【拿捏热图/详细注释】pyComplexHeatmap系列(二)之大型复杂注释热图绘制

【拿捏热图/详细注释】pyComplexHeatmap系列(二)之大型复杂注释热图绘制

KS科研分享与服务-TS的美梦
发布于 2025-12-20 17:20:46
发布于 2025-12-20 17:20:46
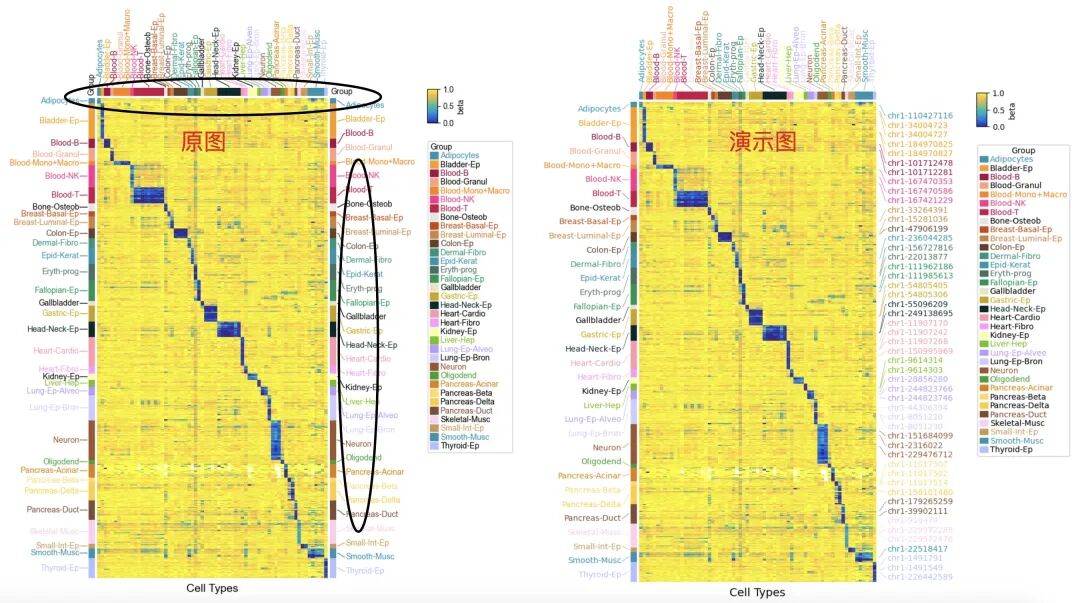
接着上一节的介绍(【拿捏热图/详细注释】pyComplexHeatmap系列(一)之基础绘制之差异基因聚类热图并标注关键基因)。从简单的入手了解函数的基本用法,然后就可以使用复杂的绘制了,万变不离其宗,关于大型热图,其实也就是多了更多的注释分组,数据集更大而已,思路与基础绘图是没有什么太大区别的。我们使用pyComplexHeatmap库官方教材提供的示例数据进行解读演示!与R中ComplexHeatmap相比,在处理可视化大型数据集上,pyComplexHeatmap的能力更强,出图很快。
虽然数据和示例使用的是官网教程,但是我们演示了一些其他操作:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import PyComplexHeatmap as pch
#from PyComplexHeatmap import * #导入所有类与函数#read data
data=pd.read_csv("https://raw.githubusercontent.com/DingWB/PyComplexHeatmap/main/data/Loyfer2023.meth.csv",sep='\t',index_col=0)
df_row=pd.read_csv("https://raw.githubusercontent.com/DingWB/PyComplexHeatmap/main/data/Loyfer2023.meth.rows.csv",sep='\t',index_col=0)
df_col=pd.read_csv("https://raw.githubusercontent.com/DingWB/PyComplexHeatmap/main/data/Loyfer2023.meth.cols.csv",sep='\t',index_col=0)#可视化矩阵是一个dataframe,单细胞甲基化数据,行是甲基化信息,列是celltype
data.head()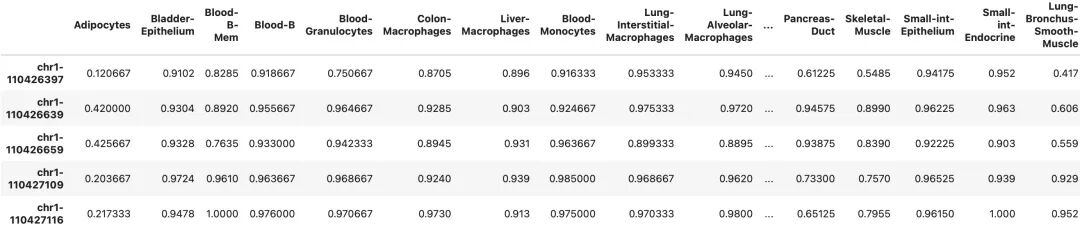
#对行数据的注释文件
#注释文件的index要与data矩阵顺序一致
df_row.head()
#对列的注释文件
#注释文件的index要与data矩阵顺序一致
df_col.head()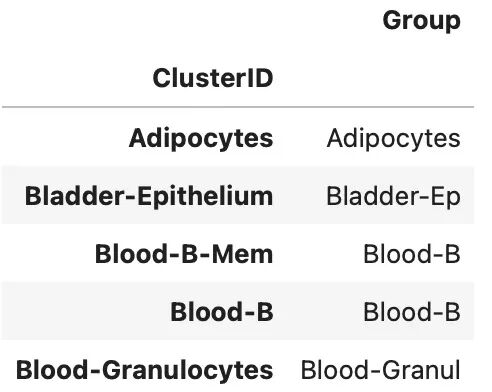
#设置分组颜色,使用字典一一对应
#这个配色还是挺好的,可以保留使用
col_colors_dict={
'Adipocytes':'#1E93AE','Bladder-Ep':'#FF9C00','Blood-B':'#A40043','Blood-Granul':'#FF9F7F',
'Blood-Mono+Macro':'#FF7F00','Blood-NK':'#FF2E8D','Blood-T':'#CC0043','Bone-Osteob':'#E5E5E5',
'Breast-Basal-Ep':'#CC4407','Breast-Luminal-Ep':'#CC843D','Colon-Ep':'#663D28','Dermal-Fibro':'#1E937C',
'Epid-Kerat':'#1E93AE','Eryth-prog':'#40705F','Fallopian-Ep':'#009351','Gallbladder':'#E7E4BF',
'Gastric-Ep':'#CCA300','Head-Neck-Ep':'#002929','Heart-Cardio':'#FF99AA','Heart-Fibro':'#FF99FF',
'Kidney-Ep':'#F6FF99','Liver-Hep':'#6CBF00','Lung-Ep-Alveo':'#BA99FF','Lung-Ep-Bron':'#CCCCFF',
'Neuron':'#9e542e','Oligodend':'#2ca02c','Pancreas-Acinar':'#DF7F00','Pancreas-Beta':'#FFD866',
'Pancreas-Delta':'#FFCC32','Pancreas-Duct':'#7F4C33','Skeletal-Musc':'#FFCCEE','Small-Int-Ep':'#CC9951',
'Smooth-Musc':'#1E93AE','Thyroid-Ep':'#B2BFFF'}#注释信息,原图演示了左右顶部的注释,但是一般plot热图,顶部和左侧注释即可,右侧可以选择展示部分行名
#pyComplexHeatmap的注释还是比较好整的,只需要HeatmapAnnotation一个函数
#anno_label用于设置标签文字
#anno_simple用于设置注释条
#顶部列注释
col_ha = pch.HeatmapAnnotation(label=pch.anno_label(df_col['Group'],#注释文件的列分组
merge=True,#有些group包含多个内容,相邻的合并
rotation=90,#文字旋转 90°,垂直显示
extend=True,#是否所有标签均一分布,这样不至于标签拥挤
colors=col_colors_dict,#注释分组颜色,标签颜色设置与分组一致,也可以直接设置为一种颜色
adjust_color=True,#自动调整文字颜色对比度(让字不被背景色淹没)
luminance=2,#背景色亮度
relpos=(0.5,0),#指示标签起点终点位置,x=0.5为注释条居中位置,y=0为底部对齐
fontsize=10),#注释文字大小
Group=pch.anno_simple(df_col['Group'],#注释文件的列分组
colors=col_colors_dict), #注释分组颜色
legend_kws={'fontsize':4},#legend设置
label_kws=dict(visible=False),#不展示注释标签标题,也就是分组标题
verbose=1,#打印运行信息
axis=1)#注释方向,因为行列注释都是使用HeatmapAnnotation,所以用来区分,1表示列注释,0表示行注释
#关于行的注释函数参数与列是一样的
left_ha = pch.HeatmapAnnotation(
label=pch.anno_label(df_row['Group'],merge=True,extend=True,
colors=col_colors_dict,adjust_color=True,luminance=0.75,
relpos=(1,0.5)),
Group=pch.anno_simple(df_row['Group'],legend=True,
colors=col_colors_dict),
verbose=1,axis=0,plot_legend=False,
label_kws=dict(visible=False))#不展示注释标签标题,也就是分组标题#右侧注释,展示部分行名,因为行名有很多,选择关键的进行展示
#这里我们随机挑战部分展示,实际情况可以展示关键信息或者感兴趣的
#随机挑选50个用于展示
import random
lable_genes= random.sample(data.index.to_list(), 50)
label_rows = data.apply(lambda x:x.name if x.name in lable_genes else None,axis=1)
#设置需要标注的name颜色与分组一致便于识别
#这里是识别需要标注的label属于哪个分组,然后提取其对应分组的颜色后形成字典
label_color_dict = {
labels: col_colors_dict.get(df_row.loc[labels, 'Group'], None)
for labels in lable_genes
if labels in df_row.index
}
#default_color = "#CCCCCC"
#gene_color_dict = {
# gene: color_dict.get(df.loc[gene, 'group'], default_color)
# if gene in df.index else default_color
# for gene in gene_list
#}
row_ha_right = pch.HeatmapAnnotation(
selected=pch.anno_label(label_rows, colors=label_color_dict,relpos=(0,0.5),merge=True,extend=True),#关于标签设置
orientation='right',#注释文字位置取向
axis=0,
verbose=1)#plot 热图
plt.figure(figsize=(6, 10))#图片尺寸
cm = pch.ClusterMapPlotter(data=data.loc[df_row.index.tolist(),df_col.index.tolist()],#data was sorted to have the same Group order for rows and columns
top_annotation=col_ha,
left_annotation=left_ha,
right_annotation=row_ha_right,
row_cluster=False,
col_cluster=False,
label='beta',
legend_gap=7,
cmap='parula',
rasterized=True,
xlabel="Cell Types",
legend_hpad=0,
xlabel_kws=dict(color='black', fontsize=14, labelpad=0)
)
#plt.savefig("Loyfer2023_heatmap.pdf",bbox_inches='tight') #图片保存为当前路径pdf文件
plt.show()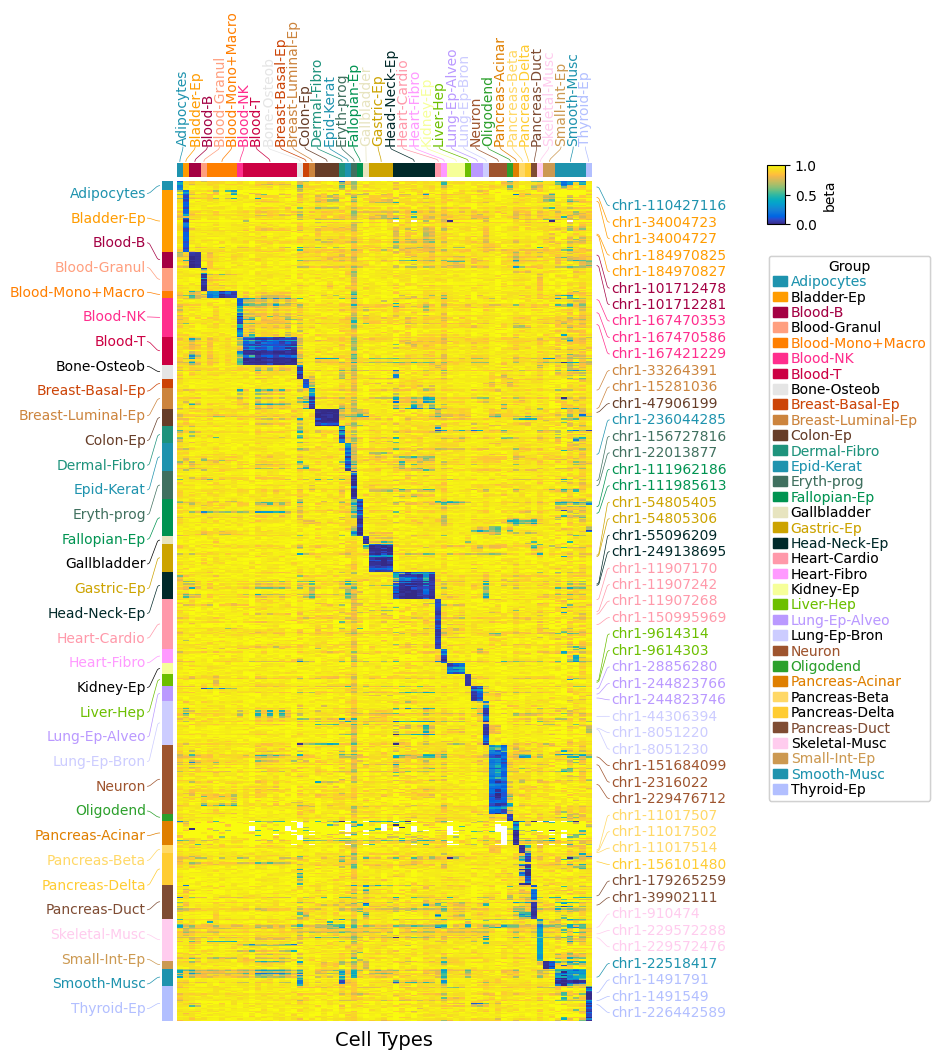
觉得我们分享有些用的,点个赞再走呗!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号