OpenClaw 的Agent记忆与 RAG 有何区别?

OpenClaw 的Agent记忆与 RAG 有何区别?

臻成AI大模型
发布于 2026-02-28 16:02:40
发布于 2026-02-28 16:02:40
先泼盆冷水
很多人觉得AI记得住,其实是个错觉。
你跟ChatGPT聊完一场,第二天它完全不知道你是谁。你说上次那个问题,它完全茫然。
这种失忆不是AI不想记住你,而是它的本职工作就是处理当前这一次的对话。它没有长期记忆这种概念。
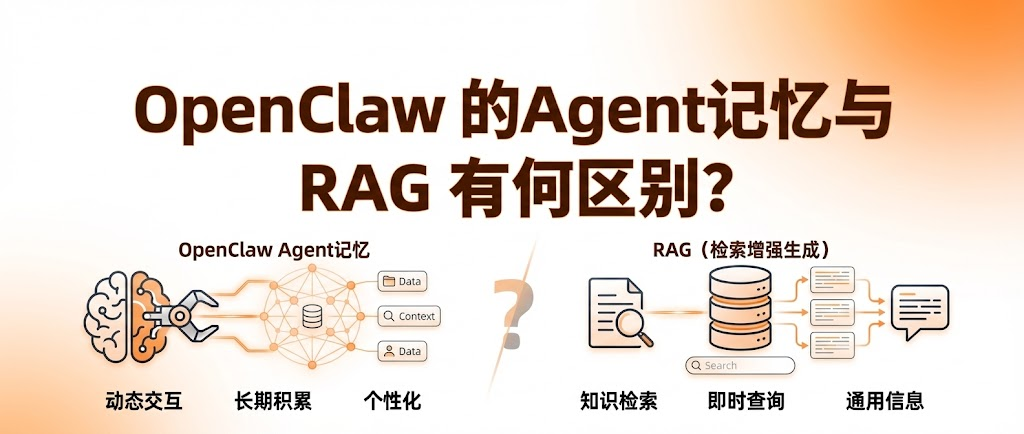
那RAG是什么呢?
RAG就像给AI配了个图书馆。你问问题,它去文档库里翻资料,找到相关内容后塞进上下文里给你答案。
它解决的是AI知识过时的问题——毕竟大模型的训练数据是有截止日期的,你问它今天发生的新闻,它当然答不上来。
但RAG有个根本性的局限:它只管查,不管记。你每次问问题,它都要重新检索;它不会主动记住你是谁、你的偏好、你做过的决策。
这就是OpenClaw真正要解决的问题。
Agent记忆和RAG,压根不是一回事
先简单说说OpenClaw是什么。
这个项目2026年1月突然爆火,经历了三次改名——从Clawd Bot到MoltBot,最后定名OpenClaw。
创始人是个奥地利开发者Peter Steinberger,之前做PDF SDK的。他最初只是想做个WhatsApp中继脚本,结果越做越大,最后连OpenAI都向他抛出了橄榄枝。
现在阿里云、腾讯云都上线了它的云端部署方案,GitHub星标破了20W+,被称为史上增长最快的开源项目。
但它最核心的创新,不是什么浏览器操控、自动部署——而是那套记忆系统。
很多人把Agent记忆和RAG混为一谈,觉得它们都是“让AI知道更多东西”。其实两者解决的是完全不同的问题。
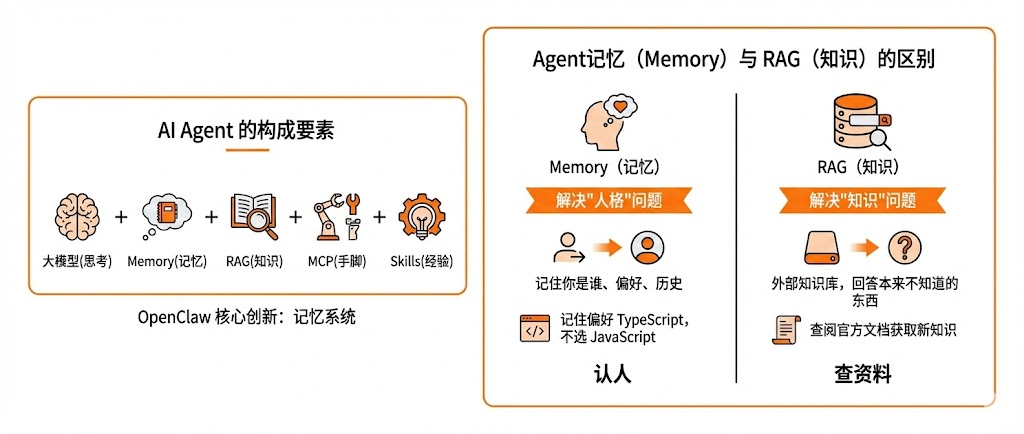
我给你一个公式,看完你就懂了:
AI Agent = 大模型(思考) + Memory(记忆) + RAG(知识) + MCP(手脚) + Skills(经验)
RAG解决的是知识的问题——它给AI配了个外部知识库,让AI能回答它本来不知道的东西。
Memory解决的是人格的问题——它让AI记住你是谁、你之前聊过什么、你的偏好是什么。
没有Memory,AI就是个冷冰冰的工具;有了Memory,AI才开始有点“人格”的样子。
打个比方:你让AI帮你写代码,用了RAG,它能查到官方文档;但用了Memory,它能记住你上次选了TypeScript而不是JavaScript,这次直接就按你的偏好来。
一个查资料,一个认人。完全两码事。
OpenClaw是怎么把“记忆”做透的
说完区别,再来看看OpenClaw具体怎么实现的。
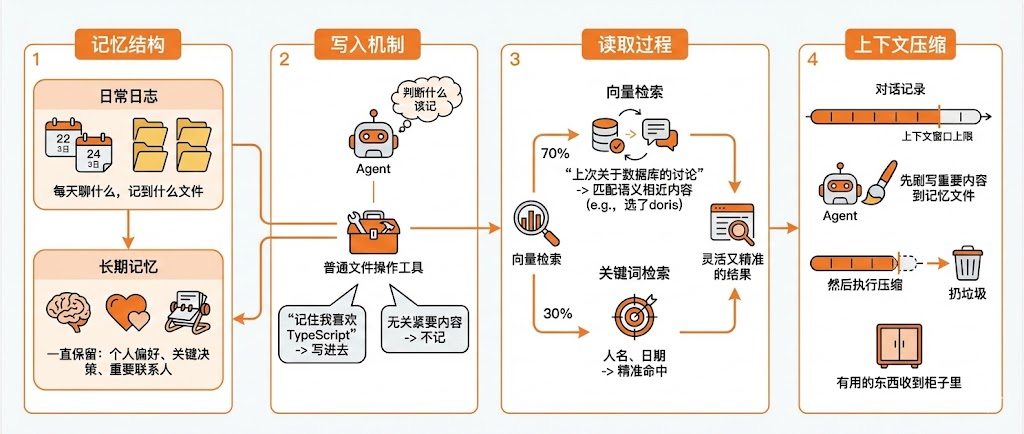
它的记忆系统分成两层。
第一层是日常日志,按日期存储,你们每天聊什么,它就记到什么文件里。
第二层是长期记忆,专门存那些需要一直保留的信息——你的个人偏好、关键决策、重要联系人。
有个细节特别有意思:它没有专门设计写记忆的工具。
Agent就直接用普通的文件操作工具,根据上下文自己判断什么该记、什么不该记。你说“记住我喜欢TypeScript”,它就写进去;你聊了点无关紧要的内容,它就不记。
读取的时候更讲究。它同时跑两路检索:向量检索占70%权重,关键词检索占30%权重。
向量检索能找到语义相近的内容,比如你问“上次关于数据库的讨论”,它能匹配到当时我们选了doris这类相关内容;关键词检索能精准命中具体的人名、日期。
这两种方式一结合,既灵活又精准。
还有一点特别关键:上下文压缩。
不管什么大模型,上下文窗口都是有上限的。聊久了肯定会被撑爆。
传统的做法是直接删掉早期的对话记录,但OpenClaw不干这种“败家”的事。
它在压缩之前,会先让Agent把重要的内容刷写到记忆文件里,然后再执行压缩。
这就相当于——你要清理房间是吧?先让我把有用的东西收到柜子里,再扔垃圾。东西不会丢。
这才是真正做产品的人会想到的细节。
为什么我说这套系统有未来
让我说句可能会得罪某些人的话:现在市面上90%的AI Agent,其实都是伪需求。
为什么?
因为它们没有记忆。
今天用完,明天就忘了你的存在。你要反复告诉它你的需求、你的偏好、你的背景。这种体验,说难听点——比请个实习生还累。
OpenClaw让我看到不一样的东西。它让我觉得,AI真的可以认识你。
而且它的设计理念我很喜欢:所有记忆都是明文存储在md文件里,你可以随时打开看、随时手动改、随时删除。
它不会把你的数据藏在一个你看不见的数据库里。这种透明度,比什么都重要。
现在阿里、腾讯都在跟进云端部署方案,说明市场已经用脚投票了。
结语
RAG是好人,帮你查资料;Agent记忆是知己,记住你是谁。
两者不冲突,可以配合使用。但如果你要的是一个真正能帮你干活、能理解你的AI,那记忆这一环省不掉。
这就是为什么我说——2026年之后,不带记忆的AI Agent,都会显得有点残疾。
各位觉着呢?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号