DeepSeek V4 Flash 量化版火了

DeepSeek V4 Flash 量化版火了

Ai学习的老章
发布于 2026-05-19 18:27:20
发布于 2026-05-19 18:27:20
最近 HuggingFace 上有个 DeepSeek V4 Flash 量化版 突然火了——更狠的是,作者是 antirez(Redis 作者 Salvatore Sanfilippo)
我查了一下 Hugging Face 模型仓库,下载量已经 26 万+
老 Redis 用户看到这名字应该会愣一下:他怎么跑去做大模型推理引擎了?
简介
事情其实是这样的:antirez 同步开源了两件配套的事:
- DeepSeek V4 Flash 的专用量化版 GGUF:托管在
huggingface.co/antirez/deepseek-v4-gguf - DwarfStar 4(简称 ds4):一个专门为 DeepSeek V4 Flash 设计的推理引擎,托管在
github.com/antirez/ds4
注意定语:ds4 不是通用 GGUF runner,也不是某个 runtime 的 wrapper——它是为 DSv4 Flash 量身打造、完全自包含的引擎,这种"一个模型一个引擎"的做法在当前生态里挺反潮流的
为什么是 DeepSeek V4 Flash 值得这么干
antirez 在 README 里给了 8 条理由,我挑硬核的几条:
- 更少的激活参数 → 更快
- Thinking 模式下,思考长度跟问题复杂度成正比——文档里写"thinking section 在很多情况下只有其他模型的 1/5",对实际使用感受影响巨大
- 上下文窗口 100 万 token
- 284B 总参数,在知识边缘采样时明显比 27B / 35B 这种小密集模型懂得多
- **英语和意大利语写作都"接近 frontier model 的感觉"**(antirez 是意大利人,这条评价比较真实)
- KV cache 压缩极致——这是 DSv4 在长 context + 本地推理上的杀手锏
- 特殊量化方法下 2bit 也能用——128GB 内存的 MacBook 跑得动,96GB 也有人实测可行,部分人甚至跑到 250k context
- DeepSeek 大概率会持续放 v4 Flash 的更新版本
整篇 README 我读下来感觉是:antirez 真的喜欢这个模型,所以才愿意花精力做一个"专用引擎+专用量化"的组合
量化方案(这部分是干货)
仓库里现在主要有几类文件:
文件 | 适合场景 | 量化重点 |
|---|---|---|
DeepSeek-V4-Flash-IQ2XXS-w2Q2K-...-v2-imatrix.gguf | 96GB / 128GB RAM 机器优先试 | 路由 MoE 专家里 gate/up 用 IQ2_XXS,down 用 Q2_K |
DeepSeek-V4-Flash-Q4KExperts-...-v2-imatrix.gguf | 256GB+ RAM 机器 | 路由专家用 Q4_K,质量更稳,体积更大 |
DeepSeek-V4-Flash-MTP-Q4K-Q8_0-F32.gguf | 可选 MTP 支持 | 不能单独跑,搭配主模型做投机解码实验 |
imatrix/DeepSeek-V4-Flash-chat-v2-routed-moe-ds4-1p5m.dat | 量化校准数据 | 给 imatrix 版本服务 |
怎么挑:
- 96GB / 128GB Mac:优先用
q2-imatrix - ≥ 256GB 内存机器:优先用
q4-imatrix - MTP:搭配前两者做投机解码实验,README 里说目前最多是轻微加速
- legacy 版本:
q2/q4还在,但现在脚本里更推荐 imatrix 版本
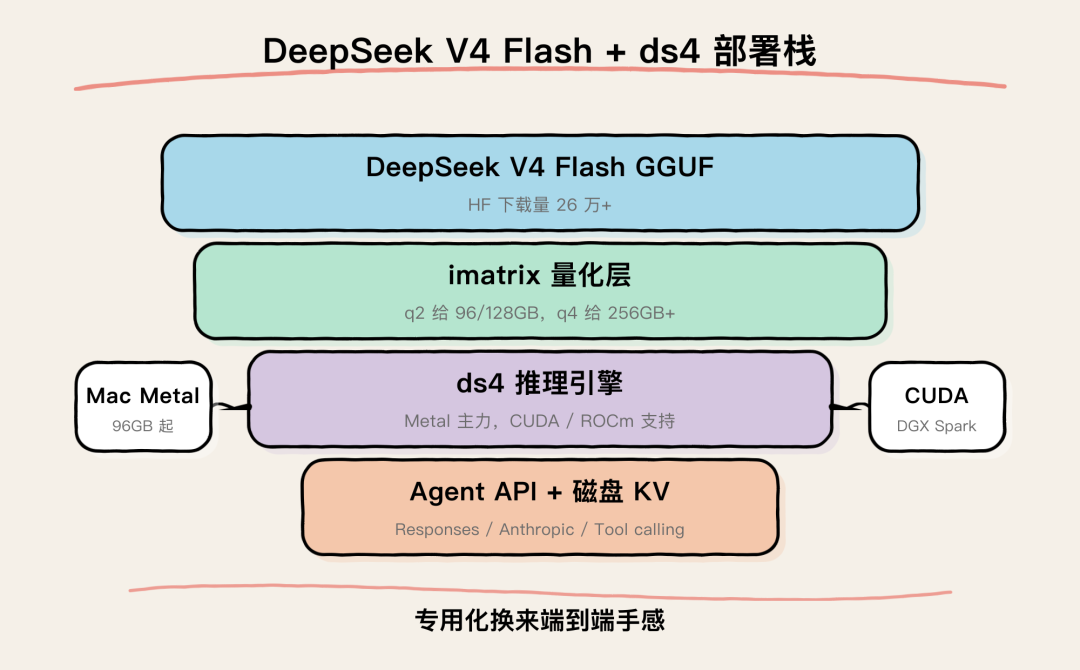
DeepSeek V4 Flash 和 ds4 部署栈
DeepSeek V4 Flash 和 ds4 部署栈
量化思路里有一段我特别认同:
❝路由专家占了模型参数的大头,但每个专家只处理一小部分 token,激进量化它们造成的平均质量损失,远小于对 router、投影矩阵、共享专家做同等量化,把"决策类组件"保留在 Q8_0,能完整保留模型行为;同时压扁专家来换体积
简单说:该压的地方狠压,不该压的地方一点不让——比一刀切的"统一 Q4"高级太多
推理引擎 ds4
git clone https://github.com/antirez/ds4
cd ds4
./download_model.sh q2-imatrix # 96 / 128 GB RAM 机器
./download_model.sh q4-imatrix # >= 256 GB RAM 机器
./download_model.sh mtp # 可选:MTP 投机解码实验
make # macOS Metal
./ds4 -p "Explain Redis streams in one paragraph."
./ds4-server --ctx 100000 --kv-disk-dir /tmp/ds4-kv --kv-disk-space-mb 8192
CUDA 机器走这两条:
make cuda-spark # DGX Spark / GB10
make cuda-generic # 普通 CUDA 机器
特性亮点:
- Metal 是主力后端:96GB 起的 MacBook 是目标硬件
- NVIDIA CUDA:对 DGX Spark 有特殊优化
- AMD ROCm:在单独的
rocm分支,社区维护(antirez 没 ROCm 硬件) - HTTP API server 内置:开箱对接 Coding Agent
- KV cache 一等公民可写盘:DSv4 的压缩 KV + Mac 的快速 SSD 让这件事可行——
--kv-disk-dir+--kv-disk-space-mb直接落盘 - Logits 与官方实现对齐验证:在不同 context size 上验证,保证量化推理的正确性
这个项目的几个独特之处
1. "一个模型一个引擎"的窄路径
antirez 自己在 README 里说得很直白:本地推理领域项目很多,但新模型不停出,注意力立刻被新模型抢走,他选了相反的方向——只押一个模型,做到端到端打磨
2. KV cache 是磁盘公民,不是内存公民
这是一个反直觉但很务实的判断:DSv4 的 KV cache 极度压缩,结合现代 Mac 的高速 SSD,把 KV 当作 disk-first 资源处理,才有可能在消费级 Mac 上跑 100k+ context
3. GPT 5.5 + 人类作者共建
antirez 自己强调了一句:这个项目是在 GPT 5.5 强力辅助下、由人主导思路/测试/调试完成的,如果对 AI 写的代码有洁癖,这个项目可能不适合你——但 antirez 把这事儿亮在 README 第一段,这种坦诚就很 Redis 作者
4. 致敬 llama.cpp / GGML
README 里专门说"没有 llama.cpp 和 GGML 这个项目就不存在"——感谢 Georgi Gerganov 和所有贡献者,一个 OG 程序员对另一个 OG 程序员的真诚
我的几点感受
1. 真大佬玩的就是手感
这事儿不像商业项目,更像 antirez "我就想让我那台 MacBook 跑得最爽"的私房作品,但因为他是 antirez,做出来的东西自带工程美学
2. 量化思路值得学习
不要"一刀 Q4 切下去",要按"参数贡献度 + 处理 token 量"分层处理,这套方法论以后会越来越主流
3. macOS / 高内存 Mac 用户:值得装
如果你恰好有一台 96GB / 128GB / 192GB 内存的 Mac,又喜欢 DeepSeek V4 Flash,这套组合是当前能找到的"最爽配置"之一
4. 通用性差是事实
不要指望它能跑 Qwen、Llama、其他 DeepSeek——它就只跑 V4 Flash,换模型就得换引擎
总结
ds4 + DeepSeek V4 Flash GGUF 这套组合,是"专用化"思路的一次有趣实验:砍掉通用性,换来端到端的丝滑,再加上 antirez 这个名字加成,关注度自然就来了
如果你正好满足"高内存 Mac + 喜欢折腾本地大模型 + 对 DeepSeek 有偏爱"三个条件,强烈推荐试一下,装完跑出来 100k context、磁盘 KV、Metal 加速的那个瞬间,会觉得很有意思
#DeepSeekV4 #antirez #GGUF #量化 #本地部署
制作不易,如果这篇文章觉得对你有用,可否点个关注,给我个三连击:点赞、转发和在看,若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号