大模型应用:大模型权重敏感性分析:L1/L2 范数、梯度贡献深入解读.39
原创
大模型应用:大模型权重敏感性分析:L1/L2 范数、梯度贡献深入解读.39
原创
未闻花名
发布于 2026-03-08 09:38:59
发布于 2026-03-08 09:38:59
一、基础概念
1. 什么是权重敏感性
大模型的权重敏感性,通俗来说就是模型中某一个或某一组权重参数的微小变化,对模型最终输出结果或性能指标的影响程度。我们可以把大模型想象成一个精密的"黑箱计算器",权重就是计算器里的成千上万个"旋钮":
- 有的旋钮敏感度高:轻轻转一下,计算器输出的结果就会发生巨大变化;
- 有的旋钮敏感度低:就算拧半圈,结果也几乎没差别。
权重敏感性的核心,就是衡量这些旋钮的灵敏程度,它是大模型优化、压缩、剪枝的核心依据。

2. 敏感性的核心因素
权重的敏感程度不是单一维度决定的,而是由"静态数值潜力"和"动态实际贡献"共同决定:
2.1 静态数值潜力(由 L1/L2 范数衡量)
权重的数值大小,决定了它的理论影响力上限。
- 范数大的权重:理论上有更大的潜力影响模型输出,是高潜力选手;
- 范数小的权重:理论影响力有限,是低潜力选手。
但潜力≠实际贡献,有的权重数值大,却在模型计算中没发挥作用。
2.2 动态实际贡献(由梯度贡献衡量)
权重在模型训练或推理过程中,对损失函数(预测误差) 的影响程度,决定了它的实际影响力。
- 梯度贡献大的权重:权重的微小调整会大幅改变模型误差,是实际核心选手;
- 梯度贡献小的权重:调整后对误差影响极小,是边缘选手。
3. 敏感性的特点和应用
3.1 高敏感性权重
核心特点:在于其微小的调整便可能导致模型输出或性能发生显著波动。这类权重通常梯度贡献较高,且自身范数(如 L2 范数)适中。
通俗理解:动一点点,结果天翻地覆,属于核心权重,不能随便改;
在实践中,它们是模型调优阶段的核心关注对象,针对这些权重进行精细、谨慎的微调,往往能够快速有效地提升模型性能。同时,出于模型稳定性与性能保护的考虑,在训练或迁移学习过程中,也常需要采取特定策略(如较小的学习率、权重冻结或正则化约束),避免对其产生过于剧烈或不当的修改,以防止模型性能发生崩塌或退化。
3.2 低敏感性权重
核心特点:即使对其进行幅度较大的调整,模型的输出或整体性能也几乎不受影响,表现出很强的鲁棒性。这类权重通常与较低的梯度贡献相关,无论其自身范数大小如何。
通俗理解:改半天,结果几乎没变,通常可裁剪、压缩,不影响模型效果。
正因如此,它们在模型轻量化与部署优化中扮演着关键角色:
- 一方面,可作为模型剪枝或压缩的重点目标,通过直接移除、置零或大幅精简这些权重,显著降低模型的参数量和计算复杂度;
- 另一方面,在对这类权重实施低精度量化(例如从 FP32 降至 INT8)时,能够在几乎不损失模型精度的前提下,有效减少模型存储空间、提升推理速度,实现高效的模型加速。
二、基础工具
1. L1 范数(L1 Norm)
1.1 核心定义
L1 范数又称曼哈顿范数,Manhattan Norm,是指一组数值中所有元素绝对值的总和,在大模型权重分析中,用于衡量某一层 / 某一组权重的"绝对值规模",反映权重"非零程度"的核心指标。
1.2 数学表达式
1.2.1 标量形式(单组权重向量)
L1 范数等于权重向量中每个元素的绝对值相加,对于权重向量 w=[w₁ , w₂ , ... , wₙ],其 L1 范数计算公式为:
L1 范数 = |w₁| + |w₂| + ... + |wₙ|(w₁到 wₙ是权重向量的所有元素)
1.2.2 矩阵形式(模型层权重矩阵)
L1 范数等于权重矩阵中所有元素的绝对值相加,对于权重矩阵 W ∈ R^(m×n)(例如全连接层的权重矩阵),其 L1 范数的计算公式为:
||W||₁ = ∑ᵢ₌₁ᵐ ∑ⱼ₌₁ⁿ |Wᵢⱼ|
计算步骤:
- 遍历矩阵的所有 m × n 个元素
- 对每个元素取绝对值 |Wᵢⱼ|
- 将所有绝对值相加得到总和
1.3 通俗解读
把权重向量想象成"从原点出发,沿坐标轴走的步数":比如权重向量 [3, -2],L1 范数 =|3| + |-2|=5,相当于在二维平面上,从 (0,0) 走到 (3,-2),沿 x 轴走 3 步、沿 y 轴走 2 步,总步数为 5(只算绝对值,不考虑方向)。
在大模型中,某一层权重的 L1 范数越大,说明该层 “非零权重的绝对值总和越高”,理论上对模型输出的 “基础影响力” 越强。
1.4 核心特点
- 对离群值的敏感度低,离群值(超大权重)的绝对值仅线性累加,不会被放大,比如权重 100 和权重 10,仅差 90
- 稀疏性倾向强,优化过程中易让部分权重趋近于 0,适合筛选"非零核心权重"
- 计算复杂度低,仅绝对值求和,无平方/开方运算,计算速度快
- 二维空间中为菱形,高维空间中为超菱形,代表"沿坐标轴的最短路径和"
1.5 权重分析中的应用场景
1.5.1 筛选"非零权重占比高"的模型层
核心机制:通过计算网络各层权重的 L1 范数,即绝对值之和,可以衡量该层中非零权重的"密度"与整体贡献强度。L1 范数显著较高的层,通常包含大量活跃的非零权重,表明该层正在执行模型的关键计算与特征变换,是模型功能得以实现的基础架构层和核心计算单元。
实际应用:在模型微调、架构分析或知识蒸馏时,优先关注和调整这些高 L1 范数层,往往能更高效地改变或迁移模型的核心能力。反之,若模型核心层 L1 范数过低,则可能预示模型存在欠拟合或表达能力不足的问题。
1.5.2 模型稀疏化
核心机制:在损失函数中引入 L1 正则化项,又称Lasso 正则化项,会惩罚权重的绝对值总和。优化过程中,模型倾向于将那些对最终任务贡献微弱的权重逐步压缩至零,从而实现权重的"稀疏化"。这是一种结构化剪枝的自动化形式。
实际应用:通过 L1 正则化获得的稀疏模型,由于其中包含大量零值可高效压缩,同时也可跳过零值运算,所以其存储和计算效率大幅提升。生成的稀疏结构为进一步的模型压缩(如非结构化剪枝)、硬件友好型加速以及低功耗部署提供了理想起点。
1.5.3 权重异常检测
核心机制:在训练或评估过程中,持续监控各层权重的 L1 范数。若某一层的 L1 范数发生突变,如急剧增大或减少,往往是一个强烈的异常信号。这通常意味着该层可能出现了梯度爆炸(权重值异常膨胀)、权重衰减过度(权重被过度惩罚)或发生了严重的过拟合,例如某些权重变得异常大以"记忆"特定样本。
实际应用:L1 范数可作为训练过程健康的仪表盘指标。其实时监控能帮助开发者快速定位问题层,及时采取干预措施,例如调整学习率、检查梯度裁剪、增强正则化或验证数据输入,从而保障训练过程的稳定性和最终模型的鲁棒性。
1.6 计算示例
import numpy as np
def compute_l1_norm(matrix):
"""
计算矩阵的 L1 范数
参数:
matrix: numpy.ndarray, 输入矩阵
返回:
float: 矩阵的 L1 范数值
"""
return np.sum(np.abs(matrix))
# 示例
W = np.array([[1, -2, 3],
[-4, 5, -6],
[7, -8, 9]])
l1_norm = compute_l1_norm(W)
print(f"权重矩阵 W 的 L1 范数为: {l1_norm}")输出结果:
权重矩阵 W 的 L1 范数为: 45.0
计算验证:
对于示例中的 3×3 矩阵: ||W||₁ = |1| + |-2| + |3| + |-4| + |5| + |-6| + |7| + |-8| + |9| = 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 = 45
2. L2 范数(L2 Norm)
2.1 核心定义
L2 范数又称欧几里得范数,Euclidean Norm,是指一组数值中所有元素的平方和的平方根,在大模型权重分析中,用于衡量某一层或某一组权重的整体规模,反映权重"数值集中度"的核心指标。
2.2 数学表达式
2.2.1 标量形式(单组权重向量)
L2 范数等于权重向量中每个元素的平方相加后开平方根,对于权重向量 w=[w₁ , w₂ , ... , wₙ],其 L2 范数计算公式为:
L2 范数 = √(w₁² + w₂² + ... + wₙ²)
2.2.2 矩阵形式(模型层权重矩阵)
L2 范数等于权重矩阵中所有元素的平方相加后开平方根,对于权重矩阵 W ∈ R^(m×n),其 L2 范数的计算公式为:
||W||₂ = √(∑ᵢ∑ⱼ Wᵢⱼ²)
计算步骤:
- 遍历矩阵的 m × n 个元素
- 对每个元素取平方 Wᵢⱼ²
- 将所有平方值相加得到总和
- 对该总和取平方根即得 L2 范数
2.3 通俗解读
仍以权重向量 [3, -2] 为例,L2 范数 =√(3² + (-2)²)=√13≈3.606,相当于在二维平面上,通过勾股定理计算从 (0,0) 到 (3,-2) 的直线距离。
在大模型中,某一层权重的 L2 范数越大,说明该层"高数值权重占比越高",由于平方运算会放大高权重的影响,所以对模型输出的潜在影响力越强。
2.4 核心特点
- 对离群值的敏感度高,离群值的平方会被大幅放大,比如权重 100 的平方是 10000,权重 10 的平方仅 100,差距达 9900
- 稀疏性弱,优化过程中易让权重均匀分布,不会轻易变为 0,更注重整体规模控制
- 计算复杂度适中,需平方、求和、开方,计算速度略慢于 L1,但仍可高效实现
- 二维空间中为圆形,高维空间中为超球体,代表原点到点的直线距离
2.5 权重分析中的应用场景
2.5.1 衡量权重整体规模
核心机制:权重的L2范数,即欧几里得范数,所有权重值的平方和开方,直观地反映了该层或该模型权重的能量或整体规模大小。当一个层或整个模型的L2范数异常高时,意味着大量权重具有较大的绝对值。
这通常是模型训练出现问题的信号:
- 一方面,过大的权重容易使模型对输入噪声和训练数据中的特异细节过度敏感,从而导致过拟合;
- 另一方面,它也是梯度爆炸,梯度值变得极大,权重更新失控的常见后果和表现。
实际应用:定期监控各层及整体模型的L2范数,是诊断训练过程稳定性的重要手段。将其作为训练健康度指标,有助于及时发现学习率设置过高、未使用梯度裁剪或正则化不足等问题,从而进行干预,确保模型朝稳定、泛化的方向收敛。
2.5.2 模型正则化
核心机制:L2正则化,就是我们在深度学习中常直接称为的"权重衰减",通过在损失函数中添加一项与权重L2范数平方成正比的惩罚项,即所有权重值的平方和,来约束权重的增长。其核心作用是惩罚高数值的权重,但不强制使其归零。这种惩罚促使优化器在拟合数据与保持权重较小之间寻找平衡,最终结果是促使权重分布趋向于更均匀、数值更小且平滑。
实际应用:L2正则化是提升模型泛化能力最经典有效的方法之一。通过抑制权重的过度增长,它降低了模型的复杂度和对训练数据的过拟合倾向,使其在面对新数据时表现更加鲁棒。这是几乎所有现代深度学习训练中都会默认使用或考量的基础技术。
2.5.3 权重相似性对比
核心机制:通过比较两个不同层或同一层在不同训练阶段权重的L2范数值,可以快速判断其整体规模或能量水平的相似程度。若两者的L2范数差值很小,表明这两组权重的"量级"和分布广度接近。虽然这不能精确反映每个权重的位置关系(即方向),但显著的差异往往意味着这两组权重在模型中所起的作用规模或所处的学习阶段可能不同。
实际应用:在模型分析、知识蒸馏或迁移学习中,该对比可用于快速筛选规模相近的层进行对齐或融合。例如,在检查微调前后模型的变化时,若某层L2范数发生剧变,可能意味着该层学到了非常新的特征或发生了灾难性遗忘。它提供了一种从宏观能量角度理解权重分布变化的快捷方式。
2.6 计算示例
import numpy as np
def compute_l2_norm(matrix):
"""
计算矩阵的 L2 范数(Frobenius 范数)
参数:
matrix: numpy.ndarray, 输入矩阵
返回:
float: 矩阵的 L2 范数值
"""
return np.linalg.norm(matrix, ord='fro') # 或 np.sqrt(np.sum(matrix**2))
def compute_l2_norm_squared(matrix):
"""
计算矩阵 L2 范数的平方
"""
return np.sum(matrix**2)
# 示例
W = np.array([[1, -2, 3],
[-4, 5, -6],
[7, -8, 9]])
l2_norm = compute_l2_norm(W)
l2_norm_sq = compute_l2_norm_squared(W)
print(f"权重矩阵 W 的 L2 范数为: {l2_norm:.4f}")
print(f"权重矩阵 W 的 L2 范数平方为: {l2_norm_sq}")输出结果:
权重矩阵 W 的 L2 范数为: 16.8819 权重矩阵 W 的 L2 范数平方为: 285.0
计算验证:
对于示例中的 3×3 矩阵: ‖W‖₂² = 1² + (-2)² + 3² + (-4)² + 5² + (-6)² + 7² + (-8)² + 9² = 1 + 4 + 9 + 16 + 25 + 36 + 49 + 64 + 81 = 285 ‖W‖₂ = √285 ≈ 16.8819
应用关联:
- 模型复杂度评估:L2 范数较大可能预示模型过拟合风险
- 正则化依据:训练中通过惩罚 ‖W‖₂² 约束权重增长
- 权重分布分析:比较不同层/模型的 L2 范数可了解其能量分布差异
- 训练稳定性监控:L2 范数骤增常提示梯度爆炸可能
3. 梯度贡献
3.1 核心定义
梯度贡献是指模型权重的梯度(损失函数对权重的偏导数)的"有效规模",反映权重在模型训练或预测过程中的实际活跃度,梯度贡献越大,说明该权重对模型损失(预测误差)的影响越大,是衡量权重实际敏感性的核心指标。
3.2 前置概念:梯度(Gradient)
在大模型中,损失函数 L 衡量模型预测值与真实值的误差,某一权重 wᵢ 的梯度 ∂L/∂wᵢ 表示:当 wᵢ 变化一个极小值时,损失函数 L 的变化量。
- 梯度为正→增大 wᵢ 会让损失增加,减小 wᵢ 会让损失降低;
- 梯度为负→增大 wᵢ 会让损失降低,减小 wᵢ 会让损失增加;
- 梯度为 0→ wᵢ 的微小变化不会影响损失,该权重无活跃度。
3.3 梯度贡献的数学表达
梯度贡献通常用 “梯度的 L1/L2 范数” 量化(类比权重范数的计算逻辑):
3.3.1 梯度的 L1 范数(梯度贡献 L1)
对于权重向量 w 的梯度向量 ∇w = [∂L/∂w₁ , ∂L/∂w₂ , ... , ∂L/∂wₙ]:
||∇w||₁ = |∂L/∂w₁| + |∂L/∂w₂| + ... + |∂L/∂wₙ|(∂L/∂wᵢ是损失函数 L 对权重 wᵢ的偏导数)。 3.3.2 梯度的 L2 范数(梯度贡献 L2)
对于权重向量 w 的梯度向量 ∇w = [∂L/∂w₁ , ∂L/∂w₂ , ... , ∂L/∂wₙ]:
||∇w||₂ = √((∂L/∂w₁)² + (∂L/∂w₂)² + ... + (∂L/∂wₙ)²)
3.4 通俗解读
想象一个生产产品的工厂,我们的目标是降低产品的次品率,即损失函数。
- 工人(权重):工厂里有无数个工人,每个工人负责调整产品生产的一个环节。
- 工人的理论能力(权重的范数):工人的理论能力由他的经验、技能水平(权重的数值大小)决定。理论上,能力强的工人(权重范数高)对生产的影响更大。
- 工人的实际影响(梯度):然而,在实际生产中,每个工人对次品率的影响程度是不同的。这种影响程度用"梯度"来衡量。梯度大的工人,只要他的操作稍有变化(权重的微小调整),次品率就会发生显著变化。
- 工人的关键性(梯度贡献):梯度贡献综合了工人的理论能力和实际影响,反映了工人实际对次品率的影响规模。梯度贡献大的工人,是降低次品率的关键人物。
举例:
- 工人A:理论能力很强(权重数值大,L2范数高),但梯度为0。这意味着他虽然有能力,但在当前生产流程中并没有发挥作用(比如被分配到了无关紧要的岗位),他的操作变化对次品率没有影响。因此,他并不关键。
- 工人B:理论能力一般(权重数值小,L2范数低),但梯度很大。这意味着他虽然能力不强,但他的岗位非常关键,操作稍微变化就会对次品率产生很大影响。因此,他是实际生产中的关键执行者。
通过这个比喻,我们可以直观地理解:
- 在模型优化中,我们更关注那些梯度贡献大的权重(关键工人),因为调整他们能快速降低损失(次品率)。
- 对于梯度贡献小的权重(非关键工人),即使他们的理论能力很强,我们也可以考虑进行压缩或剪枝(相当于调整岗位或裁员),而不太影响生产。
权重类型类比:
- 高范数、零梯度:"资深顾问"型工人:经验丰富(高范数),但已退居二线(梯度为0),工厂花高薪聘请的专家,目前不参与实际生产,对次品率无直接影响
- 低范数、高梯度:"关键技术员"型工人:资历尚浅(低范数),但掌握核心操作技术(高梯度),虽然年轻,但负责关键设备操作,稍有不慎就会导致大量次品
- 高范数、高梯度:"核心工程师"型工人:经验丰富且身处关键岗位,既是技术专家,又直接负责关键生产环节,是工厂最重要的资产
- 低范数、低梯度:"辅助工"型工人:新手或辅助岗位,工作变化对产品质量影响小,可以被调整或替换而不影响整体生产
3.5 核心特点
- 与范数的区别:范数衡量权重本身的数值规模(潜力),梯度贡献衡量权重对损失的实际影响(活跃度)
- 动态性:随训练批次/数据集变化,不同数据输入,同一权重的梯度贡献可能差异显著
- 方向性:梯度有正负,反映影响方向,梯度贡献(范数)无正负,仅反映影响规模
- 计算前提:需完成模型前向传播(计算损失)和反向传播(计算梯度),依赖具体任务和数据
3.6 权重分析中的应用场景
3.6.1 识别实际核心权重
核心机制:梯度贡献直接量化了权重在当前前向计算与反向传播中的实际影响力。一个权重的梯度贡献高,意味着损失函数对其变化极为敏感。即使该权重的绝对数值(范数)很小,也丝毫不影响其作为模型决策逻辑核心枢纽的地位。它就像电路中的一个关键低阻值电阻,虽不起眼,却控制着主要电流的走向。因此,识别并保护这些权重,是理解模型工作机理和进行有效干预的基础。
实际应用:在模型解释性分析、微调或知识蒸馏中,应优先聚焦于这些高梯度贡献的“实际核心权重”。对其进行有监督的微调,能高效地引导模型行为;在对抗攻击或鲁棒性分析中,这些权重也是防御或攻击的焦点,因为扰动它们对模型输出的改变效率最高。
3.6.2 模型训练优化
核心机制:在训练过程中,实时监控各层或各权重组的梯度贡献(如梯度范数的变化),可以洞察训练动态的稳定性。如果某些权重的梯度贡献出现剧烈、无序的波动,这是一个明确的危险信号。它表明优化过程在该参数空间区域“振荡”或“徘徊”,学习率可能设置过高,导致权重更新步幅不稳定,无法平滑收敛至最优解附近。
实际应用:梯度贡献的波动性是诊断训练健康度的听诊器。当检测到异常波动时,开发者可以及时采取干预措施,例如降低全局或层特异性学习率、引入或增强梯度裁剪、或调整优化器参数。这有助于稳定训练,避免发散或陷入不良的局部最优点,确保模型稳健收敛。
3.6.3 权重裁剪验证
核心机制:基于梯度贡献的权重重要性评估,为模型剪枝提供了最直接的依据。梯度贡献持续很低的权重,意味着在当前的输入数据分布和任务目标下,其存在与否对最终损失的改变微乎其微。从信息论角度看,这类权重所承载的“有效信息”或“决策贡献”极少,属于模型的冗余部分。
实际应用:在进行非结构化剪枝(将个别权重置零)时,优先裁剪梯度贡献最低的权重,可以在最大程度上保留模型原有性能。这实现了剪枝效果(压缩率、加速比)与精度保持之间的最优权衡。该方法比单纯依赖权重数值大小(范数)的剪枝策略更科学,因为它基于权重的“实际效用”而非“表象规模”做出决策,通常能获得更高的压缩后模型精度。
3.7 计算示例
import numpy as np
import torch
def compute_gradient_norms_example():
"""
梯度范数计算示例:L1范数与L2范数
"""
print("=" * 70)
print("梯度范数计算示例:L1范数 vs L2范数")
print("=" * 70)
# ===================== 示例1:简单人工梯度向量 =====================
print("\n1. 简单人工梯度向量示例")
print("-" * 40)
# 创建一个简单的梯度向量
gradient_vec = np.array([1.2, -0.5, 3.1, -2.0, 0.0, 0.3])
n_weights = len(gradient_vec)
print(f"梯度向量 ∇w: {gradient_vec}")
print(f"梯度维度: {n_weights}")
# 计算 L1 范数
l1_norm = np.sum(np.abs(gradient_vec))
print(f"\nL1 范数计算:")
print(f" ||∇w||₁ = |1.2| + |-0.5| + |3.1| + |-2.0| + |0.0| + |0.3|")
print(f" = {abs(1.2)} + {abs(-0.5)} + {abs(3.1)} + {abs(-2.0)} + {abs(0.0)} + {abs(0.3)}")
print(f" = {l1_norm:.4f}")
# 计算 L2 范数
l2_norm = np.linalg.norm(gradient_vec)
l2_norm_squared = np.sum(gradient_vec ** 2)
print(f"\nL2 范数计算:")
print(f" ||∇w||₂² = (1.2)² + (-0.5)² + (3.1)² + (-2.0)² + (0.0)² + (0.3)²")
print(f" = {1.2**2:.4f} + {(-0.5)**2:.4f} + {3.1**2:.4f} + {(-2.0)**2:.4f} + {0.0**2:.4f} + {0.3**2:.4f}")
print(f" = {l2_norm_squared:.4f}")
print(f" ||∇w||₂ = √{l2_norm_squared:.4f} = {l2_norm:.4f}")
# ===================== 示例2:实际神经网络梯度 =====================
print("\n\n2. 实际神经网络梯度示例")
print("-" * 40)
# 模拟一个简单的神经网络层
# 假设我们有一个全连接层,输入维度5,输出维度3
input_dim = 5
output_dim = 3
batch_size = 4
# 随机生成权重矩阵和梯度矩阵
np.random.seed(42)
weight_matrix = np.random.randn(output_dim, input_dim) * 0.1
gradient_matrix = np.random.randn(output_dim, input_dim) * 0.5
print(f"权重矩阵 W 形状: {weight_matrix.shape} ({output_dim}×{input_dim})")
print(f"梯度矩阵 ∇W 形状: {gradient_matrix.shape} ({output_dim}×{input_dim})")
# 计算整个梯度矩阵的 L1 和 L2 范数
gradient_l1 = np.sum(np.abs(gradient_matrix))
gradient_l2 = np.linalg.norm(gradient_matrix)
print(f"\n梯度矩阵的范数:")
print(f" L1范数 (||∇W||₁): {gradient_l1:.6f}")
print(f" L2范数 (||∇W||₂): {gradient_l2:.6f}")
print(f" L2范数平方 (||∇W||₂²): {gradient_l2**2:.6f}")
# ===================== 示例3:比较不同分布的梯度 =====================
print("\n\n3. 不同梯度分布对比")
print("-" * 40)
# 情况1:均匀小梯度
small_gradients = np.random.randn(10) * 0.1
# 情况2:包含几个大梯度的混合分布
mixed_gradients = np.random.randn(10) * 0.1
mixed_gradients[0] = 2.5 # 一个大梯度
mixed_gradients[5] = -1.8 # 另一个大梯度
# 情况3:梯度爆炸情况
exploding_gradients = np.random.randn(10) * 5.0
gradients_list = [
("均匀小梯度", small_gradients),
("混合梯度(含大值)", mixed_gradients),
("梯度爆炸", exploding_gradients)
]
print(f"{'梯度类型':<20} {'L1范数':<15} {'L2范数':<15} {'L2/L1比值':<15}")
print("-" * 65)
for name, grad in gradients_list:
l1 = np.sum(np.abs(grad))
l2 = np.linalg.norm(grad)
ratio = l2 / l1 if l1 > 0 else 0
print(f"{name:<20} {l1:<15.4f} {l2:<15.4f} {ratio:<15.4f}")
return gradient_vec, l1_norm, l2_norm
# 运行示例
if __name__ == "__main__":
compute_gradient_norms_example()输出结果:
==================================================================== 梯度范数计算示例:L1范数 vs L2范数 ==================================================================== 1. 简单人工梯度向量示例 ---------------------------------------- 梯度向量 ∇w: [ 1.2 -0.5 3.1 -2. 0. 0.3] 梯度维度: 6 L1 范数计算: ||∇w||₁ = |1.2| + |-0.5| + |3.1| + |-2.0| + |0.0| + |0.3| = 1.2 + 0.5 + 3.1 + 2.0 + 0.0 + 0.3 = 7.1000 L2 范数计算: ||∇w||₂² = (1.2)² + (-0.5)² + (3.1)² + (-2.0)² + (0.0)² + (0.3)² = 1.4400 + 0.2500 + 9.6100 + 4.0000 + 0.0000 + 0.0900 = 15.3900 ||∇w||₂ = √15.3900 = 3.9230 2. 实际神经网络梯度示例 ---------------------------------------- 权重矩阵 W 形状: (3, 5) (3×5) 梯度矩阵 ∇W 形状: (3, 5) (3×5) 梯度矩阵的范数: L1范数 (||∇W||₁): 5.233862 L2范数 (||∇W||₂): 1.636602 L2范数平方 (||∇W||₂²): 2.678467 3. 不同梯度分布对比 ---------------------------------------- 梯度类型 L1范数 L2范数 L2/L1比值 ----------------------------------------------------------------- 均匀小梯度 0.9262 0.3573 0.3858 混合梯度(含大值) 4.8691 3.0917 0.6350 梯度爆炸 32.0764 11.0423 0.3442
关键逻辑总结:
- L1范数(梯度贡献L1)的特点:
- 1. 计算方式:所有梯度绝对值的简单求和
- 2. 敏感性:对异常值(大梯度)相对不敏感
- 3. 解释:衡量梯度的"总体活跃度"或"总贡献量"
- L2范数(梯度贡献L2)的特点:
- 1. 计算方式:梯度平方和的平方根
- 2. 敏感性:对异常值(大梯度)非常敏感(平方放大效应)
- 3. 解释:衡量梯度的"能量强度"或"峰值影响"
- 两者对比:
- L1范数 ≈ "总量"指标,更稳健
- L2范数 ≈ "峰值"指标,对异常更敏感
- L2/L1比值可以反映梯度分布的集中程度:
- 比值接近1 → 梯度集中在少数维度
- 比值接近0 → 梯度均匀分布在许多维度
梯度分布对比分析:
- 均匀小梯度
- L1范数 (0.9262):相对较小,说明梯度绝对值总和不大
- L2范数 (0.3573):明显小于L1范数,平方和开方后进一步缩小
- L2/L1比值 (0.3858):比值较低(<0.5),表明:
- 梯度分布相对均匀
- 没有特别突出的"极端"梯度值
- 各维度的梯度贡献相对平衡
- 混合梯度(含大值)
- L1范数 (4.8691):比均匀小梯度大5倍多,梯度总体活跃度较高
- L2范数 (3.0917):比均匀小梯度大近9倍,平方放大了大梯度的影响
- L2/L1比值 (0.6350):比值最高,表明:
- 梯度分布极不均匀
- 少数大梯度值对L2范数贡献极大
- 存在明显的梯度"热点"
- 梯度爆炸
- L1范数 (32.0764):非常大,是均匀小梯度的35倍
- L2范数 (11.0423):非常大,但相对L1的增长倍数较小
- L2/L1比值 (0.3442):比值最低,表明:
- 梯度值普遍很大,但相对均匀
- 所有维度的梯度都贡献显著
- 没有特别突出的"峰值",而是整体"高原"
L2/L1比值的解读:
比值范围 | 梯度分布特征 | 训练状态评估 | 建议措施 |
|---|---|---|---|
< 0.4 | 梯度分布均匀 | 通常健康 | 监控即可 |
0.4-0.6 | 中等集中度 | 需关注 | 检查特定层,考虑调整学习率 |
> 0.6 | 高度集中 | 可能有问题 | 实施梯度裁剪,检查网络异常 |
> 0.8 | 极度集中 | 严重问题 | 立即停止,诊断网络问题 |
三、敏感性分析流程图
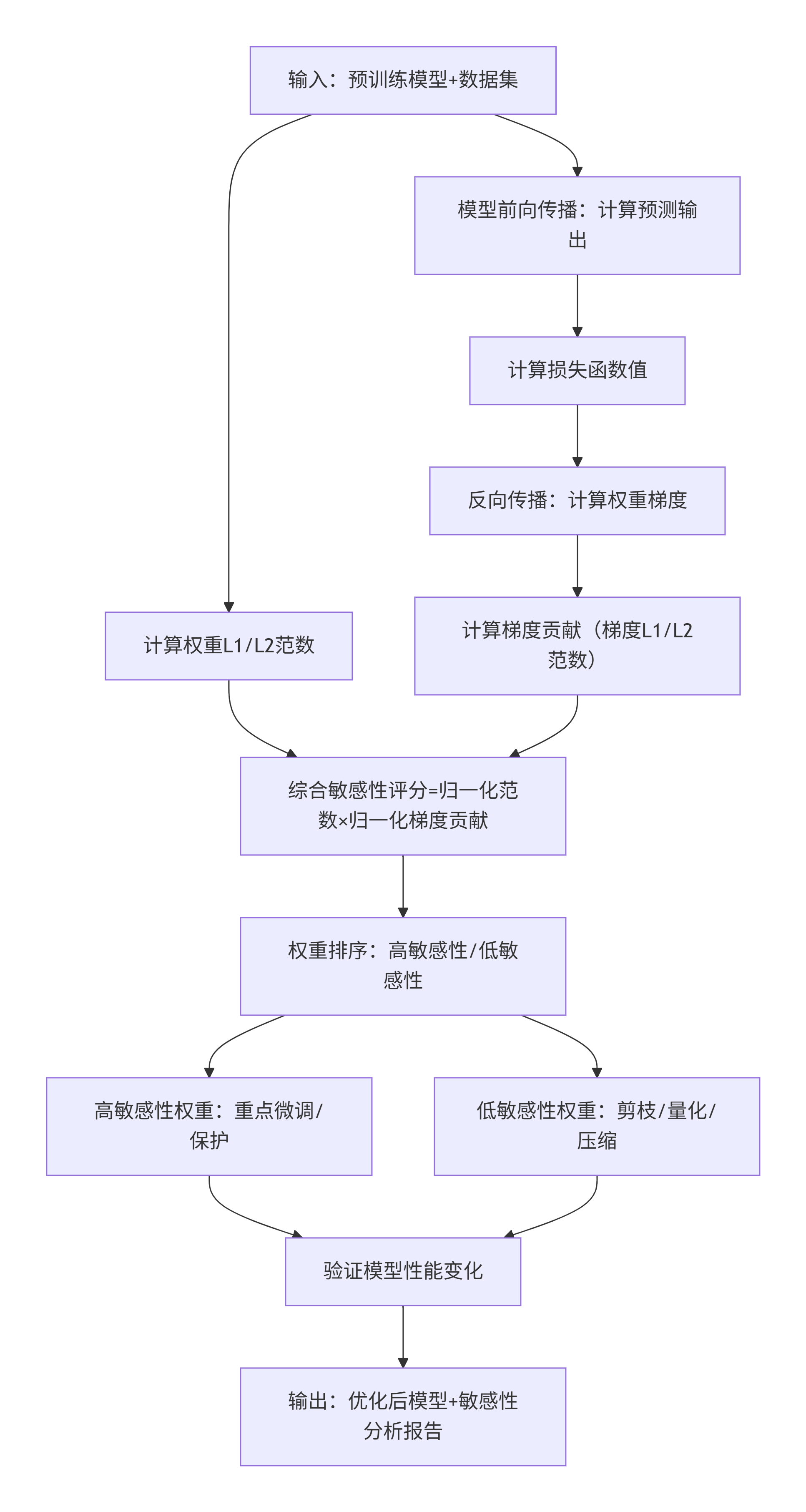
流程说明:
第一步:收集输入与双线分析
- 输入:一个现成的模型和一份代表目标任务的样本数据。
- 分析:
- 静态分析:直接计算所有权重的“规模”(L1/L2范数),看看哪些权重本身数值大。
- 动态分析:用数据跑一遍模型,通过反向传播计算每个权重的“梯度”,看看哪些权重对当前任务结果的影响大。
第二步:综合评估与排序
- 打分:将每个权重的“静态规模”和“动态影响”两项指标结合起来,计算一个综合敏感性评分。得分高的权重对模型性能至关重要。
- 分类:根据评分将所有权重分为两类:高敏感性权重和低敏感性权重。
第三步:针对性优化处理
- 对高敏感性权重:它们是模型的“核心骨干”,需要重点保护和精细微调,避免粗暴修改导致模型性能崩溃。
- 对低敏感性权重:它们是模型的“冗余部分”,可以进行大胆精简,如剪枝(删除)、量化(降低精度),以压缩模型体积、提升速度。
第四步:验证与输出
- 验证:将优化后的模型在数据上测试,确认性能没有明显下降。
- 输出:最终得到一个更轻、更快、且性能有保障的优化模型,以及一份记录了哪些权重重要、如何处理的分析报告。
四、梯度范数的逻辑与意义
import numpy as np
def gradient_norms_explanation():
"""
梯度范数的详细解释和逻辑说明
"""
print("\n" + "=" * 70)
print("梯度范数的逻辑与数学意义")
print("=" * 70)
# 创建一个示例梯度向量
gradient = np.array([1.0, -2.0, 0.5, 3.0, -0.1])
print(f"\n示例梯度向量: {gradient}")
# 计算各种统计量
abs_grad = np.abs(gradient)
squared_grad = gradient ** 2
print(f"\n梯度绝对值: {abs_grad}")
print(f"梯度平方值: {squared_grad}")
# L1范数计算
l1_norm = np.sum(abs_grad)
print(f"\n1. 梯度的L1范数(梯度贡献L1):")
print(f" ||∇w||₁ = Σ|∂L/∂wᵢ| = {l1_norm:.4f}")
print(f" 逻辑解释: 所有梯度绝对值的总和,反映梯度的'总活跃度'")
print(f" 特点: 对异常值较不敏感,衡量梯度的总体规模")
# L2范数计算
l2_norm = np.linalg.norm(gradient)
print(f"\n2. 梯度的L2范数(梯度贡献L2):")
print(f" ||∇w||₂ = √(Σ(∂L/∂wᵢ)²) = {l2_norm:.4f}")
print(f" 逻辑解释: 梯度平方和的平方根,反映梯度的'能量强度'")
print(f" 特点: 对大梯度值更加敏感(平方放大了大值的影响)")
# 范数比较
print(f"\n3. L1范数与L2范数比较:")
print(f" L1范数: {l1_norm:.4f}")
print(f" L2范数: {l2_norm:.4f}")
print(f" 比值 L2/L1: {l2_norm/l1_norm:.4f}")
# 可视化说明
print(f"\n4. 范数差异的直观理解:")
print(f" 假设有两个梯度向量:")
print(f" ∇w₁ = [1, 1, 1, 1] → L1=4.0, L2=2.0")
print(f" ∇w₂ = [2, 0, 0, 0] → L1=2.0, L2=2.0")
print(f" 注意: L2范数相同,但L1范数不同!")
print(f" 这说明L2范数更关注'峰值',L1范数更关注'总量'")
return l1_norm, l2_norm
# 运行解释示例
if __name__ == "__main__":
gradient_norms_explanation()====================================================================== 梯度范数的逻辑与数学意义 ======================================================================
示例梯度向量: [ 1. -2. 0.5 3. -0.1]
梯度绝对值: [1. 2. 0.5 3. 0.1] 梯度平方值: [1. 4. 0.25 9. 0.01]
1. 梯度的L1范数(梯度贡献L1): ||∇w||₁ = Σ|∂L/∂wᵢ| = 6.6000 逻辑解释: 所有梯度绝对值的总和,反映梯度的'总活跃度' 特点: 对异常值较不敏感,衡量梯度的总体规模
2. 梯度的L2范数(梯度贡献L2): ||∇w||₂ = √(Σ(∂L/∂wᵢ)²) = 3.7762 逻辑解释: 梯度平方和的平方根,反映梯度的'能量强度' 特点: 对大梯度值更加敏感(平方放大了大值的影响)
3. L1范数与L2范数比较: L1范数: 6.6000 L2范数: 3.7762 比值 L2/L1: 0.5722
4. 范数差异的直观理解: 假设有两个梯度向量: ∇w₁ = [1, 1, 1, 1] → L1=4.0, L2=2.0 ∇w₂ = [2, 0, 0, 0] → L1=2.0, L2=2.0 注意: L2范数相同,但L1范数不同! 这说明L2范数更关注'峰值',L1范数更关注'总量'
五、梯度监控与诊断
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体(避免乱码)
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
class GradientMonitor:
"""
梯度监控器:实时监控梯度范数,诊断训练问题
"""
def __init__(self, model_name="Untitled Model"):
self.model_name = model_name
self.l1_history = []
self.l2_history = []
self.max_gradient_history = []
def log_gradients(self, gradients):
"""
记录梯度并计算范数
参数:
gradients: dict,包含各层梯度 {layer_name: gradient_tensor}
"""
total_l1 = 0
total_l2_squared = 0
max_grad = 0
print(f"\n[梯度监控] {self.model_name}")
print("-" * 50)
for layer_name, grad in gradients.items():
if grad is not None:
# 转换为numpy数组(如果是PyTorch或TensorFlow张量)
if hasattr(grad, 'numpy'):
grad_np = grad.numpy()
elif hasattr(grad, 'detach'):
grad_np = grad.detach().numpy()
else:
grad_np = np.array(grad)
layer_l1 = np.sum(np.abs(grad_np))
layer_l2 = np.linalg.norm(grad_np)
layer_max = np.max(np.abs(grad_np))
total_l1 += layer_l1
total_l2_squared += layer_l2 ** 2
max_grad = max(max_grad, layer_max)
print(f"{layer_name:<20} L1:{layer_l1:10.4f} L2:{layer_l2:10.4f} Max:{layer_max:8.4f}")
total_l2 = np.sqrt(total_l2_squared)
# 记录历史
self.l1_history.append(total_l1)
self.l2_history.append(total_l2)
self.max_gradient_history.append(max_grad)
print(f"{'总计':<20} L1:{total_l1:10.4f} L2:{total_l2:10.4f} Max:{max_grad:8.4f}")
# 诊断建议
self._diagnose(total_l1, total_l2, max_grad)
return total_l1, total_l2
def _diagnose(self, l1_norm, l2_norm, max_grad):
"""根据梯度范数提供诊断建议"""
print("\n[诊断建议]")
# 梯度爆炸检测
if max_grad > 10.0:
print(" ⚠️ 检测到梯度爆炸!最大梯度值: {:.4f}".format(max_grad))
print(" 建议: 使用梯度裁剪(gradient clipping),降低学习率")
# 梯度消失检测
elif max_grad < 1e-6:
print(" ⚠️ 检测到梯度消失!最大梯度值: {:.8f}".format(max_grad))
print(" 建议: 检查激活函数,尝试使用ReLU,调整初始化方法")
# L1/L2范数比值分析
if l1_norm > 0:
ratio = l2_norm / l1_norm
print(f" L2/L1比值: {ratio:.4f}")
if ratio > 0.8:
print(" 梯度分布: 相对集中(少数大梯度主导)")
elif ratio < 0.3:
print(" 梯度分布: 相对分散(许多小梯度贡献)")
else:
print(" 梯度分布: 中等分散")
# 历史趋势分析
if len(self.l1_history) > 10:
recent_l1 = np.mean(self.l1_history[-10:])
early_l1 = np.mean(self.l1_history[:10])
if recent_l1 < early_l1 * 0.1:
print(" 📉 梯度规模持续下降,可能接近收敛")
elif recent_l1 > early_l1 * 10:
print(" 📈 梯度规模持续上升,需警惕不稳定")
def plot_history(self):
"""绘制梯度范数历史"""
try:
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
# L1范数历史
axes[0].plot(self.l1_history, 'b-', linewidth=2)
axes[0].set_title(f'{self.model_name} - 梯度L1范数历史')
axes[0].set_xlabel('迭代步')
axes[0].set_ylabel('L1范数')
axes[0].grid(True, alpha=0.3)
# L2范数历史
axes[1].plot(self.l2_history, 'r-', linewidth=2)
axes[1].set_title(f'{self.model_name} - 梯度L2范数历史')
axes[1].set_xlabel('迭代步')
axes[1].set_ylabel('L2范数')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
except ImportError:
print("需要matplotlib库来绘制图表")
# 使用示例
if __name__ == "__main__":
# 模拟一些梯度数据
monitor = GradientMonitor("示例模型")
# 模拟5个训练步骤
for step in range(5):
gradients = {
"conv1.weight": np.random.randn(16, 3, 3, 3) * (0.5 if step < 3 else 0.1),
"conv1.bias": np.random.randn(16) * (0.3 if step < 3 else 0.05),
"fc.weight": np.random.randn(10, 64) * (0.8 if step < 3 else 0.2),
"fc.bias": np.random.randn(10) * (0.2 if step < 3 else 0.05),
}
print(f"\n步骤 {step + 1}:")
monitor.log_gradients(gradients)
# 绘制历史图表
monitor.plot_history()输出过程:
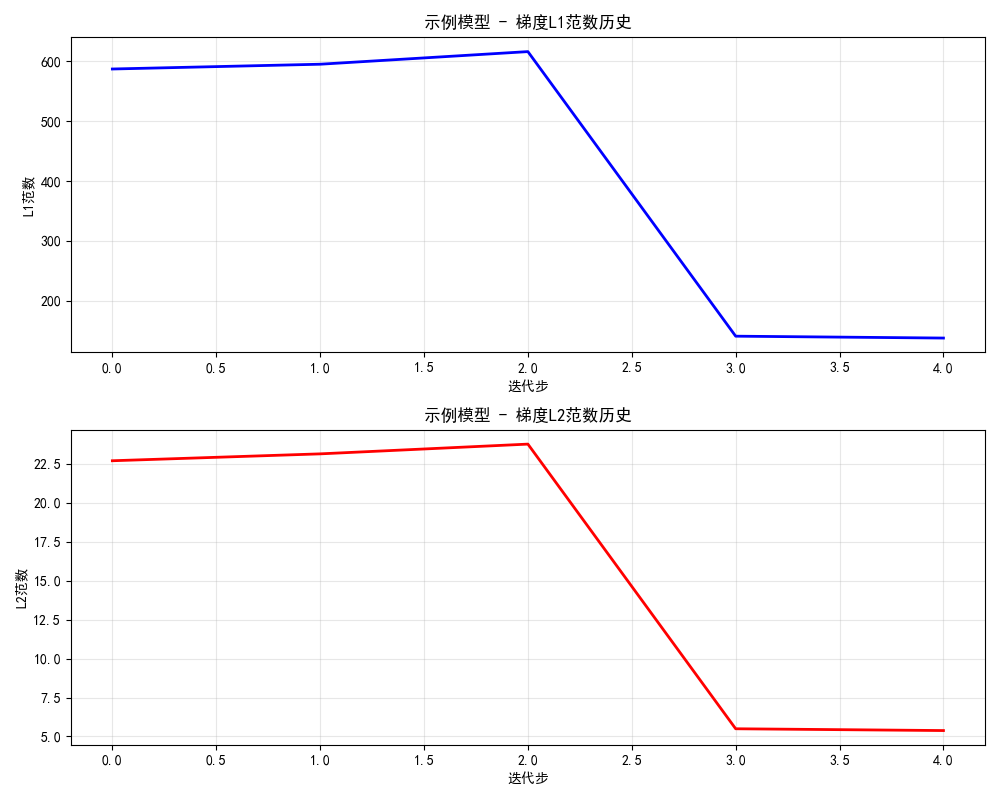
步骤 1: [梯度监控] 示例模型 -------------------------------------------------- conv1.weight L1: 179.3642 L2: 10.8387 Max: 1.5534 conv1.bias L1: 3.8408 L2: 1.1438 Max: 0.5459 fc.weight L1: 393.2635 L2: 19.6398 Max: 2.6666 fc.bias L1: 1.7399 L2: 0.6551 Max: 0.3336 总计 L1: 578.2084 L2: 22.4708 Max: 2.6666 [诊断建议] L2/L1比值: 0.0389 梯度分布: 相对分散(许多小梯度贡献) 步骤 2: [梯度监控] 示例模型 -------------------------------------------------- conv1.weight L1: 159.8652 L2: 9.6716 Max: 1.5052 conv1.bias L1: 3.9879 L2: 1.2251 Max: 0.5508 fc.weight L1: 404.6675 L2: 20.0605 Max: 3.0259 fc.bias L1: 1.3430 L2: 0.5700 Max: 0.3670 总计 L1: 569.8636 L2: 22.3112 Max: 3.0259 [诊断建议] L2/L1比值: 0.0392 梯度分布: 相对分散(许多小梯度贡献) 步骤 3: [梯度监控] 示例模型 -------------------------------------------------- conv1.weight L1: 176.2599 L2: 10.4789 Max: 1.3751 conv1.bias L1: 3.2064 L2: 1.0791 Max: 0.6065 fc.weight L1: 429.5635 L2: 21.3092 Max: 2.8286 fc.bias L1: 1.3389 L2: 0.5569 Max: 0.3806 总计 L1: 610.3688 L2: 23.7774 Max: 2.8286 [诊断建议] L2/L1比值: 0.0390 梯度分布: 相对分散(许多小梯度贡献) 步骤 4: [梯度监控] 示例模型 -------------------------------------------------- conv1.weight L1: 35.6000 L2: 2.1478 Max: 0.2757 conv1.bias L1: 0.6179 L2: 0.1825 Max: 0.0862 fc.weight L1: 103.3631 L2: 5.2028 Max: 0.7149 fc.bias L1: 0.3729 L2: 0.1622 Max: 0.1356 总计 L1: 139.9539 L2: 5.6340 Max: 0.7149 [诊断建议] L2/L1比值: 0.0403 梯度分布: 相对分散(许多小梯度贡献) 步骤 5: [梯度监控] 示例模型 -------------------------------------------------- conv1.weight L1: 34.7091 L2: 2.0815 Max: 0.3000 conv1.bias L1: 0.7693 L2: 0.2062 Max: 0.0894 fc.weight L1: 105.3489 L2: 5.2069 Max: 0.6514 fc.bias L1: 0.2106 L2: 0.0824 Max: 0.0531 总计 L1: 141.0380 L2: 5.6119 Max: 0.6514 [诊断建议] L2/L1比值: 0.0398 梯度分布: 相对分散(许多小梯度贡献)
结果图示:
六、示例:L1与L2范数、梯度贡献计算
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 设备设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示
# 1. 构造模拟权重(模拟模型某一层的权重向量/矩阵)
# 模拟权重向量(长度100,符合正态分布)
weight_vector = torch.randn(100).to(device)
# 模拟权重矩阵(10×20,模拟全连接层权重)
weight_matrix = torch.randn(10, 20).to(device)
# 2. 定义范数计算函数(文本公式对应实现)
def calculate_l1_norm(weights):
"""计算L1范数:所有元素绝对值求和"""
return torch.sum(torch.abs(weights)).item()
def calculate_l2_norm(weights):
"""计算L2范数:所有元素平方和开平方根"""
return torch.sqrt(torch.sum(torch.square(weights))).item()
# 3. 计算范数值
# 向量范数
vec_l1 = calculate_l1_norm(weight_vector)
vec_l2 = calculate_l2_norm(weight_vector)
# 矩阵范数
mat_l1 = calculate_l1_norm(weight_matrix)
mat_l2 = calculate_l2_norm(weight_matrix)
# 4. 可视化:对比向量/矩阵的L1/L2范数
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 子图1:范数值对比柱状图
categories = ['向量L1', '向量L2', '矩阵L1', '矩阵L2']
values = [vec_l1, vec_l2, mat_l1, mat_l2]
ax1.bar(categories, values, color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'])
ax1.set_title('权重向量/矩阵的L1/L2范数值', fontsize=12)
ax1.set_ylabel('范数值', fontsize=10)
# 标注数值
for i, v in enumerate(values):
ax1.text(i, v + 0.5, f'{v:.2f}', ha='center', fontsize=9)
# 子图2:权重向量分布+范数标注
ax2.plot(weight_vector.cpu().numpy(), color='#1f77b4', label='权重向量元素')
ax2.axhline(y=0, color='black', linestyle='--', alpha=0.5)
ax2.set_title('权重向量分布(L1={:.2f}, L2={:.2f})'.format(vec_l1, vec_l2), fontsize=12)
ax2.set_xlabel('元素索引', fontsize=10)
ax2.set_ylabel('权重值', fontsize=10)
ax2.legend()
plt.tight_layout()
plt.savefig('l1_l2_norm_visual.png', dpi=300, bbox_inches='tight') # 保存图片
plt.show()
# 打印结果
print("===== L1/L2范数计算结果 =====")
print(f"权重向量L1范数(绝对值求和):{vec_l1:.2f}")
print(f"权重向量L2范数(平方和开根号):{vec_l2:.2f}")
print(f"权重矩阵L1范数(绝对值求和):{mat_l1:.2f}")
print(f"权重矩阵L2范数(平方和开根号):{mat_l2:.2f}")
# 1. 构造简易模型(模拟大模型单层)
class SimpleLayer(nn.Module):
def __init__(self):
super().__init__()
# 定义可训练权重(模拟核心权重)
self.linear = nn.Linear(10, 1).to(device) # 输入10维,输出1维
def forward(self, x):
return self.linear(x)
# 2. 初始化模型、损失函数、输入数据
model = SimpleLayer()
criterion = nn.MSELoss() # 均方误差损失(模拟分类/回归任务损失)
# 模拟输入数据(批次大小8,输入维度10)
input_data = torch.randn(8, 10).to(device)
# 模拟真实标签
target = torch.randn(8, 1).to(device)
# 3. 计算梯度(反向传播)
model.train()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
optimizer.zero_grad() # 清空梯度
# 前向传播
output = model(input_data)
# 计算损失
loss = criterion(output, target)
# 反向传播:计算权重梯度
loss.backward()
# 4. 提取权重和梯度,计算梯度贡献
# 提取线性层权重(shape: [1, 10])
weights = model.linear.weight.detach().cpu().numpy()[0]
# 提取权重梯度(shape: [1, 10])
grads = model.linear.weight.grad.detach().cpu().numpy()[0]
# 计算梯度贡献(文本公式实现)
grad_l1 = sum(abs(g) for g in grads) # 梯度L1贡献:绝对值求和
grad_l2 = np.sqrt(sum(g**2 for g in grads)) # 梯度L2贡献:平方和开根号
# 5. 可视化:权重vs梯度贡献
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 8))
# 子图1:权重值与梯度值对比
x = np.arange(len(weights))
width = 0.35
ax1.bar(x - width/2, weights, width, label='权重值', color='#1f77b4')
ax1.bar(x + width/2, grads, width, label='梯度值', color='#ff7f0e')
ax1.set_title('权重值与梯度值对比', fontsize=12)
ax1.set_xlabel('权重索引', fontsize=10)
ax1.set_ylabel('数值', fontsize=10)
ax1.legend()
ax1.grid(axis='y', alpha=0.3)
# 子图2:梯度贡献分布(L1/L2)
ax2.bar(['梯度L1贡献', '梯度L2贡献'], [grad_l1, grad_l2], color=['#2ca02c', '#d62728'])
ax2.set_title('梯度贡献值(L1={:.4f}, L2={:.4f})'.format(grad_l1, grad_l2), fontsize=12)
ax2.set_ylabel('贡献值', fontsize=10)
# 标注数值
for i, v in enumerate([grad_l1, grad_l2]):
ax2.text(i, v + 0.001, f'{v:.4f}', ha='center', fontsize=9)
plt.tight_layout()
plt.savefig('gradient_contribution_visual.png', dpi=300, bbox_inches='tight') # 保存图片
plt.show()
# 打印结果
print("\n===== 梯度贡献计算结果 =====")
print(f"梯度L1贡献(梯度绝对值求和):{grad_l1:.4f}")
print(f"梯度L2贡献(梯度平方和开根号):{grad_l2:.4f}")
print(f"注:梯度贡献越大,说明该权重对损失的影响越强")输出结果:
===== L1/L2范数计算结果 ===== 权重向量L1范数(绝对值求和):80.93 权重向量L2范数(平方和开根号):10.67 权重矩阵L1范数(绝对值求和):163.65 权重矩阵L2范数(平方和开根号):14.79
结果图示:
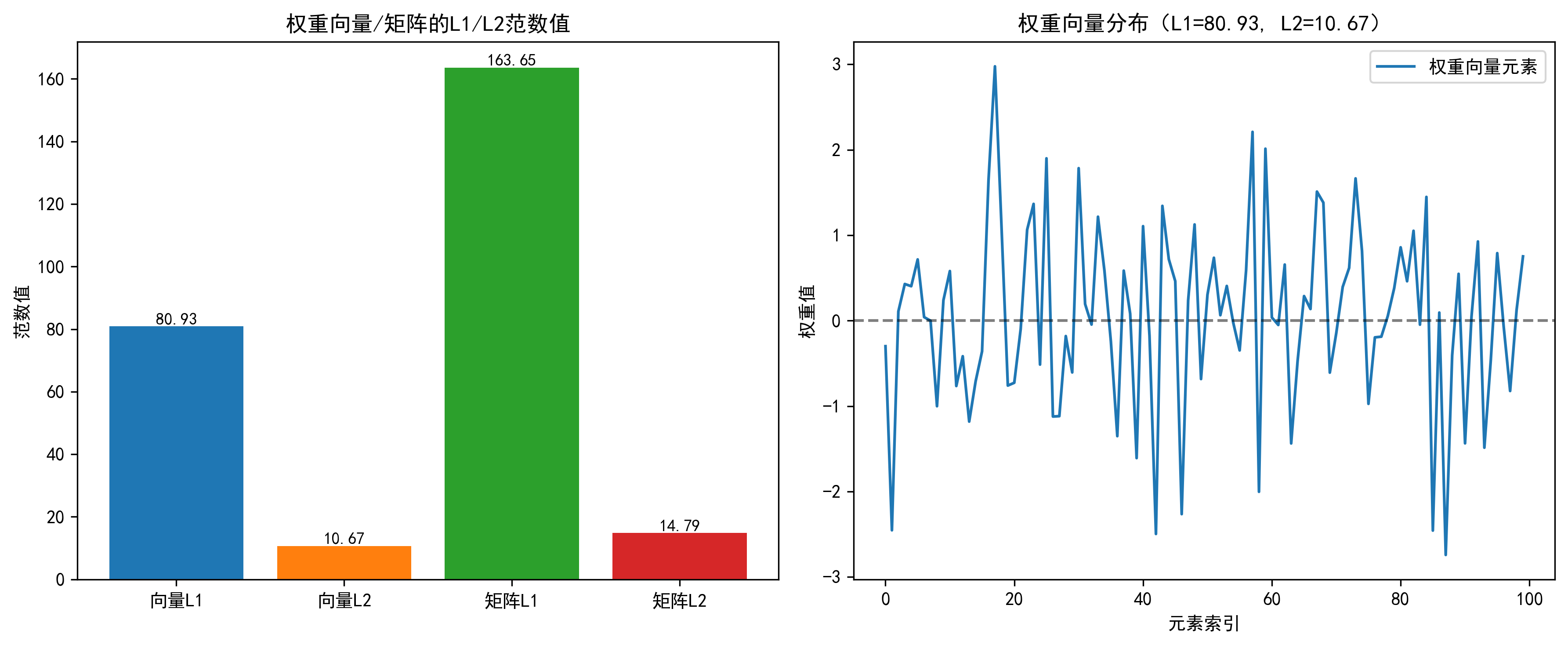
- 左图:柱状图清晰展示向量/矩阵的 L1、L2 范数值差异,L1 范数因 “绝对值求和” 数值远大于 L2 范数;
- 右图:展示权重向量的元素分布,标题标注该向量的 L1/L2 范数,直观关联 “权重分布” 与 “范数大小”。
===== 梯度贡献计算结果 ===== 梯度L1贡献(梯度绝对值求和):7.6737 梯度L2贡献(梯度平方和开根号):2.9658 注:梯度贡献越大,说明该权重对损失的影响越强
结果图示:
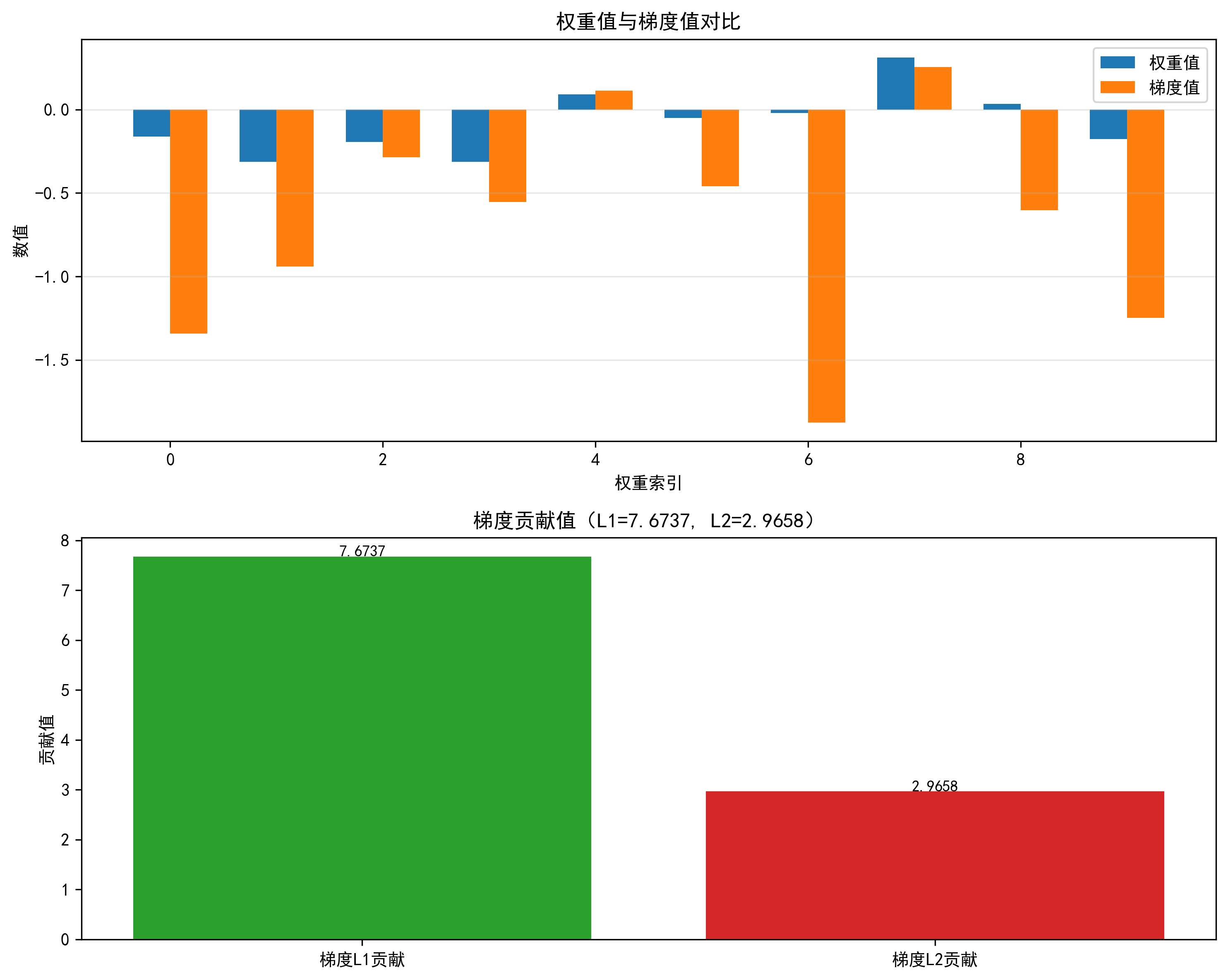
- 上图:对比每个权重的 “权重值” 和 “梯度值”,可直观看到:权重值大的元素,梯度值未必大(说明 “数值潜力”≠“实际贡献”);
- 下图:柱状图展示梯度 L1/L2 贡献的具体数值,体现 “梯度贡献” 是对所有梯度值的综合量化;
七、总结
大模型权重敏感性核心是衡量权重微小变化对模型输出或性能的影响程度,是模型优化与轻量化的关键依据。我们需掌握两大核心衡量工具:L1 范数,权重绝对值求和,适配稀疏筛选与 L2 范数,权重平方和开根号,控制整体规模,二者反映权重静态潜力;梯度贡献,即梯度的L1/L2 范数,则体现权重动态实际影响力,需结合前向传播与反向传播计算。
权重敏感性的核心价值在于模型轻量化,剪枝、量化低敏感性权重,在不损失精度的前提下,让模型能在手机、边缘设备上运行;从而训练效率提升,在只微调高敏感性权重,不用全量训练模型,节省算力和时间;同时进行故障排查,当模型性能突然下降时,可优先检查高敏感性权重是否出现异常。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号