TEF 2025 Ethernet for AI:400G/lane信号优化 & 448G测试方法 & CPC信道 & 可组合互连 (新思/是德/MTK/Lightmatter)

TEF 2025 Ethernet for AI:400G/lane信号优化 & 448G测试方法 & CPC信道 & 可组合互连 (新思/是德/MTK/Lightmatter)

光芯
发布于 2026-03-02 21:59:05
发布于 2026-03-02 21:59:05

本内容基于以太网联盟在2025年12月2-3日于美国举办的TEF 2025 Ethernet for AI峰会400G Electrical Signaling Panel专题演讲整理,本场专题Panel共包含4项技术分享,Synopsys、Keysight、联发科、Lightmatter等企业专家分别分享研究成果:Synopsys提出优化COM中最小可接受线性度修正的方案,解决PAM4/6/8调制的裕量损失问题;
Keysight展示448G信号生成与分析方案,指出PAM6尚需统一编码和测试模式;
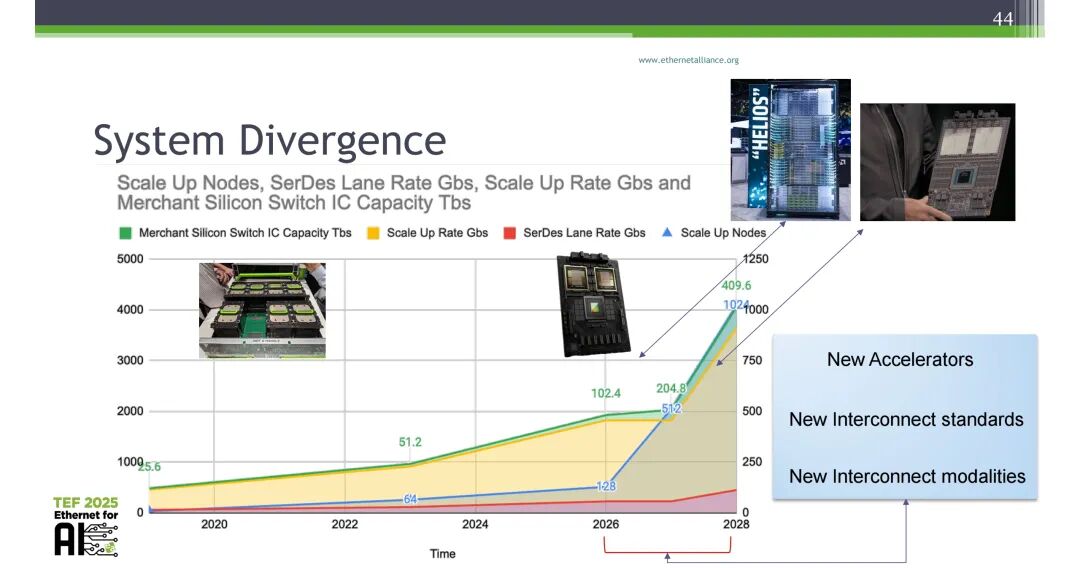
联发科实测CPC信道发现100G+带宽下PAM6表现略优于PAM4,带宽、抖动等是400G扩展关键;
Lightmatter提出封装边缘可组合互连架构,打造NG OAM多平面堆叠方案,实现400Gbs/lane AI系统互连的模块化、介质无关化与能效提升。
一、面向下一代以太网设计的COM增强方案:RLM敏感性问题优化

本部分内容由Synopsys首席架构师Ayal Shoval与Fellow John Stonick共同提出,核心针对400Gbps/lane以太网设计中,通道工作裕量(Channel Operating Margin, COM)对电平间隔失配率/线性度(Ratio Level Mismatch, RLM)的敏感性问题,提出了最小可接受线性度修正(derating factor)的方案。
1.1 核心问题概述
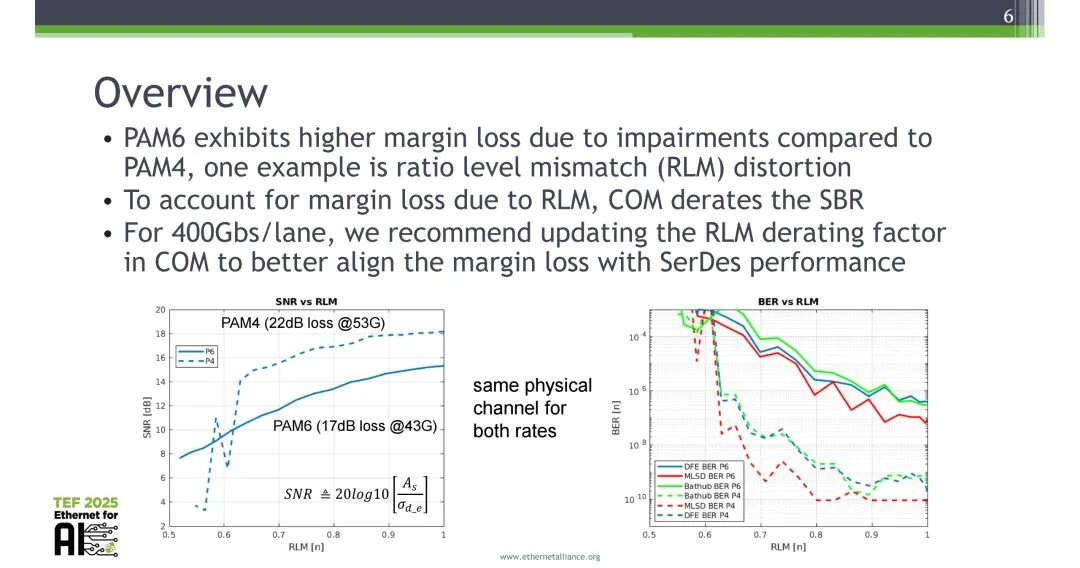
PAM6调制相比PAM4,在相同物理信道下受链路损伤影响会产生更高的裕量损失,RLM失真是核心影响因素之一。当前COM模型通过对单比特响应SBR进行降额来计入RLM的影响,但该方式与实际SerDes性能的匹配度不足,针对400Gbps/lane场景,需更新COM中的最小可接受线性度,以更精准地匹配RLM带来的裕量损失。
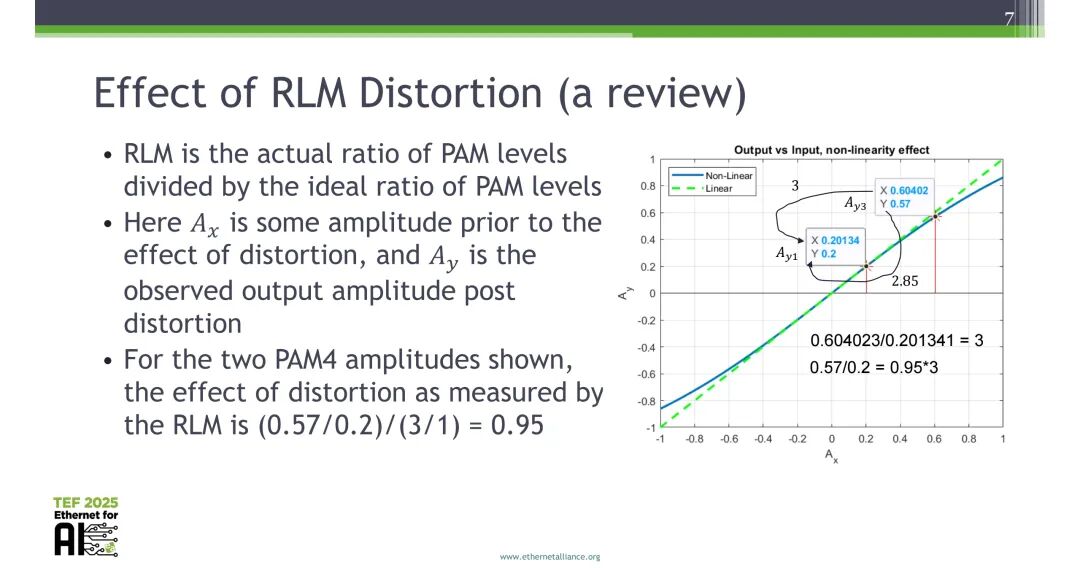

1.2 RLM失真的定义与影响
RLM定义为PAM信号的实际电平比与理想电平比的比值,其中A_x为失真前的信号幅度,A_y为失真后的观测输出幅度。以PAM4信号为例,理想内外电平比为3:1,若失真后内外电平比为2.85:1,对应的RLM为0.95。
RLM失真会直接劣化信号的信噪比(SNR)与误码率(BER),实测数据显示,相同物理信道下,PAM6信号的SNR与BER随RLM下降的劣化幅度显著高于PAM4。
1.3 现有COM的RLM降额机制缺陷
当前COM 4.12.0_beta1版本中,通过对SBR进行线性缩放来计入RLM影响,等效于将信号幅度直接按RLM数值进行降额,核心公式为A_y=RLM * A_x。该机制的核心缺陷是忽略了RLM失真对PAM信号外眼图与内眼图的影响存在显著差异,导致计算出的通道裕量偏于乐观。
1.4 精准RLM降额方案
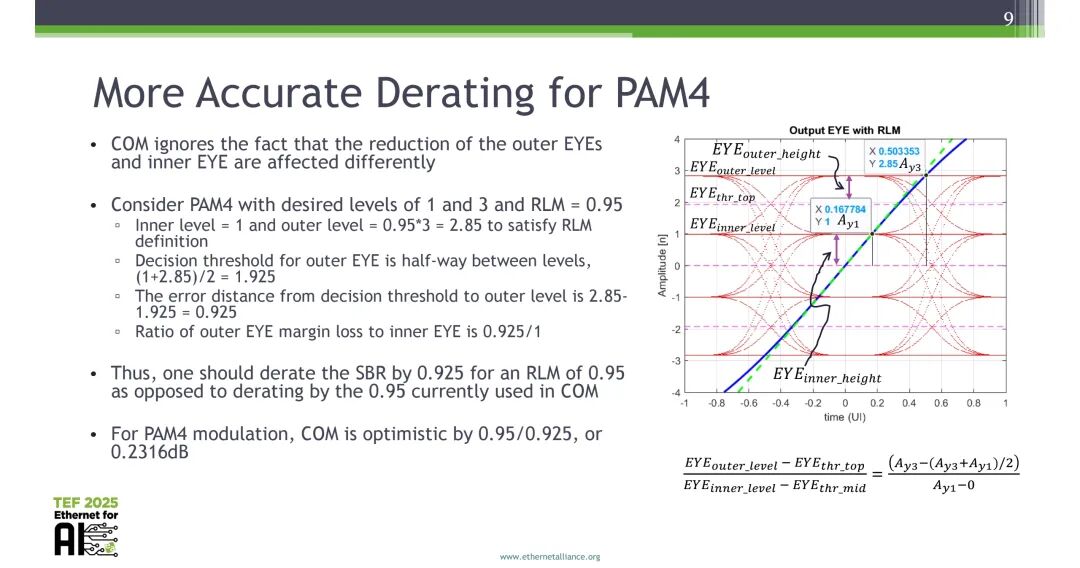
针对PAM4调制,以RLM=0.95为例,理想电平为1和3,满足RLM定义的实际电平为1和2.85,外眼图的决策阈值为(1+2.85)/2=1.925,决策阈值到外电平的误差距离为2.85-1.925=0.925,即外眼图裕量损失对应的实际最小可接受线性度为0.925,而非现有COM采用的0.95,现有方案对PAM4的裕量多计算了0.2316dB。
针对通用PAMm调制场景,可以推导得到通用最小可接受线性度计算公式,其中L=PAMm-1为PAMm信号的外电平,L-2为次低电平。
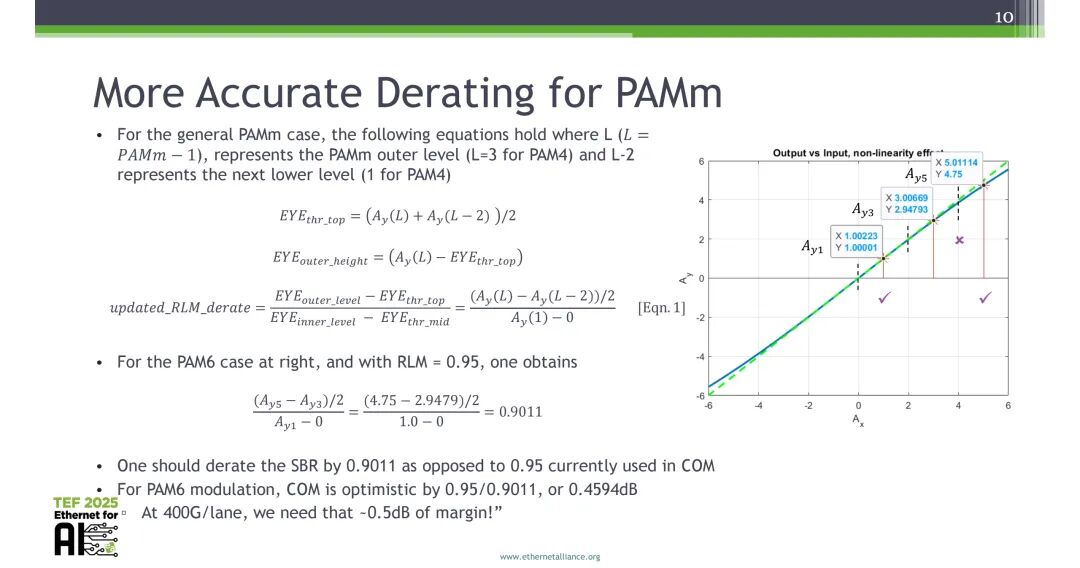
以RLM=0.95的PAM6信号为例,计算得到更新后的降额因子为0.9011,而非现有COM采用的0.95,现有方案对PAM6的裕量多计算了0.4594dB,而这部分约0.5dB的裕量对400G/lane设计至关重要。
1.5 基于tanh非线性模型的通用降额计算
针对高于PAM4的高阶调制,中间电平无法通过RLM定义直接确定,因此引入tanh非线性模型模拟发射机的输入输出关系,模型公式为:

通过最小均方误差(MMSE)迭代求解得到τ Ax的最优解,代入通用最小可接受线性度公式,即可得到任意PAM调制、任意RLM数值下的精准降额因子:

基于该方法,RLM=0.95时,不同调制阶数的COM对比如下:PAM4现有最小可接受线性度为0.95、更新后0.9250,相差0.2316dB;PAM6现有最小可接受线性度0.95、更新后为0.9011,相差0.4594dB;PAM8现有最小可接受线性度0.95、更新后为0.8894,相差0.5722dB,调制阶数越高,现有COM最小可接受线性度调整方案的收益越显著。
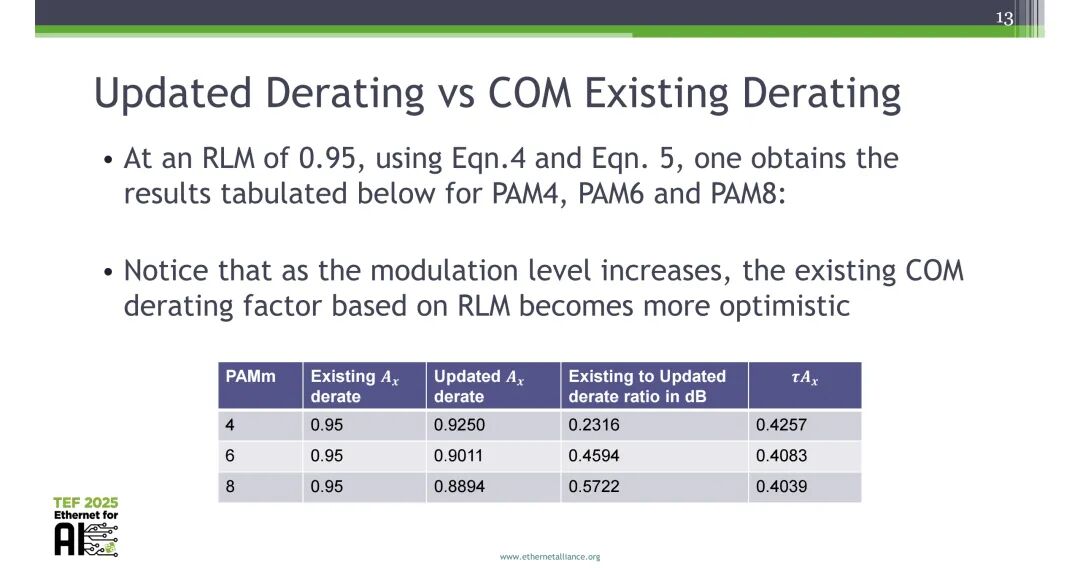
1.6 COM仿真验证与Matlab实现
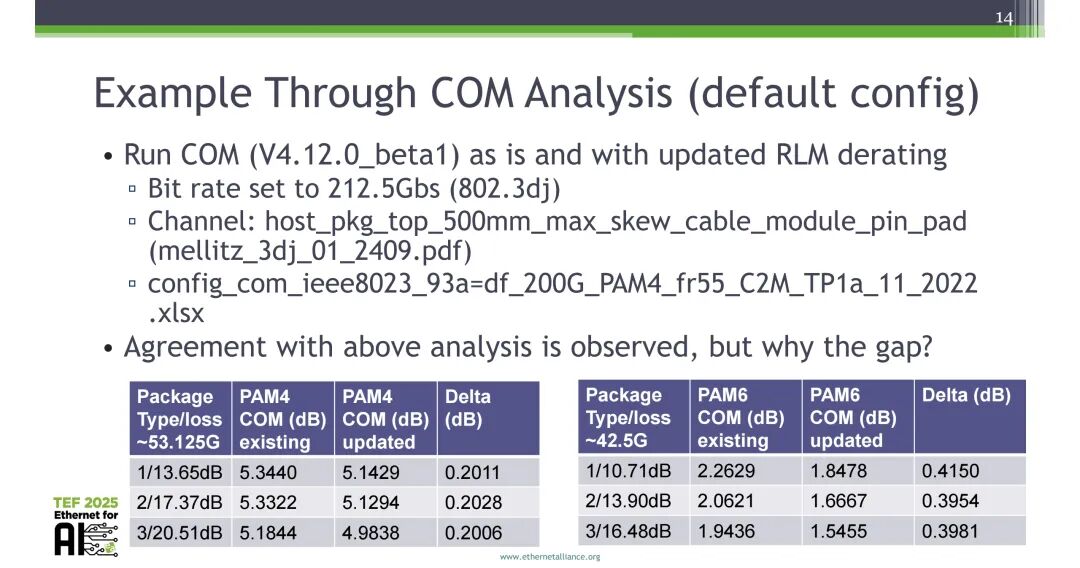
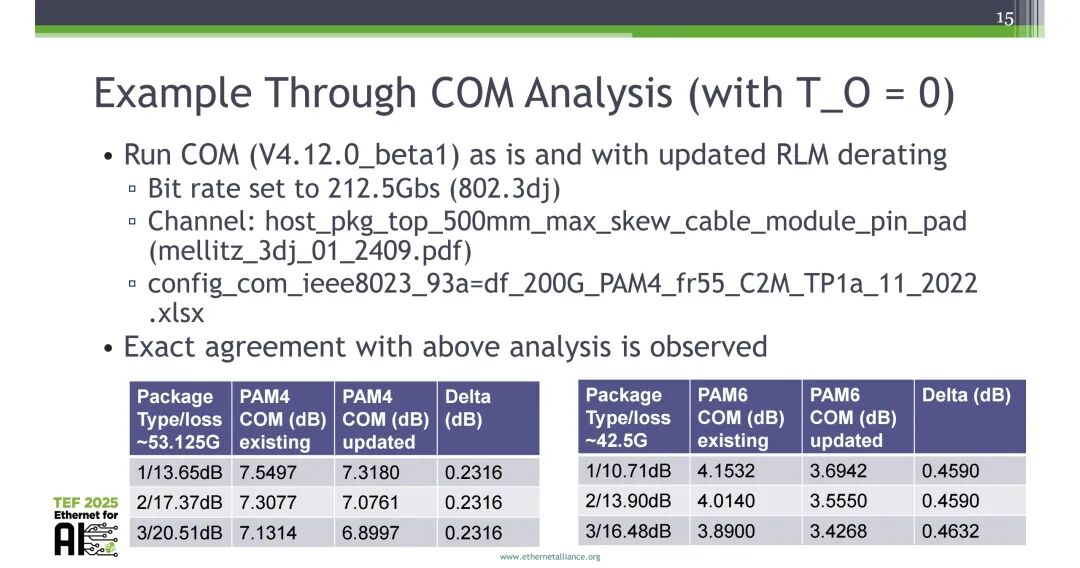
基于COM V4.12.0_beta1开展仿真验证,配置为212.5Gbps速率(802.3dj)、host_pkg_top_500mm_max_skew_cable_module_pin_pad信道、对应802.3dj的配置文件。结果显示,默认配置下,PAM4在不同损耗封装中,更新最小可接受线性度后的COM值与原方案差值约0.2dB,PAM6差值约0.4dB;在T_O=0的配置下,PAM4差值稳定为0.2316dB,PAM6差值稳定为0.4590dB,与理论计算结果完全吻合。
同时提供了更新后RLM降额的Matlab实现函数,输入为PAM调制阶数pamM与RLM数值,输出为修正后的最小可接受线性度,核心逻辑为通过fminsearch求解tanh模型的最优τ A_x,再代入通用降额公式完成计算。

二、基于先进测试测量方案的448G信号生成与分析技术演进

本部分内容由Keysight Technologies的Hadrien Louchet、Armands Ostrovskis、Fabio Pittala共同完成,核心明确了当前448G信号生成与分析的技术能力边界,以及PAM6标准化进程中待解决的核心问题。

2.1 448G信号生成技术
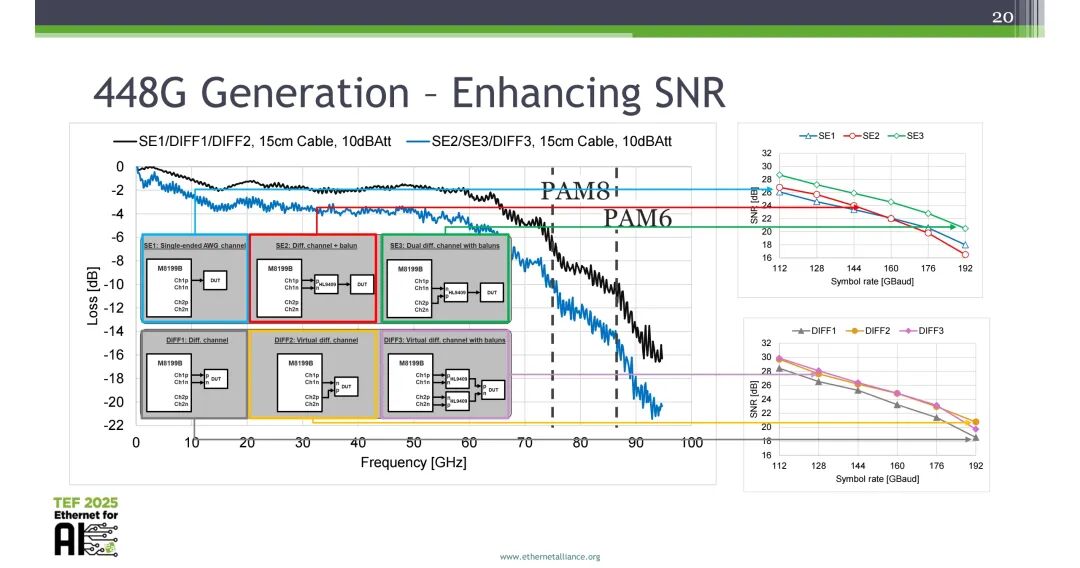
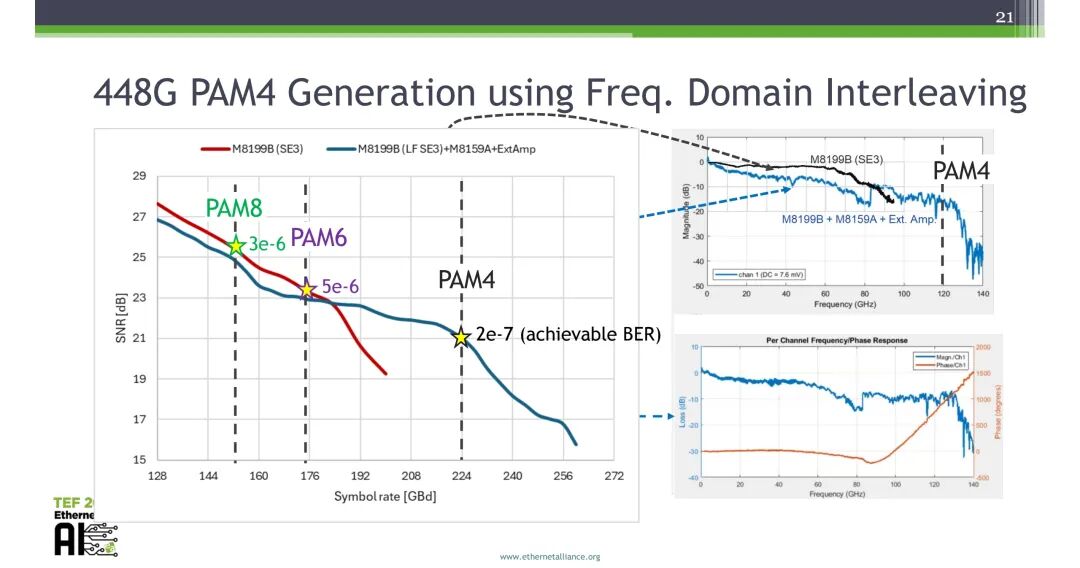
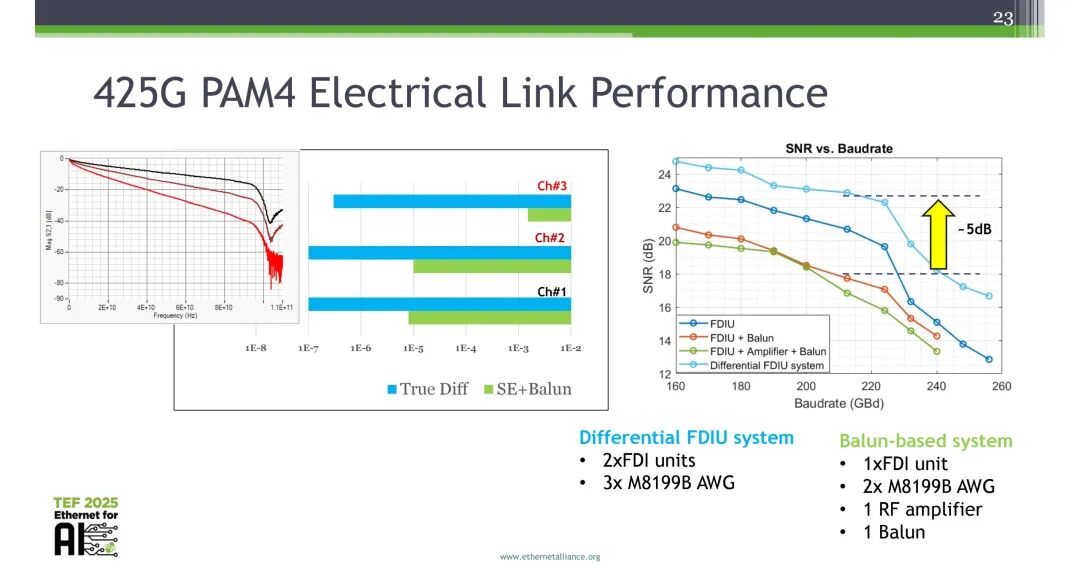
当前测试测量方案已可支撑448G信号的路径探索,核心围绕SNR提升开展优化。对比单端信道、差分+巴伦信道、双差分+巴伦信道三种方案,双差分+巴伦的SE3方案可实现最优的SNR性能,在相同符号率下,相比单端方案可实现显著的SNR提升。
基于M8199B任意波形发生器与M8159A频域交织单元(FDIU),通过频域交织技术实现了448G PAM4信号的生成,可实现亚奈奎斯特传输,结合DFE、MLSD均衡算法可完成信号检测,同时验证了FDIU+外部放大器+巴伦的方案可进一步提升SNR性能,相比纯FDIU方案可实现约5dB的SNR提升。
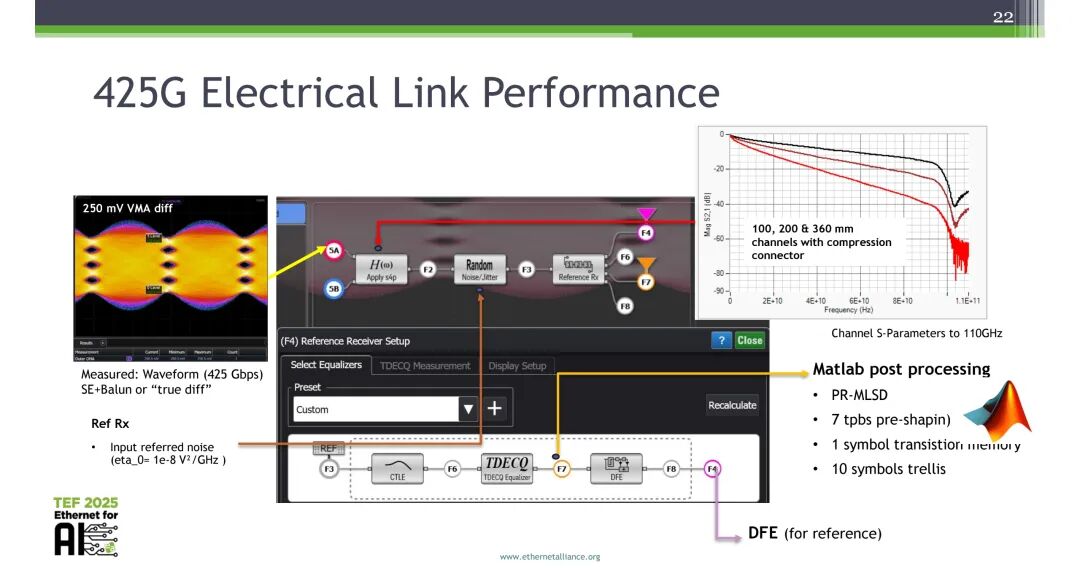
在425G电链路性能测试中,基于100mm、200mm、360mm带压缩连接器的信道,完成了最高110GHz的S参数测量,采用250mV差分VMA、随机噪声/抖动参考接收机,结合PR-MLSD、TDECQ均衡、DFE等技术,完成了425Gbps波形的实测与后处理,验证了链路的传输性能。
2.2 448G PAM6分析工具包
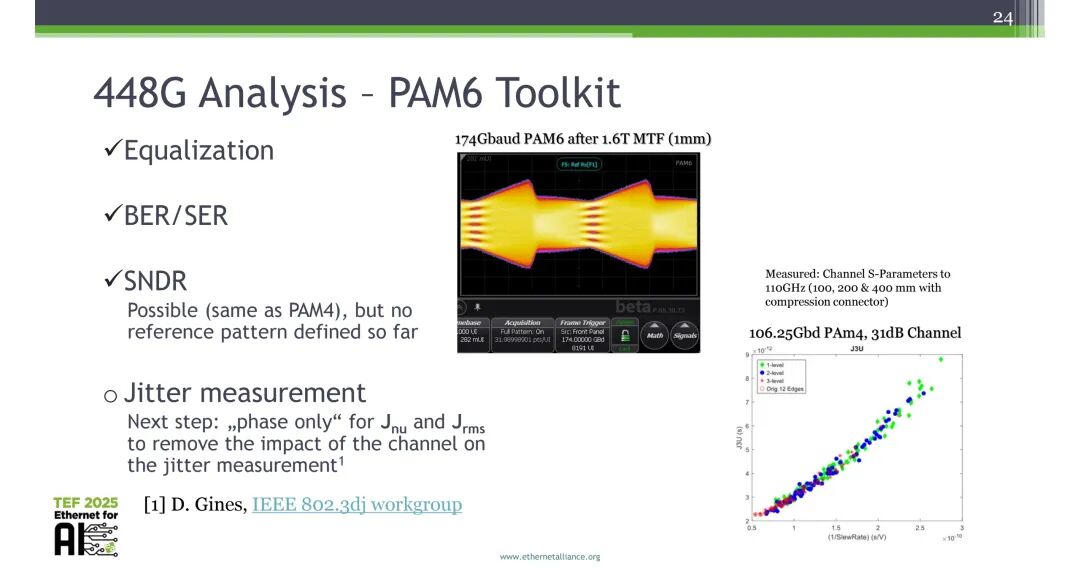
当前PAM6分析工具包已实现均衡、BER/SER、SNDR等核心测量功能,与PAM4的测量能力对齐,但仍存在两项标准化缺口:一是抖动测量缺乏统一方法,需采用“仅相位”方案测量Jnu与Jrms,以消除信道对抖动测量结果的影响;二是行业尚未达成统一的PAM6编码方案与测试图案标准。

在PAM6编码方面,PAM6可实现约2.585bit/符号的传输效率,主流候选方案为5B2S(2.5bit/符号)与18B7S(2.57bit/符号),其中18B7S编解码复杂度较高,5B2S可适配多种格雷编码方案。

在伪随机PAM6序列(PRPM6S)方面,由于6并非素数的幂,无法基于伽罗华域实现标准LFSR序列生成,PRBS基PAM6序列会丢失部分关键特性;布鲁因序列B(k,n)可包含PAM6字母表的所有n元组,但需要非线性反馈结构,ASIC实现复杂度较高,短期可采用基于短内存的序列方案。

2.3 核心结论

当前测试测量方案可支撑448G技术的路径探索,差分FDIU系统可实现PAM4的目标SNR,PAM6与PAM8仍需进一步提升SNR性能;448G电链路中,PAM4可适配CPO场景的XSR类接口,PAM6可兼容CPC接口与传统1.6T C2M信道;行业需尽快达成PAM6编码方案与测试图案的统一标准,以推进标准化进程。
三、实测共封装铜信道的瓶颈揭示:100GBd+速率下PAM6/PAM4的灵敏度分析
本部分内容由MediaTek的Jim Hsieh、Tobey P.-R. Li等团队成员完成,核心基于实测验证的100GHz+带宽共封装铜(Co-Packaged Copper, CPC)信道模型,完成了100GBd+速率下PAM4与PAM6的性能仿真与灵敏度分析,明确了信道瓶颈与400G/lane的实现关键。

3.1 研究背景
2025年初,行业针对AI网络互连的主流调制方案包括PAM8、PAM6、PAM4与双向调制,主流信道包括PCB、近封装铜(Near Package Copper, NPC)与CPC;2025年末,行业已出现基于真实CPC信道的BER仿真结果,2025 OCP展会也展示了100GHz+带宽的真实CPC信道,基于此,100GBd+速率下PAM4与PAM6的性能对比成为核心议题。


3.2 信道设置与特性
本次研究采用的两款CPC信道模型由LUXSHARE-ICT提供,仿真模型已通过实测数据验证,包含3组FEXT与3组NEXT串扰:

- CH1:20mm封装 + CPC连接器 + 200mm 31AWG散装电缆 + IO连接器 + 1英寸paddle board
- CH2:40mm封装 + CPC连接器 + 600mm 31AWG散装电缆 + IO连接器 + 1英寸paddle board
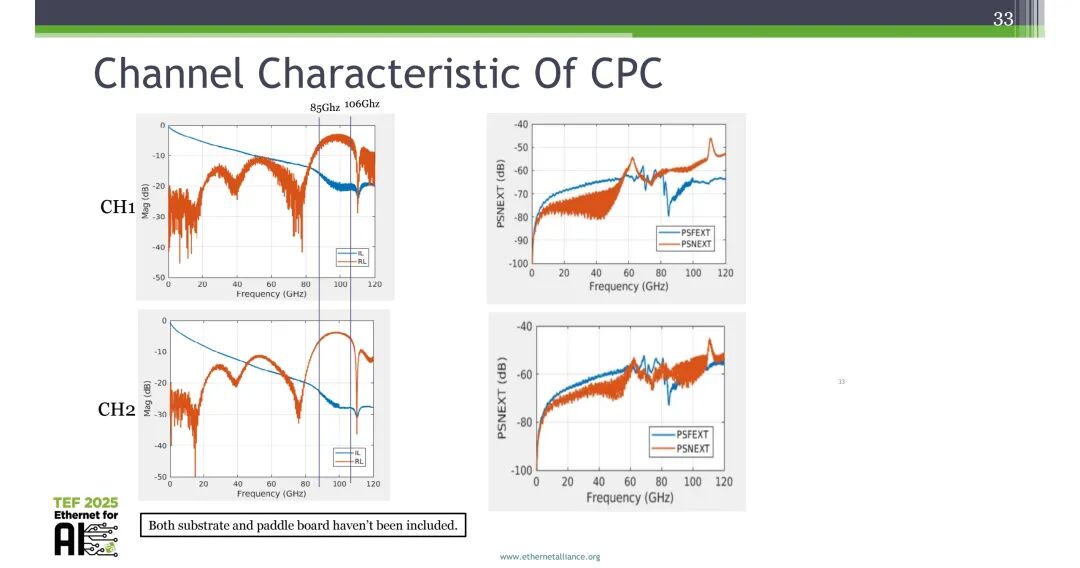
信道特性结果显示,CH1在85GHz处、CH2在106GHz处仍保持可用的带宽特性,串扰水平在全频段内保持在较低水平,可支撑100GBd+的信号传输。
3.3 仿真结果
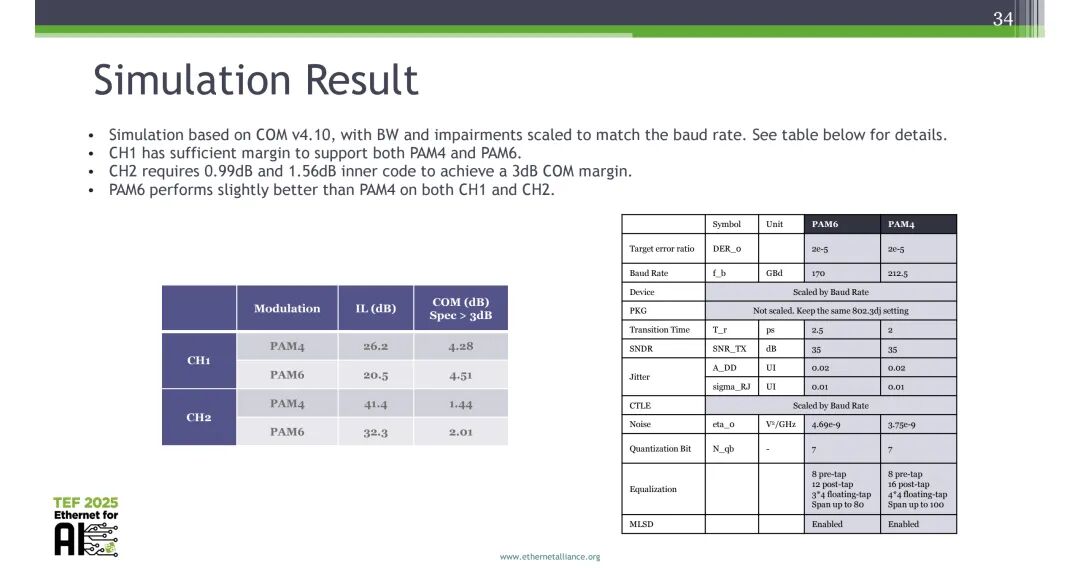
仿真基于COM v4.10开展,带宽与损伤参数 按波特率缩放,核心配置如下:目标误码率DER_0为2e-5,PAM6波特率170GBd、PAM4波特率212.5GBd,TX SNDR均为35dB,双狄拉克抖动A_DD均为0.02UI,随机抖动sigma_RJ均为0.01UI,均启用MLSD均衡。
仿真结果显示:CH1的PAM4插入损耗26.2dB、COM裕量4.28dB,PAM6插入损耗20.5dB、COM裕量4.51dB,均满足>3dB的规格要求;CH2的PAM4插入损耗41.4dB、COM裕量1.44dB,PAM6插入损耗32.3dB、COM裕量2.01dB,需分别通过0.99dB与1.56dB的内码增益才能实现3dB的COM裕量要求。整体来看,100GHz+带宽的CPC信道使PAM4成为可行方案,且PAM6在两款信道中均表现出略优于PAM4的性能。
3.4 灵敏度分析与结论
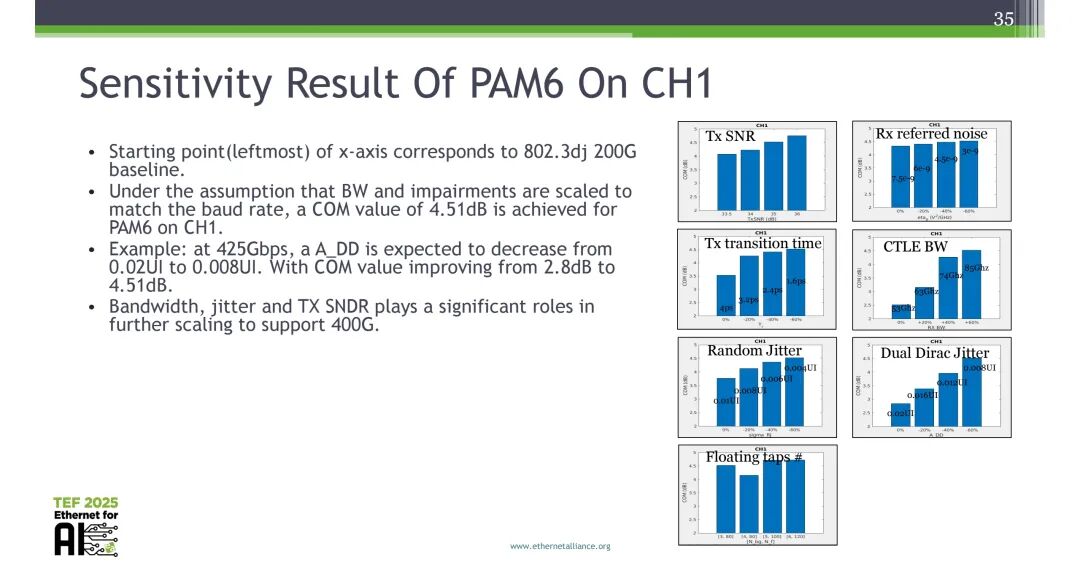
针对CH1信道的PAM6灵敏度分析结果显示,以802.3dj 200G为基线,425Gbps速率下,将A_DD从0.02UI降至0.008UI,COM裕量可从2.8dB提升至4.51dB;带宽、抖动、TX SNDR是支撑速率进一步缩放至400G/lane的核心影响因素,发射机过渡时间、CTLE带宽、接收机参考噪声、均衡器浮动抽头数量也对信道性能有显著影响。

最终结论为:100GHz+带宽的真实CPC信道使PAM4成为100GBd+场景的可行候选方案;长信道场景需采用内码增益;PAM6在两款测试信道中均表现出略优的性能;带宽、抖动、TX SNDR是400G/lane速率缩放的核心关键;仍需更多的信道实测数据,以最终确定400G/lane场景的最优调制方案。
四、封装边缘的模块化(modularity):面向400Gb/s/lane的AI系统的可组合互连

本部分内容由Lightmatter生态发展负责人Bijan Nowroozi提出,核心针对400G/lane速率下的系统设计瓶颈,提出了封装边缘的可组合互连架构,为AI系统的指数级带宽缩放提供了标准化的架构方案。
4.1 400G技术的系统设计挑战

400G/lane的物理特性对AI系统设计带来了多重核心挑战:224G+/lane速率已超出PCB的传输距离极限;长距离(Long-Reach, LR)SerDes占据了芯片的主要功耗与裸片面积;岸线瓶颈限制了端口数量的扩展;而AI计算架构对带宽的需求呈指数级增长。硅光技术虽可解决传输距离问题,但其实现方案尚未形成统一标准,同时互连技术与AI ASIC/xPU的演化路径不一致,导致行业生态碎片化,成为400G/lane技术规模化落地的核心障碍。

4.2 可组合IO的核心架构
基于OCP开放加速器规范(OAM)的市场基础,提出了下一代OAM(NG OAM)架构,核心是在ASIC/封装边缘定义稳定的IO可组合边界,将互连架构拆分为公用平面(Utility Plane)与数据平面(Data Plane):
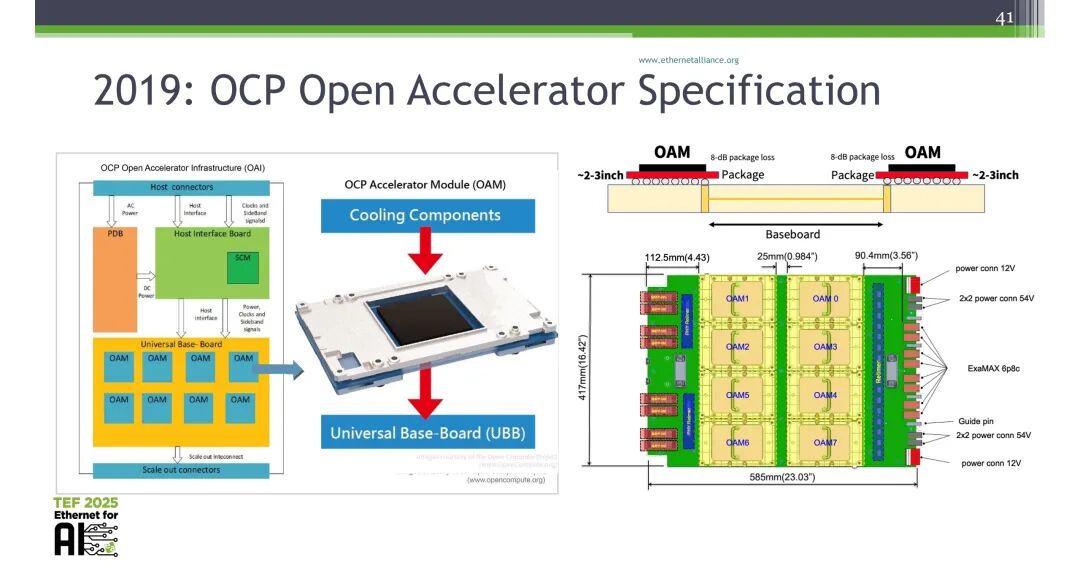


- 公用平面:负责电源传输、控制、遥测功能,为RDL基的电源与控制层,可实现LGA电源传输、健康监测与边带控制,具有标准化、慢演化的特性,可适配特定ASIC凸点图到标准OAM引脚图。
- 数据平面:负责高带宽媒体传输,支持从铜到光的平滑演进,采用XSR/UCIe/VSR短距离技术,可摒弃LR SerDes,回收20-30%的芯片裸片面积,为媒体无关的高速传输层。

4.3 NG OAM的混合3D堆叠架构
NG OAM被定义为混合3D堆叠结构,而非传统PCB模块,共分为三层:

- 底层(基础层):公用RDL层,核心功能为电源传输、接地、边带信号(I2C/GPIO)与PCIe控制,可将特定ASIC的凸点图适配到标准OAM引脚输出。
- 中间层:有源高速数据中介层,核心功能为处理所有200G+的数据流,预留了模块化设计的尺寸与空间,支持任意到任意的光网格路由。
- 顶层:计算与存储层,核心功能为集成ASIC逻辑与HBM存储。
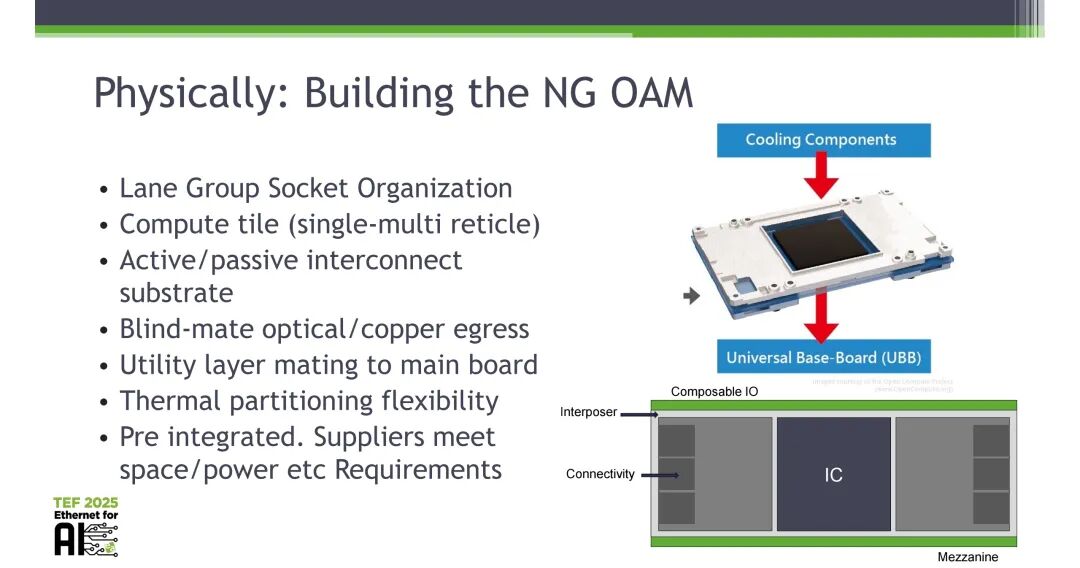
在物理实现上,NG OAM采用多通道socket插座结构(Lane group socket)、计算tile布局、有源/无源互连衬底、盲配光/铜出口、公用层与主板对接、热分区灵活设计,所有组件均为预集成,供应商需满足统一的空间、功耗等规格要求。

4.4 主机接口与性能优势

为支撑NG OAM架构,系统托盘的通用底板(UBB)采用三项核心设计:一是无连接器的电源/控制设计,移除高速铜引脚,仅通过高密度LGA阵列实现电源与低速控制信号的传输;二是统一的机械夹紧设计,通过统一的支撑板与锁存机制为LGA与热界面提供所需的压缩力;三是盲配出口设计,在模块边缘定义南北向禁布区(KOZ),用于安装浮动连接器,实现模块夹紧时的盲配对接。
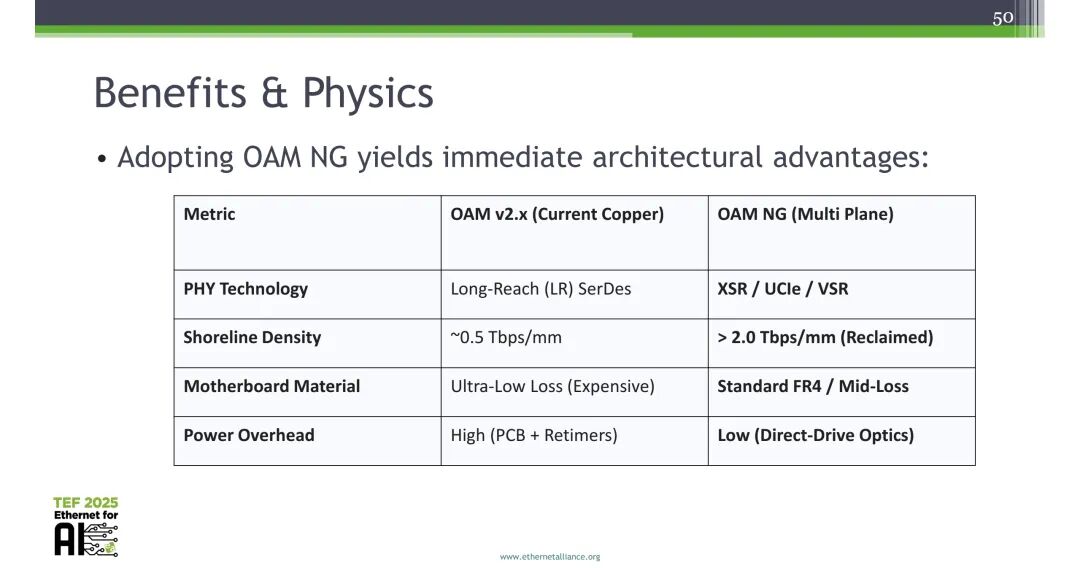
相比当前OAM v2.x铜互连方案,NG OAM实现了核心性能提升:PHY技术从LR SerDes升级为XSR/UCIe/VSR;岸线密度从约0.5Tbps/mm提升至2.0Tbps/mm以上;主板材料从昂贵的超低损耗材料改为标准FR4/中损耗材料;功耗开销通过直接驱动光技术大幅降低。

同时,NG OAM可紧密遵循OIF CMIS/OCP RAS指南,通过公用平面实现实时遥测,连接器设计支持现场级可维护性,盒式替换设计可大幅降低平均修复时间(MTTR),具备优异的RAS与可测试性。
4.5 行业影响与倡议

该可组合IO架构可将ASIC接口的稳定周期延长至十年,减少芯片的重新设计周期,实现媒体技术演进与硅片设计的解耦,同时可对齐OCP、以太网缩放SDO、IEEE、OIF、TEF等行业组织的技术路线,解决生态碎片化问题。
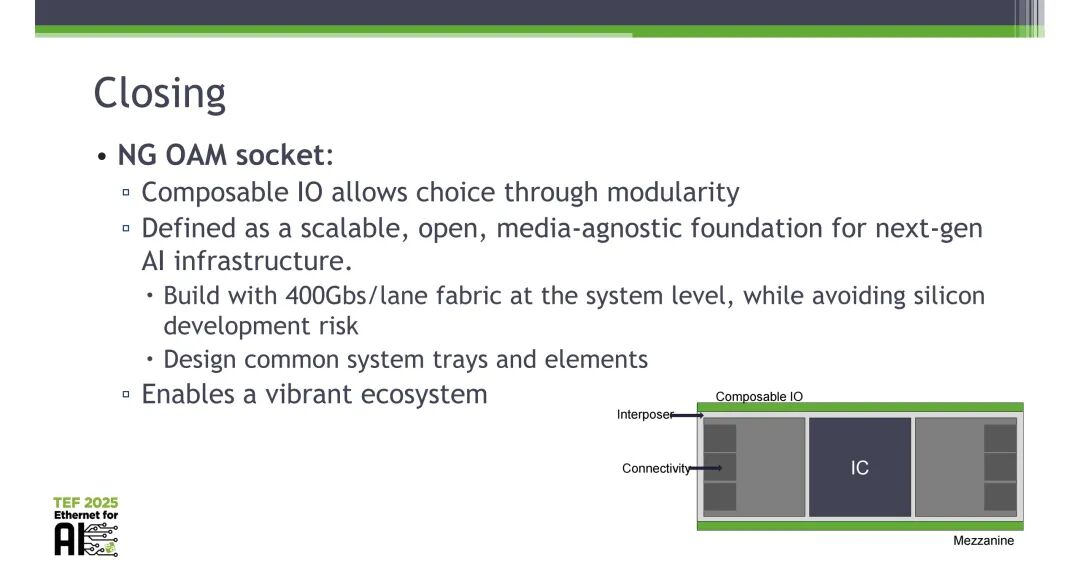
最终发出行业倡议,邀请生态伙伴协作完成以下工作:共同定义未来可组合IO插座,明确分平面机械边界;定义电源、尺寸、速率、热阻抗目标、禁布区等核心需求;标准化LGA与引脚图;定义铜与光数据平面的等级分类;成立OCP/TEF/OIF/SDO联合对齐小组,推动400Gb/s/lane架构在AI系统中的规模化落地。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号