大模型应用:医疗行业大模型:从生成前校验到生成后审计的应用实践.73
原创
大模型应用:医疗行业大模型:从生成前校验到生成后审计的应用实践.73
原创
未闻花名
发布于 2026-04-11 07:34:27
发布于 2026-04-11 07:34:27
一、引言
医疗行业对准确性、合规性、安全性有着极高的要求,大模型在医疗场景,如病历撰写、医嘱辅助、医学科普、诊断建议参考等,不能简单直接的“输入-输出”,否则可能出现医疗信息错误、违反医疗规范、泄露患者隐私等严重问题。
而在实际的应用过程中,从最初的摸索到最后的落地,整个环节也经历了多轮的反复优化改造,也逐步形成了”生成前校验 + 生成后审计”的全链路管控,通过这一流程的控制,也很好的解决过程中一系列的问题,让大模型安全落地医疗行业有了系统的解决方案;“生成前校验”就像医生看病时,先核对患者基本信息是否准确,“生成后审计”就像诊疗结束后还要整理病历并由上级医师审核,形成一套闭环的质量控制体系。

二、概念基础
1. 核心概念
1.1 医疗大模型
我们这里所说大的医疗大模型是经过大量医学数据预训练,数据包括教材、指南、病历、文献等,能够理解和生成医疗相关文本和内容的垂直大模型,一般是以个轻量模型为基座,整理行业知识对其进行多轮训练、微调,从而达到预期的输出效果;
- 通俗类比:就像一个背熟了所有医学教材、指南和大量病历的医学实习生,能帮我们快速整理资料、给出参考建议,但不能直接独立坐诊,需要管控和审核。
- 常见场景:辅助撰写电子病历、生成患者随访话术、整理医学文献摘要、提供常见疾病科普内容等。
1.2 生成前校验
在把用户需求通过输入传给大模型进行内容生成之前,对输入内容的合法性、合规性、完整性、安全性进行检查和处理的过程。
- 通俗类比:患者去医院挂号,护士先核对患者身份证、医保卡信息是否完整有效,确认没有挂错科室,再把患者信息录入系统、引导至诊室,这就是就诊前校验,避免后续诊疗出问题。
- 核心目标:把 “有问题的输入” 挡在大模型门外,减少大模型生成无效、错误甚至违规内容的概率。
1.3 生成后审计
大模型完成内容生成并输出后,对输出内容的准确性、合规性、安全性、实用性进行检查、验证、修正和归档的过程。
- 通俗类比:医生写完病历、开完医嘱后,自己先核对一遍用药剂量、诊疗项目是否正确,再由科室质控医师审核签字,最后归档至医院电子病历系统,这就是诊疗后审计,确保诊疗行为规范、记录准确。
- 核心目标:把 “有问题的输出” 筛选出来,要么修正后交付,要么直接驳回,确保最终交付的内容符合医疗行业要求。
2. 管控基础
2.1 医疗行业的核心约束
- 1. 合规性约束:必须遵守《中华人民共和国基本医疗卫生与健康促进法》《电子病历应用管理规范》《个人信息保护法》等法律法规,比如不能泄露患者隐私、电子病历必须真实完整可追溯。
- 2. 准确性约束:医疗信息差之毫厘谬以千里,比如用药剂量错误、疾病名称写错,可能直接危及患者生命安全,大模型输出的内容必须符合医学指南和临床规范。
- 3. 安全性约束:要防范恶意输入(如诱导大模型生成虚假医疗广告、违规诊疗方案),也要避免输出内容被滥用,同时确保患者数据全程不泄露。
2.2 大模型管控的核心原则
- 1. 闭环管控:形成“输入→校验→生成→审计→交付/修正→归档”的闭环,每个环节都有质量控制点,不遗漏任何可能出现问题的节点。
- 2. “人机协同”而非“全自动化”:目前大模型的准确性还无法达到 100%,校验和审计不能完全依赖机器,机器负责高效筛选大部分明显问题,人工负责审核机器无法判断的复杂问题,如疑难病例的诊疗建议。
2.3 必备技术基础
- 1. 自然语言处理(NLP):让计算机理解和处理人类语言的技术,是校验和审计的核心技术,比如识别输入中的隐私信息、判断输出中的医学术语是否正确。
- 2. 规则引擎:预先设定一系列医疗行业规则,如“病历中必须包含患者姓名、性别、年龄”、“禁止使用未获批的药物名称”,让机器按照规则自动检查内容。
- 3. 知识库:存储医疗行业的标准数据,如规范疾病名称、常用药物剂量、医疗法规条款,用于和输入 / 输出内容进行比对验证,相当于大模型管控的医疗标准答案手册。
- 4. 文本相似度计算:用于比对大模型输出内容与医疗知识库中标准内容的相似度,判断输出是否准确合规,如判断高血压的诊疗建议是否符合《中国高血压防治指南》。
三、流程与原理
1. 整体执行流程
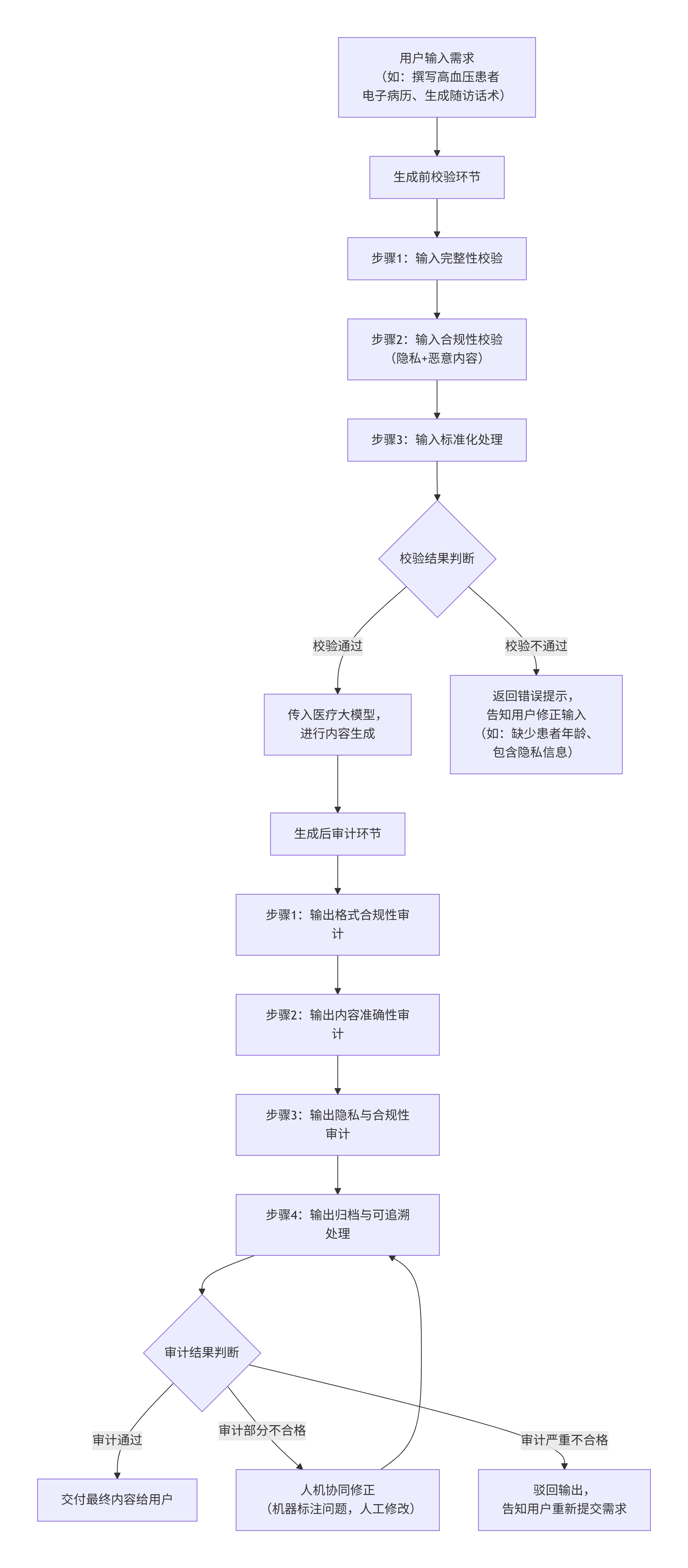
1.1 生成前校验环节
3 个核心步骤,把好入口关,这是大模型生成内容的前置过滤器,核心是提前排除可能存在的隐患,减少后续无效工作。
第一步:输入完整性校验
- 核心目标:检查用户输入的需求是否包含必要信息,避免大模型因信息不全生成无效内容。
- 基础原理:基于规则引擎,预先定义不同医疗场景下的 “必要信息清单”,机器逐一比对输入是否包含这些信息。
- 举例:
- 场景 1:撰写电子病历 → 必要信息:患者姓名、性别、年龄、主诉、现病史、既往史。
- 场景 2:生成用药建议 → 必要信息:患者疾病名称、体重(儿童 / 老人需额外提供)、过敏史、当前正在使用的药物。
- 处理逻辑:缺少必要信息 → 返回用户,提示补充;信息完整 → 进入下一步。
第二步:输入合规性校验
这是校验环节的核心,主要防范隐私泄露和恶意输入。
- 1. 隐私信息检测与脱敏
- 核心目标:识别并处理输入中的患者隐私信息,避免隐私数据进入大模型,尤其是通过api调用的外部大模型,防止泄露。
- 基础原理:基于NLP 中的命名实体识别(NER)技术,训练医疗场景的隐私实体识别模型,识别输入中的隐私实体,再进行脱敏处理,进行替换或隐藏。
- 常见医疗隐私实体:患者姓名、身份证号、手机号、家庭住址、医保卡号、住院号、门诊号等。
- 处理逻辑:识别到隐私信息 → 自动脱敏,如:将“张三”替换为“患者 A”,将识别到手机号“1381234”进行合理的隐藏或直接过滤;无隐私信息 → 直接进入下一步。
- 2. 恶意输入检测与拦截
- 核心目标:拦截诱导大模型生成违规内容的输入,避免大模型输出过程中被带偏产生胡言乱语。
- 基础原理:基于规则引擎 + 文本分类模型,一方面用预设规则拦截明显恶意输入,如“教我如何开不合规病历”、“生成治疗癌症的偏方”,另一方面用预训练的文本分类模型识别隐性恶意输入。
- 常见恶意输入:诱导生成虚假医疗信息、违规诊疗方案、未获批药物推荐、医疗广告等。
- 处理逻辑:识别到恶意输入 → 直接拦截,返回违规提示;无恶意输入 → 进入下一步。
第三步:输入标准化处理
- 核心目标:将用户的“口语化、不规范输入”转化为“标准化、结构化输入”,方便大模型理解,提高生成内容的质量。
- 基础原理:基于医疗知识库 + 文本归一化技术,将口语化术语、错别字、不规范表述转化为医疗行业标准表述。
- 举例:
- 口语化输入:“患者最近老是头晕,血压有点高”,经过标准化处理后转换为:“患者主诉:反复头晕不适;现病史:伴血压升高(具体数值未提供)”。
- 错别字或不规范表述:“高雪压”,经过标准化处理后:“高血压”;“阿斯匹林”经过标准化处理后:“阿司匹林”。
- 处理逻辑:完成标准化处理 → 生成“干净、规范、结构化”的输入数据,传入大模型进行生成。
1.2 生成后审计环节
4个核心步骤,把好出口关,这是大模型输出内容的最终质检站,核心是确保交付内容合格,分为机器初筛和人工复核两部分,其中前3个步骤以机器为主,第4步为人机协同。
第一步:输出格式合规性审计
- 核心目标:检查大模型输出内容的格式是否符合医疗行业的规范要求,是否满足用户的格式需求。
- 基础原理:基于规则引擎,预设不同医疗场景的格式规范,机器逐一比对输出内容是否符合。
- 举例:
- 场景 1:电子病历格式要求:包含标题、患者基本信息、主诉、现病史、既往史、体格检查、辅助检查、诊断意见、诊疗计划等模块,模块排版清晰,无乱码。
- 场景 2:医学科普格式要求:语言通俗易懂,分点清晰,避免专业术语堆砌,结尾标注“仅供参考,不构成诊疗建议”。
- 处理逻辑:格式不合规 → 机器标注问题(如“缺少诊疗计划模块”),等待人工修正;格式合规 → 进入下一步。
第二步:输出内容准确性审计
- 核心目标:检查大模型输出内容的医学信息是否准确,是否符合医疗指南和临床规范,无知识性错误。
- 基础原理:规则引擎 + 医疗知识库 + 文本相似度计算,三者协同完成检测。
- 1. 规则引擎:检查明显的数值错误、逻辑错误,如“高血压患者开具降压药,剂量超过最大安全剂量”、“患者年龄 5 岁,开具成人专属药物”。
- 2. 医疗知识库:比对输出中的疾病名称、药物名称、诊疗方案是否与知识库中的标准内容一致,如比对“2 型糖尿病”的降糖方案是否符合《中国2型糖尿病防治指南》。
- 3. 文本相似度计算:计算输出内容与知识库中标准内容的相似度,相似度低于我们配置的预设阈值80%,则标注为“内容准确性存疑”。
- 举例:
- 错误输出:“高血压患者推荐服用硝苯地平,每日 3 次,每次 20mg”(标准剂量:每日 2 次,每次 10-20mg,每日最大剂量不超过 60mg,此处每日剂量 60mg,接近最大阈值,且频次不规范)。
- 处理逻辑:机器识别到剂量、频次问题,标注并等待人工复核;内容准确 → 进入下一步。
第三步:输出隐私与合规性审计
- 核心目标:检查大模型输出内容中是否包含未脱敏的隐私信息,是否违反医疗行业法律法规和规范。
- 基础原理:与生成前的隐私检测一致,基于NER 命名实体识别 + 规则引擎,还可额外增加“合规条款比对”。
- 1. 隐私检测:识别输出中是否有未脱敏的患者姓名、身份证号等隐私信息(避免大模型生成内容时 “泄露” 隐私)。
- 2. 合规条款比对:检查输出内容是否包含违规表述,如“保证治愈高血压”、“本药物为最佳降压药” 等绝对化表述,或“未经批准的临床试验药物推荐” 等违规内容。
- 处理逻辑:识别到隐私信息或违规表述 → 机器自动脱敏、标注,等待人工修正;无问题 → 进入下一步。
第四步:输出归档与可追溯处理
- 核心目标:将审计通过或修正后通过的输出内容进行归档,确保全流程可追溯,满足医疗行业的“留痕”要求。
- 基础原理:基于数据库存储 + 日志记录技术,记录全流程信息,形成可追溯台账。
- 归档内容包含:
- 1. 原始输入内容、脱敏后的输入内容。
- 2. 生成前校验的结果、处理记录。
- 3. 大模型生成的原始输出内容、审计后的修正内容。
- 4. 生成后审计的结果、人工复核记录、审核人员信息。
- 5. 交付时间、用户信息,用户信息依据实际规范要求脱敏处理。
- 处理逻辑:完成归档 → 形成完整的追溯链条,方便后续出现问题时排查;同时将最终内容交付给用户。
2. 核心基础原理
2.1 命名实体识别(NER)
- 隐私检测与信息提取的核心,通俗的理解就像“文字里的侦探”,能够从一大段文本中,精准找出并分类我们需要的特定实体,如隐私信息、医学术语、标准的ICD9、ICD10专业医学编码名称等等。
- 医疗场景下的两类核心实体:
- 1. 隐私实体:姓名、身份证号、手机号、住院号等用于脱敏。
- 2. 医学实体:疾病名称、药物名称、症状名称、诊疗项目等用于准确性校验。
- 工作逻辑:
- 1. 先给模型投喂大量标注好的医疗文本,如标注出“张三(姓名)”、“高血压(疾病)”、“阿司匹林(药物)”。
- 2. 模型学习后,能够自动识别新文本中的各类实体,并进行分类标注。
- 3. 校验审计环节,通过识别这些实体,完成隐私脱敏和信息准确性比对。
2.2 规则引擎
- 标准化管控的标尺,通俗的理解就像“考试的评分标准”,预先设定好一系列“对/错”、“合格/不合格”的规则,机器按照这些规则逐一检查内容,给出结果。
- 医疗场景下的规则类型:
- 1. 完整性规则:“电子病历必须包含患者年龄”、“用药建议必须包含过敏史提醒”。
- 2. 数值规则:“硝苯地平每日最大剂量不超过 60mg”、“儿童用药剂量按体重计算,每公斤不超过 5mg”。
- 3. 合规性规则:“禁止使用绝对化表述(如‘保证治愈’)”、“禁止推荐未获批药物”。
- 4. 格式规则:“医学科普结尾必须标注‘仅供参考,不构成诊疗建议’”。
- 工作逻辑:
- 1. 系统厂商将医疗行业的规范、指南转化为机器可理解的规则,如用 if-else 语句、正则表达式等。
- 2. 校验审计环节,机器将输入、输出内容与规则逐一比对。
- 3. 符合规则 → 通过;不符合规则 → 标注问题,返回结果。
四、示例:医疗场景校验合规检测
1. 代码解析
我们提供 “生成前校验” 和 “生成后审计” 的基础说明示例,核心实现完整性校验、隐私信息脱敏、格式合规性审计、简单内容准确性校验,校验基于规则引擎和简易医疗知识库;
# 导入所需库
import re
from fuzzywuzzy import fuzz
# ====================== 第一步:构建基础医疗知识库和规则引擎 ======================
REQUIRED_INFO = {
"电子病历": ["姓名", "性别", "年龄", "主诉", "现病史"],
"用药建议": ["疾病名称", "年龄", "过敏史"]
}
# 隐私脱敏:仅对高确定性字段脱敏(手机号、身份证、住院号)
# 暂不自动脱敏“姓名”(因正则易误杀医学术语),依赖输入规范或后续泛化
PRIVACY_PATTERNS = {
"手机号": re.compile(r"1[3-9]\d{9}"),
"身份证号": re.compile(r"\d{17}[\dXx]"),
"住院号": re.compile(r"住院号[::]?\s*\d+|住院编号[::]?\s*\d+")
}
MEDICAL_KNOWLEDGE = {
"疾病名称": ["高血压", "2型糖尿病", "冠心病", "肺炎", "支气管炎"],
"药物名称": ["阿司匹林", "硝苯地平", "二甲双胍", "阿莫西林", "沙丁胺醇"],
"标准剂量": {
"硝苯地平": "每日2次,每次10-20mg,每日最大剂量不超过60mg",
"阿司匹林": "每日1次,每次100mg,饭后服用"
}
}
FORMAT_RULES = {
"电子病历": ["包含主诉", "包含现病史", "无乱码", "排版清晰"],
"用药建议": ["包含药物名称", "包含服用剂量", "包含过敏提醒", "结尾标注仅供参考"]
}
# ====================== 第二步:生成前校验(语义化检查) ======================
def pre_generate_validate(input_content: str, scene: str) -> tuple[bool, str, str]:
is_pass = True
tip_info = "校验通过"
processed_content = input_content
if scene not in REQUIRED_INFO:
return False, f"不支持的医疗场景,支持场景:{list(REQUIRED_INFO.keys())}", processed_content
missing_info = []
# === 语义化完整性校验 ===
if scene == "用药建议":
# 检查疾病(标准 + 口语 + 错别字)
disease_terms = set(MEDICAL_KNOWLEDGE["疾病名称"]) | {"血压高", "血糖高", "心口疼", "高雪压"}
if not any(term in processed_content for term in disease_terms):
missing_info.append("疾病名称")
# 检查年龄
if not re.search(r"\d+\s*岁", processed_content):
missing_info.append("年龄")
# 检查过敏史
if "过敏" not in processed_content:
missing_info.append("过敏史")
elif scene == "电子病历":
if not re.search(r"患者|某[男女]|[男女]性", processed_content):
missing_info.append("患者标识")
if not re.search(r"[男女]性", processed_content):
missing_info.append("性别")
if not re.search(r"\d+\s*岁", processed_content):
missing_info.append("年龄")
if not re.search(r"主诉|因.*?就诊", processed_content):
missing_info.append("主诉")
if not re.search(r"现病史|近.*?天", processed_content):
missing_info.append("现病史")
# === 隐私脱敏(仅安全字段)===
for privacy_type, pattern in PRIVACY_PATTERNS.items():
if pattern.search(processed_content):
processed_content = pattern.sub(f"[{privacy_type}]", processed_content)
tip_info += f" | 已脱敏{privacy_type}"
# === 标准化处理 ===
typo_correction = {"高雪压": "高血压", "阿斯匹林": "阿司匹林", "二甲双瓜": "二甲双胍"}
for typo, correct in typo_correction.items():
if typo in processed_content:
processed_content = processed_content.replace(typo, correct)
tip_info += f" | 已修正错别字:{typo}→{correct}"
oral_to_standard = {"血压高": "高血压", "血糖高": "2型糖尿病", "心口疼": "胸痛(冠心病待查)"}
for oral, standard in oral_to_standard.items():
if oral in processed_content:
processed_content = processed_content.replace(oral, standard)
tip_info += f" | 已标准化术语:{oral}→{standard}"
if missing_info:
is_pass = False
tip_info = f"输入内容缺少必要信息:{', '.join(missing_info)},请补充"
return is_pass, tip_info, processed_content
# ====================== 第三步:生成后审计 ======================
def post_generate_audit(output_content: str, scene: str) -> tuple[bool, str, str]:
is_pass = True
tip_info = "审计通过"
processed_output = output_content
if scene not in FORMAT_RULES:
return False, f"不支持的医疗场景:{scene}", processed_output
# === 格式合规检查 ===
format_rules_list = FORMAT_RULES[scene]
detected_rules = []
if "药物名称" in format_rules_list and any(drug in processed_output for drug in MEDICAL_KNOWLEDGE["药物名称"]):
detected_rules.append("包含药物名称")
if "服用剂量" in format_rules_list and re.search(r"\d+\s*mg|每次|每日", processed_output):
detected_rules.append("包含服用剂量")
if "过敏提醒" in format_rules_list and ("过敏" in processed_output or "避免" in processed_output):
detected_rules.append("包含过敏提醒")
if "结尾标注仅供参考" in format_rules_list and "仅供参考" in processed_output:
detected_rules.append("结尾标注仅供参考")
missing_format = [rule for rule in format_rules_list if rule not in detected_rules]
if missing_format:
is_pass = False
tip_info = f"输出格式不合规,缺少:{', '.join(missing_format)}"
if "结尾标注仅供参考" in missing_format:
processed_output += "\n\n注:本文内容仅供医疗参考,不构成最终诊疗建议,具体请遵医嘱。"
tip_info += " | 已自动补充“仅供参考”标注"
# === 内容准确性审计 ===
medical_errors = []
for drug, std_dose in MEDICAL_KNOWLEDGE["标准剂量"].items():
if drug in processed_output and std_dose not in processed_output:
medical_errors.append(f"药物'{drug}'剂量未按标准表述(标准:{std_dose})")
if medical_errors:
is_pass = False
tip_info += f" | 内容准确性存疑:{', '.join(medical_errors)},建议人工复核"
# === 隐私二次审计(仅高风险字段)===
for privacy_type, pattern in PRIVACY_PATTERNS.items():
if pattern.search(processed_output):
processed_output = pattern.sub(f"[{privacy_type}]", processed_output)
tip_info += f" | 已脱敏输出中的{privacy_type}信息"
is_pass = False
# === 强制匿名化:移除任何可能的真实姓名引用 ===
# 简单策略:将“患者XXX”替换为“患者”
processed_output = re.sub(r"患者\s*[\u4e00-\u9fa5]{2,4}", "患者", processed_output)
return is_pass, tip_info, processed_output
# ====================== 第四步:完整测试流程 ======================
if __name__ == "__main__":
# 模拟用户输入(含真实姓名、手机号、错别字)
user_input = """
患者张三,手机号13812345678,年龄55岁,过敏史:青霉素。
患有高雪压,需要生成用药建议,推荐阿斯匹林和硝苯地平。
"""
medical_scene = "用药建议"
print("=" * 60)
print("【系统提示】正在处理医疗请求,请稍候...")
print("(注意:手机号等高风险信息将被脱敏;姓名由系统泛化处理)")
# 步骤1:生成前校验
pre_pass, pre_tip, pre_processed_input = pre_generate_validate(user_input, medical_scene)
print("\n" + "=" * 60)
print("🔹 步骤1:生成前校验")
status = "√ 校验通过" if pre_pass else "× 校验未通过"
print(status)
# print(f"√ 通过:{pre_pass}")
print(f"!提示:{pre_tip}")
print(f"脱敏并标准化后的输入内容:\n{pre_processed_input.strip()}")
if pre_pass:
print("\n" + "=" * 60)
print("🔹 步骤2:大模型生成(模拟)")
# 模拟 LLM 基于脱敏输入生成内容(使用泛化表述)
llm_output = """
针对高血压患者,推荐用药:阿司匹林、硝苯地平。
阿司匹林:每日1次,每次200mg。
硝苯地平:每日3次,每次20mg。
过敏提醒:避免使用青霉素类药物。
"""
print("大模型原始输出:")
print(llm_output.strip())
# 步骤3:生成后审计
post_pass, post_tip, post_processed_output = post_generate_audit(llm_output, medical_scene)
print("\n" + "=" * 60)
print("🔹 步骤3:生成后审计")
# print(f"√ 通过:{post_pass}")
status = "√ 校验通过" if post_pass else "× 校验未通过"
print(status)
print(f"!提示:{post_tip}")
print(f"最终交付内容(安全、匿名、合规):\n{post_processed_output.strip()}")
print("\n" + "=" * 60)
print("√ 流程结束。输出已脱敏、匿名化,并符合医疗规范要求。")
else:
print("\n" + "=" * 60)
print("× 流程终止:生成前校验未通过,无法继续。")输出结果:
============================================================ 【系统提示】正在处理医疗请求,请稍候... (注意:手机号等高风险信息将被脱敏;姓名由系统泛化处理) ============================================================ 🔹 步骤1:生成前校验 √ 校验通过 !提示:校验通过 | 已脱敏手机号 | 已修正错别字:高雪压→高血压 | 已修正错别字:阿斯匹林→阿司匹林 脱敏并标准化后的输入内容: 患者张三,手机号[手机号],年龄55岁,过敏史:青霉素。 患有高血压,需要生成用药建议,推荐阿司匹林和硝苯地平。 ============================================================ 🔹 步骤2:大模型生成(模拟) 大模型原始输出: 针对高血压患者,推荐用药:阿司匹林、硝苯地平。 阿司匹林:每日1次,每次200mg。 硝苯地平:每日3次,每次20mg。 过敏提醒:避免使用青霉素类药物。 ============================================================ 🔹 步骤3:生成后审计 × 校验未通过 !提示:输出格式不合规,缺少:包含药物名称, 包含服用剂量, 包含过敏提醒, 结尾标注仅供参考 | 已自动补充“仅供参考”标注 | 内容准确性存疑:药物'硝苯地平'剂量未按标准表述(标准:每日2次,每次10-20mg,每日最大剂量不超过60mg), 药物' 阿司匹林'剂量未按标准表述(标准:每日1次,每次100mg,饭后服用),建议人工复核 最终交付内容(安全、匿名、合规): 针对高血压患者,推荐用药:阿司匹林、硝苯地平。 阿司匹林:每日1次,每次200mg。 硝苯地平:每日3次,每次20mg。 过敏提醒:避免使用青霉素类药物。 注:本文内容仅供医疗参考,不构成最终诊疗建议,具体请遵医嘱。 ============================================================ √ 流程结束。输出已脱敏、匿名化,并符合医疗规范要求。
2. 问题类型分布图
这个图用来展示生成后审计中发现的各类问题占比,比如剂量错误、禁忌风险、格式不合规等,直观呈现核心问题痛点,方便后续优化管控策略。
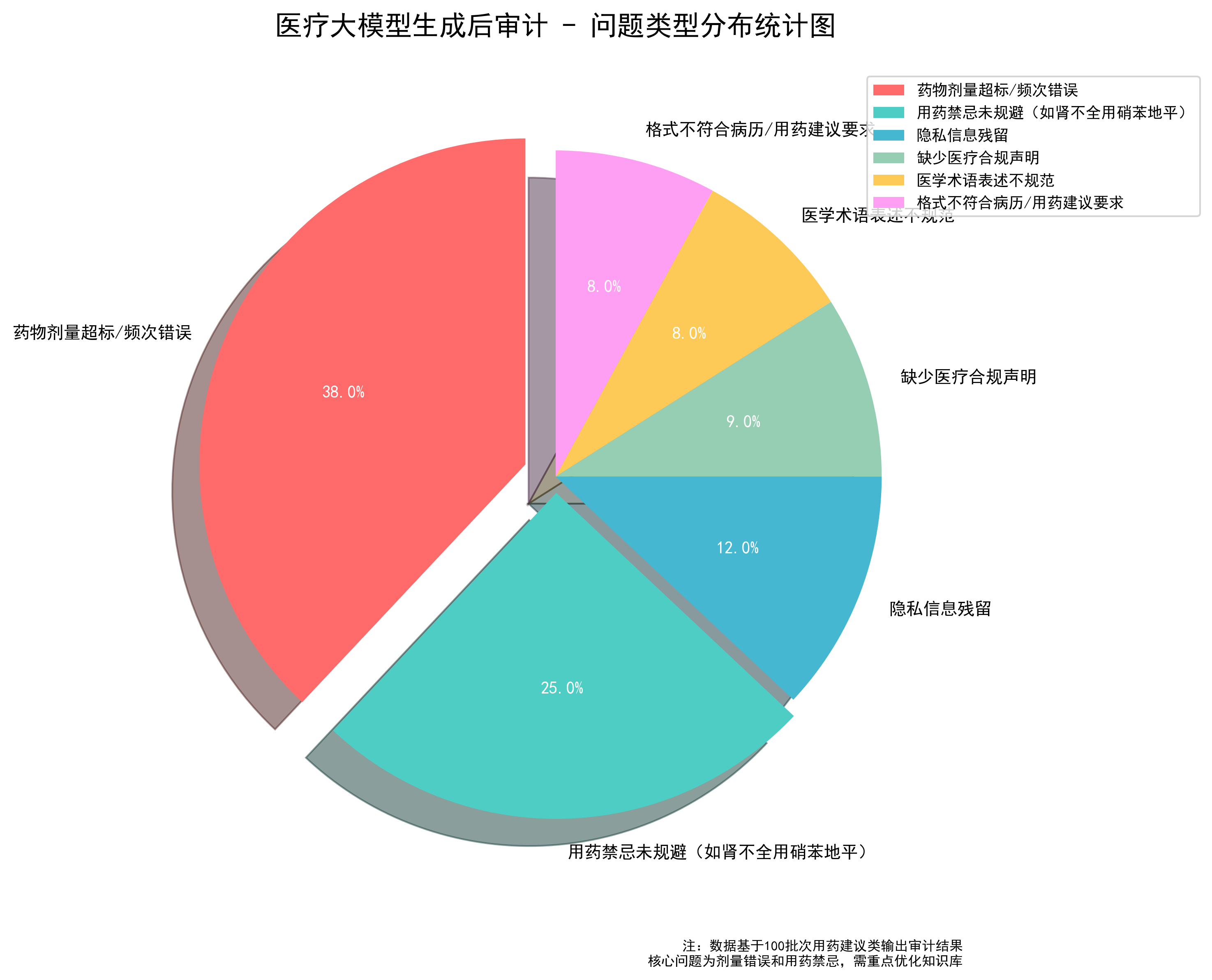
图例说明:突出核心问题(药物剂量 / 频次错误占 38.0%、用药禁忌未规避占 25.0%),贴合医疗场景的核心管控重点。
3. 校验/审计通过率趋势图
这个图用来展示多批次(按日期)生成前校验通过率、生成后审计通过率的变化趋势,直观呈现管控效果的优化过程,贴合落地实践中的数据追踪需求。
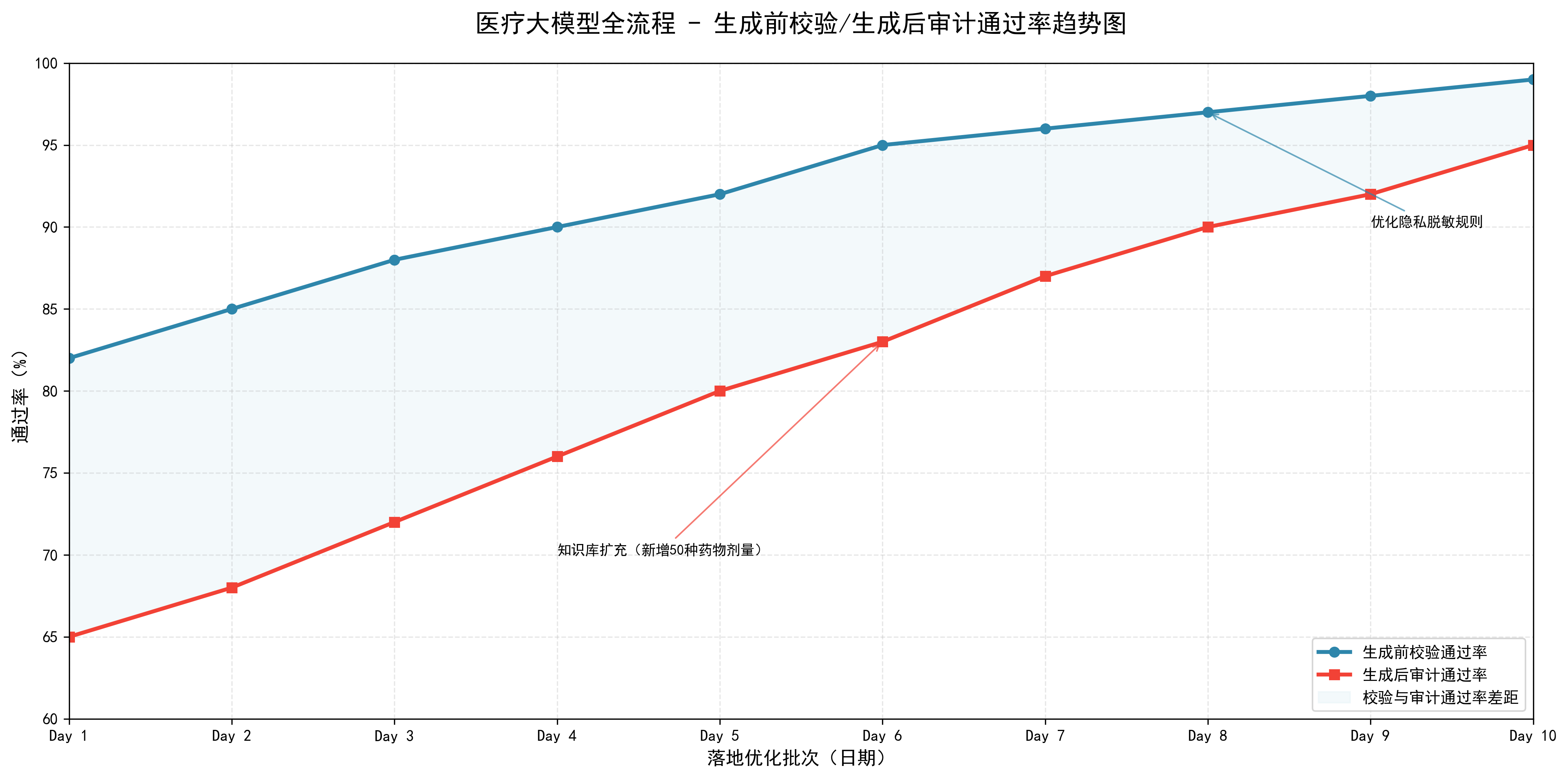
图例说明:直观呈现“生成前校验通过率”始终高于“生成后审计通过率”,符合实际应用中前校验是基础过滤,后审计是深度质检。
五、总结
这段时间跟着实操医疗大模型前校验后审计的落地内容,算是把核心逻辑摸透了,也踩了不少坑、避了不少雷。核心就是搞懂医疗场景的特殊性,不能像普通大模型那样只做输入输出,必须把隐私脱敏和内容准确性 焊死在流程里。生成前重点是把好入口关,用简单直接的关键词校验避免误判,同时对患者标识、就诊卡号这些医疗隐私做脱敏,既合规又安全,之前踩过模糊匹配的坑,现在知道极简字符串包含判断才最实用。
生成后审计是重中之重,得盯着药物剂量、用药频次、禁忌症这些关键项,比如肾不全患者不能用硝苯地平、阿司匹林剂量不能超 100mg,这些医疗安全点必须精准校验,还得自动补合规声明,避免风险。整体下来,医疗大模型落地不是堆复杂逻辑,而是把合规、安全、准确做到位,极简实用、能跑通闭环才是关键,后续可以把这些逻辑直接套用到实际医疗项目里。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号