Etcd-2GB容量限制


作者介绍:简历上没有一个精通的运维工程师,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
数据库是一个系统(应用)最重要的资产之一,所以我们的数据库将从以下几个数据库来进行介绍。
MySQL
PostgreSQL
MongoDB
Redis
Etcd(本章节)
传统的数据库是没有容量限制的,但是Etcd是一个特殊数据库,因为他是有容量上限的,今天我们这个小节就来介绍这个容量限制。
在Etcd的技术讨论中,“2GB容量限制”是被问及频率最高的话题之一。许多初次接触etcd的开发者会本能地认为:这是一个应该被“突破”或“优化”的瓶颈。但事实恰恰相反——2GB是etcd设计者主动设置的配额,而非技术上限。它的存在不是为了限制你,而是为了保护你。
本文将从配额机制、超限后果、恢复手段、性能拐点四个维度,完整解读这2GB背后的设计哲学。
一、配额机制:主动熔断,而非被动崩溃
Etcd的存储配额由参数--quota-backend-bytes控制,默认值2GB,官方建议上限8GB。
配额不是什么:它不是etcd程序无法突破的硬编码上限——你可以将其配置为20GB、50GB,etcd依然能运行。但它会面临两个严峻问题:性能和恢复。
配额是什么:它是一个主动熔断阈值。当BoltDB文件大小达到配额时,etcd主动拒绝所有写请求,集群进入维护模式(仅读/删),并在日志中输出明确的mvcc: database space exceeded错误。
为何要熔断? 设想无配额场景:磁盘写满是一个渐进过程,当磁盘剩余空间仅剩几百MB时,etcd仍在疯狂写入WAL和BoltDB。最终磁盘彻底耗尽,etcd进程可能直接崩溃,或陷入“写失败-重试-再写失败”的死循环。此时,运维人员不仅需要清理空间,还需处理一个处于未知状态的进程。恢复难度远高于配额熔断后的优雅只读模式。
2GB的定位:它是安全与容量的均衡点。对于绝大多数etcd使用场景(配置管理、服务发现、Kubernetes元数据),2GB足够支撑数万至数十万个对象;同时,2GB的快照传输、碎片整理、内存映射均在可接受开销范围内。
二、超限之后:NOSPACE告警与标准恢复三部曲
当配额耗尽,etcd会设置NOSPACE告警,可通过etcdctl endpoint status查看。此时集群处于全局只读状态,所有PUT操作均被拒绝。
恢复并非简单调高配额——因为根本问题是有效数据已满,而非预留空间不足。标准恢复流程如下:
第一步:压缩(Compact)
etcdctl compact压缩之前的所有历史版本(这个就是我们前面讲过的数据存储)。效果:BoltDB中产生大量空闲空间,dbSizeInUse(实际数据大小)显著下降,但dbSize(物理文件大小)不变——文件空洞形成。
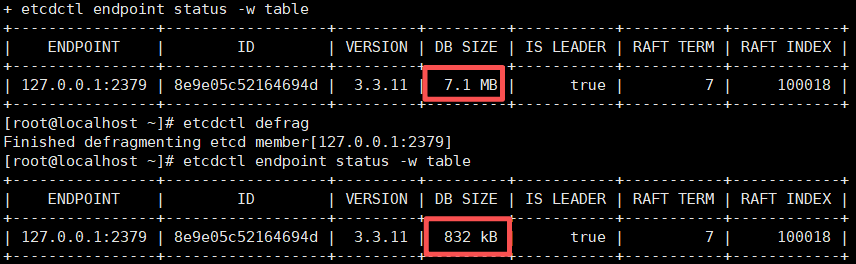
第二步:碎片整理(Defrag)
etcdctl defrag这是真正的空间回收。etcd创建新BoltDB文件,将有效数据逐页复制过去,原子替换原文件。物理文件缩小,空洞消除。重要:此操作需逐节点串行执行,且执行期间该节点短暂不可用——绝对禁止对全集群并发defrag。
第三步:解除告警
etcdctl alarm disarm配额占用降至阈值以下后,手动清除NOSPACE状态,集群恢复写入。
版本陷阱:etcd v3.5.0 - v3.5.5存在在线碎片整理缺陷,强烈建议在这些版本上执行离线整理(停止etcd进程后操作)。
三、8GB上限:性能拐点的工程判断
既然2GB可调,为何官方建议不要超过8GB?这不是武断的教条,而是多个技术因素交汇形成的工程共识:
1. BoltDB的mmap限制 BoltDB基于内存映射文件,8GB的DB文件意味着8GB的虚拟内存地址空间占用。在32位系统上这是不可能的任务;在64位系统上虽无地址空间压力,但频繁的缺页中断仍会影响性能。超过8GB后,B+树深度从3层增至4层,随机读延迟明显上升。
2. Raft快照传输成本 新节点加入或落后节点追赶时,Leader需发送全量快照。8GB的快照在网络传输、接收方磁盘写入、状态机加载三个环节均为沉重负担。生产环境中,超过4GB的快照传输就可能导致Leader心跳超时、集群不稳定。
3. 对象数量瓶颈 大量生产环境数据表明:即使DB文件未达8GB,当Kubernetes对象数量超过3-4万个时,etcd性能已显著下降——API Server LIST延迟飙升,Pod启动变慢。这是因为etcd是线性一致性系统,每一次LIST/WATCH都要遍历大量对象。容量只是表象,对象数量才是真正的性能标尺。
4. 备份与恢复耗时 超过8GB的etcd,单次etcdctl快照耗时可达数分钟,从快照恢复新集群更是长达数十分钟。在SLO要求严苛的生产环境,这是不可接受的运维窗口。
结论:8GB上限是容量、性能、运维三者博弈的均衡点。突破它并非不能运行,而是你将独自承担突破阈值后的不确定性。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号