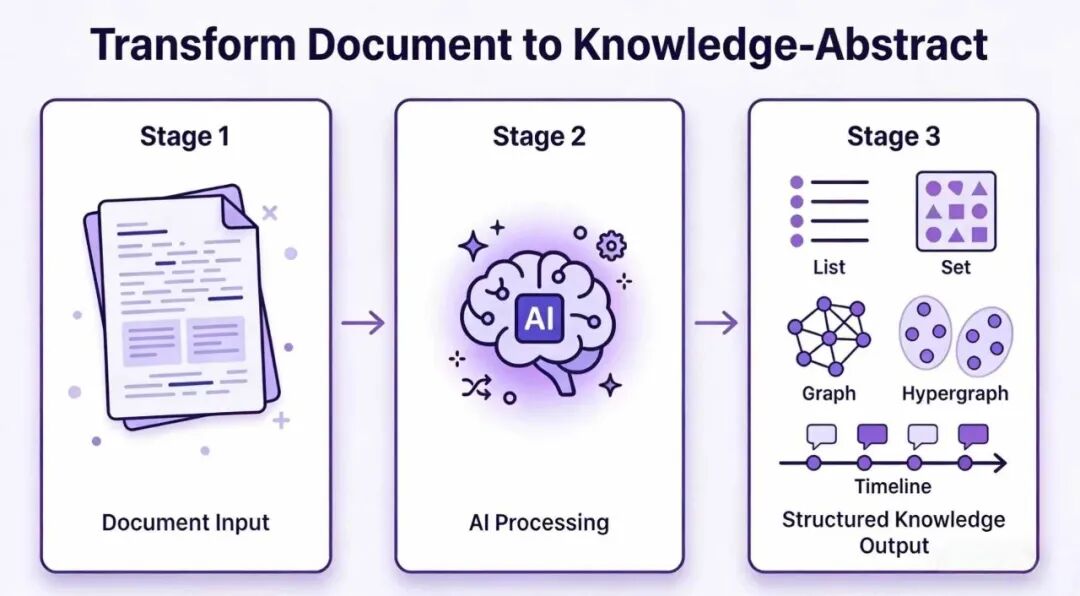
Hyper-Extract 工作流示意图
如果一个知识库只能回答“这段话里写了什么”,它还只是检索系统。真正难的是:文档里有哪些实体?实体之间是什么关系?哪些信息随时间变化?哪些关系不是普通二元关系,而是一组事件、角色、地点共同构成的复杂结构?
Hyper-Extract[1] 想解决的正是这个问题。它不是简单的文档解析器,而是一个由 LLM 驱动的 知识抽取与知识演化框架:把高度非结构化文本,转换成可持久化、可搜索、可可视化、可导出的 Knowledge Abstracts(知识抽象)。
项目官方介绍是:Smart Knowledge Extraction CLI。更直白一点说,它试图把“读文档、抽实体、建图谱、做搜索、可视化、导出笔记、给 Agent 调用”合成一条命令行工作流。
它能做什么
Hyper-Extract 的核心能力可以概括为五件事。
1从文档中抽取结构化知识
它可以把论文、财报、传记、行业文档、医学/法律/中医等领域文本,抽取成列表、集合、Pydantic 模型、知识图谱、超图、时序图、空间图、时空图等结构。
1用模板降低抽取门槛
项目内置 80+ YAML 模板,覆盖 Finance、Legal、Medical、TCM、Industry、General 等领域。用户不需要自己从零写 schema,可以选择模板快速抽取。
1支持多种知识抽取方法
README 提到它支持 GraphRAG、LightRAG、Hyper-RAG、KG-Gen、Cog-RAG 等 10+ extraction engines。也就是说,它更像一个知识抽取方法的统一入口,而不是绑定单一算法。
1支持增量演化
知识库不是一次性产物。Hyper-Extract 支持继续喂入新文档,让已有 Knowledge Abstract 被扩展、补充和细化。
1支持查询、可视化、导出与 Agent 接入
抽取后的结果可以通过 he search 做语义查询,通过 he show 可视化,也可以导出成 Obsidian vault,让图谱节点变成带 [[wikilinks]] 的 Markdown 笔记。新版还支持 MCP Server,可通过 he-mcp 给 Claude Desktop 或 IDE Agent 查询知识抽象。
README 原始示意图
下面几张图来自项目 README,保留原图位,便于直接理解官方想表达的产品形态。
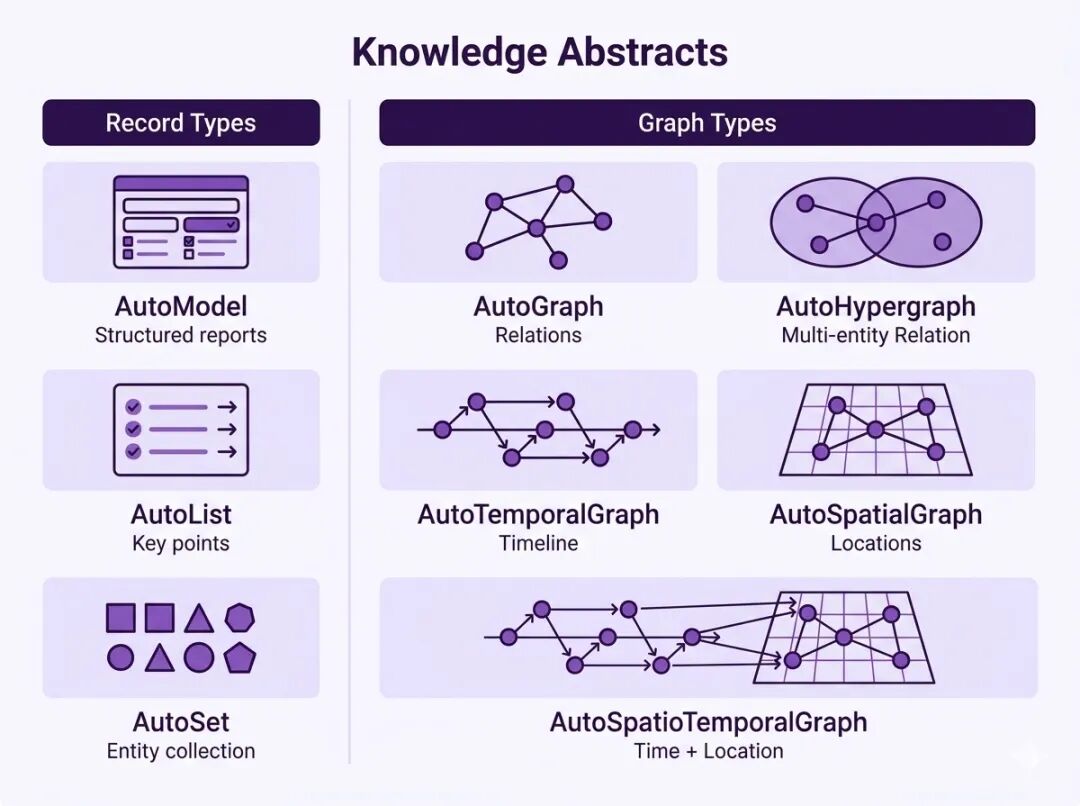
支持的知识结构矩阵
这张图展示了 Hyper-Extract 支持的知识结构。它不是只抽实体和关系,还把结构复杂度继续往上推进:从普通 Model/List/Set,到 Graph/Hypergraph,再到 Temporal Graph、Spatial Graph、Spatio-Temporal Graph。
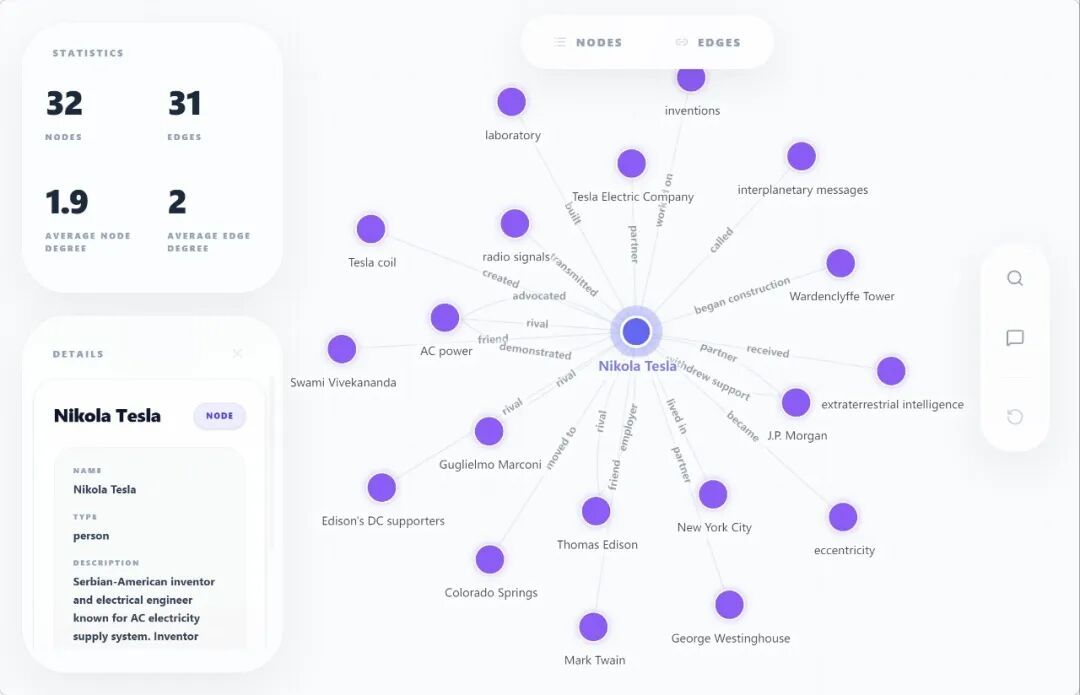
AutoGraph 可视化示例
这张图展示的是 AutoGraph 可视化结果。对于研究论文、人物传记、企业财报这类材料,图谱化的意义在于把“散落在段落里的信息”变成可导航的关系网络。
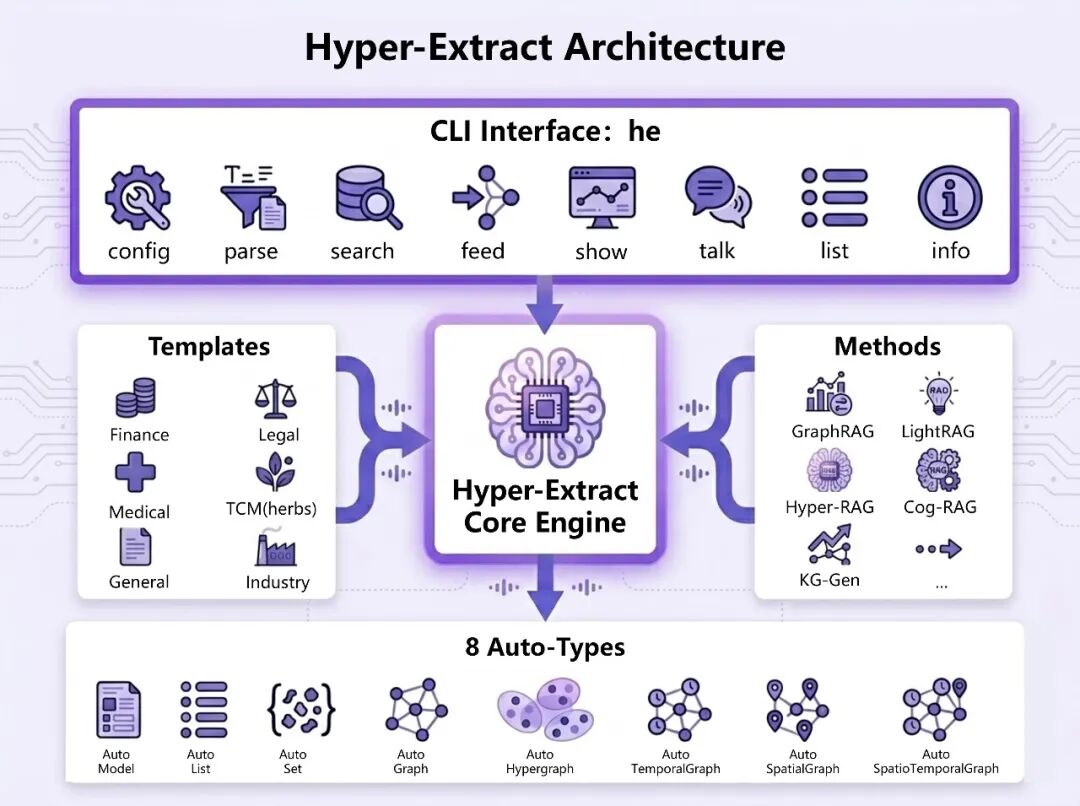
官方架构图
官方架构图把 Hyper-Extract 拆成三层:Auto-Types、Methods、Templates。这个分层很关键:数据结构负责定义“抽成什么”,方法负责决定“怎么抽”,模板负责让用户不用写代码就能落地。
功能架构图
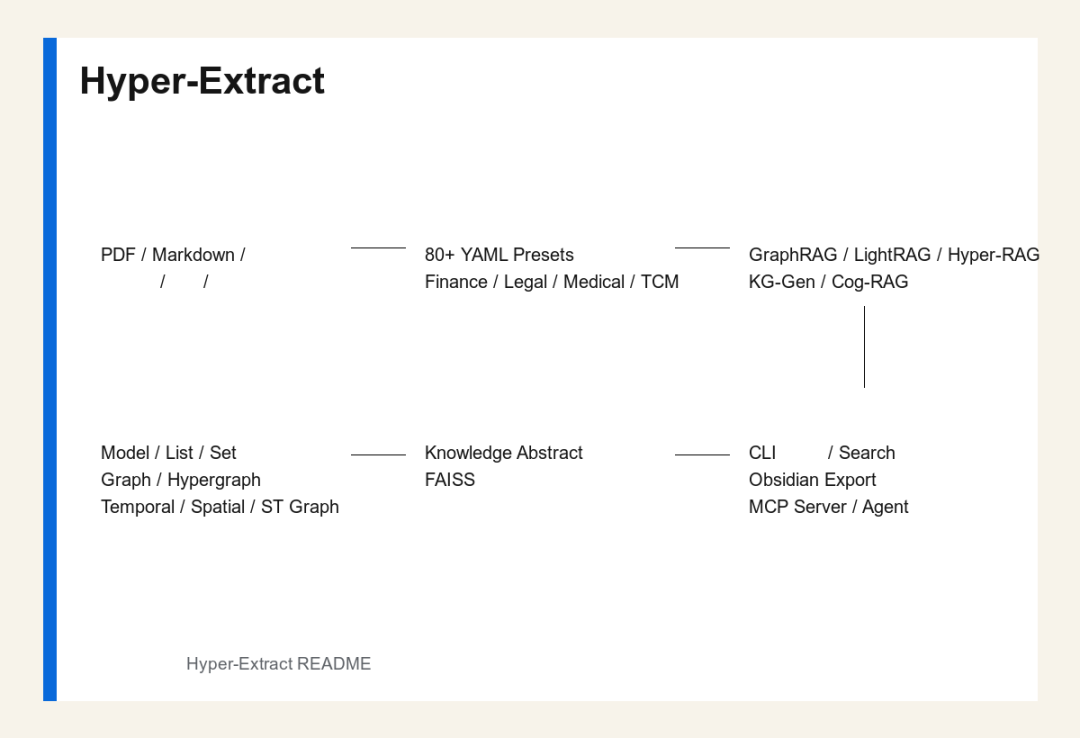
Hyper-Extract 功能架构图
从工程视角看,Hyper-Extract 可以理解为六层。
•输入层:接收 PDF、Markdown、普通文本、研究论文、财报、行业资料等非结构化内容。
•模板层:通过 80+ YAML presets 定义目标结构、字段、实体标识和关系标识。
•抽取层:调用 GraphRAG、LightRAG、Hyper-RAG、KG-Gen 等方法,把文本变成结构化输出。
•结构层:承载 8 类强类型知识结构,包括 Graph、Hypergraph、Temporal Graph、Spatial Graph、Spatio-Temporal Graph。
•存储检索层:形成 Knowledge Abstract,并结合 FAISS / embedding 做语义搜索。
•消费层:提供 CLI 查询、可视化、Obsidian 导出,以及 MCP Server 给 Agent 调用。
这个架构的好处是,用户可以从“我有什么文档”出发,而不是从“我要自己设计整个图数据库 schema”出发。
使用流程图
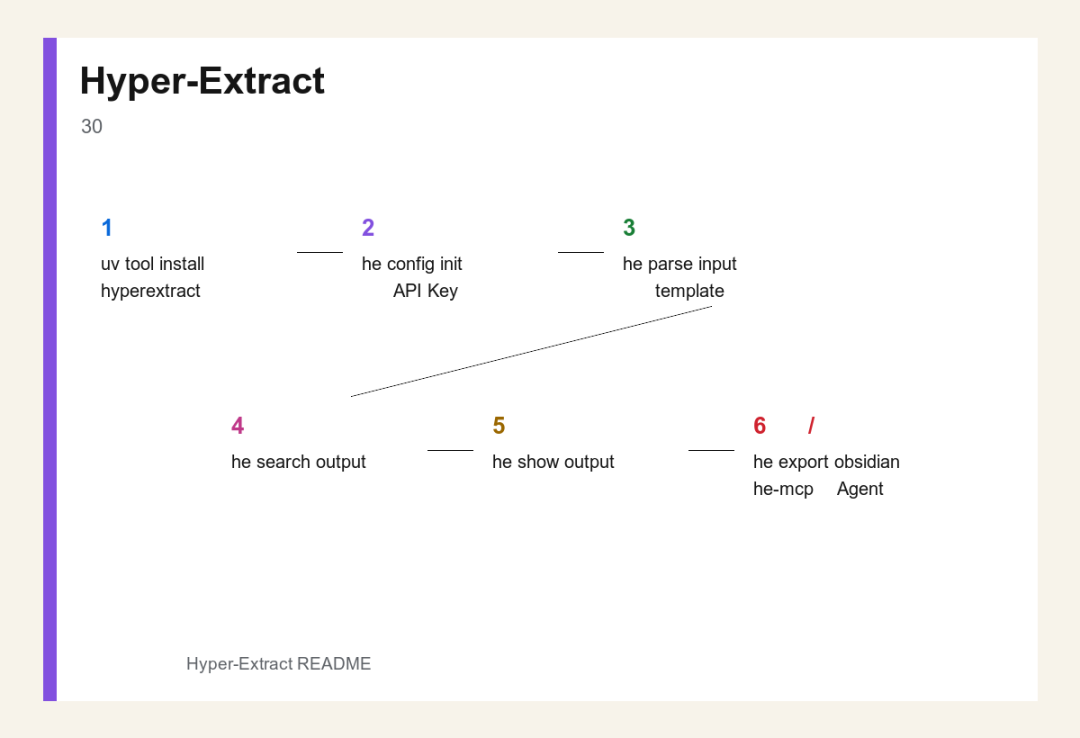
Hyper-Extract 使用流程图
README 给出的 30 秒快速开始非常直接。
class="language-bash">uv tool install hyperextract
he config init -k YOUR_OPENAI_API_KEY
he parse examples/en/tesla.md -t general/biography_graph -o ./output/ -l en
he search ./output/ "What are Tesla's major achievements?"
he show ./output/
he export obsidian ./output/ -o ./vault/
这条链路对应的是:安装工具、配置 API Key、选择模板抽取、对结果提问、可视化结果、导出到 Obsidian。
如果要用 Python API,也可以直接创建模板并解析文本:
class="language-python">from hyperextract import Template
ka = Template.create("general/biography_graph")
with open("examples/en/tesla.md") as f:
result = ka.parse(f.read())
result.show()
支持的平台和模型
Hyper-Extract 依赖模型的结构化输出能力,也就是 json_schema 或 Function Calling。
README 中列出的已验证模型包括:
•OpenAI:gpt-4o、gpt-4o-mini、gpt-5
•Anthropic:claude-opus-4-8、claude-sonnet-4-6、claude-haiku-4-5
•阿里云百炼:qwen-plus、qwen-turbo、deepseek-r1
•Local vLLM:Qwen3.5-9B (GPTQ-Marlin)
Embedding 模型用于语义搜索,支持任意 OpenAI-compatible endpoint,例如 text-embedding-3-small、百炼 text-embedding-v4、本地 vLLM 的 bge-m3。
需要注意的是,Claude 只作为 LLM 使用,Anthropic 当前没有 embeddings API,因此要搭配 OpenAI-compatible embedding provider。
class="language-python">from hyperextract import create_client
llm, emb = create_client(
llm="anthropic",
embedder="openai:text-embedding-3-small"
)
几个典型场景
研究者:把论文变成知识图谱
输入一篇 20 页论文,抽取关键概念、作者、引用关系,生成可交互图谱。
class="language-bash">he parse paper.pdf -t general/academic_graph -o ./paper_kb/
he show ./paper_kb/
金融分析师:从财报中抽取实体和关系
自动识别公司、管理层、财务指标、风险因素及其关系。
class="language-bash">he parse earnings.md -t finance/earnings_graph -o ./finance_kb/
he search ./finance_kb/ "What are the key risk factors?"
本地化部署:数据不出内网
可以通过 vLLM 跑本地模型,例如 Qwen3.5-9B 和 bge-m3。
class="language-python">from hyperextract import create_client
llm, emb = create_client(
llm="vllm:Qwen3.5-9B6a9955">#c586c0">@http://localhost:8000/v1",
embedder="vllm:bge-m36a9955">#c586c0">@http://localhost:8001/v1",
api_key="dummy",
)
和常见 GraphRAG 项目的区别
README 中将 Hyper-Extract 与 GraphRAG、LightRAG、KG-Gen、ATOM 做了功能对比。整理后可以这样理解:
•普通知识图谱:这几类工具基本都支持。
•Temporal Graph:GraphRAG、ATOM、Hyper-Extract 支持。
•Spatial Graph:README 对比中只有 Hyper-Extract 支持。
•Hypergraph:README 对比中只有 Hyper-Extract 支持。
•Domain Templates:README 对比中只有 Hyper-Extract 提供内置领域模板。
•Interactive CLI:README 对比中 GraphRAG 和 Hyper-Extract 支持,LightRAG、KG-Gen、ATOM 不支持。
•Multi-language:README 对比中 GraphRAG 和 Hyper-Extract 支持。
因此,Hyper-Extract 的差异点不是“也能做图谱”,而是它把图谱、超图、时空结构、模板、CLI、搜索、可视化和导出放在了一条产品化链路里。
技术栈与真实入口
从 pyproject.toml 看,Hyper-Extract 是 Python 3.11+ 项目,包名是 hyperextract,版本为 0.3.0。核心依赖包括:
•langchain / langchain-openai:LLM 调用与结构化输出链路
•faiss-cpu:语义索引与向量检索
•ontomem / ontosight:知识记忆和可视化相关能力
•semhash:语义哈希/去重相关能力
•typer / rich:CLI 命令行与终端展示
•python-dotenv:本地配置加载
项目提供两个命令入口:
•he:主 CLI,用于 config、parse、search、show、export、clean 等操作
•he-mcp:MCP Server,用于把知识抽象开放给 Claude Desktop 或 IDE Agent 查询
可选依赖包括:
•hyperextract[anthropic]
•hyperextract[google]
•hyperextract[mcp]
•hyperextract[all]
这说明项目定位不是单一 SaaS,而是一个本地/开发者友好的知识抽取工具包。
Star History

Star History
Star History 图来自 README 底部,可以看到项目近期关注度处于上升阶段。对这类工具来说,热度本身不是结论,但它说明知识抽取、GraphRAG、Agent 可用知识底座正在被更多开发者重新关注。
适合谁用
Hyper-Extract 适合以下几类人:
•做 RAG / GraphRAG / 知识库系统的开发者
•想把论文、财报、法律文本、医学资料变成结构化知识的研究者或分析师
•希望把知识图谱导入 Obsidian 做长期知识管理的个人用户
•想让 Claude Desktop、IDE Agent 查询本地知识抽象的 Agent 工程开发者
•需要本地化部署,不希望敏感文档离开内网的团队
风险与边界
它仍处在 Alpha 阶段,pyproject.toml 的 classifier 标注为 Development Status :: 3 - Alpha。这意味着 API、模板、CLI 行为可能还会变化。
另外,Hyper-Extract 依赖 LLM 的结构化输出能力。模型越弱、输入越乱、模板越复杂,抽取质量越容易波动。真正用于生产时,需要额外做抽取结果校验、模板版本管理、人工审核和回归测试。
最后,复杂图结构的价值来自后续使用场景。如果只是做简单问答,普通 chunk + embedding 可能就够;如果目标是实体关系分析、时序追踪、事件归因、领域知识沉淀,Hyper-Extract 的结构化路线才更有优势。
工程原则观察
•KISS:CLI 链路很清晰,parse → search → show → export 对用户友好。
•YAGNI:如果只是简单文档问答,不必一开始就上超图和时空图;先用模板验证价值。
•SOLID:Auto-Types、Methods、Templates 的三层分工清楚,结构、方法、配置相互解耦。
•DRY:领域模板复用降低重复 schema 设计成本。
•潜在违背点:抽取方法很多,模板也很多,团队落地时要避免“为了复杂而复杂”,应该先选择一个高价值文档类型做闭环验证。
声明:本文由山行整理自:Hyper-Extract GitHub 仓库[2],如果对您有帮助,请帮忙点赞、关注、收藏,谢谢~
参考链接
[1] Hyper-Extract: https://github.com/yifanfeng97/hyper-extract
[2] Hyper-Extract GitHub 仓库: https://github.com/yifanfeng97/hyper-extract
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号