程序判断你的电脑可以安装什么大模型---老登学AI

程序判断你的电脑可以安装什么大模型---老登学AI

AustinDatabases
发布于 2026-05-12 10:41:03
发布于 2026-05-12 10:41:03
上期我们说了,我想购买的主机想在本地运行大模型,那么如果你已经有了主机,或者强悍的电脑,你会问一件事,我的电脑到底能不能运行本地大模型,如果要运行本地大模型,我应该运行什么级别的大模型。
这里我下载了一个软件,通过这个软件可以判断你当前的主机可以运行什么样的大模型,同时运行的情况如何。下面看截图
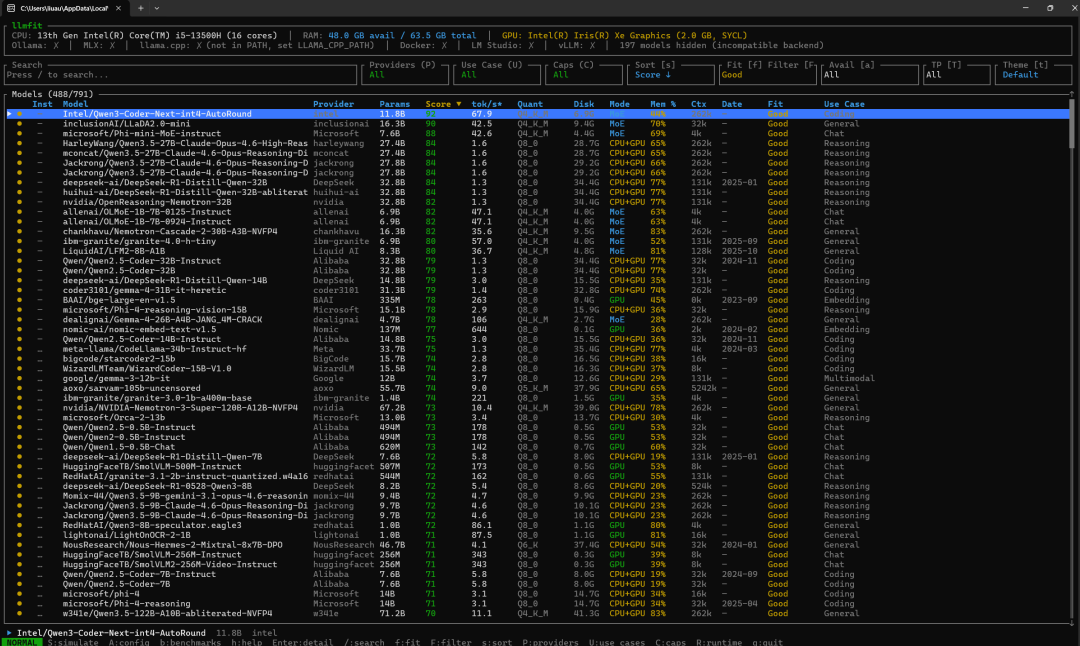
软件运行的样子

系统信息说明
上图中我们看到的是几个产生的信息模块
1 Models 这里我看可以看到市面上可以下载的大部分的大模型,通过大模型的名字你可以了解当前可以下载的大模型有多少是适合在个人主机上跑的。
2 Params 这个就是大模型的参数,我们俗称的B ,B越多大模型的智能就越高,这里列出来的是理论上你的机器可以跑的大模型。这边我的当前的笔记本可以最大跑32B的大模型。
但需要注意能跑和能用是两码事。
3 Scroe 这个是这个软件设计最好的一个地方,平分他通过平分从高到底来告诉你,你的电脑跑什么大模型是最有效率的,后面 tok/S 也说明了问题,比如第一个我的现在的电脑可以跑到 每秒67.9 tokens的成绩。
4 mode 这个我还查了一下,里面有两种 MOE 和 CPU+GPU,MoE是可以将大模型中的专家模式卸载的一种大模型运行的方式,他计算的是每次进行TOKEN输出中的需要的大模型,而不是整体大模型的参数都需要运行。
CPU+GPU则是全量运行的模式,所以通过软件我们还可以了解大模型的运行可变动的方式。
5 Mem 这里是说运行中需要的内存大小
6 FIT 说明的是词模型在当前的这台主机运行的匹配度,GOOD并不是说明可以运行的多好,GOOD知识说可以运行。
7 use case 则是指出这个模型适合做什么,有编程,有推理,有通用等等。
这里当前的主机是一个13代的 inter i5 13500 16核心的CPU,同时有64G的内存。
但我们从最后的结果上可以看到,基本上这台主机没有太能运行的当前流行的主流大模型。
问题点就在于,这台机器的显卡是集显2G的显存。而为什么结果都是GOOD 这就得益于这主机的内存比较大的原因。
经过分析,这台主机最大可以顺畅的跑7B左右的大模型,不能跑更大的模型在于显卡的无力和显存的缺失。GOOD的意思只是这些模型都可以跑,不会崩塌,但我们可以看前面的每秒的token数,基本上没有特别能流畅运行的。
所以我们借用上期的内容,总结一下如果要本地跑大模型,需要什么样的配置的主机。
如果是编程为主导的情况,想直接运行70B以下的大模型,或接近70B的模型,苹果M5 MAX 18+ 40 128G 2T 是一个好的选择,同时你可以在上面安装agent,openclaw 等以及更多的编程软件,当然如果拿来做AI视频也是OK的。

非常棒的选择
这里有人会问如果是 PRO芯片如何,经过网上一些博主的比对,在主流本地大模型上跑分,PRO 比 MAX 差了一半的性能,主要在带宽,所以如果你只是部署30B或以下的可以考虑PRO芯片 64G的MAX M5笔记本。
至于为什么要非要本地运行大模型,主要的原因还是在于TOKEN的消耗的速度的问题,如果你要编程会消耗大量的TOKEN一般订阅的TOKEN会存在很多的问题,尤其针对个人。
而最近一则新闻TOKEN涨价后续也会给我们带来新的产业,广东已经有人干起来了
1 通过廉价的苹果MIN组建起私人的TOKEN机房,来服务大量消耗TOKEN但是支付不起订阅的一些小型企业的需求。
2 给企业定制通过MAC 搭建小型企业AI机房的项目
3 一些公司在研究通过AI编程中的上下文的收缩,简化,甚至是上下文的AI话建立历史库来降低AI编程中的幻想,以及项目本身没有大的问题,在调整后经常需要回退的问题等等
AI 产业会给我们带来新的岗位和新的需求,不要太悲观,进入这个领域持续的发现,我是一个对AI中立得老登。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-07,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 AustinDatabases 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号