PyTorch GPU 内存分析(memory profiling)的实践指南:梯度检查点、混合精度、优化器选型

PyTorch GPU 内存分析(memory profiling)的实践指南:梯度检查点、混合精度、优化器选型

deephub
发布于 2026-06-08 13:23:09
发布于 2026-06-08 13:23:09
模型有 2 亿个参数,fp32 精度下理论上只需 800 MB。为什么 24 GB 的 GPU 却满了?原因在于模型参数只是训练期间占用 GPU 内存的七种因素之一。了解这七个原因才能从靠猜转变为凭工程的判断。
GPU 内存的七大消耗项
调用 loss.backward() 和 optimizer.step() 时,GPU 中存储了:
- 模型参数(Model parameters)——权重本身
- 梯度(Gradients)——与参数等大,每个参数对应一个
- 优化器状态(Optimizer state)——Adam 为每个参数额外存储 2 个张量(m 和 v)
- 激活值(Activations)——每一层的输出,在反向传播时需要保留
- 输入批次(Input batches)——加载到 GPU 上的数据
- CUDA 工作区(CUDA workspace)——kernel 临时空间和 cuDNN 选择缓存
- 内存碎片(Memory fragmentation)——已分配但因块间间隔而无法使用的内存
对于用 Adam 训练的 2 亿参数 fp32 模型:
- 参数:800 MB
- 梯度:800 MB(与参数等大)
- Adam 状态(m 和 v):1600 MB(参数量的 2 倍)
- 激活值:差异很大,通常为参数量的 2–10 倍
- 输入批次:取决于批量大小
- CUDA 工作区:500 MB–1 GB
- 内存碎片:占总量的 5%–20%
所以保守估计总计,一个"理论上"只需 800 MB 的模型,实际要占用 5–8 GB。
如何测量实际情况
PyTorch 内置了相当精确的内存可见性机制,关键在于知道从哪里看。
import torch
# PyTorch 为张量实际分配的 GPU 内存量
allocated = torch.cuda.memory_allocated() / 1024**3 # GB
# PyTorch 从 CUDA 预留的内存量(含未使用部分)
reserved = torch.cuda.memory_reserved() / 1024**3 # GB
# 上次重置以来的峰值分配量
peak = torch.cuda.max_memory_allocated() / 1024**3 # GB
# 重置峰值计数器
torch.cuda.reset_peak_memory_stats()allocated 与 reserved 之间的差值就是碎片量。如果 allocated 为 5 GB、reserved 为 8 GB,则有 3 GB 内存是 PyTorch 申请了但无法高效使用的。
print(torch.cuda.memory_summary())按分配器内存池(allocator pool)打印完整的内存分类统计,含大小分配对比、当前值与峰值,以及各类别明细。在一步训练后调用,能清楚看出内存去向。
大多数人不知道的杀手级功能
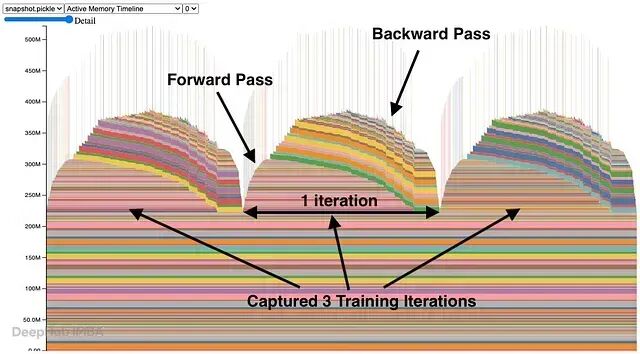
PyTorch 能记录每次内存分配,并以时间线形式将其可视化:
torch.cuda.memory._record_memory_history(max_entries=100_000)
# 执行一步训练
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
# 保存快照
torch.cuda.memory._dump_snapshot("memory_snapshot.pickle")
torch.cuda.memory._record_memory_history(enabled=None)将生成的 pickle 文件上传到 https://pytorch.org/memory_viz,可以看到一个交互式可视化界面,展示每次分配、每次释放,以及触发它们的完整调用栈。
靠这个工具,几分钟内定位到用 print 语句排查要花几天的 OOM bug。
三种管用的优化方法
能测量了,才能优化。以下按影响大小排序:
1、梯度检查点(Gradient Checkpointing)以计算换内存
激活值通常是最大的内存消耗项。梯度检查点在反向传播时重新计算激活值,而不是将其存储下来。
from torch.utils.checkpoint import checkpoint
class MyBlock(nn.Module):
def forward(self, x):
return checkpoint(self._forward, x, use_reentrant=False)
def _forward(self, x):
# 此处为耗时操作
return x典型节省幅度:激活值内存减少 40%–60%。代价:反向传播速度降低 20%–30%。
2、混合精度训练(Mixed Precision Training)内存减半,精度相近
from torch.amp import autocast, GradScaler
scaler = GradScaler('cuda')
with autocast('cuda', dtype=torch.float16):
output = model(x)
loss = criterion(output, y)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()激活值、梯度和大多数运算使用 fp16(每个值 2 字节,而非 4 字节),参数和优化器状态保持 fp32 以保证数值稳定性。
典型节省幅度:总内存减少 30%–50%。fp16 运算在现代 GPU 上速度更快,训练通常也会随之加速。
3. 优化器选择
Adam 为每个参数额外存储 2 个张量。对于 fp32 精度的 10 亿参数模型,仅优化器状态就占 8 GB。
有几个替代选择:
- SGD with momentum:每个参数额外 1 个张量(Adam 开销的一半)
- AdamW with bnb.optim.AdamW8bit:以 8 位存储优化器状态,内存减少 4 倍,精度损失极小
- Lion:内存占用与 SGD 相当,收敛效果通常接近 Adam
对于超过 10 亿参数的模型,优化器的选择可能直接决定训练是否能在现有硬件上运行。
总结
分布式系统领域有句话:无法测量的东西就无法优化。
大多数 PyTorch 团队完全跳过测量步骤:遇到 OOM 错误缩小批量大小然后继续。但是GPU 内存很贵,如果你分析过实际的内存使用情况,就可以将内存占用减半批量大小就能翻倍,这通常意味着更快的训练和更好的梯度估计。
作者:Aditya
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 DeepHub IMBA 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号