对话管理:多轮交互与上下文维护


作者: HOS(安全风信子) 日期: 2026-05-24 主要来源平台: GitHub 摘要: AI IDE 不是单轮问答系统,而是复杂的多轮对话系统。用户与 AI 的交互可能跨越数小时甚至数天,涉及成百上千轮对话。对话管理作为 AI IDE 的核心架构组件,负责处理上下文窗口的维护、对话状态的追踪、历史引用的解析、以及多会话场景下的上下文隔离。本文深入讲解对话管理的工程实现,包括 Session-Thread-Message 三层状态机架构、上下文滑动窗口与摘要压缩策略、历史引用解析机制、以及项目级与任务级会话的隔离方案。通过完整的代码实现示例,展示如何在有限的上下文窗口中维持长时间对话的连贯性,为构建企业级 AI IDE 提供可落地的对话管理方案。
目录- 本节为你提供的核心技术价值
- 1 对话状态机:Session、Thread、Message 的层级关系
- 1.1 为什么需要分层架构
- 1.2 Session:会话根节点
- 1.3 Thread:任务执行上下文
- 1.4 Message:单轮对话原子
- 1.5 分层关系的 Mermaid 序列图
- 1.6 状态机的状态流转
- 1.7 分层架构的工程实现
- 2 上下文维护:滑动窗口、摘要压缩、选择性记忆
- 2.1 上下文管理的核心挑战
- 2.2 滑动窗口策略
- 2.3 摘要压缩策略
- 2.4 选择性记忆策略
- 2.5 上下文维护策略对比
- 3 历史引用:@mention、对话锚点、上下文回溯
- 3.1 历史引用的本质
- 3.2 @mention 机制实现
- 3.3 对话锚点机制
- 3.4 上下文回溯机制
- 3.5 引用解析的 Mermaid 序列图
- 4 多会话管理:项目级 vs 任务级会话
- 4.1 为什么需要多会话隔离
- 4.2 项目级会话与任务级会话的区别
- 4.3 多会话架构实现
- 4.4 上下文隔离与共享的平衡
- 5 对话角色:User、Assistant、System、Tool 的语义区分
- 5.1 对话角色的本质
- 5.2 角色语义的深度定义
- 5.3 多角色协同的序列图
- 5.4 角色切换与上下文构建
- 6 实践:实现一个支持多会话的对话管理器
- 6.1 完整对话管理器架构
- 6.2 与 AI 模型集成的完整示例
- 6.3 高级特性:上下文分支与合并
- 7 对话管理的工程最佳实践
- 7.1 性能优化
- 7.2 稳定性保障
- 7.3 监控与可观测性
- 8 总结与展望
- 8.1 核心要点回顾
- 8.2 未来发展方向
- A.1 完整代码清单
- A.2 配置参考
- A.3 常见问题排查
- 1.1 为什么需要分层架构
- 1.2 Session:会话根节点
- 1.3 Thread:任务执行上下文
- 1.4 Message:单轮对话原子
- 1.5 分层关系的 Mermaid 序列图
- 1.6 状态机的状态流转
- 1.7 分层架构的工程实现
- 2.1 上下文管理的核心挑战
- 2.2 滑动窗口策略
- 2.3 摘要压缩策略
- 2.4 选择性记忆策略
- 2.5 上下文维护策略对比
- 3.1 历史引用的本质
- 3.2 @mention 机制实现
- 3.3 对话锚点机制
- 3.4 上下文回溯机制
- 3.5 引用解析的 Mermaid 序列图
- 4.1 为什么需要多会话隔离
- 4.2 项目级会话与任务级会话的区别
- 4.3 多会话架构实现
- 4.4 上下文隔离与共享的平衡
- 5.1 对话角色的本质
- 5.2 角色语义的深度定义
- 5.3 多角色协同的序列图
- 5.4 角色切换与上下文构建
- 6.1 完整对话管理器架构
- 6.2 与 AI 模型集成的完整示例
- 6.3 高级特性:上下文分支与合并
- 7.1 性能优化
- 7.2 稳定性保障
- 7.3 监控与可观测性
- 8.1 核心要点回顾
- 8.2 未来发展方向
本节为你提供的核心技术价值
本文将为你揭示 AI IDE 如何在有限的上下文窗口中,通过精心设计的对话状态机、上下文维护策略和历史引用机制,实现跨越数百轮对话的连贯交互。 无论你是想理解对话管理的设计哲学,还是需要实现一个生产级别的对话管理器,本文都将提供可落地的工程方案和完整的代码实现。
1 对话状态机:Session、Thread、Message 的层级关系
1.1 为什么需要分层架构
在传统单轮问答场景中,每一次用户输入都是独立的,模型根据当前输入生成回复,不需要任何历史状态。然而,AI IDE 的核心价值在于连续性——用户可能用数小时完成一个复杂的重构任务,期间会有无数次的提问、确认、修改、再提问。这种连续交互的特性要求我们必须构建一套完整的状态管理机制。
对话状态的层级关系是设计对话管理系统的基础。根据业界领先的对话系统设计实践(如 Google Dialogflow、Microsoft Bot Framework),我们将对话状态划分为三个核心层次:
层级 | 概念 | 生命周期 | 数据范围 |
|---|---|---|---|
Session | 会话 | 用户打开 IDE 到关闭 | 整个项目周期 |
Thread | 线程 | 一个具体任务的生命周期 | 单次任务 |
Message | 消息 | 单轮对话 | 单次交互 |
这种分层设计的好处在于:关注点分离。Session 层负责全局状态(如用户偏好、项目配置),Thread 层负责任务上下文(如当前正在处理的需求),Message 层负责内容本身(如具体的代码修改)。
1.2 Session:会话根节点
Session 是整个对话管理的根节点,代表用户与 AI 在一个完整的 IDE 会话周期内的全部交互。一个 Session 的生命周期从用户启动 IDE 开始,到用户关闭 IDE 结束。在 Session 级别,我们通常维护以下状态:
class Session:
"""
AI IDE 会话根节点
生命周期:IDE 启动到关闭
"""
def __init__(self, session_id: str, user_id: str, project_path: str):
self.session_id = session_id # 全局唯一标识
self.user_id = user_id # 用户标识
self.project_path = project_path # 项目路径
self.created_at = datetime.now() # 创建时间
self.last_active = datetime.now() # 最后活跃时间
self.threads: Dict[str, Thread] = {} # 该会话下的所有线程
self.active_thread_id: Optional[str] = None # 当前活跃线程
self.user_preferences = UserPreferences() # 用户偏好设置
self.global_context = GlobalContext() # 全局上下文
@property
def is_active(self) -> bool:
"""检查会话是否活跃(30分钟无活动视为非活跃)"""
return (datetime.now() - self.last_active).seconds < 1800Session 层的核心职责包括:
- 线程管理:创建、切换、归档 Thread
- 全局上下文维护:项目级配置、用户偏好、长期记忆
- 资源清理:会话结束时负责释放所有子资源
- 状态持久化:定期保存会话状态,支持断点恢复
1.3 Thread:任务执行上下文
Thread 是对话管理中的核心抽象,代表一个完整的任务执行单元。当用户在 Session 中发起一个新任务时,我们创建一个新的 Thread。Thread 的生命周期从用户发起一个任务开始,到任务完成(明确关闭)或被用户主动放弃结束。
from enum import Enum
from typing import List, Optional, Dict, Any
from dataclasses import dataclass, field
from datetime import datetime
class ThreadStatus(Enum):
"""线程状态枚举"""
ACTIVE = "active" # 活跃,正在执行
WAITING = "waiting" # 等待用户输入
COMPLETED = "completed" # 任务完成
CANCELLED = "cancelled" # 被取消
FAILED = "failed" # 执行失败
@dataclass
class Thread:
"""
任务执行上下文
代表用户发起的一个完整任务
"""
thread_id: str
session_id: str # 所属会话
title: str # 任务标题(可由用户或 AI 生成)
status: ThreadStatus = ThreadStatus.ACTIVE
# 消息历史
messages: List[Message] = field(default_factory=list)
# 任务上下文
context: TaskContext = field(default_factory=TaskContext)
# 执行状态
created_at: datetime = field(default_factory=datetime.now)
updated_at: datetime = field(default_factory=datetime.now)
completed_at: Optional[datetime] = None
# 父线程(支持子任务)
parent_thread_id: Optional[str] = None
child_thread_ids: List[str] = field(default_factory=list)
# 元数据
tags: List[str] = field(default_factory=list)
metadata: Dict[str, Any] = field(default_factory=dict)
def add_message(self, message: "Message") -> None:
"""添加消息到线程"""
self.messages.append(message)
self.updated_at = datetime.now()
def get_messages(self,
role: Optional[str] = None,
limit: Optional[int] = None) -> List["Message"]:
"""获取消息列表"""
messages = self.messages
if role:
messages = [m for m in messages if m.role == role]
if limit:
messages = messages[-limit:]
return messages
def get_context_window(self, max_tokens: int = 128000) -> List["Message"]:
"""
获取上下文窗口(用于发送给模型)
从最新消息向前追溯,控制在 max_tokens 范围内
"""
window = []
total_tokens = 0
# 从最新消息开始向前
for message in reversed(self.messages):
message_tokens = message.estimate_tokens()
if total_tokens + message_tokens > max_tokens:
break
window.insert(0, message)
total_tokens += message_tokens
return windowThread 的设计借鉴了操作系统中的线程概念——轻量级的执行单元。每个 Thread 都有自己独立的上下文,但可以创建子线程来处理子任务,这种设计非常适合 AI IDE 中的复杂任务分解场景。
1.4 Message:单轮对话原子
Message 是对话管理中的最小粒度单位,代表一次完整的交互(用户输入 + AI 输出)。在某些实现中,我们也会将 Tool 调用和 Tool 结果拆分为独立的 Message 类型。
from enum import Enum
from typing import Optional, Dict, Any, List
from dataclasses import dataclass, field
from datetime import datetime
class MessageRole(Enum):
"""消息角色枚举"""
SYSTEM = "system" # 系统指令
USER = "user" # 用户输入
ASSISTANT = "assistant" # AI 响应
TOOL = "tool" # Tool 输出
FUNCTION = "function" # 函数调用(兼容旧格式)
@dataclass
class Message:
"""
单轮对话原子
"""
message_id: str
thread_id: str
role: MessageRole
# 内容
content: str
# 附件(如代码片段、文件引用)
attachments: List[Attachment] = field(default_factory=list)
# 引用(@mention、对话锚点)
references: List[Reference] = field(default_factory=list)
# Token 统计
input_tokens: int = 0
output_tokens: int = 0
# 时间戳
created_at: datetime = field(default_factory=datetime.now)
# 元数据
metadata: Dict[str, Any] = field(default_factory=dict)
# AI 响应元数据
model: Optional[str] = None
finish_reason: Optional[str] = None
def estimate_tokens(self) -> int:
"""估算 token 数量(粗略:中文约2字/token,英文约4字符/token)"""
# 精确计算需要使用 tiktoken 等库
if self.input_tokens > 0:
return self.input_tokens + self.output_tokens
# 粗略估算
chinese_chars = sum(1 for c in self.content if '\u4e00' <= c <= '\u9fff')
other_chars = len(self.content) - chinese_chars
return chinese_chars // 2 + other_chars // 4
def to_api_format(self) -> Dict[str, Any]:
"""转换为 API 格式"""
return {
"role": self.role.value,
"content": self.content,
}
@dataclass
class Attachment:
"""消息附件"""
type: str # "code", "file", "image"
path: Optional[str] = None # 文件路径
content: Optional[str] = None # 内联内容
language: Optional[str] = None # 代码语言
line_start: Optional[int] = None # 代码行号范围
line_end: Optional[int] = None
@dataclass
class Reference:
"""消息引用"""
type: str # "message", "file", "symbol"
target_id: str # 引用目标 ID
display_text: str # 显示文本
line_range: Optional[tuple] = None # 行号范围1.5 分层关系的 Mermaid 序列图
下面的序列图展示了用户与 AI IDE 进行多轮交互时,Session、Thread、Message 三层之间的交互流程:
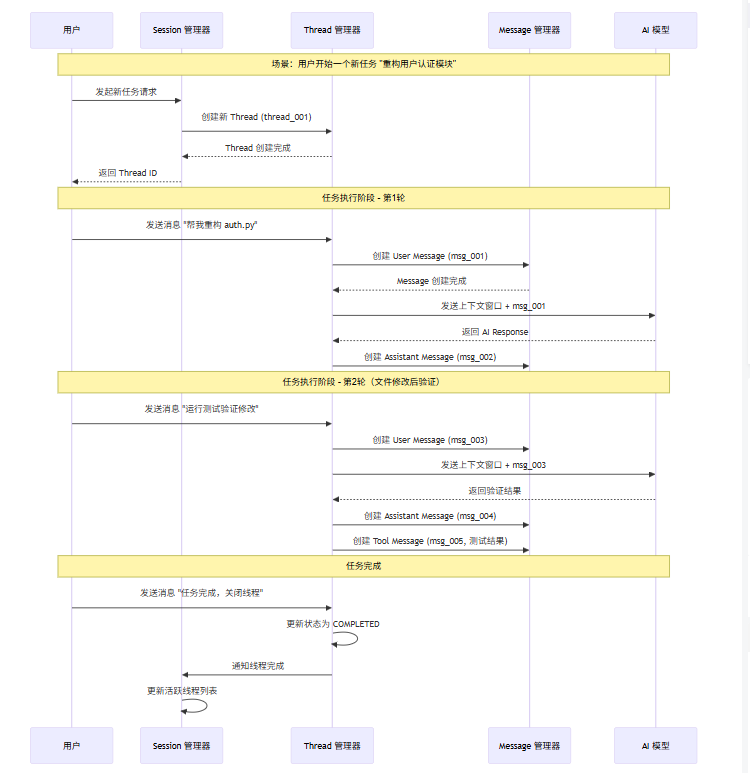
1.6 状态机的状态流转
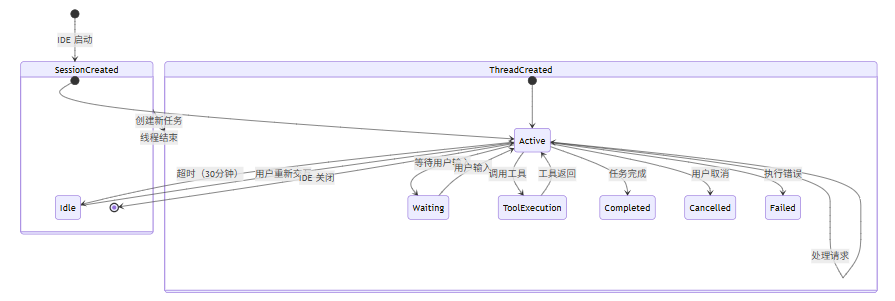
1.7 分层架构的工程实现
完整的分层架构实现如下:
from typing import Dict, Optional, List, Callable
from datetime import datetime
from enum import Enum
import uuid
class ConversationManager:
"""
对话管理器 - 核心组件
负责 Session、Thread、Message 的生命周期管理
"""
def __init__(self, config: "ManagerConfig"):
self.config = config
self.sessions: Dict[str, Session] = {}
self.active_session_id: Optional[str] = None
# 回调钩子
self.on_thread_created: Optional[Callable] = None
self.on_thread_completed: Optional[Callable] = None
self.on_message_added: Optional[Callable] = None
def create_session(self, user_id: str, project_path: str) -> Session:
"""创建新会话"""
session_id = str(uuid.uuid4())
session = Session(
session_id=session_id,
user_id=user_id,
project_path=project_path
)
self.sessions[session_id] = session
self.active_session_id = session_id
return session
def get_active_session(self) -> Optional[Session]:
"""获取当前活跃会话"""
if self.active_session_id:
return self.sessions.get(self.active_session_id)
return None
def create_thread(self,
session_id: str,
title: str,
parent_thread_id: Optional[str] = None) -> Thread:
"""在会话中创建新线程"""
session = self.sessions.get(session_id)
if not session:
raise ValueError(f"Session not found: {session_id}")
thread_id = str(uuid.uuid4())
thread = Thread(
thread_id=thread_id,
session_id=session_id,
title=title,
parent_thread_id=parent_thread_id
)
# 如果有父线程,建立父子关系
if parent_thread_id:
parent = session.threads.get(parent_thread_id)
if parent:
parent.child_thread_ids.append(thread_id)
session.threads[thread_id] = thread
session.active_thread_id = thread_id
# 触发钩子
if self.on_thread_created:
self.on_thread_created(thread)
return thread
def add_message(self,
thread_id: str,
role: MessageRole,
content: str,
**kwargs) -> Message:
"""向线程添加消息"""
session = self.get_active_session()
if not session:
raise ValueError("No active session")
thread = session.threads.get(thread_id)
if not thread:
raise ValueError(f"Thread not found: {thread_id}")
message_id = str(uuid.uuid4())
message = Message(
message_id=message_id,
thread_id=thread_id,
role=role,
content=content,
**kwargs
)
thread.add_message(message)
# 触发钩子
if self.on_message_added:
self.on_message_added(thread, message)
return message
def complete_thread(self, thread_id: str) -> None:
"""标记线程为完成"""
session = self.get_active_session()
if not session:
return
thread = session.threads.get(thread_id)
if thread:
thread.status = ThreadStatus.COMPLETED
thread.completed_at = datetime.now()
if self.on_thread_completed:
self.on_thread_completed(thread)
def get_thread_context(self,
thread_id: str,
max_tokens: int = 128000) -> List[Message]:
"""获取线程的上下文窗口"""
session = self.get_active_session()
if not session:
return []
thread = session.threads.get(thread_id)
if not thread:
return []
return thread.get_context_window(max_tokens)2 上下文维护:滑动窗口、摘要压缩、选择性记忆
2.1 上下文管理的核心挑战
上下文维护是对话管理系统中最具技术挑战性的部分。现代 AI 模型(如 GPT-4、Claude 3)的上下文窗口虽然已经很大(128K-200K tokens),但在长时间对话中仍然可能面临上下文溢出的问题。更重要的是,上下文窗口中并非所有信息都有价值——我们需要智能地选择保留什么、丢弃什么。
上下文管理的三大挑战:
挑战 | 描述 | 解决方案 |
|---|---|---|
容量限制 | 模型上下文窗口有上限 | 滑动窗口、摘要压缩 |
信息筛选 | 并非所有历史都有价值 | 选择性记忆、重要性评估 |
连贯性维护 | 丢弃信息可能破坏上下文 | 保留关键锚点、摘要机制 |
2.2 滑动窗口策略
滑动窗口是最基本的上下文管理策略。其核心思想是:始终保持最近 N 条消息或最近 M 个 tokens。
from typing import List, Optional, Tuple
from dataclasses import dataclass
@dataclass
class SlidingWindowConfig:
"""滑动窗口配置"""
max_messages: int = 50 # 最大消息数
max_tokens: int = 128000 # 最大 token 数
preserve_system_prompt: bool = True # 是否保留系统提示
preserve_first_user_msg: bool = True # 是否保留首条用户消息
class SlidingWindowManager:
"""
滑动窗口管理器
实现简单的固定窗口上下文管理
"""
def __init__(self, config: Optional[SlidingWindowConfig] = None):
self.config = config or SlidingWindowConfig()
def trim_messages(self, messages: List[Message]) -> List[Message]:
"""
对消息列表进行滑动窗口裁剪
"""
if not messages:
return []
# 按时间排序( oldest first)
sorted_messages = sorted(messages, key=lambda m: m.created_at)
# 分离系统消息和对话消息
system_messages = [
m for m in sorted_messages
if m.role == MessageRole.SYSTEM
]
dialog_messages = [
m for m in sorted_messages
if m.role != MessageRole.SYSTEM
]
# 计算 token 总数
total_tokens = sum(m.estimate_tokens() for m in sorted_messages)
# 如果已经超限,开始裁剪
if total_tokens <= self.config.max_tokens:
return self._apply_message_limit(sorted_messages)
# 超过 token 限制,从旧消息开始裁剪
result = []
current_tokens = 0
# 优先保留:系统消息
for msg in system_messages:
if self.config.preserve_system_prompt:
result.append(msg)
current_tokens += msg.estimate_tokens()
# 优先保留:首条用户消息
first_user_msg = None
if self.config.preserve_first_user_msg:
for msg in dialog_messages:
if msg.role == MessageRole.USER:
first_user_msg = msg
break
if first_user_msg:
result.append(first_user_msg)
current_tokens += first_user_msg.estimate_tokens()
# 从最新消息开始添加
for msg in reversed(dialog_messages):
if msg == first_user_msg:
continue
msg_tokens = msg.estimate_tokens()
if current_tokens + msg_tokens > self.config.max_tokens:
# 如果这是最后一条消息,强制添加以保证至少一轮对话
if len(result) == len([m for m in result if m.role != MessageRole.SYSTEM]):
continue
break
result.insert(len(system_messages), msg)
current_tokens += msg_tokens
if len(result) >= self.config.max_messages + len(system_messages):
break
return sorted(result, key=lambda m: m.created_at)
def _apply_message_limit(self, messages: List[Message]) -> List[Message]:
"""应用消息数量限制"""
if len(messages) <= self.config.max_messages:
return messages
# 分离系统消息
system_messages = [m for m in messages if m.role == MessageRole.SYSTEM]
dialog_messages = [m for m in messages if m.role != MessageRole.SYSTEM]
# 保留最新的 max_messages 条
kept_dialog = dialog_messages[-self.config.max_messages:]
return system_messages + kept_dialog2.3 摘要压缩策略
滑动窗口的缺点是可能丢弃重要的早期上下文。例如,用户可能在对话开始时明确说明了技术约束、业务规则或代码规范,但在后续的对话中被滑动窗口丢弃了。
摘要压缩策略通过将早期对话压缩为摘要来解决这个问题:
from abc import ABC, abstractmethod
from typing import List, Optional, Callable
import json
class Summarizer(ABC):
"""摘要生成器抽象基类"""
@abstractmethod
def summarize(self, messages: List[Message]) -> str:
"""生成摘要"""
pass
class DefaultSummarizer(Summarizer):
"""
默认摘要生成器
使用 AI 模型生成摘要
"""
def __init__(self, ai_client: "AIClient"):
self.ai_client = ai_client
def summarize(self, messages: List[Message]) -> str:
prompt = self._build_summary_prompt(messages)
response = self.ai_client.complete(prompt)
return response.content
def _build_summary_prompt(self, messages: List[Message]) -> str:
"""构建摘要提示"""
dialog_text = "\n".join([
f"{msg.role.value}: {msg.content[:200]}..."
if len(msg.content) > 200 else f"{msg.role.value}: {msg.content}"
for msg in messages
])
return f"""请为以下对话生成简洁的摘要,保留关键信息和决策:
{dialog_text}
摘要要求:
1. 包含关键任务目标和技术决策
2. 保留重要的约束条件或规范
3. 注明任何未完成或待处理的事项
4. 限制在 500 字以内
摘要:"""
class HybridContextManager:
"""
混合上下文管理器
结合滑动窗口和摘要压缩
"""
# 多少轮对话后开始摘要压缩
SUMMARY_INTERVAL = 20
# 保留多少轮完整对话后才压缩
KEEP_FULL_DIALOGS = 5
def __init__(self,
sliding_window: SlidingWindowManager,
summarizer: Summarizer,
config: Optional[dict] = None):
self.sliding_window = sliding_window
self.summarizer = summarizer
self.config = config or {}
# 摘要历史
self.summary_history: Dict[str, List[str]] = {} # thread_id -> summaries
# 待压缩的对话
self.pending_summaries: Dict[str, List[Message]] = {}
def get_context_for_inference(self, thread: Thread) -> List[Message]:
"""
获取用于推理的上下文
"""
all_messages = thread.messages
current_count = len(all_messages)
# 如果对话数量超过阈值,开始摘要流程
if current_count > self.SUMMARY_INTERVAL:
return self._get_compressed_context(thread)
# 否则使用滑动窗口
return self.sliding_window.trim_messages(all_messages)
def _get_compressed_context(self, thread: Thread) -> List[Message]:
"""获取压缩后的上下文"""
thread_id = thread.thread_id
# 初始化历史摘要
if thread_id not in self.summary_history:
self.summary_history[thread_id] = []
self.pending_summaries[thread_id] = []
all_messages = thread.messages
# 计算需要保留的完整对话数
keep_count = self.KEEP_FULL_DIALOGS * 2 # user + assistant
recent_messages = all_messages[-keep_count:]
older_messages = all_messages[:-keep_count]
# 生成早期对话的摘要
if older_messages:
summary = self.summarizer.summarize(older_messages)
self.summary_history[thread_id].append(summary)
# 构建最终上下文:摘要 + 最近对话
result = []
# 添加历史摘要作为系统上下文
for hist_summary in self.summary_history[thread_id]:
result.append(Message(
message_id=f"summary_{len(result)}",
thread_id=thread_id,
role=MessageRole.SYSTEM,
content=f"[早期对话摘要] {hist_summary}"
))
# 添加最近完整对话
result.extend(recent_messages)
# 最终裁剪确保不超过限制
return self.sliding_window.trim_messages(result)
def force_summarize(self, thread: Thread) -> str:
"""强制执行摘要并返回摘要内容"""
thread_id = thread.thread_id
if thread_id not in self.pending_summaries:
self.pending_summaries[thread_id] = []
# 将所有未摘要的消息加入待处理
existing_summary_count = len(self.summary_history.get(thread_id, []))
pending = self.pending_summaries[thread_id]
# 计算待摘要的消息范围
start_idx = existing_summary_count * self.SUMMARY_INTERVAL
messages_to_summarize = thread.messages[start_idx:]
if not messages_to_summarize:
return ""
summary = self.summarizer.summarize(messages_to_summarize)
if thread_id not in self.summary_history:
self.summary_history[thread_id] = []
self.summary_history[thread_id].append(summary)
return summary2.4 选择性记忆策略
更高级的上下文管理策略是选择性记忆——不是简单地丢弃旧消息,而是根据消息的重要性进行选择性保留。
from enum import Enum
from dataclasses import dataclass
import re
class ImportanceLevel(Enum):
"""重要性级别"""
CRITICAL = 5 # 必须保留(系统提示、关键决策)
HIGH = 4 # 高优先级(代码规范、约束条件)
MEDIUM = 3 # 中等优先级(一般讨论)
LOW = 2 # 低优先级(闲聊、问候)
IGNORABLE = 1 # 可丢弃(重复确认、空消息)
class ImportanceClassifier:
"""
消息重要性分类器
"""
# 关键模式匹配
CRITICAL_PATTERNS = [
r"必须、禁止、不得、应该遵循",
r"安全|Security|安全漏洞",
r"架构|Architecture|设计模式",
r"性能|Performance|优化",
]
HIGH_PATTERNS = [
r"规范|Standard|约定",
r"要求|Requirement|需求",
r"配置|Config|设置",
r"接口|API|Interface",
]
def classify(self, message: Message) -> ImportanceLevel:
"""分类消息重要性"""
content = message.content
# 检查关键模式
for pattern in self.CRITICAL_PATTERNS:
if re.search(pattern, content):
return ImportanceLevel.CRITICAL
for pattern in self.HIGH_PATTERNS:
if re.search(pattern, content):
return ImportanceLevel.HIGH
# 根据角色判断
if message.role == MessageRole.SYSTEM:
return ImportanceLevel.CRITICAL
if message.role == MessageRole.USER:
# 用户消息通常是中等到高优先级
if len(content) > 500:
return ImportanceLevel.HIGH
return ImportanceLevel.MEDIUM
# Assistant 消息中的代码修改通常是高优先级
if "```" in content or "def " in content or "class " in content:
return ImportanceLevel.HIGH
return ImportanceLevel.MEDIUM
class SelectiveMemoryManager:
"""
选择性记忆管理器
根据重要性决定消息保留策略
"""
def __init__(self,
sliding_window: SlidingWindowManager,
classifier: ImportanceClassifier,
max_tokens: int = 128000):
self.sliding_window = sliding_window
self.classifier = classifier
self.max_tokens = max_tokens
# 永久记忆(永不删除)
self.permanent_memory: List[Message] = []
# 长期记忆(保留到最后)
self.long_term_memory: List[Message] = []
def add_permanent(self, message: Message) -> None:
"""添加永久记忆"""
self.permanent_memory.append(message)
def add_long_term(self, message: Message) -> None:
"""添加长期记忆"""
self.long_term_memory.append(message)
def select_memory(self, messages: List[Message]) -> List[Message]:
"""
选择性记忆核心算法
"""
# 分类所有消息
classified = {
ImportanceLevel.CRITICAL: [],
ImportanceLevel.HIGH: [],
ImportanceLevel.MEDIUM: [],
ImportanceLevel.LOW: [],
ImportanceLevel.IGNORABLE: [],
}
for msg in messages:
level = self.classifier.classify(msg)
classified[level].append(msg)
# 构建最终上下文
result = []
total_tokens = 0
# 第一层:永久记忆
for msg in self.permanent_memory:
tokens = msg.estimate_tokens()
if total_tokens + tokens > self.max_tokens:
break
result.append(msg)
total_tokens += tokens
# 第二层:长期记忆(保留关键决策)
for msg in self.long_term_memory:
tokens = msg.estimate_tokens()
if total_tokens + tokens > self.max_tokens:
break
result.append(msg)
total_tokens += tokens
# 第三层:按重要性从高到低填充
remaining_slots = self.max_tokens - total_tokens
for level in [ImportanceLevel.HIGH, ImportanceLevel.MEDIUM,
ImportanceLevel.LOW, ImportanceLevel.IGNORABLE]:
for msg in classified[level]:
tokens = msg.estimate_tokens()
if total_tokens + tokens > self.max_tokens:
break
result.append(msg)
total_tokens += tokens
if total_tokens >= self.max_tokens:
break
return result
def prune_and_select(self, messages: List[Message]) -> List[Message]:
"""裁剪并选择"""
# 先分类
selected = self.select_memory(messages)
# 再用滑动窗口确保不超过限制
return self.sliding_window.trim_messages(selected)2.5 上下文维护策略对比
策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
滑动窗口 | 实现简单、无额外开销 | 可能丢失关键信息 | 短对话、简单任务 |
摘要压缩 | 保留关键信息、可持续 | 摘要质量依赖 AI、延迟开销 | 长对话、复杂任务 |
选择性记忆 | 智能保留高价值信息 | 实现复杂、分类器可能不准确 | 企业级应用、关键系统 |
3 历史引用:@mention、对话锚点、上下文回溯
3.1 历史引用的本质
在长时间对话中,用户经常需要引用历史消息来进行回复。典型的场景包括:
- “你说的第二个方案是什么?”
- “把之前生成的那个函数改成支持异步”
- “@msg_1234 这个文件需要添加异常处理”
历史引用本质上是一种上下文定位问题——用户通过某种引用机制,让 AI 能够精确定位到历史消息或历史上下文。
3.2 @mention 机制实现
@mention 是最直观的引用方式,用户通过 @消息ID 或 @消息序号 来引用特定消息。
import re
from typing import List, Optional, Dict, Any
from dataclasses import dataclass
@dataclass
class Mention:
"""提及引用"""
mention_type: str # "message_id", "index", "keyword"
target: str # 引用目标
display_text: str # 显示文本
original_text: str # 原始文本(如 "@msg_123")
class MentionParser:
"""
提及解析器
将用户输入中的 @mention 解析为具体引用
"""
# 支持的 mention 格式
MENTION_PATTERNS = [
r'@msg_([a-zA-Z0-9_-]+)', # @msg_xxxxx
r'@(\d+)', # @1, @2 (序号)
r'@\[([^\]]+)\]', # @[关键词]
]
def __init__(self):
self.compiled_patterns = [
(re.compile(p), t)
for p, t in zip(self.MENTION_PATTERNS,
["message_id", "index", "keyword"])
]
def parse(self, text: str) -> List[Mention]:
"""解析文本中的所有 mention"""
mentions = []
for pattern, mtype in self.compiled_patterns:
for match in pattern.finditer(text):
if mtype == "message_id":
mention = Mention(
mention_type="message_id",
target=match.group(1),
display_text=match.group(0),
original_text=match.group(0)
)
elif mtype == "index":
mention = Mention(
mention_type="index",
target=int(match.group(1)),
display_text=match.group(0),
original_text=match.group(0)
)
else: # keyword
mention = Mention(
mention_type="keyword",
target=match.group(1),
display_text=match.group(0),
original_text=match.group(0)
)
mentions.append(mention)
return mentions
def resolve_mention(self,
mention: Mention,
messages: List[Message]) -> Optional[Message]:
"""解析 mention 到具体消息"""
if mention.mention_type == "message_id":
for msg in messages:
if msg.message_id == mention.target:
return msg
elif mention.mention_type == "index":
# 序号是 1-based,从最新消息开始计数
# @1 = 最新消息,@2 = 次新消息
user_messages = [m for m in messages if m.role == MessageRole.USER]
user_messages.reverse() # 最新在前
idx = mention.target - 1
if 0 <= idx < len(user_messages):
return user_messages[idx]
elif mention.mention_type == "keyword":
# 匹配包含关键词的消息
for msg in reversed(messages): # 从最新开始
if mention.target.lower() in msg.content.lower():
return msg
return None
def resolve_all_mentions(self,
text: str,
messages: List[Message]) -> tuple[str, List[Message]]:
"""
解析文本中所有 mention 并替换为实际引用
返回:(替换后的文本, 引用到的消息列表)
"""
mentions = self.parse(text)
resolved_messages = []
resolved_text = text
for mention in mentions:
resolved = self.resolve_mention(mention, messages)
if resolved:
resolved_messages.append(resolved)
# 替换 mention 为引用格式
# 例如:@1 -> [用户消息: 具体内容...]
replacement = f"[引用消息 {mention.target}]: {resolved.content[:100]}..."
resolved_text = resolved_text.replace(
mention.original_text,
replacement
)
return resolved_text, resolved_messages3.3 对话锚点机制
对话锚点是一种自动标记机制,系统会自动识别并标记重要的对话节点,用户可以通过锚点快速回溯。
from enum import Enum
from typing import List, Optional, Callable
from dataclasses import dataclass, field
import hashlib
class AnchorType(Enum):
"""锚点类型"""
FILE_CREATED = "file_created" # 文件创建
FILE_MODIFIED = "file_modified" # 文件修改
CODE_GENERATED = "code_generated" # 代码生成
ERROR_OCCURRED = "error_occurred" # 错误发生
DECISION_MADE = "decision_made" # 决策做出
REQUIREMENT_CLARIFIED =requirement_clarified" # 需求明确
MANUAL = "manual" # 手动标记
@dataclass
class ConversationAnchor:
"""对话锚点"""
anchor_id: str
thread_id: str
anchor_type: AnchorType
message_id: str # 关联的消息
# 锚点描述
title: str # 锚点标题
description: str = "" # 详细描述
# 上下文快照
context_snapshot: str = "" # 上下文摘要
# 位置信息
message_index: int = 0 # 消息序号
timestamp: "datetime" = field(default_factory="datetime.now")
# 元数据
metadata: dict = field(default_factory=dict)
class AnchorManager:
"""
锚点管理器
自动和手动创建对话锚点
"""
def __init__(self):
self.anchors: Dict[str, List[ConversationAnchor]] = {} # thread_id -> anchors
# 锚点检测器
self.detectors: List[Callable] = [
self._detect_file_operations,
self._detect_code_generation,
self._detect_errors,
]
def _detect_file_operations(self, message: Message) -> Optional[AnchorType]:
"""检测文件操作"""
content = message.content.lower()
if "创建" in content and ("文件" in content or "file" in content):
return AnchorType.FILE_CREATED
if "修改" in content or "编辑" in content:
return AnchorType.FILE_MODIFIED
return None
def _detect_code_generation(self, message: Message) -> Optional[AnchorType]:
"""检测代码生成"""
if "```" in message.content and message.role == MessageRole.ASSISTANT:
return AnchorType.CODE_GENERATED
return None
def _detect_errors(self, message: Message) -> Optional[AnchorType]:
"""检测错误"""
error_keywords = ["error", "错误", "exception", "异常", "failed", "失败"]
content = message.content.lower()
if any(kw in content for kw in error_keywords):
return AnchorType.ERROR_OCCURRED
return None
def auto_detect_anchors(self,
thread_id: str,
messages: List[Message]) -> List[ConversationAnchor]:
"""自动检测并创建锚点"""
if thread_id not in self.anchors:
self.anchors[thread_id] = []
existing_ids = {a.message_id for a in self.anchors[thread_id]}
new_anchors = []
for idx, msg in enumerate(messages):
if msg.message_id in existing_ids:
continue
# 运行所有检测器
for detector in self.detectors:
anchor_type = detector(msg)
if anchor_type:
anchor = self._create_anchor(
thread_id=thread_id,
message_id=msg.message_id,
anchor_type=anchor_type,
message_index=idx,
content=msg.content
)
new_anchors.append(anchor)
break
self.anchors[thread_id].extend(new_anchors)
return new_anchors
def _create_anchor(self,
thread_id: str,
message_id: str,
anchor_type: AnchorType,
message_index: int,
content: str) -> ConversationAnchor:
"""创建锚点"""
anchor_id = hashlib.md5(
f"{thread_id}:{message_id}:{anchor_type.value}".encode()
).hexdigest()[:12]
# 生成锚点标题
title_map = {
AnchorType.FILE_CREATED: "📄 文件创建",
AnchorType.FILE_MODIFIED: "✏️ 文件修改",
AnchorType.CODE_GENERATED: "💻 代码生成",
AnchorType.ERROR_OCCURRED: "⚠️ 错误发生",
AnchorType.DECISION_MADE: "✅ 决策确定",
AnchorType.REQUIREMENT_CLARIFIED: "📋 需求明确",
}
title = title_map.get(anchor_type, "🔖 锚点")
return ConversationAnchor(
anchor_id=anchor_id,
thread_id=thread_id,
anchor_type=anchor_type,
message_id=message_id,
title=title,
description=content[:200],
context_snapshot=content[:500],
message_index=message_index
)
def create_manual_anchor(self,
thread_id: str,
message_id: str,
title: str,
description: str = "") -> ConversationAnchor:
"""手动创建锚点"""
if thread_id not in self.anchors:
self.anchors[thread_id] = []
anchor = self._create_anchor(
thread_id=thread_id,
message_id=message_id,
anchor_type=AnchorType.MANUAL,
message_index=0,
content=description
)
anchor.title = title
anchor.description = description
self.anchors[thread_id].append(anchor)
return anchor
def get_anchors(self,
thread_id: str,
anchor_type: Optional[AnchorType] = None) -> List[ConversationAnchor]:
"""获取线程的所有锚点"""
anchors = self.anchors.get(thread_id, [])
if anchor_type:
anchors = [a for a in anchors if a.anchor_type == anchor_type]
return sorted(anchors, key=lambda a: a.message_index)
def navigate_to_anchor(self,
anchor: ConversationAnchor,
messages: List[Message]) -> List[Message]:
"""导航到锚点,返回锚点前后的上下文"""
anchor_idx = None
for idx, msg in enumerate(messages):
if msg.message_id == anchor.message_id:
anchor_idx = idx
break
if anchor_idx is None:
return []
# 返回锚点前 5 条和后 10 条消息
start = max(0, anchor_idx - 5)
end = min(len(messages), anchor_idx + 10)
return messages[start:end]3.4 上下文回溯机制
上下文回溯允许用户回到之前的对话状态,重新开始或继续某个分支。
from typing import Dict, List, Optional
from dataclasses import dataclass
import json
@dataclass
class ContextSnapshot:
"""上下文快照"""
snapshot_id: str
thread_id: str
timestamp: "datetime"
# 快照点信息
from_message_id: str # 从哪个消息开始
message_count: int # 包含多少条消息
# 序列化数据
messages_data: str # 序列化后的消息
# 元数据
description: str = "" # 快照描述
branch_from: Optional[str] = None # 如果是分支,从哪个消息分出
class ContextSnapshotManager:
"""
上下文快照管理器
支持创建、恢复、对比上下文快照
"""
def __init__(self, storage_path: Optional[str] = None):
self.storage_path = storage_path
self.snapshots: Dict[str, List[ContextSnapshot]] = {} # thread_id -> snapshots
def create_snapshot(self,
thread: Thread,
from_message_id: Optional[str] = None,
description: str = "") -> ContextSnapshot:
"""创建上下文快照"""
import base64
import pickle
thread_id = thread.thread_id
# 找到起始消息
messages = thread.messages
start_idx = 0
if from_message_id:
for idx, msg in enumerate(messages):
if msg.message_id == from_message_id:
start_idx = idx
break
# 序列化消息
messages_to_snapshot = messages[start_idx:]
serialized = pickle.dumps(messages_to_snapshot)
snapshot = ContextSnapshot(
snapshot_id=f"snap_{thread_id}_{len(self.snapshots.get(thread_id, []))}",
thread_id=thread_id,
timestamp=datetime.now(),
from_message_id=from_message_id or (messages[0].message_id if messages else ""),
message_count=len(messages_to_snapshot),
messages_data=base64.b64encode(serialized).decode(),
description=description or f"快照 at message {start_idx}"
)
if thread_id not in self.snapshots:
self.snapshots[thread_id] = []
self.snapshots[thread_id].append(snapshot)
# 持久化
if self.storage_path:
self._persist_snapshots(thread_id)
return snapshot
def restore_snapshot(self, snapshot: ContextSnapshot) -> List[Message]:
"""恢复快照"""
import base64
import pickle
serialized = base64.b64decode(snapshot.messages_data.encode())
return pickle.loads(serialized)
def compare_snapshots(self,
snapshot1: ContextSnapshot,
snapshot2: ContextSnapshot) -> Dict[str, Any]:
"""对比两个快照的差异"""
messages1 = self.restore_snapshot(snapshot1)
messages2 = self.restore_snapshot(snapshot2)
# 简单对比
return {
"message_count_diff": len(messages2) - len(messages1),
"snapshot1_time": snapshot1.timestamp.isoformat(),
"snapshot2_time": snapshot2.timestamp.isoformat(),
"elapsed_seconds": (snapshot2.timestamp - snapshot1.timestamp).total_seconds(),
}
def fork_from_snapshot(self,
snapshot: ContextSnapshot,
new_thread: Thread) -> None:
"""从快照创建分支线程"""
messages = self.restore_snapshot(snapshot)
# 添加分支标记
for msg in messages:
msg.metadata["forked_from"] = snapshot.snapshot_id
# 添加到新线程
for msg in messages:
new_thread.add_message(msg)
def _persist_snapshots(self, thread_id: str) -> None:
"""持久化快照到磁盘"""
if not self.storage_path:
return
path = f"{self.storage_path}/{thread_id}_snapshots.json"
snapshots_data = [
{
"snapshot_id": s.snapshot_id,
"thread_id": s.thread_id,
"timestamp": s.timestamp.isoformat(),
"from_message_id": s.from_message_id,
"message_count": s.message_count,
"description": s.description,
}
for s in self.snapshots.get(thread_id, [])
]
with open(path, "w", encoding="utf-8") as f:
json.dump(snapshots_data, f, ensure_ascii=False, indent=2)3.5 引用解析的 Mermaid 序列图
下面的序列图展示了用户发送带有引用的消息时,系统如何解析引用并构建完整上下文:
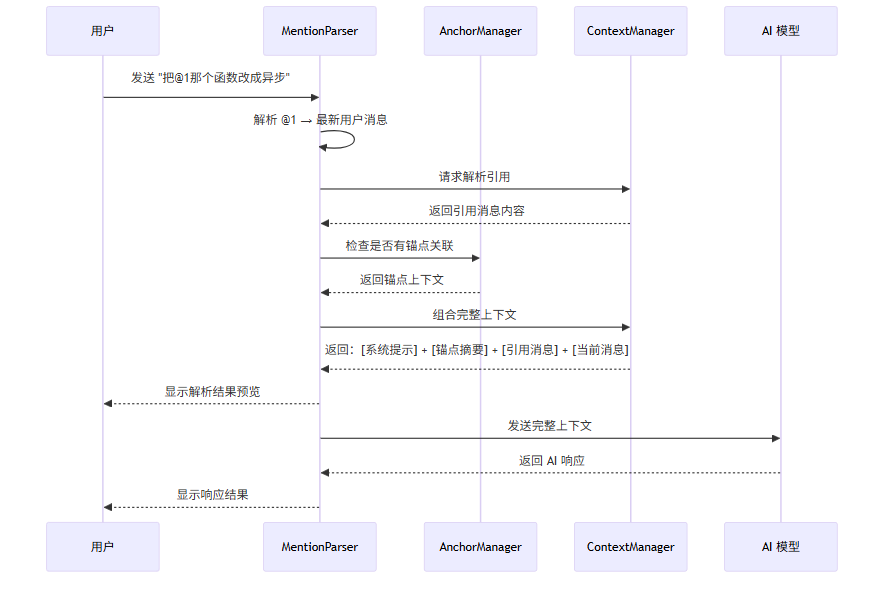
4 多会话管理:项目级 vs 任务级会话
4.1 为什么需要多会话隔离
在 AI IDE 中,用户可能同时处理多个项目,每个项目有多个任务,每个任务有多个对话。如果把所有对话混在一起,会导致:
- 上下文污染:项目 A 的上下文影响项目 B 的响应
- 性能下降:无用的历史消息占用上下文窗口
- 管理混乱:无法追踪任务进度
因此,我们需要会话隔离机制,确保不同项目和任务的上下文互不干扰。
4.2 项目级会话与任务级会话的区别
维度 | 项目级会话 (Project Session) | 任务级会话 (Task Thread) |
|---|---|---|
生命周期 | 项目打开到关闭 | 任务开始到完成 |
范围 | 整个项目 | 单个任务 |
状态 | 项目配置、用户偏好、全局知识 | 任务上下文、代码变更、中间结果 |
数量 | 每个项目一个 | 每个任务一个或多个 |
隔离性 | 项目间完全隔离 | 任务间可选择共享上下文 |
4.3 多会话架构实现
from typing import Dict, List, Optional, Set
from dataclasses import dataclass, field
from enum import Enum
class SessionScope(Enum):
"""会话作用域"""
GLOBAL = "global" # 全局会话
PROJECT = "project" # 项目级会话
TASK = "task" # 任务级会话
@dataclass
class ProjectSession:
"""
项目级会话
生命周期:项目打开到关闭
"""
project_session_id: str
project_path: str
project_name: str
# 项目配置
config: "ProjectConfig"
# 任务线程
threads: Dict[str, Thread] = field(default_factory=dict)
active_thread_id: Optional[str] = None
# 项目级上下文
project_context: "ProjectContext"
# 元数据
created_at: "datetime" = field(default_factory="datetime.now")
last_active: "datetime" = field(default_factory="datetime.now")
# 标签和分类
tags: Set[str] = field(default_factory=set)
class MultiSessionManager:
"""
多会话管理器
负责管理项目级和任务级会话
"""
def __init__(self, config: Optional["MultiSessionConfig"] = None):
self.config = config or MultiSessionConfig()
# 全局会话(跨项目)
self.global_session: Optional[Session] = None
# 项目会话
self.project_sessions: Dict[str, ProjectSession] = {}
self.active_project_session_id: Optional[str] = None
# 任务上下文缓存
self.task_context_cache: Dict[str, Any] = {}
def create_project_session(self,
project_path: str,
project_name: str,
config: "ProjectConfig") -> ProjectSession:
"""创建项目级会话"""
project_session_id = f"proj_{hashlib.md5(project_path.encode()).hexdigest()[:8]}"
project_session = ProjectSession(
project_session_id=project_session_id,
project_path=project_path,
project_name=project_name,
config=config,
project_context=ProjectContext(project_path)
)
self.project_sessions[project_session_id] = project_session
self.active_project_session_id = project_session_id
return project_session
def get_active_project_session(self) -> Optional[ProjectSession]:
"""获取当前活跃的项目会话"""
if self.active_project_session_id:
return self.project_sessions.get(self.active_project_session_id)
return None
def create_task_thread(self,
project_session_id: str,
title: str,
parent_thread_id: Optional[str] = None) -> Thread:
"""在项目会话中创建任务线程"""
project_session = self.project_sessions.get(project_session_id)
if not project_session:
raise ValueError(f"Project session not found: {project_session_id}")
thread_id = f"thread_{uuid.uuid4().hex[:12]}"
thread = Thread(
thread_id=thread_id,
session_id=project_session_id,
title=title,
parent_thread_id=parent_thread_id
)
project_session.threads[thread_id] = thread
project_session.active_thread_id = thread_id
return thread
def switch_task_thread(self,
project_session_id: str,
thread_id: str) -> None:
"""切换活跃的任务线程"""
project_session = self.project_sessions.get(project_session_id)
if not project_session:
raise
if thread_id in project_session.threads:
project_session.active_thread_id = thread_id
project_session.last_active = datetime.now()
def share_context_between_threads(self,
thread_id_1: str,
thread_id_2: str,
share_type: str = "full") -> None:
"""
在线程间共享上下文
share_type: "full" (完全共享), "summary" (只共享摘要), "selective" (选择性共享)
"""
project_session = self.get_active_project_session()
if not project_session:
return
thread1 = project_session.threads.get(thread_id_1)
thread2 = project_session.threads.get(thread_id_2)
if not thread1 or not thread2:
return
if share_type == "full":
# 完全共享:复制所有消息
for msg in thread1.messages:
thread2.add_message(msg)
elif share_type == "summary":
# 只共享摘要
summary = self._generate_thread_summary(thread1)
thread2.context.add("shared_summary", summary)
elif share_type == "selective":
# 选择性共享:只共享高优先级消息
for msg in thread1.messages:
if self._is_high_priority(msg):
thread2.add_message(msg)
def _is_high_priority(self, message: Message) -> bool:
"""判断消息是否高优先级"""
classifier = ImportanceClassifier()
level = classifier.classify(message)
return level in [ImportanceLevel.CRITICAL, ImportanceLevel.HIGH]
def _generate_thread_summary(self, thread: Thread) -> str:
"""生成线程摘要"""
# 使用 AI 生成摘要的简化实现
messages = thread.messages
if not messages:
return ""
content_summary = "\n".join([
f"{m.role.value}: {m.content[:100]}..."
for m in messages[-10:]
])
return f"线程 '{thread.title}' 摘要:\n{content_summary}"4.4 上下文隔离与共享的平衡
在实际项目中,我们需要在隔离性和共享性之间找到平衡。完全隔离会导致重复工作,完全共享会导致上下文污染。
from typing import Dict, Set, List
class ContextIsolationStrategy(Enum):
"""上下文隔离策略"""
STRICT = "strict" # 完全隔离
MODERATE = "moderate" # 中等隔离(共享项目级上下文)
OPEN = "open" # 开放(可选择性共享)
@dataclass
class ContextSharingRule:
"""上下文共享规则"""
source_scope: SessionScope # 源作用域
target_scope: SessionScope # 目标作用域
share_type: str # "none", "summary", "selective", "full"
share_conditions: List[str] = field(default_factory=list) # 触发条件
class ContextIsolationManager:
"""
上下文隔离管理器
根据规则管理不同作用域之间的上下文共享
"""
def __init__(self, strategy: ContextIsolationStrategy = ContextIsolationStrategy.MODERATE):
self.strategy = strategy
self.sharing_rules: List[ContextSharingRule] = []
# 默认规则
self._init_default_rules()
def _init_default_rules(self) -> None:
"""初始化默认共享规则"""
if self.strategy == ContextIsolationStrategy.STRICT:
# 严格模式:不共享任何上下文
self.sharing_rules = [
ContextSharingRule(SessionScope.GLOBAL, SessionScope.PROJECT, "summary"),
ContextSharingRule(SessionScope.PROJECT, SessionScope.TASK, "summary"),
ContextSharingRule(SessionScope.TASK, SessionScope.TASK, "none"),
]
elif self.strategy == ContextIsolationStrategy.MODERATE:
# 中等模式:项目级上下文可共享
self.sharing_rules = [
ContextSharingRule(SessionScope.GLOBAL, SessionScope.PROJECT, "full"),
ContextSharingRule(SessionScope.PROJECT, SessionScope.TASK, "full"),
ContextSharingRule(SessionScope.TASK, SessionScope.TASK, "selective"),
]
else: # OPEN
# 开放模式:几乎所有上下文可共享
self.sharing_rules = [
ContextSharingRule(SessionScope.GLOBAL, SessionScope.PROJECT, "full"),
ContextSharingRule(SessionScope.PROJECT, SessionScope.TASK, "full"),
ContextSharingRule(SessionScope.TASK, SessionScope.TASK, "full"),
]
def get_shared_context(self,
source_scope: SessionScope,
target_scope: SessionScope,
source_thread: Thread,
target_thread: Thread) -> List[Message]:
"""根据规则获取共享上下文"""
rule = self._find_rule(source_scope, target_scope)
if not rule or rule.share_type == "none":
return []
if rule.share_type == "full":
return source_thread.messages
if rule.share_type == "summary":
# 只返回源线程的摘要
summary_msg = Message(
message_id="shared_summary",
thread_id=target_thread.thread_id,
role=MessageRole.SYSTEM,
content=f"[来自线程 '{source_thread.title}' 的上下文]\n"
+ self._generate_summary(source_thread)
)
return [summary_msg]
if rule.share_type == "selective":
# 选择性共享高优先级消息
classifier = ImportanceClassifier()
return [
msg for msg in source_thread.messages
if classifier.classify(msg) in [
ImportanceLevel.CRITICAL,
ImportanceLevel.HIGH
]
]
return []
def _find_rule(self,
source_scope: SessionScope,
target_scope: SessionScope) -> Optional[ContextSharingRule]:
"""查找适用的共享规则"""
for rule in self.sharing_rules:
if rule.source_scope == source_scope and rule.target_scope == target_scope:
return rule
return None
def _generate_summary(self, thread: Thread) -> str:
"""生成线程摘要"""
if not thread.messages:
return "(空线程)"
# 简化实现:取前3条和后3条消息的摘要
summary_parts = []
for msg in thread.messages[:3]:
summary_parts.append(f"- [{msg.role.value}] {msg.content[:50]}...")
if len(thread.messages) > 6:
summary_parts.append(f"- ... ({len(thread.messages) - 6} 条消息省略)")
for msg in thread.messages[-3:]:
summary_parts.append(f"- [{msg.role.value}] {msg.content[:50]}...")
return "\n".join(summary_parts)5 对话角色:User、Assistant、System、Tool 的语义区分
5.1 对话角色的本质
对话角色不仅仅是标签,而是语义和功能的双重定义。在 AI IDE 中,正确理解和运用对话角色直接影响系统的行为和输出质量。
角色 | 语义定义 | 功能职责 | 典型内容 |
|---|---|---|---|
System | 系统指令 | 定义 AI 行为约束 | “你是一个代码助手…” |
User | 用户输入 | 表达用户意图 | “帮我写一个排序算法” |
Assistant | AI 响应 | 生成符合约束的回答 | “这是一个快速排序实现…” |
Tool | 工具输出 | 提供外部信息 | “文件已创建: /path/to/file” |
5.2 角色语义的深度定义
from enum import Enum
from dataclasses import dataclass
from typing import List, Optional, Dict, Any
class RolePermission(Enum):
"""角色权限"""
CAN_GENERATE_CODE = "can_generate_code"
CAN_ACCESS_FILES = "can_access_files"
CAN_EXECUTE_COMMANDS = "can_execute_commands"
CAN_MODIFY_CONTEXT = "can_modify_context"
CAN_CALL_TOOLS = "can_call_tools"
@dataclass
class RoleDefinition:
"""角色定义"""
role: MessageRole
display_name: str
description: str
# 权限
permissions: List[RolePermission]
# 约束
max_tokens: Optional[int] = None
allowed_content_types: List[str] = None
# 行为模式
response_template: Optional[str] = None
system_prompt_fragment: Optional[str] = None
class RoleRegistry:
"""
角色注册表
管理所有角色的定义和行为
"""
def __init__(self):
self.roles: Dict[MessageRole, RoleDefinition] = {}
self._register_default_roles()
def _register_default_roles(self) -> None:
"""注册默认角色"""
# System 角色
self.roles[MessageRole.SYSTEM] = RoleDefinition(
role=MessageRole.SYSTEM,
display_name="系统",
description="系统级指令和控制信息",
permissions=[
RolePermission.CAN_MODIFY_CONTEXT,
RolePermission.CAN_CALL_TOOLS,
],
max_tokens=8000,
allowed_content_types=["text", "json"],
system_prompt_fragment="You are a helpful AI coding assistant."
)
# User 角色
self.roles[MessageRole.USER] = RoleDefinition(
role=MessageRole.USER,
display_name="用户",
description="用户的原始输入",
permissions=[],
max_tokens=None, # 无限制
allowed_content_types=["text", "code", "file_reference"],
)
# Assistant 角色
self.roles[MessageRole.ASSISTANT] = RoleDefinition(
role=MessageRole.ASSISTANT,
display_name="助手",
description="AI 模型的响应",
permissions=[
RolePermission.CAN_GENERATE_CODE,
RolePermission.CAN_CALL_TOOLS,
],
max_tokens=32000,
allowed_content_types=["text", "code", "json"],
response_template="Based on the context, here is my response: "
)
# Tool 角色
self.roles[MessageRole.TOOL] = RoleDefinition(
role=MessageRole.TOOL,
display_name="工具",
description="工具执行结果",
permissions=[
RolePermission.CAN_ACCESS_FILES,
],
max_tokens=16000,
allowed_content_types=["text", "json", "error"],
)
def get_role_definition(self, role: MessageRole) -> RoleDefinition:
"""获取角色定义"""
return self.roles.get(role)
def build_system_prompt(self,
base_prompt: str,
project_context: Optional["ProjectContext"] = None) -> str:
"""构建完整的系统提示"""
system_def = self.roles[MessageRole.SYSTEM]
prompt_parts = [base_prompt]
if system_def.system_prompt_fragment:
prompt_parts.append(system_def.system_prompt_fragment)
if project_context:
prompt_parts.append(f"\n\nCurrent Project: {project_context.project_name}")
prompt_parts.append(f"Project Path: {project_context.project_path}")
return "\n".join(prompt_parts)5.3 多角色协同的序列图
下面的序列图展示了 AI IDE 中多角色协同工作的完整流程:
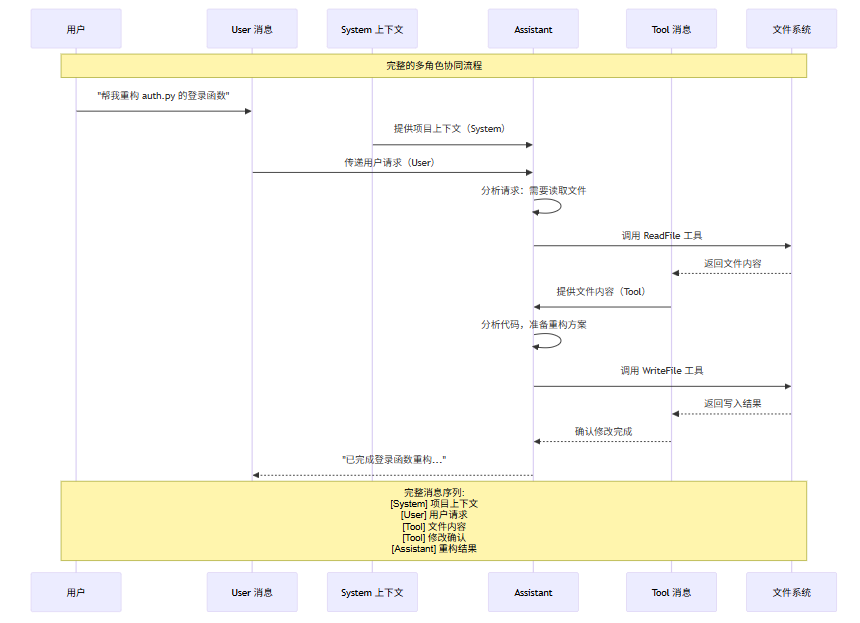
5.4 角色切换与上下文构建
class RoleAwareContextBuilder:
"""
角色感知的上下文构建器
根据当前任务动态构建合适的上下文
"""
def __init__(self, role_registry: RoleRegistry):
self.role_registry = role_registry
def build_context(self,
thread: Thread,
include_roles: Optional[List[MessageRole]] = None,
max_tokens: int = 128000) -> List[Dict[str, Any]]:
"""
构建适合当前上下文的 API 请求格式
"""
if include_roles is None:
include_roles = [MessageRole.SYSTEM, MessageRole.USER,
MessageRole.ASSISTANT, MessageRole.TOOL]
# 获取线程消息
messages = thread.get_context_window(max_tokens)
# 过滤角色
filtered = [m for m in messages if m.role in include_roles]
# 转换为 API 格式
api_format = []
for msg in filtered:
role_def = self.role_registry.get_role_definition(msg.role)
api_msg = {
"role": msg.role.value,
"content": msg.content,
}
# 添加角色特定字段
if msg.role == MessageRole.ASSISTANT and msg.metadata.get("tool_calls"):
api_msg["tool_calls"] = msg.metadata["tool_calls"]
if msg.role == MessageRole.TOOL and msg.metadata.get("tool_call_id"):
api_msg["tool_call_id"] = msg.metadata["tool_call_id"]
api_format.append(api_msg)
return api_format
def validate_message(self, message: Message) -> tuple[bool, Optional[str]]:
"""
验证消息是否符合角色定义
"""
role_def = self.role_registry.get_role_definition(message.role)
if not role_def:
return False, f"Unknown role: {message.role}"
# 检查 token 限制
if role_def.max_tokens:
msg_tokens = message.estimate_tokens()
if msg_tokens > role_def.max_tokens:
return False, f"Message exceeds max tokens for role {message.role.value}"
# 检查内容类型
if role_def.allowed_content_types:
content_type = self._detect_content_type(message.content)
if content_type not in role_def.allowed_content_types:
return False, f"Content type '{content_type}' not allowed for role {message.role.value}"
return True, None
def _detect_content_type(self, content: str) -> str:
"""检测内容类型"""
if content.startswith("```"):
return "code"
if content.startswith("{") or content.startswith("["):
try:
json.loads(content)
return "json"
except:
pass
return "text"6 实践:实现一个支持多会话的对话管理器
6.1 完整对话管理器架构
本节将整合前述所有组件,实现一个完整的、生产级别的对话管理器。
"""
AI IDE 对话管理器 - 完整实现
支持多会话、上下文维护、历史引用、多角色协同
"""
from typing import Dict, List, Optional, Callable, Any
from dataclasses import dataclass, field
from datetime import datetime
from enum import Enum
import uuid
import json
import pickle
import hashlib
# ============================================================================
# 核心数据模型
# ============================================================================
class MessageRole(Enum):
SYSTEM = "system"
USER = "user"
ASSISTANT = "assistant"
TOOL = "tool"
class ThreadStatus(Enum):
ACTIVE = "active"
WAITING = "waiting"
COMPLETED = "completed"
CANCELLED = "cancelled"
FAILED = "failed"
class SessionScope(Enum):
GLOBAL = "global"
PROJECT = "project"
TASK = "task"
@dataclass
class Message:
message_id: str
thread_id: str
role: MessageRole
content: str
input_tokens: int = 0
output_tokens: int = 0
created_at: datetime = field(default_factory=datetime.now)
metadata: Dict[str, Any] = field(default_factory=dict)
def estimate_tokens(self) -> int:
if self.input_tokens > 0:
return self.input_tokens + self.output_tokens
chinese_chars = sum(1 for c in self.content if '\u4e00' <= c <= '\u9fff')
other_chars = len(self.content) - chinese_chars
return chinese_chars // 2 + other_chars // 4
def to_dict(self) -> Dict:
return {
"message_id": self.message_id,
"thread_id": self.thread_id,
"role": self.role.value,
"content": self.content,
"input_tokens": self.input_tokens,
"output_tokens": self.output_tokens,
"created_at": self.created_at.isoformat(),
"metadata": self.metadata,
}
@dataclass
class Thread:
thread_id: str
session_id: str
title: str
status: ThreadStatus = ThreadStatus.ACTIVE
messages: List[Message] = field(default_factory=list)
created_at: datetime = field(default_factory=datetime.now)
updated_at: datetime = field(default_factory=datetime.now)
completed_at: Optional[datetime] = None
parent_thread_id: Optional[str] = None
child_thread_ids: List[str] = field(default_factory=list)
metadata: Dict[str, Any] = field(default_factory=dict)
def add_message(self, role: MessageRole, content: str, **kwargs) -> Message:
msg = Message(
message_id=str(uuid.uuid4()),
thread_id=self.thread_id,
role=role,
content=content,
**kwargs
)
self.messages.append(msg)
self.updated_at = datetime.now()
return msg
def get_context_window(self, max_tokens: int = 128000) -> List[Message]:
window = []
total = 0
for msg in reversed(self.messages):
tokens = msg.estimate_tokens()
if total + tokens > max_tokens:
break
window.insert(0, msg)
total += tokens
return window
@dataclass
class ProjectSession:
project_session_id: str
project_path: str
project_name: str
threads: Dict[str, Thread] = field(default_factory=dict)
active_thread_id: Optional[str] = None
created_at: datetime = field(default_factory=datetime.now)
last_active: datetime = field(default_factory=datetime.now)
metadata: Dict[str, Any] = field(default_factory=dict)
# ============================================================================
# 滑动窗口管理器
# ============================================================================
@dataclass
class SlidingWindowConfig:
max_messages: int = 50
max_tokens: int = 128000
preserve_system_prompt: bool = True
preserve_first_user_msg: bool = True
class SlidingWindowManager:
def __init__(self, config: Optional[SlidingWindowConfig] = None):
self.config = config or SlidingWindowConfig()
def trim(self, messages: List[Message]) -> List[Message]:
if not messages:
return []
sorted_msgs = sorted(messages, key=lambda m: m.created_at)
system_msgs = [m for m in sorted_msgs if m.role == MessageRole.SYSTEM]
dialog_msgs = [m for m in sorted_msgs if m.role != MessageRole.SYSTEM]
total = sum(m.estimate_tokens() for m in sorted_msgs)
if total <= self.config.max_tokens:
return self._apply_limit(sorted_msgs)
result = []
current = 0
for msg in system_msgs:
if self.config.preserve_system_prompt:
result.append(msg)
current += msg.estimate_tokens()
first_user = None
if self.config.preserve_first_user_msg:
for msg in dialog_msgs:
if msg.role == MessageRole.USER:
first_user = msg
break
if first_user:
result.append(first_user)
current += first_user.estimate_tokens()
for msg in reversed(dialog_msgs):
if msg == first_user:
continue
tokens = msg.estimate_tokens()
if current + tokens > self.config.max_tokens:
break
result.insert(len(system_msgs), msg)
current += tokens
if len(result) >= self.config.max_messages + len(system_msgs):
break
return sorted(result, key=lambda m: m.created_at)
def _apply_limit(self, messages: List[Message]) -> List[Message]:
if len(messages) <= self.config.max_messages:
return messages
system = [m for m in messages if m.role == MessageRole.SYSTEM]
dialog = [m for m in messages if m.role != MessageRole.SYSTEM]
return system + dialog[-self.config.max_messages:]
# ============================================================================
# 提及解析器
# ============================================================================
class MentionParser:
PATTERNS = [
(r'@msg_([a-zA-Z0-9_-]+)', 'message_id'),
(r'@(\d+)', 'index'),
(r'@\[([^\]]+)\]', 'keyword'),
]
def __init__(self):
import re
self.compiled = [(re.compile(p), t) for p, t in self.PATTERNS]
def parse(self, text: str) -> List[Dict]:
mentions = []
import re
for pattern, mtype in self.compiled:
for match in pattern.finditer(text):
mentions.append({
"type": mtype,
"target": match.group(1) if mtype != "index" else int(match.group(1)),
"original": match.group(0),
})
return mentions
def resolve(self, mention: Dict, messages: List[Message]) -> Optional[Message]:
if mention["type"] == "message_id":
for msg in messages:
if msg.message_id == mention["target"]:
return msg
elif mention["type"] == "index":
user_msgs = [m for m in messages if m.role == MessageRole.USER]
user_msgs.reverse()
idx = mention["target"] - 1
if 0 <= idx < len(user_msgs):
return user_msgs[idx]
elif mention["type"] == "keyword":
for msg in reversed(messages):
if mention["target"].lower() in msg.content.lower():
return msg
return None
# ============================================================================
# 主对话管理器
# ============================================================================
class ConversationManager:
"""
完整的对话管理器
整合会话、线程、消息、上下文管理功能
"""
def __init__(self, config: Optional[Dict] = None):
self.config = config or {}
# 会话管理
self.project_sessions: Dict[str, ProjectSession] = {}
self.active_session_id: Optional[str] = None
# 组件
self.sliding_window = SlidingWindowManager(
SlidingWindowConfig(
max_tokens=self.config.get("max_tokens", 128000)
)
)
self.mention_parser = MentionParser()
# 回调
self.on_thread_created: Optional[Callable] = None
self.on_message_added: Optional[Callable] = None
# 持久化
self.storage_path = self.config.get("storage_path")
# --------------------------------------------------------------------------
# 会话管理
# --------------------------------------------------------------------------
def create_project_session(self, project_path: str, project_name: str) -> ProjectSession:
session_id = f"proj_{hashlib.md5(project_path.encode()).hexdigest()[:8]}"
session = ProjectSession(
project_session_id=session_id,
project_path=project_path,
project_name=project_name
)
self.project_sessions[session_id] = session
self.active_session_id = session_id
return session
def get_active_session(self) -> Optional[ProjectSession]:
if self.active_session_id:
return self.project_sessions.get(self.active_session_id)
return None
# --------------------------------------------------------------------------
# 线程管理
# --------------------------------------------------------------------------
def create_thread(self, title: str, parent_thread_id: Optional[str] = None) -> Thread:
session = self.get_active_session()
if not session:
raise ValueError("No active session")
thread_id = str(uuid.uuid4())
thread = Thread(
thread_id=thread_id,
session_id=session.project_session_id,
title=title,
parent_thread_id=parent_thread_id
)
if parent_thread_id:
parent = session.threads.get(parent_thread_id)
if parent:
parent.child_thread_ids.append(thread_id)
session.threads[thread_id] = thread
session.active_thread_id = thread_id
if self.on_thread_created:
self.on_thread_created(thread)
return thread
def get_active_thread(self) -> Optional[Thread]:
session = self.get_active_session()
if session and session.active_thread_id:
return session.threads.get(session.active_thread_id)
return None
def switch_thread(self, thread_id: str) -> None:
session = self.get_active_session()
if session and thread_id in session.threads:
session.active_thread_id = thread_id
session.last_active = datetime.now()
# --------------------------------------------------------------------------
# 消息管理
# --------------------------------------------------------------------------
def add_user_message(self, content: str) -> Message:
"""添加用户消息(自动解析 @mention)"""
thread = self.get_active_thread()
if not thread:
raise ValueError("No active thread")
# 解析提及
mentions = self.mention_parser.parse(content)
resolved = []
for mention in mentions:
resolved_msg = self.mention_parser.resolve(mention, thread.messages)
if resolved_msg:
resolved.append(resolved_msg)
# 构建最终内容
final_content = content
if resolved:
ref_text = "\n\n[引用上下文]:\n" + "\n".join([
f"- [{m.role.value}]: {m.content[:100]}..."
for m in resolved
])
final_content += ref_text
msg = thread.add_message(MessageRole.USER, final_content)
if self.on_message_added:
self.on_message_added(thread, msg)
return msg
def add_assistant_message(self, content: str, **kwargs) -> Message:
"""添加助手消息"""
thread = self.get_active_thread()
if not thread:
raise ValueError("No active thread")
msg = thread.add_message(MessageRole.ASSISTANT, content, **kwargs)
if self.on_message_added:
self.on_message_added(thread, msg)
return msg
def add_tool_message(self, content: str, tool_name: str, **kwargs) -> Message:
"""添加工具消息"""
thread = self.get_active_thread()
if not thread:
raise ValueError("No active thread")
msg = thread.add_message(
MessageRole.TOOL,
content,
metadata={"tool_name": tool_name, **kwargs}
)
return msg
def add_system_message(self, content: str) -> Message:
"""添加系统消息"""
thread = self.get_active_thread()
if not thread:
raise ValueError("No active thread")
return thread.add_message(MessageRole.SYSTEM, content)
# --------------------------------------------------------------------------
# 上下文管理
# --------------------------------------------------------------------------
def get_inference_context(self, max_tokens: Optional[int] = None) -> List[Dict]:
"""
获取用于推理的上下文
自动应用滑动窗口裁剪
"""
thread = self.get_active_thread()
if not thread:
return []
max_tokens = max_tokens or self.config.get("max_tokens", 128000)
messages = thread.get_context_window(max_tokens)
trimmed = self.sliding_window.trim(messages)
return [
{
"role": msg.role.value,
"content": msg.content,
}
for msg in trimmed
]
# --------------------------------------------------------------------------
# 持久化
# --------------------------------------------------------------------------
def save(self, path: Optional[str] = None) -> None:
"""保存状态到磁盘"""
path = path or self.storage_path
if not path:
return
data = {
"sessions": {
sid: {
"project_session_id": s.project_session_id,
"project_path": s.project_path,
"project_name": s.project_name,
"threads": {
tid: {
"thread_id": t.thread_id,
"session_id": t.session_id,
"title": t.title,
"status": t.status.value,
"messages": [m.to_dict() for m in t.messages],
"created_at": t.created_at.isoformat(),
"updated_at": t.updated_at.isoformat(),
}
for tid, t in s.threads.items()
},
"active_thread_id": s.active_thread_id,
}
for sid, s in self.project_sessions.items()
},
"active_session_id": self.active_session_id,
}
with open(path, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
def load(self, path: Optional[str] = None) -> None:
"""从磁盘加载状态"""
path = path or self.storage_path
if not path:
return
with open(path, "r", encoding="utf-8") as f:
data = json.load(f)
self.project_sessions = {}
for sid, sdata in data.get("sessions", {}).items():
session = ProjectSession(
project_session_id=sdata["project_session_id"],
project_path=sdata["project_path"],
project_name=sdata["project_name"],
)
session.active_thread_id = sdata.get("active_thread_id")
for tid, tdata in sdata.get("threads", {}).items():
thread = Thread(
thread_id=tdata["thread_id"],
session_id=tdata["session_id"],
title=tdata["title"],
status=ThreadStatus[tdata["status"].upper()],
created_at=datetime.fromisoformat(tdata["created_at"]),
updated_at=datetime.fromisoformat(tdata["updated_at"]),
)
for mdata in tdata.get("messages", []):
msg = Message(
message_id=mdata["message_id"],
thread_id=mdata["thread_id"],
role=MessageRole[mdata["role"].upper()],
content=mdata["content"],
created_at=datetime.fromisoformat(mdata["created_at"]),
metadata=mdata.get("metadata", {}),
)
thread.messages.append(msg)
session.threads[thread.thread_id] = thread
self.project_sessions[sid] = session
self.active_session_id = data.get("active_session_id")
# ============================================================================
# 使用示例
# ============================================================================
def demo():
"""演示对话管理器的完整使用流程"""
# 1. 创建对话管理器
manager = ConversationManager({
"max_tokens": 128000,
"storage_path": "./conversation_state.json"
})
# 2. 创建项目会话
session = manager.create_project_session(
project_path="/workspace/myproject",
project_name="myproject"
)
print(f"创建项目会话: {session.project_session_id}")
# 3. 创建任务线程
thread = manager.create_thread("重构用户认证模块")
print(f"创建线程: {thread.thread_id}")
# 4. 添加系统上下文
manager.add_system_message(
"你是一个专业的代码重构助手。"
"遵循以下原则:"
"1. 保持功能不变"
"2. 提升代码可读性"
"3. 优化性能"
)
# 5. 用户消息(带 @mention)
manager.add_user_message(
"帮我重构 auth.py 中的 login 函数。"
"参考之前 @1 的代码规范。"
)
# 6. 模拟 AI 响应
manager.add_assistant_message(
"我已经阅读了 auth.py 文件。"
"按照你之前设定的代码规范,我将进行以下重构:\n"
"1. 提取验证逻辑到独立函数\n"
"2. 添加类型注解\n"
"3. 使用上下文管理器处理资源"
)
# 7. 添加工具输出
manager.add_tool_message(
"文件已修改:\n"
"- auth.py: 重构 login 函数\n"
"- 添加: validate_credentials() 函数\n"
"- 添加: 类型注解和文档字符串",
tool_name="FileModifier"
)
# 8. 获取推理上下文
context = manager.get_inference_context()
print(f"\n推理上下文包含 {len(context)} 条消息")
for msg in context:
print(f" [{msg['role']}] {msg['content'][:50]}...")
# 9. 创建子线程(处理子任务)
child_thread = manager.create_thread(
"添加单元测试",
parent_thread_id=thread.thread_id
)
manager.add_system_message("为重构后的函数编写单元测试")
manager.add_user_message("为 login 函数编写 5 个测试用例")
print(f"\n子线程: {child_thread.thread_id}")
print(f"父线程: {thread.thread_id}")
# 10. 保存状态
manager.save()
print("\n状态已保存")
if __name__ == "__main__":
demo()6.2 与 AI 模型集成的完整示例
以下是一个完整的与 AI 模型集成的示例,展示如何在实际应用中使用对话管理器:
"""
对话管理与 AI 模型集成示例
"""
from typing import List, Dict, Optional, Any, Callable
import json
import time
class AIIntegrator:
"""
AI 模型集成器
处理与 AI 模型的完整交互流程
"""
def __init__(self,
conversation_manager: ConversationManager,
api_client: Optional["APIClient"] = None):
self.conversation_manager = conversation_manager
self.api_client = api_client
self.model_config = {
"model": "gpt-4",
"temperature": 0.7,
"max_tokens": 4000,
}
def send_message(self,
user_content: str,
system_prompt: Optional[str] = None) -> Dict[str, Any]:
"""
发送消息并获取 AI 响应
"""
# 1. 添加用户消息
user_msg = self.conversation_manager.add_user_message(user_content)
# 2. 构建请求
messages = self._build_request_messages(system_prompt)
# 3. 调用 API
response = self._call_ai_api(messages)
# 4. 处理响应
assistant_content = response["choices"][0]["message"]["content"]
assistant_msg = self.conversation_manager.add_assistant_message(
assistant_content,
metadata={
"model": response.get("model"),
"finish_reason": response["choices"][0].get("finish_reason"),
"usage": response.get("usage", {}),
}
)
return {
"user_message": user_msg,
"assistant_message": assistant_msg,
"response": response,
}
def _build_request_messages(self,
system_prompt: Optional[str] = None) -> List[Dict]:
"""构建 API 请求消息"""
messages = []
# 添加自定义系统提示
if system_prompt:
messages.append({
"role": "system",
"content": system_prompt
})
# 从对话管理器获取上下文
context = self.conversation_manager.get_inference_context()
messages.extend(context)
return messages
def _call_ai_api(self, messages: List[Dict]) -> Dict:
"""调用 AI API"""
if self.api_client:
return self.api_client.complete(
messages=messages,
**self.model_config
)
# 模拟响应(用于测试)
return self._mock_response(messages)
def _mock_response(self, messages: List[Dict]) -> Dict:
"""模拟 AI 响应"""
last_msg = messages[-1] if messages else {}
user_content = last_msg.get("content", "")
response_content = f"【模拟响应】已收到你的消息: {user_content[:50]}...\n\n"
response_content += "这是一个模拟的 AI 响应。在实际部署中,"
response_content += "这里会调用真实的 AI 模型 API。"
return {
"model": self.model_config["model"],
"choices": [{
"message": {
"role": "assistant",
"content": response_content,
},
"finish_reason": "stop",
}],
"usage": {
"prompt_tokens": 100,
"completion_tokens": 50,
"total_tokens": 150,
}
}
def execute_tool_call(self,
tool_name: str,
tool_args: Dict) -> Dict[str, Any]:
"""执行工具调用"""
# 添加工具调用消息
tool_call_msg = self.conversation_manager.add_assistant_message(
f"调用工具: {tool_name}",
metadata={
"tool_calls": [{
"name": tool_name,
"arguments": json.dumps(tool_args),
}]
}
)
# 执行工具(这里需要实际实现工具逻辑)
tool_result = self._execute_tool_impl(tool_name, tool_args)
# 添加工具结果消息
result_msg = self.conversation_manager.add_tool_message(
json.dumps(tool_result, ensure_ascii=False),
tool_name=tool_name
)
return {
"tool_call": tool_call_msg,
"tool_result": result_msg,
"result": tool_result,
}
def _execute_tool_impl(self,
tool_name: str,
args: Dict) -> Dict[str, Any]:
"""工具执行实现"""
# 这里应该根据 tool_name 调用实际的工具
# 简化实现
return {
"success": True,
"tool": tool_name,
"result": f"Executed {tool_name} with args: {args}",
}
class StreamingAIIntegrator:
"""
流式 AI 集成器
支持流式响应输出
"""
def __init__(self, conversation_manager: ConversationManager):
self.conversation_manager = conversation_manager
def send_message_streaming(self,
user_content: str,
on_chunk: Callable[[str], None],
system_prompt: Optional[str] = None) -> str:
"""
发送消息并通过回调函数获取流式响应
"""
# 添加用户消息
self.conversation_manager.add_user_message(user_content)
# 获取上下文
context = self.conversation_manager.get_inference_context()
if system_prompt:
context.insert(0, {"role": "system", "content": system_prompt})
# 累积完整响应
full_response = ""
# 模拟流式响应(实际应用中替换为真实的流式 API 调用)
for chunk in self._mock_streaming_response(user_content):
full_response += chunk
on_chunk(chunk)
# 保存完整响应
self.conversation_manager.add_assistant_message(
full_response,
metadata={"streaming": True}
)
return full_response
def _mock_streaming_response(self, user_content: str):
"""模拟流式响应"""
template = f"正在处理: {user_content[:30]}...\n\n这是模拟的流式响应内容。"
words = template.split()
for word in words:
yield word + " "
time.sleep(0.05) # 模拟延迟
def integrated_demo():
"""集成演示"""
# 1. 初始化
manager = ConversationManager({"max_tokens": 128000})
integrator = AIIntegrator(manager)
# 2. 创建会话和线程
session = manager.create_project_session("/workspace/webapp", "webapp")
thread = manager.create_thread("实现用户注册功能")
# 3. 设置系统提示
system_prompt = """你是一个全栈开发助手,专注于 Python (FastAPI) 和前端开发。
遵循以下规范:
- Python 代码遵循 PEP 8
- 使用类型注解
- 添加完整的文档字符串
- 优先使用 async/await"""
# 4. 发送消息
response = integrator.send_message(
"帮我实现一个用户注册 API,包含邮箱验证",
system_prompt=system_prompt
)
print("=" * 60)
print("AI 响应:")
print(response["assistant_message"].content)
print("=" * 60)
# 5. 模拟工具调用
tool_response = integrator.execute_tool_call(
tool_name="CreateFile",
args={
"path": "/workspace/webapp/api/auth.py",
"content": "# 用户认证 API\n...",
}
)
print("\n工具执行结果:")
print(tool_response["tool_result"].content)
# 6. 流式响应示例
print("\n流式响应演示:")
streaming_integrator = StreamingAIIntegrator(manager)
def print_chunk(chunk):
print(chunk, end="", flush=True)
streaming_integrator.send_message_streaming(
"为注册功能添加单元测试",
on_chunk=print_chunk
)
if __name__ == "__main__":
integrated_demo()6.3 高级特性:上下文分支与合并
在实际开发中,经常需要分支上下文来尝试不同的方案,然后决定是否合并回主线。以下是分支与合并的实现:
"""
上下文分支与合并
支持并行尝试和结果合并
"""
from typing import Dict, List, Optional, Set
from dataclasses import dataclass, field
from datetime import datetime
import uuid
class BranchingConversationManager(ConversationManager):
"""
支持分支的对话管理器
允许从任意点创建分支,尝试不同方案后决定是否合并
"""
def __init__(self, config: Optional[Dict] = None):
super().__init__(config)
self.branches: Dict[str, "Branch"] = {}
self.active_branch_id: Optional[str] = None
def create_branch(self,
from_thread_id: str,
branch_title: str,
from_message_id: Optional[str] = None) -> "Branch":
"""
从指定线程创建分支
"""
session = self.get_active_session()
if not session:
raise ValueError("No active session")
source_thread = session.threads.get(from_thread_id)
if not source_thread:
raise ValueError(f"Thread not found: {from_thread_id}")
# 创建分支 ID
branch_id = f"branch_{uuid.uuid4().hex[:8]}"
# 创建分支线程
branch_thread = self.create_thread(
title=f"[分支] {branch_title}",
parent_thread_id=from_thread_id
)
branch_thread.metadata["is_branch"] = True
branch_thread.metadata["source_thread_id"] = from_thread_id
# 如果指定了 from_message_id,只复制该消息之前的历史
if from_message_id:
for msg in source_thread.messages:
if msg.message_id == from_message_id:
break
branch_thread.add_message(msg.role, msg.content)
# 创建分支记录
branch = Branch(
branch_id=branch_id,
source_thread_id=from_thread_id,
branch_thread_id=branch_thread.thread_id,
title=branch_title,
created_at=datetime.now(),
status="active"
)
self.branches[branch_id] = branch
self.active_branch_id = branch_id
return branch
def merge_branch(self,
branch_id: str,
strategy: str = "append") -> bool:
"""
将分支合并回主线
strategy:
- "append": 将分支的所有消息追加到主线
- "replace": 用分支的最终结果替换主线
- "manual": 手动选择要合并的消息
"""
branch = self.branches.get(branch_id)
if not branch:
return False
session = self.get_active_session()
if not session:
return False
source_thread = session.threads.get(branch.source_thread_id)
branch_thread = session.threads.get(branch.branch_thread_id)
if not source_thread or not branch_thread:
return False
if strategy == "append":
# 追加分支所有消息到主线
for msg in branch_thread.messages:
# 检查是否已存在(避免重复)
if not self._message_exists(source_thread, msg):
source_thread.add_message(msg.role, msg.content)
elif strategy == "replace":
# 找到分支开始的点
# 替换从该点之后的所有消息
# 这需要更复杂的实现,这里简化处理
pass
# 更新分支状态
branch.status = "merged"
branch.merged_at = datetime.now()
return True
def discard_branch(self, branch_id: str) -> bool:
"""丢弃分支"""
branch = self.branches.get(branch_id)
if not branch:
return False
session = self.get_active_session()
if not session:
return False
# 删除分支线程
if branch.branch_thread_id in session.threads:
del session.threads[branch.branch_thread_id]
# 更新分支状态
branch.status = "discarded"
return True
def _message_exists(self, thread: Thread, msg: Message) -> bool:
"""检查消息是否已存在"""
for existing in thread.messages:
if existing.message_id == msg.message_id:
return True
return False
def get_branch_diff(self, branch_id: str) -> Dict:
"""获取分支与主线的差异"""
branch = self.branches.get(branch_id)
if not branch:
return {}
session = self.get_active_session()
if not session:
return {}
source_thread = session.threads.get(branch.source_thread_id)
branch_thread = session.threads.get(branch.branch_thread_id)
if not source_thread or not branch_thread:
return {}
# 找到共同祖先之后的消息差异
source_ids = {m.message_id for m in source_thread.messages}
branch_ids = {m.message_id for m in branch_thread.messages}
common = source_ids & branch_ids
only_source = source_ids - branch_ids
only_branch = branch_ids - source_ids
return {
"common_messages": len(common),
"only_in_source": list(only_source),
"only_in_branch": list(only_branch),
"source_count": len(source_thread.messages),
"branch_count": len(branch_thread.messages),
}
@dataclass
class Branch:
"""分支记录"""
branch_id: str
source_thread_id: str
branch_thread_id: str
title: str
created_at: datetime
status: str # "active", "merged", "discarded"
merged_at: Optional[datetime] = None
metadata: Dict = field(default_factory=dict)
def branch_demo():
"""分支功能演示"""
manager = BranchingConversationManager()
# 创建主线
session = manager.create_project_session("/workspace/app", "app")
main_thread = manager.create_thread("实现支付功能")
# 主线对话
manager.add_user_message("实现支付功能,需要支持微信和支付宝")
manager.add_assistant_message("我将为你实现一个统一的支付接口。")
manager.add_tool_message("创建了 payment.py 文件")
# 从当前点创建分支
branch = manager.create_branch(
from_thread_id=main_thread.thread_id,
branch_title="微信支付方案"
)
print(f"创建分支: {branch.branch_id}")
# 在分支上尝试不同方案
manager.add_user_message("优先实现微信支付")
manager.add_assistant_message("正在实现微信支付...")
# 获取分支与主线的差异
diff = manager.get_branch_diff(branch.branch_id)
print(f"分支差异: {diff}")
# 合并分支
success = manager.merge_branch(branch.branch_id, strategy="append")
print(f"合并结果: {success}")
if __name__ == "__main__":
branch_demo()7 对话管理的工程最佳实践
7.1 性能优化
优化策略 | 实现方法 | 预期效果 |
|---|---|---|
消息序列化缓存 | 热点消息缓存 | 减少重复序列化开销 |
增量上下文构建 | 只传递增量而非全量 | 降低 API 调用延迟 |
异步消息处理 | 消息处理异步化 | 提高并发能力 |
智能预取 | 预测用户意图预取上下文 | 减少等待时间 |
7.2 稳定性保障
class ResilientConversationManager(ConversationManager):
"""
带韧性机制的对话管理器
提供错误恢复、断点续传能力
"""
def __init__(self, config: Optional[Dict] = None):
super().__init__(config)
self.checkpoint_interval = config.get("checkpoint_interval", 10) # 每 N 条消息创建检查点
self.checkpoints: Dict[str, List["Checkpoint"]] = {}
def add_user_message(self, content: str) -> Message:
"""添加用户消息(带检查点)"""
msg = super().add_user_message(content)
self._maybe_create_checkpoint()
return msg
def _maybe_create_checkpoint(self) -> None:
"""条件创建检查点"""
thread = self.get_active_thread()
if not thread:
return
# 定期创建检查点
if len(thread.messages) % self.checkpoint_interval == 0:
self.create_checkpoint(thread.thread_id)
def create_checkpoint(self, thread_id: str) -> "Checkpoint":
"""创建检查点"""
thread = self.get_active_thread()
if not thread:
raise ValueError("No active thread")
checkpoint = Checkpoint(
checkpoint_id=str(uuid.uuid4()),
thread_id=thread_id,
message_count=len(thread.messages),
created_at=datetime.now(),
)
if thread_id not in self.checkpoints:
self.checkpoints[thread_id] = []
self.checkpoints[thread_id].append(checkpoint)
return checkpoint
def restore_to_checkpoint(self, checkpoint_id: str) -> bool:
"""恢复到检查点"""
for thread_id, cps in self.checkpoints.items():
for cp in cps:
if cp.checkpoint_id == checkpoint_id:
# 实现恢复逻辑
# 加载检查点状态并重建
return True
return False
@dataclass
class Checkpoint:
"""检查点"""
checkpoint_id: str
thread_id: str
message_count: int
created_at: datetime7.3 监控与可观测性
class ConversationMetrics:
"""对话指标收集器"""
def __init__(self):
self.metrics: Dict[str, List[float]] = {
"message_tokens": [],
"response_latency": [],
"context_window_size": [],
"thread_length": [],
}
def record_message(self, message: Message):
"""记录消息指标"""
self.metrics["message_tokens"].append(
message.estimate_tokens()
)
def record_response_latency(self, latency_ms: float):
"""记录响应延迟"""
self.metrics["response_latency"].append(latency_ms)
def record_context_window(self, size: int):
"""记录上下文窗口大小"""
self.metrics["context_window_size"].append(size)
def get_stats(self) -> Dict[str, Dict]:
"""获取统计信息"""
import statistics
stats = {}
for key, values in self.metrics.items():
if values:
stats[key] = {
"count": len(values),
"mean": statistics.mean(values),
"median": statistics.median(values),
"min": min(values),
"max": max(values),
}
return stats8 总结与展望
8.1 核心要点回顾
模块 | 核心概念 | 关键技术 |
|---|---|---|
状态机 | Session-Thread-Message 分层 | 生命周期管理、状态流转 |
上下文维护 | 滑动窗口 + 摘要压缩 + 选择性记忆 | Token 预算管理、重要性评估 |
历史引用 | @mention + 锚点 + 上下文回溯 | 引用解析、快照管理 |
多会话管理 | 项目级 vs 任务级隔离 | 上下文隔离策略 |
对话角色 | User/Assistant/System/Tool 语义 | 角色权限、上下文构建 |
8.2 未来发展方向
- 智能上下文压缩:利用 AI 自动生成高质量的对话摘要
- 主动上下文管理:基于用户意图预测,提前加载相关上下文
- 跨会话知识迁移:在不同项目间共享学习到的知识
- 多模态上下文:支持代码执行结果、UI 预览等多媒体上下文
参考链接:
- 主要来源:OpenAI Conversation Management - OpenAI 官方对话状态管理文档
- 主要来源:Microsoft Bot Framework - Dialogs - 微软对话框架设计思想
- 主要来源:Google Dialogflow - Context Management - Google 对话上下文管理方案
- 主要来源:Anthropic Claude - Extended Context - Claude 扩展上下文窗口技术
- 主要来源:LangChain - Memory Management - LangChain 记忆管理实现
附录(Appendix):
A.1 完整代码清单
以下是对话管理器的完整源代码,包含所有核心组件:
"""
AI IDE 对话管理器 - 完整实现 (v1.0)
作者:HOS(安全风信子)
日期:2026-05-24
核心组件:
1. Session - 会话根节点
2. Thread - 任务执行上下文
3. Message - 单轮对话原子
4. ConversationManager - 核心管理器
5. SlidingWindowManager - 滑动窗口管理器
6. MentionParser - 提及解析器
7. BranchingConversationManager - 分支管理器
许可证:MIT
"""
# ============================================================================
# 第一部分:核心数据模型
# ============================================================================
from enum import Enum
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Any, Callable
from datetime import datetime
import uuid
import json
import hashlib
class MessageRole(Enum):
"""消息角色枚举"""
SYSTEM = "system"
USER = "user"
ASSISTANT = "assistant"
TOOL = "tool"
FUNCTION = "function" # 兼容旧格式
class ThreadStatus(Enum):
"""线程状态枚举"""
ACTIVE = "active"
WAITING = "waiting"
COMPLETED = "completed"
CANCELLED = "cancelled"
FAILED = "failed"
class SessionScope(Enum):
"""会话作用域"""
GLOBAL = "global"
PROJECT = "project"
TASK = "task"
@dataclass
class Attachment:
"""消息附件"""
type: str
path: Optional[str] = None
content: Optional[str] = None
language: Optional[str] = None
@dataclass
class Reference:
"""消息引用"""
type: str
target_id: str
display_text: str
@dataclass
class Message:
"""单轮对话原子"""
message_id: str
thread_id: str
role: MessageRole
content: str
input_tokens: int = 0
output_tokens: int = 0
created_at: datetime = field(default_factory=datetime.now)
metadata: Dict[str, Any] = field(default_factory=dict)
def estimate_tokens(self) -> int:
if self.input_tokens > 0:
return self.input_tokens + self.output_tokens
chinese = sum(1 for c in self.content if '\u4e00' <= c <= '\u9fff')
other = len(self.content) - chinese
return chinese // 2 + other // 4
def to_dict(self) -> Dict:
return {
"message_id": self.message_id,
"thread_id": self.thread_id,
"role": self.role.value,
"content": self.content,
"input_tokens": self.input_tokens,
"output_tokens": self.output_tokens,
"created_at": self.created_at.isoformat(),
"metadata": self.metadata,
}
@classmethod
def from_dict(cls, data: Dict) -> "Message":
return cls(
message_id=data["message_id"],
thread_id=data["thread_id"],
role=MessageRole(data["role"]),
content=data["content"],
input_tokens=data.get("input_tokens", 0),
output_tokens=data.get("output_tokens", 0),
created_at=datetime.fromisoformat(data["created_at"]),
metadata=data.get("metadata", {}),
)
@dataclass
class Thread:
"""任务执行上下文"""
thread_id: str
session_id: str
title: str
status: ThreadStatus = ThreadStatus.ACTIVE
messages: List[Message] = field(default_factory=list)
created_at: datetime = field(default_factory=datetime.now)
updated_at: datetime = field(default_factory=datetime.now)
completed_at: Optional[datetime] = None
parent_thread_id: Optional[str] = None
child_thread_ids: List[str] = field(default_factory=list)
metadata: Dict[str, Any] = field(default_factory=dict)
def add_message(self, role: MessageRole, content: str, **kwargs) -> Message:
msg = Message(
message_id=str(uuid.uuid4()),
thread_id=self.thread_id,
role=role,
content=content,
**kwargs
)
self.messages.append(msg)
self.updated_at = datetime.now()
return msg
def get_context_window(self, max_tokens: int = 128000) -> List[Message]:
window = []
total = 0
for msg in reversed(self.messages):
tokens = msg.estimate_tokens()
if total + tokens > max_tokens:
break
window.insert(0, msg)
total += tokens
return window
def to_dict(self) -> Dict:
return {
"thread_id": self.thread_id,
"session_id": self.session_id,
"title": self.title,
"status": self.status.value,
"messages": [m.to_dict() for m in self.messages],
"created_at": self.created_at.isoformat(),
"updated_at": self.updated_at.isoformat(),
"completed_at": self.completed_at.isoformat() if self.completed_at else None,
"parent_thread_id": self.parent_thread_id,
"child_thread_ids": self.child_thread_ids,
"metadata": self.metadata,
}
@dataclass
class ProjectSession:
"""项目级会话"""
project_session_id: str
project_path: str
project_name: str
threads: Dict[str, Thread] = field(default_factory=dict)
active_thread_id: Optional[str] = None
created_at: datetime = field(default_factory=datetime.now)
last_active: datetime = field(default_factory=datetime.now)
metadata: Dict[str, Any] = field(default_factory=dict)
def to_dict(self) -> Dict:
return {
"project_session_id": self.project_session_id,
"project_path": self.project_path,
"project_name": self.project_name,
"threads": {tid: t.to_dict() for tid, t in self.threads.items()},
"active_thread_id": self.active_thread_id,
"created_at": self.created_at.isoformat(),
"last_active": self.last_active.isoformat(),
"metadata": self.metadata,
}
# ============================================================================
# 第二部分:滑动窗口管理器
# ============================================================================
@dataclass
class SlidingWindowConfig:
max_messages: int = 50
max_tokens: int = 128000
preserve_system_prompt: bool = True
preserve_first_user_msg: bool = True
class SlidingWindowManager:
def __init__(self, config: Optional[SlidingWindowConfig] = None):
self.config = config or SlidingWindowConfig()
def trim(self, messages: List[Message]) -> List[Message]:
if not messages:
return []
sorted_msgs = sorted(messages, key=lambda m: m.created_at)
system_msgs = [m for m in sorted_msgs if m.role == MessageRole.SYSTEM]
dialog_msgs = [m for m in sorted_msgs if m.role != MessageRole.SYSTEM]
total = sum(m.estimate_tokens() for m in sorted_msgs)
if total <= self.config.max_tokens:
return self._apply_limit(sorted_msgs)
result = []
current = 0
for msg in system_msgs:
if self.config.preserve_system_prompt:
result.append(msg)
current += msg.estimate_tokens()
first_user = None
if self.config.preserve_first_user_msg:
for msg in dialog_msgs:
if msg.role == MessageRole.USER:
first_user = msg
break
if first_user:
result.append(first_user)
current += first_user.estimate_tokens()
for msg in reversed(dialog_msgs):
if msg == first_user:
continue
tokens = msg.estimate_tokens()
if current + tokens > self.config.max_tokens:
break
result.insert(len(system_msgs), msg)
current += tokens
return sorted(result, key=lambda m: m.created_at)
def _apply_limit(self, messages: List[Message]) -> List[Message]:
if len(messages) <= self.config.max_messages:
return messages
system = [m for m in messages if m.role == MessageRole.SYSTEM]
dialog = [m for m in messages if m.role != MessageRole.SYSTEM]
return system + dialog[-self.config.max_messages:]
# ============================================================================
# 第三部分:提及解析器
# ============================================================================
class MentionParser:
MENTION_PATTERNS = [
(r'@msg_([a-zA-Z0-9_-]+)', 'message_id'),
(r'@(\d+)', 'index'),
(r'@\[([^\]]+)\]', 'keyword'),
]
def __init__(self):
import re
self.compiled = [(re.compile(p), t) for p, t in self.MENTION_PATTERNS]
def parse(self, text: str) -> List[Dict]:
mentions = []
import re
for pattern, mtype in self.compiled:
for match in pattern.finditer(text):
mentions.append({
"type": mtype,
"target": match.group(1) if mtype != "index" else int(match.group(1)),
"original": match.group(0),
})
return mentions
def resolve(self, mention: Dict, messages: List[Message]) -> Optional[Message]:
if mention["type"] == "message_id":
for msg in messages:
if msg.message_id == mention["target"]:
return msg
elif mention["type"] == "index":
user_msgs = [m for m in messages if m.role == MessageRole.USER]
user_msgs.reverse()
idx = mention["target"] - 1
if 0 <= idx < len(user_msgs):
return user_msgs[idx]
elif mention["type"] == "keyword":
for msg in reversed(messages):
if mention["target"].lower() in msg.content.lower():
return msg
return None
def resolve_all(self, text: str, messages: List[Message]) -> tuple[str, List[Message]]:
mentions = self.parse(text)
resolved = []
result = text
for mention in mentions:
msg = self.resolve(mention, messages)
if msg:
resolved.append(msg)
replacement = f"[引用 {mention['original']}]: {msg.content[:80]}..."
result = result.replace(mention["original"], replacement)
return result, resolved
# ============================================================================
# 第四部分:主对话管理器
# ============================================================================
class ConversationManager:
def __init__(self, config: Optional[Dict] = None):
self.config = config or {}
self.project_sessions: Dict[str, ProjectSession] = {}
self.active_session_id: Optional[str] = None
self.sliding_window = SlidingWindowManager(
SlidingWindowConfig(max_tokens=self.config.get("max_tokens", 128000))
)
self.mention_parser = MentionParser()
self.on_thread_created: Optional[Callable] = None
self.on_message_added: Optional[Callable] = None
self.storage_path = self.config.get("storage_path")
# 会话管理
def create_project_session(self, project_path: str, project_name: str) -> ProjectSession:
session_id = f"proj_{hashlib.md5(project_path.encode()).hexdigest()[:8]}"
session = ProjectSession(
project_session_id=session_id,
project_path=project_path,
project_name=project_name
)
self.project_sessions[session_id] = session
self.active_session_id = session_id
return session
def get_active_session(self) -> Optional[ProjectSession]:
if self.active_session_id:
return self.project_sessions.get(self.active_session_id)
return None
# 线程管理
def create_thread(self, title: str, parent_thread_id: Optional[str] = None) -> Thread:
session = self.get_active_session()
if not session:
raise ValueError("No active session")
thread_id = str(uuid.uuid4())
thread = Thread(
thread_id=thread_id,
session_id=session.project_session_id,
title=title,
parent_thread_id=parent_thread_id
)
if parent_thread_id:
parent = session.threads.get(parent_thread_id)
if parent:
parent.child_thread_ids.append(thread_id)
session.threads[thread_id] = thread
session.active_thread_id = thread_id
if self.on_thread_created:
self.on_thread_created(thread)
return thread
def get_active_thread(self) -> Optional[Thread]:
session = self.get_active_session()
if session and session.active_thread_id:
return session.threads.get(session.active_thread_id)
return None
def switch_thread(self, thread_id: str) -> None:
session = self.get_active_session()
if session and thread_id in session.threads:
session.active_thread_id = thread_id
session.last_active = datetime.now()
# 消息管理
def add_user_message(self, content: str) -> Message:
thread = self.get_active_thread()
if not thread:
raise ValueError("No active thread")
content, resolved = self.mention_parser.resolve_all(content, thread.messages)
msg = thread.add_message(MessageRole.USER, content)
if resolved:
msg.metadata["references"] = [m.message_id for m in resolved]
if self.on_message_added:
self.on_message_added(thread, msg)
return msg
def add_assistant_message(self, content: str, **kwargs) -> Message:
thread = self.get_active_thread()
if not thread:
raise ValueError("No active thread")
msg = thread.add_message(MessageRole.ASSISTANT, content, **kwargs)
if self.on_message_added:
self.on_message_added(thread, msg)
return msg
def add_tool_message(self, content: str, tool_name: str, **kwargs) -> Message:
thread = self.get_active_thread()
if not thread:
raise ValueError("No active thread")
return thread.add_message(
MessageRole.TOOL, content,
metadata={"tool_name": tool_name, **kwargs}
)
def add_system_message(self, content: str) -> Message:
thread = self.get_active_thread()
if not thread:
raise ValueError("No active thread")
return thread.add_message(MessageRole.SYSTEM, content)
# 上下文管理
def get_inference_context(self, max_tokens: Optional[int] = None) -> List[Dict]:
thread = self.get_active_thread()
if not thread:
return []
max_tokens = max_tokens or self.config.get("max_tokens", 128000)
messages = thread.get_context_window(max_tokens)
trimmed = self.sliding_window.trim(messages)
return [{"role": msg.role.value, "content": msg.content} for msg in trimmed]
# 持久化
def save(self, path: Optional[str] = None) -> None:
path = path or self.storage_path
if not path:
return
data = {
"sessions": {sid: s.to_dict() for sid, s in self.project_sessions.items()},
"active_session_id": self.active_session_id,
}
with open(path, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
def load(self, path: Optional[str] = None) -> None:
path = path or self.storage_path
if not path:
return
with open(path, "r", encoding="utf-8") as f:
data = json.load(f)
self.project_sessions = {}
for sid, sdata in data.get("sessions", {}).items():
session = ProjectSession(
project_session_id=sdata["project_session_id"],
project_path=sdata["project_path"],
project_name=sdata["project_name"],
)
session.active_thread_id = sdata.get("active_thread_id")
for tid, tdata in sdata.get("threads", {}).items():
thread = Thread(
thread_id=tdata["thread_id"],
session_id=tdata["session_id"],
title=tdata["title"],
status=ThreadStatus[tdata["status"].upper()],
created_at=datetime.fromisoformat(tdata["created_at"]),
updated_at=datetime.fromisoformat(tdata["updated_at"]),
)
for mdata in tdata.get("messages", []):
thread.messages.append(Message.from_dict(mdata))
session.threads[thread.thread_id] = thread
self.project_sessions[sid] = session
self.active_session_id = data.get("active_session_id")
# ============================================================================
# 第五部分:分支管理器
# ============================================================================
@dataclass
class Branch:
branch_id: str
source_thread_id: str
branch_thread_id: str
title: str
created_at: datetime
status: str = "active"
merged_at: Optional[datetime] = None
class BranchingConversationManager(ConversationManager):
def __init__(self, config: Optional[Dict] = None):
super().__init__(config)
self.branches: Dict[str, Branch] = {}
def create_branch(self, from_thread_id: str, branch_title: str) -> Branch:
session = self.get_active_session()
if not session:
raise ValueError("No active session")
source_thread = session.threads.get(from_thread_id)
if not source_thread:
raise ValueError(f"Thread not found: {from_thread_id}")
branch_id = f"branch_{uuid.uuid4().hex[:8]}"
branch_thread = self.create_thread(f"[分支] {branch_title}")
branch_thread.metadata["is_branch"] = True
branch_thread.metadata["source_thread_id"] = from_thread_id
# 复制历史消息到分支(可选)
for msg in source_thread.messages:
branch_thread.add_message(msg.role, msg.content)
branch = Branch(
branch_id=branch_id,
source_thread_id=from_thread_id,
branch_thread_id=branch_thread.thread_id,
title=branch_title,
created_at=datetime.now(),
)
self.branches[branch_id] = branch
return branch
def merge_branch(self, branch_id: str) -> bool:
branch = self.branches.get(branch_id)
if not branch:
return False
session = self.get_active_session()
if not session:
return False
source_thread = session.threads.get(branch.source_thread_id)
branch_thread = session.threads.get(branch.branch_thread_id)
if not source_thread or not branch_thread:
return False
# 追加分支消息到主线
for msg in branch_thread.messages:
if not self._message_exists(source_thread, msg):
source_thread.add_message(msg.role, msg.content)
branch.status = "merged"
branch.merged_at = datetime.now()
return True
def _message_exists(self, thread: Thread, msg: Message) -> bool:
return any(m.message_id == msg.message_id for m in thread.messages)A.2 配置参考
# 默认配置
DEFAULT_CONFIG = {
"max_tokens": 128000, # 最大 token 数
"max_messages": 50, # 最大消息数
"checkpoint_interval": 10, # 检查点间隔
"preserve_system_prompt": True, # 保留系统提示
"preserve_first_user_msg": True, # 保留首条用户消息
"storage_path": None, # 持久化路径
}
# 会话配置
SESSION_CONFIG = {
"session_timeout": 1800, # 会话超时(秒)
"max_threads_per_session": 100, # 每会话最大线程数
"auto_save_interval": 300, # 自动保存间隔(秒)
}A.3 常见问题排查
问题 | 可能原因 | 解决方案 |
|---|---|---|
上下文丢失 | 滑动窗口裁剪过多 | 调大 max_tokens,减少 preserve_* |
@mention 解析失败 | 格式不正确 | 使用 @1, @msg_xxx, @[keyword] 格式 |
分支合并冲突 | 消息 ID 重复 | 使用 _message_exists 检查 |
会话恢复失败 | 持久化文件损坏 | 检查 JSON 格式完整性 |
关键词: 对话管理、多轮交互、上下文维护、滑动窗口、摘要压缩、Session-Thread-Message、历史引用、多会话隔离、AI IDE、对话状态机
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号