智谱GLM-4.7编程第一

智谱GLM-4.7编程第一

程序员NEO
发布于 2026-04-29 19:30:19
发布于 2026-04-29 19:30:19
国产大模型又一力作!GLM-4.7 编程能力实测:代码生成更稳定、前端审美大升级
从写代码到做 PPT,GLM-4.7 全能升级,实测体验如何?
实测 100 个真实编程任务:GLM-4.7 编程能力提升有多明显?
GLM-4.7 来了,这次真的不一样。
作为智谱最新旗舰模型,GLM-4.7 面向 Agentic Coding 场景全面升级:编码能力更强、长程任务规划更稳、工具协同更顺。
在多个公开基准测试中,GLM-4.7 已取得开源模型中的领先表现。
核心参数一览
- • 上下文窗口:200K
- • 最大输出 Tokens:128K
- • 输入/输出模态:文本
八大能力,全面提升
01 思考模式
提供多种思考模式,覆盖不同任务需求
02 流式输出
支持实时流式响应,提升用户交互体验
03 Function Call
强大的工具调用能力,支持多种外部工具集成
04 上下文缓存
智能缓存机制,优化长对话性能
05 结构化输出
支持 JSON 等结构化格式输出,便于系统集成
06 MCP 支持
可灵活调用外部 MCP 工具与数据源,扩展应用场景
07 Agentic Coding
面向「任务完成」而非单点代码生成,能够从目标描述出发,自主完成需求理解、方案拆解与多技术栈整合。在包含前后端联动、实时交互与外设调用的复杂场景中,可直接生成结构完整、可运行的代码框架,显著减少人工拼装与反复调试成本。
08 多模态交互
在需要摄像头、实时输入与交互控制的场景中,GLM-4.7 展现出更强的系统级理解能力。能够将视觉识别、逻辑控制与应用代码整合为统一方案,支持如手势控制、实时反馈等交互式应用的快速构建,加速从想法到可运行应用的落地过程。
六大推荐场景
① Agentic Coding 复杂开发
从需求理解到落地实现,GLM-4.7 能直接给出完整、可运行的代码框架,适合复杂 Demo、原型验证与自动化开发流程。
② 实时应用开发
更强系统级理解能力,快速构建手势控制、实时反馈等交互式应用。
③ 前端视觉优化
布局结构、配色和谐度与组件样式的默认方案更美观,减少样式反复"微调"的时间成本。
④ 高质量对话协作
在多轮对话中更稳定地保持上下文与约束条件,简单问题直接回应,复杂问题持续推进解决路径。GLM-4.7 更像一名可协作的"问题解决型伙伴"。
⑤ 沉浸式写作创作
文字表达更细腻、更具画面感,通过气味、声音、光影等感官细节构建氛围。角色扮演中世界观与人设遵循更加稳定。
⑥ 专业 PPT/海报生成
版式遵循与审美稳定性明显提升,16:9 主流比例适配更稳定,生成结果更接近"即用级"。
Coding 能力五维突破
GLM-4.7 在编程、推理与智能体三个维度实现了显著突破:
更强的编程能力
显著提升了模型在多语言编码和在终端智能体中的效果。GLM-4.7 现在可以在 Claude Code、Kilo Code、TRAE、Cline 和 Roo Code 等编程框架中实现"先思考、再行动"的机制,在复杂任务上有更稳定的表现。
前端审美提升
GLM-4.7 在前端生成质量方面明显进步,能够生成观感更佳的网页、PPT、海报。
更强的工具调用能力
在 BrowseComp 网页任务评测中获得 67 分;在 τ²-Bench 交互式工具调用评测中实现 84.7 分的开源 SOTA,超过 Claude Sonnet 4.5。
推理能力提升
在 HLE("人类最后的考试")基准测试中获得 42.8% 的成绩,较 GLM-4.6 提升 41%,超过 GPT-5.1。
通用能力增强
对话更简洁智能且富有人情味,写作与角色扮演更具文采与沉浸感。

Code Arena:全球百万用户参与盲测的专业编码评估系统,GLM-4.7 位列开源第一、国产第一,超过 GPT-5.2
实测数据说话
在主流基准测试表现中,GLM-4.7 的代码能力对齐 Claude Sonnet 4.5:
- • SWE-bench-Verified:开源第一,达到 73.8%(相较 GLM-4.6 提升 5.8%)
- • LiveCodeBench V6:达到 84.9 的开源 SOTA 分数,超过 Claude Sonnet 4.5
- • SWE-bench Multilingual:达到 66.7%(提升 12.9%)
- • Terminal Bench 2.0:达到 41%(提升 16.5%)
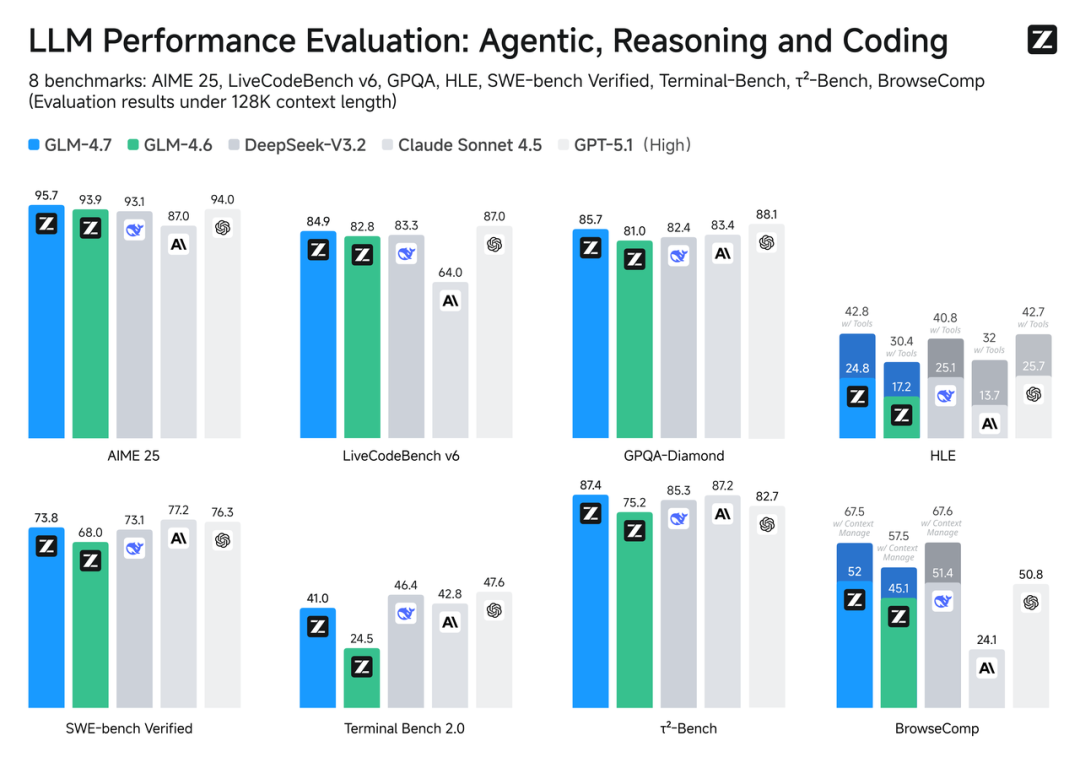
真实场景体感提升
100 个真实编程任务测试
在 Claude Code 环境中,对 100 个真实编程任务进行了测试,覆盖前端、后端与指令遵循等核心能力。
结果显示:GLM-4.7 相较 GLM-4.6 在稳定性与可交付性上均有明显提升。
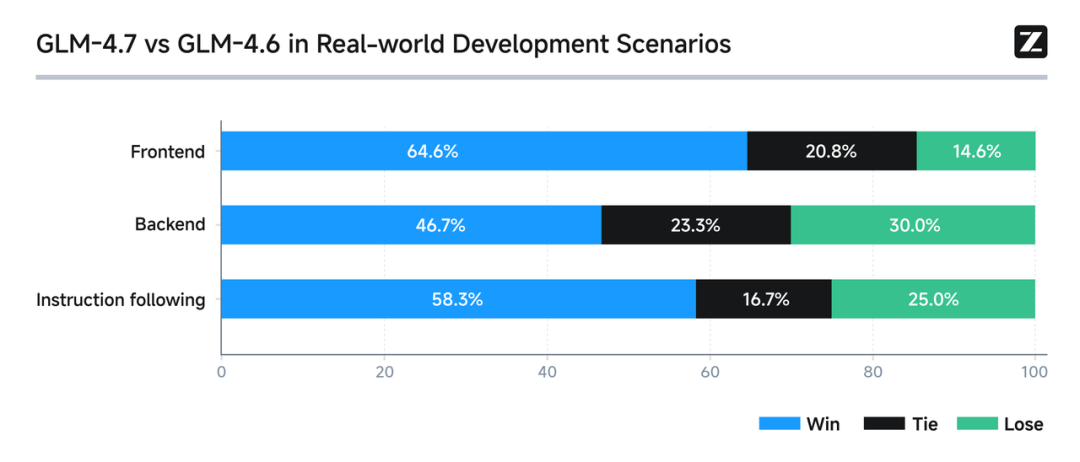
随着编程能力的增强,开发者可以更自然地以"任务交付"为核心组织开发流程,形成从需求理解到落地实现的端到端闭环。
思考能力可控进化
GLM-4.7 进一步强化了 GLM-4.5 以来就支持的交错式思考能力,引入保留式思考与轮级思考,使复杂任务执行更稳、更可控:
交错式思考
每次回答/工具调用前都会思考,提升复杂指令的遵循能力和代码生成质量。
保留式思考
多轮对话中自动保留思考块,提升缓存命中率,降低成本,适合长程复杂任务。
轮级思考
支持在同一会话内按"轮"控制推理开销——简单任务可关闭思考以降低时延,复杂任务可开启思考以提升准确性与稳定性。
相关参考文档:https://docs.bigmodel.cn/cn/guide/capabilities/thinking-mode
前端与办公创作升级
前端审美提升
GLM-4.7 增强了对视觉代码的理解。在前端设计中,它能更好地理解 UI 设计规范,在布局结构、配色和谐度及组件样式上提供更具美感的默认方案,从而减少开发者在样式"微调"上花费的时间。
办公创作升级
GLM-4.7 在办公创作中版式与审美显著升级:
- • PPT 16:9 适配率:从 52% 跃升至 91%,生成结果基本"即开即用"
- • 海报设计:排版与配色更加灵活,具备设计感
综合任务执行能力
GLM-4.7 在复杂任务中展现出更强的任务拆解与技术栈整合能力,能够一次性给出完整、可运行的代码,并明确关键依赖与运行步骤,显著减少人工调试成本。
案例展示由 GLM-4.7 独立完成的高交互小游戏,如植物大战僵尸、水果忍者。
写在最后
GLM-4.7 的这次升级,不仅仅是参数的提升,更是从"生成代码"到"完成任务"的思维方式转变。
它不再是一个简单的代码生成工具,而是一个能够理解需求、拆解任务、整合技术栈、给出完整方案的智能开发伙伴。
后续我将购买 GLM-4.7 的使用权限,进行更深入的测试与体验,期待它在实际项目中的表现!
你对 GLM-4.7 有什么期待?是否已经在使用国产大模型辅助开发?欢迎在评论区分享你的看法和使用体验!
点赞 + 在看 + 转发,让更多开发者看到国产大模型的进步!
如果这篇文章帮到了你,不妨点个分享给同样需要的朋友吧! 你的每一次支持,都是我持续创作的动力!💪
往期推荐:
序号 | 文章标题 | 链接 |
|---|---|---|
1 | MCP协议爆火揭秘 | 查看详情 |
2 | 轻松配置Cursor玩转MCP | 查看详情 |
3 | Browser-Tool 前端开发神器 | 查看详情 |
4 | AI编码焕新:用Context7 | 查看详情 |
5 | NotebookLM:靠谱知识库 | 查看详情 |
6 | Spring AI 玩转多轮对话 | 查看详情 |
7 | Cursor生成UI,加一步封神 | 查看详情 |
8 | 神器!免费替代Postman | 查看详情 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号