管道如何连接进程?从基础原理到高级应用,构建你的进程通信全景视野

管道如何连接进程?从基础原理到高级应用,构建你的进程通信全景视野

海棠蚀omo
发布于 2026-01-12 17:32:22
发布于 2026-01-12 17:32:22
今天我们就要步入新的内容了:进程间通信,而这篇的主要内容是来讲进程间通信的其中一种方式:管道,那么在讲管道之前,我们有必要了解进程间通信的一些背景知识。
一.进程间通信的一些背景知识
这部分其实也就是两个问题:
1.什么是进程间通信?
进程间通信,简称 IPC,是指两个或多个进程之间进行数据交换、信息传递或同步操作的机制。对于进程间通信的概念我们可以映射到人身上,我们只要思考一个问题就知道进程间通信在干什么了:人与人之间交流沟通是在干什么?
将进程间通信转换到人与人之间,换个问法相信大家就好理解多了,其实也就跟人与人之间交流沟通是很相似的。
2.为什么要有进程间通信?
这个问题我们换个问法:未来进程之间有没有可能需要协同工作呢?也就是一个进程把自己的数据交给另一个进程,让另一个进程去完成某个工作,有没有这个可能呢?
当然是有可能的啊,这就像人与人之间在工作当中是需要交流沟通的,就比如:你的领导让你做一个产品,给了你要求,让你按照这个要求去做。
或者说你在一个小组当中,每个人分别负责不同的模块,当最后汇总的时候,你们每个人之间也是需要交流沟通来完成交接工作的。
等等生活中有很多例子,进程间也是如此,它们有时候也需要共同协作去完成某个工作,自然也就需要交流,也就是通信。
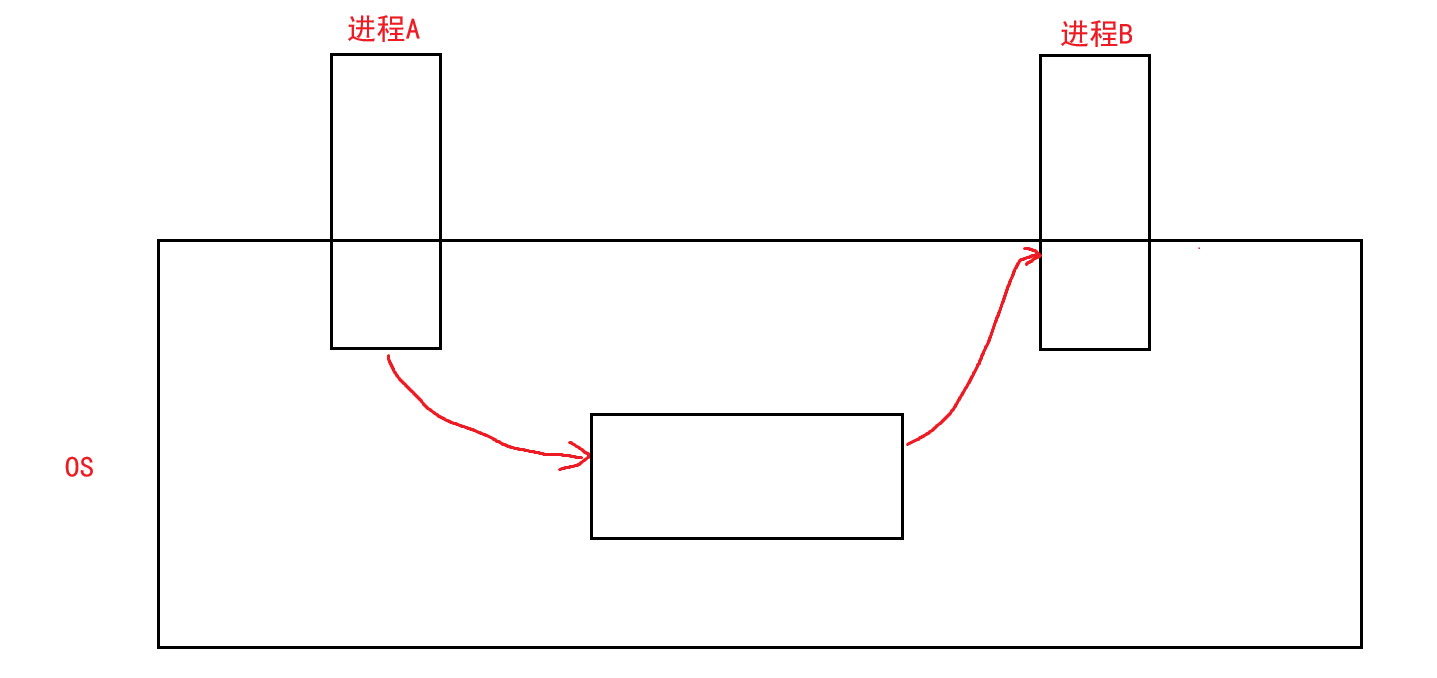
但是进程是具有独立性的,我们想一个问题:既然进程间具有独立性,那么直接把一个进程的数据交给另一个进程,也就是一个进程去访问另一个进程,这种情况可能会出现吗?
当然不可能啊,如果允许这种情况出现,那么就破坏了进程间的独立性,如果操作系统一边保持进程间的独立性,一边还允许进程间互相访问,这不纯纯左右脑互博嘛。
父子进程之间还要通过写时拷贝来保持独立性呢,所以进程与进程之间是不可能之间进行通信的,也就是进程间要想进行通信就要有另一个人的参与,那么是谁呢?
当然是我们的操作系统大人了,那么如何做到进程间通信呢?
从上图我画了个草图,大概就是进程A将数据放在一个地方,而进程B再从这个地方去拿这份数据,换句话说:进程间通信的前提就是先让不同的进程看到同一份资源!!!
而这份资源是由操作系统提供的,而这份资源一定是某种形式的内存空间,这样进程才能将数据存在其中。
在讲解后面的知识前,我们要先要有上面的这些概念。
二.进程间通信介绍
2.1进程间通信的目的
数据传输:⼀个进程需要将它的数据发送给另⼀个进程 资源共享:多个进程之间共享同样的资源。 通知事件:⼀个进程需要向另⼀个或⼀组进程发送消息,通知它(它们)发⽣了某种事件(如进程终⽌时要通知⽗进程)。 进程控制:有些进程希望完全控制另⼀个进程的执⾏(如Debug进程),此时控制进程希望能够拦截另⼀个进程的所有陷⼊和异常,并能够及时知道它的状态改变。
上面只是简单提了进程间通信是在干什么,这里我就把主要的用途给列举出来,加深大家对进程间通信的理解。
不得不说进程间通信的目的和我们人与人之间交流沟通的目的是真的很相似,甚至可以说是一样的。
2.2进程间通信的发展
管道 System V进程间通信 POSIX进程间通信
在进程间通信的漫长历史中,我们共出现了如上的三种通信方式,它们是按照时间顺序所出现的,下面我对它们做个简单的介绍。
管道:我们要知道,一个新技术的出现,其实也就意味着程序员要写的代码更多了,所以为了不写更多的代码,某些程序员就想着我不用新技术,我用以前的技术给你实现一个类似的不就行了?
而管道这种通信方式就应运而生,它是一种基于文件的通信方法,不使用新技术也能完成进程间的通信,缝缝补补又是一年。
System V进程间通信:但是你管道再缝缝补补,那也终究有满足不了需求的一天啊,所以System V进程间通信这种新技术也就出现了,它是来单独设计通信模块,不在和管道一样基于以前的技术来实现。
POSIX进程间通信:但是后来Linux中又引入了网络的概念,那System V这种通信方式就也不能再满足需求了,为了实现网络间进程通信,就出现了POSIX这种新的通信方式,也是目前现代Unix/Linux系统中主流的、标准的IPC机制之一。
2.3进程间通信分类
这里我们大概看一下每种通信方式都有哪些内容:
管道: 匿名管道pipe 命名管道
System V IPC: System V 消息队列 System V 共享内存 System V 信号量
POSIX IPC 消息队列 共享内存 信号量 互斥量 条件变量 读写锁
上面皆是每种通信方式中的主要内容,后面我们也会从中进行讲解。
三.管道
3.1何为管道?
管道是Unix中最古老的进程间通信的形式,我们把一个进程连接到另一个进程的一个数据流称为一个" 管道 ",下面我们看一个简单的例子:

我们通过一个简单的操作来观察管道的作用,who这个命令就是显示当前登录到系统的用户信息,也就是现在谁在使用这台机器,而后面的wc -l在这里的作用就是统计who命令输出信息的行数。
而我们上面就是将who命令输出的信息放入到管道文件中,之后再由wc -l命令从管道文件中读取数据,进而将结果输出出来。
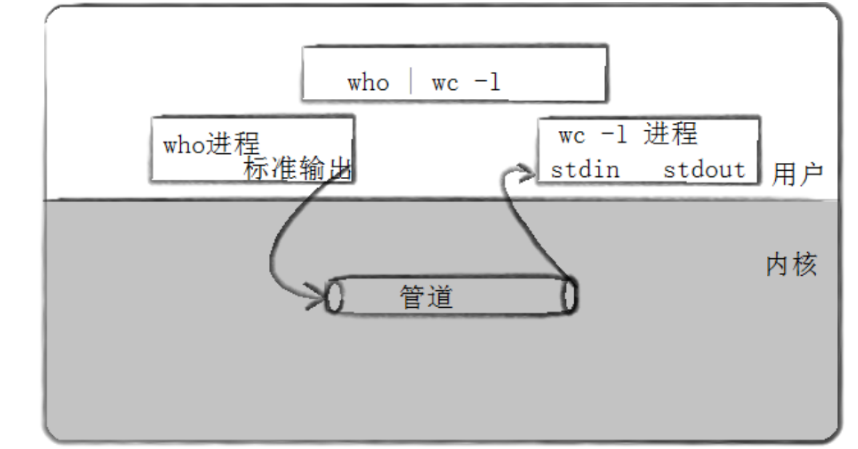
用图来演示这个过程则更为直接,who和wc -l这两个进程就通过管道文件看到了同一份资源,并完成了进程间通信的工作。那么管道的底层原理是什么呢?我们接着往下看。
3.2管道的底层原理 && 图
下面我们来探讨一下管道的底层原理是怎样的:
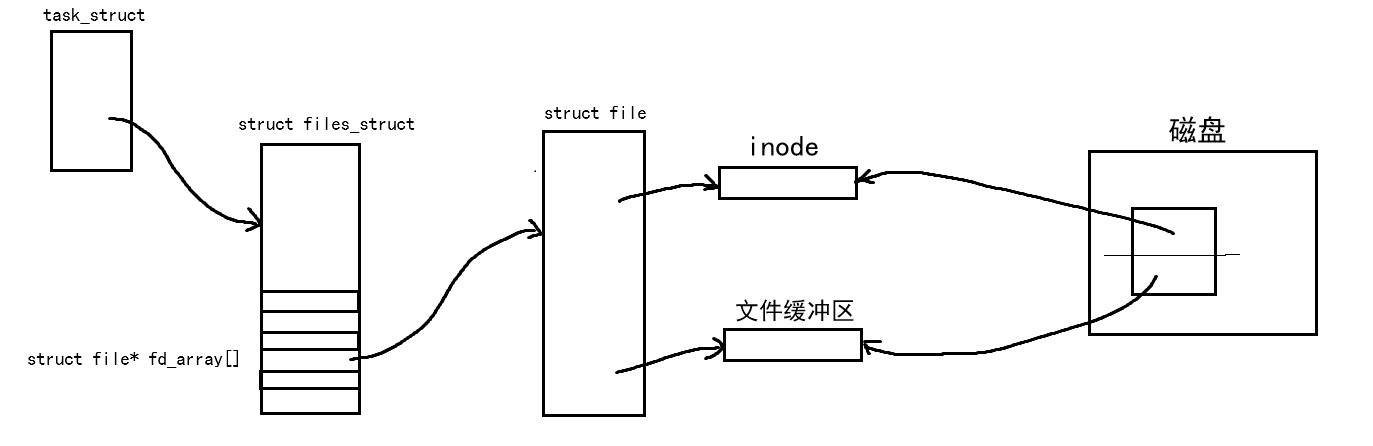
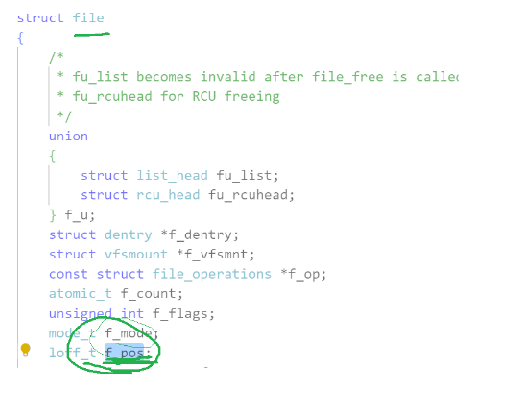
我们创建一个进程,在进程的task_struct中我们可以找到struct files_struct,在这里面有文件描述表struct file* fd_array[],其中的每个位置都指向了一个struct file结构体,在这个结构体中我们能够找到硬盘文件的inode和文件缓冲区,这些知识呢在我们前面的章节中已经讲过。
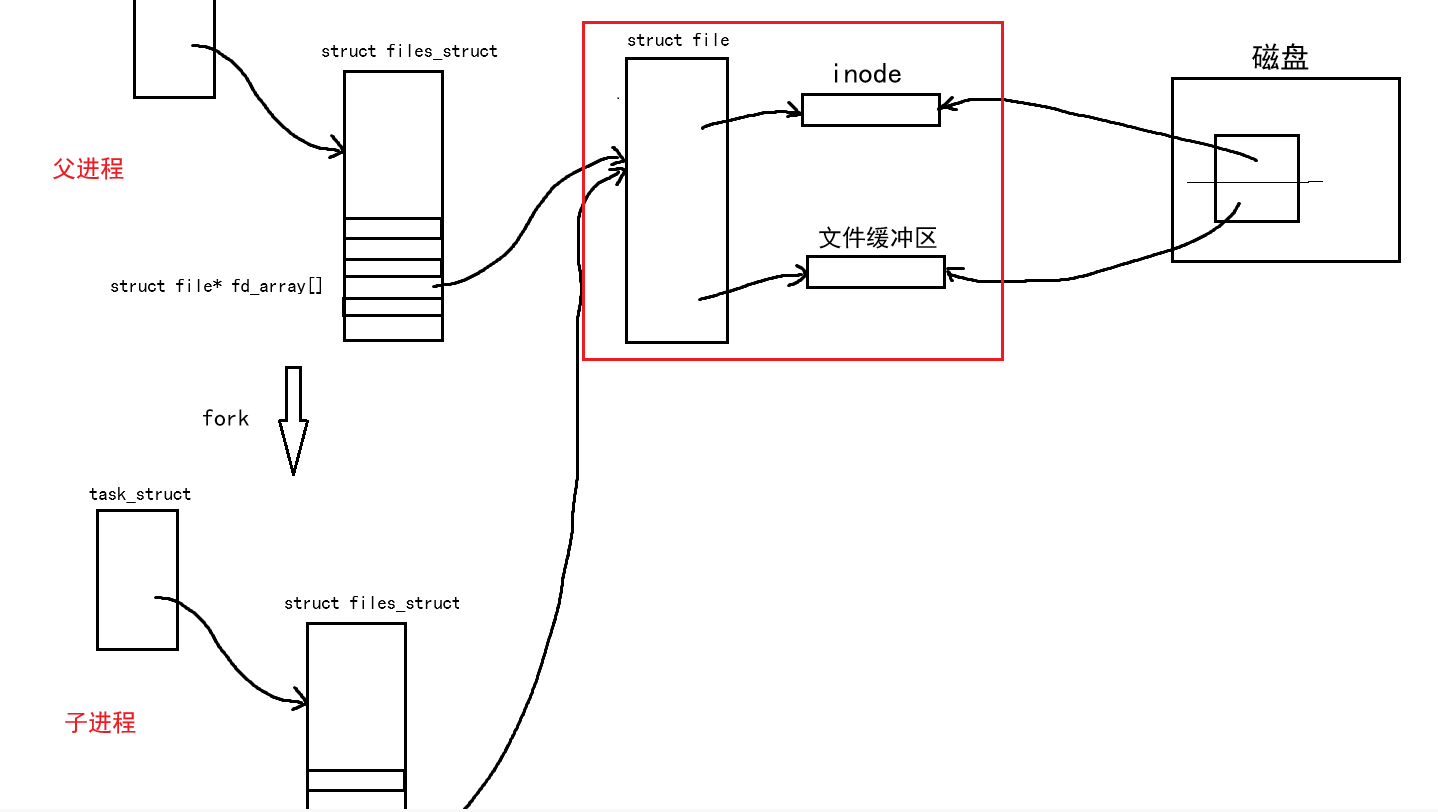
当父进程通过fork创建子进程时,同样也会拷贝父进程的task_struct,那么同样也会将里面的struct files_struct也拷贝一份,这我们之前也讲过了,那么为了帮助大家回忆,我问一个问题:子进程会将上图中红色方框圈起来的部分也拷贝一份吗?
想必大家心中也有了答案,当然不会了,所以子进程的struct files_struct同样也会指向同一个struct file,不管父进程还是子进程都能向这个文件中写入内容,父子进程也就能看到文件中全部的内容。
那么这不就相当于父子进程看到同一份资源了吗?
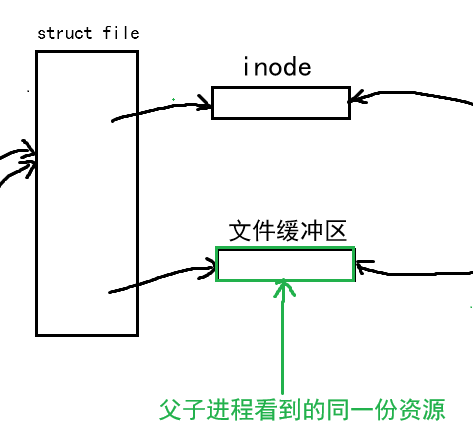
这里面最核心的就是文件缓冲区,进程间通信的前提:两个进程看到同一份资源,这个条件上面满足了,而且struct file中的文件缓冲区也正是操作系统提供的。
通过管道进行进程间通信的条件不就齐了嘛:两个进程看到同一份资源,由操作系统提供,这块空间还是一段某种形式的内存空间。
条件齐全,我们现在就对管道的底层原理有了那么一点理解了,但是这里面还存在着问题:
1.我们平常打开的是普通文件,位于文件缓冲区的内容将来是要被刷新到磁盘文件中的,但是我们并不需要对文件缓冲区中的内容进行刷新,该怎么办?
2.众所周知,一个文件中呢只有一个读写位置,也就是说如果父进程向文件中写入内容,写到哪儿,读写位置就会停留在哪儿,那么子进程读取数据的时候就会从当前读写位置之后开始读,但是读写位置后面没数据啊,怎么让子进程从开头开始读呢?
这就是我们要真正理解管道的底层原理之前至关重要的一步,只有将这两个问题解决了,我们才能对管道有更深的理解。
我们先解决第二个问题:
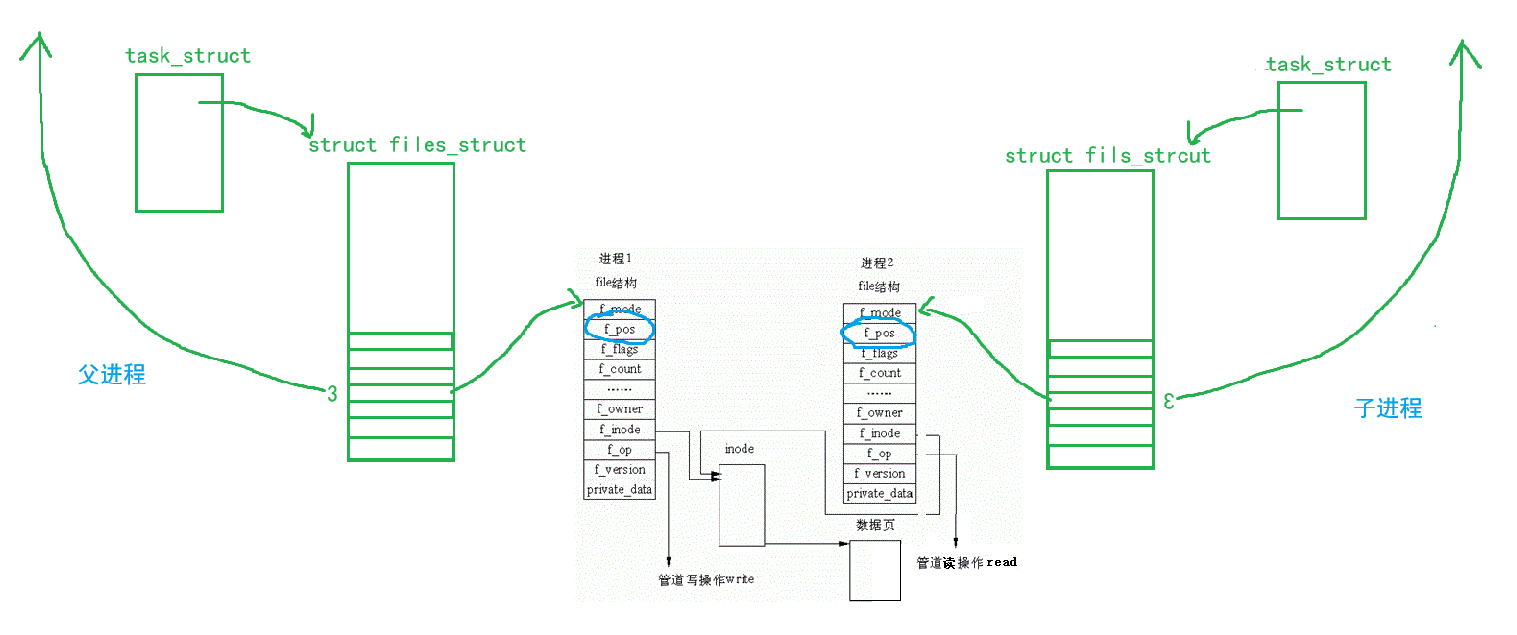
其实呢,当要利用管道文件进行进程间通信时,子进程也会将父进程的struct file也同时拷贝下来,这样读写位置不就有两个了吗,你父进程该写写,你有你的读写位置,不影响我子进程,我又没写,所以我读取的时候就会从文件的开始处进行读取。
这样不就解决了只有一个读写位置存在的问题了吗?
而针对第一个问题我的回答是:管道文件是一个内存级别的文件,也就是管道文件并不是我们认知中位于磁盘的普通文件,它是位于内存中的一个文件,我们是看不到的,所以也就不会将文件缓冲区的内容刷新到磁盘上了。
而有了上面的理解后,我们就可以看看更为完整的过程:
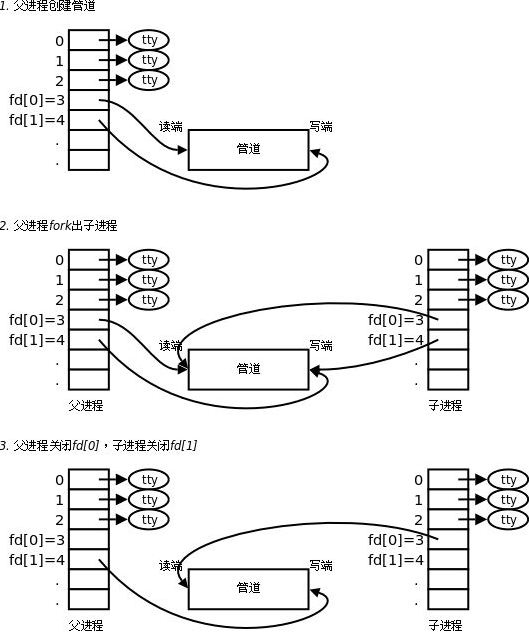
看了这张图,想必大家问题应该还不少,我用下面几个问题来为大家解决疑惑:
1.为什么要使用读写方式打开管道文件?
要解决这个问题,我们要先知道:
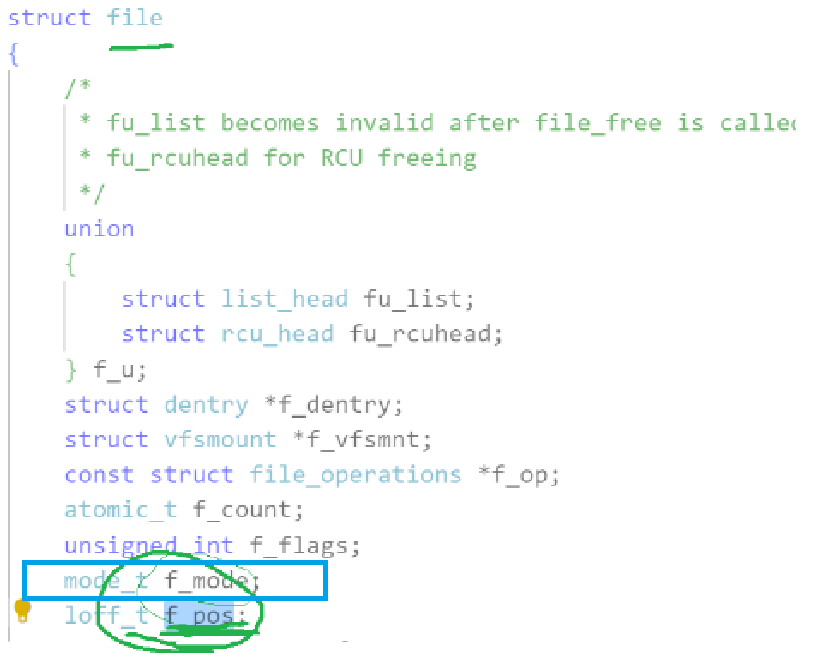
在struct file中是有mode_t f_mode这个成员变量来记录的打开文件的方式的,如果父进程只以读(read)或者写(write)的方式来打开文件,之后子进程继承父进程的struct file后,里面的mode_t f_mode也就会是同样的打开方式,那么父子进程就都会是读(read)或者写(write)这一种方式。
那么就无法做到父进程写(write)而子进程读(read)了,大家想一想是不是这个理?
所以以读写方式打开管道文件就是为了让子进程也继承rw方式!!!
2.为什么要关闭读写端?
相信大家都有这样的疑惑:父进程该写就写,我不用父进程读取数据,子进程该读就读,不用它来写入数据不就行了,为什么要关闭父子进程的读写端呢?
如你所说,不关闭其实也可以通信,但是建议关闭,主要还是为了避免误操作,那万一你用父进程读取数据了呢?万一你用子进程写入数据了呢?
除了可能会误操作外最大的原因是管道只需要单向通信!!!
这点我们可以借鉴生活中的例子,就比如:天然气管道,这个想必大家都不陌生,家中应该都有这种管道,用来向百姓家中输送天然气,它就是单向运输的,难不成还能从百姓家中输送天然气到其它地方吗?这不倒反天罡嘛,所以说管道这个名字起的还是比较贴合实际的。
这样的例子我们生活中还有很多,我们以这样的方式理解管道的单向通信就好理解多了。
3.上面的例子中是父写子读,那能不能父读子写呢?那能不能互相通信呢?
既然能父写子读,那么当然就可以父读子写,而要想做到父子进程间互相通信,创建两个管道就好了。
一个管道负责父写子读,另一个管道负责父读子写,这样不就实现了父子进程间的互相通信吗?
而有了上面的完整认知后,我们就可以对管道进行一个更为完整的定义:管道是一个基于文件系统的一个内存级的单向通信的文件,是主要用来完成进程间通信的一种方式!!!
3.3管道的demo代码
上面都是些概念性的东西,都是只停留在纸面上的,能不能实操一下见见呢?
包能的,管道要想实操我们就有必要了解一个系统调用:
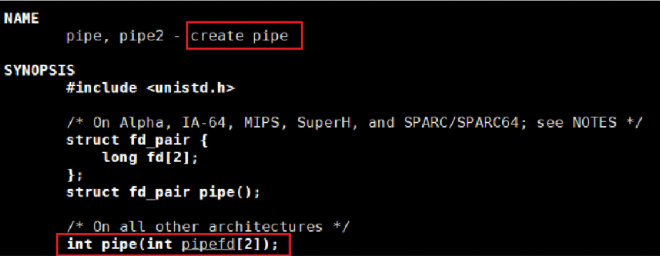
正是管道的系统调用,pipe这个系统调用函数的作用就是创建一个管道文件,并且我们可以看到它的参数是一个int类型的数组,并且只有两个数,这个数组是什么呢?
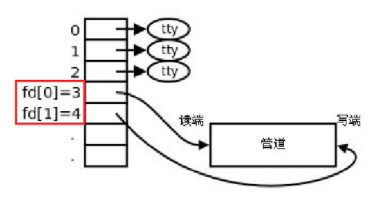
想必我们在看这张图都对旁边的这个fd数组比较好奇,上面我没讲,这里我就告诉大家这个数组正是pipe函数的参数数组。
这个pipefd数组是一个输出型参数,所谓的输出型参数我在进程等待的章节就已经讲过,这里就不再赘述了,我们随意传入一个int类型的容量为2的数组,它就会带出来两个文件描述符。打开管道文件不比我们平常打开的普通文件,绝大多数情况下不管以何种方式打开一个普通文件,都是会返回一个文件描述符,而以读写的方式打开管道文件,则会返回两个文件描述符。
如果我们在一个程序中在这之前并未打开过任意一个文件,那么这两个文件描述符的值就应为3和4,毕竟0,1,2是标准输入流,标准输出流和标准错误流这三兄弟。
简单介绍了pipe函数的参数,我们下来看看它的返回值:

它的返回值是也是int类型,创建成功的话就返回0,创建失败的话就返回-1。
有了上面对pipe函数的简单认识,下面就来用一个简单的例子来带大家看看:
int main()
{
int pipefd[2]={0};
int n=pipe(pipefd);
if(n == 0)
{
printf("pipe success, pipefd[0] = %d,pipefd[1] = %d\n",pipefd[0],pipefd[1]);
}
return 0;
}
结果正如我们上面所说,数组中的两个数分别为3和4,并且我们要知道数组的0号下标代表的是读,1号下标代表的是写,数组中下标0和1当中的文件描述符未来可能并不是3和4,但0代表读,1代表写这是固定不变的!!!
对于上面的例子,想必大家会有这样的疑问:我们打开文件了吗?有路径吗?有文件名吗?
既然都有了文件描述符,说明我们一定是打开了文件,那么路径呢?
上面我们说了,管道文件是内存级的文件,既然不在磁盘上,自然也就没有路径,那有文件名吗?
既然是在内存中,自然也就没有名字,所以截止到现在我们讲的都是管道中的匿名管道!!!
3.4匿名管道的4种情况和5大特性
对于匿名管道而言,它有4种情况和5大特性,下面我先依次讲解5大特性。
3.4.1五大特性
经过上面对管道知识的了解,我们现在可以得出两大特性:
1.单向通信,这点想必不用多介绍了
2.常用于具有血缘关系的进程,进行IPC,常用于父子进程之间
针对第二条也是为什么我上面一直用的都是父子进程来演示,因为匿名管道的特殊性,两个没有血缘关系的进程是不可能看到同一份资源的,也就不可能实现进程间通信,血缘关系对于匿名管道来说是刚需的。
而后面要讲的命名管道对血缘关系就没有要求了,不过这都是后话了,等讲到的时候我们再说。
那么我们现在来思考一个问题:既然我们打开了匿名管道文件,那该如何关闭呢?或者说不关闭会怎样?
这个问题的答案就是匿名管道的第三大特性:管道的生命周期跟随进程,也就是当进程结束时会由操作系统来对匿名管道文件进行关闭回收,这个特性也可以叫做自动回收特性。
下面我用一个例子来实现上面父读子写的同时,来展现后两大特性:
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <sys/types.h>
#include <unistd.h>
#include <string>
#include <sys/wait.h>
using namespace std;
int main()
{
//1.父进程创建管道
int pipefd[2]={0};
int n=pipe(pipefd);
(void)n;
//2.通过fork创建子进程
int id=fork();
if(id < 0)
{
perror("fork");
exit(1);
}
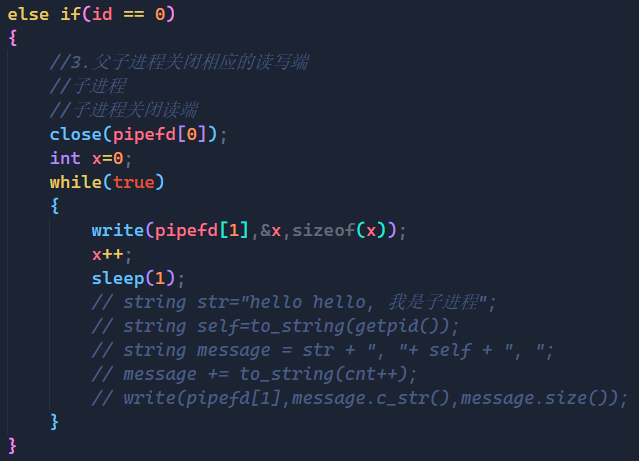
else if(id == 0)
{
//3.父子进程关闭相应的读写端
//子进程
//子进程关闭读端
close(pipefd[0]);
int cnt=0;
while(true)
{
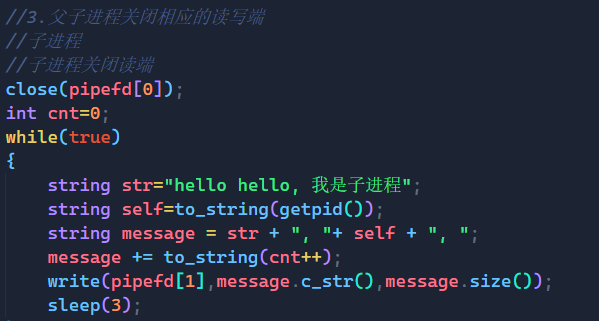
string str="hello hello, 我是子进程";
string self=to_string(getpid());
string message = str + ", "+ self + ", ";
message += to_string(cnt++);
write(pipefd[1],message.c_str(),message.size());
sleep(1);
}
}
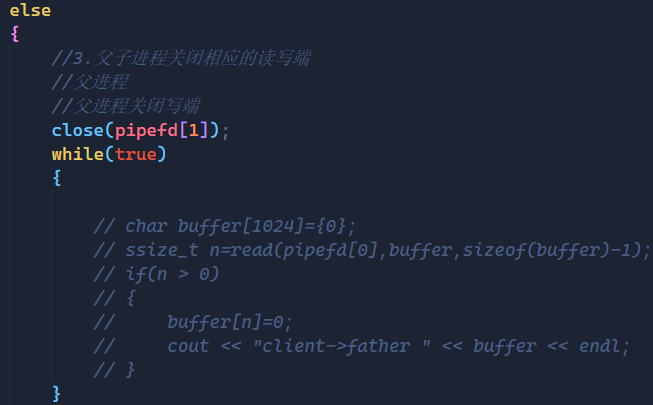
else
{
//3.父子进程关闭相应的读写端
//父进程
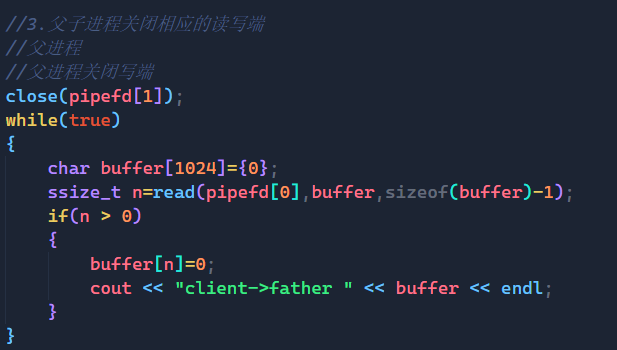
//父进程关闭写端
close(pipefd[1]);
while(true)
{
char buffer[1024]={0};
ssize_t n=read(pipefd[0],buffer,sizeof(buffer)-1);
if(n > 0)
{
buffer[n]=0;
cout << "client->father " << buffer << endl;
}
}
}
//4.传递数据
pid_t rid=waitpid(id,nullptr,0);
(void)rid;
return 0;
}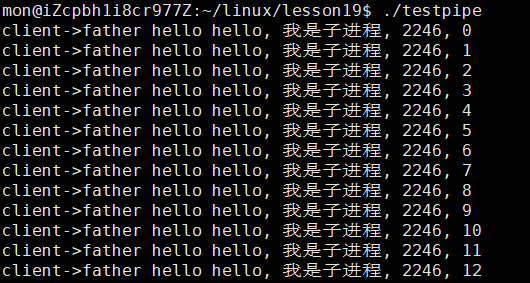

通过上面的例子,我们成功实现了父读子写的情况,由子进程向管道文件中写入内容,再由父进程从管道文件中读取,并将读取到的内容放在buffer数组中,最终将读取到的内容打印出来。
在这个例子中我们关闭了子进程的读端,关闭了父进程的写端,遵循着上面我们上面所说的关闭父子进程对应的读写端。
这里可能有人会有疑惑,那么到这里就可以解答了:pipe函数为什么要返回两个文件描述符?
我们上面也说了父子进程后面是要关闭相应的读写端的,正如我们上面所写的close,如果只有一个文件描述符,也就是只有一个struct file,那么父子进程如果关闭了相应的读写端,那么就会导致引用计数为0,也就彻底关闭了管道文件。
而如果返回了两个文件描述符,也就有了两个struct file,读端和写端的引用计数就可以分开进行计数,即使父进程关闭了写端,写端的引用计数也不会为0,因为还有子进程的写端呢,子进程也是如此,通过这种方式确保持有管道的进程可以独立管理自己的读写端,而不会因为其他进程的操作导致管道意外关闭。
下面我们就接着来看看匿名管道文件的剩下两种特性:



现在我们让父进程等待5秒后再打印内容,可以看到子进程在5秒内写入的内容会被父进程全部读出,这其实就是第四大特性:面向字节流的一种体现,不过这里展示的不完全。
面向字节流其实就是子进程往里面写,父进程可能会一次性读完,也可能分多次读完,也可能只读一部分,也就是在子进程往里面写数据的时候,父进程读取没有一个标准,换句话说就是父进程不保证每次读写的粒度一致性!!!
这里我们无法讲的太清楚,只有到网络部分的时候,到时候重谈面向字节流才能彻底讲清。
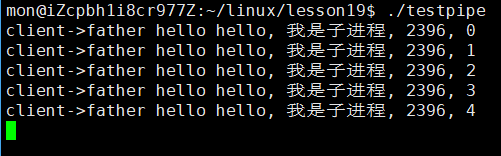
这次我们让子进程多等一会儿,父进程不再等待,可以看到,在子进程休眠期间,父进程也无法接着读取内容,因为子进程不写,父进程没有内容可读啊,父进程此时就会阻塞住,它要等子进程,所以这就是第五大特性:管道的同步机制!!!
3.4.2四种情况
其实通过上面的例子我们已经得到了第一种情况:管道里没有数据,读端就会被阻塞!!!
上面最后一种特性的例子中子进程不写,父进程也就读不到,也就会被阻塞住。
下面我们接着看:
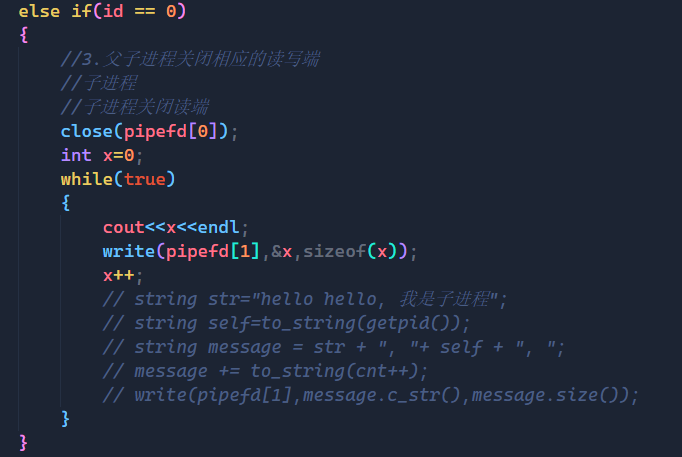

现在我们不让父进程去读,而让子进程一直向管道里面写,从结果可以看到,当写入了16385个整数后,整个程序阻塞住了,不动了,这是为什么呢?
答案就是管道中已经写满了,既然已经写满了,那自然就不能再往里面接着写了,整个程序就会阻塞住,操作系统不让写了。
以上就是第二种情况:读端不读,但是读端也不关,那么写端将管道写满时,就不再写入了!!!
我们接着往下看:
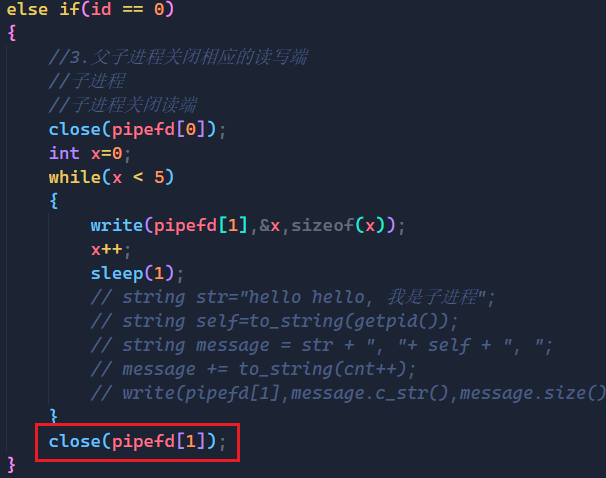
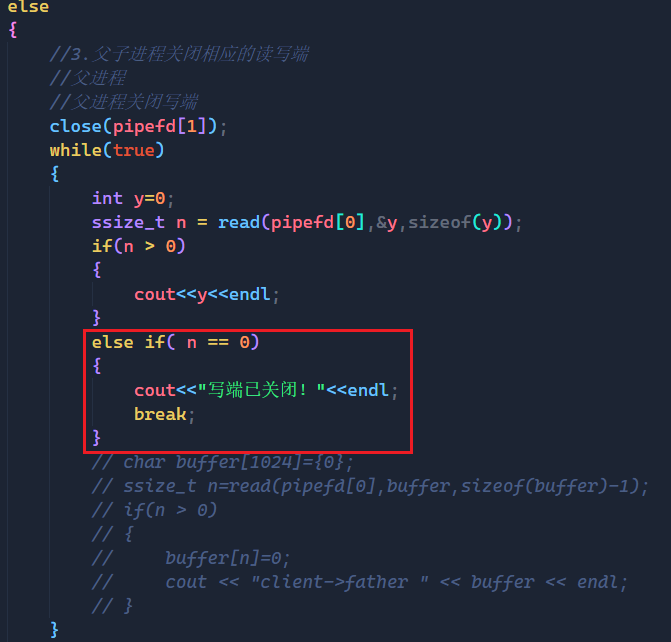
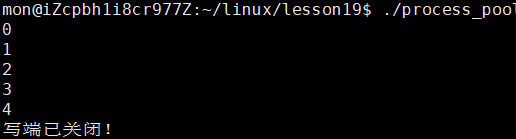
这次我们限制子进程写入的次数,写完5次后就不写了,并且将写端关闭。
而我们通过程序的输出结果可以看到,前面子进程没有关闭写端的时候,父进程还是正常读的,但是子进程关闭写端后,read函数就返回了0,也就执行了" 写段已关闭的 "程序。
这就是第三种情况:写端不写,写端关闭,那么read就会返回0,表示读到文件末尾!!!
这里我们要与第一种情况区分开,当写端不写,但是不关时,读端是会阻塞住的,但是读端一旦关了,其实就是告诉read函数:" 我不会再往管道中写了 ",read也就不会再读了,即返回0!!!
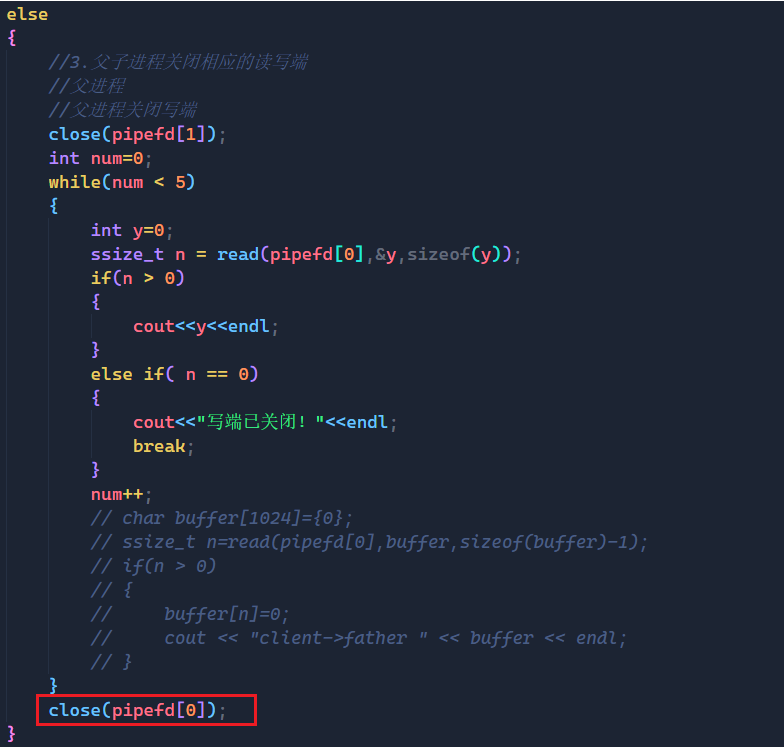
上面就是最后一种情况了,这里我先说明第四种情况的做法和结果:读端关闭,写端正常,导致的结果就是OS会自动杀掉写进程!!!
在上面的例子中我们让父进程读取5次过后不再读取,并关闭读端,这里我说一下为什么OS会自动杀掉写进程?
我们换个问法:读端关闭了,写端再向管道中写数据,不管写多少数据还有意义吗?
没有意义了,你写再怎么多的数据,没人读,那还有什么意义,所以OS不会做无效动作,它会亲自将写进程给杀掉。
而杀掉进程其实也就是给进程传递一个信号,我们之前见过:kill -9的信号,但是这次并不是它,而是另一个:
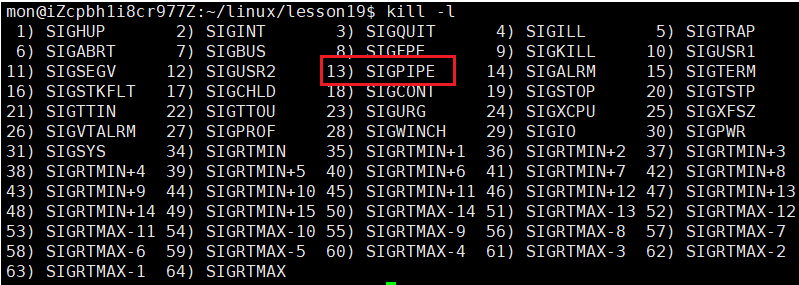
它这次所发送的信号为kill的13号信号:SIGPIPE,怎么证明呢?我们来看:
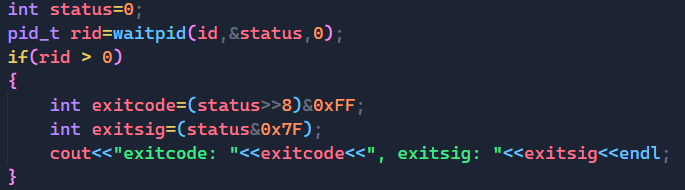
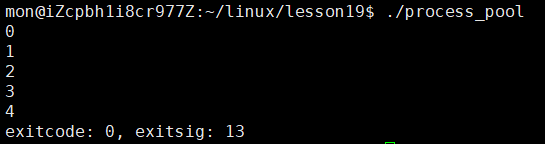
结果如我们所料,当父进程关闭读端后,子进程就被OS杀掉了,我们通过进程等待的方式可以拿到子进程的退出信息,从结果中我们可以看到,退出码为0,退出信号为13,符合我们上面所说的。
四.命名管道
有了上面对匿名管道的理解后,对于命名管道我们就不再赘述那么多了,命名管道的原理和匿名管道是一样的,所以下面我们直接就从实操开始。
4.1命名管道的操作:命令级
我们是可以通过系统的内置命令来创建命名管道的,下面我们看看所创建的命名管道长什么样:
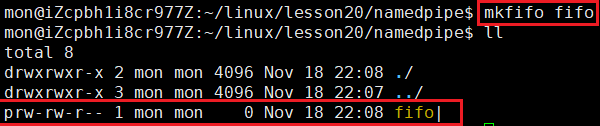
上面我们就通过mkfifo命令创建了一个名为fifo的命名管道文件,可以看到这个文件权限的最前面是p,在linux中p就表示该文件是管道文件。
命名管道与匿名管道不同的是匿名管道我们看不见也摸不着,只能通过pipe函数来感知它的存在,但是命名管道我们是看得见也摸得着的,就和我们看见的普通文件是一样的。
命名管道之所以叫命名管道也正是以为它是有名字的,就像上面我为命名管道取名为fifo一样。
那么下面我用一个简单的例子来为大家演示命名管道的操作:



这里我们通过" > "来完成重定向的工作,将我们要输出的内容重定向到fifo中,最后通过" < "来将fifo中的内容给输出出来。
其实从这里我们就已经能够看到,明明是两个毫无关系的进程,却能通过fifo进行通信,这就是命名管道与匿名管道的重要区别:命名管道不依赖血缘关系!!!
那为什么上面echo的命令我截了两张图呢?
第一张图是还没有执行cat时候的现象,执行echo命令后,程序阻塞住了,而当执行cat命令后,echo进程就不再阻塞,这是为什么呢?
这是命名管道的一个特性:当读端没有打开时,写端会阻塞住!!!

我们接着看,我们上面通过重定向向fifo中写入数据,又通过重定向读取数据后,fifo文件的大小依旧是0,为什么呢?
上面我们说了命名管道和匿名管道的原理是一样的,而匿名管道不会将缓冲区的数据刷新到磁盘上,命名管道也同样不会将缓冲区中的数据刷新到磁盘的文件中,所以我们看到的fifo文件大小始终为0。
4.2命名管道的操作:代码级
上面命名管道是比匿名管道多了一种命令级别的操作,但是和匿名管道一样的是它同样也有系统调用函数,也可以进行代码级的操作,我们下面来看看:
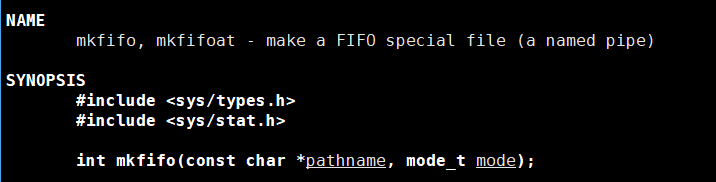

这个系统调用函数和命令的名字是一样的,都是mkfifo,这个函数的两个参数分别就是文件的路径名称以及要给文件设置的权限。
而返回值和pipe的返回值是一样的,创建成功就返回0,失败就返回-1。
下面我们就用一个简单的例子来实现两个毫不相关的进程间的通信:
首先我们要先有两个进程,这里我用的就是client表示客户端,后面是向管道中写入内容的,server表示服务端,后面是用来读取管道中的内容的。
而common.hpp是来保存二者都相通的内容的,这样写起来更加方便,Makefile的作用想必不用多说。
有了这些前置工作,我们就来补充里面的内容:
Makefile:
.PHONY:all
all:server client
server:server.cc
g++ -o $@ $^ -std=c++11
client:client.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f server clientcommon.hpp:
#pragma once
#include <iostream>
#include <cstdio>
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
using namespace std;
const string fifoname = "fifo";
mode_t mode = 0666;
#define SIZE 1024server.cc:
#include "common.hpp"
int main()
{
// 1.创建命名管道文件
int n = mkfifo(fifoname.c_str(), mode);
if (n < 0)
{
perror("mkfifo:");
exit(1);
}
// 2.打开管道文件
int fd = open(fifoname.c_str(), O_RDONLY);
if (fd < 0)
{
perror("open:");
exit(1);
}
// 3.读取管道内容
char buffer[SIZE];
while (true)
{
// 清空字符数组
buffer[0] = 0;
ssize_t m = read(fd, buffer, sizeof(buffer) - 1);
if (m > 0)
{
buffer[m] = 0;
cout << "client read: " << buffer << endl;
}
else if (m == 0)
{
cout << "server quit, me too!" << endl;
break;
}
}
// 回收管道
close(fd);
unlink(fifoname.c_str());
return 0;
}client:
#include "common.hpp"
int main()
{
//1.打开文件
int fd=open(fifoname.c_str(),O_WRONLY);
if(fd < 0)
{
perror("open:");
exit(1);
}
//2.向管道中写入内容
string message;
while(true)
{
cout<<"请输入:";
getline(cin,message);
write(fd,message.c_str(),message.size());
}
return 0;
}以上就是所有文件的全部代码,我们下面看看实战效果:
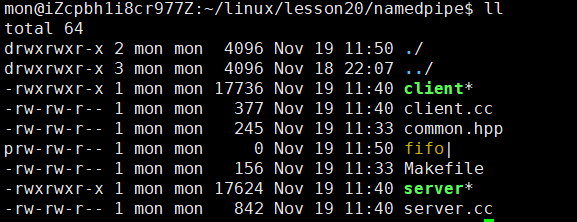

从结果中我们可以看到在启动server和client后,我们在client中输入数据,在server端就可以立即读取出来,至此我们就实现了毫无关系的两个进程间的通信。
从上面的代码中我们可以看到,无非就是server创建管道文件,再打开文件,最后等着读取数据即可,client则更为简单,打开server创建的管道文件,向其中写入内容就行。因为server和client打开的是同一个文件,路径是唯一的,所以它们看到的是同一份资源。
毕竟fifo我们是看得见摸得着的,对其进行操作不就是对文件进行操作吗?
至此我们就可以总结命名管道的作用:主要解决,毫无关系的进程之间,进行文件级的进程通信!!!
以上就是管道如何连接进程?从基础原理到高级应用,构建你的进程通信全景视野的全部内容。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号