LLaMA Factory 详解

LLaMA Factory 详解

Dragon水魅
发布于 2026-01-23 20:30:24
发布于 2026-01-23 20:30:24
前言
本文不涉及 LLaMA Factory 的具体使用,而仅仅是对 LLaMA Factory 其中各种参数设定等功能进行详解。
LLaMA Factory 快速使用:使用 LLaMA Factory 微调一个 Qwen3-0.6B 猫娘
本文重点参考 code秘密花园 的教程,因其过于繁琐,故用本人阅读喜好重写笔记,用作留存。
原版教程:从零教你微调一个专属领域大模型,看完小白也能学会炼丹!(完整版)
LLaMA Factory WebUI
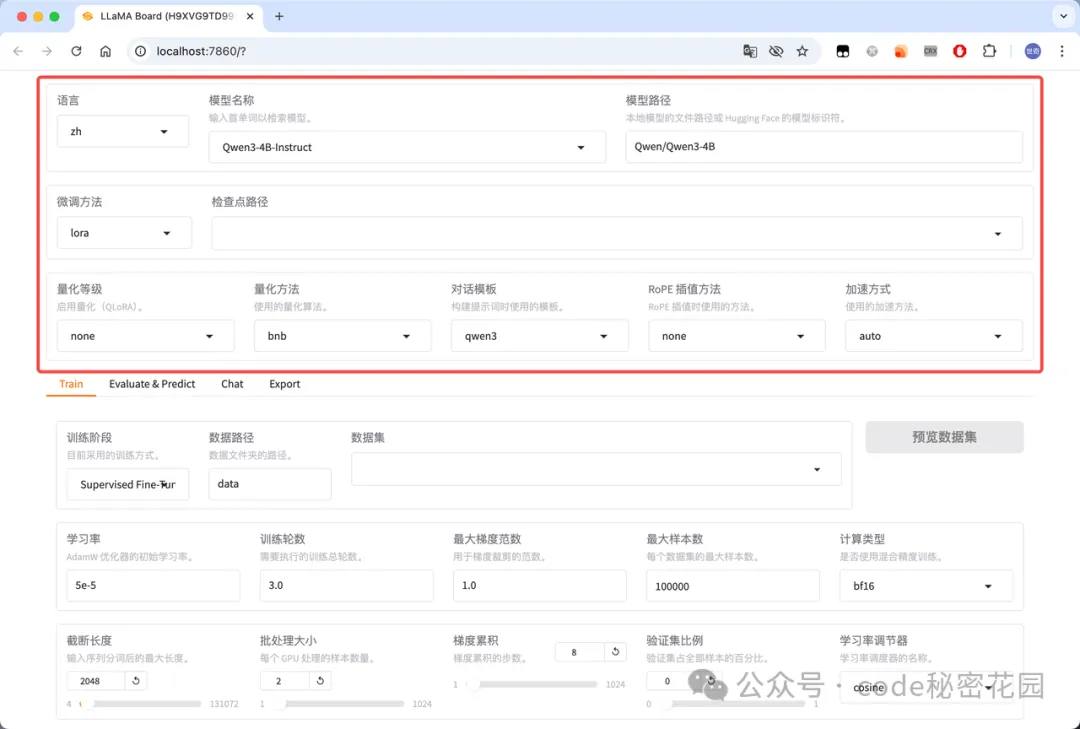
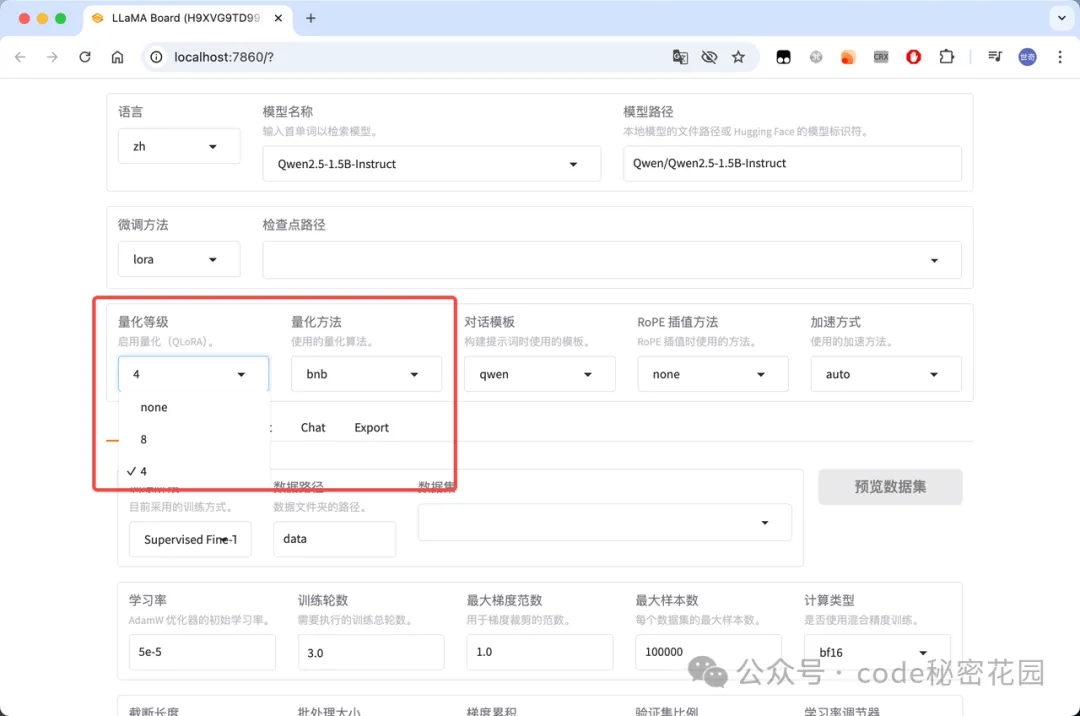
- 通用设置:可以设置 WebUI 展示的语言、需要微调的模型、微调的方法、是否量化、微调的加速方式等配置:
在这里插入图片描述
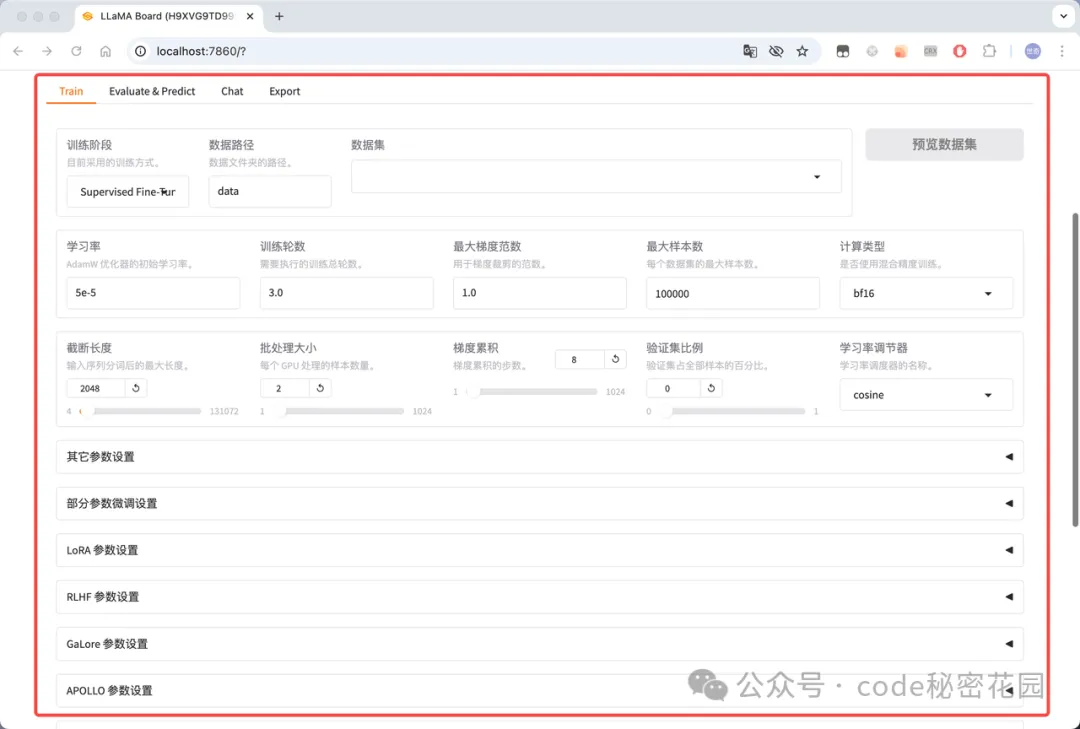
- 微调训练:包括以下几部分配置:
- 微调训练的阶段:预训练、指令微调、强化学习等等;
- 微调使用的数据集:数据集的格式、路径、验证集的比例等等;
- 关键微调参数:在我们之前教程中重点学习的:学习率、训练轮数、批量 大小等等;
- LoRA 参数:当使用 Lora 微调时需要配置的一些特殊参数;
- RLHF 参数:当训练阶段为强化学习时需要配置的一些特殊参数;
- 特殊优化参数:当选择使用 GaLore、APOLLO 和 BAdam 优化器时需要配置的一些参数;
- SwanLab 参数:一款开源的模型训练跟踪与可视化工具;
 在这里插入图片描述
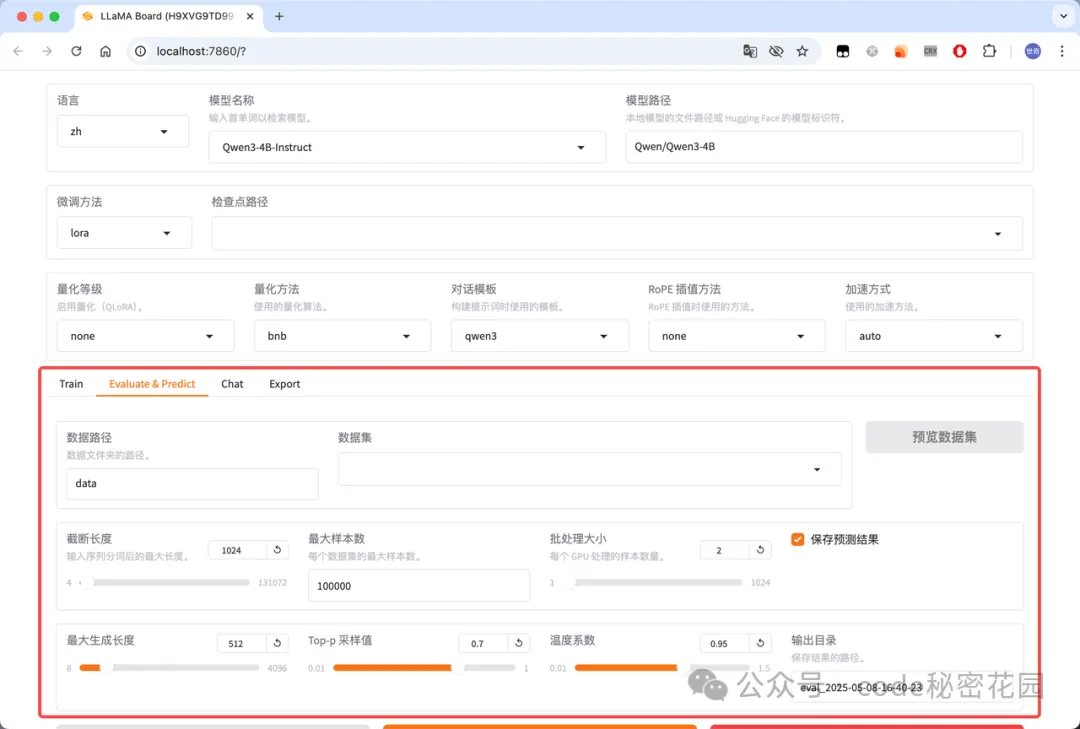
在这里插入图片描述 - 模型评估:在完成模型训练后,可以通过此模块来评估模型效果,这里可配置模型评估所需的数据集等:
在这里插入图片描述
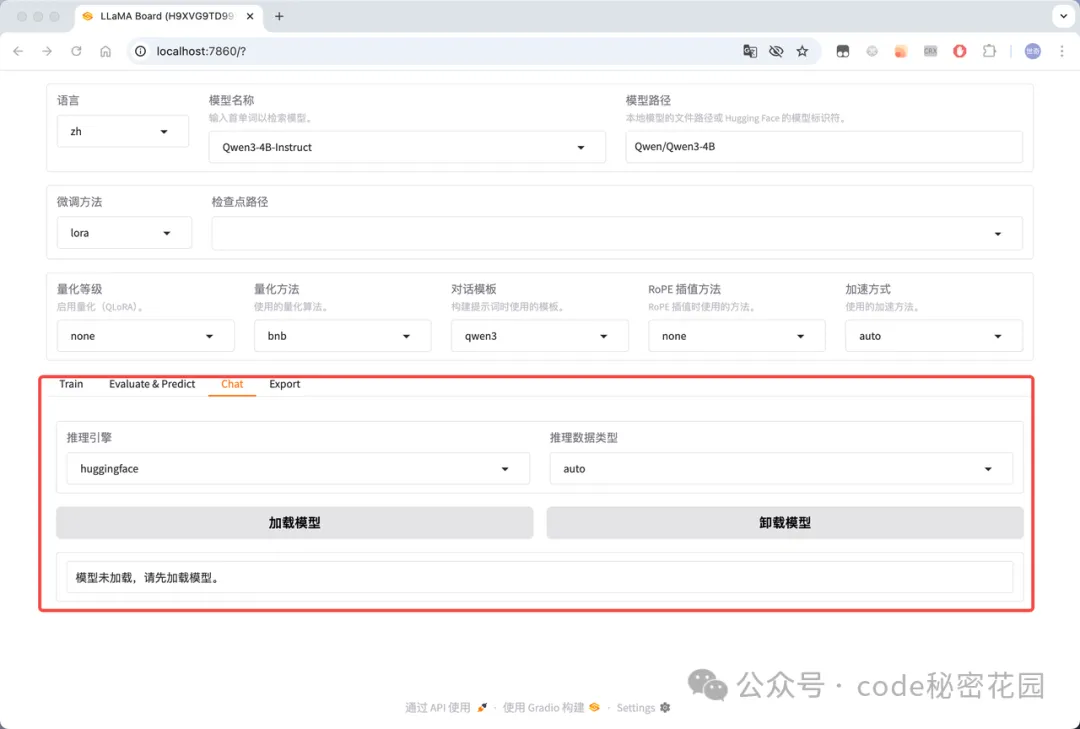
- 在线推理:可以选择使用 huggingface、vllm 等推理引擎和模型在线聊天,主要用来测试加载模型:
在这里插入图片描述
- 模型导出:可以指定模型、适配器、分块大小、导出量化等级及校准数据集、导出设备、导出目录等。
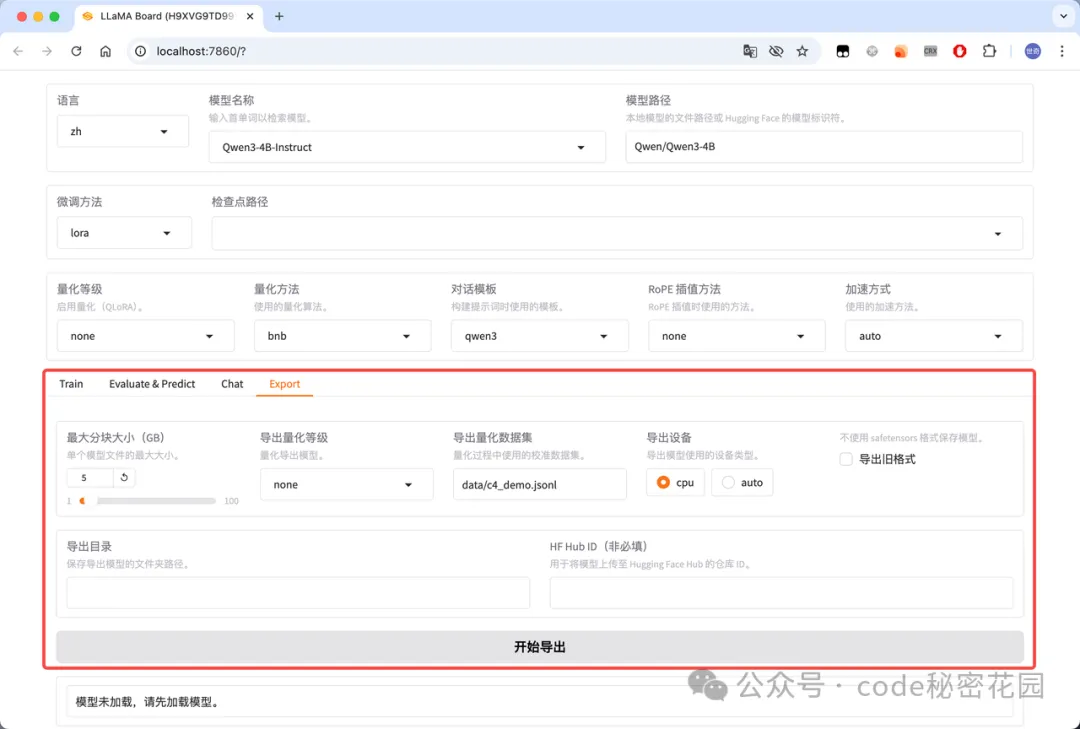
在这里插入图片描述
LLaMA Factory 微调通用设置
基座选择
分类 | 标识 | 含义 | 示例(模型名称) |
|---|---|---|---|
功能开发与任务类型 | -Base | 基础模型,未经过特定任务微调,提供原始能力(用于二次开发)。 | Qwen3-14B-Base |
-Chat | 对话优化模型,支持交互式聊天、问答,不针对特定任务微调。 | DeepSeek-LLM-7B-Chat | |
-Instruct | 指令微调模型,擅长遵循具体任务指令(推理、生成、翻译等)。 | Qwen3-0.6B-Instruct | |
-Distill | 知识蒸馏模型,通过蒸馏技术压缩,模型更小、推理更高效。 | DeepSeek-R1-1.5B-Distill | |
-Math | 专注数学推理任务,优化数值计算、公式推导、逻辑证明等能力。 | DeepSeek-Math-7B-Instruct | |
-Coder | 针对代码生成、编程任务优化,支持代码补全、漏洞检测、算法实现等。 | DeepSeek-Coder-V2-16B | |
多模态 | -VL | 视觉-语言多模态(Vision-Language),支持图文联合输入输出。 | Kimi-VL-3B-Instruct |
-Video | 视频多模态模型,结合视频帧与文本进行交互。 | LLaVA-NeXT-Video-7B-Chat | |
-Audio | 支持音频输入,涉及语音识别(ASR)或语音合成(TTS)。 | Qwen2-Audio-7B | |
技术特性与存在优化 | -Int8/-Int4 | 权重量化模型(Int8为8位,Int4为4位),降低显存占用,提升推理速度(适合低资源设备)。 | Qwen2-VL-2B-Instruct-GPTQ-Int8 |
-AWQ/-GPTQ | 特定量化技术(自适应权重/GPT量化),优化低精度下的模型性能。 | Qwen2.5-VL-7B-Instruct-AWQ | |
-MoE | 混合专家模型(Mixture of Experts),包含多个专用模块处理复杂任务。 | DeepSeek-MoE-16B-Chat | |
-RL | 使用强化学习(Reinforcement Learning)优化,提升对话质量或任务响应。 | MiMo-7B-Instruct-RL | |
版本与变体标识 | -v0.1/-alpha/beta | 模型版本号,标识开发阶段(alpha/beta/正式版)。 | Mistral-7B-v0.1 |
-Pure | 纯净版模型,去除领域数据或保留原始能力,避免特定偏见。 | Index-1.9B-Base | |
-Character | 角色对话模型,支持角色扮演或特定人设(如虚拟助手、动漫角色)。 | Index-1.9B-Character-Chat | |
-Long-Chat | 支持长上下文对话(通常≥4k tokens),处理超长输入输出。 | Orion-14B-Long-Chat | |
领域与应用标识 | -RAG | 检索增强生成模型,结合外部知识库检索与生成能力。 | Orion-14B-RAG-Chat |
-Chinese | 中文优化版本,支持中文分词、方言、拼音纠错等本土化能力。 | Llama-3-7B-Chinese-Chat | |
-MT | 机器翻译专用模型,支持多语言翻译任务(如中英、英日互译)。 | BLOOMZ-7B1-mt |
微调方法
Full(全参)
- 全参数微调是最直接的迁移学习方法,通过在目标任务数据上继续训练预训练模型的全部参数。
- 通俗理解:就好比把一栋房子彻底拆掉重建。预训练模型就像已经建好的房子,里面的每一块砖、每一根梁,在全参数微调时都要重新调整。例如,当我们想用一个原本用于识别普通图片的模型,改造为识别医学影像的模型时,就要把模型里所有参数都更新一遍。
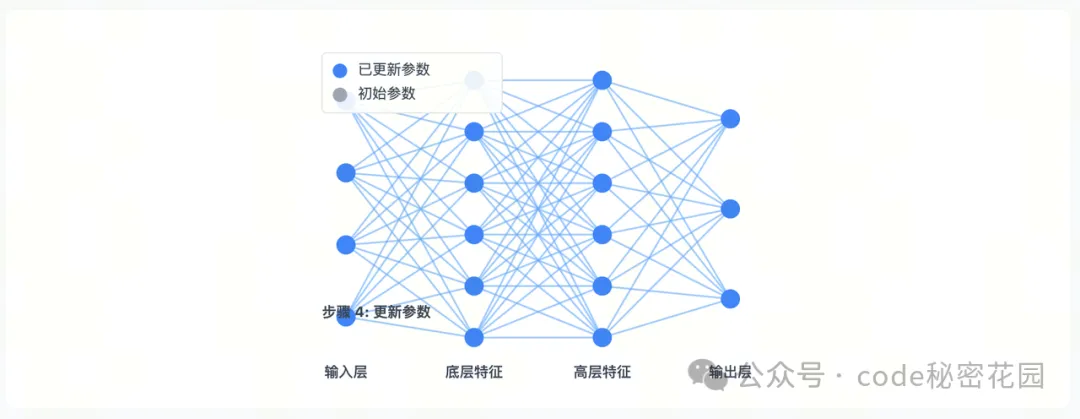
在这里插入图片描述
- 优点
- 最大化性能:通常能够在目标任务上达到最佳性能
- 完全适应性:允许模型充分适应新任务的特性
- 灵活性:可以用于各种不同的下游任务
- 实现简单:概念直接,实现相对简单
- 缺点
- 计算资源需求高:需要大量GPU内存和计算能力
- 存储成本高:每个任务都需要保存一个完整模型副本
- 灾难性遗忘:可能会丢失原始预训练中获得的知识
- 过拟合风险:在小数据集上容易过拟合
- 不适合低资源场景:在资源受限设备上难以部署
全参数微调适用场景:有充足的计算资源、需要最大化模型性能、目标任务与预训练任务有显著差异、 或有足够的任务数据可以有效训练所有参数。
Freeze(冻结)
- 参数冻结微调通过选择性地冻结模型的某些部分,只更新剩余参数,从而减少计算量并防止过拟合。
- 通俗理解:像是给房子做局部装修。我们保留房子的框架结构,只对部分区域进行改造。在模型中,就是保留预训练模型的底层结构,只调整顶层的部分参数。比如在训练一个糖尿病问答模型时,我们可以把语言模型的前 24 层参数冻结起来,只训练最后 3 层专门用于医学领域问答的分类器。
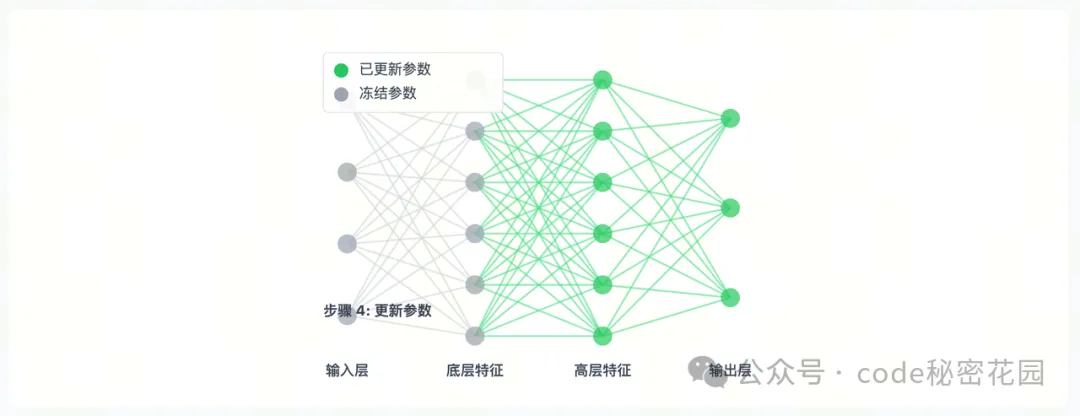
在这里插入图片描述
- 优点
- 计算效率:减少需要计算的参数数量,加快训练速度
- 内存效率:反向传播中不需要存储冻结参数的梯度
- 防止过拟合:特别适合小型数据集训练
- 保留通用特征:防止破坏预训练模型中有价值的通用特征
- 减少灾难性遗忘:保持模型的泛化能力
- 缺点
- 性能可能次优:在某些任务上可能无法达到全参数微调的性能
- 需要专业知识:选择哪些层冻结需要对模型架构有深入了解
- 灵活性降低:在任务与预训练差异大时效果可能不佳
- 调优困难:找到最佳的冻结点可能需要多次实验
参数冻结微调适用场景:计算资源受限的环境、训练数据集较小、目标任务与预训练任务相似、模型主要需要学习任务特定的表示、需要防止过拟合。
LoRA(低秩矩阵)
- LoRA 通过向预训练模型中注入小型、可训练的低秩矩阵,在保持原始参数不变的情况下实现高效微调。
- 通俗理解:可以想象成给房子安装智能设备,不改变房子的原有结构,却能让房子变得更智能。在模型里,它不会直接修改原有的参数,而是在关键位置插入可训练的 “小模块”。
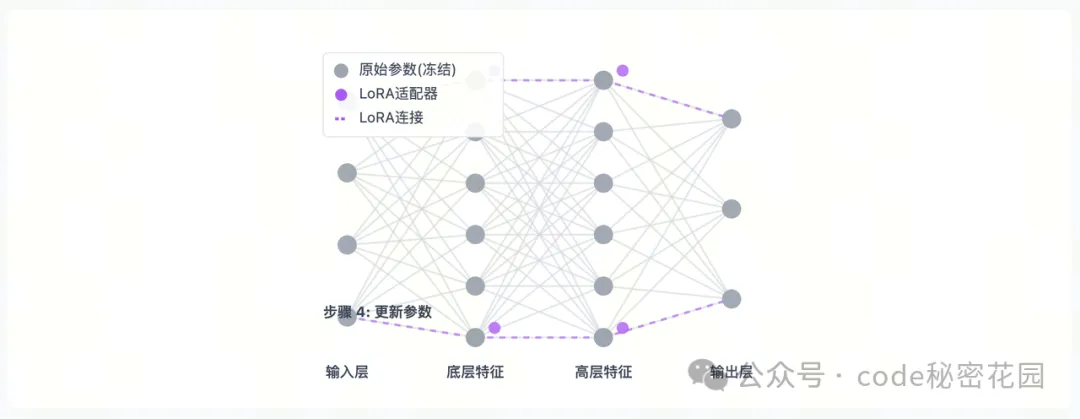
在这里插入图片描述
- 优点
- 极高的参数效率:训练参数数量减少99%以上
- 内存效率:大幅降低GPU内存需求
- 训练速度快:减少计算量,加快收敛
- 存储高效:每个任务只需保存小型适配器
- 可组合性:不同任务的适配器可以组合使用
- 避免灾难性遗忘:原始参数保持不变
- 缺点
- 性能上限:在某些复杂任务上可能弱于全参数微调
- 秩超参数选择:需要为不同模型和任务调整适当的秩
- 实现复杂性:比简单的微调方法实现更复杂
- 不是所有层都适合:某些特殊层可能不适合低秩适应
- 推理稍复杂:需要额外处理原始模型和适配器的组合
Lora 微调适用场景:计算资源有限、需快速适配新任务(如多任务切换)、追求轻量化模型部署与分享、目标任务和预训练任务存在中等差异、多模态任务场景、需频繁基于新数据迭代优化的场景。
对比和总结
比较指标 | FULL PARAMETER | FREEZE | LORA |
|---|---|---|---|
参数数量 | 100% 所有参数都参与训练 | 10-50% 仅顶层参数参与训练 | <1% 只训练低秩适配矩阵 |
内存消耗 | 高 需要存储所有参数的梯度 | 中 仅需存储部分参数梯度 | 低 只存储少量适配器参数梯度 |
训练速度 | 慢 更新所有参数,计算量大 | 中 更新部分参数,速度适中 | 快 仅更新小量参数,速度快 |
存储需求 | 高 每个任务需保存完整模型 | 高 仍需保存完整模型 | 低 只需保存小型适配器 |
性能上限 | 最高 理论上能达到最佳性能 | 中高 取决于冻结策略 | 中高 接近全参数微调但有差距 |
灾难性遗忘 | 高风险 可能丢失预训练知识 | 低风险 底层知识得到保留 | 极低风险 原始参数完全保留 |
多任务支持 | 困难 每个任务需要一个完整模型 | 中等 通常仍需一个模型一个任务 | 简单 只需切换适配器都即可切换任务 |
实现复杂度 | 简单 直接训练全部参数 | 中等 需要选择冻结策略 | 较复杂 需要实现低秩适配架构 |
各微调方法各有优劣势:全参数微调性能最优但计算资源需求高;参数冻结提供了性能和效率的平衡;LoRA则在极高的参数效率下提供接近全参数微调的性能。选择何种方法应基于具体任务需求,可用资源和性能要求。
模型量化
在这里插入图片描述
模型的量化还有蒸馏,其实都是属于模型压缩的常见方法。对于一些大参数模型,比如前段时间非常火的 DeepSeek-R1 满血版具有 6710 亿个参数、最新的 Qwen3 满血版有 2350 亿个参数,它们都是各自公司下的旗舰版模型,具备着最先进的能力。但是由于参数量巨大,普通的小公司或者个人想要在本地部署模型需要的成本是非常高的,所以我们一般会选择使用量化、蒸馏这些手段对模型进行压缩,从而在损失一定精度的情况下减小模型的部署成本。
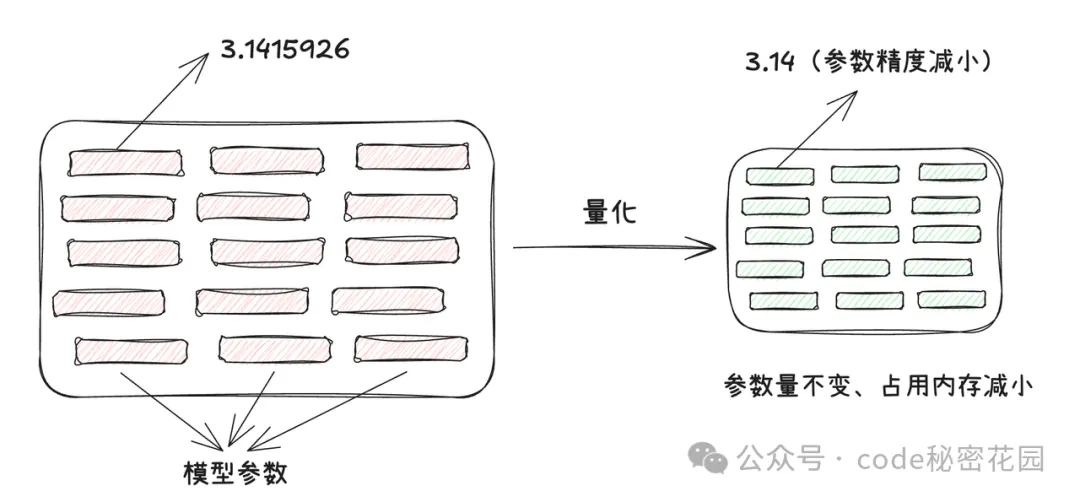
模型量化是一种通过降低权重和激活值的精度来减小模型尺寸、加快推理速度,同时尽量保持模型准确率的技术。简单来说,就是用更少的数字位数来表示模型中的数据。
通俗理解:想象一下从无损音乐(FLAC)到压缩音乐(MP3)的转换。无损音乐就像 FP32 模型,保存了所有细节,但文件很大。MP3 就像量化后的INT8模型,牺牲了一些人耳难以察觉的细节,但大幅减小了文件体积。不同的比特率 (320kbps、128kbps等) 就像不同等级的量化 (INT8、INT4等) 。
大模型本质上是由很多参数构成的,比如 DeepSeek-R1 满血版具有 6710 亿个参数。大模型通常是基于深度学习的神经网络架构,由大量的神经元和连接组成。这些参数主要包括神经元之间的连接权重以及偏置项等。在模型的训练过程中,这些参数会通过反向传播算法等优化方法不断调整和更新,以最小化损失函数,从而使模型能够学习到数据中的规律和特征。而在计算机中,这些参数是以数字的形式存储和计算的,通常使用浮点数(如单精度浮点数 float32 或双精度浮点数 float64)来表示,以在精度和计算效率之间取得平衡。
在这里插入图片描述
为了表示这些参数,我们需要在计算机上开辟一些内存空间,开辟多大的内存空间就取决于这些参数存储的精度。如果参数的精度越低,所需的内存空间就越小,反之参数精度越高,所需内存空间就越大。比如我们把原本存储了 7 位小数的一个参数:3.1415926,转换成一个精度更低的值:3.14 来进行存储,很明显我们丢掉的精度仅仅为 0.0015926 ,但是我们却大大节省了存储空间,模型量化的本质其实就是把模型的参数从高精度转换成低精度的过程。
常用的精度单位有:
- FP:浮点(Floating Point),如 FP16、FP32,可以理解为科学计数法表示的数字,包含符号位、指数部分和尾数部分;优点:可表示范围广,精度高、缺点:占用空间较大。 计算机底层使用的是二进制存储(也就是只能存0 和 1)这里的 16、32 是二进制位数(bit),也就是计算机存储这个数时用了多少个 0 和 1。比如 FP32 就是用 32 个二进制位(4 字节,1 字节 = 8 位) 存一个浮点数。FP16 就是用 16 个二进制位(2 字节) 存一个浮点数。
- BF:脑浮点(Brain Floating Point),如 BF16,专为深度学习设计的浮点数格式,相比传统浮点数,在保持数值范围的同时减少精度,平衡了精度和范围的需求,兼顾精度与效率。
- INT:整数(Integer),如 INT8、INT4,用整数表示权重和激活值,压缩模型体积并加速推理。优点:结构简单,占用空间小、缺点:表示范围有限,精度丢失较多。
常见的模型参数的精度:
- FP32(单精度):32 位 = 1 位符号 + 8 位指数 + 23 位尾数,能够表示的精度范围是:±3.4×10³⁸ ;
- FP16(半精度):16 位 = 1 位符号 + 5 位指数 + 10 位尾数,能够表示的精度范围是: ±65,504;
- BF16(脑浮点):16 位 = 1 位符号 + 8 位指数 + 7 位尾数,范围与 FP32 相同(±3.4×10³⁸),但尾数更短;
- INT8:8 位二进制,有符号范围 - 128~127,无符号 0~255;
- INT4:4 位二进制,有符号范围 - 8~7,无符号 0~15。
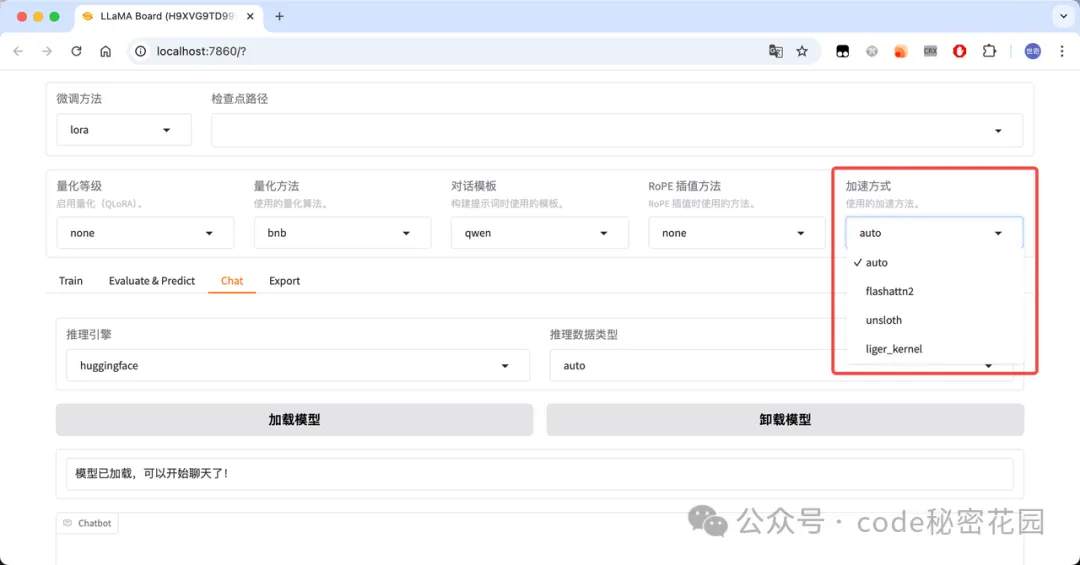
加速方式
在这里插入图片描述
比较熟悉的加速方式是 Unsloth,它默认就会采用动态的 4 位量化,这也是它一个非常重要的加速手段;我们在 LLaMA Factory 中将量化等级选择为 4 bit,然后加速方法选择 Unsloth 时,模型微调的速度与内存占用和直接使用 Unsloth 是相似的。
另外两种加速方式,大家做简单了解即可,如果你对微调性能没有过多要求,可以选择默认(默认会使用 Flash Attention 加速),如果本地硬件条件非常受限,可以选择启用 Unsloth + 4 位量化。
数据集
指令监督微调(SFT),在 LLaMA Factory 中主要支持 Alpaca 格式和 ShareGPT 两种格式:
- Alpaca 格式的指令微调数据集:

在这里插入图片描述
- ShareGPT 格式的指令微调数据集:

在这里插入图片描述
学习率(Learning Rate)
分类 | 说明 |
|---|---|
核心概念 | 学习率(Learning Rate)决定了模型在每次更新时参数调整的幅度,通常在 (0, 1) 之间。也就是告诉模型在训练过程中 “学习” 的速度有多快。学习率越大,模型每次调整的幅度就越大;学习率越小,调整的幅度就越小。 |
通俗理解 | 通俗来说,学习率可以用来控制复习的“深度”,确保不会因为调整幅度过大而走偏,也不会因为调整幅度过小而进步太慢。如果你每次复习完一道题后,你会根据答案和解析调整自己的理解和方法。学习率大(比如0.1):每次做完一道题后,你会对解题方法进行很大的调整。比如,你可能会完全改变解题思路。优点是进步可能很快,因为你每次都在进行较大的调整。缺点就是可能会因为调整幅度过大而“走偏”,比如突然改变了一个已经掌握得很好的方法,导致之前学的东西都忘了。学习率小(比如0.0001):每次做完一道题后,你只对解题方法进行非常细微的调整。比如,你发现某个步骤有点小错误,就只调整那个小错误。优点是非常稳定,不会因为一次错误而“走偏”,适合需要精细调整的场景。缺点就是进步会很慢,因为你每次只调整一点点。 |
个人经验 | 一般保持在 5e-5(0.00005) 和 4e-5(0.00004)之间,小数据集尽量不要用大学习率,不要担心速度慢,速度快了反而会影响微调跳过(如果是全参数微调,由于所有参数都会参与更新,为了防止原始知识被破坏,需要采用更小的学习率,一般比 Lora 的学习率小一个数量级)。 |
显存影响 | 几乎无影响。 |
本次取值 | 5e-5 (即 0.00005) |
训练轮数(Number of Epochs)
分类 | 说明 |
|---|---|
核心概念 | 训练轮数(Number of Epochs)Epoch 是机器学习中用于描述模型训练过程的一个术语,指的是模型完整地遍历一次整个训练数据集的次数。换句话说,一个 Epoch 表示模型已经看到了所有训练样本一次。 |
通俗理解 | 通俗来说,训练轮数就是我们从头到尾复习一本教材的次数。轮数少:比如你只复习一遍,可能对书里的内容还不是很熟悉,考试成绩可能不会太理想。轮数多:比如你复习了 10 遍,对书里的内容就很熟悉了,但可能会出现一个问题——你对书里的内容背得很熟,但遇到新的、类似的问题就不会解答了,简单讲就是 “学傻了“,只记住这本书里的内容了,稍微变一变就不会了**(过拟合)**。 |
个人经验 | 一般情况下 3 轮就可以,在实际开始训练后,只要 LOSS 没有趋于平缓,就可以再继续加大训练轮数,反之如果 LOSS 开始提前收敛,就可以减小 Epoch 或者提前结束。注意不要把 LOSS 降的过低(趋近于零),训练轮数尽量不要超过 10 ,这两种情况大概率会导致过拟合(把模型练傻)。一般情况下,数据集越小,需越多 Epoch;数据集越大,需越少 Epoch,LOSS 控制在 0.5 -> 1.5 之间。 |
显存影响 | 几乎无影响。 |
本次取值 | 3 |
批量大小(Batch Size)
分类 | 说明 |
|---|---|
核心概念 | 批量大小(Batch Size) 是指在模型训练过程中,每次更新模型参数时所使用的样本数量。它是训练数据被分割成的小块,模型每次处理一个小块的数据来更新参数。 |
通俗理解 | 通俗来说,批量大小可以用来平衡复习速度和专注度,确保既能快速推进复习进度,又能专注细节。假设你决定每次复习时集中精力做一定数量的题目,而不是一次只做一道题。批量大(比如100):每次复习时,你集中精力做100道题。优点是复习速度很快,因为你每次处理很多题目,能快速了解整体情况(训练更稳定,易收敛到全局最优)。缺点是可能会因为一次处理太多题目而感到压力过大,甚至错过一些细节(耗显存,泛化能力差,易过拟合)。批量小(比如1):每次复习时,你只做一道题,做完后再做下一道。优点是可以非常专注,能仔细分析每道题的细节,适合需要深入理解的场景(省显存,易捕捉数据细节,泛化能力强)。缺点就是复习速度很慢,因为每次只处理一道题(训练不稳定,易陷入局部最优)。 |
显存影响 | 影响明显,批量大小越大,对显存消耗越大。 |
批量计算 | 在实际微调任务中,批量大小(Batch Size)一般是由(单CPU)批处理大小(Per Device Train Batch Size)和梯度累计步数(Gradient Accumulation Steps)共同决定的。(实际的批量大小:per_device_train_batch_size * gradient_accumulation_steps) |
批处理大小(Per Device Train Batch Size),就是每个 GPU 一次处理的样本数(比如 per_evice_train_batch_size=8,就是 1 块 GPU处理 8 条数据),在你只有一块 GPU,没有设定梯度累计步数的时候其实和批量大小就是一样的。 | |
梯度累计步数(Gradient Accumulation Steps)实际上是一个降低显存的优化手段,当我们显存不够用,但是又想采用大批量的时候,就可以加大梯度累积步数,从而实现分批次计算梯度然后累积进行更新。比如我们像设定批量大小为 6,但是我们的 CPU 显存只能支持到 2 了,这时候就可以把 **梯度累计步数 设置为 3 **,实际的步骤就是:1. 先算 2 个样本的梯度,不更新参数; 2. 再算 2 个样本的梯度,不更新参数; 3. 再算 2 个样本的梯度,与前两次累积后一起更新参数。 这样就能实现用小显存实现大 batch_size 的效果,类似于 “分期付款” 的效果。 | |
个人经验 | 一般情况下,大 batch_size 需搭配大学习率,小 batch_size 需搭配小学习率,对于一些小参数模型、小数据集的微调,单 GPU 批处理大小(Per Device Train Batch Size)建议从 2 甚至是 1 开始(要想省显存就直接设置 1),通过调大梯度累积步数(比如设置为 4 或者 8)来加快模型微调速度。 |
本次取值 | 批处理大小:1、梯度累计步数:8 |
截断长度(Cutoff length)
分类 | 说明 |
|---|---|
核心概念 | 截断长度(Max Length)决定了模型处理文本时能接收的最大 token 数量(token 是文本分块后的单元,如词语、子词)。它直接影响模型对上下文信息的捕获能力,同时制约计算资源的消耗。 |
显存影响 | 影响显著:截断长度每增加 1 倍,模型处理每个样本的显存消耗近似线性增长。例如:截断长度 1024 时,1 块 32GB 显存可能支持批量大小 16;截断长度增至 2048,同显存下批量大小可能需减半至 8,否则会因显存不足报错。 |
个人经验 | 为啥一定要设置截断长度呢?假定你的显存处理的单条数据的极限大小为 4096 个 Token,你大部分的训练数据都小于 4096 个 Token,但是其中有一条是 5000 Token,那么训练到这条数据时你的显存一定会爆掉,从而中断整个训练,所以设定一个合理的截断长度是非常有必要的。在实际训练中,不能为了省显存而把截断长度设定的过小,比如你的训练数据平均大小为 2048 个 Token,那你把截断长度也设定为了 2048 个 Token,那有接近一半的训练数据都将是被截断、不完整的,这会大大影响训练效果。在显存条件允许的情况下,最好的截断长度当然是设定为数据集中单条数据的最大 Token 数,但现实可能不允许,你可以去计算你的数据集 Token 长度的 P99、P95 的值,来根据你的显存大小逐步调整,当然这也就意味着有 1%、5% 的训练数据是不完整的,你也可以在训练前把这部分较长的数据集剔除出去,这样可以减小对训练效果的影响。 |
本次取值 | 4096 |
LoRA 秩(LoRA rank)
分类 | 说明 |
|---|---|
核心概念 | LoRA(低秩适应)中的秩(Rank)是决定模型微调时参数更新 “表达能力” 的关键参数。它通过低秩矩阵分解的方式,控制可训练参数的规模与模型调整的灵活程度。秩的数值越小,模型微调时的参数更新越 “保守”;秩的数值越大,模型能捕捉的特征复杂度越高,但也会消耗更多计算资源。 |
通俗理解 | 秩低(如 4):相当于用固定的几种 “思维模板” 学习新知识。比如学数学时,只记 3 种解题套路,遇到新题只能用这 3 种方法套。优点是学习过程很稳定,不容易学偏(过拟合风险低),且 “脑子”(显存)不费力;缺点是遇到复杂问题可能束手无策,因为模板太少(表达能力有限)。 秩高(如 64):相当于掌握了 100 种解题思路,遇到新题可以灵活组合方法。优点是能处理更复杂的任务(比如生成风格更细腻的内容),模型微调的 “潜力” 更大;缺点是容易学 “乱”—— 可能把无关的知识强行关联(过拟合),而且太费 “脑子”(显存消耗显著增加)。 |
个人经验 | 日常微调建议从 8-16 开始尝试,这是平衡效果与效率的常用区间。一般就是从 8 开始,如果微调完觉得模型没学会就调大,建议最低不要 < 8,小数据集不要调的过大。 |
显存影响 | 影响有限,例如对于 7B 模型,秩从 8 提升到 64,大概仅会增加 2GB 显存。 |
本次取值 | 4096 |
验证集比例(Val size)
分类 | 说明 |
|---|---|
核心概念 | 验证集比例是指从原始训练数据中划分出用于模型性能评估的子集比例(通常用 0-1 之间的小数表示)。这部分数据不参与模型训练,仅用于在训练过程中实时监控模型的泛化能力,避免过拟合。例如:验证集比例设为 0.2,表示将 20% 的数据作为验证集,80% 作为训练集。 |
通俗理解 | 一般来说,设不设置验证集是不影响模型的训练效果的,但是可以额外增加一条验证集的 LOSS 曲线,方便更好的观察模型微调的效果。 |
个人经验 | 小数据(<1000 样本):0.1-0.2,建议验证集样本数 ≥ 100(如 500 样本用 100 做验证);大数据(>10000 样本):0.05-0.1,建议验证集样本数 ≥ 1000 即可(如 10 万样本用 5000 做验证)。比较复杂的任务可适当提高比例,因需要更严格监控各类别的拟合情况;比较简单单任务可适当降低比例,避免浪费训练数据。 |
本次取值 | 0.15 |
LOSS(损失值)
在模型微调中,LOSS(损失函数)是一个可微的数学函数,它量化了模型预测结果与真实目标值之间的误差(输出为一个标量数值)。微调的核心目标就是通过优化算法(如梯度下降)持续最小化这个 LOSS 值:计算 LOSS 对模型参数的梯度,并据此调整参数,使预测误差不断减小。LOSS 值的高低直接反映了模型预测的准确性,其持续下降是学习过程有效的关键指标。
- LOSS 是什么?
- 简单说,LOSS 就是模型在微调过程中犯错误的“程度”的评分,它是一个数字。
- 怎么算出来的?
- 模型对一条数据做预测(比如判断图片是猫还是狗)。然后,我们把模型的预测结果和这条数据的正确答案拿出来对比。
- 对比什么?
- 对比模型“猜”得有多不准。猜得越离谱,这个错误评分(LOSS)就越大;猜得越接近正确答案,这个错误评分(LOSS)就越小。
- 微调时用它干什么?
- 微调的核心目标就是让模型少犯错。所以,微调过程就是想尽办法让这个 LOSS(错误评分)变得越来越小。
- 怎么变小?
- 模型内部有很多可以调整的小旋钮(参数)。微调算法会根据当前这个 LOSS 值,自动计算出应该拧哪些旋钮、往哪个方向拧(增大一点还是减小一点),才能让下次遇到类似数据时,错误评分(LOSS)降低一些。
- 为什么关心它?
- 在微调过程中,我们主要盯着 LOSS 的变化趋势。如果 LOSS 稳定地下降,说明模型的调整是有效的,它在学习,错误在减少。如果 LOSS 不降反升或者剧烈波动,就说明学习过程可能出了问题。
- 常见误区
- LOSS 曲线很好看(逐步下降趋于平缓),不代表模型最终的训练效果一定会好,它只能表示整个训练过程是没问题的。
几种常见的 LOSS 曲线

在这里插入图片描述
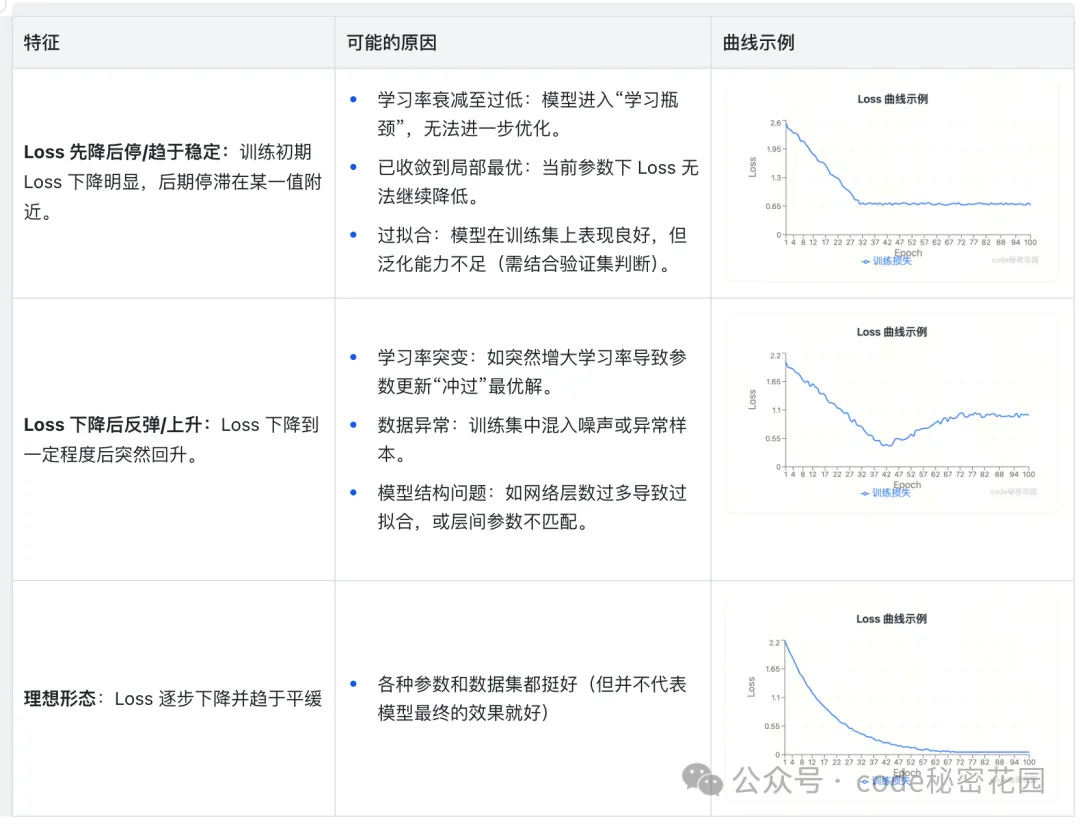
在这里插入图片描述
Train LOSS 与 Eval LOSS
当我们在微调参数中设定了一定的验证集比例,将会多生成一条 Eval LOSS 曲线,体现模型在验证集上的表现。
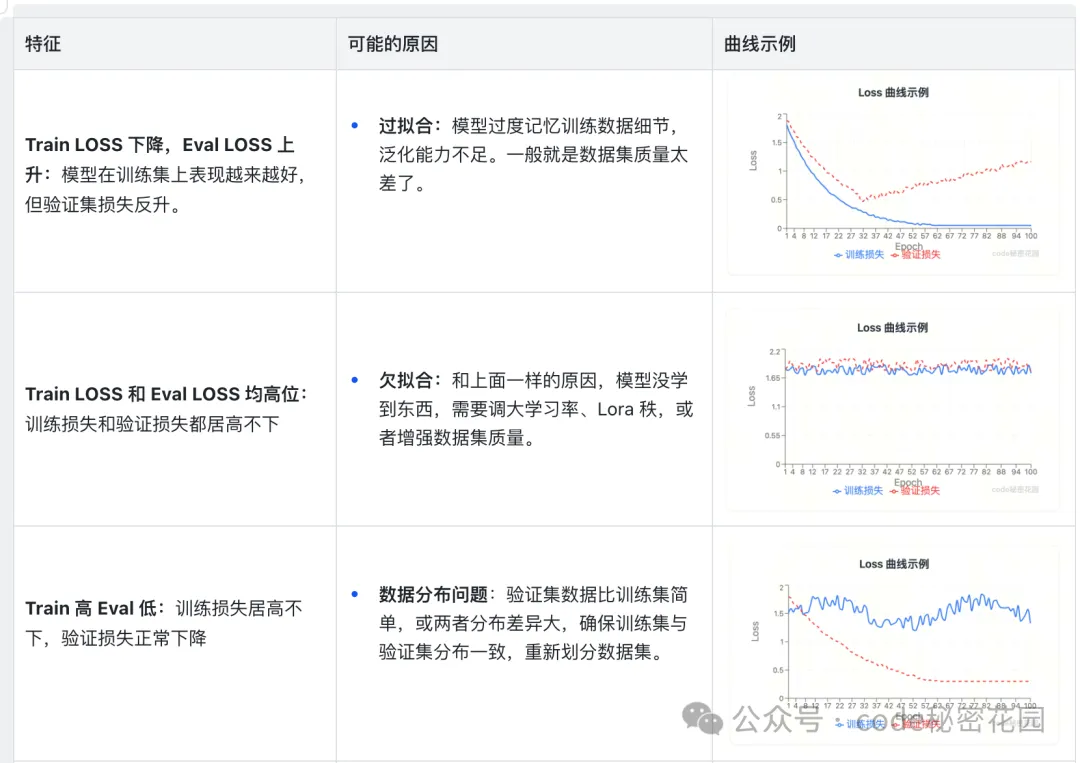
在这里插入图片描述
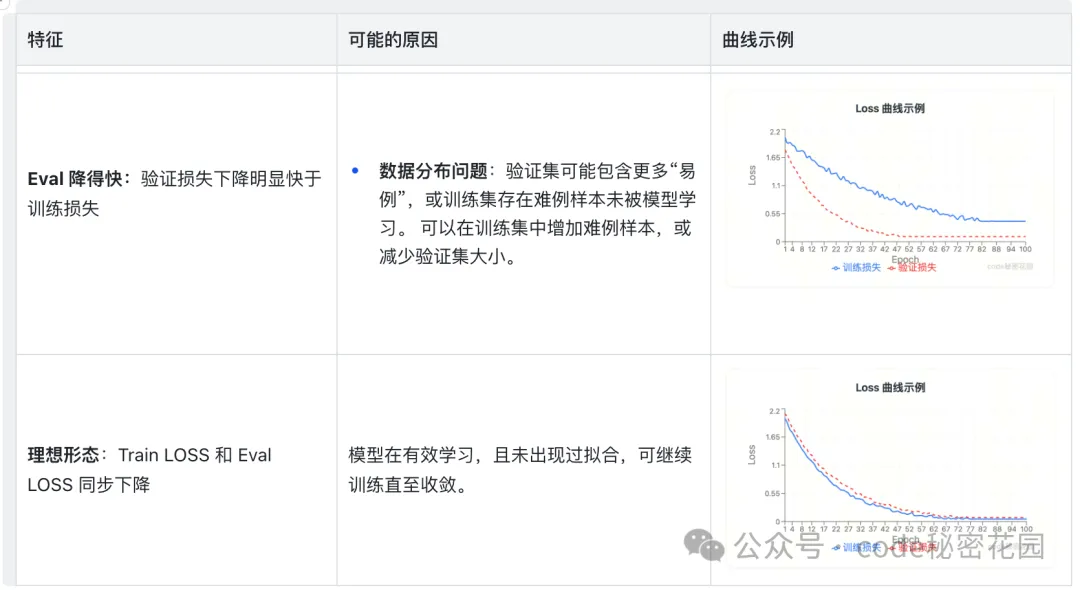
在这里插入图片描述
微调后模型使用及效果验证
输出目录
微调任务完成后,在设定的输出目录内,可以看到如下文件:
- 模型权重文件
- adapter_model.safetensors:LoRA 适配器的权重文件(核心增量参数)
- checkpoint-100/200/…:不同步数的训练检查点(含模型参数,用于恢复训练)
- 配置文件
- adapter_config.json:LoRA 训练配置(如秩、目标层等)
- tokenizer_config.json / special_tokens_map.json:分词器配置
- training_args.yaml / training_args.bin:训练超参数(学习率、批次等)
- 日志与结果
- trainer_log.jsonl / running_log.txt:训练过程日志
- all_results.json / train_results.json:训练指标(损失、精度等)
- training_loss.png:损失曲线可视化图
- 分词器数据
- merges.txt:BPE 分词合并规则
- tokenizer.json / vocab.json:分词器词表与编码规则
- added_tokens.json:训练中新增的自定义 Token
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号