Llama-Factory 意图识别模型微调实战(RTX 4090D 24G)
原创
Llama-Factory 意图识别模型微调实战(RTX 4090D 24G)
原创
Wangzy
修改于 2026-01-21 13:09:32
修改于 2026-01-21 13:09:32
一、在AutoDL平台创建云主机并配置微调环境
此处没有广告,线上大家都说该平台性价比高,实际体验下来确实如此,一小时2元左右,配置加微调应该一两个小时就差不多了。
省钱小妙招:如果仅环境配置,可以选择无卡启动,这样一小时只需要0.1元。
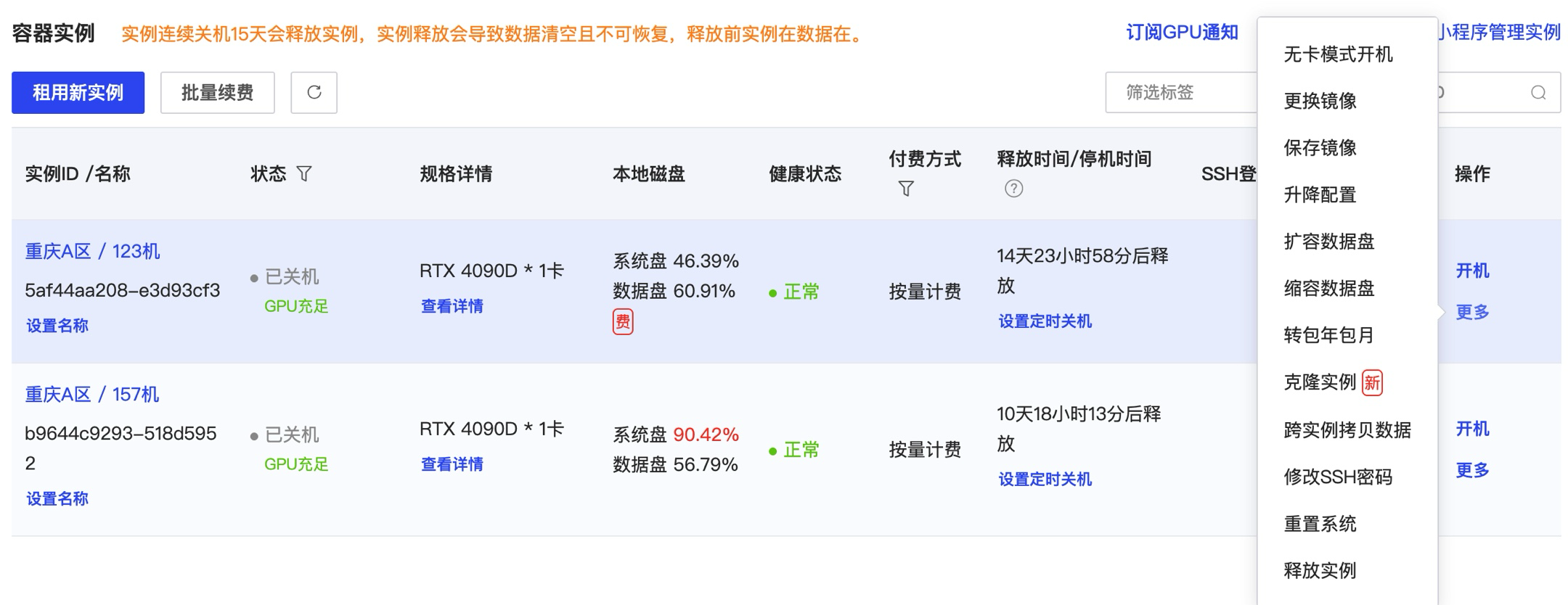
1、创建主机并开机
如下截图,选择租用了RTX 4090D的显卡,主机的cpu和内存配置也都还不错,数据盘默认是50G,有需要的话可以额外付费扩容。
我训练的时候由于存储微调后的模型文件需要转存成不同量化的版本,所以扩容了50G,一天只需要不到0.4元。创建实例开机后,就可以开始配置了。
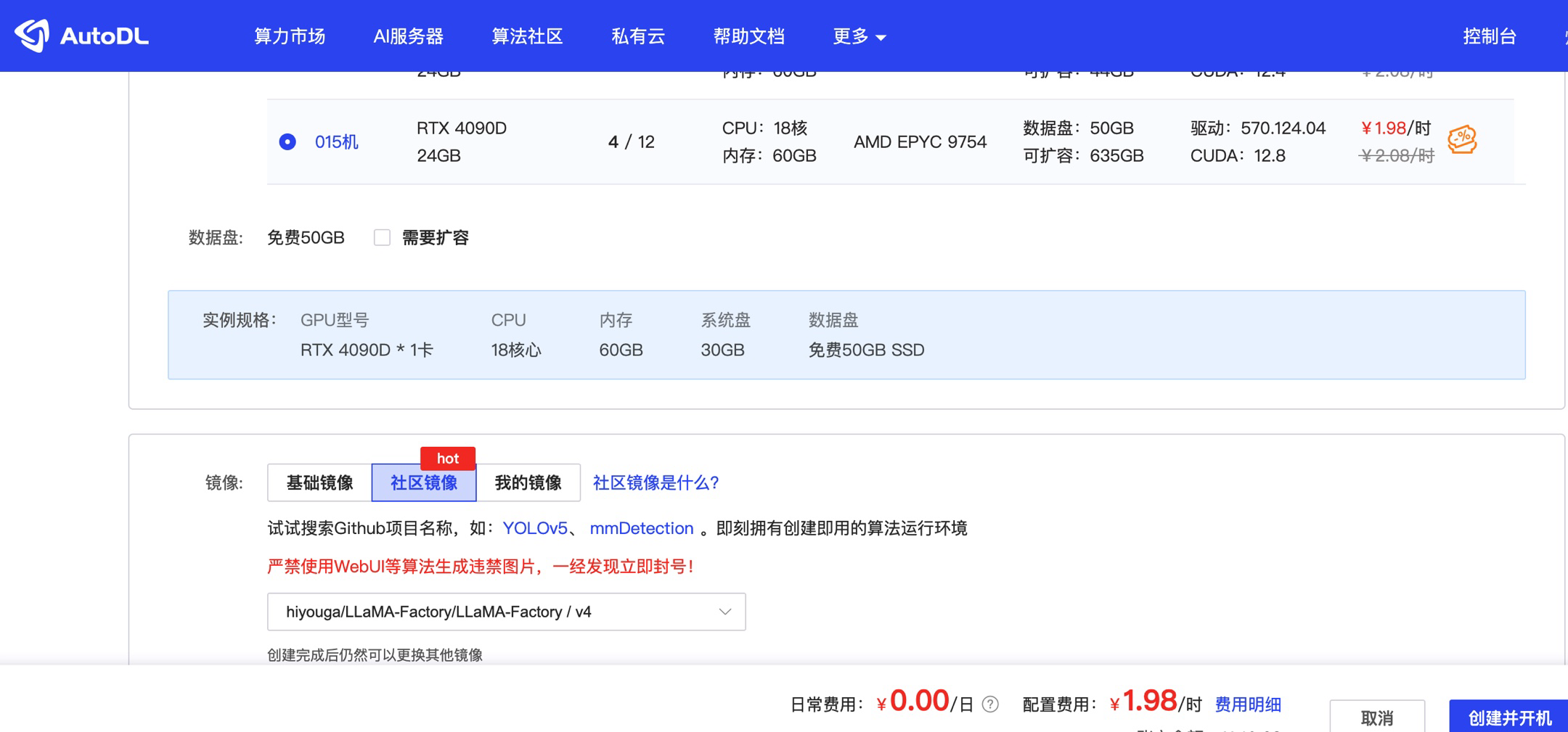
2、云主机配置及启动llama-factory webui
开机后可以通过JupyterLab跳转页面进行配置且打开llama-factory webui页面/

jupyterlab页面如下:
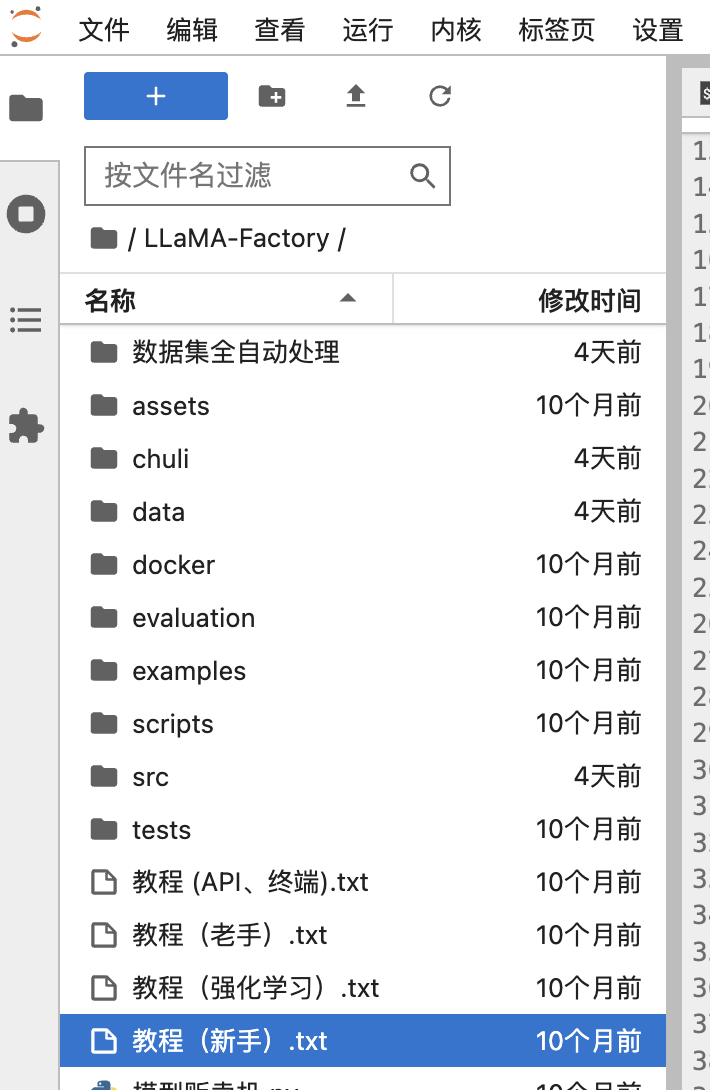
根目录中LLaMa-Factory目录中有模型创建、数据集自动处理等相关的新手教程,可以先看看对应的教程。
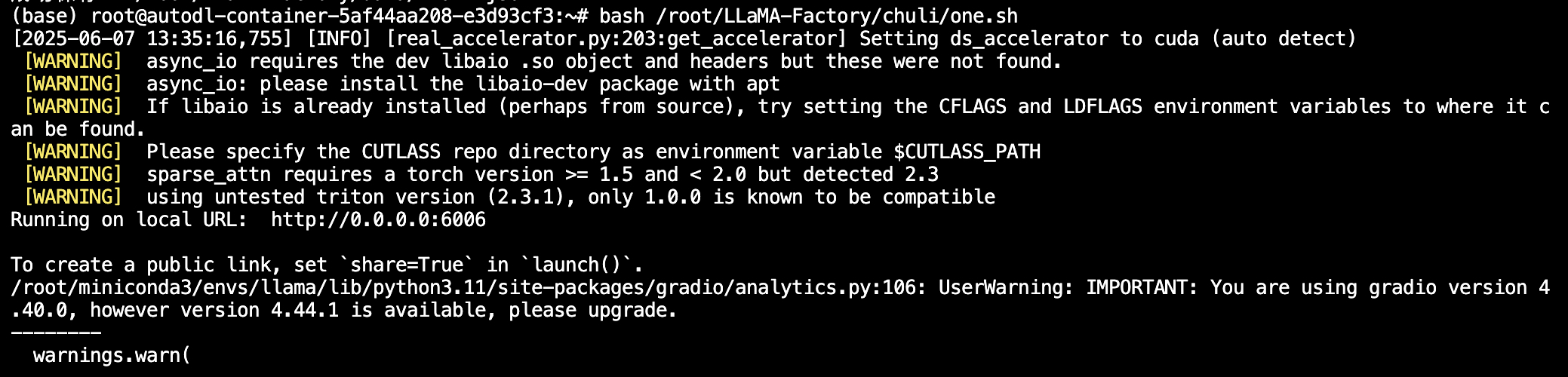
选择创建终端,接着启动Llama-Factory框架的webui,如截图就说明启动成功了。
bash /root/LLaMA-Factory/chuli/one.sh
然后到AutoDL实例页面选择“自定义服务”

根据本地电脑os不同选择对应的使用方式:笔者是mac系统。
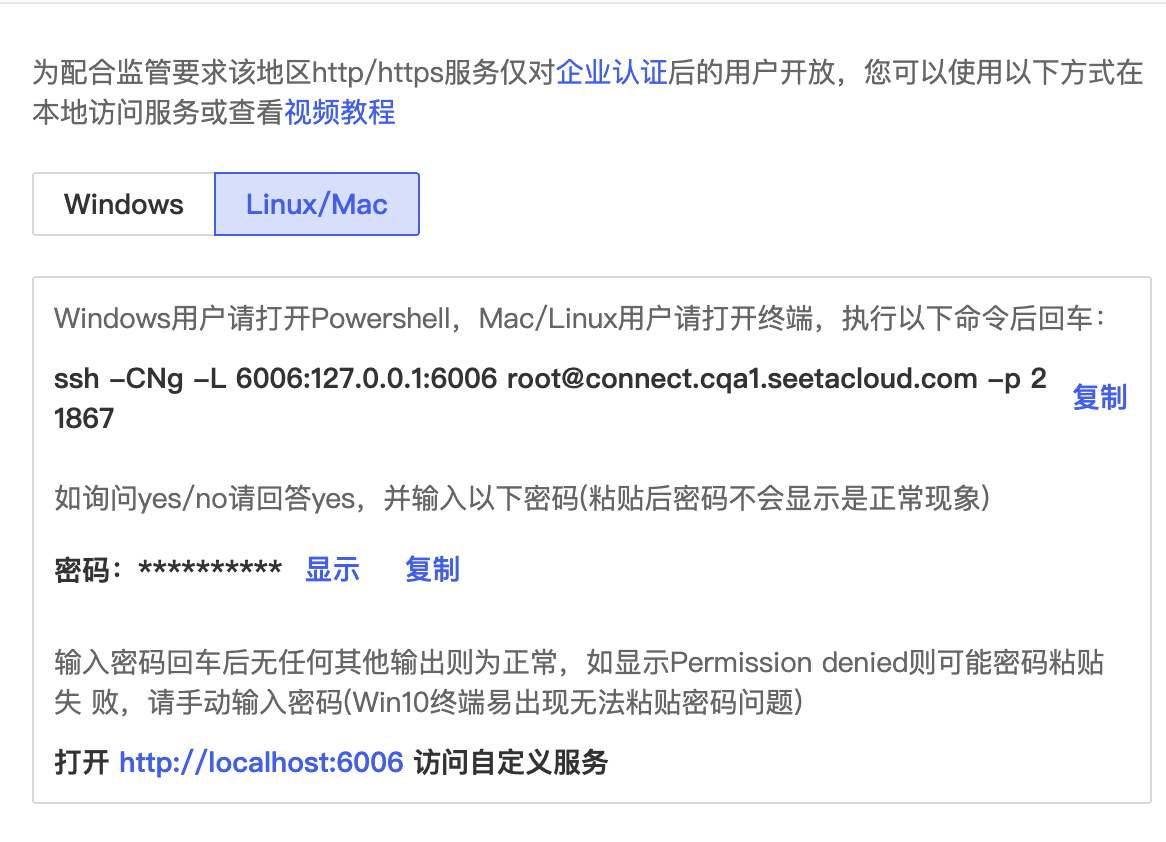
复制如上截图中的ssh命令和密码,在终端验证密码

之后,就可以在浏览器使用http://localhost:6006打开llama-factory的webui页面
二、模型微调过程
1、下载对应的微调基础模型
在终端中选择执行如下脚本,下载微调的基础模型。笔者这次微调是使用Qwen2.5-7B-Instruct,所以输入模型名称为:Qwen/Qwen2.5-7B-Instruct
下载速度还是很快的,大概1分钟左右可以下载完成。
python /root/LLaMA-Factory/模型贩卖机.py

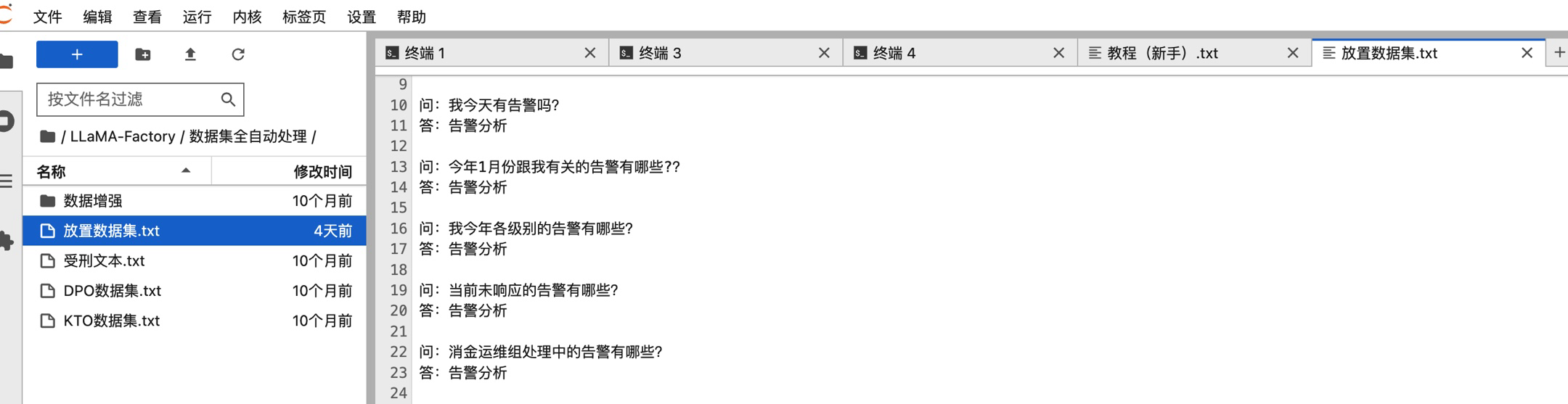
2、准备对应的训练数据集
按照如下截图将微调数据集按照如下问答的格式粘贴到“放置数据集.txt”文件中
接下来,在终端中执行命令处理数据集,会自动将如上准备的问答数据集转存到训练格式的train.json文件中
bash /root/LLaMA-Factory/chuli/单多轮脚本/DD.sh

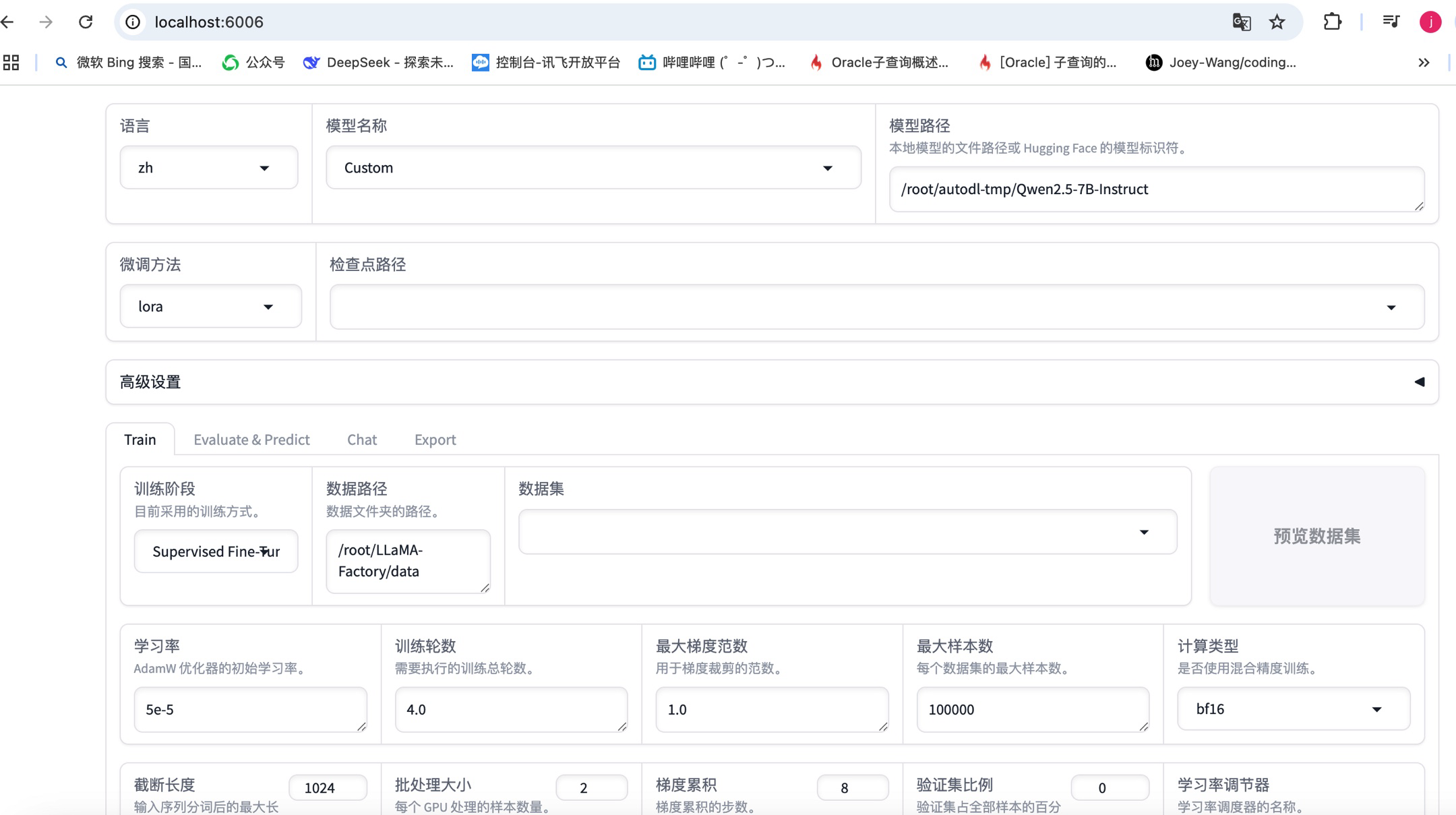
3、llama-factory框架微调相关配置
选择基础模型:
模型名称选择“Custom”,模型路径选择微调基础模型下载的路径

选择数据集:
上述数据集处理后的train.json文件会被标注为“你的数据集”,

train.json到“你的数据集”,这个映射关系是通过如下这个dataset_info.json文件配置的。
/root/LLaMA-Factory/data/dataset_info.json

可以预览数据集内容
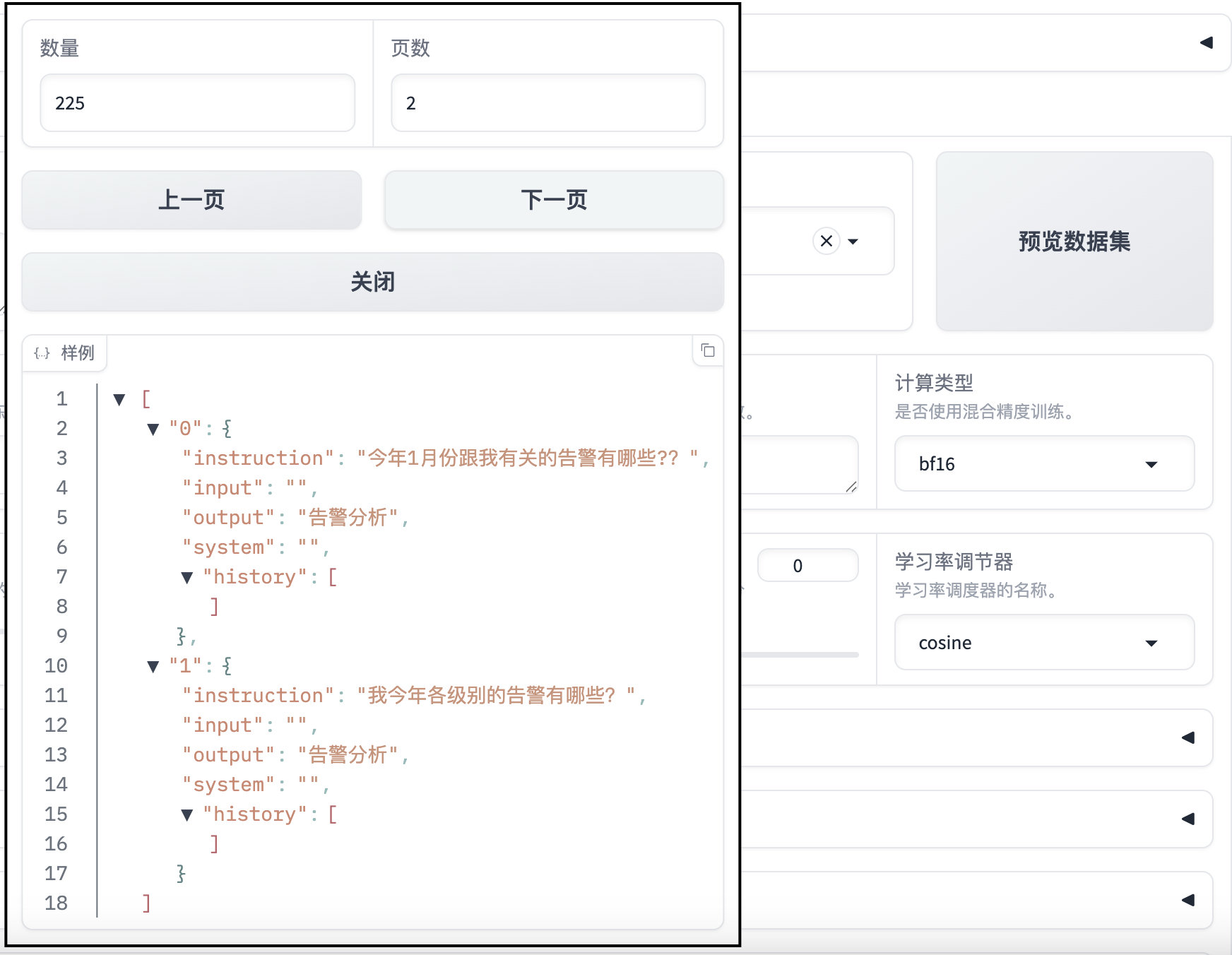
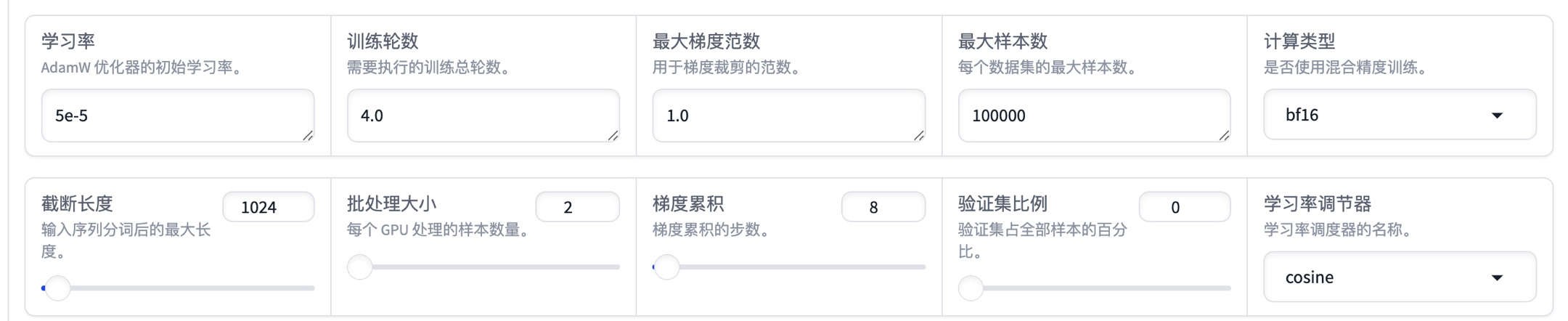
LoRA微调配置保持默认就行
三、微调模型及对话验证
选择输入目录,笔者这里定义了数字“002”,随意定义就行,每次微调定义不同的目录。
可以预览微调的命令
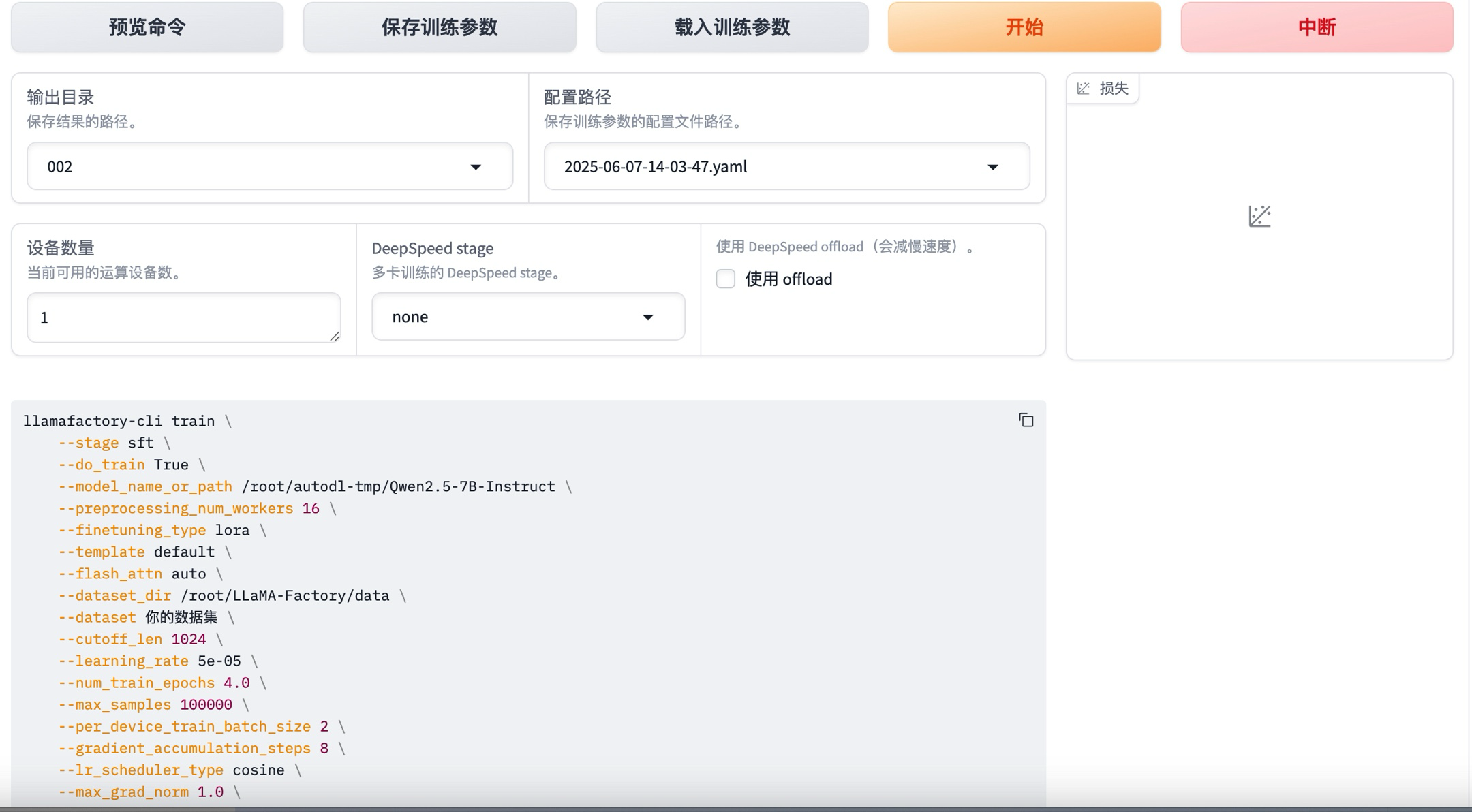
接着就可以点击“开始”按钮开始模型微调
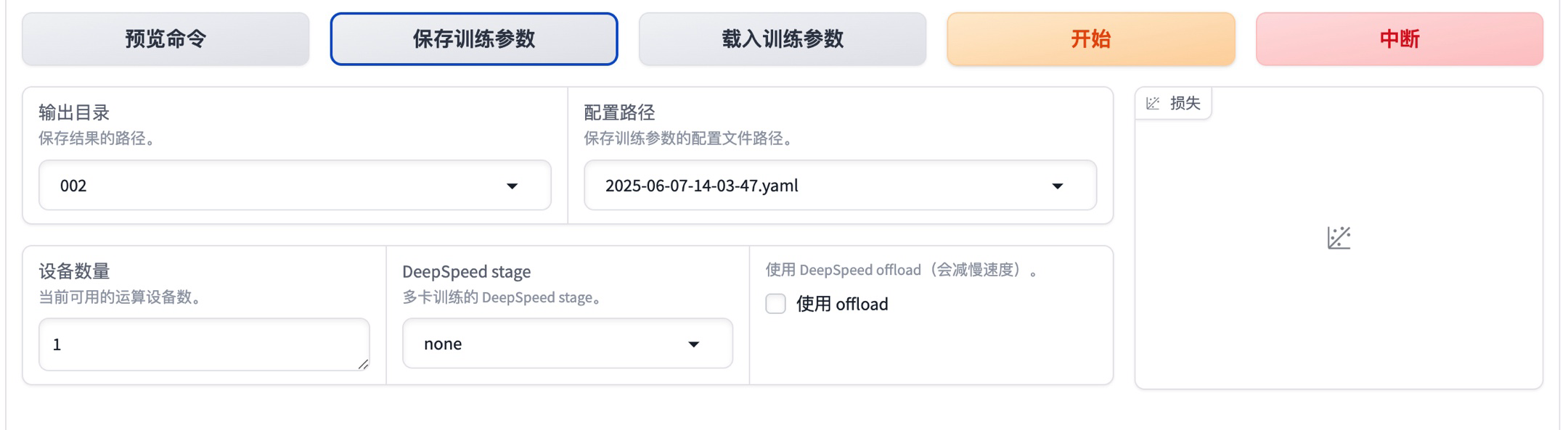
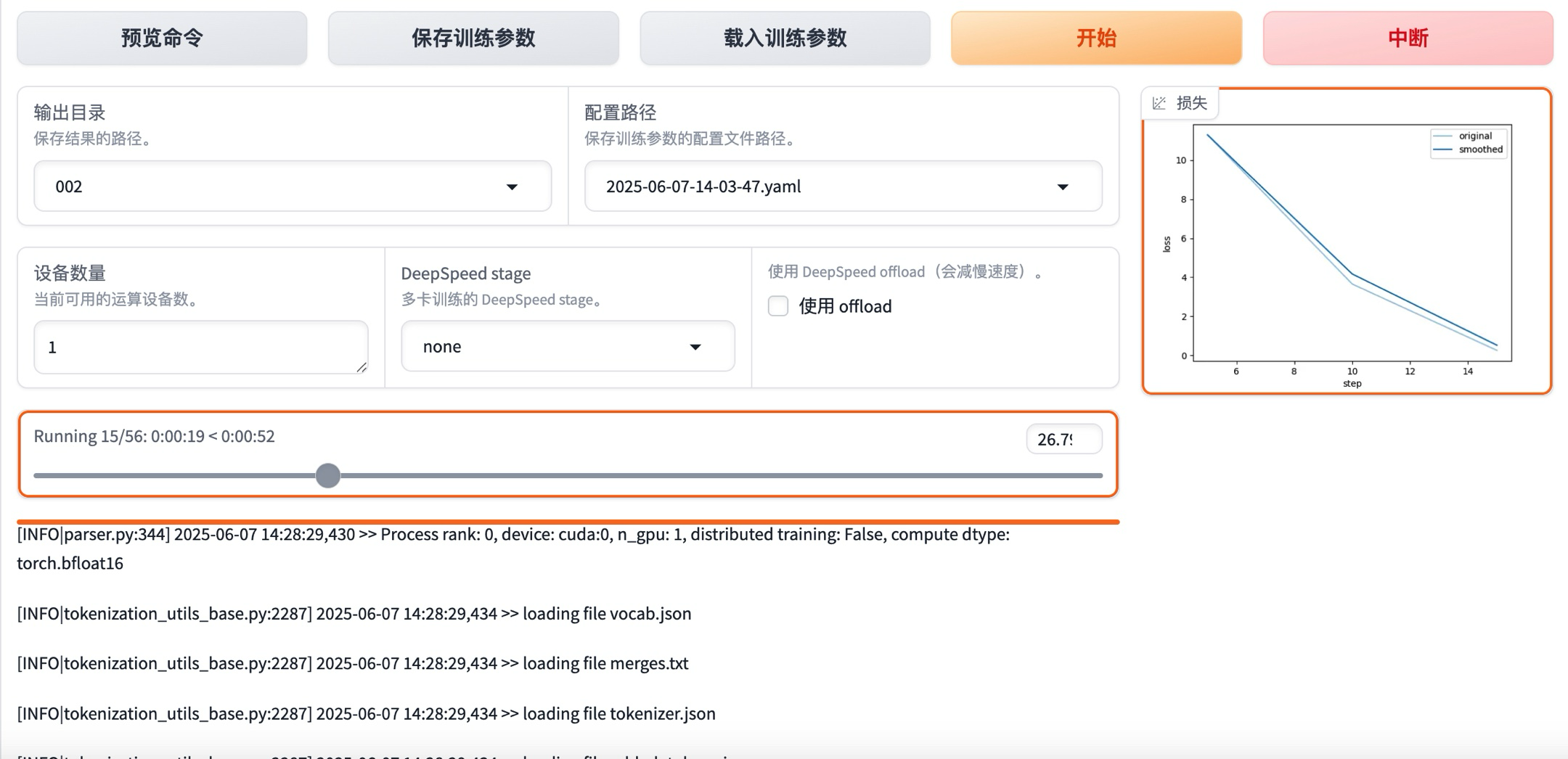
可以看到,一共225条训练数据,微调过程只需要两分钟左右就完成了(14:28:29-->14:29:55)。
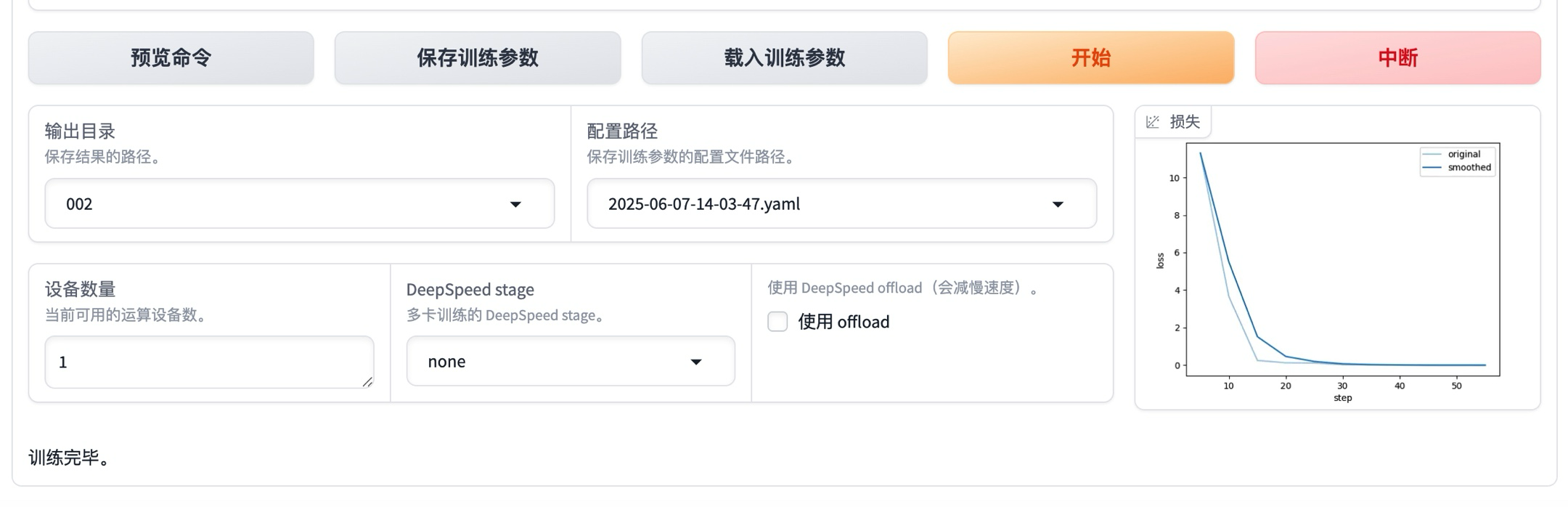
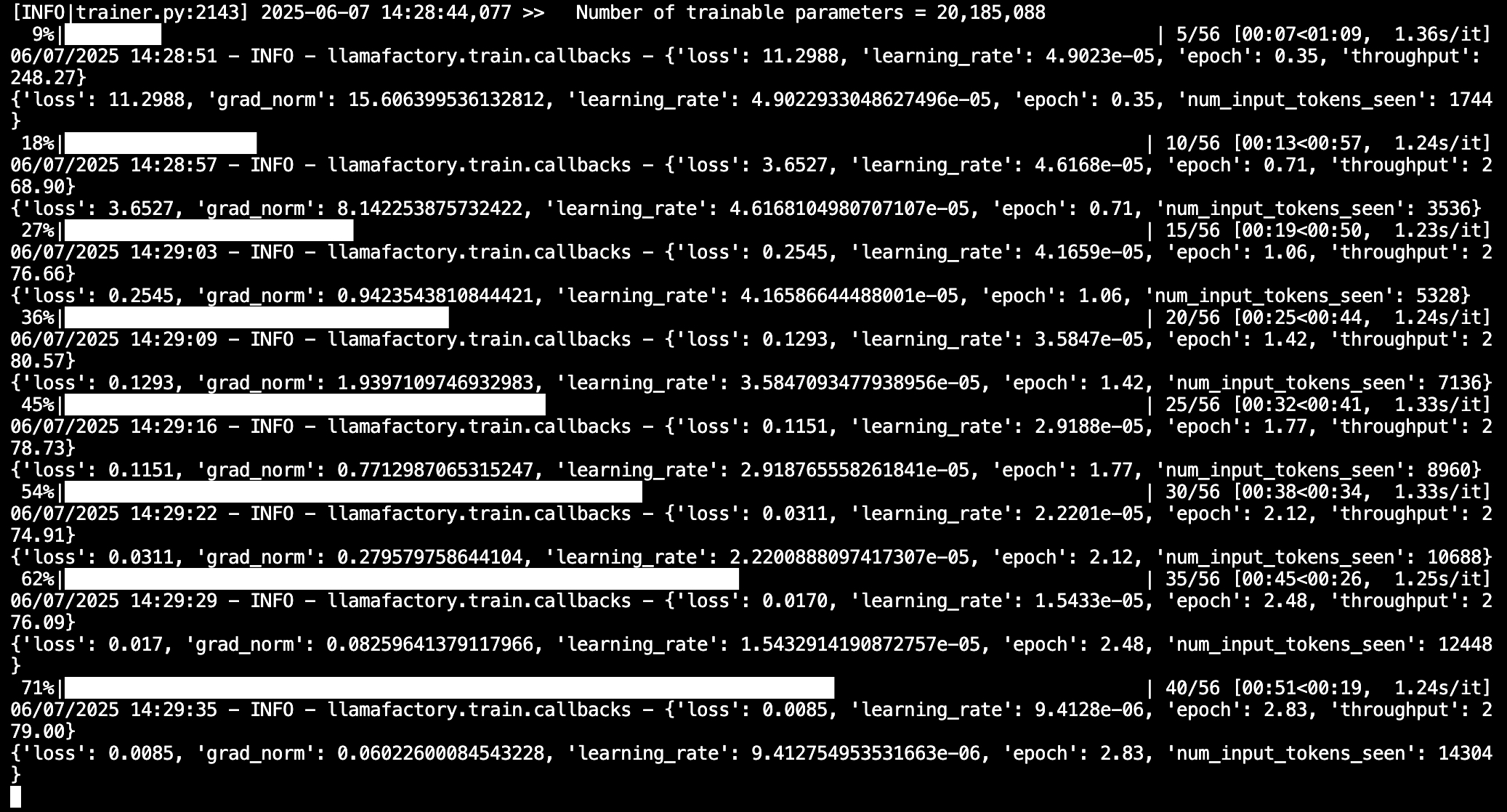
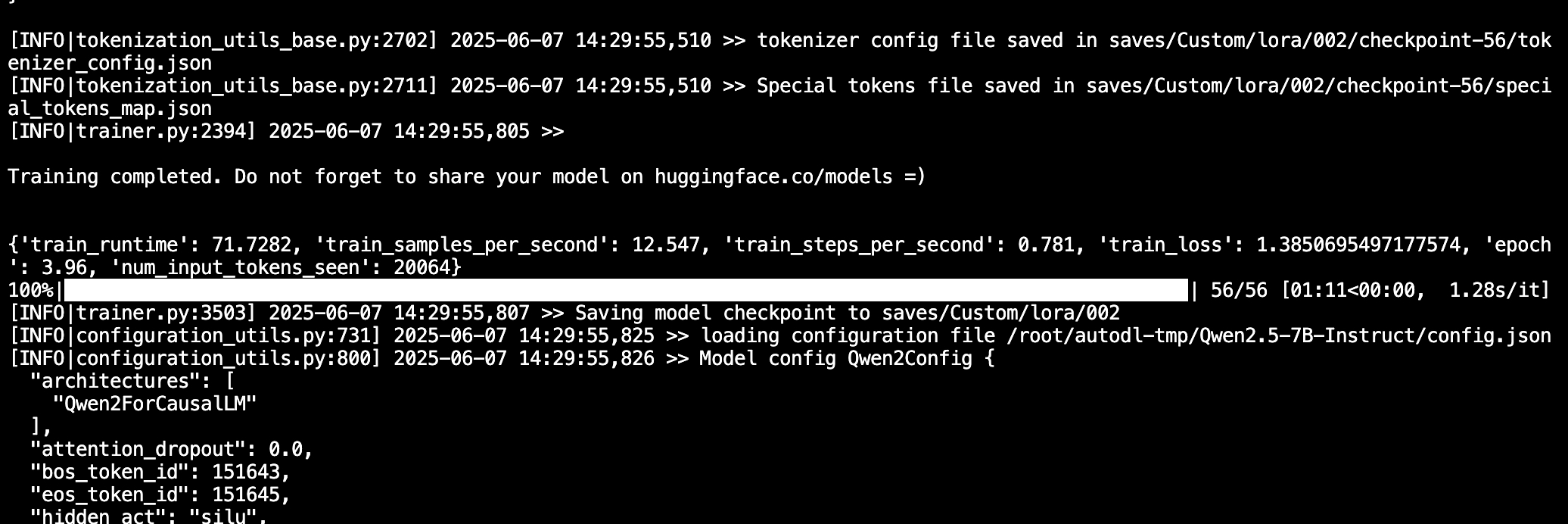
四、微调后模型对话验证
1、选择之前微调配置的微调输出目录“002”,然后选择“Chat”tab页
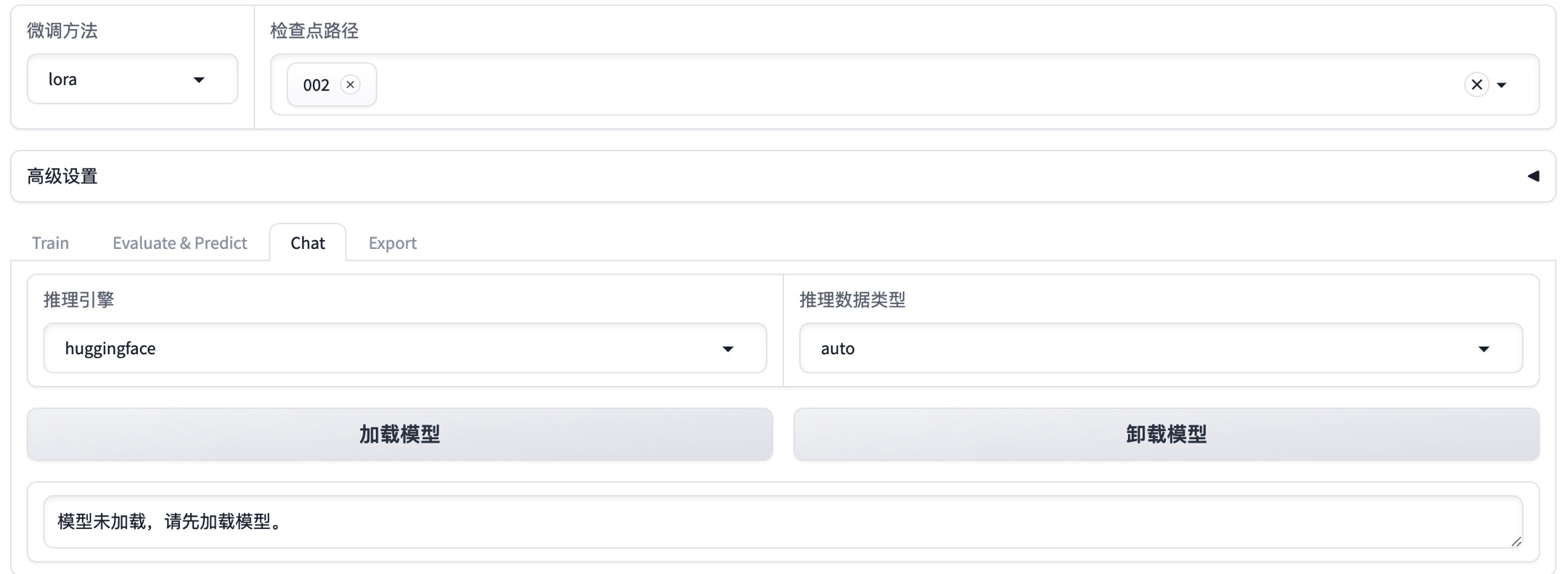
2、加载微调后的模型
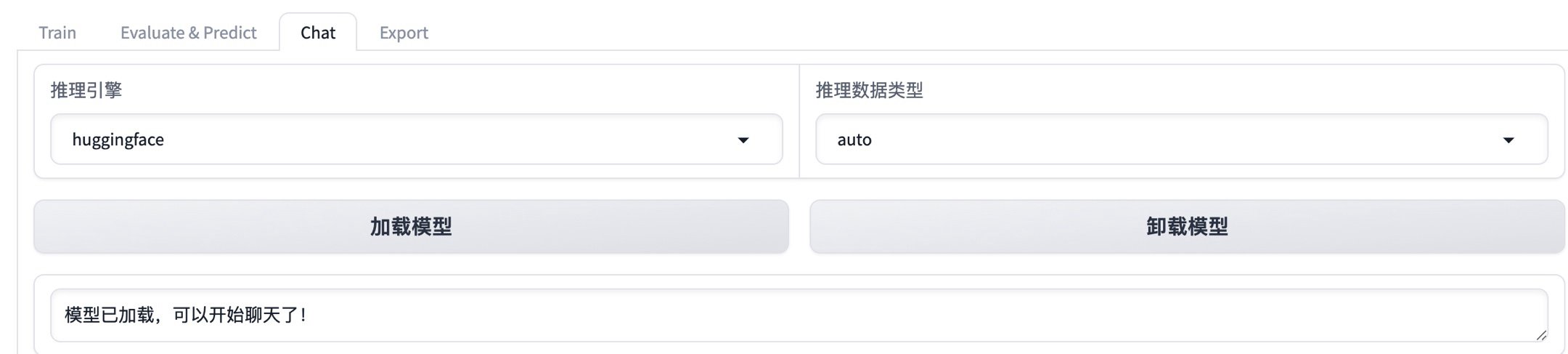
3、对话验证模型,可以看到微调后的模型回答已经达到数据集中的意图识别目标
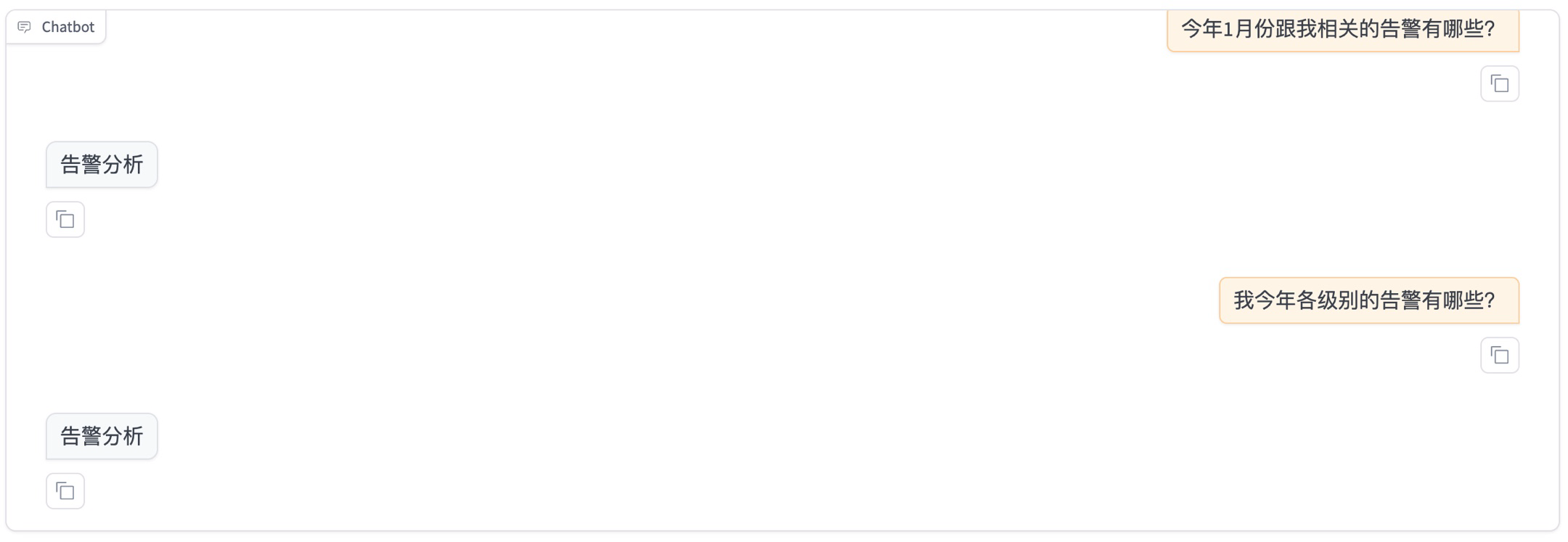
关于模型评估,应该是有单独的评估工具,后续研究后再单独发文章分享记录。
验证后可以卸载模型,释放显卡资源
五、微调后的模型导出、转换gguf、下载本地并用ollama部署
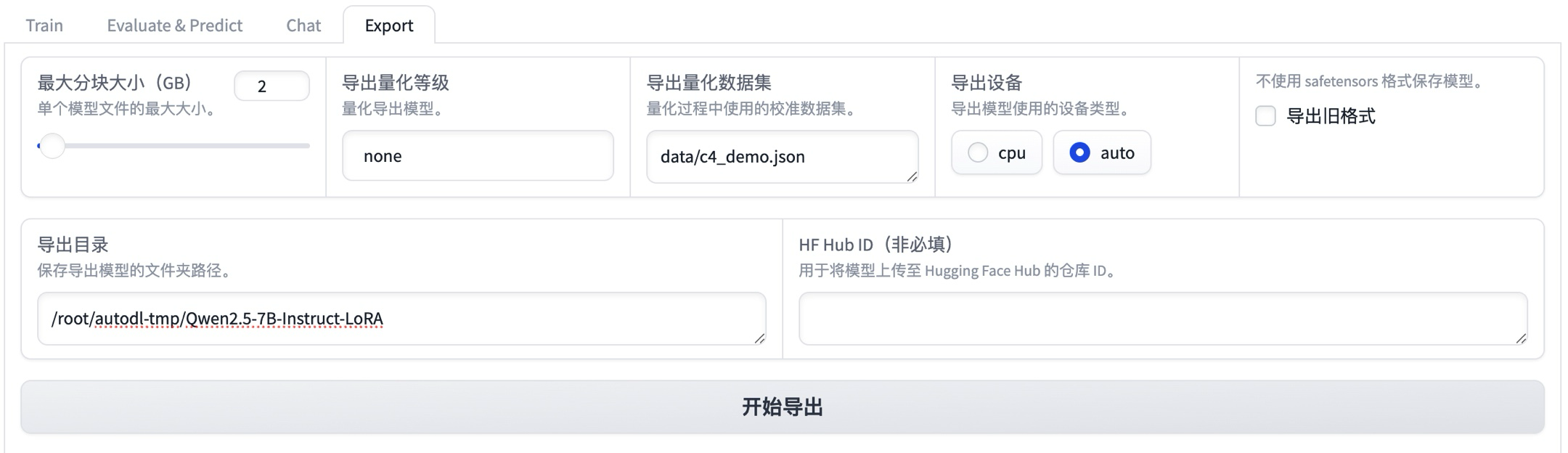
1、导出模型:
笔者这里配置做大分开大小为2GB,导出设备选择“auto”,配置导出目录为云主机的数据盘目录
导出后的模型文件如下截图:

2、在云主机下载安装llama.cpp工具
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
cmake -B build -DGGML_CUDA=ON 还需要禁用另一个参数,可以根据报错提示把另一个参数给禁用
cmake --build build --config Release 编译需要耗时20分钟左右
3、将导出的模型文件转换成gguf格式及量化模型降低gguf文件大小。
### 将导出的模型文件转换成gguf格式
python convert_hf_to_gguf.py --outfile Qwen2.5-7B-Instruct-LoRA.gguf /root/autodl-tmp/Qwen2.5-7B-Instruct-LoRA
### 将模型量化,降低模型大小
cd build/bin
./llama-quantize /root/autodl-tmp/Qwen2.5-7B-Instruct-LoRA.gguf /root/autodl-tmp/qwen7b_lora_q4.gguf q4_0
可以看到量化前和量化后的gguf文件大小比较

4、下载gguf文件到本地,ollama运行微调后的模型
通过filezilla工具将量化后的4GB左右的gguf文件下载的本地pc,且在gguf文件所在目录新建Modelfile的文件,然后编辑文件加入如下文本内容
FROM ./qwen7b_lora_q4.gguf

然后在当前目录下执行如下命令,"qwen2.5-7b-lora-v1"是在ollama中给gguf定义的模型名称
ollama create qwen2.5-7b-lora-v1 -f ./Modelfile
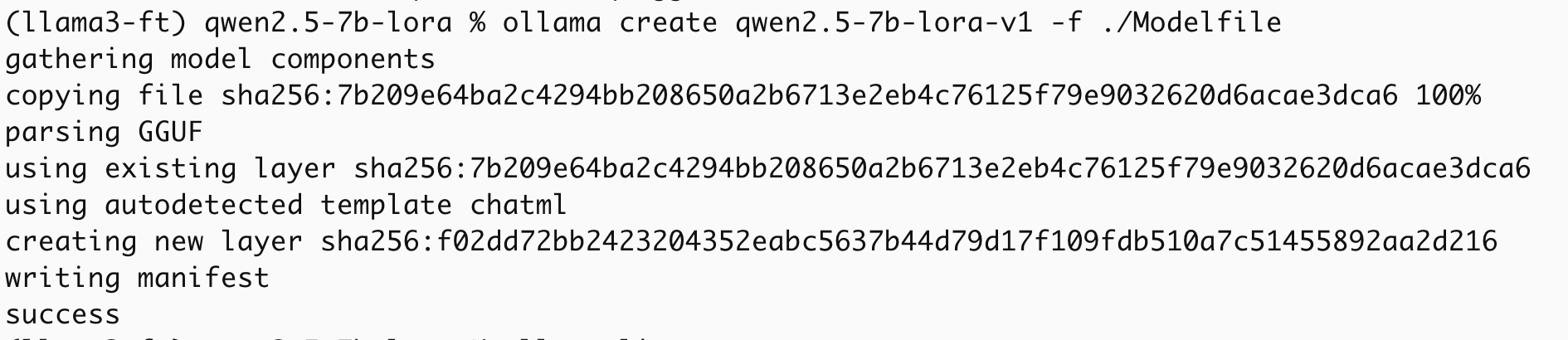
然后通过ollama list可以查看ollama中已有的大模型,这里就可以看到我们根据gguf文件新建的大模型。

然后在ollama运行我们微调后的大模型,并验证问题。

对比微调前的qwen2.5-7b-instruct大模型回答如下:

至此,我们的模型微调实战就已经完成啦。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号