给文档中心装个 AI 大脑:轻量RAG智能问答助手的设计与取舍(开源)
原创
给文档中心装个 AI 大脑:轻量RAG智能问答助手的设计与取舍(开源)
原创
拉丁解牛说技术
发布于 2026-06-22 19:30:33
发布于 2026-06-22 19:30:33
RAG 研究上,已经走到"图结构 + agent 自主控制"融合的前沿,本demo项目处于 Vector RAG 这一务实成熟层,而GraphRAG / Agentic RAG 是明确的演进方向,但建图与自主检索的成本在中小场景未必划算。
一、从一个习以为常的文档搜索体验说起
二、它是什么:一句话与三条设计原则
三、整体架构:离线建库+在线AI问答
四、几个值得说的工程取舍
五、跨语言:一份中文文档,服务多语种用户
六、技术栈一览
七、快速上手(5 步)
一、从一个习以为常的文档搜索体验说起
我们每天都在和各类文档中心打交道:企业内部 Wiki、对外官网帮助中心、云厂商的产品文档。想找一个具体答案时,绝大多数时候,迎接我们的还是一个搜索框。

搜索框的本质是"找页面",不是"给答案"。你搜"人脸识别计费方式",它返回十几篇标题里带"人脸识别""计费"相关的文档,至于哪一篇、哪一段才是你要的,得自己一篇篇点开读、再在脑子里拼。它把"理解问题、定位答案、归纳表述"这三件事,全留给了用户。
这两年不少文档中心开始接入 AI 智能客服,方向是对的。但我在实际体验里,反复遇到两个工程层面的硬伤:
硬伤一:响应慢。 很多 AI 客服默认挂着"深度思考"模式,你问一句,它先转圈圈"正在为您解答,请稍等片刻……",等好几秒甚至十几秒才憋出第一段话。对一个"我只想快速确认一个配置项"的用户来说,这个等待是劝退级的。
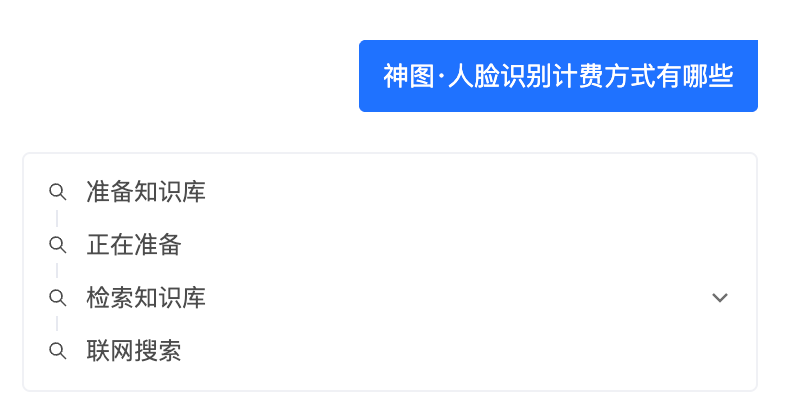
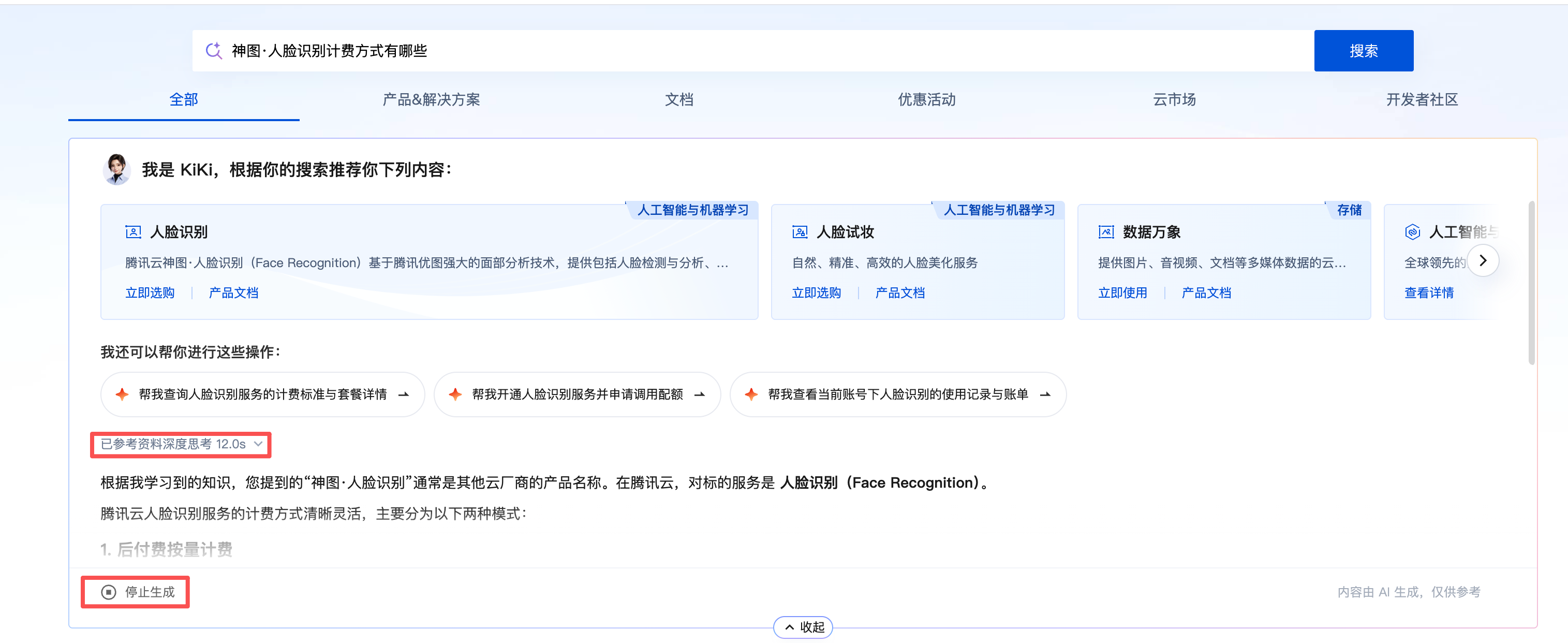
硬伤二:重复问题重复算。 同一个高频问题——比如"怎么计费""有没有免费额度"——换个用户问、或者同一个人再问一遍,系统每次都重新调用大模型,从头思考一遍。对用户是重复等待,对企业是重复烧 token。文档问答的提问分布有明显长尾,头部高频问题占比很高,这部分本可以"算一次、复用多次",却被白白浪费。
之前在公司做过一版"官网文档中心智能问答助手"的技术架构,踩过检索质量、并发、成本控制上的不少坑。最近把那套思路抽离业务、技术架构做精简,重写开源了一个轻量版本,取名 DocMind,供有同样诉求的团队参考。这篇是系列开篇,我想把它的设计目标、整体架构和几个关键工程取舍讲清楚——重点不在"它能跑",而在"为什么要这么设计"。
二、它是什么:一句话与三条设计原则
先给一句话定义:
给它一个文档站的入口 URL + 一个(OpenAI 兼容的)大模型 Key,它会把该站点文档爬取、清洗、切片、向量化,建成知识库;然后对外提供一个带来源溯源的流式问答界面。
在重写和开源之前,定了三条设计原则,后面所有取舍都围绕它们:
- 轻量可落地:不引入 Redis、MongoDB 这类外部中间件,不强依赖 Docker。一台普通机器、一条命令就能起。中间件每多一个,部署门槛和运维负担就高一截——对"想快速验证"的团队不友好。
- 敢对外开放:它的定位是直接挂到公网的"轻量 AI 助手",所以安全防控必须是第一公民,而不是事后补丁(这块内容很厚,单独放在系列第 3 篇)。
- 跨语言:知识库可以只有一份中文 or 英文文档,但要能服务全球多语种用户。这是我认为最有价值、也最容易被忽视的能力,也是我们公司之前官网全球化的最大的一个诉求。
它实际跑起来的样子(Demo 用一份公开产品文档作为知识源):
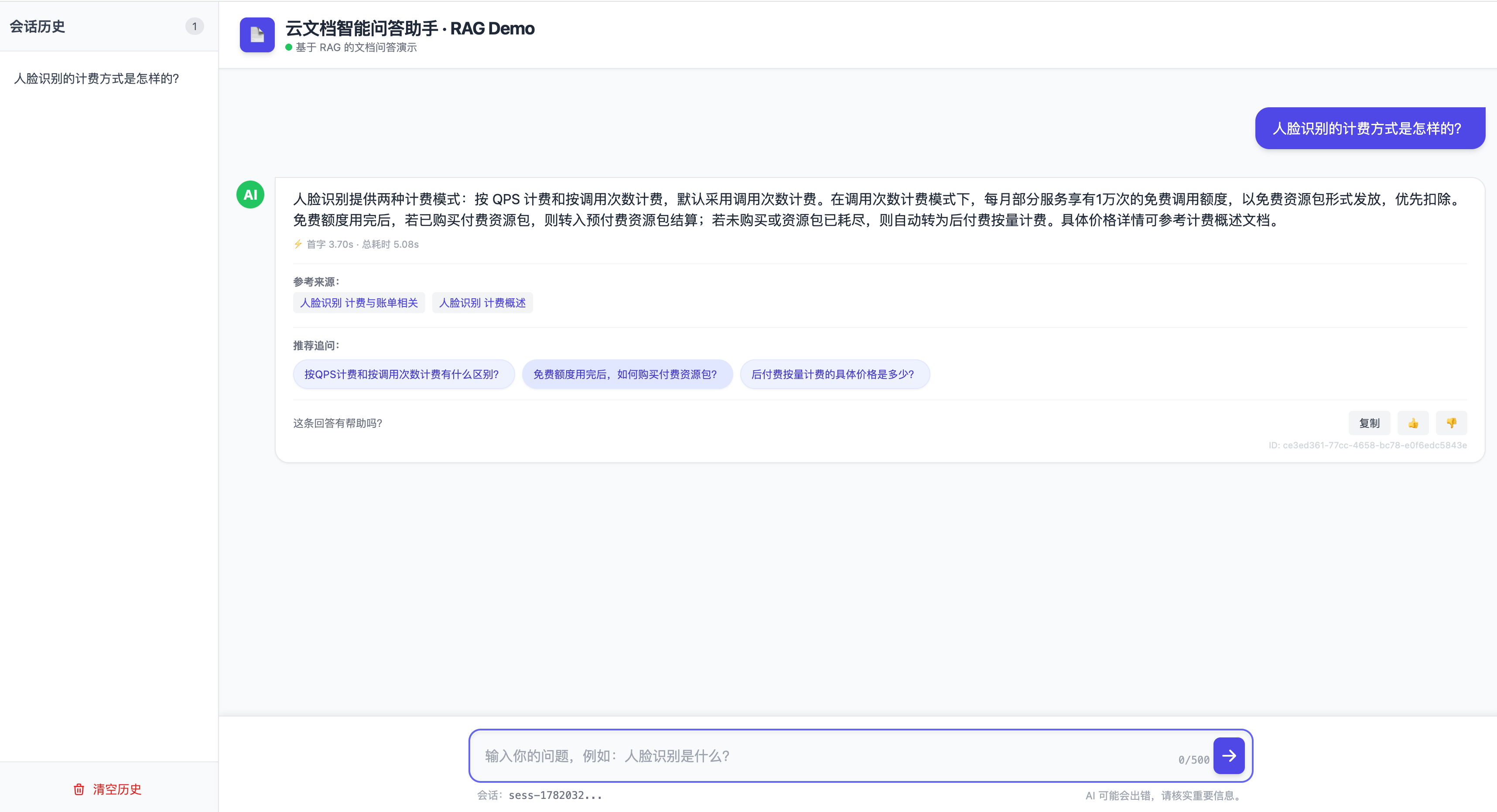
请留意答案下方两个细节:响应耗时是明着标出来的,参考来源点开就是原文。这两个看似不起眼的设计,背后都是刻意的工程考虑。
三、整体架构:离线建库+在线AI问答
抛开细节,DocMind 本质上就是两条链路:离线建库(ingest) 和 在线问答(chat),简略说明如下:

3.1 离线建库:把一个文档站变成可检索的知识
① 抓取范围按路径前缀限定。 爬虫以起始 URL 的 path 作为前缀,只抓该目录下的页面。比如直接提供整个文档中心的导航入口,爬虫脚本从根地址开始进行全量爬取,支持整个文档中心全部内容AI智能问答。如果文档中心很大,你也可以有针对性的只选某个产品或者模块进行爬取,比如人脸识别产品入口是 .../document/product/867,系统就只爬这一个产品的文档,不会顺着导航链接把整个站点都拖下来。这是个很实用的"圈地"机制——文档站内部互链极多,没有这个约束,爬虫会迅速失控。
② 正文容器自动识别。 网页里导航栏、侧边目录、页脚占了大量噪声,直接全文向量化会严重污染检索质量。我的做法是按优先级依次尝试一组正文容器选择器:<article> → <main> →(部分文档站的自定义正文容器)→ .markdown-body(常见 markdown 主题),都命中不了才回退整个 <body>。识别到正文后再做空白合并、噪声行清洗。换一个新文档站时,若它的正文结构特殊,只需在选择器列表里加一条 class 即可,不用改主流程。
③ 切片:诚实地说,目前是固定窗口。 当前用的是固定长度滑动窗口:每片约 800 字符、相邻片重叠 100 字符。重叠是为了避免把一个完整语义切断在两片边界、导致检索召回不到。我不打算把它包装成什么高级策略——它简单、可预测、对大多数文档够用。但我们也清楚它的局限:它不理解段落和语义边界。按语义/标题层级切片是后续优化的明确方向,会放在第 2 篇里和检索质量一起讨论。
④⑤ 向量化与增量更新。 切片经 BGE-M3 本地模型编码后写入 ChromaDB,每条携带 url / title / chunk_index 元数据——title 后面用于来源溯源的友好展示。重复 ingest 时,按页面内容哈希判断是否变化,未变则跳过,并清理掉已不存在的过期文档,做到增量而非每次全量重灌。
3.2 在线问答:从一句提问到一段带出处的回答
⑥ 语种识别。 用确定性规则判断提问语种(是否含 CJK 字符),决定回答应使用的语言基调。这里我选规则而非再调一次模型,是为了省一次往返、降一份延迟和成本——能用确定性逻辑解决的,不必动用大模型。
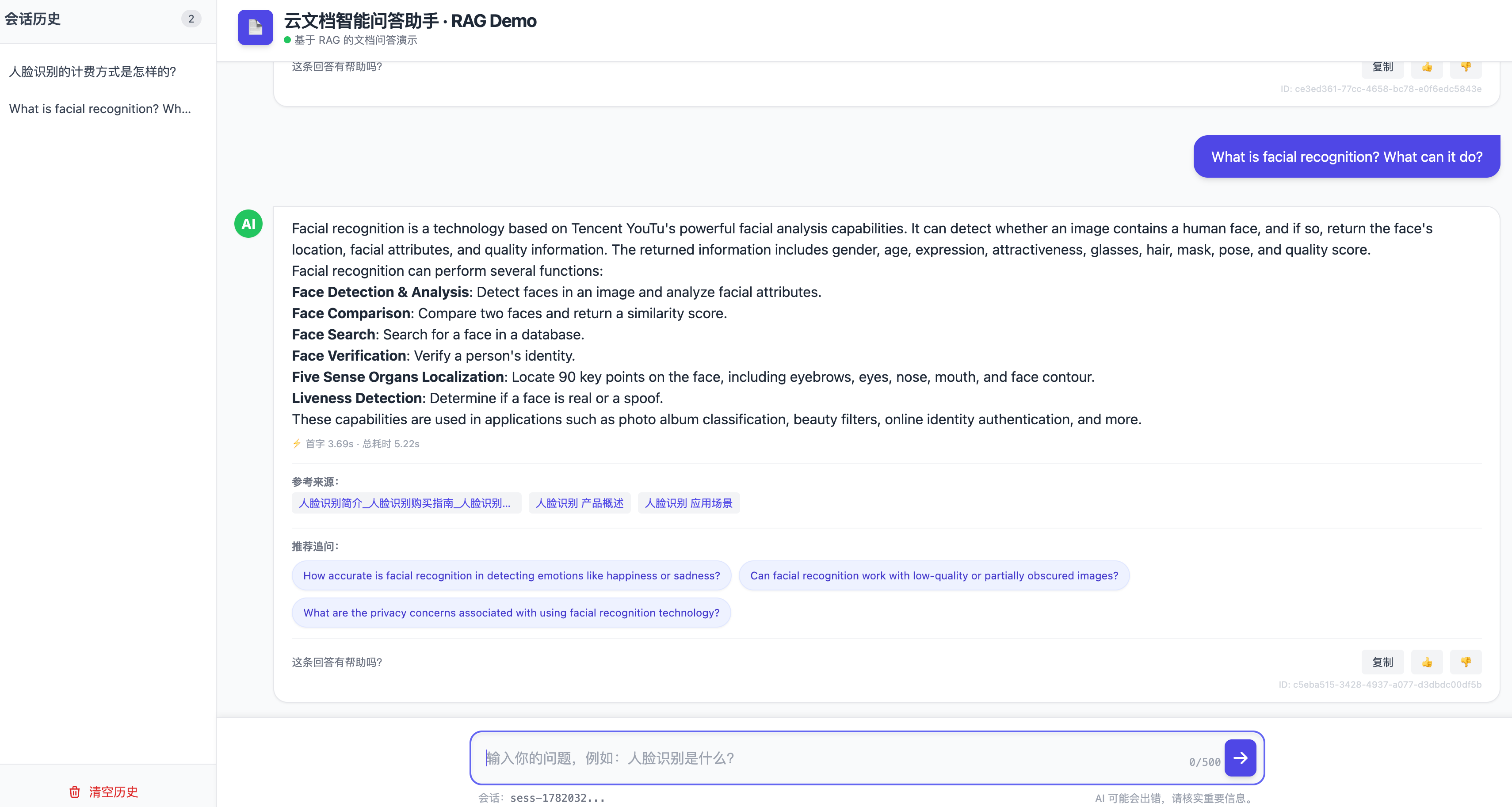
多语言AI问答支持
⑦ 向量检索 Top-3。 提问经同一个 BGE-M3 编码后,在 ChromaDB 里按向量距离取最相近的 3 个切片。这里藏着本项目最关键的能力之一:因为 BGE-M3 是多语言模型,中文文档和外语问题被映射到同一个语义空间,所以"中文知识库 + 外语提问"才能对得上——这是第 2 篇的主题。
⑧ 相关度阈值闸门:查不到就老实说没有。 这是我最想强调的一个设计。检索结果的最小距离一旦超过阈值(默认 0.55),说明知识库里没有足够相关的内容,此时系统直接礼貌拒答,根本不调用大模型。
这个闸门同时解决三个问题:
- 防幻觉:没有上下文支撑时,宁可说"我这儿没有这个信息",也不让模型硬编一个似是而非的答案。
- 省成本:无关提问被挡在 LLM 之前,不产生 token 消耗。
- 划边界:让助手始终待在"文档知识范围内",不被诱导去回答它不该答的问题。
对一个面向公众的问答系统,"敢于拒答"比"什么都敢答"要可靠得多。
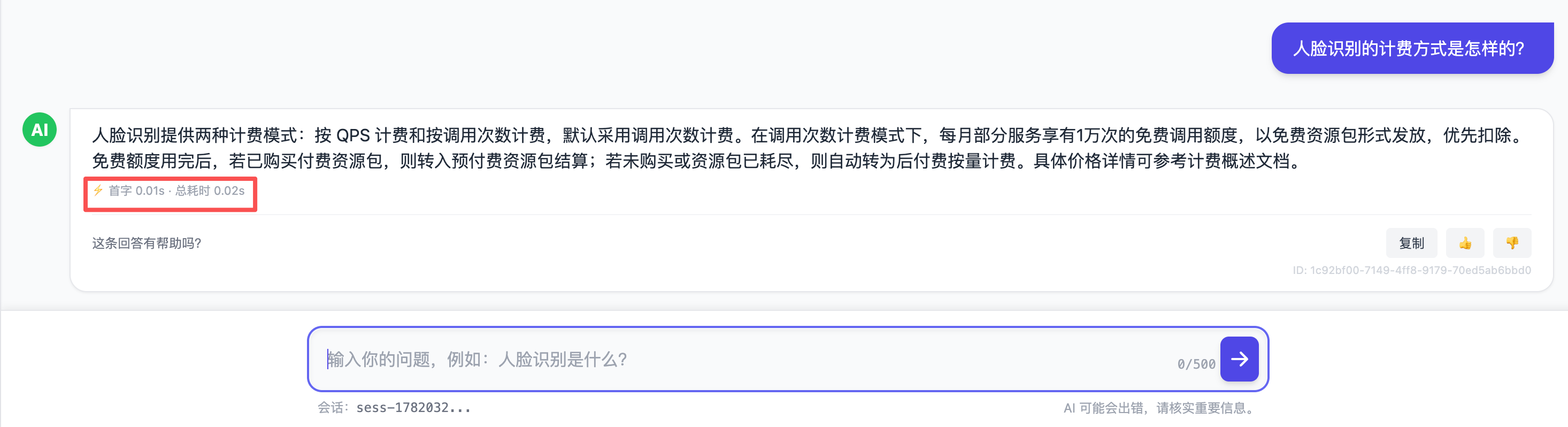
⑨ 缓存:相同问题,算一次复用多次。 回到开头那个"重复问题重复算"的痛点——这正是我重点解决的地方。系统对"完全相同的问题 + 相同对话上下文"做答案缓存:第一次正常生成,之后再问一模一样的,直接命中缓存返回,0 token、瞬时响应。缓存键由问题与上下文哈希得到,并带 TTL 与基于会话的失效联动(会话清空时一并清掉其缓存)。
需要把话说准:这是精确匹配缓存,不是语义缓存——"人脸识别是什么"和"什么是人脸识别"目前会被当作两个问题。把它升级成语义级缓存是一个有价值的方向,但也要权衡误命中的风险,这个取舍我留待后续。
⑩ 上下文组装与截断。 命中的切片拼成上下文喂给模型,超过长度上限时截断,避免把过长上下文砸给 LLM 既费 token 又稀释重点。
⑪ 后处理:把回答收拾干净。 模型产出后我做了两步纠偏:一是语言一致性——回答语种与提问语种不符时触发一次改写(中/英之间),避免"中文提问、英文作答"的尴尬;二是剥离开头废话——大模型很爱用"根据提供的上下文信息,……""Based on the provided context, ……"开头,prompt 里要求过它别这么干,但模型并不可靠,所以我在输出侧用规则确定性地把这类前缀剥掉。能用 prompt 降低概率、但要用代码兜底保证,是我处理这类"模型不老实"问题的一贯做法。
⑫ 输出、溯源与追问。 最终通过 SSE 把回答推送到前端,同时附上参考来源(文档标题 + 链接)和几个推荐追问,并写入缓存。
四、几个值得说的工程取舍
4.1 "流式"其实是模拟的——一个我有意识做出的取舍
界面上回答是逐字蹦出来的打字机效果,但我要诚实地讲清楚它的实现:上游 LLM 调用是非流式的——我先一次性拿到完整答案,再在本地把它切成小片,通过 SSE 逐片下发,模拟出流式效果。
为什么不直接用真流式?因为我在拿到完整答案后还要做两件需要全文才能做的事:语言一致性纠偏、剥离开头废话;以及把完整答案写入缓存。真正的逐 token 流式,会让这些"针对全文的后处理"变得复杂得多。
它的代价我也不回避:因为要等全文生成完才开始吐字,界面上的"首字耗时"其实约等于整段生成时间(这也是为什么 Demo 里首字 ~3s、总耗时 ~4s 两个数字很接近)。所以我想强调:demo项目真正的"快",是缓存命中时的秒回,而不是首次生成的首字延迟——首次延迟取决于你接的上游模型。
如果要兼得,正确方向是"真流式 + 增量后处理"(边收 token 边做可增量的清洗),这是我列出的优化项。
4.2 把"耗时"显示做成一等公民
我特意把每条回答的首字 / 总耗时直接显示在界面上。这不只是个炫技的小徽章——它是一种对用户和对自己的诚实:用户能直观感知快慢,我自己也能借它快速评估"换个上游模型值不值""缓存命中率高不高"。一个系统愿不愿意把自己的延迟摊在明面上,某种程度上反映了它对自身表现的底气。
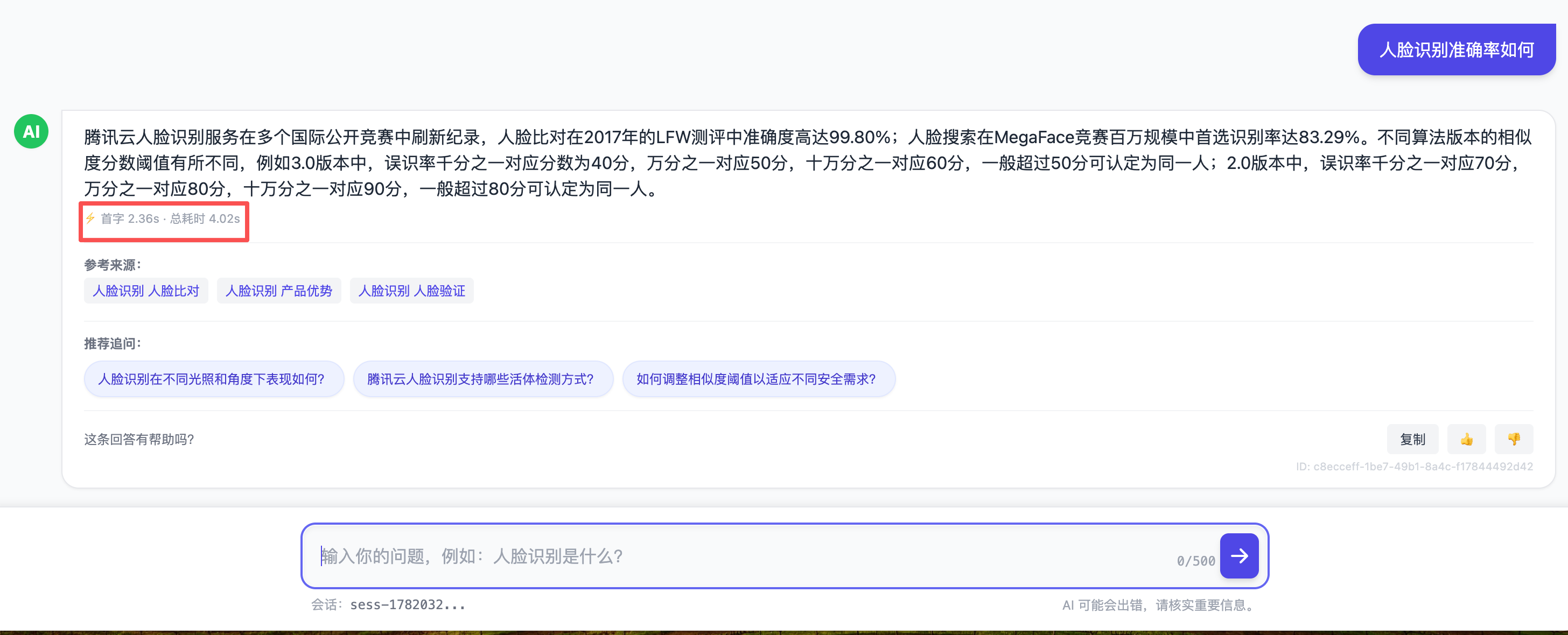
4.3 来源溯源:让 AI 不是黑箱嘴替
每个回答都带回它依据的文档标题和链接,用户一点就能跳到原文核对。对文档问答这种"答案必须可信"的场景,可溯源不是加分项,是底线——它把"AI 说的"还原成"文档里写的,AI 只是帮你找到并归纳"。
4.4 轻量的理由与代价
无 Redis、无 MongoDB——向量库用嵌入式 ChromaDB(一个本地目录),审计/反馈与爬虫元数据各用一个 SQLite 文件,限流、缓存、会话历史等运行时状态用进程内的 LRU + TTL 容器承载。
好处是部署极简,git clone 到能用就几步。代价我也清楚:进程内状态意味着单实例——要做多副本水平扩展,这些内存态就得外移到共享存储。这是一个明确的定位取舍:DocMind 服务的是中小规模文档中心的"轻量落地",不是为超大规模高可用集群设计的。
4.5 为什么没有直接套一个现成 RAG 框架
这是个绕不开的问题:LangChain、LlamaIndex、Dify 这些成熟方案都在,为什么还要自己写一套?
我的判断是:对这个具体场景,自己实现这条主干链路的边际成本,低于驾驭一个大框架的认知成本与约束成本。 RAG 的核心链路——爬取、切片、向量化、检索、阈值判断、组装、调用——本身并不复杂,代码量可控、每一步都看得见摸得着。而通用框架为了覆盖所有场景,引入了大量抽象层;一旦我需要做"阈值拒答""输出侧剥废话""精确匹配缓存""面向公网的多维限流"这类贴着业务的定制,在框架的抽象里反而要绕路、甚至要和它的默认行为对抗。
这不是说造轮子更高明——而是在"可控、可读、可改"和"开箱即用、但内部是黑箱"之间,我为这个项目选了前者。如果是一个要快速对接几十种数据源、上百种工具的复杂 Agent 系统,我的选择会反过来。技术选型从来不是比谁更先进,而是看它是否匹配你当前要解决的问题的形状。
4.6 可观测与反馈闭环:上线只是开始
一个要对外服务的系统,光能跑还不够,得"看得见、调得动"。这块我做了两件事:
- 审计双写:每一次问答、每一条用户反馈,都同时写到结构化日志(stdout JSON,方便实时
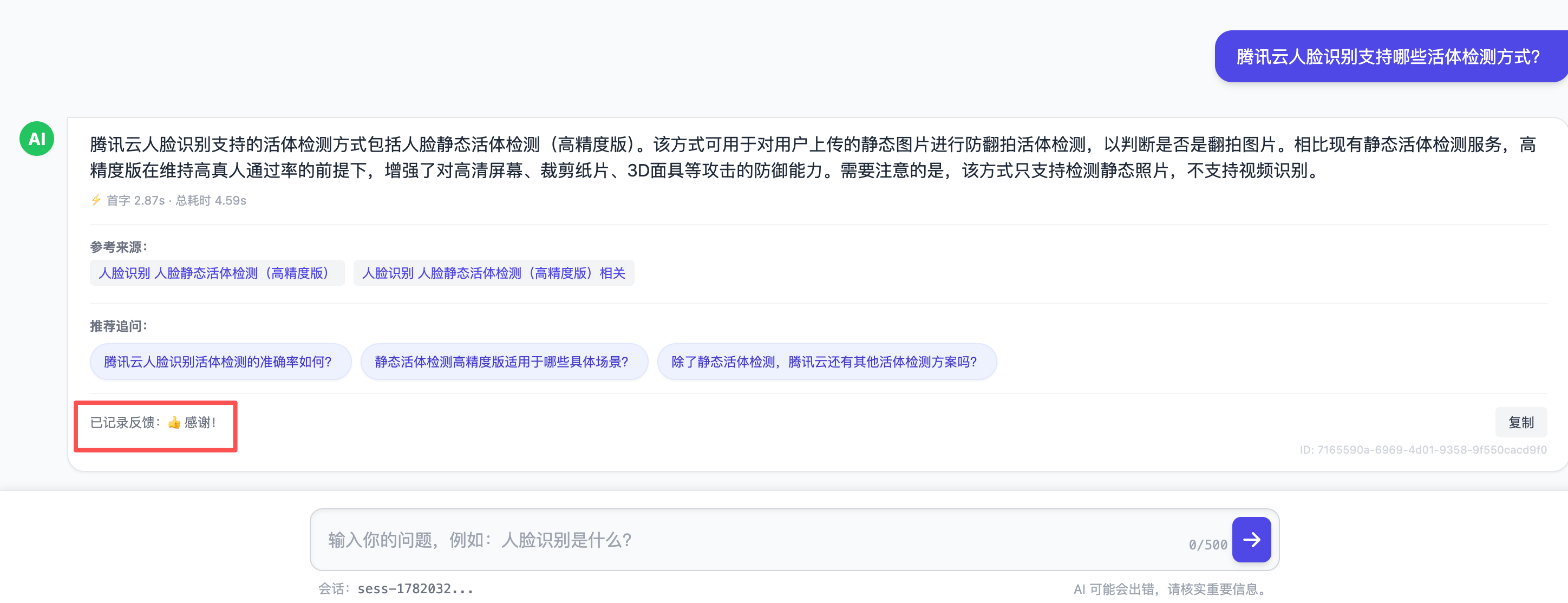
grep+jq)和一个独立的 SQLite 表(支持分页、过滤、关键字检索)。每条记录带request_id,可串起全链路追踪。需要强调的是:审计数据绝不进向量库——避免有人通过提问反查到"别人问了什么"。 - 反馈闭环:每条回答下方有 👍 / 👎,差评可填具体原因。这些反馈结构化落库,是后续迭代"哪些问题答得不好、知识库哪里有缺口"的第一手依据。一个问答系统的质量不是上线那一刻定死的,而是靠这个闭环持续往上走。
五、跨语言:一份中文文档,服务多语种用户
这是我最看重的能力,第 2 篇会完整展开,这里先给一个准确的轮廓。
传统多语言方案往往是"把文档翻译成 N 种语言、维护 N 套知识库",成本和一致性都是负担。DocMind 走的是另一条路:知识库只放一份原始文档(源文档是什么语言就是什么语言),靠 BGE-M3 多语言向量做跨语言检索——外语问题和中文原文被映射到同一语义空间,所以英语、日语等提问也能命中中文文档;回答语种则跟随提问语种(中英之间还做了一致性纠偏兜底,demo版本已去进行精简,实际上可以基于用户原语言进行自动跟随多语种问答)。
对有海外用户、或团队本身多语种的文档中心,这意味着:一份知识库,多语种可用,不必翻译、不必多套维护。 至于"跨语言检索为什么能成立""回复语种如何稳定控制"这些机制细节,留给第 2 篇。
六、技术栈一览
层 | 选型 | 说明 |
|---|---|---|
后端 | FastAPI + Uvicorn | 全异步,天然适合 IO 密集的检索+LLM 调用 |
向量库 | ChromaDB | 嵌入式持久化,一个本地目录,无需独立服务 |
Embedding | BAAI/bge-m3 | 本地多语言模型,跨语言检索的基石 |
LLM | OpenAI 兼容 API | 默认 DeepSeek,可换任意兼容网关 |
存储 | 2 个 SQLite 文件 | 审计/反馈 + 爬虫元数据,无 Redis / 无 MongoDB |
前端 | 原生 HTML/JS + TailwindCSS | 无构建步骤,一个静态页 |
整套东西的设计哲学就一句话:能不引入的依赖,就不引入。
七、快速上手(5 步)
# 1) 克隆 + 装依赖
git clone https://github.com/lukyFun/search-ai.git docmind && cd docmind
pip install -r requirements.txt
# 2) 下载 embedding 模型(国内走 ModelScope 镜像更快)
pip install modelscope && python3 scripts/download_model_cn.py
# 3) 配置 .env:至少填 LLM_API_KEY;
# 换文档站只改 ASSISTANT_NAME / KNOWLEDGE_SCOPE / TARGET_URL 等几项,无需改代码
cp .env.example .env
# 4) 启动(首次会加载 BGE-M3 模型,约 5~10 秒)
bash run.sh
# 5) 建知识库:先 preview 验证抓取效果,再正式 ingest
python3 scripts/ingest_cli.py --mode preview --url "<你的文档入口>" --limit 5
python3 scripts/ingest_cli.py --mode ingest --url "<你的文档入口>" --limit 50随后打开 http://localhost:8100 即可提问。换成你自己的文档站,通常只改配置、不动代码。
八、写在最后
DocMind 想解决的诉求其实很朴素:让文档中心不止能"搜"、还能"答";不止服务一种语言、还能服务全球用户;而且别太重、别太贵。
这一篇我刻意没有停留在"功能罗列",而是把架构链路和几个关键取舍——模拟流式的代价、阈值拒答的边界、缓存的精确匹配局限、轻量的单实例代价——都摊开讲。因为我相信,一个系统可不可靠,不取决于它宣称了多少能力,而取决于它的作者是否清楚每个决策的代价、并诚实地标注出适用边界。
系列后续两篇会深入这次只点到的两个主菜:
- 第 2 篇:跨语言问答是怎么做到的——BGE-M3 多语言向量、语种自适应回复,以及"让 RAG 别瞎编"的检索质量工程(阈值、来源溯源、切片优化)。
- 第 3 篇:把它扔到公网——无中间件的轻量持久化、内存防 OOM,以及面向公网的 15 层安全防护(多维限流、每日 token 预算、提示注入拦截……)。
项目已开源:仓库地址 有相同场景的同行,欢迎参考、提 Issue、拍砖。
再次说明:本项目为个人开源实践,文中 Demo 基于公开文档构建,非任何厂商官方产品,回答由 AI 生成、仅供参考。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号