LoRA大模型微调介绍
原创

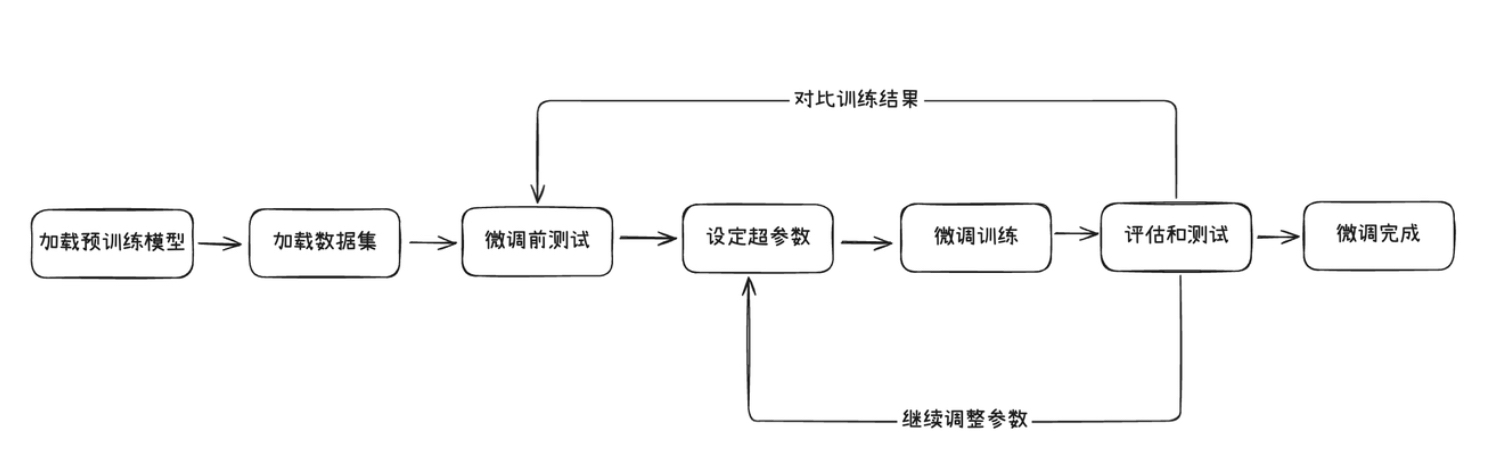
一、微调流程
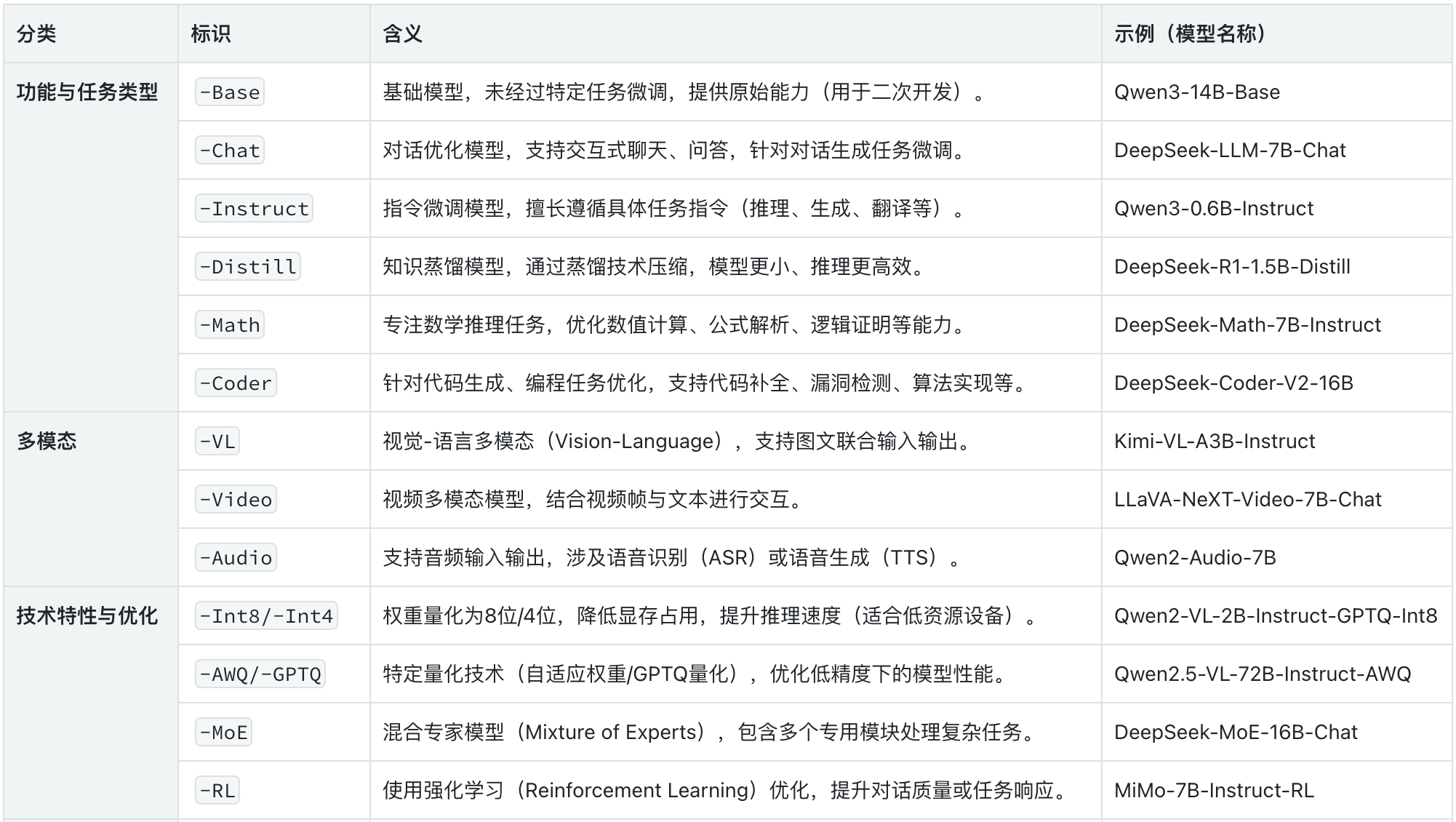
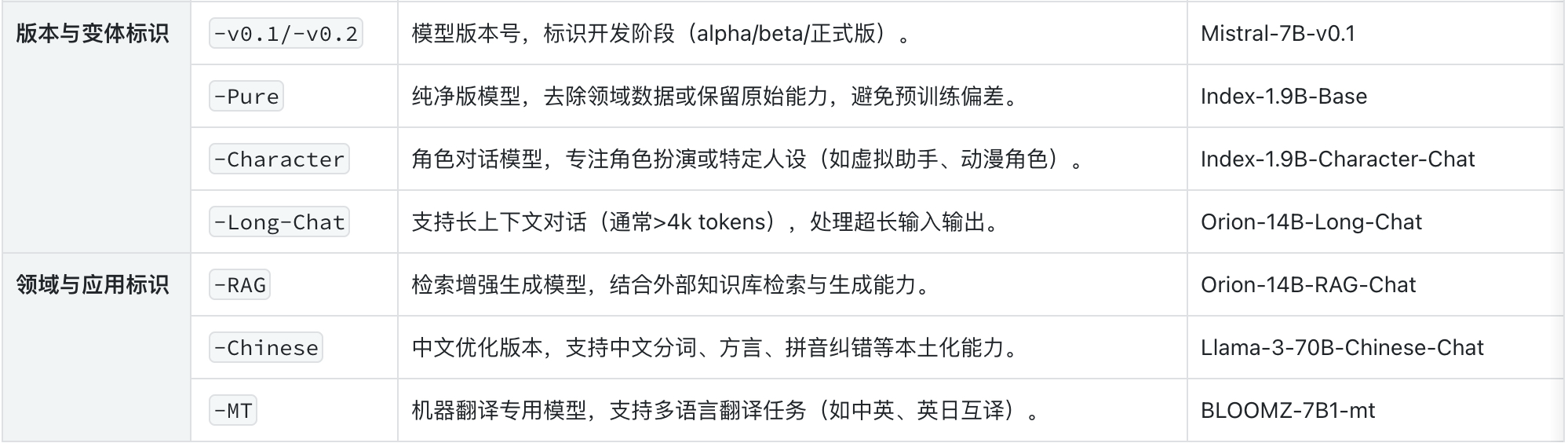
二、选择微调基础模型
如果我们需要进行的是监督指令微调,建议选择带-Instruct后缀的模型,关于模型命名及后缀说明如下截图:
三、准备意图识别微调训练集和验证集
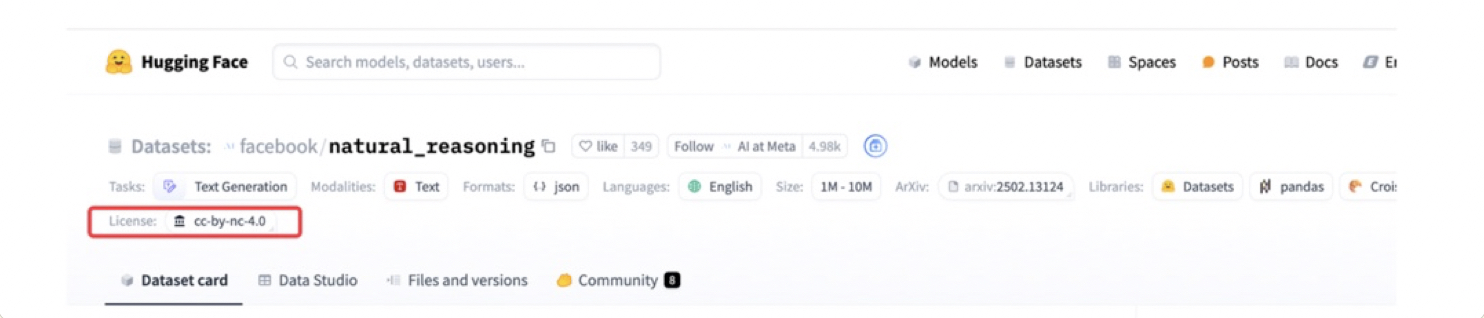
提醒:从开源平台(如Hugging Face等)下载开源数据集时,记得查看数据使用协议,需要关注下数据集是否能商用。比如下面这个Facebook提供的推理数据集,协议为cc-by-nc-4.0就不能商用。
### 训练数据集样例
[{"instruction":"你是一个意图识别专家,可以根据用户的问题识别出意图,并返回对应的意图和参数", "input":"我想听音乐", "output":"play_music()"}]
可以从训练数据集中抽出10%用作验证数据集
四、微调主要参数介绍
1、学习率(Learning Rate)
决定了模型在每次更新时参数调整的幅度,通常在 (0, 1) 之间。也就是告诉模型在训练过程中 “学习” 的速度有多快。学习率越大,模型每次调整的幅度就越大;学习率越小,调整的幅度就越小。
建议大家一开始使用比较小的学习率比较好,例如5e-5、4e-5 这种。然后看情况看模型效果,慢慢调高或者。特别是小数据集的朋友们,一开始不要用特别大的学习率。例如1e-4、2e-4这种的。总的来说,小一点的学习率确实比较好拟合。也有不错的效果。
2、训练轮数(Number of Epochs)
Epoch 是机器学习中用于描述模型训练过程的一个术语,指的是模型完整地遍历一次整个训练数据集的次数。换句话说,一个 Epoch 表示模型已经看到了所有训练样本一次。
一般建议最好控制在10个epoch以内。尽可能在10个epoch里面将模型拟合到0.7~1.4 loss范围之间。
3、截断长度(Cutoff length)
截断长度(Max Length)决定了模型处理文本时能接收的最大 token 数量(token 是文本分块后的单元,如词语、子词)。它直接影响模型对上下文信息的捕获能力,同时制约计算资源的消耗。
这个截断的长度可以自行手动调整,但是cutoff length也直接影响训练的资源。也就是显存的占用,所以这个取决于你的数据集的平均长度。来设置一个合适的截断长度。
4、批量大小(Batch Size)和 梯度累计步数(Gradient Accumulation Steps)
批量大小(Batch Size)意思就是在训练过程中,每个设备(你的GPU)一次处理的样本数量。如果你有一块GPU,batch size调到16 那么就意味着你一块GPU一次处理16个样本(这里的样本指的就是你一条数据集)
梯度累计步数(Gradient Accumulation Steps)实际上是一个降低显存的优化手段,当我们显存不够用,但是又想采用大批量的时候,就可以加大梯度累积步数,从而实现分批次计算梯度然后累积进行更新。比如我们像设定批量大小为 6,但是我们的CPU 显存只能支持到 2了,这时候就可以把梯度累计步数 设置为 3,实际的步骤就是:
- 先算 2 个样本的梯度,不更新参数;
- 再算 2 个样本的梯度,不更新参数;
- 再算 2 个样本的梯度,与前两次累积后一起更新参数。这样就能实现用小显存实现大 batch size 的效果,类似于 “分期付款” 的效果。
一般来说,小模型,例如10b以下的模型,建议batch size调小一些比较好,其次如果你的数据集很少,那batch size还调的很大的话,特别容易严重过拟合。导致效果很差。小batch size的拟合效果其实是不错的。这里建议从batch size调到2开始,甚至可以从1开始。
5、LoRA 秩(LoRA rank)
LoRA(低秩适应)中的秩(Rank)是决定模型微调时参数更新 “表达能力” 的关键参数。它通过低秩矩阵分解的方式,控制可训练参数的规模与模型调整的灵活程度。秩的数值越小,模型微调时的参数更新越 “保守”;秩的数值越大,模型能捕捉的特征复杂度越高,但也会消耗更多计算资源。
显存紧张的时候,可优先降低秩(比降低批量大小更有效),例如将秩从 16 降至 8,可能直接释放 30% 以上的显存,不过建议最低不要 < 8,会影响模型的学习效果。
五、模型微调后验证
通过预留的10%的微调数据集用做训练后的模型验证集。
模型验证数据集中可以加上对应训练时的提示词,如:
你是一个意图识别专家,可以根据用户的问题识别出意图,并返回对应的函数调用和参数。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号