FLUX已经“懂物理”了吗?南洋理工最新免训练框架SHINE让「抠图贴纸」升级成「真实融入」

FLUX已经“懂物理”了吗?南洋理工最新免训练框架SHINE让「抠图贴纸」升级成「真实融入」

AI生成未来
发布于 2026-02-28 18:33:31
发布于 2026-02-28 18:33:31
作者:Shilin Lu等
解读:AI生成未来

文章链接: https://arxiv.org/abs/2509.21278 git链接: https://github.com/ZhumingLian/SHINE
你有没有发现:把一个物体“P”进照片里,最难的从来不是抠图——而是光。 阴影对不对?水面倒影有没有?夜景/逆光会不会穿帮?再加上背景分辨率一高,很多方法直接崩掉。
这篇 ICLR 2026 论文问了一个很直接的问题:像 FLUX 这种文生图扩散模型,可能已经学会了大量“物理/分辨率先验”,只是我们不会把它逼出来?
作者给的答案是:可以,而且不需要再训练一个新模型——他们提出了 SHINE:一个免训练的高保真插入框架(Seamless, High-fidelity Insertion with Neutralized Errors)。

一句话总结
SHINE 用“三板斧”把“主体像不像 + 场景融不融”这对矛盾同时拉起来: 1)用“锚点式”的 latent 优化把主体身份稳住; 2)用一种“反向变差”的引导把画面质量拉回正轨; 3)用注意力生成的自适应 mask 把边缘缝合得更自然。
这篇论文想解决什么痛点?
作者点名了两类常见翻车:
- 复杂光照不真实:阴影、强光、倒影(水面)很容易露馅。
- 分辨率“死板”:很多专门微调过的组合模型绑定固定分辨率,高分图要裁剪/缩放,质量跟着掉。
而免训练方向又常被两座大山卡住:
- inversion 会锁姿态:把参考物体 latent 直接贴进去,姿态就被参考图“钉死”,经常和背景语境冲突。
- attention 操作太脆:调参敏感、稳定性差。
SHINE 的整体流程:先“搭骨架”,再“稳身份”,最后“补细节”
论文里把流程画得很清楚: (1)不用 inversion,先做一次“带描述的补洞”当起点 → (2)MSA 优化稳住主体 → (3)DSG 抑制画质劣化 → (4)ABB 自适应融合边界。
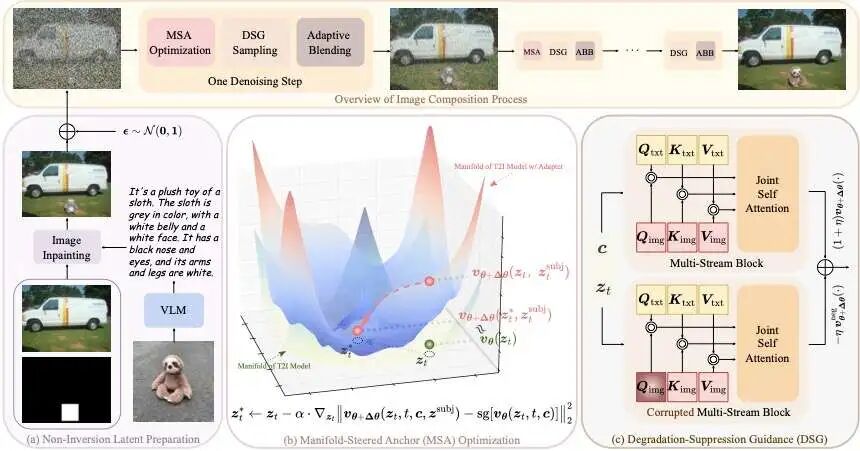
下面按这三块核心贡献拆开讲。
核心 1:不做 inversion 的 latent 起步——先“合理摆姿势”
作者直接把“复制粘贴 inverted latent”这条路绕开了:他们先用 VLM 给主体图做描述,再配合 inpainting 在背景的用户 mask 区域生成一个“主体已在场景里”的初始图,然后加噪得到起始 latent。
直观理解:
- inversion 像是把“同一个姿势的贴纸”硬贴进不同照片;
- 这一步更像是:先让主体在背景里“摆一个看起来合理的姿势/构图”,再进入扩散采样。
核心 2:MSA(Manifold‑Steered Anchor)——“两条世界线”把身份和背景同时锁住
MSA 的关键想法很“工程但聪明”:
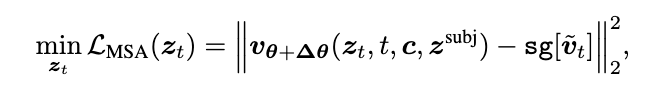
- 用一个预训练的个性化/主体适配器(例如 IP‑Adapter 一类)来提供“长得像参考主体”的方向;
- 同时用基座模型对原始 noisy latent 的预测当“锚点”,保证背景结构别被你改塌。
一句话类比:
适配器负责“像他/它”,锚点负责“别把房间装修拆了”。
核心 3:DSG(Degradation‑Suppression Guidance)——不给“低质感分布”机会
MSA 会把主体拉准,但作者观察到:优化 + 采样的随机性会让结果偶尔出现过饱和、画质下降、身份不稳的问题,于是加了 DSG。
有意思的是:在 FLUX 上,“写负面提示词”基本没用——模型依旧很高保真。 那怎么办?作者做了一个系统实验:分别“模糊”注意力里的不同分量,发现模糊 (图像 query)能在保持结构的同时显著拉低质感,最适合作为“负方向”。
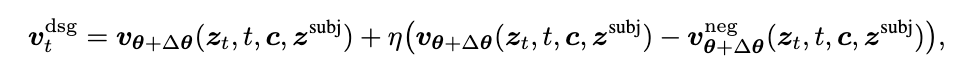

所以 DSG 的直觉可以理解为:
先构造一个“会变糟但不乱结构”的负例方向(通过 blur ),再像 CFG 那样把采样轨迹从它身边推开。
核心 4:ABB(Adaptive Background Blending)——边缘缝合不是靠“硬 mask”,而是靠“语义 mask”
很多插入方法最后都死在边缘:你用用户矩形/粗 mask 去 blend,边界很容易出现“接缝”。作者提出 ABB:
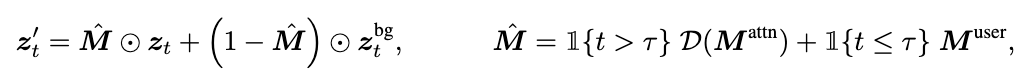
- 早期步(t > τ)不用用户 mask,而用跨注意力里与主体 token 对应的区域生成更精准的注意力 mask;
- 后期步再回到用户 mask,避免把主体阴影/倒影截断得太狠。

实验
1)新基准:ComplexCompo(更贴近真实场景)
传统基准多是 512×512,太“温室”。作者做了 ComplexCompo:
- 300 组组合对;
- 多分辨率 + 横竖构图;
- 特别强调 低光、强光、复杂阴影、水面反射。
2)结果:不仅指标更好,关键是“人类偏好指标”也更强
论文强调:在 ComplexCompo 和 DreamEditBench 上达到 SOTA,且在人类对齐指标(DreamSim / ImageReward / VisionReward)上表现突出。
(数字细节可参考论文实验表格与附录)
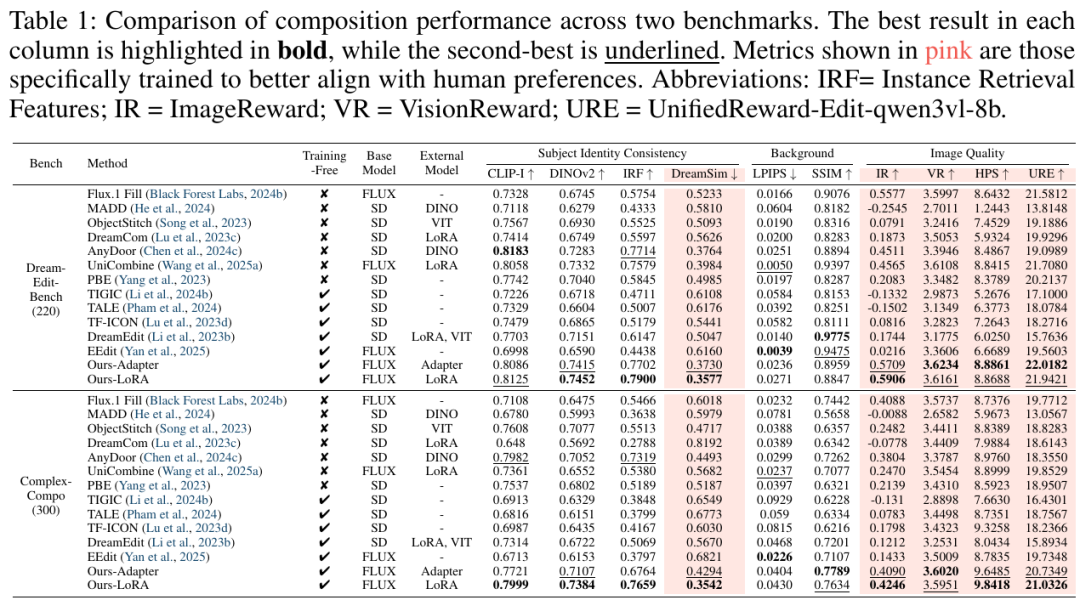
3)消融:三板斧缺一不可
消融结果的直观结论是:
- MSA 主要拉高身份一致性;
- DSG 主要提升整体质感/人类偏好;
- ABB 主要解决边缘接缝(更偏“看起来舒服”,不一定被结构指标完整捕捉)。

局限与启发
论文自己承认的局限
- 如果 inpainting 提示词把颜色写错了,最终结果可能会“继承”这个错误颜色。
- 最终“像不像参考主体”也依赖你用的适配器质量;LoRA 做单概念测试时通常更像。

值得带走的 3 个方法论
- 别急着再训练:大模型可能已经学到很多“物理一致性”,缺的是一个能把先验释放出来的推理框架。
- 把“身份”和“背景结构”拆成两条约束:一个来自适配器,一个来自基座锚点,工程上很稳。
- 负向引导不一定来自文本:在 FLUX 这种架构里,操控内部表征(比如 )可能比写负面 prompt 更有效。
参考文献
[1] Does FLUX Already Know How to Perform Physically Plausible Image Composition?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号