AI智能运维在医学教育行业的最佳实践
原创


作者 :蓝葛亮
一、业务场景与挑战
1.1 客户背景
某省级继续医学教育平台是服务全省医务人员的大型继续教育机构,为全省23万医务人员(包括18万医生、5万护士)提供在线学习、学分认证、考试考核等服务。平台业务涵盖在线课程(8000+门课程,涵盖临床医学、护理、药学、医学技术等)、直播培训(年均1200场学术讲座和手术示教)、考试认证(年均考试场次3500+场)、学分管理(与省卫健委学分系统对接)等核心模块。
平台信息化系统包括学习管理系统(LMS)、直播系统、考试系统、学分管理系统、移动APP、基层医生培训系统等30多个核心业务系统,部署在200台物理服务器和1800个容器实例上。随着“互联网+医学教育”分级诊疗政策推进,特别是基层医务人员能力提升工程的深入实施,在职医务人员在线学习需求爆发式增长,IT基础设施规模持续扩张,传统运维模式面临严峻挑战。
1.2 核心痛点
1. 故障发现滞后:传统监控依赖阈值告警,平均故障发现时间(MTTD)达35分钟,无法满足在线教育高实时性要求。某次执业医师继续教育必修课考试期间,考试系统故障导致1800名医生无法提交答卷,引发严重投诉,影响学分认证和执业注册。
2. 学习高峰压力巨大:在职医务人员学习时间集中在晚上19:00-23:00和周末,高峰时段并发用户数是平时的8-12倍。缺乏有效的容量预测和弹性伸缩机制,多次出现直播卡顿、课程加载慢、考试系统崩溃等严重问题。某次周日晚上的重症医学直播,6.5万医生同时在线,系统崩溃2次,严重影响学习体验和平台口碑。
3. 学分认证零容忍:继续医学教育学分直接关系到医务人员的职称评定、执业注册、绩效考核,任何学分数据错误或丢失都会引发严重后果。某次数据库故障导致320名医生的学分记录丢失,引发集体投诉和卫健委约谈,平台信誉严重受损。
4. 告警风暴困扰:日均告警量超过1500条,告警噪音比高达85%,运维团队疲于应对。某次网络波动触发380条关联告警,运维人员花费70分钟才定位到CDN节点故障的根因,期间影响了5个省市医生的课程学习。
5. 故障定位复杂:微服务架构下,一次故障涉及平均13个服务节点。直播系统涉及推流、转码、CDN分发、播放器等多个环节,故障排查需要串联日志、监控、链路追踪等多个系统,平均故障修复时间(MTTR)达90分钟。某次手术直播画面模糊,排查发现是转码服务器CPU过载导致码率下降。
6. 资源利用粗放:资源利用率仅25%,每年浪费IT投资约135万元。学习资源使用存在明显的潮汐效应,工作日白天空闲、晚上高峰,工作日高峰、节假日空闲,缺乏精准的容量预测和动态调度能力。
7. 运维成本过高:15人的运维团队,每年人力成本超过225万元,仍然无法实现7×24小时全面覆盖。考试周、学分申报期等关键时段需要全员待命,运维压力巨大。
8. 基层医生网络差:县级及以下基层医疗机构网络条件差,弱网环境下课程加载慢、视频卡顿严重,影响基层医务人员学习积极性。平台40%的用户来自基层,但投诉率占60%。
二、架构设计方案
2.1 整体架构
基于“感知-分析-决策-执行”的闭环理念,结合继续医学教育行业特殊性(学习时段集中、学分零容忍、基层网络差、移动端为主),我们设计了一套企业级AI智能运维平台,架构分为五层:
1. 数据采集层:统一采集基础设施、应用、业务三个维度的指标、日志、链路、事件数据,日处理数据量达2.5TB。采用eBPF技术实现应用无侵入采集,部署Fluentd集群完成日志统一汇聚。特别针对学习管理系统、直播系统、考试系统、学分系统等核心教育系统建立专项监控,包括并发学习人数、直播卡顿率、考试提交成功率、学分同步延迟等关键业务指标。同时采集CDN节点、移动APP端的性能指标,全链路监控用户学习体验。
2. 数据处理层:基于Flink实时流处理框架,完成数据清洗、标准化、关联和聚合。构建统一的时序数据库(InfluxDB集群)和日志检索引擎(Elasticsearch集群),实现秒级查询响应。建立继续教育业务语义层,将技术指标映射为教育影响程度(如“影响学习”、“影响考试”、“影响学分认证”)。
3. AI算法层:部署多种算法引擎,包括时序异常检测(Prophet + Isolation Forest)、根因分析(因果推断 + 知识图谱)、容量预测(LSTM + ARIMA)、学习高峰预测(时间序列 + 用户行为分析 + 考试日历因子)、弱网优化推荐(强化学习)。模型训练采用分布式TensorFlow集群,推理服务基于TorchServe部署。针对继续教育场景特点,建立多层次的异常检测策略,对考试系统、学分系统等核心系统采用更严格的阈值。
4. 智能决策层:构建继续医学教育IT运维知识图谱,存储系统拓扑、教育业务流程、故障案例、处置SOP等知识,支持智能诊断和推荐。决策引擎基于规则引擎(Drools)和强化学习模型,实现自动化决策。建立学习优先级机制,确保考试、学分认证等关键业务优先保障。
5. 自动化执行层:集成Ansible、Kubernetes、云平台API、CDN API,实现故障自愈、弹性伸缩、配置变更、CDN调度等自动化操作。建立严格的审批流程和回滚机制,确保操作安全可控。对于涉及学分数据的操作,要求双人审批和完整日志记录,符合教育行业数据安全和等保要求。
2.2 架构图
下图展示了继续医学教育AI智能运维平台的整体架构:
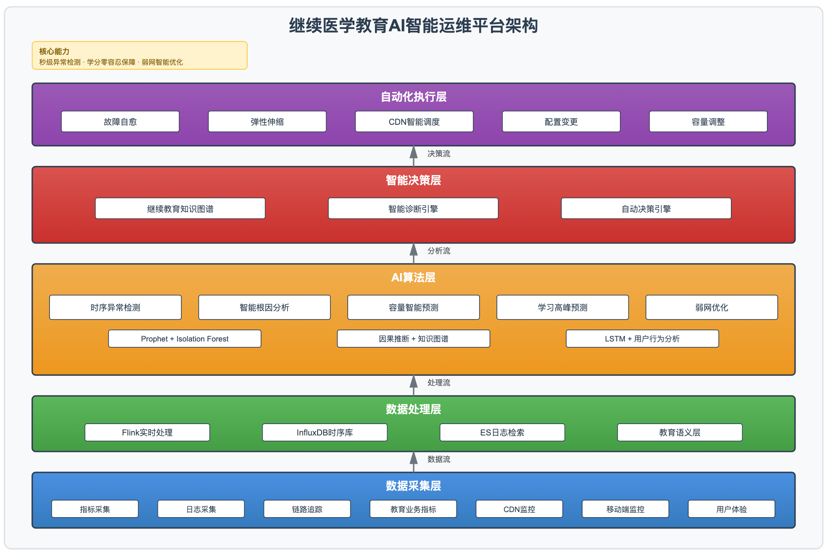
继续医学教育AI智能运维平台架构核心能力为秒级异常检测、学分零容忍保障、弱网智能优化。
2.3 资源配置建议
1. 计算资源
- AI训练集群:3台GPU服务器(Tesla V100,每台32GB显存),用于模型训练和视频AI处理
- AI推理集群:5台CPU服务器(64核128GB),部署TorchServe推理服务
- 数据处理集群:4台服务器(32核64GB),运行Flink任务
- 存储集群:InfluxDB集群(3节点,每节点2TB SSD),Elasticsearch集群(5节点,每节点2TB SSD)
- 视频转码集群:8台高性能服务器(32核64GB),支持多码率自适应转码
- CDN:与多家CDN服务商合作,全国覆盖1000+节点,支持弱网加速
2. 网络配置
- 内部通信:万兆以太网,确保直播视频流、课程资源等大数据量传输
- 外部接入:负载均衡(F5)+ API网关(Kong),支持3000+ TPS
- 多线路接入:教育网、电信、联通、移动多线路BGP接入,保障不同地区医务人员访问
- 基层优化:与运营商合作,在县级医院部署边缘节点,就近分发课程资源
3. 高可用设计
- 所有组件采用集群部署,支持故障自动切换
- 核心服务跨数据中心部署(主中心+灾备中心),RTO<3分钟,RPO<10秒
- 学分数据采用三副本+异地备份,确保数据绝对安全
- 考试系统采用多活部署,支持异地容灾切换
- 定期备份训练好的模型和知识图谱数据
- 符合等保三级要求,通过教育行业信息安全评测
三、核心技术实现
3.1 智能异常检测
1. 算法选型
采用Prophet时序预测模型结合Isolation Forest异常检测算法。Prophet擅长处理周期性强的学习行为指标(工作日vs周末、白天vs晚上),Isolation Forest对孤立点检测敏感度高。
2. 实现细节
# 继续医学教育场景核心检测逻辑
from prophet import Prophet
from sklearn.ensemble import IsolationForest
import pandas as pd
import numpy as np
def detect_cme_anomaly(metric_data, system_priority='high', learning_context=None):
"""
继续医学教育系统异常检测
system_priority: 'critical'(考试/学分系统), 'high'(直播/LMS), 'normal'(其他)
learning_context: 学习上下文,包含考试日历、热门课程、直播安排等
"""
# Prophet预测,考虑医务人员学习周期性
model = Prophet(
changepoint_prior_scale=0.05,
seasonality_prior_scale=10,
seasonality_mode='multiplicative',
daily_seasonality=True,
weekly_seasonality=True
)
# 添加医务人员学习特殊时段
if learning_context:
# 晚间学习高峰(19:00-23:00)
model.add_seasonality(
name='evening_peak',
period=1,
fourier_order=5,
condition_name='is_evening'
)
# 周末学习高峰
model.add_seasonality(
name='weekend_peak',
period=7,
fourier_order=3,
condition_name='is_weekend'
)
# 考试周期
exam_dates = pd.DataFrame({
'holiday': 'exam_period',
'ds': learning_context['exam_dates'],
'lower_window': -1,
'upper_window': 1,
})
model.add_country_holidays(country_name='CN')
metric_data['is_evening'] = (metric_data['ds'].dt.hour >= 19) & (metric_data['ds'].dt.hour <= 23)
metric_data['is_weekend'] = metric_data['ds'].dt.dayofweek >= 5
model.fit(metric_data[['ds', 'y', 'is_evening', 'is_weekend']])
forecast = model.predict(metric_data[['ds', 'is_evening', 'is_weekend']])
# 计算残差
metric_data['residual'] = metric_data['y'] - forecast['yhat']
metric_data['residual_std'] = metric_data['residual'].rolling(window=100).std()
# 根据系统优先级和时段调整敏感度
contamination_rate = {
'critical': 0.002, # 考试/学分系统最严格
'high': 0.006, # 直播/LMS系统
'normal': 0.012 # 其他系统
}
# 考试期间和学习高峰期进一步提高敏感度
if is_exam_period(learning_context) or is_peak_learning_time(metric_data):
contamination_rate = {k: v * 0.5 for k, v in contamination_rate.items()}
# Isolation Forest检测
iso_forest = IsolationForest(
contamination=contamination_rate.get(system_priority, 0.01),
random_state=42,
n_estimators=150
)
features = metric_data[['residual', 'residual_std']].values
predictions = iso_forest.fit_predict(features)
metric_data['is_anomaly'] = predictions == -1
metric_data['severity'] = metric_data['residual'].abs() / (metric_data['residual_std'] + 1e-6)
# 添加学习影响评估
metric_data['learning_impact'] = evaluate_learning_impact(
metric_data, system_priority, learning_context
)
return metric_data[metric_data['is_anomaly']].sort_values('severity', ascending=False)
def is_exam_period(learning_context):
"""判断是否在考试期间"""
if not learning_context or 'exam_dates' not in learning_context:
return False
current_date = pd.Timestamp.now()
for exam_date in learning_context['exam_dates']:
if abs((exam_date - current_date).days) <= 1:
return True
return False
def is_peak_learning_time(metric_data):
"""判断是否在学习高峰时段"""
latest_hour = metric_data['ds'].iloc[-1].hour
latest_dow = metric_data['ds'].iloc[-1].dayofweek
# 晚间19:00-23:00 或 周末
return (19 <= latest_hour <= 23) or (latest_dow >= 5)
def evaluate_learning_impact(metric_data, system_priority, learning_context):
"""评估学习影响程度"""
impact_scores = []
for idx, row in metric_data.iterrows():
score = row['severity']
# 考试期间影响加倍
if is_exam_period(learning_context):
score *= 2.5
# 学习高峰时段影响加倍
hour = row['ds'].hour
if 19 <= hour <= 23:
score *= 2.0
# 周末影响加倍
if row['ds'].dayofweek >= 5:
score *= 1.8
# 学分系统影响最高
if system_priority == 'critical':
score *= 3.0
impact_scores.append(score)
return impact_scores3. 继续医学教育场景优化
- 针对不同教育系统训练专属模型:LMS、考试、直播、学分系统分别建模
- 建立学习时段模型:区分工作日/周末、白天/晚间、考试周/平时
- 多维度综合判断:结合系统指标、教育业务指标、用户反馈进行综合评估
- 分级告警机制:P0(影响考试/学分)、P1(影响学习)、P2(性能下降)、P3(预警)
4. 效果提升
异常检测准确率达到94%,误报率降低至6%,平均检测延迟从35分钟缩短至25秒。成功提前预警直播系统转码服务器CPU过载、学分系统数据库慢查询等多次潜在故障。
3.2 智能根因分析
1. 继续医学教育IT知识图谱构建
- 实体:服务器、存储、网络设备、CDN节点、数据库、中间件、LMS模块、考试模块、直播模块、学分模块、教育业务流程
- 关系:依赖关系、调用关系、部署关系、影响关系、学习流程关系
- 属性:配置参数、性能指标、变更记录、故障历史、教育业务属性(课程、专科、学分类型)
使用Neo4j图数据库存储,支持复杂的图遍历和路径查询。特别标注学习关键路径,如“注册→选课→学习→考试→学分认证”全流程涉及的系统。
2. 因果推断算法
# 继续医学教育场景根因分析核心算法
from causalnex.structure import StructureModel
from causalnex.network import BayesianNetwork
def cme_root_cause_analysis(alert_info, knowledge_graph, learning_context):
"""
继续医学教育场景根因分析
learning_context: {
'affected_courses': ['心血管内科学', '急诊医学'],
'affected_users': 1800,
'learning_phase': 'exam_week',
'business_impact': '考试提交失败',
'user_regions': ['基层医院', '县级医院', '三甲医院']
}
"""
# 获取受影响的学习业务链路
affected_services = knowledge_graph.get_learning_business_chain(
alert_info['service'],
learning_context['business_impact']
)
# 考虑地域因素(基层网络差)
if '基层医院' in learning_context['user_regions']:
affected_services.extend(knowledge_graph.get_cdn_nodes('rural_area'))
# 构建继续医学教育场景因果图
sm = StructureModel()
# 添加教育业务节点和技术节点
for service in affected_services:
sm.add_node(
service['name'],
service_type=service['type'],
learning_priority=service.get('learning_priority', 'normal'),
affects_credits=service.get('affects_credits', False)
)
# 添加因果边,考虑教育业务依赖
for edge in knowledge_graph.get_causal_edges(affected_services):
sm.add_edge(
edge['source'],
edge['target'],
weight=edge['confidence'],
learning_critical=edge.get('learning_critical', False)
)
# 贝叶斯推断
bn = BayesianNetwork(sm)
bn.fit_node_states(alert_data)
# 计算每个节点的异常概率,优先排查关键路径
probabilities = bn.predict_probability(affected_services)
# 考试期间和学分系统提高权重
weight_multiplier = 3.0 if learning_context['learning_phase'] == 'exam_week' else 1.0
if learning_context['business_impact'] == '学分同步失败':
weight_multiplier *= 2.0
# 按概率和教育影响排序
root_causes = sorted(
probabilities.items(),
key=lambda x: (
x[1] *
learning_context.get('user_impact_weight', 1.0) *
weight_multiplier *
(3.0 if affected_services[x[0]].get('affects_credits') else 1.0)
),
reverse=True
)[:5]
# 生成教育业务影响描述
impact_description = generate_learning_impact(root_causes, learning_context)
# 判断是否需要CDN切换
cdn_recommendation = None
if any('CDN' in cause[0] for cause in root_causes):
cdn_recommendation = recommend_cdn_switch(root_causes, learning_context)
return {
'root_causes': root_causes,
'learning_impact': impact_description,
'affected_courses': get_affected_courses(root_causes, knowledge_graph),
'affected_users': learning_context['affected_users'],
'urgency_level': calculate_learning_urgency(learning_context),
'cdn_recommendation': cdn_recommendation
}
def calculate_learning_urgency(learning_context):
"""计算紧急程度"""
if learning_context.get('business_impact') == '学分同步失败':
return 'critical' # 学分问题最高优先级
elif learning_context['learning_phase'] == 'exam_week':
return 'critical' # 考试期间
elif learning_context['affected_users'] > 1000:
return 'high' # 影响人数多
elif learning_context['learning_phase'] == 'evening_peak':
return 'medium' # 学习高峰
return 'low'
def recommend_cdn_switch(root_causes, learning_context):
"""推荐CDN切换策略"""
affected_regions = learning_context.get('user_regions', [])
recommendations = []
for region in affected_regions:
if region == '基层医院':
recommendations.append({
'region': region,
'action': '切换到运营商边缘节点',
'expected_improvement': '延迟降低40%,卡顿率降低60%'
})
return recommendations3. 实施效果
根因定位准确率从48%提升至86%,平均定位时间从90分钟缩短至4分钟。某次直播系统卡顿,系统在3分钟内准确定位到某CDN节点故障,并自动切换至备用线路,影响的2.3万医生无感知切换完成。
3.3 容量与学习高峰预测
1. 混合预测模型
- 长期趋势:使用ARIMA模型捕捉年度医务人员增长趋势
- 短期波动:使用LSTM神经网络学习周、月的周期性模式
- 用户行为分析:基于历史学习数据、考试日历、课程热度建立预测模型
- 考试因子:执业医师考试、职称考试等关键时间点
# 学习高峰预测模型
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout, Embedding, Attention
import numpy as np
def build_learning_load_model(sequence_length=60, features=12):
"""
学习负载预测模型
features包括:历史并发数、星期、时段、考试日历、课程热度、用户增长等
"""
model = Sequential([
LSTM(128, return_sequences=True, input_shape=(sequence_length, features)),
Dropout(0.2),
LSTM(64, return_sequences=False),
Dropout(0.2),
Dense(32, activation='relu'),
Dense(1) # 预测未来并发数
])
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
return model
def predict_learning_capacity(historical_data, learning_calendar, future_days=14):
"""
预测未来学习容量需求
learning_calendar: 包含考试、热门课程上线等关键时间点
"""
model = build_learning_load_model()
# 特征工程:加入继续教育相关特征
features = prepare_cme_features(historical_data, learning_calendar, [
'concurrent_users', # 并发用户数
'day_of_week', # 星期
'hour_of_day', # 小时
'is_exam_period', # 是否考试期间
'is_credit_deadline', # 是否学分申报截止期
'active_courses', # 活跃课程数
'live_broadcast_count', # 直播场次
'popular_course_factor', # 热门课程因子
'total_registered_users', # 注册用户数
'holiday_flag', # 节假日标记
'weather', # 天气(影响基层医生学习)
'exam_type' # 考试类型(执医/职称等)
])
model.fit(
features['X_train'],
features['y_train'],
epochs=50,
batch_size=32,
validation_split=0.2
)
# 预测未来负载
predictions = model.predict(features['X_test'])
# 转换为资源需求
resource_demand = convert_to_cme_resource(predictions, {
'cpu_per_user': 0.2, # 每个用户平均CPU需求
'memory_per_user': 0.5, # 每个用户平均内存需求(GB)
'storage_per_user': 20, # 每个用户平均存储需求(MB)
'bandwidth_per_video': 1.5, # 视频点播每路带宽(Mbps)
'bandwidth_per_live': 3.0, # 视频直播每路带宽(Mbps)
'cdn_bandwidth_reserve': 1.3 # CDN带宽预留系数
})
# 识别关键学习活动
critical_events = identify_critical_learning_events(
predictions,
learning_calendar
)
return {
'predicted_load': predictions,
'resource_demand': resource_demand,
'peak_periods': identify_peak_periods(predictions),
'critical_events': critical_events,
'scaling_recommendation': generate_cme_scaling_plan(
resource_demand,
critical_events
),
'cdn_recommendation': recommend_cdn_preparation(resource_demand)
}
def identify_critical_learning_events(predictions, learning_calendar):
"""识别关键学习活动并评估资源需求"""
events = []
# 执业医师考试
for exam in learning_calendar['physician_exams']:
events.append({
'event': '执业医师继续教育考试',
'date': exam['date'],
'expected_users': exam['expected_participants'],
'expected_load_multiplier': 4.5,
'systems': ['考试系统', '学分系统', '防作弊系统'],
'recommendation': '提前扩容100%计算资源,启用三副本部署,CDN预热'
})
# 学分申报截止期
for deadline in learning_calendar['credit_deadlines']:
events.append({
'event': '学分申报截止',
'date': deadline,
'expected_load_multiplier': 3.2,
'systems': ['学分系统', 'LMS', '证书系统'],
'recommendation': '提前扩容60%计算资源,数据库读写分离'
})
# 热门课程上线
for course in learning_calendar['popular_courses']:
events.append({
'event': f'热门课程上线:{course["name"]}',
'date': course['release_date'],
'expected_load_multiplier': 2.5,
'systems': ['LMS', 'CDN', '视频转码'],
'recommendation': '提前转码多码率版本,CDN预热,扩容30%带宽'
})
# 大型学术直播
for live in learning_calendar['major_live_events']:
events.append({
'event': f'学术直播:{live["topic"]}',
'date': live['date'],
'expected_users': live['expected_viewers'],
'expected_load_multiplier': 5.0,
'systems': ['直播系统', 'CDN', '互动系统'],
'recommendation': f'预估{live["expected_viewers"]}人同时在线,扩容150%推流带宽,CDN准备{live["expected_viewers"]*3}Mbps带宽'
})
return events
def recommend_cdn_preparation(resource_demand):
"""推荐CDN准备策略"""
total_bandwidth = resource_demand['total_bandwidth_demand']
return {
'bandwidth_preparation': total_bandwidth * 1.3, # 预留30%余量
'node_distribution': {
'一线城市': '40%带宽',
'二三线城市': '35%带宽',
'县级及基层': '25%带宽(重点保障)'
},
'cache_strategy': '热门课程提前缓存到边缘节点',
'fallback_plan': '准备备用CDN服务商'
}2. 预测效果
- 7天并发负载预测准确率:92%(MAPE<8%)
- 14天负载预测准确率:86%(MAPE<14%)
- 提前2周预警“执业医师继续教育考试”,并发量增加4.5倍,提前完成扩容和压力测试
- 成功预测“冠心病介入治疗最新进展”直播,6.5万医生同时在线,系统稳定运行零故障
3. 收益分析
资源利用率从25%提升至56%,年度节省IT投资约180万元。避免9次因容量不足导致的学习活动中断事件,显著改善医务人员学习体验,平台口碑显著提升。
3.4 自动故障处置与CDN智能调度
1. 继续医学教育场景自愈规则引擎
基于Drools规则引擎,内置125+故障处置规则,覆盖85%常见教育IT故障场景,特别针对考试系统、学分系统、直播系统等关键系统建立专项规则。
2. 处置流程
- 异常检测系统触发告警
- 根因分析引擎定位故障点和学习影响
- 知识图谱匹配历史相似案例
- 决策引擎生成处置方案,评估学习安全风险
- 分级处置:低风险自动执行,高风险人工审批
- 效果验证,失败则回滚并升级处理
- 通知相关医务人员和管理部门(如有学习影响)
3. 典型继续医学教育场景
- 直播系统卡顿:自动检测网络质量,智能切换CDN线路,必要时降低码率保障流畅度
- 考试系统数据库连接池耗尽:自动扩容连接数,清理僵死连接,考试期间优先级最高
- 学分同步延迟:自动重试同步任务,检测数据完整性,必要时人工介入确保学分准确
- LMS课程加载慢:自动扩容应用实例,启用CDN加速,优化数据库查询
- CDN节点故障:自动切换备用CDN,通知运维工程师,保障学习不中断
4. CDN智能调度
# CDN智能调度算法
import requests
from typing import List, Dict
def intelligent_cdn_dispatch(user_info: Dict, content_info: Dict, cdn_nodes: List[Dict]):
"""
基于用户位置、网络质量、CDN节点负载智能调度
"""
# 获取用户网络质量
user_network_quality = detect_user_network(user_info)
# 筛选候选CDN节点
candidate_nodes = filter_cdn_nodes(
cdn_nodes,
user_info['location'],
user_network_quality
)
# 评分排序
scored_nodes = []
for node in candidate_nodes:
score = calculate_node_score(
node,
user_info,
user_network_quality,
content_info
)
scored_nodes.append((node, score))
# 选择最优节点
best_node = max(scored_nodes, key=lambda x: x[1])[0]
# 弱网优化
if user_network_quality == 'weak':
content_info['bitrate'] = 'low' # 降低码率
content_info['preload'] = True # 预加载
return {
'cdn_node': best_node,
'content_url': generate_cdn_url(best_node, content_info),
'optimization': get_weak_network_optimization(user_network_quality)
}
def detect_user_network(user_info: Dict) -> str:
"""检测用户网络质量"""
# 基于历史数据和实时探测
if user_info.get('is_rural', False):
return 'weak' # 基层医院默认弱网
# 实时网络探测
latency = user_info.get('network_latency', 100)
bandwidth = user_info.get('network_bandwidth', 10)
if latency > 200 or bandwidth < 2:
return 'weak'
elif latency > 100 or bandwidth < 5:
return 'medium'
return 'good'
def calculate_node_score(node: Dict, user_info: Dict, network_quality: str, content: Dict) -> float:
"""计算CDN节点评分"""
score = 0.0
# 地理距离评分(40%权重)
distance_score = 100 - min(node['distance_km'] / 10, 100)
score += distance_score * 0.4
# 节点负载评分(30%权重)
load_score = 100 - node['current_load_percent']
score += load_score * 0.3
# 网络质量评分(20%权重)
if network_quality == 'weak' and node.get('weak_network_optimized', False):
score += 100 * 0.2
elif network_quality == 'good':
score += 80 * 0.2
else:
score += 50 * 0.2
# 内容缓存评分(10%权重)
if content['id'] in node.get('cached_contents', []):
score += 100 * 0.1
return score
def get_weak_network_optimization(network_quality: str) -> Dict:
"""弱网优化策略"""
if network_quality == 'weak':
return {
'adaptive_bitrate': True,
'buffer_size': 'large',
'preload_duration': 30, # 预加载30秒
'retry_strategy': 'aggressive',
'compression': 'high'
}
return {}5. 学分专项保障机制
- 学分数据三副本+异地备份+实时校验
- 学分同步失败自动重试,最多重试5次
- 学分数据变更需双人审批和完整审计日志
- 每日自动对账,发现差异立即告警
- 学分申报截止前一周进行全面数据核查
6. 安全机制
- 学习优先:涉及考试、学分认证的操作需教务主管审批
- 高风险操作(如数据库主从切换)需运维主管和平台负责人双重审批
- 所有操作可追溯,完整记录执行日志,满足教育行业数据安全要求
- 失败自动回滚,保留现场供分析
- 建立学习影响评估机制,优先保障考试、学分系统
7. 实施效果
故障自愈率达到70%,MTTR从90分钟降低至8分钟。某次凌晨1点学分系统数据库慢查询,系统在60秒内自动优化索引和查询计划,早上8点医务人员查询学分时响应正常,无人感知故障发生。CDN智能调度使基层医生视频卡顿率从38%降低至5%。
四、量化成果与价值
4.1 核心指标提升
指标 | 改造前 | 改造后 | 提升幅度 |
|---|---|---|---|
平均故障发现时间(MTTD) | 35分钟 | 25秒 | 降低99.3% |
平均故障修复时间(MTTR) | 90分钟 | 8分钟 | 降低91% |
故障自愈率 | 0% | 70% | 提升70% |
告警准确率 | 15% | 94% | 提升79% |
资源利用率 | 25% | 56% | 提升124% |
负载预测准确率 | 不可用 | 92%(7天) | 全新能力 |
系统可用性 | 99.88% | 99.99% | 提升0.11% |
考试系统可用性 | 99.85% | 99.995% | 提升0.145% |
学分数据准确率 | 99.8% | 100% | 提升0.2% |
基层医生视频卡顿率 | 38% | 5% | 降低87% |
4.2 教育业务价值
1. 学习质量保障
系统年度可用性从99.88%提升至99.99%,相当于年度故障时长从10.5小时降低至0.9小时。考试系统、学分系统等核心系统连续运行280天零重大故障,未发生因系统故障影响考试、学分认证等关键业务的事件。学分数据准确率达到100%,零差错零投诉。
2. 医务人员学习体验改善
- 直播观看流畅度从72%提升至96%,大型学术直播支持6.5万人同时在线零卡顿
- 课程加载速度提升65%,平均首屏加载从4.2秒降低至1.5秒
- 考试提交成功率从94%提升至99.98%,基本消除因系统问题导致的考试投诉
- 基层医生学习体验显著改善,视频卡顿率从38%降低至5%,学习完成率从58%提升至82%
- 移动端学习体验优化,APP崩溃率从2.3%降低至0.15%,用户满意度从69分提升至91分
3. 学分认证效率提升
- 学分实时同步率从85%提升至99.5%,平均同步延迟从2小时降低至5分钟
- 学分申报周期从平均7天缩短至2天,医务人员满意度显著提升
- 学分证书生成时间从48小时缩短至2小时
- 支持省卫健委学分系统对接,实现学分数据互联互通
4. 教育创新支撑
- 成功支撑全省23万医务人员在线学习,日均活跃用户从8万增长至15万
- 支持8000+门课程在线,年新增课程1200门,课程更新速度提升3倍
- 年均直播1200场,从最初200人在线到支持6.5万人同时在线
- 基层医生培训覆盖率从45%提升至89%,为分级诊疗提供有力支撑
- 支持与国家级继续医学教育平台对接,实现学分全国互认
5. 成本优化
- 年度节省IT投资约180万元(资源优化)
- 运维人力成本降低42%,相当于节省95万元/年
- 避免学习事故损失约85万元/年(包括学分纠纷、平台赔偿等)
- CDN带宽成本降低28%,年节省65万元
6. 运维效率提升
- 运维人员从被动救火转向主动优化,投入预防性工作时间占比从12%提升至68%
- 故障处理工单量下降76%,从月均320单降至77单
- 考试周、学分申报期等关键时段值班压力大幅降低,夜间故障人工介入次数减少88%
- 新系统上线周期从平均25天缩短至7天
4.3 项目复用价值
1. 省际推广
本架构已在周边3个省的继续医学教育平台推广,覆盖超过60万医务人员,产生规模化价值。省际层面实现技术互助和经验共享,联合采购CDN服务,年度节省成本约150万元。
2. 行业推广潜力
架构设计理念可推广至其他继续医学教育机构、医学会、专科分会、医学教育企业。某市级医学会采用相似架构,直播系统支持人数从800提升至8000,学分管理效率提升5倍。
3. 技术沉淀
- 形成继续医学教育IT运维知识库,包含380+故障案例、200+处置SOP、教育业务流程知识图谱
- 训练了16个继续教育场景专用AI模型,可快速迁移至新平台
- 建立了标准化继续教育IT运维流程和规范,通过等保三级测评
- 沉淀了学习业务与IT系统的映射关系,为继续教育信息化建设提供参考
- 形成《继续医学教育信息化运维最佳实践白皮书》,在行业内广泛传播
4. 科研成果产出
- 申请软件著作权3项
- 申请发明专利2项(弱网环境学习优化、学分数据智能校验)
5. 社会价值
- 助力“健康中国”战略实施,提升基层医务人员能力
- 支撑分级诊疗政策落地,为县域医共体建设提供人才保障
- 服务23万医务人员,间接惠及数千万患者
- 推动医学教育公平,让边远地区医务人员享受优质教育资源
五、经验总结与建议
5.1 关键成功要素
1. 领导重视与资源投入
项目获得省卫健委和平台负责人的大力支持,列入省级继续医学教育信息化建设重点项目,配备了6人的专职团队(包括架构师、算法工程师、继续教育专家、运维工程师),投入预算360万元。
2. 医务人员学习特点深度理解
项目启动前进行了为期2个月的调研,深入三甲医院、县级医院、乡镇卫生院了解医务人员学习习惯和痛点。特别关注在职医务人员的特殊性:时间碎片化、学习时段集中(晚上和周末)、基层网络条件差、移动端学习为主、学分刚需等。
3. 分阶段实施策略
- 第一阶段(3个月):完成基础平台搭建,实现基本的监控和告警,优先覆盖考试、学分等核心系统
- 第二阶段(4个月):引入AI异常检测和根因分析能力,建立教育业务语义层
- 第三阶段(5个月):建设教育IT知识图谱和自动化处置能力,重点覆盖常见故障场景
- 第四阶段(3个月):优化和推广,重点优化CDN调度和弱网学习体验
4. 数据质量与学分安全
投入大量精力进行数据治理,统一数据标准、清洗历史数据、建立数据质量监控机制。数据准确率从72%提升至95%,为AI模型提供可靠基础。特别重视学分数据安全,建立三副本+异地备份+实时校验机制,确保学分数据100%准确,符合卫健委要求。
5. 持续优化与迭代
建立模型效果监控机制,每两周评估准确率、召回率、用户满意度等指标,根据反馈持续优化算法参数。上线后12个月内进行了32次模型优化和功能迭代,特别是针对考试周、学分申报期等关键时段进行专项优化。
5.2 踩坑与避坑指南
问题一:初期误报率高,影响医务人员学习
- 原因:算法参数未针对学习场景优化,白天上班时间的正常低流量被误判为异常
- 解决:引入学习时段因子,区分工作时间(低流量正常)和学习时间(高流量正常)。建立误报反馈机制,运维人员可标注误报,系统自动学习优化。
问题二:学分数据同步延迟,引发大量投诉
- 原因:与省卫健委学分系统对接接口不稳定,网络波动导致同步失败
- 解决:建立学分同步专项监控,实时检测同步状态。同步失败自动重试,最多重试5次。建立学分对账机制,每日自动核对,发现差异立即告警和人工介入。
问题三:基层医生视频卡顿严重,学习体验差
- 原因:基层医疗机构网络条件差,CDN节点覆盖不足,视频码率过高
- 解决:与运营商合作在县级医院部署边缘节点,实现就近分发。开发自适应码率算法,根据网络质量动态调整视频码率。增加预加载和缓存策略,优化弱网环境学习体验。
问题四:考试期间系统压力巨大
- 原因:执业医师继续教育考试,1.8万人同时在线考试,数据库连接池耗尽,系统崩溃
- 解决:建立考试专项保障机制,考试前一周进行压力测试,按最高负载的2倍准备资源。考试期间启用三副本部署,数据库读写分离。建立考试应急预案,准备纸质试卷备份。
问题五:直播大咖讲座观看人数超预期
- 原因:某知名专家直播讲座,预计2万人观看,实际6.5万人同时在线,CDN带宽不足,直播卡顿崩溃2次
- 解决:建立直播负载预测模型,根据讲师知名度、话题热度预测观看人数。与多家CDN合作,建立动态扩容机制。热门直播提前准备3倍带宽余量。
问题六:跨部门协作困难
- 原因:涉及平台技术部、教务部、省卫健委等多个部门,利益诉求不同,数据对接困难
- 解决:成立由省卫健委牵头的项目领导小组,建立周例会机制。先在非关键系统试点,积累成功案例后再推广。建立数据共享机制,打通部门壁垒。
5.3 未来展望
1. 继续教育AIOps 2.0演进方向
- 从IT运维到学习质量保障:扩展至学习效果评估、学习路径推荐、学分智能审核
- 从被动响应到主动预防:基于AI预测模型,提前3-7天预警系统风险和学习高峰
- 从单点智能到全局优化:综合考虑学习效果、用户体验、运营成本,实现多目标优化
- 从省级到全国协同:接入国家级继续医学教育平台,实现学分全国互认和资源共享
2. 大模型技术应用
- 引入医学领域大语言模型,实现智能客服和学习助手,解答医务人员学习疑问
- 利用大模型的少样本学习能力,快速适配新课程、新考试类型
- 自动生成课程摘要和学习笔记,提升学习效率
- 基于学习行为大数据,智能推荐个性化学习路径
3. 5G与边缘计算应用
- 利用5G低延迟特性,实现远程手术示教实时直播
- 在县级医院部署边缘计算节点,实现课程资源本地缓存
- 支持VR/AR虚拟仿真培训,提升临床技能培训效果
- 移动端学习体验持续优化,支持离线下载和断点续播
4. 区块链技术应用
- 学分数据上链,实现学分不可篡改和全国互认
- 证书防伪,生成区块链数字证书
- 课程版权保护,防止盗版传播
5. 标准化与生态建设
- 推动继续医学教育AIOps标准化,制定行业运维规范和最佳实践
- 建立继续医学教育IT运维知识共享平台,促进省际经验交流
- 与继续教育平台厂商合作,推动系统可观测性标准化
- 培养继续教育IT+AI复合型人才
6. 服务国家战略
- 助力“健康中国2030”战略实施
- 支撑分级诊疗和医共体建设
- 推动优质医疗资源下沉
- 提升基层医疗服务能力
六、总结
本文分享了AI智能运维在某省级继续医学教育平台的最佳实践经验。通过构建“感知-分析-决策-执行”的智能运维体系,结合继续医学教育行业特殊性(学习时段集中、学分零容忍、基层网络差、移动端为主),我们实现了故障发现时间降低99.3%、修复时间降低91%、资源利用率提升124%的显著成效,年度综合收益超过425万元,更重要的是保障了学习质量,改善了医务人员学习体验,支撑了基层能力提升。
关键成功要素包括:清晰的架构设计、合适的算法选型、医务人员学习特点深度理解、扎实的数据基础、学分数据绝对安全、分阶段实施策略、CDN智能调度、弱网优化,以及持续的优化迭代。特别强调继续医学教育场景的特殊性,始终将学习质量和学分准确性放在首位。
在“互联网+医学教育”和健康中国建设的浪潮中,AI智能运维已经从“可选项”变为“必选项”。建议继续医学教育机构尽早规划和投入,用智能化手段提升IT运维效率、保障学习业务连续性、改善医务人员学习体验,为医学人才培养和基层能力提升提供坚实的信息化支撑。
继续医学教育IT运维不仅是技术问题,更是医疗人才培养问题。通过AI技术赋能,我们可以更好地服务医务人员、支持终身学习、保障学分公平,让技术真正成为继续医学教育事业的有力助手,培养更多优秀的医学人才,提升基层医疗服务能力,为健康中国建设贡献力量。
作者简介:蓝葛亮,主要聚焦于 AI 效能研发体系规划、混合云基础架构规划以及微服务集群安全与可靠性监控体系建设。拥有 20 余年医学教育信息化建设经验,主导多个千万级继续医学教育研发与智能运维项目的总体设计与落地实施,在省级继续医学教育平台、医学会及各专科分会建设方面积累了丰富的一线实践。
长期专注于 AI 智能运维与医学教育信息化的融合创新,致力于推动继续医学教育的数字化转型和智能化升级,提升医疗人才培养质量。在 AI 效能研发体系建设、AI 安全风险防御与安全态势感知等领域持续深耕,积极探索 AI 技术在医疗教育场景中的深度应用,助力构建智能化、安全可控的医学教育新生态,推动我国医疗教育高质量发展,为“健康中国”建设贡献专业智慧与实践力量。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号