《C++进阶之STL》【unordered_set/unordered_map 模拟实现】

《C++进阶之STL》【unordered_set/unordered_map 模拟实现】

序属秋秋秋
发布于 2025-12-18 16:13:07
发布于 2025-12-18 16:13:07
【unordered_set/unordered_map 模拟实现】目录
往期《C++初阶》回顾:《C++初阶》目录导航
往期《C++进阶》回顾:
/------------ 继承多态 ------------/
【普通类/模板类的继承 + 父类&子类的转换 + 继承的作用域 + 子类的默认成员函数】
【final + 继承与友元 + 继承与静态成员 + 继承模型 + 继承和组合】
【多态:概念 + 实现 + 拓展 + 原理】
/------------ STL ------------/
【二叉搜索树】
【AVL树】
【红黑树】
【set/map 使用介绍】
【set/map 模拟实现】
【哈希表】
【unordered_set/unordered_map 使用介绍】
前言:
hi~ 小伙伴们大家好呀! (っ◔◡◔)っ ♥ 最近的天气真是越来越有秋意了,不知道你们所在的城市有没有下雨呀?☔️🍂 鼠鼠这儿已经连着下了三四天雨啦,打开天气预报一看,未来几天不是阴沉沉的阴天 (´-ω-`),就是小雨淅淅沥沥飘个不停 (。•́︿•̀。),偶尔还会来一场大雨哗哗啦啦下个痛快 (ノω・、),气温也跟着一点点降了下来,大家可得记得及时添衣服哦~(。・ω・。)ノ♡
不过就算天气有些阴冷,学习的热情可不能减!🔥 今天我们要解锁的新内容是…… 哎?这位小伙伴怎么一下子就说出是 【unordered_set/unordered_map 模拟实现】 了!Σ(っ °Д °;)っ 这绝对是鼠鼠的铁杆忠实粉没跑了,必须给你点个大大的赞!(づ ̄ ³ ̄)づ👍✨ 说起来,这篇博客可是咱们 STL 系列的最后一篇啦,算得上是收尾的重磅内容。里面藏了不少实打实的干货,从底层原理到模拟实现的关键细节都给大家梳理清楚了,大家一定要慢慢看、细细品,可别错过这些精华哦!(๑•̀ㅂ•́)و✧
------------标准介绍------------
1. 标准库中的unordered_set/map是怎么实现的呢?
SGI - STL30 版本的源代码里,不存在
unordered_set和unordered_map这是因为 SGI - STL30 版本属于 C++11 之前的 STL 版本,而unordered_set和unordered_map这两个容器,是在 C++11 之后才更新加入标准的
- 不过,SGI - STL30 实现了哈希表相关功能,对应的容器名为
hash_set和hash_map,它们属于非标准容器(非标准指并非 C++ 标准规定必须实现的容器 ) - 其源代码可在
stl_hash_set/、stl_hash_map/、stl_hashtable.h这些文件中找到
下面截取 hash_set和 hash_map实现结构框架的核心部分,展示如下:
stl_hashtable.h
/*-------------------------- stl_hashtable.h --------------------------*/
// stl_hashtable.h
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
class hashtable
{
public:
typedef Key key_type;
typedef Value value_type;
typedef HashFcn hasher;
typedef EqualKey key_equal;
private:
hasher hash;
key_equal equals;
ExtractKey get_key;
typedef __hashtable_node<Value> node;
vector<node*, Alloc> buckets;
size_type num_elements;
public:
typedef __hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> iterator;
pair<iterator, bool> insert_unique(const value_type& obj);
const_iterator find(const key_type& key) const;
};
template <class Value>
struct __hashtable_node
{
__hashtable_node* next;
Value val;
};stl_hash_set
/*-------------------------- stl_hash_set --------------------------*/
// stl_hash_set
template <class Value, class HashFcn = hash<Value>,
class EqualKey = equal_to<Value>, class Alloc = alloc>
class hash_set
{
private:
typedef hashtable<Value, Value, HashFcn,
identity<Value>, EqualKey, Alloc> ht;
ht rep;
public:
typedef typename ht::key_type key_type;
typedef typename ht::value_type value_type;
typedef typename ht::hasher hasher;
typedef typename ht::key_equal key_equal;
typedef typename ht::const_iterator iterator;
typedef typename ht::const_iterator const_iterator;
hasher hash_funct() const { return rep.hash_funct(); }
key_equal key_eq() const { return rep.key_eq(); }
};stl_hash_map
/*-------------------------- stl_hash_map --------------------------*/
// stl_hash_map
template <class Key, class T, class HashFcn = hash<Key>,
class EqualKey = equal_to<Key>, class Alloc = alloc>
class hash_map
{
private:
typedef hashtable<pair<const Key, T>, Key, HashFcn,
select1st<pair<const Key, T> >, EqualKey, Alloc> ht;
ht rep;
public:
typedef typename ht::key_type key_type;
typedef T data_type;
typedef T mapped_type;
typedef typename ht::value_type value_type;
typedef typename ht::hasher hasher;
typedef typename ht::key_equal key_equal;
typedef typename ht::iterator iterator;
typedef typename ht::const_iterator const_iterator;
};从上面的源码中我们可以清晰的看出:在结构设计上,
hash_set和hash_map与set和map高度相似,它们复用同一个hashtable来实现关键结构,以此适配不同的存储与查找需求 。
- 对于hash_set:传递给
hashtable的是单纯的key - 对于hash_map:传递给
hashtable的则是pair<const key, value>这种键值对形式
------------代码实现------------
unordered_set/map容器的结构
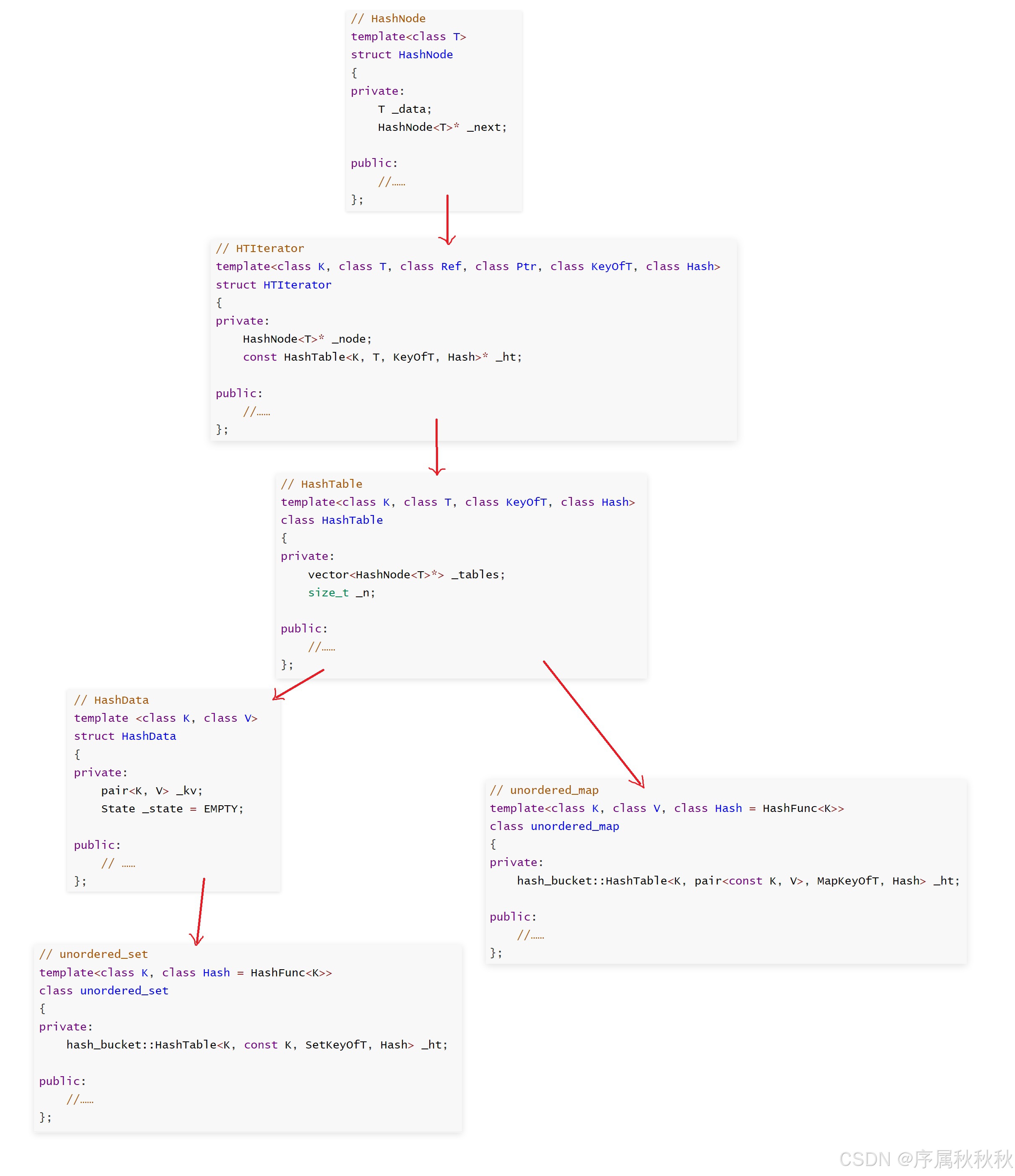
在这里插入图片描述
头文件:
HashTable.h
#pragma once
//包含需要使用的头文件
#include <iostream>
#include <vector>
using namespace std;
/*------------------任务:定义哈希表函数的“通用类模板”------------------*/
template <class K>
struct HashFunc
{
//1.重载()运算符 ---> 作用:将K类型转化为size_t类型,用于计算哈希值
size_t operator()(const K& key)
{
return (size_t)key; //注意:默认为直接转换,适用于int、long等整数类型
}
};
/*------------------任务:定义哈希函数的“模板特化”------------------*/
template <>
struct HashFunc<string>
{
//1.实现:“()运算符的重载” ---> 作用:将string类型的变量转化为哈希值
size_t operator()(const string& s)
{
//1.定义size_t类型变量记录string类型的变量计算的哈希值
size_t hash = 0;
//2.使用范围for循环遍历字符串并用BKDR算法计算其哈希值
for (auto it : s)
{
//2.1:先将字符的ASCII值累加到哈希值中
hash += it;
//2.2:再让哈希值乘以质数131(BKDR哈希算法认为:131可有效减少冲突)
hash *= 131;
}
//3.返回最终计算的哈希值
return hash;
}
};
/*------------------任务:实现“获取下一个 >=n 的质数的函数”---> “用于哈希表扩容”------------------*/
inline unsigned long _stl_next_prime(unsigned long n)
{
//1.指定素数表的大小
static const int _stl_num_primes = 28;
//2.定义素数表覆盖常见哈希表大小
static const unsigned long _stl_prime_list[_stl_num_primes] = //注意:这里的素数表的类型是unsigned long 类型
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
//3.使用二分查找找到第一个 >=n 的素数
//3.1:使用一个指针指向素数表中的“第一个素数”
const unsigned long* first = _stl_prime_list;
//3.1:使用一个指针指向素数表中的“最后一素数的下一位置”
const unsigned long* last = _stl_prime_list + _stl_num_primes;
//3.3:使用lower_bound()接口函数求出第一个 >=n 的素数
const unsigned long* pos = lower_bound(first, last, n);
//3.4:适合作为哈希表容量的质数
return pos == last ? *(last - 1) : *pos;
/*
* 说明遍历完质数表,所有预定义的质数都比 n 小
* 此时返回最大的质数 *(last - 1),因为 last 是数组末尾的下一个位置,last - 1 指向最后一个有效质数
*/
}
/*------------------任务:使用“链地址法”实现哈希表------------------*/
namespace hash_bucket
{
/*------------------任务:定义“哈希表节点的结构体模板”------------------*/
//template<class K, class V>
template<class T> //注意:为了封装unordered_set/unordered_map 容器这里的模板参数已经从<class K, class V> ---> <class T>
struct HashNode
{
/*------------------成员变量------------------*/
//1.存储的数据
//2.指向下一个节点的指针
//pair<K, V> _kv;
//HashNode<K, V>* _next;
T _data;
HashNode<T>* _next;
/*------------------成员函数------------------*/
//1.实现:哈希桶节点的“构造函数”
//HashNode(const pair<K, V>& kv)
HashNode(const T& data)
//:_kv(kv)
:_data(data)
, _next(nullptr)
{
}
};
//前置声明,因为 HTIterator 中要用到 HashTable
template<class K, class T, class KeyOfT, class Hash> //注意:类模板的前置声明的方法
class HashTable;
/*------------------任务:定义“哈希表的迭代器的结构体模板------------------*/
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
struct HTIterator
{
/*------------------成员变量------------------*/
//1.指向当前节点的指针
//2.指向哈希表的指针 ---> 用于遍历的桶
HashNode<T>* _node;
const HashTable<K, T, KeyOfT, Hash>* _ht; // 注意:迭代器这里需要使用到哈希表,所以在定义迭代器之前我们先进行了哈希表的前置声明
/*------------------类型别名------------------*/
//1.重命名“哈希表节点”的类型:HashNode<T> ---> Node
typedef HashNode<T> Node;
//2.重命名“哈希表的迭代器”的类型:HTIterator<K,T,Ref,Ptr,SetKeyOfT,Hash> ---> Self
typedef HTIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;
//3.重命名“哈希表”的类型:HashTable<K,T,KeOfT,Hash> ---> HT
typedef HashTable<K, T, KeyOfT, Hash> HT;
/*------------------成员函数------------------*/
//1.实现:“迭代器的构造函数”
HTIterator(Node* node, const HT* ht)
:_node(node)
, _ht(ht)
{
}
//2.实现:“*运算符的重载” ---> 返回数据的引用(本身)
Ref operator*()
{
return _node->_data;
}
//3.实现:“->运算符的重载”---> 返回数据的指针(地址)
Ptr operator->()
{
return &_node->_data;
}
//4.实现:“!=运算符的重载” ---> 用于判断两个迭代器是否指向不同节点
bool operator!=(const Self& ht)
{
return _node != ht._node;
}
//5.实现:“==运算符的重载” ---> 用于判断两个迭代器是否指向相同节点
bool operator==(const Self& ht)
{
return _node == ht._node;
}
//6.实现:“前置++运算符的重载”---> 用于遍历哈希表
Self& operator++()
{
//情况1:当前链表中的还有后序节点 ---> 访问下个节点
if (_node->_next)
{
_node = _node->_next;
}
//情况2:当前链表中的所有节点都已经遍历完了 ---> 寻找下一个非空桶
else
{
/*----------------第一步:定义仿函数----------------*/
//1.定义提取当前节点的键的仿函数
KeyOfT kot;
//2.定义将键转化为size_t类型的仿函数
Hash hashFunc;
/*----------------第二步:寻找空桶----------------*/
//1.计算当前键对应桶索引
size_t hash_i = hashFunc(kot(_node->_data)) % _ht->_tables.size(); //注意:第一步一定要先计算桶索引,因为元素可能分布在不同的桶中
//2.从当前桶的下一个位置开始线性搜索空桶的位置
++hash_i; //注意这一步哟,如果你不添加这一不步的话,程序会死循环,别问我是怎么知道的哈哈哈
//3.使用while循环遍历后序的桶 ---> 直到找到非空桶或结束
while (hash_i < _ht->_tables.size()) //未找到:遍历到最后一桶结束
{
//3.1:获取当桶的头节点
_node = _ht->_tables[hash_i];
//3.2:情况1:当前桶是非空桶 ---> 停止搜索
if (_node)
{
break; //找到了:找到非空桶
}
//3.3:情况2:当前桶是空桶 ---> 继续检查下一桶
else
{
++hash_i;
}
}
//4.处理未找到空桶的情况 ---> 将迭代器置为end()的状态
if (hash_i == _ht->_tables.size())
{
_node = nullptr;
}
/*----------------第三步: 返回自身的引用----------------*/
return *this;
}
}
};
/*------------------任务:定义“哈希表的类模板”------------------*/
//template<class K, class V, class Hash = HashFunc<K>>
template<class K, class T, class KeyOfT, class Hash> //注意:这里要封装unordered_set/unordered_map 这里的模板参数已经从
class HashTable //<class K, class V, class Hash = HashFunc<K>> ---> <class K, class T, class KeyOfT, class Hash>
{
private:
/*------------------成员变量------------------*/
//1.存储HashNode<K, V>*类型数据的数组,每个元素都是桶的头指针
//2.记录哈希表中有效元素的变量
//vector<HashNode<K, V>*> _tables;
vector<HashNode<T>*> _tables;
size_t _n;
/*注意现在的结构的形式是:
* 1.哈希表
* 1.1:成员变量:容器vector
* 1.1.1:哈希表节点类型的指针:HashNode<K,V>*
* 1.1.1.1:键值对:_kv
* 1.1.1.2:下一个节点的指:_next
* 1.2:成员变量:变量_n
*/
/*------------------类型别名------------------*/
////1.重命名哈希表节点的类型:HashNode<K,V> ---> Node
//typedef HashNode<K, V> Node;
//1.重命名哈希表节点的类型:HashNode<T> ---> Node
typedef HashNode<T> Node;
/*------------------友元声明------------------*/
//1.将“哈希表迭代器的类模板”声明为“哈希表类模板”的友元类
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash> //注意:类模板的友元的声明
friend struct HTIterator;
public:
/*------------------类型别名------------------*/
//1.重命名哈希表的“普通迭代器”的类型:HTIterator<K,T,T&,T*,KeyOfT,Hash> ---> Iterator
typedef HTIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;
//2.重命名哈希表的“常量迭代器”的类型:HTIterator<K,T,const T&,const T*,KeyOfT,Hash> ---> ConstIterator
typedef HTIterator<K, T, const T&, const T*, KeyOfT, Hash> ConstIterator;
/*------------------成员函数------------------*/
//1.实现:“获取普通迭代器的起始位置”---> 找到第一个非空桶的第一个节点
Iterator Begin()
{
//1.若哈希表中没有任何有效数据,直接返回结束迭代器
if (_n == 0)
{
return End();
}
//2.使用for循环遍历哈希桶数组寻找第一个非空桶
for (size_t i = 0; i < _tables.size(); i++)
{
//2.1:获取第i的桶的头节点
Node* current = _tables[i];
//2.2:若当前桶的头节点不为空,说明该桶有数据
if (current)
{
return Iterator(current, this); //注意:返回指向该桶第一个节点的迭代器,同时传入当前哈希表指针(供迭代器内部使用)
}
}
}
//2.实现:“获取普通迭代器的终止位置”---> 用nullptr表示
Iterator End()
{
return Iterator(nullptr, this);
}
//3.实现:“获取常量迭代器的起始位置”---> 找到第一个非空桶的第一个节点(只读)
ConstIterator Begin()const
{
//1.若哈希表中没有任何有效数据,直接返回结束迭代器
if (_n == 0)
{
return End();
}
//2.使用for循环遍历哈希桶数组寻找第一个非空桶
for (size_t i = 0; i < _tables.size(); i++)
{
//2.1:获取第i的桶的头节点
Node* current = _tables[i];
//2.2:若当前桶的头节点不为空,说明该桶有数据
if (current)
{
return ConstIterator(current, this); //注意:返回指向该桶第一个节点的迭代器,同时传入当前哈希表指针(供迭代器内部使用)
}
}
}
//4.实现:“获取常量迭代器的终止位置”---> 用nullptr表示
ConstIterator End()const
{
return ConstIterator(nullptr, this);
}
//5.实现:“哈希表的构造函数”
HashTable()
:_tables(_stl_next_prime(0)) //初始化为11个桶
, _n(0)
{
}
//6.实现:“哈希表的析构函数”
~HashTable()
{
//1.遍历哈希表的每个桶(注:_tables 是存储桶头节点指针的容器)
for (size_t i = 0; i < _tables.size(); ++i)
{
//2.获取当前桶的头节点指针,从第一个桶开始清理
Node* current = _tables[i];
//3.遍历当前桶对应的链表,逐个释放节点内存
while (current)
{
//3.1:提前保存当前节点的下一个节点指针 ---> 防止删除当前节点后丢失链表连接
Node* next = current->_next;
//3.2:释放当前节点的内存(避免内存泄漏)
delete current;
//3.3:移动到下一个节点,继续清理
current = next;
}
//4.将当前桶的头节点指针置空,确保析构后桶不会指向无效内存
_tables[i] = nullptr;
}
}
//3.实现:“查找操作”---> 根据键查找对应的节点,找到返回节点指针,未找到返回 nullptr
//Node* Find(const K& key)
Iterator Find(const K& key) //注意:这里要封装unordered_set / unordered_map 这里函数的返回类型已经从:Node* ---> Iterator
{
/*----------------第一步:定义仿函数----------------*/
//1. 定义提取当前节点的键的仿函数
KeyOfT kot;
//2. 定义将键转化为size_t类型的仿函数
Hash hashFunc;
/*----------------第二步:寻找键对应的桶----------------*/
//1. 计算键的哈希值并取模,得到对应的桶索引
size_t hash_i = hashFunc(key) % _tables.size();
/* 代码解释:
* 1. hashFunc(key):调用哈希函数,将键转换为 size_t 类型的哈希值
* 2. % _tables.size():对哈希表的桶数量取模,确定节点应该落在哪个桶中
* 3.目的:将任意键映射到 [0, _tables.size()-1] 范围内的桶索引
*/
//2. 获取对应桶的头节点,开始遍历链表
Node* current = _tables[hash_i]; //注意:_tables[hash_i] 是桶的头节点指针
/*----------------第三步:遍历当前桶的链表----------------*/
//1. 遍历当前桶中的链表,查找目标键
while (current) //注意:若 current 为 nullptr,说明桶为空,直接跳过循环
{
//1.1 检查当前节点的键是否匹配目标 key
//if (current->_kv.first == key)
if (kot(current->_data) == key)
{
//return current;
return Iterator(current, this);
}
//1.2 若不匹配,移动到链表的下一个节点
else
{
current = current->_next;
}
}
////2. 遍历完链表后仍未找到匹配的键,返回 nullptr
//return nullptr;
//2. 遍历完整个桶的链表仍未找到,返回 End() 迭代器
return End();
}
//4.实现:“删除操作”---> 根据键删除哈希表中的节点,成功返回 true,失败返回 false
bool Erase(const K& key)
{
/*----------------第一步:定义仿函数----------------*/
//1.定义提取当前节点的键的仿函数
KeyOfT kot;
//2.定义将键转化为size_t类型的仿函数
Hash hashFunc;
/*----------------第二步:寻找键对应的桶----------------*/
//1.计算键对应的桶索引
size_t hash_i = hashFunc(key) % _tables.size();
//2.定义一个指向桶的头节点的指针
Node* curr = _tables[hash_i];
//3.定义一个指向当前节点的前驱节点的指针
Node* prev = nullptr; //作用记录待删除节点的前驱节点
/*----------------第三步:遍历当前桶的链表----------------*/
//1.遍历当前桶的链表,查找目标键
while (curr)
{
//情况一:找到目标节点
//if (curr->_kv.first == key)
if (kot(curr->_data) == key)
{
//1.删除目标节点
///场景一:待删除节点是桶的头节点
if (prev == nullptr)
{
_tables[hash_i] = curr->_next; // 直接将桶的头指针指向头节点的下一个节点
}
//场景二:待删除节点在链表中间或末尾
else
{
prev->_next = curr->_next; // 让前驱节点的 next 指针跳过当前节点,指向后一个节点
}
//2.释放目标节点的内存
delete curr;
//3.更新有效元素数量
--_n;
//4.删除成功,返回 true
return true;
}
//情况二:未找到目标节点,继续遍历
//1.当前节点的前驱节点指向当前节点
prev = curr;
//2.当前节点指向下一个节点的位置
curr = curr->_next;
}
//2.遍历完整个桶的链表仍未找到目标键,删除失败
return false;
}
//5.实现:“插入操作”---> 插入键值对,成功返回true,键已存在返回false
//bool Insert(const pair<K, V>& kv)
pair<Iterator, bool> Insert(const T& data) //注意:封装unordered_map 时候会添加operator[]操作,所以这里的Insert函数的返回类型从bool ---> pair<Iterator bool>
{
/*----------------第一步:查重判断----------------*/
//1.定义提取当前节点的键的仿函数
KeyOfT kot;
//2.使用Find函数判断键是否已经存在
Iterator it = Find(kot(data));
if (it != End())
{
//return false; // 当键kv.first已经存在时,插入失败
return { it,false }; //若存在,直接返回已有迭代器和插入失败标志
}
/*----------------第二步:扩容操作----------------*/
//1.进行扩容判断:负载因子(元素数/桶数)等于1时触发扩容
if (_n == _tables.size()) //目的:避免哈希冲突过多导致链表过长,影响性能
{
//2.创建新数组,容量为大于当前size的最小质数(减少哈希冲突)
//vector<Node*> newVector(_stl_next_prime(_tables.size() + 1));
vector<Node*> newVector(_tables.size() * 2);
//3.使用for循环遍历旧表中的所有桶 ---> 将旧表中的所有节点重新插入到新表中
for (size_t i = 0; i < _tables.size(); i++)
{
//4.定义一个指针指向当前节点的指针
Node* current = _tables[i];
//5.遍历链表 ---> 将遍历的到的每个节点节点进行插入
while (current)
{
//6.定义一个指针指向当前节点的下一个节点的指针 ---> 暂存下一节点避免链表断裂
Node* next = current->_next;
//7.定义将键转化为size_t类型的仿函数
Hash hashFunc;
//8.重新计算“遍历到节点”在新表中的桶索引 ---> 因表长变化,哈希值需重新取模
//size_t hash_i = hashFunc(current->_kv.first) % newVector.size();
size_t hash_i = hashFunc(kot(current->_data)) % newVector.size();
//9.使用头插入法将当前节点插入新表对应桶的头部
//第一步:新插入的节点的下一个节点 ---> 该节点的桶索引位置的链表头节点
current->_next = newVector[hash_i];
//第二步:将新插入的节点的指针赋值给其对应的桶
newVector[hash_i] = current;
//第三步:指向当前节点的current指针向后移动一位
current = next;
}
//10.清空旧表的当前桶
_tables[i] = nullptr; //注意:当前桶在旧表中的哈希值是i,在新表中的哈希值是hash_i
}
//11.交换新旧哈希表:旧表.swap(新表)
_tables.swap(newVector); //注意:当前表指向新表,旧表由newht接管(离开作用域时自动释放)
}
/*----------------第三步:插入数据----------------*/
//1.创建新节点
//Node* newNode = new Node(kv);
Node* newNode = new Node(data);
//2.定义将键转化为size_t类型的仿函数
Hash hashFunc;
//3.计算“新插入数据”的哈希值/桶索引
//size_t hash_i = hashFunc(kv.first) % _tables.size();
size_t hash_i = hashFunc(kot(data)) % _tables.size();
//4.1:头插第一步:
newNode->_next = _tables[hash_i];
//4.2:头插第二步:
_tables[hash_i] = newNode;
//5.更新新表中有效元素的数量
++_n;
////6.插入成功返回true即可
//return true;
//6.返回插入成功的信息
return { Iterator(newNode, this), true }; //新节点迭代器和插入成功标志
//注意:迭代器由两部分组成:1.当前节点的指针 2.当前哈希表的指针
}
};
}Myunordered_set.h
#pragma once
#include "HashTable.h"
namespace Myunordered_set
{
/*------------任务:定义哈希表中节点的三种状态的“枚举”------------*/
enum State
{
EXIST, //存在状态
EMPTY, //空状态
DELETE //删除状态
};
/*------------任务:定义哈希表存储的数据结构的“结构体模板”------------*/
template <class K, class V>
struct HashData
{
//1.存储键值对类型的数据
//2.记录存储的节点的状态
pair<K, V> _kv;
State _state = EMPTY; //节点的状态默认为空
};
/*------------任务:实现一个基于哈希表的无序集合------------*/
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
private:
/*--------------------成员函数--------------------*/
//1.实现:“从键值对中取键的仿函数”(当然这里的键就是本身)
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
/*--------------------成员变量--------------------*/
//注意:unoredered_set容器的底层是“使用链地址法实现的哈希表”
hash_bucket::HashTable<K, const K, SetKeyOfT, Hash> _ht;
public:
/*--------------------类型别名--------------------*/
//1.重定义哈希表底层的“普通迭代器”hash_bucket::HashTable<K,const K,SetKeyOfT,Hash>::Iterator ---> iterator
typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, Hash>::Iterator iterator;
//2.重定义哈希表底层的“常量迭代器”hash_bucket::HashTable<K,const K,SetKeyOfT,Hash>::ConstIterator ---> const_iterator
typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator const_iterator;
/*--------------------成员函数--------------------*/
//1.实现:“获取普通迭代器的起始位置”
iterator begin()
{
return _ht.Begin();
}
//2.实现:“获取普通迭代器的终止位置”
iterator end()
{
return _ht.End();
}
//3.实现:“获取常量迭代器的起始位置”
const_iterator begin()const
{
return _ht.Begin();
}
//4.实现:“获取常量迭代器的终止位置”
const_iterator end()const
{
return _ht.End();
}
//5.实现:“查找操作”
iterator find(const K& key)
{
return _ht.Find(key);
}
//6.实现:“删除操作”
bool erase(const K& key)
{
return _ht.Erase(key);
}
//7.实现:“插入操作”
pair<iterator, bool> insert(const K& key)
{
return _ht.Insert(key);
}
};
}Myunordered_map.h
#pragma once
#include "HashTable.h"
namespace Myunordered_map
{
/*------------任务:实现基于哈希表的无序映射(键值对存储)------------*/
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
private:
/*--------------------成员函数--------------------*/
//1.实现:“从键值对中取键的仿函数”(用于哈希表操作)
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
/*--------------------成员变量--------------------*/
//注意:unoredered_set容器的底层是“使用链地址法实现的哈希表”
hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;
public:
/*--------------------类型别名--------------------*/
//1.重定义哈希表底层的“普通迭代器”hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator ---> iterator
typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;
//2.重定义哈希表底层的“常量迭代器”hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator ---> const_iterator
typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator const_iterator;
/*--------------------成员函数--------------------*/
//1.实现:“获取普通迭代器的起始位置”
iterator begin()
{
return _ht.Begin();
}
//2.实现:“获取普通迭代器的终止位置”
iterator end()
{
return _ht.End();
}
//3.实现:“获取常量迭代器的起始位置”
const_iterator begin()const
{
return _ht.Begin();
}
//4.实现:“获取常量迭代器的终止位置”
const_iterator end()const
{
return _ht.End();
}
//5.实现:“查找操作”
iterator find(const K& key)
{
return _ht.Find(key);
}
//6.实现:“删除操作”
bool erase(const K& key)
{
return _ht.Erase(key);
}
//7.实现:“插入操作”
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
//8.实现:“[]运算符的重载”
V& operator[](const K& key)
{
//1定义变量接收insert函数的返回值
pair<iterator, bool> ret = insert({ key,V() });
//2.返回插入或已存在的键对应的值引用
return ret.first->second;
}
/* 注意事项:
* 1. 如果键存在,返回对应值的引用
* 2. 如果键不存在,插入新键值对(值为默认构造)并返回引用
*/
};
}测试文件:Test.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include <string>
#include "Myunordered_set.h"
#include "Myunordered_map.h"
using namespace std;
/*--------------------------测试:unordered_set容器的基本功能--------------------------*/
void test01()
{
cout << "=== 测试 unordered_set 基本功能 ===" << endl;
//1. 初始化与插入
Myunordered_set::unordered_set<int> s;
s.insert(3);
s.insert(1);
s.insert(4);
s.insert(1); // 重复插入,应被忽略
s.insert(2);
s.insert(5);
//2. 迭代器遍历(无序)
cout << "遍历元素: ";
for (auto it = s.begin(); it != s.end(); ++it)
{
cout << *it << " ";
}
cout << endl;
//3. 查找操作
int key = 3;
auto find_ret = s.find(key);
if (find_ret != s.end())
{
cout << "找到元素: " << *find_ret << endl;
}
else
{
cout << "未找到元素: " << key << endl;
}
//4. 删除操作
key = 4;
bool erase_ret = s.erase(key);
if (erase_ret)
{
cout << "删除元素 " << key << " 成功" << endl;
}
else
{
cout << "删除元素 " << key << " 失败" << endl;
}
//5. 验证删除结果
cout << "删除后遍历: ";
for (auto val : s) // 范围for循环(依赖begin/end)
{
cout << val << " ";
}
cout << endl << endl;
}
/*--------------------------测试:unordered_set 对“字符串类型”的支持--------------------------*/
void test02()
{
cout << "=== 测试 unordered_set 字符串类型 ===" << endl;
Myunordered_set::unordered_set<string> str_set;
str_set.insert("apple");
str_set.insert("banana");
str_set.insert("cherry");
str_set.insert("apple"); // 重复插入
cout << "字符串集合元素: ";
for (const auto& str : str_set)
{
cout << str << " ";
}
cout << endl;
// 查找测试
string target = "banana";
auto it = str_set.find(target);
if (it != str_set.end())
{
cout << "找到字符串: " << *it << endl;
}
else
{
cout << "未找到字符串: " << target << endl;
}
// 删除测试
str_set.erase("cherry");
cout << "删除 cherry 后: ";
for (const auto& str : str_set)
{
cout << str << " ";
}
cout << endl << endl;
}
/*--------------------------测试:unordered_map 的基本功能--------------------------*/
void test03()
{
cout << "=== 测试 unordered_map 基本功能 ===" << endl;
//1. 初始化与插入
Myunordered_map::unordered_map<string, int> m;
m.insert({ "apple", 10 });
m.insert({ "banana", 20 });
m.insert({ "cherry", 30 });
m.insert({ "apple", 15 }); // 重复插入,应被忽略
//2. 使用[]运算符(插入+修改)
m["date"] = 40; // 插入新键值对
m["banana"] = 25; // 修改已有值
//3. 迭代器遍历(键值对)
cout << "遍历键值对: " << endl;
for (auto it = m.begin(); it != m.end(); ++it)
{
cout << it->first << ": " << it->second << endl;
}
//4. 查找操作
string key = "cherry";
auto it = m.find(key);
if (it != m.end())
{
cout << "找到 " << key << ": " << it->second << endl;
}
else
{
cout << "未找到 " << key << endl;
}
//5. 删除操作
key = "banana";
bool erase_ret = m.erase(key);
if (erase_ret)
{
cout << "删除 " << key << " 成功" << endl;
}
else
{
cout << "删除 " << key << " 失败" << endl;
}
//6. 验证删除结果
cout << "删除后 " << key << " 是否存在: "
<< (m.find(key) != m.end() ? "是" : "否") << endl << endl;
}
/*--------------------------测试:Myunordered_map 的[]运算符特殊场景--------------------------*/
void test04()
{
cout << "=== 测试 unordered_map []运算符 ===" << endl;
Myunordered_map::unordered_map<int, string> m;
//1. 插入新键(值为默认构造)
m[1]; // 插入{1, ""}
//2. 插入并修改
m[2] = "two";
//3. 修改已有值
m[2] = "second";
//4. 插入新键值对
m[3] = "three";
//5.遍历验证
for (auto& kv : m)
{
cout << kv.first << ": " << kv.second << endl;
}
cout << endl;
}
/*--------------------------测试:测试边界情况(空容器、删除不存在元素等)--------------------------*/
void test05()
{
cout << "=== 测试边界情况 ===" << endl;
//1.测试空set
Myunordered_set::unordered_set<int> s_empty;
cout << "空set的begin() == end(): "
<< (s_empty.begin() == s_empty.end() ? "true" : "false") << endl;
cout << "删除空set中的元素: "
<< (s_empty.erase(100) ? "成功" : "失败") << endl << endl;
//2.测试空map
Myunordered_map::unordered_map<int, int> mp_empty;
cout << "空map的begin() == end(): "
<< (mp_empty.begin() == mp_empty.end() ? "true" : "false") << endl;
cout << "访问空map的[]: " << mp_empty[100] << endl;
}
int main()
{
test01();
test02();
test03();
test04();
test05();
return 0;
}运行结果:
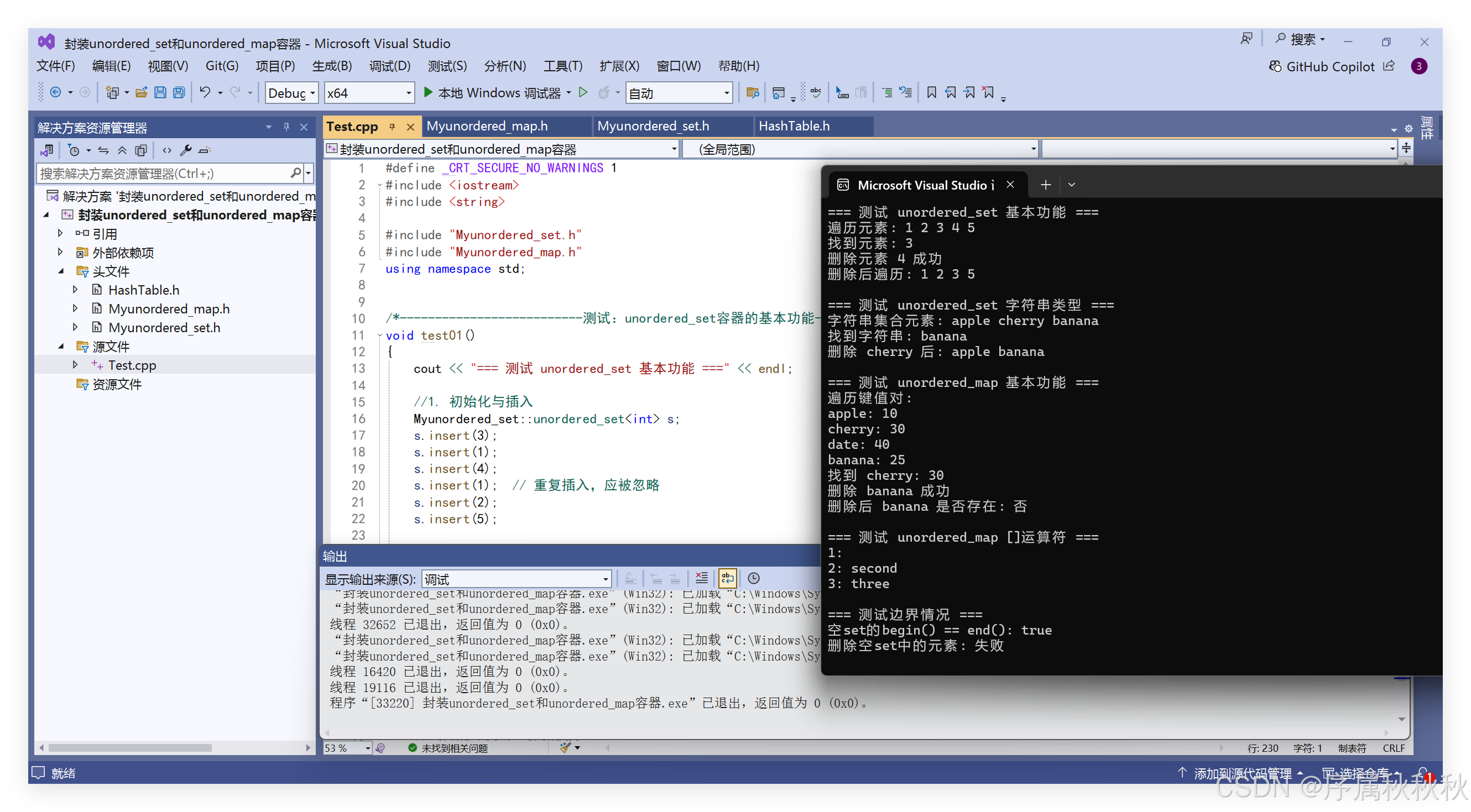
在这里插入图片描述
------------代码解释------------
片段一:仿函数的设计
与
set、map相比,unordered_set和unordered_map的模拟实现类结构要更复杂一些,但整体大框架和思路是完全类似的。
由于HashTable是泛型实现,无法确定模板参数T具体是K(像unordered_set的元素类型 ),还是pair<K, V>(像unordered_map的键值对类型 )。
在插入操作(insert)时,需要用K对象转换为整数取模,以及进行K的相等性比较。
- 可
pair的value本就不参与取模计算 - 而且默认比较逻辑是对
key和value一起比较是否相等,但我们实际只需要比较K对象
所以:在unordered_set和unordered_map这一层,我们分别实现SetKeyOfT和MapKeyOfT这两个仿函数,传递给HashTable的KeyOfT
之后:HashTable就能通过KeyOfT仿函数,从T类型对象里提取出K对象,再完成转换为整数取模以及K相等性比较的操作
/*-------------------------- Myunordered_set.h --------------------------*/
// Myunordered_set.h
namespace Myunordered_set
{
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
private:
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
hash_bucket::HashTable<K, const K, SetKeyOfT, Hash> _ht;
public:
pair<iterator, bool> insert(const K& key)
{
return _ht.Insert(key);
}
};
}
/*-------------------------- Myunordered_map.h --------------------------*/
// Myunordered_map.h
namespace bit
{
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
private:
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;
public:
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
};
}
/*-------------------------- HashTable.h --------------------------*/
// HashTable.h
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
inline unsigned long _stl_next_prime(unsigned long n)
{
static const int _stl_num_primes = 28;
static const unsigned long _stl_prime_list[_stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
const unsigned long* first = _stl_prime_list;
const unsigned long* last = _stl_prime_list + _stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
namespace hash_bucket
{
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
: _data(data)
, _next(nullptr)
{
}
};
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
private:
vector<HashNode<T>*> _tables;
size_t _n;
typedef HashNode<T> Node;
public:
HashTable()
{
_tables.resize(_stl_next_prime(_tables.size()), nullptr);
}
~HashTable()
{
//1.遍历哈希表的每个桶(注:_tables 是存储桶头节点指针的容器)
for (size_t i = 0; i < _tables.size(); ++i)
{
//2.获取当前桶的头节点指针,从第一个桶开始清理
Node* current = _tables[i];
//3.遍历当前桶对应的链表,逐个释放节点内存
while (current)
{
//3.1:提前保存当前节点的下一个节点指针 ---> 防止删除当前节点后丢失链表连接
Node* next = current->_next;
//3.2:释放当前节点的内存(避免内存泄漏)
delete current;
//3.3:移动到下一个节点,继续清理
current = next;
}
//4.将当前桶的头节点指针置空,确保析构后桶不会指向无效内存
_tables[i] = nullptr;
}
}
pair<Iterator, bool> Insert(const T& data) //注意:封装unordered_map 时候会添加operator[]操作,所以这里的Insert函数的返回类型从bool ---> pair<Iterator bool>
{
/*----------------第一步:查重判断----------------*/
//1.定义提取当前节点的键的仿函数
KeyOfT kot;
//2.使用Find函数判断键是否已经存在
Iterator it = Find(kot(data));
if (it != End())
{
//return false; // 当键kv.first已经存在时,插入失败
return { it,false }; //若存在,直接返回已有迭代器和插入失败标志
}
/*----------------第二步:扩容操作----------------*/
//1.进行扩容判断:负载因子(元素数/桶数)等于1时触发扩容
if (_n == _tables.size()) //目的:避免哈希冲突过多导致链表过长,影响性能
{
//2.创建新数组,容量为大于当前size的最小质数(减少哈希冲突)
//vector<Node*> newVector(_stl_next_prime(_tables.size() + 1));
vector<Node*> newVector(_tables.size() * 2);
//3.使用for循环遍历旧表中的所有桶 ---> 将旧表中的所有节点重新插入到新表中
for (size_t i = 0; i < _tables.size(); i++)
{
//4.定义一个指针指向当前节点的指针
Node* current = _tables[i];
//5.遍历链表 ---> 将遍历的到的每个节点节点进行插入
while (current)
{
//6.定义一个指针指向当前节点的下一个节点的指针 ---> 暂存下一节点避免链表断裂
Node* next = current->_next;
//7.定义将键转化为size_t类型的仿函数
Hash hashFunc;
//8.重新计算“遍历到节点”在新表中的桶索引 ---> 因表长变化,哈希值需重新取模
//size_t hash_i = hashFunc(current->_kv.first) % newVector.size();
size_t hash_i = hashFunc(kot(current->_data)) % newVector.size();
//9.使用头插入法将当前节点插入新表对应桶的头部
//第一步:新插入的节点的下一个节点 ---> 该节点的桶索引位置的链表头节点
current->_next = newVector[hash_i];
//第二步:将新插入的节点的指针赋值给其对应的桶
newVector[hash_i] = current;
//第三步:指向当前节点的current指针向后移动一位
current = next;
}
//10.清空旧表的当前桶
_tables[i] = nullptr; //注意:当前桶在旧表中的哈希值是i,在新表中的哈希值是hash_i
}
//11.交换新旧哈希表:旧表.swap(新表)
_tables.swap(newVector); //注意:当前表指向新表,旧表由newht接管(离开作用域时自动释放)
}
private:
vector<Node*> _tables; // 指针数组
size_t _n = 0; // 表中存储有效数据个数
}
};
}片段二:迭代器的设计
第一点:unordered_set 和 unordered_map的 iterator 的实现框架,和 list 的 iterator 思路一致:
- 用一个类型封装 “结点指针”,再通过重载运算符,让迭代器能像指针一样完成访问操作
- 需要注意的是,哈希表的迭代器是单向迭代器(只能向后遍历,无法反向)
第二点:unordered_set 和 unordered_map的 iterator 的容器特性的满足:
unordered_set 迭代器的 “不可修改性”
unordered_set 的迭代器不支持修改 key,只需把 unordered_set 的第二个模板参数改为 const K 即可,对应哈希表声明为:
HashTable<K, const K, SetKeyOfT, Hash> _ht;unordered_map 迭代器的 “部分可修改性”
unordered_map 的迭代器不允许修改 key,但允许修改 value 。只需把 unordered_map 的键值对中 “第一个参数(key)” 设为 const K 即可,对应哈希表声明为:
HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;总结:这样一来,迭代器遍历、修改的规则就和容器特性(unordered_set/unordered_map 的 “键是否可改” 需求 )匹配上了,既保证逻辑合理,也符合 C++ 对容器迭代器的设计习惯。
//前置声明,因为 HTIterator 中要用到 HashTable
template<class K, class T, class KeyOfT, class Hash> //注意:类模板的前置声明的方法
class HashTable;
/*------------------任务:定义“哈希表的迭代器的结构体模板------------------*/
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
struct HTIterator
{
/*------------------成员变量------------------*/
//1.指向当前节点的指针
//2.指向哈希表的指针 ---> 用于遍历的桶
HashNode<T>* _node;
const HashTable<K, T, KeyOfT, Hash>* _ht; // 注意:迭代器这里需要使用到哈希表,所以在定义迭代器之前我们先进行了哈希表的前置声明
/*------------------类型别名------------------*/
//1.重命名“哈希表节点”的类型:HashNode<T> ---> Node
typedef HashNode<T> Node;
//2.重命名“哈希表的迭代器”的类型:HTIterator<K,T,Ref,Ptr,SetKeyOfT,Hash> ---> Self
typedef HTIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;
//3.重命名“哈希表”的类型:HashTable<K,T,KeOfT,Hash> ---> HT
typedef HashTable<K, T, KeyOfT, Hash> HT;
/*------------------成员函数------------------*/
//1.实现:“迭代器的构造函数”
HTIterator(Node* node, const HT* ht)
:_node(node)
, _ht(ht)
{
}
//2.实现:“*运算符的重载” ---> 返回数据的引用(本身)
Ref operator*()
{
return _node->_data;
}
//3.实现:“->运算符的重载”---> 返回数据的指针(地址)
Ptr operator->()
{
return &_node->_data;
}
//4.实现:“!=运算符的重载” ---> 用于判断两个迭代器是否指向不同节点
bool operator!=(const Self& ht)
{
return _node != ht._node;
}
//5.实现:“==运算符的重载” ---> 用于判断两个迭代器是否指向相同节点
bool operator==(const Self& ht)
{
return _node == ht._node;
}
//6.实现:“前置++运算符的重载”---> 用于遍历哈希表
Self& operator++()
{
//情况1:当前链表中的还有后序节点 ---> 访问下个节点
if (_node->_next)
{
_node = _node->_next;
}
//情况2:当前链表中的所有节点都已经遍历完了 ---> 寻找下一个非空桶
else
{
/*----------------第一步:定义仿函数----------------*/
//1.定义提取当前节点的键的仿函数
KeyOfT kot;
//2.定义将键转化为size_t类型的仿函数
Hash hashFunc;
/*----------------第二步:寻找空桶----------------*/
//1.计算当前键对应桶索引
size_t hash_i = hashFunc(kot(_node->_data)) % _ht->_tables.size(); //注意:第一步一定要先计算桶索引,因为元素可能分布在不同的桶中
//2.从当前桶的下一个位置开始线性搜索空桶的位置
++hash_i; //注意这一步哟,如果你不添加这一不步的话,程序会死循环,别问我是怎么知道的哈哈哈
//3.使用while循环遍历后序的桶 ---> 直到找到非空桶或结束
while (hash_i < _ht->_tables.size()) //未找到:遍历到最后一桶结束
{
//3.1:获取当桶的头节点
_node = _ht->_tables[hash_i];
//3.2:情况1:当前桶是非空桶 ---> 停止搜索
if (_node)
{
break; //找到了:找到非空桶
}
//3.3:情况2:当前桶是空桶 ---> 继续检查下一桶
else
{
++hash_i;
}
}
//4.处理未找到空桶的情况 ---> 将迭代器置为end()的状态
if (hash_i == _ht->_tables.size())
{
_node = nullptr;
}
/*----------------第三步: 返回自身的引用----------------*/
return *this;
}
}
};片段三:operator++的设计
迭代器内部会维护一个
“指向结点的指针”,operator++实现时,要分两种情况:
- 如果
当前桶还有后续结点,直接让指针指向下一个结点即可 - 如果
当前桶已经遍历完毕,就需要 “寻找下一个桶”
这里的关键设计是:迭代器中除了存 “结点指针”,还会存 “哈希表对象的指针”
这样,当当前桶遍历完时:
- 可通过
哈希表对象,结合key 值计算当前桶位置 - 然后往后找 “第一个不为空的桶”,就能拿到下一批结点
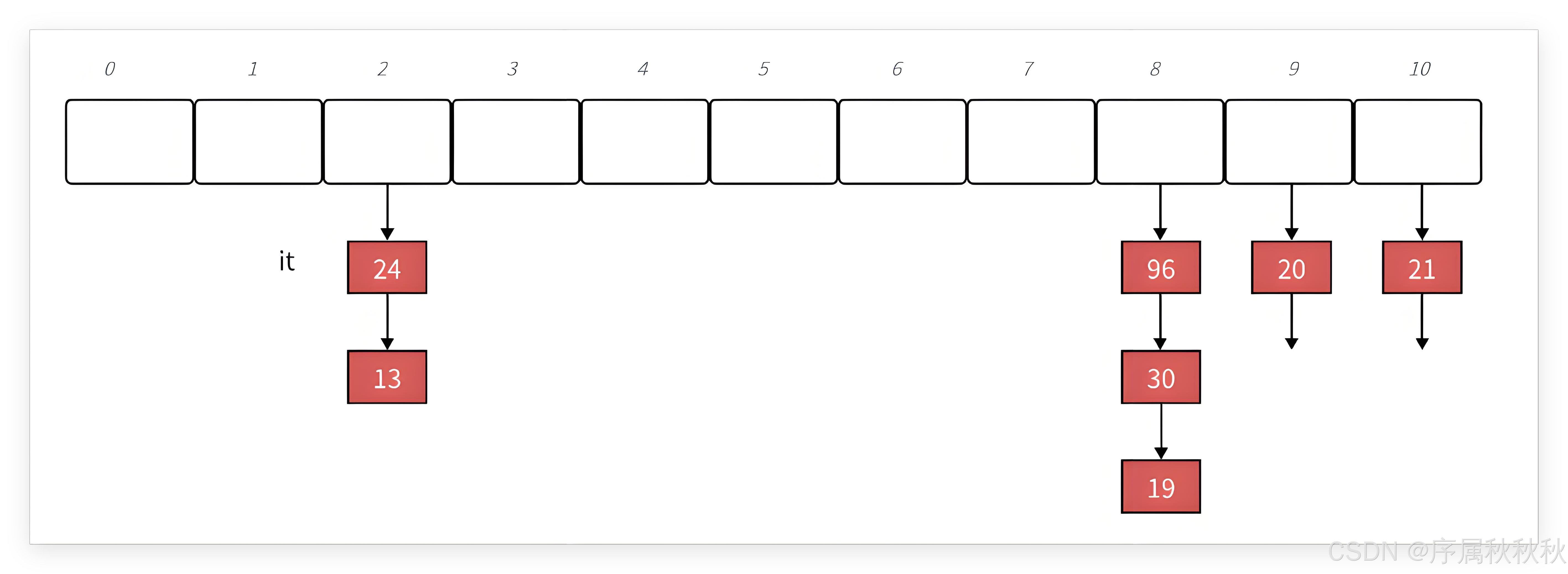
在这里插入图片描述
//6.实现:“前置++运算符的重载”---> 用于遍历哈希表
Self& operator++()
{
//情况1:当前链表中的还有后序节点 ---> 访问下个节点
if (_node->_next)
{
_node = _node->_next;
}
//情况2:当前链表中的所有节点都已经遍历完了 ---> 寻找下一个非空桶
else
{
/*----------------第一步:定义仿函数----------------*/
//1.定义提取当前节点的键的仿函数
KeyOfT kot;
//2.定义将键转化为size_t类型的仿函数
Hash hashFunc;
/*----------------第二步:寻找空桶----------------*/
//1.计算当前键对应桶索引
size_t hash_i = hashFunc(kot(_node->_data)) % _ht->_tables.size(); //注意:第一步一定要先计算桶索引,因为元素可能分布在不同的桶中
//2.从当前桶的下一个位置开始线性搜索空桶的位置
++hash_i; //注意这一步哟,如果你不添加这一不步的话,程序会死循环,别问我是怎么知道的哈哈哈
//3.使用while循环遍历后序的桶 ---> 直到找到非空桶或结束
while (hash_i < _ht->_tables.size()) //未找到:遍历到最后一桶结束
{
//3.1:获取当桶的头节点
_node = _ht->_tables[hash_i];
//3.2:情况1:当前桶是非空桶 ---> 停止搜索
if (_node)
{
break; //找到了:找到非空桶
}
//3.3:情况2:当前桶是空桶 ---> 继续检查下一桶
else
{
++hash_i;
}
}
//4.处理未找到空桶的情况 ---> 将迭代器置为end()的状态
if (hash_i == _ht->_tables.size())
{
_node = nullptr;
}
/*----------------第三步: 返回自身的引用----------------*/
return *this;
}
}片段四:begin()和end()的设计
begin()和end()的设计:
begin():返回 “第一个非空桶的第一个结点指针” 构造的迭代器end():返回一个代表 “遍历结束” 的空迭代器(可用空指针等方式表示)
//1.实现:“获取普通迭代器的起始位置”---> 找到第一个非空桶的第一个节点
Iterator Begin()
{
//1.若哈希表中没有任何有效数据,直接返回结束迭代器
if (_n == 0)
{
return End();
}
//2.使用for循环遍历哈希桶数组寻找第一个非空桶
for (size_t i = 0; i < _tables.size(); i++)
{
//2.1:获取第i的桶的头节点
Node* current = _tables[i];
//2.2:若当前桶的头节点不为空,说明该桶有数据
if (current)
{
return Iterator(current, this); //注意:返回指向该桶第一个节点的迭代器,同时传入当前哈希表指针(供迭代器内部使用)
}
}
}
//2.实现:“获取普通迭代器的终止位置”---> 用nullptr表示
Iterator End()
{
return Iterator(nullptr, this);
}片段五:map支持[]运算符的重载
要让 unordered_map 支持 [] 运算符,关键在于调整 insert 相关的返回值逻辑 。
具体来说,需要修改 HashTable 中的 Insert 函数,使其返回值类型变为 pair<Iterator, bool> ,也就是把 Insert 函数定义改为
pair<Iterator, bool> Insert(const T& data)这样的修改,能为 unordered_map 实现 [] 运算符提供必要的返回值支撑,让插入操作的结果可以被合理利用
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号