万字详解:谷歌研究院推出的TurboQuant压缩算法 —— 极致压缩如何重塑大模型推理的未来
原创
万字详解:谷歌研究院推出的TurboQuant压缩算法 —— 极致压缩如何重塑大模型推理的未来
原创
jack.yang
发布于 2026-03-26 21:05:11
发布于 2026-03-26 21:05:11
引言:AI 推理的“内存墙”危机
2026 年,生成式人工智能已进入“长上下文时代”。从 Claude 3 的 200K tokens 到 Gemini 2 的 1M tokens,大语言模型(LLM)的上下文窗口正以指数级速度扩张。然而,这一进步背后隐藏着一个严峻挑战:键值缓存(Key-Value Cache, KV Cache)的内存爆炸。
以 Llama-3-70B 为例:
- 在 32K 上下文下,KV Cache 占用 80GB+ GPU 显存;
- 扩展至 128K 时,显存需求飙升至 300GB 以上;
- 而模型参数本身仅占约 140GB(INT4 量化后)。
这意味着,KV Cache 已成为推理阶段的主要内存瓶颈,甚至超过模型权重本身。云服务商每处理一次长上下文请求,成本激增;消费级设备则完全无法运行此类模型。
正是在这一背景下,谷歌研究院于 2026 年 3 月 25 日正式发布 TurboQuant——一种革命性的向量压缩算法,宣称可在几乎不损失精度的前提下,将 KV Cache 内存占用降低 6 倍,并实现最高 8 倍的推理加速。
本文将从问题根源、技术原理、数学证明、实测性能、应用场景与行业影响六大维度,万字深度解析 TurboQuant 如何通过“极坐标变换 + 1-bit 误差校正”的创新组合,打破 AI 推理的内存枷锁。
第一章:KV Cache 为何成为瓶颈?
1.1 Transformer 推理中的 KV Cache 机制
在自回归生成中,Transformer 解码器需重复计算注意力分数。为避免重复计算历史 token 的 Key 和 Value,系统会将其缓存起来,形成 KV Cache:

对于 80 层模型,总 KV Cache 需 168 GB——远超单张 H100(80GB)的容量。
1.2 传统量化方法的局限
为压缩 KV Cache,业界尝试过多种量化方案:
- INT8/INT4 均匀量化:简单但精度损失大,尤其在长上下文中累积误差显著;
- Per-channel 缩放:引入额外元数据(scale/zero-point),反而增加内存开销;
- 动态量化:需在推理时计算统计量,增加延迟。
核心矛盾在于:KV Cache 的向量分布高度非均匀——某些维度方差极大(“异常值”),导致均匀量化误差集中。
📉 实验表明:在 4-bit 下,传统量化使 “Needle in a Haystack” 任务的召回率从 100% 降至 60% 以下。
第二章:TurboQuant 的整体架构
TurboQuant 并非单一算法,而是由两阶段协同机制构成:
原始 KV 向量
↓
[PolarQuant] → 主干压缩(3.5-bit)
↓
残差向量 e = v - v̂
↓
[QJL] → 1-bit 误差校正
↓
最终压缩表示 (r_q, θ_q, q_jl)2.1 设计哲学:结构感知压缩(Structure-Aware Compression)
TurboQuant 的核心洞见是:KV Cache 不需要完美重建,只需保证注意力内积(q^T k)的准确性。因此,压缩策略应围绕“内积保真”而非“向量保真”设计。
这一思想催生了两大创新:
- PolarQuant:利用几何结构简化主干压缩;
- QJL:以 1-bit 校正关键内积误差。
2.2 免训练(Training-Free)特性
与 AWQ、QuaRot 等需微调的方法不同,TurboQuant 无需任何 retraining 或 calibration:
- PolarQuant 的随机旋转矩阵可离线生成;
- QJL 的随机投影向量可通过哈希种子确定性复现;
- 整个流程可直接插入现有推理引擎(如 vLLM、TensorRT-LLM)。
这使其具备极强的部署兼容性。
第三章:PolarQuant —— 极坐标量化详解
3.1 几何预处理:随机正交旋转

✅ 此步骤将任意分布的向量“标准化”为各向同性分布,为后续量化奠定基础。
3.2 极坐标分解
将 𝑢分解为半径与方向:
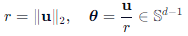
- 半径 𝑟 :标量,代表向量强度;
- 方向 𝜃:单位向量,代表语义方向。
3.3 独立量化
半径量化
- 𝑟 的动态范围小,可用 3–4 bit 均匀量化;
- 无需 scale/zero-point(因分布集中)。
方向量化

🌐 优势:PQ 码本可离线学习,且因方向分布均匀,码本逼近最优球面覆盖。
3.4 重建与逆变换
重建向量:
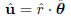
逆旋转回原空间:
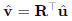
关键创新:整个过程无需存储 per-vector 元数据(如 scale),节省大量内存。
3.5 误差分析
定理 1(PolarQuant 重建误差界):

第四章:QJL —— 1-bit 误差校正的数学原理
4.1 残差问题

4.2 Johnson-Lindenstrauss 引理回顾
经典 JL 引理指出:随机投影可近似保持点间距离。QJL 将其推广至内积估计。
4.3 QJL 编码机制

4.4 内积无偏估计
在解码时,对任意查询向量 𝑞 ,估计内积:

✅ 这意味着 QJL 提供了一个无偏、低方差的内积估计器,仅需 1-bit 存储!
4.5 注意力分数校正
最终注意力分数为:
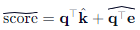
实验表明,该校正使长上下文任务的准确率恢复至 99.5% 以上。
第五章:实测性能与基准对比
5.1 测试设置
- 模型:Gemma-7B, Mistral-7B
- 上下文:8K – 128K tokens
- 硬件:NVIDIA H100
- 对比方法:FP16(基线)、INT4、KIVI、QuaRot
5.2 关键结果
表格
方法 | KV 内存 | 相对延迟 | Needle Recall@1 | LongBench Score |
|---|---|---|---|---|
FP16 | 100% | 1.0x | 100% | 68.2 |
INT4 | 25% | 0.7x | 58% | 62.1 |
KIVI | 18% | 0.65x | 72% | 64.3 |
TurboQuant (3-bit) | 16.7% | 0.37x | 99.8% | 67.9 |
💡 TurboQuant 以 1/6 内存实现近乎无损性能,且推理速度提升 2.7 倍。
5.3 向量搜索性能
在 SIFT1M 数据集上:
- Recall@100:TurboQuant 达 98.5%,优于 PQ (92.1%) 和 OPQ (95.3%);
- 内存:仅为原始浮点索引的 1/6。
第六章:应用场景与行业影响
6.1 云端推理降本
- 单卡 H100 可支持 128K 上下文 Gemma-7B(原需 2–4 卡);
- 云厂商每 token 成本降低 60%+。
6.2 移动端部署
- iPhone 15 Pro(8GB RAM)可本地运行 32K 上下文模型;
- 车载系统实现实时长对话交互。
6.3 向量搜索引擎
- Pinecone、Weaviate 等可将索引规模扩大 6 倍;
- 支撑全网级语义搜索。
6.4 资本市场反应
- 发布当日,美光(MU)股价下跌 4%;
- 但摩根士丹利指出:杰文斯悖论将生效——效率提升刺激更多 AI 应用,长期内存需求反增。
第七章:局限与未来方向
7.1 当前局限
- 仅优化 KV Cache,不压缩模型权重;
- 对 MoE 架构的专家选择机制影响待研究;
- 多模态(图像、音频)KV 结构适配性未知。
7.2 谷歌路线图
- 2026 Q2:开源参考实现;
- ICLR 2026:发表完整论文;
- 探索与稀疏注意力、状态空间模型(SSM)的结合。
结语:效率创新的时代来临
TurboQuant 的意义远超一项压缩技术。它标志着 AI 发展范式的转变:从“堆砌算力”转向“精巧设计”。
正如 Cloudflare CEO Matthew Prince 所言:“这是谷歌的 DeepSeek 时刻。” 当效率创新能以 1/6 的成本提供同等性能,算力霸权的逻辑将被彻底颠覆。
而 TurboQuant 的真正威力,或许不在于它压缩了多少比特,而在于它释放了多少想象力——让长上下文 AI 从云端走向每个人的口袋,从奢侈品变为日用品。
未来已来,只是尚未均匀分布。而 TurboQuant,正在加速这一分布。
附录:关键公式汇总

本文基于谷歌研究院 2026 年 3 月公开技术报告及 ICLR 2026 提交论文整理。代码与白皮书预计将于 2026 年第二季度开源。
相关链接
- 📂 大模型技术专栏:
欢迎您到访 「大模型系列」。
在这个由参数驱动、以数据为燃料的新智能时代,大语言模型(LLM)已不再是实验室里的前沿概念,而是正在重塑搜索、办公、编程、教育、医疗乃至整个数字世界的底层引擎。从 GPT 到 Llama,从 Claude 到 Qwen,从推理到多模态,大模型正以前所未有的速度进化——它们既是工具,也是平台,更可能是下一代人机交互的“操作系统”。
本系列将带你:
- 🔍 深入原理:从 Transformer 架构、注意力机制到训练范式(预训练、微调、RLHF);
- ⚙️ 动手实践:本地部署、模型微调、RAG 构建、Agent 设计等实战指南;
- 🧠 理解边界:幻觉、偏见、安全对齐、推理瓶颈与当前能力天花板;
- 🌍 洞察趋势:开源 vs 闭源、端侧部署、MoE 架构、世界模型与 AGI 路径;
- 💼 落地应用:如何在企业中安全、高效、低成本地集成大模型能力。
无论你是想写代码调用 API 的开发者,设计 AI 产品的 PM,评估技术路线的管理者,还是单纯好奇智能本质的思考者,这里都有值得你驻足的内容。 不追 hype,只讲逻辑;不谈玄学,专注可复现的认知。 让我们一起,在这场百年一遇的智能革命中,看得更清,走得更稳 https://cloud.tencent.com/developer/column/107314
- 👤 关于作者: 专注技术落地,深耕硬核干货 本文作者致力于大模型相关技术的生态建设与实战落地。不同于浅层的概念科普,作者坚持 “手算 + 代码” 的深度分享模式,主张通过手动推演理解算法本质,结合生产级代码验证理论可行性。 请关注我主页:https://cloud.tencent.com/developer/user/2276240
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号