prefix LM 和 causal LM 区别是什么?

prefix LM 和 causal LM 区别是什么?

福大大架构师每日一题
发布于 2025-12-19 08:43:39
发布于 2025-12-19 08:43:39
prefix LM 和 causal LM 区别是什么?
答案:
Prefix LM(前缀语⾔模型)和Causal LM(因果语⾔模型)是两种不同类型的语⾔模型,它们的区别在于⽣成⽂本的⽅式和训练⽬标。
1.Prefix LM:前缀语⾔模型是⼀种⽣成模型,它在⽣成每个词时都可以考虑之前的上下⽂信息。在⽣成时,前缀语⾔模型会根据给定的前缀(即部分⽂本序列)预测下⼀个可能的词。这种模型可以⽤于⽂本⽣成、机器翻译等任务。
2.Causal LM:因果语⾔模型是⼀种⾃回归模型,它只能根据之前的⽂本⽣成后续的⽂本,⽽不能根据后续的⽂本⽣成之前的⽂本。在训练时,因果语⾔模型的⽬标是预测下⼀个词的概率,给定之前的所有词作为上下⽂。这种模型可以⽤于⽂本⽣成、语⾔建模等任务。
总结来说,前缀语⾔模型可以根据给定的前缀⽣成后续的⽂本,⽽因果语⾔模型只能根据之前的⽂本⽣成后续的⽂本。它们的训练⽬标和⽣成⽅式略有不同,适⽤于不同的任务和应⽤场景。
chatgpt:
好的,我们来仔细讲一下 Prefix LM 和 Causal LM 的区别。
1. Causal LM(因果语言模型)
核心思想:模型只能看到过去的 token,不能看到未来,用来做自回归(auto-regressive)预测。
- • 训练方式:给定一个序列 (x_1, x_2, ..., x_T),训练模型去预测:[ P(x_1, x_2, ..., x_T) = \prod_{t=1}^{T} P(x_t \mid x_{<t}) ]
- • 注意力掩码(Attention Mask):使用 全下三角掩码,禁止模型在预测 token (x_t) 时看到未来的 token。
- • 用途:
- • 生成任务(GPT 系列、LLaMA、Mistral)
- • 聊天、续写、故事生成
- • 典型示例:
- • GPT-2 / GPT-3 / LLaMA
- • 每次只根据已有文本往后生成
2. Prefix LM(前缀语言模型)
核心思想:在一个前缀部分(prefix)可以同时看到全部信息,但在预测后续 token 时依然是自回归的。
- • 训练方式:
- • 输入序列分为两部分:
- • 前缀部分(已知上下文,可以使用全注意力 mask)
- • 生成部分(只能看到自己之前生成的 token)
- • 可以理解为 "prefix 是已知条件,后面是要生成的内容"。
- • 输入序列分为两部分:
- • 注意力掩码:
- • 前缀部分:允许看到前缀中所有 token(全连接)。
- • 生成部分:只能看到前缀 + 自己之前的 token(因果掩码)。
- • 用途:
- • 融合已知输入作为条件进行生成(条件语言模型)
- • 更适合 NLP 中的 seq2seq 场景(如编码输入后生成输出)
- • 典型示例:
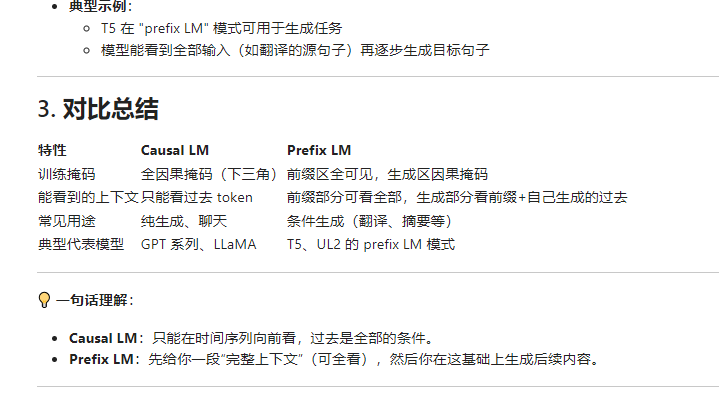
- • T5 在 "prefix LM" 模式可用于生成任务
- • 模型能看到全部输入(如翻译的源句子)再逐步生成目标句子
3. 对比总结
特性 | Causal LM | Prefix LM |
|---|---|---|
训练掩码 | 全因果掩码(下三角) | 前缀区全可见,生成区因果掩码 |
能看到的上下文 | 只能看过去 token | 前缀部分可看全部,生成部分看前缀+自己生成的过去 |
常见用途 | 纯生成、聊天 | 条件生成(翻译、摘要等) |
典型代表模型 | GPT 系列、LLaMA | T5、UL2 的 prefix LM 模式 |
💡 一句话理解:
- • Causal LM:只能在时间序列向前看,过去是全部的条件。
- • Prefix LM:先给你一段“完整上下文”(可全看),然后你在这基础上生成后续内容。

deepseek:
好的,这是一个非常核心的自然语言处理概念。我们来详细解释一下 Prefix LM(前缀语言模型)和 Causal LM(因果语言模型,通常指标准的自回归语言模型)的区别。
核心区别一句话概括:
- • Causal LM:在预测下一个词时,只能看到它之前的词。(严格单向)
- • Prefix LM:在预测下一个词时,对于输入序列的前缀部分,可以双向地看;只有在预测后缀部分的词时,才像 Causal LM 一样单向进行。
下面我们通过一个详细的对比表格和解释来深入理解。
对比表格
特性 | Causal LM (因果语言模型) | Prefix LM (前缀语言模型) |
|---|---|---|
常用名称 | 自回归语言模型、GPT 风格模型、Decoder-only 模型 | 编码器-解码器模型(部分)、 UniLM |
注意力机制 | 严格单向的掩码。每个 token 只能关注它之前的所有 token。 | 两部分掩码。前缀部分使用双向注意力,后缀部分使用单向注意力。 |
工作流程 | 1. 给定 "A B C"2. 预测下一个词 "D"3. 输入变为 "A B C D"4. 预测下一个词 "E" | 1. 给定一个前缀 "A B C"2. 模型双向编码这个前缀3. 开始自回归地生成后缀 "D E F"4. 生成 "D" 时,可以充分看到整个前缀 "A B C" |
信息流 | 严格从左到右,像一串多米诺骨牌。 | 前缀内部信息自由流动,从前缀到后缀的信息流动也是双向的(在生成前就已编码)。 |
典型代表 | GPT 系列 (GPT-2, GPT-3, LLaMA, ChatGLM) | T5、BART、UniLM |
主要应用 | 文本生成(对话、创作、代码生成) | 文本摘要、问答、翻译(需要理解整个输入再输出的任务) |
详细解释与示意图
1. Causal LM (因果语言模型)
这种模型是当前大语言模型(如 GPT、LLaMA)的主流架构。它的核心思想是:在预测序列中的下一个词时,模型只能依赖于该词之前出现的所有词(即“因”),而不能看到未来的词(即“果”)。
工作原理:
- • 通过一个因果注意力掩码实现。这个掩码是一个下三角矩阵(包括对角线),确保第
i个位置的 token 只能与位置1到i的 token 进行计算。 - • 生成过程是严格自回归的:一个一个地生成 token,每个新生成的 token 都会作为下一次预测的上下文的一部分。
示意图: 预测序列 <S> A B C D
时间步: 1 2 3 4
输入: <S> A B C
预测: A B C D
注意力: [] [A] [A,B] [A,B,C]在预测 D 时,模型只能看到 <S>, A, B, C。
优点:
- • 非常适合开放式文本生成,逻辑连贯。
- • 训练和推理过程简单统一。
缺点:
- • 在理解整个输入的任务(如摘要、翻译)上,效率相对较低,因为它无法对输入进行全局编码。
2. Prefix LM (前缀语言模型)
Prefix LM 可以看作是 Causal LM 和 Encoder-Decoder 模型的混合体。它将输入序列分为两部分:
- 1. Prefix(前缀):这部分是给定的、已知的上下文。模型在处理这部分时,可以使用双向注意力,让所有前缀 token 之间充分交互。
- 2. Suffix(后缀):这部分是需要模型生成的内容。在生成这部分时,模型像 Causal LM 一样,只能关注所有前缀 token 以及已经生成的后缀 token。
工作原理:
- • 通过一个特殊的前缀注意力掩码实现。这个掩码允许前缀区域的所有 token 相互关注,但对后缀区域,依然是单向的因果掩码。
示意图: 给定前缀 "A B",生成后缀 "C D"
Prefix: A B
/ \ / \ <-- 双向注意力
Suffix: C D
\ \ <-- 单向注意力(只能看前面所有Token)在生成后缀的第一个词 C 时,模型已经对前缀 A 和 B 进行了双向编码,因此它对输入的理解更全面、更深刻。
优点:
- • 在需要深度理解输入的任务上表现更好,因为它能对输入(前缀)进行充分的双向编码。
- • 比传统的 Encoder-Decoder 模型(两者完全分离)在结构和训练上可能更简洁。
缺点:
- • 生成速度可能略慢于纯 Causal LM,因为需要先对前缀进行复杂的双向计算。
- • 在非常纯粹的生成任务上,优势不明显。
一个生动的例子
假设任务是根据问题生成答案。
- • Causal LM 的处理方式(如 GPT):
- • 输入:
"中国的首都是哪里?答案是:" - • 模型从左到右逐个 token 处理这个序列,当处理到
":"时,它基于整个之前的上下文来生成"北京"。它无法在开始时就让"首都"和"中国"直接交互来更好地理解问题。
- • 输入:
- • Prefix LM 的处理方式(如 T5):
- • 输入:
"中国的首都是哪里?"(作为前缀) - • 模型首先双向地理解整个问题
"中国的首都是哪里?",充分捕捉到"中国"和"首都"之间的关系。 - • 然后,它开始自回归地生成答案:
"北京"。在生成"北"时,它已经对整个问题有了完整的理解。
- • 输入:
总结与现状
- • Causal LM 是当前生成式大语言模型的基石,因其架构简单、生成能力强大而成为主流。
- • Prefix LM 更像是理解-生成任务的专家,在摘要、翻译等特定领域表现出色。T5 模型是其中的杰出代表,它将所有 NLP 任务都重构为 "前缀 + 后缀" 的文本到文本形式。
值得注意的是,随着模型的发展,界限有时会模糊。例如,一些模型(如 PALM)在架构上是标准的 Causal LM,但通过指令微调,使其在行为上能够像 Prefix LM 一样工作(即用户输入作为“前缀”,模型回复作为“后缀”)。但就其底层注意力机制而言,它仍然是 Causal LM。真正的 Prefix LM 在注意力机制层面就存在根本的不同。
通义千问:
Prefix LM(前缀语言模型)和 Causal LM(因果语言模型)都是用于生成文本的自回归模型,但它们在处理输入和生成输出的方式上存在关键区别,主要体现在**注意力机制的可见性(attention mask)**上。
简单来说,它们的核心区别在于:
- • Causal LM: 严格遵循“未来信息不可见”的原则,任何位置只能看到它之前的 token。
- • Prefix LM: 允许在“前缀”部分(通常是输入/上下文)进行双向信息流动,而在“生成”部分则采用单向(因果)注意力。
下面我们详细解释:
1. Causal LM (因果语言模型)
• 工作原理:
- • 这是最经典的自回归语言模型,如 GPT 系列。
- • 它遵循严格的从左到右的生成方式。
- • 在计算每个位置的 token 的表示时,模型只能“看到”该位置之前的所有 token,而不能看到当前或未来的 token。这通过因果注意力掩码 (causal attention mask) 实现。
• 应用场景:
- • 纯文本生成(如写故事、续写)。
- • 在传统设置中,所有输入都被视为需要被“预测”的一部分,因此无法有效利用长上下文。
• 示意图:
输入: [A] [B] [C] [D] [E] [F]
注意力: A -> (看不到)
B -> A
C -> A, B
D -> A, B, C
E -> A, B, C, D
F -> A, B, C, D, E每个位置只能关注它左边的 token。
2. Prefix LM (前缀语言模型)
• 工作原理:
- • 将输入序列明确地分为两部分:
- 1. 前缀 (Prefix):这部分是上下文或条件信息(例如,指令、文档、对话历史)。
- 2. 生成部分 (Suffix/Autoregressive part):这部分是需要模型生成的文本。
- • 在注意力机制上:
- • 前缀部分内部:允许双向注意力。这意味着前缀中的每个 token 都可以看到该部分内的所有其他 token。这有助于模型更好地理解输入的上下文。
- • 生成部分:采用因果注意力,即每个生成的 token 只能看到它之前的 token(包括前缀部分的所有 token 和生成部分中它之前的 token)。
- • 前缀到生成部分:允许前缀中的所有 token 被生成部分的所有 token 看到。
• 应用场景:
- • 条件文本生成:这是其主要优势。例如:
- • 根据一篇长文档进行问答或摘要。
- • 遵循复杂的指令生成文本(Instruction Tuning)。
- • 对话系统,其中对话历史作为前缀,回复作为生成部分。
- • 它结合了 BERT(双向编码)和 GPT(自回归解码)的优点。
• 示意图:
序列: [Prefix: A] [B] [C] | [Suffix: D] [E] [F]
注意力规则:
- 前缀内部 (A, B, C): 双向可见 (A<->B<->C)
- 生成部分 (D, E, F): 因果可见 (D<-A,B,C; E<-A,B,C,D; F<-A,B,C,D,E)
- 前缀 -> 生成: 全部可见 (A,B,C 可以被 D,E,F 看到)
- 生成 -> 前缀: 不可见 (D,E,F 不能被 A,B,C 看到)关键区别总结
特性 | Causal LM | Prefix LM |
|---|---|---|
注意力模式 | 全局因果(单向) | 前缀内双向,生成部分因果 |
输入/上下文处理 | 作为序列的一部分,以因果方式处理 | 作为“前缀”,允许双向理解 |
信息流 | 严格从左到右 | 前缀内自由流动,生成时从左到右 |
典型应用 | 开放域文本生成 | 条件文本生成(问答、摘要、指令遵循) |
效率/效果 | 简单,但上下文理解受限 | 更好地利用上下文信息,适合任务导向生成 |
代表模型/场景 | GPT-2, GPT-3 (预训练) | UL2, T5 (在特定任务中), 大多数现代指令微调模型 |
为什么 Prefix LM 在指令微调中更有效?
在指令微调(Instruction Tuning)中,模型需要根据指令(前缀)来生成响应(生成部分)。使用 Prefix LM 允许模型在处理指令时像 BERT 一样进行双向理解,从而更准确地把握指令的含义,然后再像 GPT 一样自回归地生成响应。这比让模型以因果方式一个字一个字地“猜测”指令的含义要高效和准确得多。
总结: Causal LM 是纯粹的“预测下一个词”模型,而 Prefix LM 是一种更灵活的架构,它将输入作为可充分理解的“条件”,然后在此条件下进行自回归生成,因此在处理条件生成任务时通常表现更优。
豆包:
Prefix LM(前缀语言模型)和 Causal LM(因果语言模型)是自然语言处理中两种核心的语言模型架构,其差异主要体现在模型结构、训练目标和应用场景上。以下是具体分析:
1. 模型结构与注意力机制
- • Causal LM(因果语言模型) 采用 Decoder-only 架构(如 GPT 系列),严格遵循 单向自回归 模式。其注意力掩码为下三角矩阵,确保每个位置只能看到左侧已生成的内容,无法“窥视”未来的词。例如,生成句子“A B C D”时,预测“D”只能依赖“A B C”,而无法知晓后续可能的内容。这种设计使得模型在生成时逐词推进,符合人类阅读和写作的顺序,但也限制了其对全局上下文的理解能力。
- • Prefix LM(前缀语言模型)
是 Encoder-Decoder 架构的轻量变体(如 GLM、UniLM),通过注意力掩码将输入分为两部分:
- • 前缀部分:允许双向注意力,所有词相互可见,类似 Encoder 的功能,用于深度理解上下文。
- • 生成部分:采用单向自回归,仅能看到前缀和已生成的内容,类似 Decoder 的功能。 例如,输入“我昨天去了___,那里风景优美”时,前缀“我昨天去了___”可以双向编码,结合后续的“那里风景优美”推断出缺失的词(如“公园”),而生成时仍需逐词预测。
2. 训练目标与任务适配
- • Causal LM 训练目标是 最大化序列的联合概率,即 ( P(w_1, w_2, \ldots, w_n) = \prod_{t=1}^n P(w_t | w_{<t}) )。这种目标天然适合 开放式生成任务,如故事续写、对话生成等,因为它能逐步构建连贯的上下文。但由于只能依赖历史信息,在需要全局语义理解的任务(如摘要、翻译)中表现较弱。
- • Prefix LM 训练目标是 最大化条件概率,即 ( P(\text{生成部分} | \text{前缀部分}) )。前缀的双向编码使其能更好地捕捉全局语义,适用于 多任务学习 和 指令微调场景。例如,在摘要任务中,前缀可以是原文,生成部分为摘要;在翻译任务中,前缀是源语言句子,生成部分为目标语言。这种设计让模型既能“理解题目”,又能“续写文章”,兼具 NLU(自然语言理解)和 NLG(自然语言生成)能力。
3. 应用场景与优缺点
- • Causal LM 的典型应用
- • 长文本生成:如小说创作、代码生成,因其自回归特性可逐步构建长序列。
- • 对话系统:逐轮生成回复,符合对话的时序性。 优势:架构简单、训练高效,适合预训练大规模模型(如 GPT-4)。 局限:缺乏双向上下文理解,难以直接处理需要全局信息的任务(如阅读理解)。
- • Prefix LM 的典型应用
- • 多模态任务:结合图像或结构化数据时,前缀可编码额外信息,生成符合条件的文本。
- • 复杂指令生成:如“根据用户问题生成答案”,前缀作为指令,生成部分需严格遵循要求。 优势:灵活兼容多种任务,参数共享机制(如共享 Transformer 结构)提升效率。 局限:注意力掩码设计复杂,训练难度高于 Causal LM,且长文本生成时可能因前缀过长导致计算瓶颈。
4. 核心差异总结
维度 | Causal LM | Prefix LM |
|---|---|---|
架构 | Decoder-only,单向自回归 | Encoder-Decoder 变体,前缀双向 + 生成单向 |
注意力掩码 | 下三角矩阵(仅左侧可见) | 前缀全连接 + 生成下三角混合矩阵 |
训练目标 | 最大化联合概率 ( P(w_1, ..., w_n) ) | 最大化条件概率 ( P(\text{生成} |
擅长场景 | 长文本生成、对话 | 多任务学习、指令驱动生成 |
典型模型 | GPT、LLaMA、Mistral | GLM、UniLM、Prefix-Tuning |
5. 实际选择建议
- • 选 Causal LM:若任务需 高效生成连贯长文本(如小说、代码),或资源有限需快速训练,Causal LM 是更优解。
- • 选 Prefix LM:若需 兼顾理解与生成(如摘要、翻译),或进行多任务微调,Prefix LM 的灵活性更具优势。例如,GLM 等模型通过前缀编码用户问题,生成精准回答,在指令遵循任务中表现突出。
6. 工程实现细节
- • 参数共享:Prefix LM 常通过共享 Transformer 结构实现 Encoder-Decoder 功能,减少参数量(如 GLM)。
- • 掩码设计:Causal LM 的掩码由
torch.tril生成,而 Prefix LM 需手动分割区域,前缀部分为全 1 矩阵,生成部分为下三角。 - • 推理效率:Causal LM 因结构简单,推理速度通常更快;Prefix LM 需处理前缀的双向计算,延迟略高。
总结
Causal LM 是“纯粹的写作选手”,专注于单向生成,适合开放式创作;Prefix LM 则是“全能型选手”,通过前缀理解全局,再精准生成,更适合复杂任务。两者的差异本质上反映了“生成优先”与“理解-生成平衡”的设计哲学,实际应用中需根据具体需求选择。
文心一言:
Prefix LM 与 Causal LM 的核心区别解析
1. 定义与核心机制
- • Causal LM(因果语言模型)
- • 自回归生成:基于已生成的文本序列(仅左侧/历史tokens)预测下一个token,严格遵循“因果性”原则(不能使用未来信息)。
- • 典型模型:GPT系列、LLaMA等Decoder-only架构模型,通过自回归方式从左到右生成文本。
- • 训练目标:最大化序列中每个token的条件概率(如
P(x_i | x_1, ..., x_{i-1})),训练时采用“预测下一个词”的自回归任务。 - • 上下文限制:生成过程中仅依赖已生成的tokens,无法直接利用输入的全局上下文。
- • Prefix LM(前缀语言模型)
- • 双向+自回归混合:允许模型在生成时同时利用“前缀”(输入序列的固定部分,如问题/上下文)和已生成的tokens。
- • 典型模型:T5、UniLM、GLM(清华),通过共享的Transformer架构和Attention Mask机制实现。
- • 训练目标:结合前缀部分(如输入文本)与生成部分(如答案),通过“前缀-生成”联合任务训练(如T5的文本到文本转换)。
- • 上下文利用:解码器可访问前缀部分的全局信息(如输入序列的所有tokens),同时保持自回归生成特性。
2. 关键差异对比
维度 | Causal LM | Prefix LM |
|---|---|---|
上下文范围 | 仅已生成的tokens(历史信息) | 前缀部分(全局输入)+ 已生成tokens |
模型结构 | Decoder-only(如GPT) | Encoder-Decoder混合(共享Transformer) |
Attention机制 | 严格单向(仅左侧可见) | 前缀部分双向可见,生成部分单向可见 |
训练任务 | 纯自回归预测(如“下一个词预测”) | 前缀-生成联合任务(如T5的“文本填空”) |
应用场景 | 文本生成、对话系统、续写任务 | 问答、摘要、条件生成、多任务学习 |
优势 | 生成连贯性强,适合无条件生成 | 理解输入全局上下文,适合条件生成任务 |
3. 典型案例与场景
- • Causal LM 应用:
- • GPT-3生成故事、对话回复时,仅依赖前文生成后续内容。
- • 优点:生成过程直接高效,适合开放域生成任务。
- • 局限:对输入的全局信息(如问题、上下文)理解较弱。
- • Prefix LM 应用:
- • T5模型在问答任务中,将问题作为前缀,生成答案时同时参考问题和已生成内容。
- • 优点:在情境学习(In-Context Learning)中表现更优,能利用前缀中的示例或上下文信息。
- • 局限:模型结构更复杂,训练和推理成本可能更高。
4. 理论差异与选择建议
- • 因果性 vs 上下文理解:Causal LM严格遵循时间因果性,适合生成连贯文本;Prefix LM通过前缀机制增强对输入上下文的理解,适合需要全局信息的任务。
- • 效率与灵活性:Causal LM结构简单,推理速度快;Prefix LM通过共享Transformer和Attention Mask实现灵活上下文利用,但可能增加计算开销。
- • 选择依据:
- • 若任务以生成连贯文本为主(如故事续写),Causal LM更合适;
- • 若任务需结合输入上下文(如问答、摘要),Prefix LM能提供更准确的生成结果。
总结:Prefix LM与Causal LM的核心区别在于上下文利用方式和模型结构设计。Causal LM以自回归生成见长,而Prefix LM通过前缀机制融合全局上下文,适用于需要深度理解输入的任务。两者在NLP任务中互补,选择需根据具体场景需求权衡。
讯飞星火:
Prefix LM(前缀语言模型)和Causal LM(因果语言模型)是自然语言处理中两种重要的语言模型架构,它们在多个方面存在显著差异。以下是详细介绍:
一、核心定义与原理
Causal LM 是一种自回归模型,生成文本时只能基于前面的词预测下一个词,无法利用未来的信息。 其目标是最大化序列的似然概率,即给定前面的词,预测下一个词。
Prefix LM 在训练和生成时,允许模型同时利用前缀信息和后续信息。 给定前缀,模型预测后续的词,前缀部分可以双向编码,后续部分只能单向解码。
二、注意力机制与信息利用范围
Causal LM 单向性:采用“下三角注意力掩码”,对于第k个token,仅允许其关注1k-1位置的token,完全屏蔽k+1n位置的token,确保单向依赖。 局限性:由于严格单向,无法利用上下文全局信息,在需要理解语义的任务中表现较弱。
Prefix LM 混合掩码:前缀内部允许双向注意力,预测段内部则采用下三角掩码,且预测段可访问前缀所有信息。 优势:既能通过前缀双向编码增强语义理解,又能保持生成阶段的自回归特性。
三、训练目标与生成方式
Causal LM 训练目标:最小化交叉熵损失,逐词预测。 生成方式:从左到右逐步生成,依赖历史token。
Prefix LM 训练目标:分为两部分——前缀部分双向建模,预测段单向生成。 生成方式:先对前缀进行双向编码,再基于前缀生成后续内容。
四、典型应用场景
Causal LM 适用场景:开放式文本生成、对话系统、代码补全等纯生成任务。 代表模型:GPT系列、LLaMA、Mistral等。
Prefix LM 适用场景:需结合上下文理解的任务,如机器翻译、文本摘要、填空任务。 代表模型:T5、BART、PEGASUS等。
总的来说,选择哪种模型取决于具体任务需求:若仅需生成连贯文本,Causal LM足够高效;若需兼顾理解与生成,Prefix LM更具优势。
360智脑:
Prefix LM 和 Causal LM 是两种不同的语言模型,它们在处理和预测序列中的下一个词时有不同的方法。以下是它们的主要区别:
- 1. 定义:
- • Prefix LM(前缀语言模型):在给定一个文本前缀的情况下,模型能够基于这个前缀生成接下来的文本内容。它可以在生成文本时有条件地利用部分未来信息(即已知的后续文本片段)。
- • Causal LM(因果语言模型):是一种自回归模型,它在生成文本时只能依赖于之前已经生成的文本,而不能利用未来信息。每个新词都是根据之前的词序列来预测的。
- 2. 注意力机制:
- • Prefix LM:使用一种特殊的注意力掩码(Attention Mask),使得模型在生成每个词时可以访问整个输入序列(包括前缀和之前生成的输出),从而更好地理解上下文。
- • Causal LM:使用一种掩码(masking),确保在生成每个词时,只能考虑它之前(包括当前)的词,而不能看到未来的词。
- 3. 应用场景:
- • Prefix LM:适合于需要基于已有文本继续生成文本的任务,例如文本补全、续写故事等。它能够利用完整的上下文信息来生成文本,有助于生成更加准确和连贯的内容。
- • Causal LM:广泛用于需要生成新文本的任务,例如文本摘要、聊天机器人、语言生成等。它逐个生成词,每个新词都是基于之前所有词的上下文。
- 4. 模型结构:
- • Prefix LM:通常是Encoder-Decoder模型的变体,Encoder和Decoder共享同一个Transformer结构。在Transformer内部通过特定的Attention Mask机制实现功能。
- • Causal LM:只涉及Encoder-Decoder中的Decoder部分,采用自回归(AutoRegressive)的模式,通过掩码来保证生成当前token时只能依据之前的token信息。
- 5. 代表模型:
- • Prefix LM:T5、UniLM、GLM等。
- • Causal LM:GPT系列模型、LLaMa等。
- 6. 训练数据处理方式:
- • Prefix LM:在训练中可能会进行特殊的优化以更好地处理输入中的前缀部分,也许会将前缀部分同等对待为正常的输入部分,并且为了让模型学会利用前缀和后续部分的联系而调整训练方式。
- • Causal LM:训练数据处理可能更侧重于让模型掌握根据历史数据预测下一个token的能力,不涉及到对前置文本的特殊处理机制。
总结来说,Prefix LM 和 Causal LM 的核心区别在于它们如何使用上下文信息来进行预测。Prefix LM 可以利用更全面的上下文信息,而 Causal LM 则只能利用已经生成的文本作为上下文。选择哪种模型取决于具体的应用需求和上下文环境。
智谱清言:
Prefix LM(前缀语言模型)和 Causal LM(因果语言模型)的区别如下:
1. 基本定义
- • Prefix LM(前缀语言模型): 在生成每个词时,可以利用给定的前缀(即部分文本序列)作为上下文,前缀部分的所有 token 之间可以相互关注(即双向可见),后续生成部分采用自回归方式,即只能看到已经生成的 token,不能看到未来的 token。它通过 Attention Mask 机制,在同一个 Transformer 结构中实现 Encoder-Decoder 的功能。
- • Causal LM(因果语言模型): 严格自回归,生成每个 token 时只能利用该 token 之前的所有历史信息,不能看到后续 token。模型整体只包含 Decoder 部分,不包含 Encoder,所有 token 之间都是单向(从左到右)依赖。
2. 结构差异
- • Prefix LM:
- • Encoder-Decoder 变体,Encoder 和 Decoder 共享同一个 Transformer 结构,通过 Attention Mask 区分不同区域。
- • Encoder 部分(前缀)采用自编码(AE)模式,Decoder 部分采用自回归(AR)模式。
- • 代表模型:UniLM、T5、GLM(清华)等。
- • Causal LM:
- • 只有 Decoder 结构,全部为自回归(AR)模式。
- • Attention Mask 确保每个 token 只能关注左侧(历史)的 token。
- • 代表模型:GPT 系列、LLaMA 等。
3. 信息流动与上下文利用
- • Prefix LM:
- • 前缀部分(如输入的上下文)内部可以双向交互,生成部分可看到前缀全部内容。
- • 适合需要丰富上下文理解的生成任务,如条件文本生成、摘要、翻译等。
- • Causal LM:
- • 信息流动严格单向,只能利用历史信息。
- • 适合纯生成任务,如续写、对话等。
4. 典型应用场景
- • Prefix LM:
- • 上下文学习(In-Context Learning)、条件生成、需要双向理解的生成任务。
- • 研究表明,Prefix LM 在上下文学习中表现优于 Causal LM。
- • Causal LM:
- • 自由文本生成、对话系统、开放式创作等。
5. 总结
- • Prefix LM: 前缀部分双向可见,生成部分自回归,适合需要充分利用上下文的生成任务。
- • Causal LM: 严格自回归,只利用历史信息,适合纯生成任务。
6. 参考出处
- • 详细原理、图示和模型举例可参考博客园《LLM面面观之Prefix LM vs Causal LM》。
- • 相关理论分析与实验可参考论文:Google T5、微软 UniLM 等。
天工:
“prefix LM”和“causal LM”的区别主要在模型处理上下文和生成方式上:
- 1. Causal LM(因果语言模型):
- • 经典的自回归语言模型,逐词生成,每次只看当前词之前的所有词(左侧上下文)。
- • 输入是一个序列,从左到右预测下一个词,不能访问未来词。
- • 典型例子:GPT系列。
- • 适合纯文本生成任务,比如写文章、对话生成。
- 2. Prefix LM(前缀语言模型):
- • 模型在生成时,除了因果左侧上下文外,还能同时利用输入的“前缀”(可能来自任意上下文,包括编码器传来的非严格顺序信息)。
- • 通常做法是先用一个编码器处理前缀,再让解码器基于这个编码器的输出和生成的历史令牌生成新词。
- • 这类模型设计上比纯因果模型更灵活,能结合“条件信息”进行生成。
- • 应用场景如有提示的文本生成、条件生成任务。
简单总结:
- • Causal LM只能根据左侧文本生成下一个词。
- • Prefix LM能用额外的前缀信息(编码的上下文)辅助生成,不限于简单左侧上下文。
kimi:
Prefix LM(前缀语言模型)和 Causal LM(因果语言模型)最核心的区别在于注意力机制(attention mask)的设计不同,这直接影响了它们在训练和生成阶段如何利用上下文信息:
✅ 一句话总结:
- • Causal LM 只能从左到右看前文,不能看未来信息;
- • Prefix LM 对前缀部分可以双向编码,只有生成部分是从左到右。
🔍 详细区别:
特性 | Causal LM | Prefix LM |
|---|---|---|
注意力方向 | 单向(只能看到前面的词) | 前缀双向,生成部分单向 |
训练方式 | 自回归:逐词预测下一个 | 前缀双向编码,后续自回归生成 |
上下文利用 | 只能利用左侧上下文 | 前缀部分可利用全部上下文 |
适用任务 | 文本续写、对话生成等 | 条件生成、文本补全、翻译等 |
代表模型 | GPT 系列、LLaMA、Claude 等 | T5、UniLM、GLM、BART 等 |
📌 举个例子:
句子:“The cat sat on the ___”
- • Causal LM:逐词生成,只能看到前面的词,无法“偷看”后面的内容。
- • Prefix LM:将 “The cat sat on the” 作为前缀,可以双向理解这段前缀,然后生成 “mat”。
✅ 总结:
- • Causal LM 更适合自由生成任务;
- • Prefix LM 更适合需要理解上下文的条件生成任务;
- • 本质区别是 attention mask 的设计不同。
腾讯元宝:
Prefix LM(前缀语言模型)和Causal LM(因果语言模型)是两种不同的语言模型架构,主要区别在于注意力掩码的设计:
Causal LM(因果语言模型)
特点:
- • 严格单向注意力:每个位置只能关注到它之前的位置(包括自身)
- • 自回归生成:在生成时,只能基于已生成的内容预测下一个token
- • 训练目标:最大化序列的似然概率,即 P(x₁, x₂, ..., xₙ)
注意力掩码:
[1, 0, 0, 0]
[1, 1, 0, 0]
[1, 1, 1, 0]
[1, 1, 1, 1]Prefix LM(前缀语言模型)
特点:
- • 双向注意力:前缀部分(prompt)可以双向关注
- • 单向生成:生成部分只能单向关注
- • 训练目标:给定前缀,最大化后续序列的条件概率
注意力掩码(前缀长度为2):
[1, 1, 0, 0] # 前缀位置1
[1, 1, 0, 0] # 前缀位置2
[1, 1, 1, 0] # 生成位置1
[1, 1, 1, 1] # 生成位置2主要区别
特征 | Causal LM | Prefix LM |
|---|---|---|
注意力机制 | 严格单向 | 前缀双向,生成单向 |
训练效率 | 相对较低 | 更高(前缀可并行) |
生成质量 | 稳定但可能保守 | 可能更准确(利用前缀信息) |
应用场景 | 纯生成任务 | 条件生成、对话、摘要等 |
代表模型 | GPT系列 | T5、UniLM等 |
实际应用
Causal LM 更适合:
- • 创意写作
- • 代码生成
- • 故事续写
Prefix LM 更适合:
- • 对话系统
- • 文本摘要
- • 机器翻译
- • 问答系统
现代大语言模型(如GPT-3、PaLM等)通常采用Causal LM架构,但在训练和推理时通过不同的提示工程来模拟Prefix LM的效果。
我们相信人工智能为普通人提供了一种“增强工具”,并致力于分享全方位的AI知识。在这里,您可以找到最新的AI科普文章、工具评测、提升效率的秘籍以及行业洞察。 欢迎关注“福大大架构师每日一题”,发消息可获得面试资料,让AI助力您的未来发展。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号