【SpringBoot实战系列】Sharding-Jdbc实现分库分表到分布式ID生成器Snowflake自定义wrokId实战

【SpringBoot实战系列】Sharding-Jdbc实现分库分表到分布式ID生成器Snowflake自定义wrokId实战

工藤学编程
发布于 2025-12-22 09:16:50
发布于 2025-12-22 09:16:50
大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
作业侠系列最新文章😉 | Java实现聊天程序 |
SpringBoot实战系列🐷 | 【SpringBoot实战系列】Sharding-Jdbc实现分库分表到分布式ID生成器Snowflake自定义wrokId实战 |
环境搭建大集合 | 环境搭建大集合(持续更新) |
在本栏中,我们之前已经完成了: 【SpringBoot实战系列】之发送短信验证码 【SpringBoot实战系列】之从Async组件应用实战到ThreadPoolTaskExecutor⾃定义线程池 【SpringBoot实战系列】之图形验证码开发并池化Redis6存储 【SpringBoot实战系列】阿里云OSS接入上传图片实战
本片速览: 1.ShardingSphere 下的Sharding-JDBC简介 2.分库分表和Sharding-Jdbc常⻅概念术语介绍 3.Sharding-Jdbc实现分库分表实战 4.分库分表暴露的问题-ID冲突及解决 5.分布式 ID ⽣成算法Snowflake原理 6.Snowflake自定义wrokId实战
ShardingSphere 下的Sharding-JDBC简介
- 地址:https://shardingsphere.apache.org/
- Apache ShardingSphere 是⼀套开源的分布式数据库中间件解决⽅案组成的⽣态圈
- 它由 Sharding-JDBC、Sharding-Proxy 和 ShardingSidecar 3个独⽴产品组合
- Sharding-JDBC 基于jdbc驱动,不⽤额外的proxy,⽀持任意实现 JDBC规范的数据库 它使⽤客户端直连数据库,以 jar 包形式提供服务,⽆需额外部署和依赖 可理解为加强版的 JDBC 驱动,兼容 JDBC 和各类 ORM框架
Mycat和ShardingJdbc区别
- 两者设计理念相同,主流程都是SQL解析–>SQL路由–>SQL改 写–>结果归并
- sharding-jdbc 基于jdbc驱动,不⽤额外的proxy,在本地应⽤层重写Jdbc原⽣的⽅法,实现数据库分⽚形式 是基于 JDBC 接⼝的扩展,是以 jar 包的形式提供轻量级服务的,性能⾼ 代码有侵⼊性
- Mycat 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server伪装成⼀个 MySQL 数据库 客户端所有的jdbc请求都必须要先交给MyCat,再由MyCat转发到具体的真实服务器 缺点是效率偏低,中间包装了⼀层 代码⽆侵⼊性
分库分表和Sharding-Jdbc常⻅概念术语介绍
- 数据节点Node 数据分⽚的最⼩单元,由数据源名称和数据表组成 ⽐如:ds_0.product_order_0
- 真实表 在分⽚的数据库中真实存在的物理表 ⽐如订单表 product_order_0、product_order_1、product_order_2
- 逻辑表 ⽔平拆分的数据库(表)的相同逻辑和数据结构表的总称⽐如订单表 product_order_0、product_order_1、product_order_2,逻辑表就是product_order
- 绑定表 指分⽚规则⼀致的主表和⼦表 ⽐如product_order表和product_order_item表,均按照order_id分⽚,则此两张表互为绑定表关系绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将⼤⼤提升 +⼴播表 指所有的分⽚数据源中都存在的表,表结构和表中的数据在每 个数据库中均完全⼀致 适⽤于数据量不⼤且需要与海量数据的表进⾏关联查询的场景 例如:字典表、配置表
Sharding-Jdbc实现分库分表实战 先来建两个表
CREATE TABLE `traffic_0` (
`id` int(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`account_no` bigint DEFAULT NULL COMMENT '账号'
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;CREATE TABLE `traffic_1` (
`id` int(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`account_no` bigint DEFAULT NULL COMMENT '账号'
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<sharding-jdbc.version>4.1.1</sharding-jdbc.version>
</dependency>mybatis-plus
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<mybatisplus.boot.starter.version>3.4.0</mybatisplus.boot.starter.version>
</dependency>设置配置:
shardingsphere:
datasource:
ds0:
connectionTimeoutMilliseconds: 30000
driver-class-name: com.mysql.cj.jdbc.Driver
idleTimeoutMilliseconds: 60000
jdbc-url: jdbc:mysql://127.0.0.1:3306/user_account?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
maintenanceIntervalMilliseconds: 30000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 50
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
names: ds0
props:
# 打印执⾏的数据库以及语句
sql:
show: true
sharding:
tables:
traffic:
actual-data-nodes: ds0.traffic_$->{0..1}
# ⽔平分表策略+⾏表达式分⽚
table-strategy:
inline:
algorithm-expression: traffic_$->{ account_no % 2 }
sharding-column: account_no对应实体类 只需要有account_no就行,应为分片策略需要使用,其他字段无所谓
测试:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = AccountApplication.class)
@Slf4j
public class trafficTest {
@Resource
private TrafficMapper trafficMapper;
Random random = new Random();
@Test
public void insert(){
for(int i=0;i<10;i++){
TrafficDO trafficDO = new TrafficDO();
trafficDO.setAccountNo(Long.valueOf(random.nextInt(100)));
;
trafficMapper.insert(trafficDO);
}
}
}运行后使用navicat可视化工具查看如下:
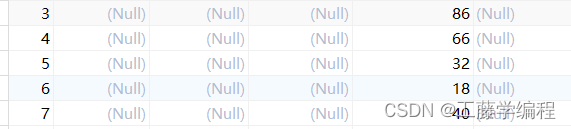
在这里插入图片描述

在这里插入图片描述
根据我们的分区策略,%2来选择插入那个表
但是有个问题
两个表主键id互相重复
上面分库分表暴露的问题-ID冲突
解决方法:分布式id⽣成
分布式id生成需求
- 性能强劲
- 全局唯⼀
- 防⽌恶意⽤户根据id的规则来获取数据 业界常⽤ID解决⽅案
- 数据库⾃增ID 利⽤⾃增id, 设置不同的⾃增步⻓, auto_increment_offset、auto-increment-increment DB1: 单数 //从1开始、每次加2 DB2: 偶数 //从2开始,每次加2 缺点 依靠数据库系统的功能实现,但是未来扩容麻烦主从切换时的不⼀致可能会导致重复发号 性能瓶颈存在单台sql上
- UUID 性能⾮常⾼,没有⽹络消耗 缺点 ⽆序的字符串,不具备趋势⾃增特性 UUID太⻓,不易于存储,浪费存储空间,很多场景不适⽤
- Redis发号器 利⽤Redis的INCR和INCRBY来实现,原⼦操作,线程安全,性能⽐Mysql强劲 缺点 需要占⽤⽹络资源,增加系统复杂度
- Snowflake雪花算法 twitter 开源的分布式 ID ⽣成算法,代码实现简单、不占⽤宽带、数据迁移不受影响 ⽣成的 id 中包含有时间戳,所以⽣成的 id 按照时间递增部署了多台服务器,需要保证系统时间⼀样,机器编号不⼀样 缺点 依赖系统时钟(多台服务器时间⼀定要⼀样)
分布式 ID ⽣成算法Snowflake原理 什么是雪花算法Snowflake twitter⽤scala语⾔编写的⾼效⽣成唯⼀ID的算法 优点 ⽣成的ID不重复 算法性能⾼ 基于时间戳,基本保证有序递增 雪花算法⽣成的数字,long类,所以就是8个byte,64bit表示的值 -9223372036854775808(-2的63次⽅) ~9223372036854775807(2的63次⽅-1) ⽣成的唯⼀值⽤于数据库主键,不能是负数,所以值为0~9223372036854775807(2的63次⽅-1)

在这里插入图片描述
使用Sharding-Jdbc配置⽂件,设置主键生成使用雪花算法,配置变为如下
shardingsphere:
datasource:
ds0:
connectionTimeoutMilliseconds: 30000
driver-class-name: com.mysql.cj.jdbc.Driver
idleTimeoutMilliseconds: 60000
jdbc-url: jdbc:mysql://127.0.0.1:3306/user_account?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
maintenanceIntervalMilliseconds: 30000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 50
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
names: ds0
props:
# 打印执⾏的数据库以及语句
sql:
show: true
sharding:
tables:
traffic:
actual-data-nodes: ds0.traffic_$->{0..1}
# ⽔平分表策略+⾏表达式分⽚
table-strategy:
inline:
algorithm-expression: traffic_$->{ account_no % 2 }
sharding-column: account_no
#id⽣成策略
key-generator:
column: id
props:
worker:
id: 0
#id⽣成策略
type: SNOWFLAKE再次运行我们之前编写的测试代码,可在数据库中看到如下结果:
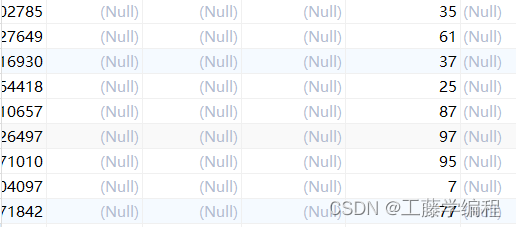
在这里插入图片描述
好了,主键id不一样了,我们分布式下我们还要保证workid不同和account_no不同,于是我们需要编写以下代码
@Configuration
@Slf4j
public class SnowFlakeWordIdConfig {
/**
* 动态指定sharding jdbc 的雪花算法中的属性work.id属 性
* 通过调⽤System.setProperty()的⽅式实现,可⽤容器的
id 或者机器标识位
* workId最⼤值 1L << 100,就是1024,即 0<= workId
< 1024
* {@link
SnowflakeShardingKeyGenerator#getWorkerId()}
*
*/
static {
try {
InetAddress ip4 = Inet4Address.getLocalHost();
String addressIp = ip4.getHostAddress();
String workerId = (Math.abs(addressIp.hashCode())%1024)+"";
System.setProperty("workerId", workerId);
} catch (UnknownHostException e) {
log.error("生成雪花id出错{}",e);
}
}
}并将配置中的
props:
worker:
id: 0
#id⽣成策略
type: SNOWFLAKE
改为
props:
worker:
id: ${workerId}
#id⽣成策略
type: SNOWFLAKE同样使用雪花算法生成acoount_no 代码:
public class IDUtil {
private static SnowflakeShardingKeyGenerator shardingKeyGenerator = new SnowflakeShardingKeyGenerator();
/**
* 雪花算法⽣成器,配置workId,避免重复
* <p>
* 10进制 654334919987691526
* 64位
* 0000100100010100101010100010010010010110000000000000
* 000000000110
* <p>
*
* @return
*/
public static Comparable<?> geneSnowFlakeID() {
return shardingKeyGenerator.generateKey();
}
}将测试代码中的随机生成换位idutil的生成即可
@Test
public void insert(){
for(int i=0;i<10;i++){
TrafficDO trafficDO = new TrafficDO();
//trafficDO.setAccountNo(Long.valueOf(random.nextInt(100)));
trafficDO.setAccountNo(Long.valueOf(IDUtil.geneSnowFlakeID().toString()));
trafficMapper.insert(trafficDO);
}
}
}运行后,如下:
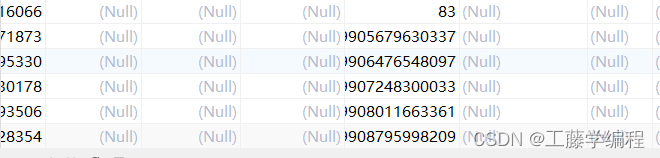
在这里插入图片描述
本篇完!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号