从 HPC 到大模型:Roofline 性能模型为何至今具备核心价值

从 HPC 到大模型:Roofline 性能模型为何至今具备核心价值

霞姐聊IT
发布于 2026-05-22 19:51:58
发布于 2026-05-22 19:51:58
如果你做过CUDA Kernel 优化、GPU 性能分析、HPC、Transformer 推理部署,或者深度学习编译器相关开发,那么你大概率都经历过这样一种困惑时刻:
GPU 参数表上明明写着:312 TFLOPS Tensor Core,1.5 TB/s HBM 带宽,
看起来像一头不折不扣的性能怪兽。
但程序真正跑起来时:实际算力只有十几TFLOPS,GPU 利用率甚至不到 40%。
更让人困惑的是:有时候只是少了一次显存读写、做了一次Kernel Fusion、调整了一下Tile 大小,性能却直接翻倍。
这些问题的答案,最终往往都会指向一个经典模型:Roofline。Roofline 诞生于 HPC 时代,但今天很多现代 AI 优化,例如FlashAttention、TensorRT、Triton,本质上依然可以用Roofline 模型来理解。但与此同时,也有人开始质疑:“Roofline 太老了吧?”“现在 GPU 架构已经这么复杂了,它还管用吗?”
Roofline其实并没有过时,真正开始过时的,其实是最早那个只有“两条线”的经典 Roofline。
在今天的性能工程体系里,Roofline 已经不再只是一个简单模型,而是逐渐演化成了一整套关于:“计算”与“数据移动”之间关系的分析框架。
一、性能问题的本质:算得慢,还是搬得慢?
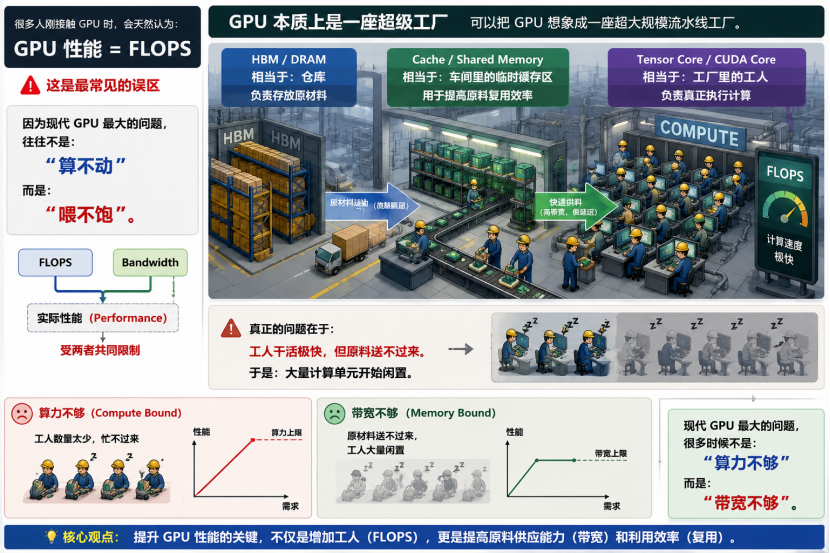
不少人初次接触GPU,都会陷入一个固有认知:GPU 性能等同于 FLOPS 浮点算力,这也是行业里最普遍的认知误区。
如今制约GPU 发挥实力的核心痛点,早已不是算力不足、算不动任务,而是数据供给跟不上,硬件根本喂不饱。
我们可以把GPU 形象比作一座超大型流水线工厂:
CUDA Core、Tensor Core,就是工厂里高速作业的工人,专职完成各类运算任务;
HBM、片外 DRAM 如同仓储仓库,用来存储海量计算原料;
高速缓存与共享内存,则是车间临时中转区,提升数据调取复用效率。
这套架构里,运算核心处理速度极致迅猛,可一旦数据传输、存取带宽跟不上原料输送节奏,大量算力核心就只能空转闲置。
简言之,当代GPU 性能瓶颈,大多不在于浮点算力匮乏,而在于数据带宽受限。
二、为什么现代GPU 特别容易“饿死”?
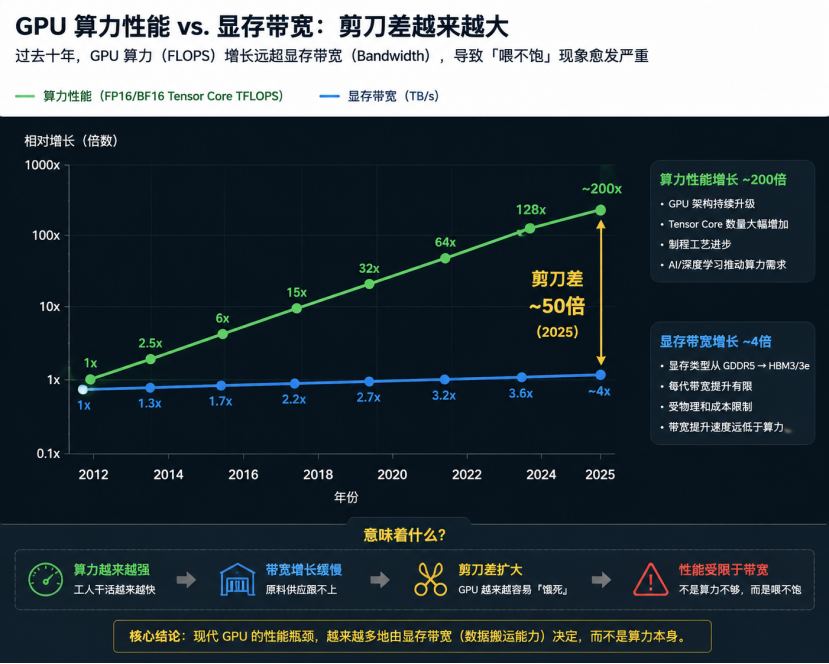
近十年GPU 硬件迭代呈现鲜明特征:算力性能的增长速率,远远甩开了显存带宽的提升速度。
以主流AI 算力 GPU 为例,两代硬件参数差距直观体现了这一趋势:
硬件阶段 | 浮点算力 | HBM 显存带宽 |
|---|---|---|
NVIDIA P100 | FP32: 10.6TFLOPS | 732GB/s |
NVIDIA H100 | FP16: 989TFLOPS | 3350GB/s |
累计增长倍数 | 约46倍 | 约4.6倍 |
从数据来看,显存带宽虽同步稳步提升,但算力规模的涨幅更为悬殊。这就导致单位字节数据可支撑的理论计算量持续飙升,最终形成行业通病:
GPU 算力愈发强悍,却愈发容易出现数据供给不足,陷入算力闲置、硬件吃不饱的困境。
这种算力与带宽发展不均衡带来的性能矛盾,无法依靠硬件参数直观判断解决,而是需要一套标准化可视化分析方法,量化区分程序究竟受算力制约还是受数据传输制约,而Roofline 屋顶线模型正是解决这一问题的经典理论工具。
三、经典Roofline (屋顶线)模型解析
Roofline模型,因绘制出的轮廓酷似屋顶而得名,是分析程序性能瓶颈的经典工具。
1. 模型基础
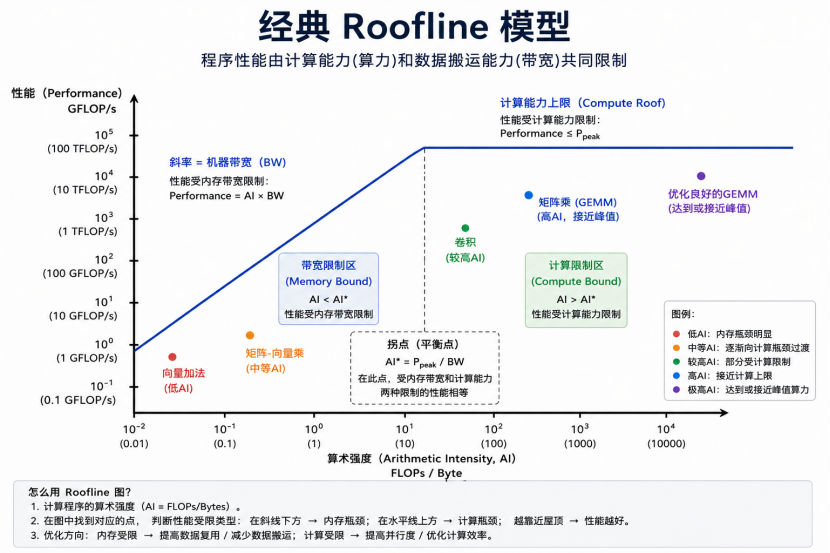
(1) 坐标轴定义
横轴(算术强度AI):单位为FLOPs/Byte,通俗理解是程序每读取/写入 1字节数据,能完成多少次浮点运算。
- AI 越低:计算少、数据读写频繁(如向量加法),更易受带宽限制;
- AI 越高:计算多、数据复用率高(如矩阵乘法),更易发挥算力优势。
纵轴(运算性能):单位为GFLOP/s、TFLOP/s,代表程序实际跑出的运算速度。
(2) 为什么用双对数坐标?
实际业务中,程序算术强度与硬件性能的数值跨度可达数个数量级(从0.01 到 10000FLOPs/Byte、从0.1 GFLOP/s 到 100 TFLOP/s),线性坐标无法清晰展示分布。
采用双对数刻度有两大优势:
- 超大范围数据能均匀平铺在一张图中,避免小数值挤成一团、大数值飞出画布;
- 让带宽约束线保持标准直线形态,完整保留“斜线 + 水平线” 的经典屋顶结构,一眼就能区分瓶颈类型。
2. 核心结构:两条“屋顶线” 与拐点
模型由两条边界线组成,共同构成性能上限的“屋顶”:
水平顶线(算力限制区):代表硬件的理论峰值算力(Compute Roof),是计算能力的绝对上限。当程序算术强度足够高(AI > AI*),数据不再拖后腿,性能直接触达这条线,受算力瓶颈约束。
倾斜斜线(带宽限制区):斜率等于硬件显存带宽(BW),代表数据传输速度带来的性能约束。当程序算术强度较低(AI <AI*),性能由 “算术强度 × 带宽” 决定,只能沿斜线线性增长,受带宽瓶颈限制。
两条线的交点是拐点(平衡点AI*),计算公式为:AI* =峰值算力Ppeak/显存带宽。
这是两种瓶颈的分界点:AI 低于拐点,性能由带宽决定;AI 高于拐点,性能由算力决定。
3. 模型画法:
以下面这组参数为例:
峰值算力312 TFLOP/s,带宽 1.5 TB/s,拐点 AI*=208 FLOPs/Byte),通用画法如下:
(1)建双对数坐标轴:
横轴为算术强度(范围0.01~10000 FLOPs/Byte),纵轴为运算性能(范围 0.1 GFLOP/s~100 TFLOP/s),按 10 倍量级均匀标注刻度。
(2)画带宽约束斜线:
- 取起点:AI=1 FLOPs/Byte,对应性能 1 × 1.5 TB/s = 1.5 TFLOP/s,坐标为(1, 1.5 TFLOP/s);
- 取终点(拐点):AI=208 FLOPs/Byte,对应性能 208 × 1.5 TB/s = 312 TFLOP/s,坐标为(208, 312 TFLOP/s);
- 用直线连接两点并向左延伸,即为带宽约束斜线。
(3)画算力水平顶线:
从拐点(208, 312 TFLOP/s) 向右画一条水平直线,即为峰值算力上限线。
4. 实操方法:程序性能点如何在图上定位?
以图中示例程序为例,通用找点步骤如下:
(1)计算算术强度AI:用程序的总浮点运算次数(FLOPs)除以总数据读写量(Bytes),得到 AI = FLOPs / Bytes。
(2)计算实际性能:用程序的总浮点运算次数除以运行时间,得到实际运算速度(GFLOP/s 或 TFLOP/s)。
(3)在图中标记坐标点:以AI 为横轴、性能为纵轴,找到对应的位置标记点。
(4)判断瓶颈类型:
- 点在斜线下方:受内存带宽瓶颈限制(如向量加法、矩阵- 向量乘),优化方向是提高数据复用率、减少数据搬运;
- 点在水平顶线下方、拐点右侧:受算力瓶颈限制(如优化良好的矩阵乘),优化方向是提高并行度、优化计算效率;
- 点越靠近“屋顶” 线,说明硬件利用率越高,程序性能越好。
四、Roofline的现代化升级:从两条线到多层性能分析框架
经典Roofline 在显存带宽主导的场景下依然快速有效,但对于缓存层级敏感的现代 AI等工作负载,需要以下扩展模型:
1. 分层屋顶线(Hierarchical Roofline)
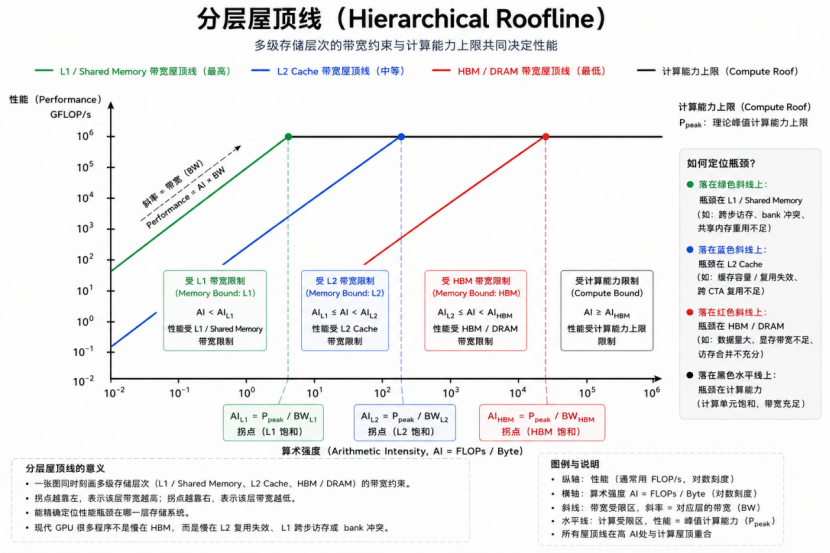
经典单层Roofline 模型存在明显局限性,因为它无法进一步区分程序性能究竟受限于 HBM 显存、L2 Cache,还是片上 L1 Cache 与 Shared Memory。
分层Roofline模型则对这一问题进行了扩展与完善。
该模型在同一双对数坐标系中,同时绘制L1 Cache、L2 Cache 与 HBM 三层带宽约束斜线,并统一叠加硬件峰值算力上限,从而实现对程序性能瓶颈的层级化定位。
相比传统单层Roofline,分层模型不仅能够判断程序是否属于 Memory Bound 或 Compute Bound,还能够进一步分析性能瓶颈究竟发生在哪一级存储系统内部。
依据性能采样点在Roofline 图中的位置,可以较为直观地判断程序当前的核心受限层级。
绿色区间对应L1 Cache 与 Shared Memory 受限区域。
在主流GPU 架构中,L1 Cache 与片上 Shared Memory 通常共享同一片 SRAM 资源,仅允许通过硬件配置动态调整容量划分比例,因此二者相关性能问题通常统一归入该层级分析。
以NVIDIA GPU 为例,该区域主要包含两类典型问题:
其一是程序数据局部性较差,L1 Cache 命中率偏低,导致数据频繁回退至 L2 或 HBM 重新读取;
其二是Shared Memory 访问模式不合理,例如出现 Bank Conflict、广播访问低效或跨步访存等问题,从而显著降低片上数据吞吐效率。
此类问题会直接限制程序运行速度,即便下层L2 与 HBM 带宽资源仍有富余,也难以进一步释放硬件性能。
蓝色区间对应L2 Cache 受限区域,代表程序性能主要受二级缓存吞吐能力制约。
常见场景包括线程块之间数据复用率不足、全局数据排布不合理导致Cache Line 利用率偏低,以及跨固定字节大步长访存等典型问题。
例如程序虽然完整加载了一整条Cache Line,但实际仅使用其中极少部分数据,从而大量浪费 L2 有效带宽。
在NVIDIA A100 等大缓存 GPU 中,由于 L2 Cache 通常采用分区式结构,杂乱无序的访问模式还可能进一步引发分区访问失衡,导致部分分区过载、部分分区空闲,从而持续拉低整体吞吐能力。
在这种情况下,即便HBM 显存带宽尚未达到瓶颈,程序性能也难以继续提升。
红色区间对应HBM 高带宽显存受限区域,这也是实际工程开发中最常见的带宽瓶颈场景。
该区域通常出现在数据规模庞大、计算逻辑简单且数据复用率极低的程序中,程序运行过程长期依赖频繁的片外显存读写,整体吞吐能力几乎完全受HBM 数据传输速率限制。
典型场景包括大规模向量处理、Embedding Lookup,以及部分低 Arithmetic Intensity 的 Attention 流程。
在此类程序中,即便继续提升Tensor Core 数量或理论 FLOPS,往往也难以带来显著性能收益。
黑色水平线附近则对应计算受限区域(Compute Bound)。
当程序已经充分打通各层级数据传输链路,L1、L2 与 HBM 均能够稳定供给计算数据时,GPU 运算核心将逐渐进入高占用率运行状态,程序性能开始逼近硬件理论峰值算力。
此时后续优化重点通常转向计算侧,包括指令级并行(ILP)、Warp 调度、Tensor Core 利用率、低精度算力调用、指令流水优化以及 Occupancy 调优等方向。
需要注意的是,真实工程场景中的性能采样点通常不会严格贴合某一条单独Roof,而更常落在不同层级 Roof 的交界区域,形成典型的混合多瓶颈状态。
其判定逻辑也较为直观:性能点越接近某一级Roof,说明该层级对程序性能的主导限制越明显;若性能点位于多个 Roof 的交界区域,则通常意味着程序同时受到多级存储系统的共同制约,优化阶段需要综合考虑多个层级的问题,而无法仅依赖单一方向优化。
Hierarchical Roofline 最大的价值,在于它揭示了现代 GPU 性能优化中一个极易被忽视的事实:
大量低性能程序并非真正受限于HBM 显存带宽,而是隐藏在片上缓存层级中的访存缺陷,例如 L2 Cache 复用失效、L1 跨步访存、Shared Memory Bank Conflict、Cache Line 利用率偏低等问题。这些细节往往不会直接体现在传统单层Roofline 模型中,却恰恰构成了现代 GPU 深度性能优化最关键、也最困难的突破方向。
分层Roofline 的另一个重要价值,在于它能够实现性能问题的层级化定向优化,从而有效避免传统性能调优中的盲目试错。
实际分析过程中,NVIDIA Nsight Compute 通常需要采集各层级带宽利用率、运算量以及访存统计信息,并结合脚本进一步换算 Arithmetic Intensity 后完成自主绘图;而 Intel Advisor 则已经能够直接导出多级带宽 Roofline 数据。
不同瓶颈区域对应的优化方向也存在明显差异:
L1 / Shared Memory 更关注访存模式与数据排布,L2 更强调分块策略与数据复用,而 HBM 层级则重点减少显存读写与片外数据搬运;若程序已经进入 Compute Bound 区域,则优化重点将转向并行调度、Tensor Core 利用率以及低精度计算路径等计算侧优化。
此外还需注意,Roofline 中各条斜线的斜率本质上由 GPU 硬件带宽决定,因此不同 GPU 架构之间对应的 Roofline 形态也会明显不同。
例如NVIDIA A100 与 NVIDIA H100 在 HBM 带宽、L2 Cache 规模以及 Shared Memory 吞吐能力方面均存在显著差异,因此不能简单套用统一 Roofline 模型,而应针对具体硬件平台重新构建对应的层级 Roof。
2. 指令屋顶线(Instruction Roofline)
指令屋顶线是传统Roofline 在现代 GPU 架构上的一次重要扩展。
经典Roofline模型在矩阵乘法、科学计算等典型浮点密集型场景中具有极强解释能力,但随着 GPU 应用类型不断扩展,其局限性也逐渐显现。
在大量现代GPU 程序中,真正主导性能的往往并不是浮点运算本身,而是整数地址生成、访存指令调度、线程控制流以及大量非浮点数据处理逻辑。
例如图计算、数据库查询、稀疏计算、基因序列比对等场景中,程序可能几乎不包含高密度FLOPs,却依然会消耗大量 GPU 指令吞吐资源。
此时若继续使用传统FLOP-based Roofline 分析,往往会出现严重失真:程序明明已经达到硬件执行瓶颈,但 Roofline 图中却仍显示“距离峰值算力很远”,导致开发者无法准确判断真实瓶颈来源。
指令屋顶线正是为解决这一问题提出的。
该模型不再以浮点FLOPS 作为核心度量,而是将纵轴替换为 GIPS(Giga Instructions Per Second,十亿级指令吞吐率),
横轴则改为单位访存事务对应的指令数(Instructions per Transaction),从而将 GPU 性能分析从“浮点运算视角”扩展到“整体指令执行视角”。
这一变化使Roofline 能够精准分析大量传统模型难以覆盖的问题。
例如在整型密集型程序中,指令屋顶线可以清晰观察整数ALU 是否已经达到吞吐瓶颈;
在访存密集型Kernel 中,则能够分析大量 Load / Store 指令是否正在压制整体执行效率。
对于现代Transformer 中复杂的 Attention 机制、矩阵转置、Scatter / Gather 等低 FLOP 高访存程序,指令屋顶线往往比传统Roofline 更接近真实硬件行为。
与此同时,该模型还能够更直观地暴露GPU 微架构层面的隐藏问题。
例如线程分支(Warp Divergence)会导致部分线程长期闲置,从而显著降低有效指令吞吐率;
访存跨步(Strided Access)则会增加无效访存事务数量,导致单位事务对应的有效指令比例下降;
而Shared Memory Bank Conflict、非对齐访存、缓存行浪费等问题,也都会直接体现在 Instruction Intensity 的下降上。
相比传统Roofline 主要回答“浮点算力是否被充分利用”,Instruction Roofline 更进一步,它开始回答:
GPU 指令流水是否已经饱和;
指令发射能力是否成为瓶颈;
整数运算与访存指令是否正在竞争执行资源;
线程调度与控制流是否正在降低整体利用率;
数据访问模式是否导致大量无效事务开销。
从某种意义上说,指令屋顶线的出现,标志着Roofline 模型开始从“浮点计算分析工具”演化为“通用 GPU 执行模型分析框架”。它不仅扩大了 Roofline 的适用范围,也使 Roofline 能够覆盖更多现代计算场景,包括图计算、稀疏计算、数据库系统、基因序列分析、网络数据处理,以及大量 AI 推理中的低 Arithmetic Intensity Kernel。
更重要的是,它揭示了现代GPU 优化中的一个关键事实:很多程序真正的瓶颈,并不在 FLOPS,而在于“指令执行效率”。当 GPU 已经拥有远超需求的浮点算力后,真正限制性能的,往往变成了整数指令吞吐、访存事务效率、线程控制流以及底层调度能力,而这正是传统 Roofline 长期难以准确描述的部分。

2. 其他屋顶线模型
随着异构并行与分布式计算发展,Roofline 已延伸为通用资源上限分析框架,衍生出多类细分模型:
其中,Communication Roofline(通信屋顶线)是当前大模型训练领域极为重要的一类扩展。
随着分布式训练规模持续扩大,GPU 间通信逐渐成为性能核心瓶颈,NVLink、PCIe、InfiniBand 乃至 AllReduce 吞吐能力都可以被抽象为新的通信 Roof。
该模型重点分析通信带宽、通信与计算重叠效率以及跨节点扩展能力,尤其适用于 Megatron-LM、DeepSpeed、MoE 等超大规模分布式训练系统。
Energy Roofline(能耗屋顶线)则将 Roofline 从“性能优化”进一步扩展到“能效优化”。
传统 Roofline 关注的是程序吞吐上限,而 Energy Roofline 更强调单位功耗对应的有效性能,即 Performance per Watt。
在现代 AI 数据中心中,由于功耗与散热成本持续上升,程序很多时候并非受限于算力本身,而是受限于热设计功耗(TDP)或整体能耗预算,因此 Energy Roofline 已逐渐成为绿色计算与边缘 AI 领域的重要分析工具。
Tensor Core Roofline 是 AI GPU 时代最具代表性的扩展之一。
现代 GPU 已不再只有统一的浮点峰值算力,而是同时存在 FP32、FP16、BF16、INT8、FP8 乃至 Sparse Tensor Core 等多种异构计算单元。
因此现代 Roofline 不再对应单一 Compute Roof,而是形成多组 Tensor Core Roof,用于分析 Tensor Core 利用率、矩阵 MMA 指令吞吐以及低精度计算路径效率。
这类模型广泛应用于 CUTLASS、TensorRT、FlashAttention 与 Triton 等 AI Kernel 优化框架中。
Sparse Roofline(稀疏屋顶线)则主要面向稀疏计算场景。
在 MoE、结构化稀疏、图神经网络等现代 AI 系统中,大量计算已不再满足规则稠密矩阵特征,传统 FLOP 统计方法会严重高估真实有效计算量。Sparse Roofline 会进一步考虑稀疏压缩、非规则访存、无效线程以及稀疏索引开销,从而更准确分析稀疏系统中的实际性能上限。
除此之外,现代 Roofline 还逐渐向 Runtime Roofline、Network Roofline 与 3D Roofline 等方向扩展。
例如 Runtime Roofline 更关注 Kernel Launch、CUDA Graph、Runtime 调度与同步开销;Network Roofline 则面向超算网络与 MPI 通信系统;而 3D Roofline 则尝试将 Cache、Energy、Communication 等多维资源同时纳入统一分析空间,从二维 Roofline 进一步扩展为多维 Roofline Surface。
从发展趋势来看,Roofline 已经不再只是最初那个“FLOPS vs Bandwidth”的经典性能图,而是逐渐演化为现代计算系统中的统一资源上界分析框架。
它真正的核心思想也从“浮点性能分析”转变为:“程序性能究竟受哪一种系统资源限制”。而这种资源既可以是 FLOPS,也可以是缓存带宽、通信吞吐、指令发射能力、Tensor Core 利用率、能耗预算,甚至运行时调度效率。
五、大模型优化的底层逻辑都在Roofline里
如本文第二部分分析:算力增长速度远远超过了带宽增长速度。这导致机器平衡点(Machine Balance)持续向高 Arithmetic Intensity 区域右移,即 GPU 想要真正跑满峰值算力,需要程序具备越来越高的数据复用能力。
其结果便是:现代GPU 虽然理论算力越来越强,但真正能够长期稳定跑满 Compute Roof 的程序反而越来越少。
大量AI 推理、Transformer Kernel 与 HPC 程序实际上长期停留在 Roofline 左侧的带宽受限区域(Memory Bound Region),GPU 运算核心大量时间都在等待数据供给,而不是执行计算。
从Roofline 视角来看,当前几乎所有主流大模型优化技术,本质上都在做同一件事情:
提升Arithmetic Intensity(AI),减少数据搬运,让程序从带宽瓶颈区向算力瓶颈区迁移。
换句话说,大模型优化的核心目标,并不是单纯“减少 FLOPS”,而是:
用尽可能少的数据搬运,完成尽可能多的有效计算。
这一思想几乎贯穿了现代AI 系统优化的全部核心路径。
例如FlashAttention 的核心突破,并不在于减少 Attention FLOPs,而在于通过 Block-wise Tiling、Shared Memory Reuse 与 Register Reuse,大幅减少中间 Attention Matrix 的 HBM 回写与重复读取,从而显著提升数据复用率与 Arithmetic Intensity,使程序性能点从 HBM Roof 向 Compute Roof 方向移动。
Kernel Fusion 的底层逻辑同样如此。传统 Transformer 推理中,大量 Kernel 会在每一步结束后将中间 Tensor 写回 HBM,随后下一个 Kernel 再重新读取,导致显存带宽被大量消耗。Fusion 技术通过在单 Kernel 内部完成多个算子计算,减少中间 Tensor 回写与 Kernel Launch 开销,本质上仍然是在降低 Bytes/FLOP,提高 Roofline 中的 Arithmetic Intensity。
低精度量化(FP16、BF16、FP8、INT8)则进一步体现了 Roofline 的核心思想。量化不仅意味着 Tensor Core 吞吐提升,更重要的是单位数据所承载的有效计算量显著增加。例如 FP8 相比 FP32,单次显存读取能够携带更多计算数据,从而有效降低数据搬运成本,提高单位带宽对应的有效计算能力,本质上依旧是在提升 AI。
包括Triton、TensorRT、CUTLASS 等现代 AI 编译与 Kernel 优化框架,其自动分块(Tiling)、Tensor Layout 重排、访存合并(Coalescing)、Shared Memory 分配以及 Pipeline 调度等优化策略,也几乎全部可以放回 Roofline 框架下统一理解。它们的目标并不只是“代码更快”,而是尽可能减少片外显存访问,提高片上数据复用率,持续推动程序逼近 Roofline 上界。
甚至在大模型推理领域被广泛关注的KV Cache 优化、PagedAttention、Continuous Batching 与 Prefix Cache,本质上也都属于 Roofline 问题。因为随着上下文长度持续增长,LLM 推理越来越容易从“计算瓶颈”退化为“显存带宽瓶颈”,程序大量时间消耗在 KV Cache 搬运而非真正计算上。因此现代推理框架越来越强调 Cache 局部性、KV Block 管理以及数据分页复用,其目标依旧是减少 HBM 流量,提高有效数据复用效率。
从更宏观的角度来看,Roofline 真正重要的意义,并不只是提供一张性能分析图,而是它为现代 AI 系统建立了一套统一的优化逻辑:
为什么FlashAttention 会快;
为什么Kernel Fusion 有效;
为什么量化能够提升吞吐;
为什么Tensor Layout 如此重要;
为什么大模型推理越来越依赖Cache 管理;
为什么现代GPU 优化越来越强调“数据移动”而不是“浮点计算”。
这些问题最终都可以回归到同一个核心:
程序性能究竟是受“计算能力”限制,还是受“数据供给能力”限制。
而Roofline 正是这一问题最统一、最直观、也最具工程解释力的分析框架。
它使现代AI 优化不再是依赖经验的盲目调参,而是逐渐演化为一种具备明确目标与理论方向的系统工程:尽可能减少数据移动,提高数据复用效率,并持续推动程序向 Roofline 上界逼近。
六、总结:Roofline经久不衰的价值
GPU 硬件架构迭代、AI 业务场景革新从未停滞,Roofline 模型也在持续拓展边界,但其核心底层逻辑始终恒定:并行程序性能由计算资源上限与数据调度能力共同决定。
架构越复杂、业务场景越多元,越需要简洁统一的理论框架梳理核心矛盾。Roofline 并非用于精准复刻硬件微架构运行细节,而是作为性能分析决策工具,快速定位程序核心瓶颈、明确优化优先级、判定优化方案有效性。
对于高性能计算研发人员、CUDA 内核开发者、大模型部署优化工程师而言,Roofline 是梳理性能逻辑的通用标尺,拨开硬件参数繁杂表象,直击 “计算与数据调度” 的核心博弈关系。
从传统高性能计算到万亿参数大模型部署,从初代并行架构到新一代异构加速芯片,算力与带宽的平衡关系始终不变,这也是Roofline 模型历经十余年发展,依旧稳居性能优化理论核心地位的根本原因。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号