Firecrawl - 让网页数据无缝适配LLM的高效工具

Firecrawl - 让网页数据无缝适配LLM的高效工具

wangmcn
发布于 2025-11-18 09:41:43
发布于 2025-11-18 09:41:43
1、前言
在 AI 大模型时代,获取高质量、结构化的网页数据是许多开发者和企业的核心需求。Firecrawl 作为一款专注于网页数据处理的 API 服务,凭借其强大的爬取、转换与提取能力,成为连接网页内容与 LLM 应用的关键桥梁,无需复杂配置,即可快速将整站内容转化为适配 LLM 的格式。
2、简介
Firecrawl 是一项可将整站内容转换为适配 LLM 格式(如 Markdown、HTML、结构化数据、截图等)的 API 服务,支持 Scrape(单 URL 抓取)、Crawl(整站爬取)、Map(网站 URL 极速获取)、Search(全网搜索)、Extract(AI 结构化数据提取)五大核心功能。
提供托管版和自托管版两种使用方式,需注册获取 API Key 才能调用。
兼容 Python、Node 等官方 SDK 及 LangChain、LlamaIndex 等 LLM 框架,还支持通过 JSON 模式(含 pydantic 架构)或无 schema prompt 提取数据,能处理动态内容、反爬机制等棘手问题,数秒内返回结果。
核心功能:
- Scrape:单 URL 抓取,返回多格式内容(Markdown/HTML/JSON/截图等)
- Crawl:整站爬取(含子页面),支持任务状态查询与分段获取(超 10MB 分拆)
- Map:输入网站,极速获取所有 URL
- Search:全网搜索,支持指定格式(Markdown等)、来源(网页/新闻/图片)与自定义参数
- Extract:AI 提取结构化数据(支持JSON 模式/pydantic 架构、无 schema prompt)
技术特性与优势:
- LLM 就绪格式:支持输出 Markdown、摘要、结构化数据、截图、HTML、链接、元数据,直接适配LLM 应用场景。
- 棘手问题解决:内置代理、反爬 / 反机器人机制应对、动态内容(JS 渲染)处理、输出解析与任务编排能力。
- 极速性能:数秒内返回结果,专为速度和高吞吐量场景设计。
- 高可定制性:排除特定标签,精准提取所需内容;通过自定义请求头,爬取需认证的内容;设置最大爬取深度,控制爬取范围。
- 多媒体解析:支持解析 PDF、DOCX、图像等非网页格式内容。
- 交互操作支持:抓取前可执行点击、滚动、输入文本、等待(毫秒级,如 1500 毫秒)、截图等操作,适配动态内容场景。
官方网址:
https://www.firecrawl.dev/
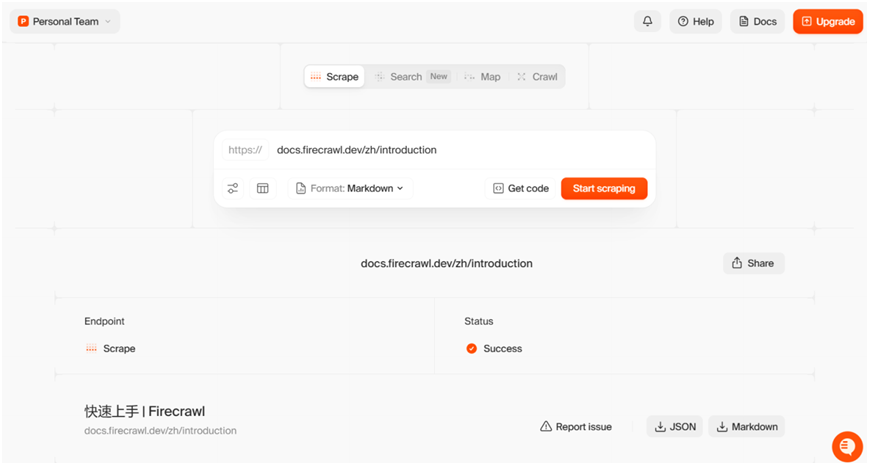
3、快速上手
使用前提:必须在 Firecrawl 注册并获取 API Key,才能调用 API 功能。
https://www.firecrawl.dev/app

使用官网的演示环境进行单 URL 抓取。
https://www.firecrawl.dev/app/playground

安装 Firecrawl 的 Python 包:
pip install firecrawl-py
1、抓取
要抓取单个 URL,使用 scrape 方法。该方法接收 URL 作为参数,并以字典形式返回抓取的数据。
from firecrawl import Firecrawl
firecrawl = Firecrawl(api_key="fc-YOUR-API-KEY")
doc = firecrawl.scrape("https://firecrawl.dev", formats=["markdown", "html"])
print(doc)2、爬取
爬取功能可让你自动发现并提取某个 URL 及其所有可访问子页面的内容。
from firecrawl import Firecrawl
firecrawl = Firecrawl(api_key=" fc-YOUR-API-KEY ")
docs = firecrawl.crawl(url="https://docs.firecrawl.dev", limit=10)
print(docs)3、JSON 模式
借助 JSON 模式,可以轻松从任意 URL 提取结构化数据。
from firecrawl import Firecrawl
from pydantic import BaseModel
app = Firecrawl(api_key="fc-YOUR-API-KEY")
class JsonSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
result = app.scrape(
'https://firecrawl.dev',
formats=[{
"type": "json",
"schema": JsonSchema
}],
only_main_content=False,
timeout=120000
)
print(result)4、搜索
Firecrawl 的搜索 API 支持你进行网页搜索,并可在一次操作中可选地抓取搜索结果。
- 选择特定输出格式(Markdown、HTML、链接、截图)
- 选择特定来源(网页、新闻、图片)
- 通过可自定义参数(如位置等)进行网页搜索
from firecrawl import Firecrawl
firecrawl = Firecrawl(api_key="fc-YOUR-API-KEY")
results = firecrawl.search(
query="Firecrawl",
limit=3,
)
print(results)5、使用操作与页面交互
Firecrawl 允许你在抓取页面内容之前在网页上执行各种操作。这对于处理动态内容、在页面间导航或访问需要用户交互的内容尤其有用。
from firecrawl import Firecrawl
firecrawl = Firecrawl(api_key="fc-YOUR-API-KEY")
doc = firecrawl.scrape(
url="https://example.com/login",
formats=["markdown"],
actions=[
{"type": "write", "text": "john@example.com"},
{"type": "press", "key": "Tab"},
{"type": "write", "text": "secret"},
{"type": "click", "selector": 'button[type="submit"]'},
{"type": "wait", "milliseconds": 1500},
{"type": "screenshot", "fullPage": True},
],
)
print(doc.markdown, doc.screenshot)本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-18,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 AllTests软件测试 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号