ACS Cent. Sci. | 革命与阻碍:机器学习在生物催化中的新兴角色

ACS Cent. Sci. | 革命与阻碍:机器学习在生物催化中的新兴角色

DrugAI
发布于 2026-01-06 12:41:43
发布于 2026-01-06 12:41:43
DRUGONE
机器学习正在迅速成为生物催化领域的核心技术。通过学习氨基酸序列、蛋白质结构及功能数据中的模式,机器学习模型能够帮助研究人员探索复杂的适应性景观、在数据库中发现新型酶,甚至实现全新的酶设计。随着 DNA 合成与测序技术的进步,以及实验室自动化和高通量筛选的普及,机器学习显著提升了酶开发的速度与效率。本综述总结了机器学习在酶发现、设计与工程中的最新应用,重点分析了当前面临的挑战与新兴解决方案,并探讨了影响该领域进一步发展的障碍与未来方向。

近年来,蛋白质设计与工程经历了深刻变革,出现了定制化蛋白质结合剂、纳米颗粒疫苗与新型分子传感器等成果。这些突破得益于机器学习在结构预测、全新设计和序列–功能映射中的应用。传统上,酶的开发依赖于定向进化,而机器学习的引入为该流程提供了新的动力。酶发现、酶设计和酶工程是生物催化的三大关键任务,机器学习工具已经在其中展现出超过传统方法的潜力。然而,酶的复杂反应机制和实验验证的特殊要求,仍使得该领域充满挑战。
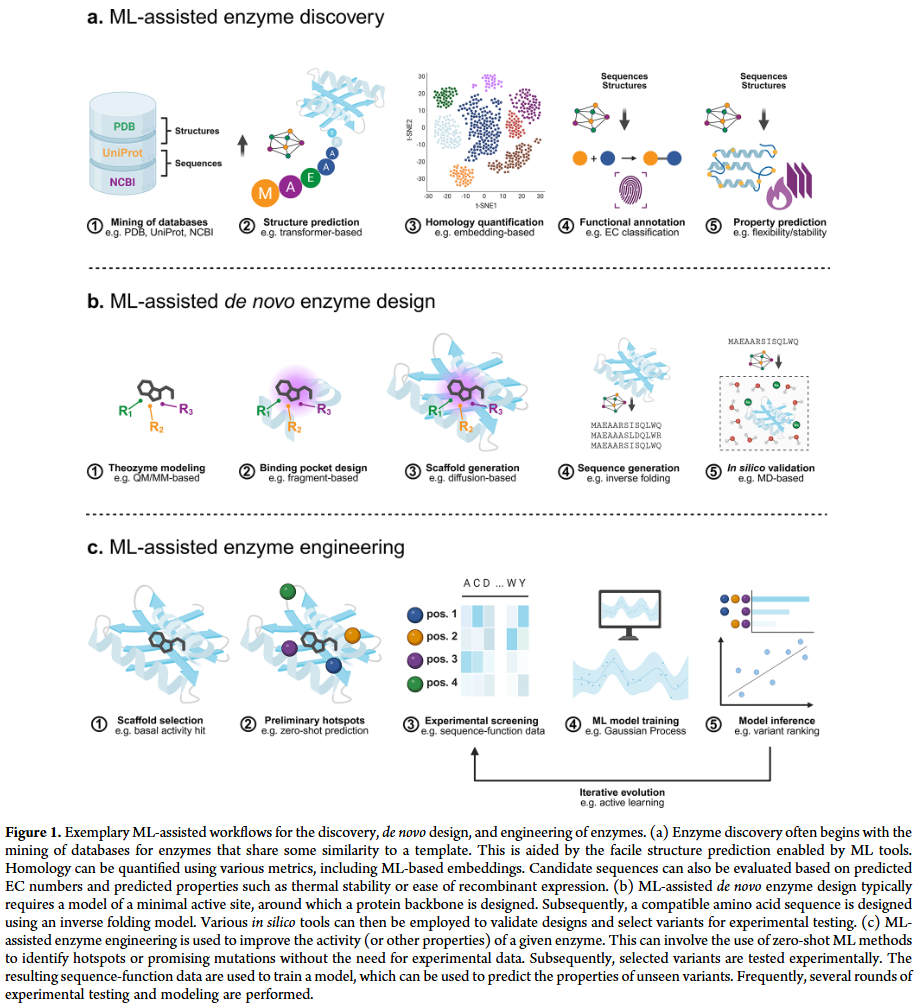
酶开发的新范式
酶发现
- 数据库挖掘:现代基因组和宏基因组项目产生了数亿条蛋白质序列,其中大多数未被实验验证。机器学习工具可结合序列同源性、结构预测与功能注释,提高挖掘效率。
- 结构驱动的发现:随着 AlphaFold 等工具的发展,研究人员能够基于预测结构进行大规模挖掘,克服了序列同源性方法的局限。
- 功能注释与预测:对比学习、图神经网络等方法使 EC 编号及动力学参数预测更加准确,但受限于实验数据稀缺与不一致性。
酶设计
- 早期探索:最初的全新酶设计基于“理论酶”(theozyme)和天然骨架,但活性较低,需要大量定向进化。
- 深度学习革命:AlphaFold、RFdiffusion 等生成模型使得设计准确性显著提升,能够围绕特定活性位点生成新的结构。
- 序列生成与语言模型:蛋白质语言模型展现出生成远离训练集的新序列的能力,并可结合强化学习实现定向优化。
- 挑战:预测高活性变体仍然困难,需要结合动力学模拟、电场效应和构象动态分析来提高设计成功率。
酶工程
- 传统方法局限:序列空间庞大且易陷入局部最优,定向进化效率有限。
- 机器学习辅助定向进化(MLDE):通过训练模型预测序列–功能关系,迭代优化突变选择,提高效率。
- 关键因素:数据编码方式、模型选择、训练数据规模与质量都影响结果。零样本预测和迁移学习成为重要方向。
- 多目标优化:尽管工业应用常需兼顾活性、热稳定性和溶解性,但多目标酶工程仍未充分探索。
实验技术进展
- DNA 合成与测序成本下降:使得大规模训练数据与验证成为可能。
- 高通量筛选与自动化:微流控、细胞传感器、质谱耦合检测等方法提高了数据生成速度。
- 挑战:实验条件差异和噪声会影响模型可靠性,需要更标准化的流程与元数据报告。
采用与推进机器学习流程的挑战
- 工具可及性:许多工具缺乏统一接口,对非计算背景研究人员不够友好。
- 跨学科沟通障碍:实验人员与计算人员之间常存在数据需求与实际产出之间的落差。
- 协作模式:有效合作需要在项目初期明确目标、实验方案与数据可行性。

未来方向
- 数据集建设:需要跨酶家族的大规模、高质量数据,涵盖催化参数、表达水平与稳定性等。
- 多模态模型:整合序列、结构与功能信息,有望实现更精确的多目标优化。
- 统一管线:将酶设计与工程结合,形成“生成–优化–反馈”的闭环工作流。
- 标准化与验证:通过竞赛和基准测试,推动社区对工具性能的信任与采用。
- 民主化发展:建立开源工具、集中式生物工厂与低成本自动化平台,降低技术门槛。
- 绿色化学应用:面向二氧化碳固定、废弃物升值等“梦想反应”的酶开发,将推动可持续经济转型。
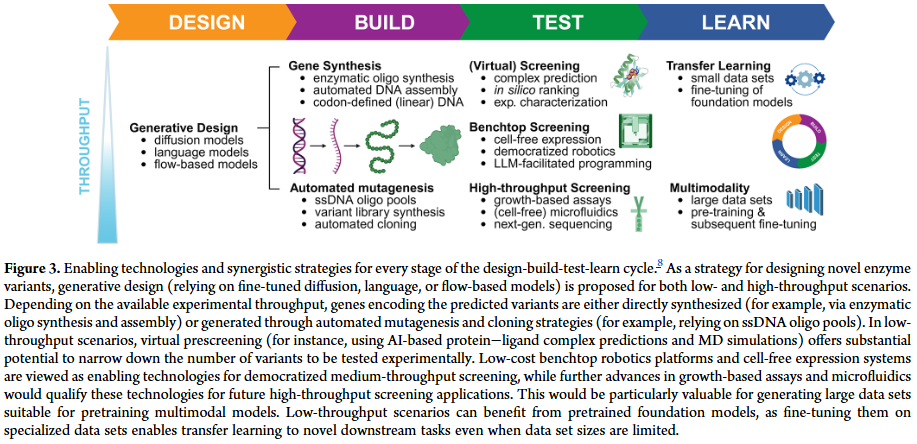
总结
机器学习正为生物催化注入革命性动力,但同时也面临数据、工具与协作上的阻碍。研究人员认为,通过构建高质量数据集、发展多模态模型、加强自动化实验和跨学科合作,机器学习将在未来几年显著拓展酶开发的能力,并推动生物催化在工业和绿色化学中的应用。
整理 | DrugOne团队
参考资料
Of Revolutions and Roadblocks: The Emerging Role of Machine Learning in Biocatalysis. Tobias Vornholt, Peter Stockinger, Mojmír Mutný, Markus Jeschek, Bettina Nestl, Gustav Oberdorfer, Silvia Osuna, Jürgen Pleiss, Ditte Hededam Welner, Andreas Krause, Rebecca Buller, and Thomas R. Ward. ACS Central Science.
DOI: 10.1021/acscentsci.5c00949
内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号