Agent框架如何选型?别再无脑选LangChain了

Agent框架如何选型?别再无脑选LangChain了

老周聊架构
发布于 2026-05-26 19:48:42
发布于 2026-05-26 19:48:42
同一个Claude Opus 4模型,放进不同的Agent框架里跑GAIA基准测试,得分差了整整7个百分点。不是模型不行,是你的"脚手架"拖后腿了。
2026年的Agent框架赛道,用一个字形容:乱。
LangGraph刚过9万Star,CrewAI月下载量冲到520万,AutoGen被亲爹微软拆成了4块,Karpathy上周刚从OpenAI跳到Anthropic,Dify和Coze在国内杀得你死我活,还有人写了篇爆款文章叫《最好的Agent框架也许是"没有框架"》。
选型?每个团队的CTO大概都经历过这样的场景:
开周会的时候,前端说要用Mastra,后端说要用LangGraph,算法说要用AutoGen,产品经理说他在Coze上5分钟就搭了一个Demo——"你们这些人到底在干什么?"
今天这篇文章,帮你把这锅粥理清楚。
一、先搞清一个问题:你到底需不需要Agent框架?
在选框架之前,先灵魂拷问一下自己:
你的场景真的需要Agent吗?
如果你只是想调一个API,让大模型回答几个问题,加个RAG——拜托,一个requests.post()就够了,别上框架。
Karpathy说过一句话:"90% of your AI coding bill is paying for context you didn't need to send."——你90%的AI费用,花在了不需要发送的上下文上。
框架不是免费的。每一层抽象都会带来:
- 额外的Token消耗(CrewAI在简单任务上比LangGraph多吃3倍Token)
- 调试复杂度(出了Bug你是调你的代码还是调框架的代码?)
- 升级风险(AutoGen用户已经被拆家拆怕了)
什么时候才真正需要Agent框架?
场景 | 需要框架吗 | 推荐方案 |
|---|---|---|
单轮问答/简单RAG | 不需要 | 直接调API |
需要调用2-3个工具 | 看情况 | Function Calling就够 |
多步骤任务编排 | 需要 | LangGraph / Claude Agent SDK |
多Agent协作 | 需要 | CrewAI / AutoGen(AG2) |
非技术人员搭建 | 需要 | Dify / Coze |
我的判断是:80%的团队高估了自己对Agent框架的需求,但剩下20%的团队低估了选错框架的代价。
二、2026年Agent框架全景图
先上一张全景图,让你对战局有个整体认知。
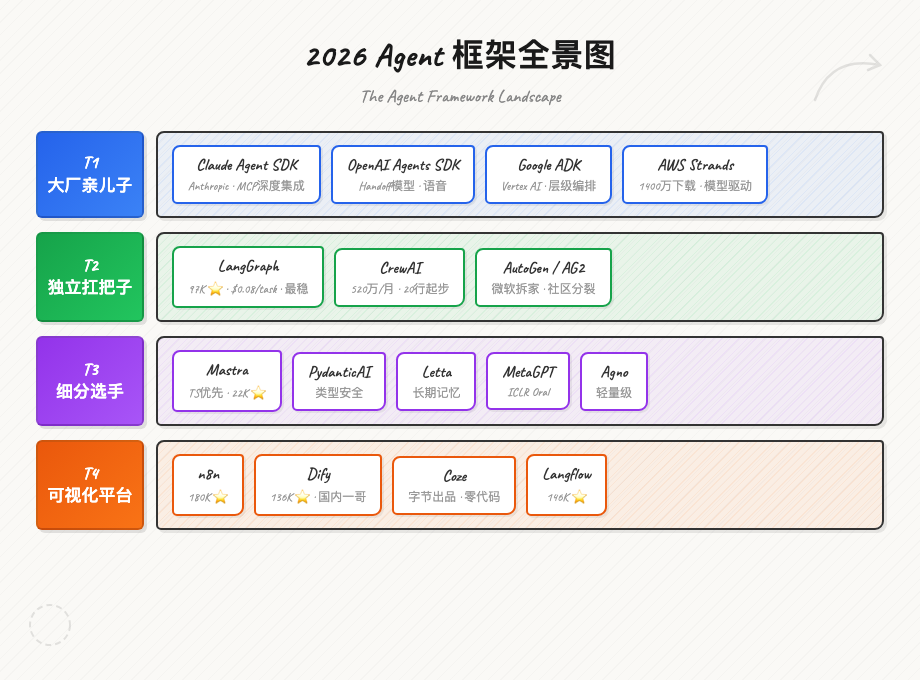
2026 Agent框架全景图
我把当前主流框架分成四个梯队:
第一梯队:大厂亲儿子
这些框架背后站着的是模型厂商本身,最大的优势是跟自家模型深度绑定,最大的劣势也是——跟自家模型深度绑定。
Claude Agent SDK(Anthropic)
Karpathy刚加入的那家公司出品。Safety-first设计理念,内置8个开箱即用的工具(Read、Write、Edit、Bash、Glob、Grep、WebSearch、WebFetch),MCP集成是所有框架里最深的。Hooks机制提供了完整的生命周期回调。
优点:给Agent一台电脑,让它自己干活——这个范式最成熟。 缺点:只能用Claude模型。你跟老板说"我们只能用Anthropic",看他的表情。
OpenAI Agents SDK
Handoff模型是所有框架里最干净的——Agent A干不了的事,无缝交给Agent B。内置Tracing和Guardrails,语音场景通过Realtime API支持得最好。
优点:客服路由、语音场景的首选。 缺点:Hosted Tools跑在OpenAI的基础设施上,数据合规是个问题。
Google ADK + AWS Strands
Google ADK主打层级式Agent树编排,背靠Vertex AI。AWS Strands开源一年就突破1400万下载量,走的是"模型驱动"路线——让LLM自己推理规划,而不是靠硬编码的流程。
第二梯队:独立框架扛把子
LangGraph
LangChain生态的亲儿子,目前Star数约9.7万。用有向图(Directed Graph)做编排,支持条件分支、循环、检查点、流式输出、时间旅行调试。配合LangSmith做可观测性,生产就绪度是所有独立框架里最高的。
关键数据:单任务成本约$0.08,是同类框架中最低的。
缺点?学习曲线陡。图结构的心智模型不是每个开发者都能快速建立的。简单场景用它,就像开坦克去买菜。
CrewAI
月下载量520万,1500+企业在用。最大的卖点是角色扮演DSL——你定义几个"角色"(研究员、写手、审核员),20行代码就能跑起来。
优点:上手最快,原型最快。 缺点:简单任务的Token消耗是LangGraph的3倍。你原型跑得快,账单也跑得快。
AutoGen / AG2(年度最大狗血剧)
这个故事值得单独讲。2024年11月,AutoGen的核心作者Chi Wang从微软跳到了Google DeepMind,然后把AutoGen fork了一份出来叫AG2,MIT协议,社区驱动。微软这边把AutoGen 0.4重写了,跟Azure/Semantic Kernel深度绑定。
现在的局面是:两个团队,两个仓库,两个路线图,一群懵逼的用户。
AG2适合开放式推理和多Agent辩论,但成本是LangGraph的5-6倍。
第三梯队:细分场景选手
框架 | 定位 | 亮点 |
|---|---|---|
Mastra | TypeScript优先 | 22K Star,300K+周下载,94家模型提供商 |
PydanticAI | 类型安全 | Pydantic团队出品,结构化输出+依赖注入 |
Letta(原MemGPT) | 长期记忆 | 专为有状态Agent设计 |
MetaGPT | 软件公司模拟 | PM→架构师→工程师全链路,ICLR 2025 Oral |
Agno(原Phidata) | 轻量级 | 牺牲角色模式换吞吐量 |
第四梯队:可视化/零代码平台
这个梯队在GitHub上Star数反而最高,因为用户基数大:
- n8n:180K Star
- Langflow:146K Star
- Dify:136K Star,国内开源LLM应用平台一哥
- Coze:字节出品,国内版支持智谱、通义千问等国产模型
一个有意思的现象:GitHub Star数前五的AI项目,有三个是可视化搭建工具。 Web开发领域发生过的"低代码革命",正在AI Agent领域重演。
三、选型的五个核心维度
别被Star数迷惑。选框架要看这五个硬指标:
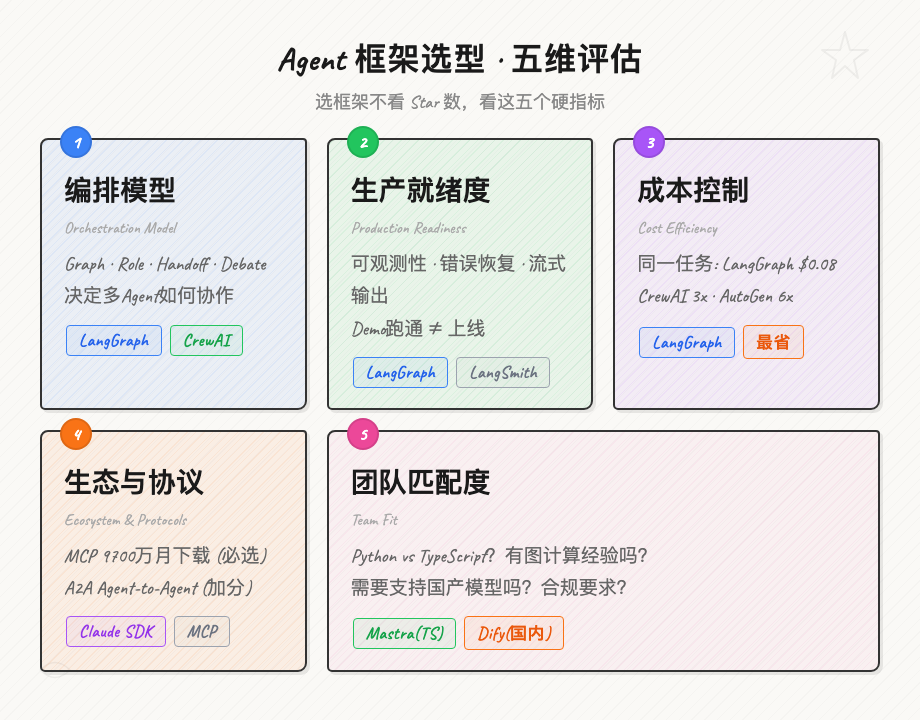
Agent框架选型五维度
维度1:编排模型(Orchestration Model)
这是最核心的差异。不同框架对"多个Agent怎么协作"有完全不同的哲学:
编排模式 | 代表框架 | 优点 | 缺点 |
|---|---|---|---|
有向图(Graph) | LangGraph | 精确控制,可调试 | 学习曲线陡 |
角色扮演(Role) | CrewAI | 直觉,易理解 | Token开销大 |
接力赛(Handoff) | OpenAI SDK | 简洁清晰 | 灵活性有限 |
辩论式(Debate) | AutoGen/AG2 | 输出质量最高 | 20+轮LLM调用,贵 |
怎么选? 如果你的任务流程是确定的(A→B→C),选Graph。如果你需要Agent之间"商量着来",选Role或Debate。如果你只是需要路由分发,Handoff就够了。
维度2:生产就绪度(Production Readiness)
Demo跑通和上线是两回事。关键看:
- 可观测性:出了问题能不能追踪到具体哪一步?LangGraph + LangSmith目前最强。
- 错误恢复:Agent执行到一半挂了,能不能从断点恢复?LangGraph的Checkpointing支持得最好。
- 流式输出:用户能不能看到Agent"正在思考"?
维度3:成本控制
这是很多团队踩的最大的坑。
同样一个"帮我调研竞品并写报告"的任务: - LangGraph:~$0.08 - CrewAI:~$0.24(3倍) - AutoGen:~$0.48(6倍)
差距在哪?上下文管理。
CrewAI的角色扮演模式会给每个Agent注入大量的角色描述和背景信息,AutoGen的辩论模式会产生大量的对话历史——这些都是Token。
维度4:生态与协议支持
2026年有三个协议你必须知道:
- MCP(Model Context Protocol):模型↔工具的垂直协议。16个月内从200万月下载飙升到9700万,Anthropic已经把它捐给了Linux基金会。200+个MCP Server实现(GitHub、Slack、PostgreSQL等)。
- A2A(Agent-to-Agent Protocol):Agent↔Agent的水平协议。Google发起,通过Agent Card实现互发现。
- ACP:已经并入A2A。
选框架时,至少要支持MCP。 这已经不是"加分项",而是"必选项"。
维度5:团队匹配度
最容易被忽略,但可能是最重要的:
- 团队是Python还是TypeScript? Python选LangGraph/CrewAI,TypeScript选Mastra。
- 团队有没有图计算经验? 没有的话,LangGraph的学习曲线会很痛。
- 需不需要支持国产模型? 需要的话,Dify和Coze的国内版是更务实的选择。
四、我的选型决策树
说了这么多,直接给你一棵决策树:
1 你的团队是技术团队吗?
2 ├── 不是 → Dify / Coze(可视化搭建)
3 └── 是
4 ├── 只用一个模型厂商?
5 │ ├── Anthropic → Claude Agent SDK
6 │ ├── OpenAI → OpenAI Agents SDK
7 │ └── Google → Google ADK
8 └── 需要模型无关?
9 ├── 单Agent + 多工具 → Function Calling就够了
10 └── 多Agent协作
11 ├── 流程确定 → LangGraph
12 ├── 快速原型 → CrewAI
13 ├── 长期记忆 → Letta
14 └── TypeScript → Mastra但是——决策树只是起点。 真正的选型还要考虑:你的数据在哪?你的合规要求是什么?你的团队能承受多大的学习成本?
五、一个反直觉的真相:框架选对了,模型选错了也能赢
回到开头说的那个数据:
同样的Claude Opus 4:
- 在HAL的Generalist Agent框架里跑GAIA:64.9%
- 在HuggingFace的Open Deep Research框架里跑:57.6%
差了7个百分点。 这不是模型的差距,这是编排的差距。
更夸张的是,裸模型和精心工程化的脚手架之间的差距,可以达到30个百分点。
这意味着什么?
你花大价钱升级模型带来的提升,可能还不如花一周时间优化你的Agent框架配置。
Karpathy在加入Anthropic之前分享过一个经历:他让autoresearch Agent跑了2天,Agent自主执行了约700次修改,其中约20次改进了验证集的loss。他说这种体验是"wild"的——看着Agent端到端地自己完成整个工作流。
但这700次修改里,有680次是无效的。Agent的执行效率,完全取决于你给它搭的脚手架。
六、Vibe Coding已死,Agentic Engineering当立
最后聊一个趋势。
2025年2月,Karpathy发了一条推特,创造了"Vibe Coding"这个概念——全身心拥抱氛围感,忘记代码的存在。
2026年2月,几乎整整一年后,他又发了一条推特,宣布Vibe Coding时代"effectively over",取而代之的是Agentic Engineering。
原话是这样的:
"You are not writing the code directly 99% of the time. You are orchestrating agents who do and acting as oversight." ——你99%的时间不再直接写代码。你在编排Agent来写,而你充当监督者。
区别在哪?
Vibe Coding | Agentic Engineering | |
|---|---|---|
目标 | 快速出活 | 正确、可维护、可信赖 |
代码所有权 | 交给AI | 人类负责 |
适用场景 | 低风险原型 | 生产系统 |
工程判断 | 交给模型 | 人类把控 |
一个新的岗位正在出现:Agentic Engineer,市场报价约$190K。
这个岗位干什么?不写代码,写"约束"——定义Agent的行为边界、成功标准、回滚策略。就像Karpathy的CLAUDE.md那65行Markdown,拿了22万Star。
选Agent框架,本质上就是在选你的"约束系统"。 选对了,你是坐在驾驶座上的工程师;选错了,你是坐在副驾上祈祷的乘客。
写在最后
回到最初的问题:Agent框架怎么选?
三句话总结:
- 80%的场景不需要Agent框架。 先确认你是真需要,不是跟风。
- 编排能力 > 模型能力。 同一个模型换个框架差7个点,这个差距比换模型还大。
- 选框架就是选约束系统。 不是选谁的Star多,而是选谁能让你的Agent在生产环境里不翻车。
如果非要我推荐一个"万金油":
- 已确定用Claude → Claude Agent SDK,没有比原厂更懂自家模型的
- 需要模型无关 + 生产级 → LangGraph,贵在稳
- 快速验证想法 → CrewAI,20行跑起来再说
- 非技术团队 → Dify / Coze,别折磨自己了
最后用Karpathy的一句话收尾:
"围绕模型的脚手架,才是真正的产品。"
你选的不是框架,是产品的骨架。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号