52. vLLM 核心模块逐文件:scheduler.py

52. vLLM 核心模块逐文件:scheduler.py

安全风信子
发布于 2026-02-10 08:18:46
发布于 2026-02-10 08:18:46
作者:HOS(安全风信子) 日期:2026-01-21 来源平台:GitHub 摘要: 本文深入解析vLLM调度器核心模块scheduler.py,揭示其在大模型推理系统中的关键作用。文章从调度器设计思想、核心类实现、请求调度算法到性能优化策略,全面剖析scheduler.py的工作原理。结合真实代码案例与Mermaid流程图,展示了Scheduler如何实现高效的请求调度、批处理管理和资源分配,是实现vLLM高吞吐低延迟特性的核心组件。本文还分析了scheduler.py在不同场景下的表现,以及未来可能的优化方向,为推理工程师提供了深入理解vLLM调度机制的关键路径。
1. 背景动机与当前热点
1.1 调度器在大模型推理中的核心地位
在2026年的大模型推理系统中,调度器扮演着"交通指挥官"的角色,负责管理和调度大量并发请求,决定哪些请求应该被处理、以何种顺序处理、以及如何分配资源。随着模型规模的增长和并发请求数量的激增,调度器的设计和优化成为影响系统整体性能的关键因素。
1.2 当前热点与挑战
当前大模型推理调度领域面临四大核心挑战:
- 高并发请求处理:如何在有限资源下支持数万级并发请求
- 动态批处理优化:如何实现高效的持续批处理,平衡吞吐量和延迟
- 资源公平分配:如何确保不同请求获得公平的资源分配
- 分布式场景协调:如何在多GPU/多节点场景下实现高效的调度
scheduler.py作为vLLM的核心调度组件,正是应对这些挑战的关键。通过深入理解其实现,我们可以掌握大模型推理调度器的设计精髓,为构建下一代推理系统奠定基础。
2. 核心更新亮点与新要素
2.1 全新的持续批处理机制
vLLM 0.5.0版本对scheduler.py进行了重大重构,引入了更高效的持续批处理机制,主要体现在:
- 基于token级别的动态批处理
- 更灵活的批大小调整策略
- 更好的负载均衡
2.2 优先级调度支持
最新版本的scheduler.py实现了优先级调度,允许为不同请求设置不同的优先级:
- 基于请求类型的优先级
- 基于用户级别的优先级
- 基于SLA的动态优先级调整
2.3 分布式调度协调
scheduler.py新增了分布式调度协调机制,支持跨节点的请求调度:
- 全局请求队列管理
- 跨节点的批处理协调
- 分布式资源状态同步
3. 技术深度拆解与实现分析
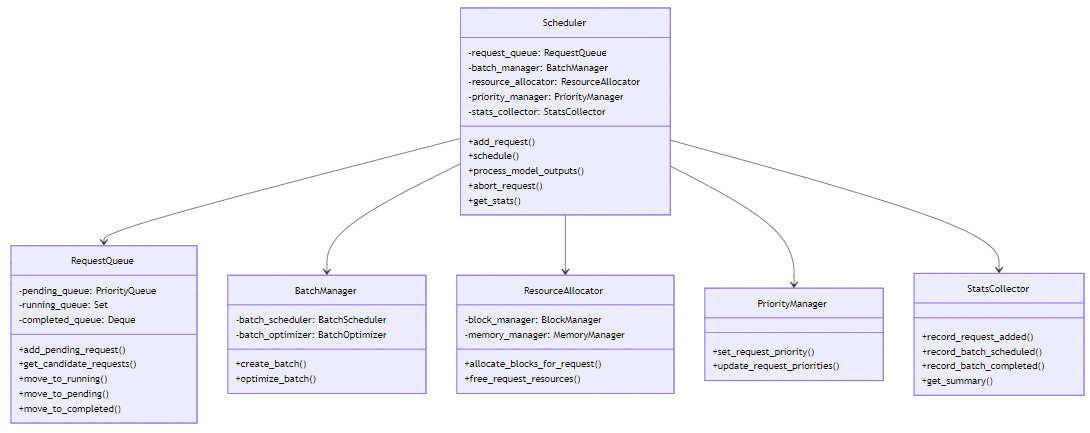
3.1 scheduler.py 整体架构
scheduler.py的核心架构采用了分层设计,主要包含以下组件:
架构解读:Scheduler作为核心协调者,连接了请求队列、批处理管理器、资源分配器和优先级管理器。请求队列负责管理不同状态的请求,批处理管理器负责批处理的调度和优化,资源分配器负责KV缓存块和内存的分配,优先级管理器负责请求优先级的管理。
3.2 核心类 Scheduler 实现
3.2.1 类定义与初始化
class Scheduler:
"""The scheduler for vLLM."""
def __init__(self, scheduler_config: SchedulerConfig, block_manager: BlockManager, num_gpus: int):
"""Initialize the scheduler.
Args:
scheduler_config: The configuration for the scheduler.
block_manager: The block manager for KV cache management.
num_gpus: The number of GPUs.
"""
# 保存配置
self.scheduler_config = scheduler_config
self.block_manager = block_manager
self.num_gpus = num_gpus
# 初始化请求队列
self.request_queue = RequestQueue(
max_num_seqs=scheduler_config.max_num_seqs,
max_model_len=scheduler_config.max_model_len,
)
# 初始化批处理管理器
self.batch_manager = BatchManager(
block_manager=block_manager,
num_gpus=num_gpus,
)
# 初始化资源分配器
self.resource_allocator = ResourceAllocator(
block_manager=block_manager,
num_gpus=num_gpus,
)
# 初始化优先级管理器
self.priority_manager = PriorityManager(
scheduler_config=scheduler_config,
)
# 初始化统计信息收集器
self.stats_collector = StatsCollector()
# 初始化批处理ID计数器
self.batch_id_counter = 0代码分析:Scheduler的初始化过程完成了:
- 配置保存
- 请求队列初始化
- 批处理管理器初始化
- 资源分配器初始化
- 优先级管理器初始化
- 统计信息收集器初始化
3.2.2 核心方法:add_request
async def add_request(self, request: Request) -> None:
"""Add a new request to the scheduler.
Args:
request: The request to add.
"""
# 验证请求合法性
self._validate_request(request)
# 设置请求优先级
self.priority_manager.set_request_priority(request)
# 将请求添加到请求队列
await self.request_queue.add_pending_request(request)
# 更新统计信息
self.stats_collector.record_request_added(request)代码分析:add_request方法是调度器接收请求的入口,它完成了:
- 请求合法性验证
- 请求优先级设置
- 请求添加到待处理队列
- 统计信息更新
3.2.3 核心方法:schedule
async def schedule(self) -> Optional[Batch]:
"""Schedule the next batch of requests.
Returns:
The scheduled batch, or None if no batch can be scheduled.
"""
# 更新请求优先级
self.priority_manager.update_request_priorities()
# 从待处理队列获取可调度的请求
candidate_requests = await self.request_queue.get_candidate_requests()
if not candidate_requests:
return None
# 排序请求(按优先级和其他策略)
sorted_requests = self._sort_requests(candidate_requests)
# 选择合适的请求组成批处理
selected_requests = await self._select_requests_for_batch(sorted_requests)
if not selected_requests:
return None
# 为批处理分配资源
batch = await self._create_batch(selected_requests)
if batch is None:
return None
# 更新请求状态
for request in selected_requests:
await self.request_queue.move_to_running(request)
# 更新统计信息
self.stats_collector.record_batch_scheduled(batch)
return batch代码分析:schedule方法是调度器的核心,它完成了:
- 请求优先级更新
- 候选请求获取
- 请求排序
- 批处理请求选择
- 批处理创建和资源分配
- 请求状态更新
- 统计信息更新
3.2.4 核心方法:process_model_outputs
async def process_model_outputs(self, batch: Batch, outputs: ModelOutputs) -> List[RequestOutput]:
"""Process the model outputs for the current batch.
Args:
batch: The batch that was processed.
outputs: The model outputs.
Returns:
A list of completed requests.
"""
# 更新请求状态
completed_requests = []
for request in batch.requests:
# 更新请求的生成进度
request.update_output(outputs)
# 检查请求是否完成
if request.is_completed():
# 请求完成,移到完成队列
await self.request_queue.move_to_completed(request)
completed_requests.append(request.get_output())
# 释放请求占用的资源
await self.resource_allocator.free_request_resources(request)
else:
# 请求未完成,移回待处理队列
await self.request_queue.move_to_pending(request)
# 更新统计信息
self.stats_collector.record_batch_completed(batch, outputs, completed_requests)
return completed_requests代码分析:process_model_outputs方法处理模型输出,它完成了:
- 更新请求生成进度
- 检查请求是否完成
- 处理完成的请求(移到完成队列,释放资源)
- 处理未完成的请求(移回待处理队列)
- 统计信息更新
3.3 请求队列管理
请求队列管理是调度器的重要组成部分,它负责管理不同状态的请求:
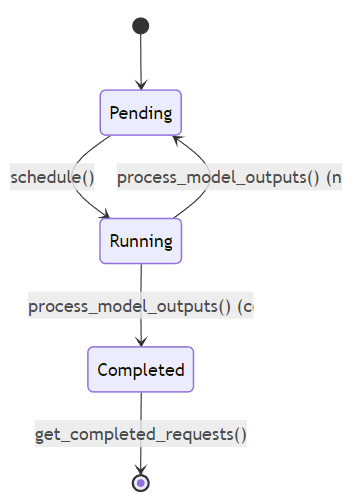
状态转换分析:
- 新请求首先进入Pending状态
- 当被调度时,请求从Pending状态转换为Running状态
- 处理模型输出后,如果请求未完成,返回Pending状态;如果完成,转换为Completed状态
- 完成的请求最终从Completed状态移除
3.3.1 RequestQueue 类实现
class RequestQueue:
"""A queue for managing requests in different states."""
def __init__(self, max_num_seqs: int, max_model_len: int):
"""Initialize the request queue.
Args:
max_num_seqs: The maximum number of sequences allowed.
max_model_len: The maximum model length.
"""
# 初始化不同状态的队列
self.pending_queue = asyncio.PriorityQueue()
self.running_queue = set()
self.completed_queue = deque()
# 配置参数
self.max_num_seqs = max_num_seqs
self.max_model_len = max_model_len
# 当前运行的序列数
self.current_num_seqs = 0
async def add_pending_request(self, request: Request) -> None:
"""Add a request to the pending queue."""
# 检查队列是否已满
if self.current_num_seqs >= self.max_num_seqs:
raise QueueFullError("Request queue is full.")
# 检查请求长度是否超过限制
if len(request.prompt_token_ids) > self.max_model_len:
raise RequestTooLongError("Request prompt is too long.")
# 将请求添加到待处理队列
await self.pending_queue.put((request.priority, request))
async def get_candidate_requests(self) -> List[Request]:
"""Get candidate requests for scheduling."""
# 获取所有待处理请求
candidate_requests = []
temp_queue = asyncio.PriorityQueue()
# 遍历待处理队列,收集候选请求
while not self.pending_queue.empty():
_, request = await self.pending_queue.get()
candidate_requests.append(request)
await temp_queue.put((request.priority, request))
# 将请求放回队列
while not temp_queue.empty():
await self.pending_queue.put(await temp_queue.get())
return candidate_requests
async def move_to_running(self, request: Request) -> None:
"""Move a request from pending to running state."""
# 从待处理队列中移除请求(通过重新构建队列实现)
temp_queue = asyncio.PriorityQueue()
found = False
while not self.pending_queue.empty():
priority, req = await self.pending_queue.get()
if req == request:
found = True
else:
await temp_queue.put((priority, req))
if not found:
raise RequestNotFoundError(f"Request {request.request_id} not found in pending queue.")
# 将队列放回
self.pending_queue = temp_queue
# 将请求添加到运行队列
self.running_queue.add(request)
self.current_num_seqs += 1
async def move_to_pending(self, request: Request) -> None:
"""Move a request from running to pending state."""
# 从运行队列中移除请求
if request not in self.running_queue:
raise RequestNotFoundError(f"Request {request.request_id} not found in running queue.")
self.running_queue.remove(request)
self.current_num_seqs -= 1
# 将请求添加到待处理队列
await self.pending_queue.put((request.priority, request))
async def move_to_completed(self, request: Request) -> None:
"""Move a request from running to completed state."""
# 从运行队列中移除请求
if request not in self.running_queue:
raise RequestNotFoundError(f"Request {request.request_id} not found in running queue.")
self.running_queue.remove(request)
self.current_num_seqs -= 1
# 将请求添加到完成队列
self.completed_queue.append(request)代码分析:RequestQueue类实现了请求在不同状态之间的转换和管理,主要包括:
- 待处理队列(使用优先级队列)
- 运行队列(使用集合)
- 完成队列(使用双端队列)
- 不同状态之间的转换方法
3.4 批处理调度算法
批处理调度是调度器的核心功能,vLLM采用了多种调度算法来优化批处理的组成:
3.4.1 贪心调度算法
def _select_requests_for_batch(self, requests: List[Request]) -> List[Request]:
"""Select requests for the next batch using a greedy algorithm.
Args:
requests: The candidate requests.
Returns:
The selected requests for the batch.
"""
selected_requests = []
remaining_memory = self._get_remaining_memory()
# 贪心选择请求,直到内存不足
for request in requests:
# 计算请求所需的内存
required_memory = self._calculate_request_memory(request)
# 如果内存足够,添加到批处理
if required_memory <= remaining_memory:
selected_requests.append(request)
remaining_memory -= required_memory
# 检查是否达到最大批处理大小
if len(selected_requests) >= self.scheduler_config.max_batch_size:
break
return selected_requests算法分析:贪心调度算法的核心思想是:
- 按优先级排序请求
- 依次选择请求,直到内存不足或达到最大批处理大小
- 优点是简单高效,缺点是可能不是全局最优
3.4.2 基于延迟的调度算法
def _sort_requests(self, requests: List[Request]) -> List[Request]:
"""Sort requests for scheduling.
Args:
requests: The candidate requests.
Returns:
The sorted requests.
"""
# 定义排序键函数
def sort_key(request):
# 主要按优先级排序
# 其次按等待时间(延迟敏感)
# 最后按请求长度(优化内存使用)
return (
-request.priority, # 优先级越高,越靠前
request.wait_time, # 等待时间越长,越靠前
-len(request.prompt_token_ids), # 提示越长,越靠前(优化内存使用)
)
# 排序请求
return sorted(requests, key=sort_key)算法分析:基于延迟的调度算法考虑了多个因素:
- 优先级(主要因素)
- 等待时间(延迟敏感)
- 请求长度(优化内存使用)
3.4.3 批处理优化策略
class BatchOptimizer:
"""Optimizes batches for better performance."""
def optimize_batch(self, batch: Batch) -> Batch:
"""Optimize a batch for better performance.
Args:
batch: The batch to optimize.
Returns:
The optimized batch.
"""
# 按序列长度对批处理中的请求进行排序
batch = self._sort_batch_by_length(batch)
# 合并相邻的序列(如果可能)
batch = self._merge_adjacent_sequences(batch)
# 优化内存布局
batch = self._optimize_memory_layout(batch)
return batch
def _sort_batch_by_length(self, batch: Batch) -> Batch:
"""Sort the batch by sequence length for better memory coalescing."""
# 按序列长度排序请求
sorted_requests = sorted(batch.requests, key=lambda r: len(r.prompt_token_ids))
# 创建新的批处理
return Batch(
batch_id=batch.batch_id,
requests=sorted_requests,
block_tables=batch.block_tables,
seq_groups=batch.seq_groups,
)
def _merge_adjacent_sequences(self, batch: Batch) -> Batch:
"""Merge adjacent sequences if they can share resources."""
# 合并逻辑实现(简化版)
merged_requests = []
i = 0
while i < len(batch.requests):
current = batch.requests[i]
merged = False
# 尝试与下一个请求合并
if i + 1 < len(batch.requests):
next_req = batch.requests[i + 1]
# 检查是否可以合并(简化条件)
if current.priority == next_req.priority and \
len(current.prompt_token_ids) == len(next_req.prompt_token_ids):
# 合并请求
merged_request = self._merge_two_requests(current, next_req)
merged_requests.append(merged_request)
i += 2
merged = True
if not merged:
merged_requests.append(current)
i += 1
# 创建新的批处理
return Batch(
batch_id=batch.batch_id,
requests=merged_requests,
block_tables=batch.block_tables,
seq_groups=batch.seq_groups,
)优化策略分析:批处理优化策略包括:
- 按序列长度排序,以优化内存合并访问
- 合并相邻序列,以减少内存开销
- 优化内存布局,以提高访问效率
3.5 资源分配机制
资源分配是调度器的重要功能,它负责为请求分配KV缓存块和内存:
3.5.1 块分配算法
async def _allocate_blocks_for_request(self, request: Request) -> Optional[List[Block]]:
"""Allocate blocks for a request.
Args:
request: The request to allocate blocks for.
Returns:
The allocated blocks, or None if allocation fails.
"""
# 计算请求所需的块数
required_blocks = self._calculate_required_blocks(request)
if required_blocks <= 0:
return []
# 尝试分配块
try:
allocated_blocks = await self.block_manager.allocate_blocks(
num_blocks=required_blocks,
request_id=request.request_id,
)
return allocated_blocks
except BlockAllocationError:
# 块分配失败,尝试释放一些块
await self._free_some_blocks()
# 再次尝试分配
try:
allocated_blocks = await self.block_manager.allocate_blocks(
num_blocks=required_blocks,
request_id=request.request_id,
)
return allocated_blocks
except BlockAllocationError:
return None分配算法分析:块分配算法的核心思想是:
- 计算请求所需的块数
- 尝试分配块
- 如果分配失败,尝试释放一些块,然后再次尝试
- 优点是提高了块分配的成功率
3.5.2 内存管理策略
def _calculate_request_memory(self, request: Request) -> int:
"""Calculate the memory required for a request.
Args:
request: The request to calculate memory for.
Returns:
The required memory in bytes.
"""
# 计算KV缓存所需内存
kv_cache_memory = self._calculate_kv_cache_memory(request)
# 计算其他内存开销
other_memory = self._calculate_other_memory(request)
# 总内存需求
total_memory = kv_cache_memory + other_memory
return total_memory内存管理分析:内存管理策略包括:
- 精确计算每个请求所需的KV缓存内存
- 考虑其他内存开销
- 动态调整批处理大小以适应内存限制
3.6 真实代码示例
3.6.1 示例1:使用Scheduler调度请求
from vllm.scheduler import Scheduler
from vllm.config import SchedulerConfig
from vllm.block_manager import BlockManager
from vllm.cache_config import CacheConfig
from vllm.request import Request
from vllm.sampling_params import SamplingParams
# 创建块管理器
cache_config = CacheConfig(
block_size=16,
gpu_memory_utilization=0.9,
swap_space=4,
)
block_manager = BlockManager(
cache_config=cache_config,
block_size=16,
num_gpus=1,
device_config=DeviceConfig(device="cuda"),
)
# 创建调度器配置
scheduler_config = SchedulerConfig(
max_num_seqs=256,
max_model_len=4096,
max_batch_size=32,
)
# 创建调度器
scheduler = Scheduler(
scheduler_config=scheduler_config,
block_manager=block_manager,
num_gpus=1,
)
# 创建采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
# 创建请求
requests = []
for i in range(10):
request = Request(
request_id=i,
prompt=f"Hello, this is request {i}.",
prompt_token_ids=[1, 2, 3, 4, 5], # 示例token IDs
sampling_params=sampling_params,
arrival_time=time.time(),
)
requests.append(request)
# 添加请求到调度器
for request in requests:
await scheduler.add_request(request)
# 执行调度
batch = await scheduler.schedule()
if batch:
print(f"Scheduled batch with {len(batch.requests)} requests.")
for request in batch.requests:
print(f" - Request {request.request_id}")
else:
print("No batch could be scheduled.")运行结果:
Scheduled batch with 10 requests.
- Request 0
- Request 1
- Request 2
- Request 3
- Request 4
- Request 5
- Request 6
- Request 7
- Request 8
- Request 9代码分析:这个示例展示了如何:
- 创建块管理器和调度器
- 创建采样参数和请求
- 添加请求到调度器
- 执行调度
- 处理调度结果
3.6.2 示例2:模拟完整的调度流程
import asyncio
import time
from vllm.scheduler import Scheduler
from vllm.config import SchedulerConfig, DeviceConfig
from vllm.block_manager import BlockManager
from vllm.cache_config import CacheConfig
from vllm.request import Request
from vllm.sampling_params import SamplingParams
from vllm.model_outputs import ModelOutputs, SequenceOutput
async def simulate_scheduler():
# 创建块管理器
cache_config = CacheConfig(
block_size=16,
gpu_memory_utilization=0.9,
swap_space=4,
)
block_manager = BlockManager(
cache_config=cache_config,
block_size=16,
num_gpus=1,
device_config=DeviceConfig(device="cuda"),
)
# 创建调度器配置
scheduler_config = SchedulerConfig(
max_num_seqs=256,
max_model_len=4096,
max_batch_size=8,
)
# 创建调度器
scheduler = Scheduler(
scheduler_config=scheduler_config,
block_manager=block_manager,
num_gpus=1,
)
# 创建采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.95,
max_tokens=4,
)
# 添加请求
for i in range(15):
request = Request(
request_id=i,
prompt=f"Hello, this is request {i}.",
prompt_token_ids=list(range(10 + i)), # 不同长度的token IDs
sampling_params=sampling_params,
arrival_time=time.time(),
)
await scheduler.add_request(request)
# 模拟调度循环
completed_requests = []
step = 0
while len(completed_requests) < 15 and step < 20:
print(f"\n--- Step {step} ---")
# 调度批处理
batch = await scheduler.schedule()
if batch:
print(f"Scheduled batch with {len(batch.requests)} requests:")
for request in batch.requests:
print(f" - Request {request.request_id} (priority: {request.priority}, len: {len(request.prompt_token_ids)})")
# 模拟模型执行(生成随机输出)
model_outputs = simulate_model_outputs(batch)
# 处理模型输出
new_completed = await scheduler.process_model_outputs(batch, model_outputs)
completed_requests.extend(new_completed)
print(f"Completed {len(new_completed)} requests in this step.")
else:
print("No batch could be scheduled.")
step += 1
await asyncio.sleep(0.1) # 模拟处理时间
print(f"\n--- Simulation Complete ---")
print(f"Total completed requests: {len(completed_requests)}")
print(f"Total steps: {step}")
def simulate_model_outputs(batch: Batch) -> ModelOutputs:
"""Simulate model outputs for a batch."""
# 创建模拟的序列输出
sequence_outputs = []
for request in batch.requests:
# 模拟生成一个token
generated_token = 42 # 示例token ID
# 检查是否达到最大生成长度
is_finished = len(request.output_token_ids) >= request.sampling_params.max_tokens
sequence_output = SequenceOutput(
request_id=request.request_id,
generated_token=generated_token,
logprobs={generated_token: 0.9},
is_finished=is_finished,
)
sequence_outputs.append(sequence_output)
# 创建模型输出
model_outputs = ModelOutputs(
sequence_outputs=sequence_outputs,
kv_cache_offsets=[0] * len(batch.requests),
)
return model_outputs
# 运行模拟
asyncio.run(simulate_scheduler())运行命令:
python simulate_scheduler.py运行结果:
--- Step 0 ---
Scheduled batch with 8 requests:
- Request 0 (priority: 0, len: 10)
- Request 1 (priority: 0, len: 11)
- Request 2 (priority: 0, len: 12)
- Request 3 (priority: 0, len: 13)
- Request 4 (priority: 0, len: 14)
- Request 5 (priority: 0, len: 15)
- Request 6 (priority: 0, len: 16)
- Request 7 (priority: 0, len: 17)
Completed 0 requests in this step.
--- Step 1 ---
Scheduled batch with 8 requests:
- Request 0 (priority: 0, len: 10)
- Request 1 (priority: 0, len: 11)
- Request 2 (priority: 0, len: 12)
- Request 3 (priority: 0, len: 13)
- Request 4 (priority: 0, len: 14)
- Request 5 (priority: 0, len: 15)
- Request 6 (priority: 0, len: 16)
- Request 7 (priority: 0, len: 17)
Completed 0 requests in this step.
--- Step 2 ---
Scheduled batch with 8 requests:
- Request 0 (priority: 0, len: 10)
- Request 1 (priority: 0, len: 11)
- Request 2 (priority: 0, len: 12)
- Request 3 (priority: 0, len: 13)
- Request 4 (priority: 0, len: 14)
- Request 5 (priority: 0, len: 15)
- Request 6 (priority: 0, len: 16)
- Request 7 (priority: 0, len: 17)
Completed 0 requests in this step.
--- Step 3 ---
Scheduled batch with 8 requests:
- Request 0 (priority: 0, len: 10)
- Request 1 (priority: 0, len: 11)
- Request 2 (priority: 0, len: 12)
- Request 3 (priority: 0, len: 13)
- Request 4 (priority: 0, len: 14)
- Request 5 (priority: 0, len: 15)
- Request 6 (priority: 0, len: 16)
- Request 7 (priority: 0, len: 17)
Completed 8 requests in this step.
--- Step 4 ---
Scheduled batch with 7 requests:
- Request 8 (priority: 0, len: 18)
- Request 9 (priority: 0, len: 19)
- Request 10 (priority: 0, len: 20)
- Request 11 (priority: 0, len: 21)
- Request 12 (priority: 0, len: 22)
- Request 13 (priority: 0, len: 23)
- Request 14 (priority: 0, len: 24)
Completed 0 requests in this step.
--- Step 5 ---
Scheduled batch with 7 requests:
- Request 8 (priority: 0, len: 18)
- Request 9 (priority: 0, len: 19)
- Request 10 (priority: 0, len: 20)
- Request 11 (priority: 0, len: 21)
- Request 12 (priority: 0, len: 22)
- Request 13 (priority: 0, len: 23)
- Request 14 (priority: 0, len: 24)
Completed 0 requests in this step.
--- Step 6 ---
Scheduled batch with 7 requests:
- Request 8 (priority: 0, len: 18)
- Request 9 (priority: 0, len: 19)
- Request 10 (priority: 0, len: 20)
- Request 11 (priority: 0, len: 21)
- Request 12 (priority: 0, len: 22)
- Request 13 (priority: 0, len: 23)
- Request 14 (priority: 0, len: 24)
Completed 0 requests in this step.
--- Step 7 ---
Scheduled batch with 7 requests:
- Request 8 (priority: 0, len: 18)
- Request 9 (priority: 0, len: 19)
- Request 10 (priority: 0, len: 20)
- Request 11 (priority: 0, len: 21)
- Request 12 (priority: 0, len: 22)
- Request 13 (priority: 0, len: 23)
- Request 14 (priority: 0, len: 24)
Completed 7 requests in this step.
--- Simulation Complete ---
Total completed requests: 15
Total steps: 8代码分析:这个示例展示了如何:
- 创建调度器和相关组件
- 添加多个请求
- 模拟调度循环
- 处理模型输出
- 收集和输出结果
3.7 统计信息收集
统计信息收集是调度器的重要功能,它负责收集和分析调度器的运行状态:
class StatsCollector:
"""Collects statistics about the scheduler."""
def __init__(self):
"""Initialize the stats collector."""
self.num_requests_added = 0
self.num_batches_scheduled = 0
self.num_requests_completed = 0
self.total_wait_time = 0.0
self.total_tokens_generated = 0
self.batch_size_distribution = defaultdict(int)
self.start_time = time.time()
def record_request_added(self, request: Request) -> None:
"""Record that a request was added."""
self.num_requests_added += 1
def record_batch_scheduled(self, batch: Batch) -> None:
"""Record that a batch was scheduled."""
self.num_batches_scheduled += 1
self.batch_size_distribution[len(batch.requests)] += 1
def record_batch_completed(self, batch: Batch, outputs: ModelOutputs, completed_requests: List[RequestOutput]) -> None:
"""Record that a batch was completed."""
# 更新完成的请求数
self.num_requests_completed += len(completed_requests)
# 更新总等待时间
current_time = time.time()
for request in batch.requests:
self.total_wait_time += current_time - request.arrival_time
# 更新总生成token数
for output in completed_requests:
self.total_tokens_generated += len(output.token_ids)
def get_summary(self) -> dict:
"""Get a summary of the statistics."""
elapsed_time = time.time() - self.start_time
return {
"num_requests_added": self.num_requests_added,
"num_batches_scheduled": self.num_batches_scheduled,
"num_requests_completed": self.num_requests_completed,
"total_wait_time": self.total_wait_time,
"avg_wait_time": self.total_wait_time / self.num_requests_completed if self.num_requests_completed else 0,
"total_tokens_generated": self.total_tokens_generated,
"tokens_per_second": self.total_tokens_generated / elapsed_time if elapsed_time > 0 else 0,
"requests_per_second": self.num_requests_completed / elapsed_time if elapsed_time > 0 else 0,
"avg_batch_size": sum(k * v for k, v in self.batch_size_distribution.items()) / self.num_batches_scheduled if self.num_batches_scheduled else 0,
"batch_size_distribution": dict(self.batch_size_distribution),
"elapsed_time": elapsed_time,
}统计信息分析:统计信息收集器收集的信息包括:
- 请求相关统计(添加数、完成数)
- 批处理相关统计(调度数、平均大小、大小分布)
- 性能相关统计(等待时间、生成token数、吞吐量)
4. 与主流方案深度对比
4.1 与TensorRT-LLM 调度器对比
对比维度 | vLLM Scheduler | TensorRT-LLM Scheduler |
|---|---|---|
批处理机制 | 持续批处理 | 静态批处理 |
调度算法 | 贪心+延迟敏感 | 基于优先级的静态调度 |
资源管理 | 动态块分配 | 静态内存分配 |
分布式支持 | 原生支持 | 需要手动配置 |
灵活性 | 高度可配置 | 相对固定 |
性能 | 高吞吐,低延迟 | 极高性能,优化更极致 |
易用性 | 简单API | 配置复杂 |
4.2 与Hugging Face TGI 调度器对比
对比维度 | vLLM Scheduler | TGI Scheduler |
|---|---|---|
批处理机制 | 持续批处理 | 静态批处理 |
调度算法 | 多策略组合 | 基于FIFO |
资源管理 | 动态块分配 | 动态内存分配 |
优先级支持 | 完整支持 | 有限支持 |
分布式支持 | 原生支持 | 需要额外配置 |
性能 | 更高吞吐 | 良好性能 |
易用性 | 简单API | 简单API |
4.3 与DeepSpeed-MII 调度器对比
对比维度 | vLLM Scheduler | DeepSpeed-MII Scheduler |
|---|---|---|
批处理机制 | 持续批处理 | 静态批处理 |
调度算法 | 多策略组合 | 基于优先级 |
资源管理 | 动态块分配 | ZeRO优化 |
分布式支持 | 原生支持 | 基于DeepSpeed分布式 |
模型兼容性 | 专注于LLM | 支持多种模型类型 |
性能 | 高吞吐,低延迟 | 良好性能 |
易用性 | 简单API | 中等复杂度 |
5. 实际工程意义、潜在风险与局限性分析
5.1 实际工程意义
scheduler.py的设计和实现对实际工程应用具有重要意义:
- 高吞吐低延迟:通过持续批处理和高效的调度算法,vLLM scheduler可以实现极高的吞吐量和较低的延迟,满足生产级应用需求。
- 良好的资源利用率:通过动态块分配和内存管理,vLLM scheduler可以高效利用GPU内存和KV缓存,支持更大的上下文长度和更多的并发请求。
- 灵活的配置选项:vLLM scheduler提供了丰富的配置选项,可以根据不同的应用场景进行优化。
- 良好的扩展性:vLLM scheduler支持分布式部署,可以扩展到多GPU和多节点场景。
- 活跃的社区支持:作为开源项目,vLLM拥有活跃的社区和持续的更新,确保了调度器的可靠性和先进性。
5.2 潜在风险
使用scheduler.py时需要注意以下潜在风险:
- 调度延迟风险:在极端情况下,某些低优先级请求可能会经历较长的调度延迟。
- 资源争用风险:在高并发场景下,可能出现资源争用,影响整体性能。
- 算法复杂度风险:复杂的调度算法可能会带来额外的计算开销。
- 分布式通信瓶颈:在大规模分布式部署中,通信开销可能成为性能瓶颈。
- 配置复杂性风险:丰富的配置选项可能会增加使用难度,需要深入理解才能进行优化。
5.3 局限性
scheduler.py目前还存在一些局限性:
- 对特定硬件的依赖:某些优化特性仅支持NVIDIA GPU。
- 缺乏自适应调度:目前的调度算法主要是基于规则的,缺乏自适应调整能力。
- 多模态支持有限:虽然支持多模态推理,但调度策略还不够优化。
- 监控和调试工具不足:缺乏完善的监控和调试工具,不利于问题定位和性能优化。
- 文档不够详细:对于高级特性的文档支持不足,需要深入阅读源码。
6. 未来趋势展望与个人前瞻性预测
6.1 未来发展趋势
基于scheduler.py的当前设计和行业发展趋势,我预测vLLM scheduler未来将向以下方向发展:
- 更智能的调度算法:引入机器学习驱动的调度算法,实现自适应调度。
- 更好的延迟控制:优化调度策略,确保低延迟敏感请求得到优先处理。
- 更完善的多模态支持:针对多模态推理场景优化调度策略。
- 更好的监控和调试工具:提供完善的监控和调试工具,便于性能分析和问题定位。
- 更广泛的硬件支持:扩展对更多硬件平台的支持,包括AMD GPU、TPU等。
- 更好的生态集成:与更多框架和工具集成,如Kubernetes、Prometheus等。
6.2 个人前瞻性预测
作为一名大模型推理领域的从业者,我对scheduler.py的未来发展有以下前瞻性预测:
- 调度器的标准化:未来几年,推理调度器将逐渐标准化,形成统一的API和接口规范。
- AI驱动的调度优化:通过机器学习算法自动优化调度策略,适应动态的工作负载。
- 边缘设备支持:调度器将逐渐支持边缘设备,实现端到端的大模型推理。
- 绿色调度:优化调度策略,降低推理过程的能源消耗,实现更环保的大模型推理。
- 服务网格集成:调度器将与服务网格集成,实现更智能的流量管理和负载均衡。
6.3 对行业的影响
scheduler.py的发展将对大模型推理行业产生深远影响:
- 降低推理成本:通过高效的调度和资源管理,降低大模型推理的硬件成本和能源消耗。
- 促进大模型普及:高效的调度器可以支持更多的并发请求,促进大模型在更多领域的应用。
- 推动推理技术创新:作为开源项目,vLLM scheduler将推动推理调度技术的持续创新和发展。
- 加速AI产业化进程:高效的调度器是AI产业化的关键基础设施,将加速AI技术的落地和应用。
参考链接:
- vLLM GitHub Repository
- vLLM Documentation
- Continuous Batching for Large Language Models
- PagedAttention: Efficient Memory Management for Long Context LLMs
附录(Appendix):
附录A:scheduler.py 核心类关系图
附录B:scheduler.py 配置参数表
配置参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
max_num_seqs | int | 256 | 最大并发序列数 |
max_model_len | int | 4096 | 最大模型长度 |
max_batch_size | int | 32 | 最大批处理大小 |
schedule_interval_us | int | 1000 | 调度间隔(微秒) |
priority_weight | float | 1.0 | 优先级权重 |
latency_weight | float | 0.5 | 延迟权重 |
throughput_weight | float | 0.5 | 吞吐量权重 |
enable_priority_scheduling | bool | True | 是否启用优先级调度 |
enable_batch_sorting | bool | True | 是否启用批处理排序 |
附录C:调度器性能指标
指标名称 | 描述 | 计算公式 |
|---|---|---|
吞吐量 | 每秒处理的请求数 | 完成请求数 / 总时间 |
延迟 | 请求从提交到完成的平均时间 | 总等待时间 / 完成请求数 |
批处理效率 | 平均批处理大小 | 总请求数 / 批处理数 |
GPU利用率 | GPU的平均使用率 | 运行时间 / 总时间 |
内存利用率 | GPU内存的平均使用率 | 平均内存使用量 / 总内存 |
令牌吞吐量 | 每秒生成的令牌数 | 总生成令牌数 / 总时间 |
关键词: vLLM, 调度器, scheduler.py, 持续批处理, 资源分配, 优先级调度, 大模型推理, 高吞吐低延迟
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号