DeepSeek v4 这波,关键不是更强,而是更省事


这两天 DeepSeek v4 很热。 但普通人真正需要的不是“谁赢了榜单”,而是一个更现实的答案:用了它以后,事情会不会更省钱、更稳、更省心。
一、这次不只是技术圈热闹,普通人也会被影响
以前模型升级,很多人会觉得“和我无关”。 现在不一样了:写文案、做表格、整理会议、写代码、做客服回复,几乎都在被大模型重塑。
DeepSeek 官方文档给了一个很关键的信息:它支持与 OpenAI / Anthropic 兼容的 API 格式,并且明确了旧模型名的弃用节奏(DeepSeek API Docs)。
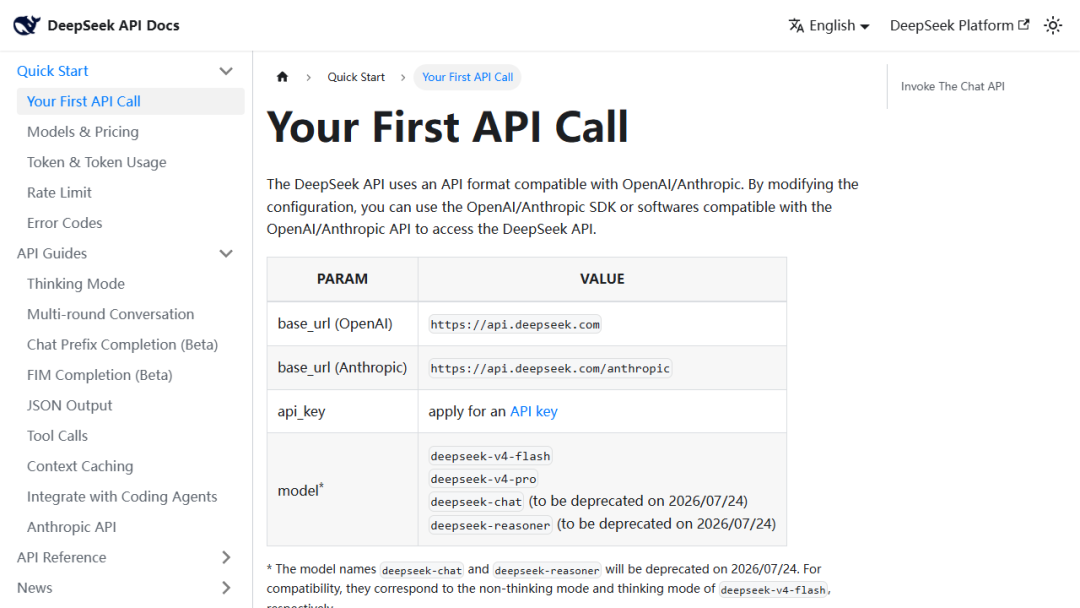
这意味着什么? 意味着你不一定要推倒重来,很多已有流程可以先小改、先试跑、再决定是否长期切换。
对普通用户来说,这就是最重要的价值:不是“它多先进”,而是“你现在手上的活会不会更顺”。
二、别被热度带节奏,先看三笔最关键的账
第一笔账:迁移账。 如果接入一个新模型要大规模改脚本、换一堆工具、重做流程,那这不叫升级,叫额外成本。 兼容能力做得越好,迁移账就越小。
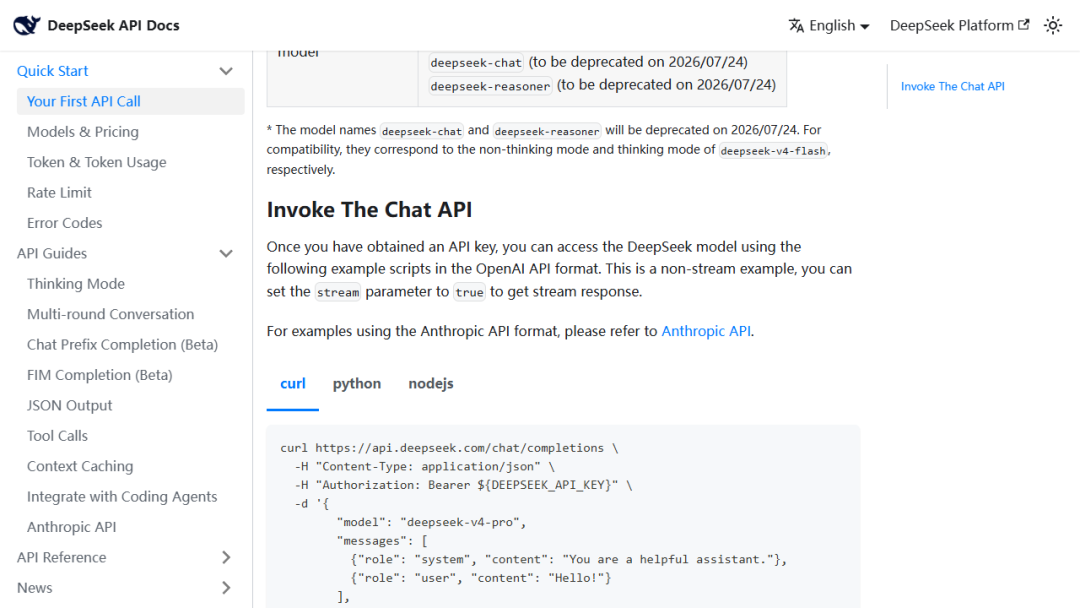
第二笔账:稳定账。 模型好不好,不看发布会词藻,看你真实任务会不会“今天能跑、明天翻车”。 尤其是长任务、批量任务、多人协同时,稳定性比单次峰值更重要。
第三笔账:自由账。 最怕的是“用了以后离不开”。 如果你的调用结构可替换、可回滚、可并行测试,那你就有主动权; 反过来,供应商再强,你也容易被绑死。
一句话总结:真正拉开差距的不是追热点速度,而是你做决策时有没有留后路。
三、给你一个能立刻用的 7 天测试法
不想被带节奏,最有效的方法就是拿真实任务做短周期验证。 别用“演示用例”,直接用你每周都在做的任务:比如写周报、整理客服话术、处理文档、修一段固定脚本。
7 天这样跑就够了:
- 第 1-2 天:同一任务双模型对照,记耗时和返工次数
- 第 3-4 天:上中等复杂任务,观察稳定性和中断率
- 第 5-6 天:让同事按同流程复现一次,测“新人可用性”
- 第 7 天:只看三项结果——成本、稳定、迁移摩擦
如果三项都过线,再扩大使用; 只要有一项明显不过线,就继续观望并补监控。 这套方法看起来“慢”,但它能帮你避开最贵的一种错误:投入一周后被迫回滚。
四、最后一句实话:别急着站队,先把自己的账算明白

所以这篇最务实的结论只有一个:DeepSeek v4 可以试,但别盲冲; 先用真实任务跑一个小闭环,再决定要不要全量上车。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号