DeepSeek 更新:更稳、更强、更全面了



近期DeepSeek-V3.1-Terminus版本的发布,该版本在语言一致性、Agent能力等方面的显著改进。
结合近期各大AI厂商产品发布和技术路线的观察分析,可以发现一个明显的趋势:传统的"智商"、"推理能力"等指标正在让位于"工具调用"、"任务执行"、"用户体验"等更加务实的评价标准。
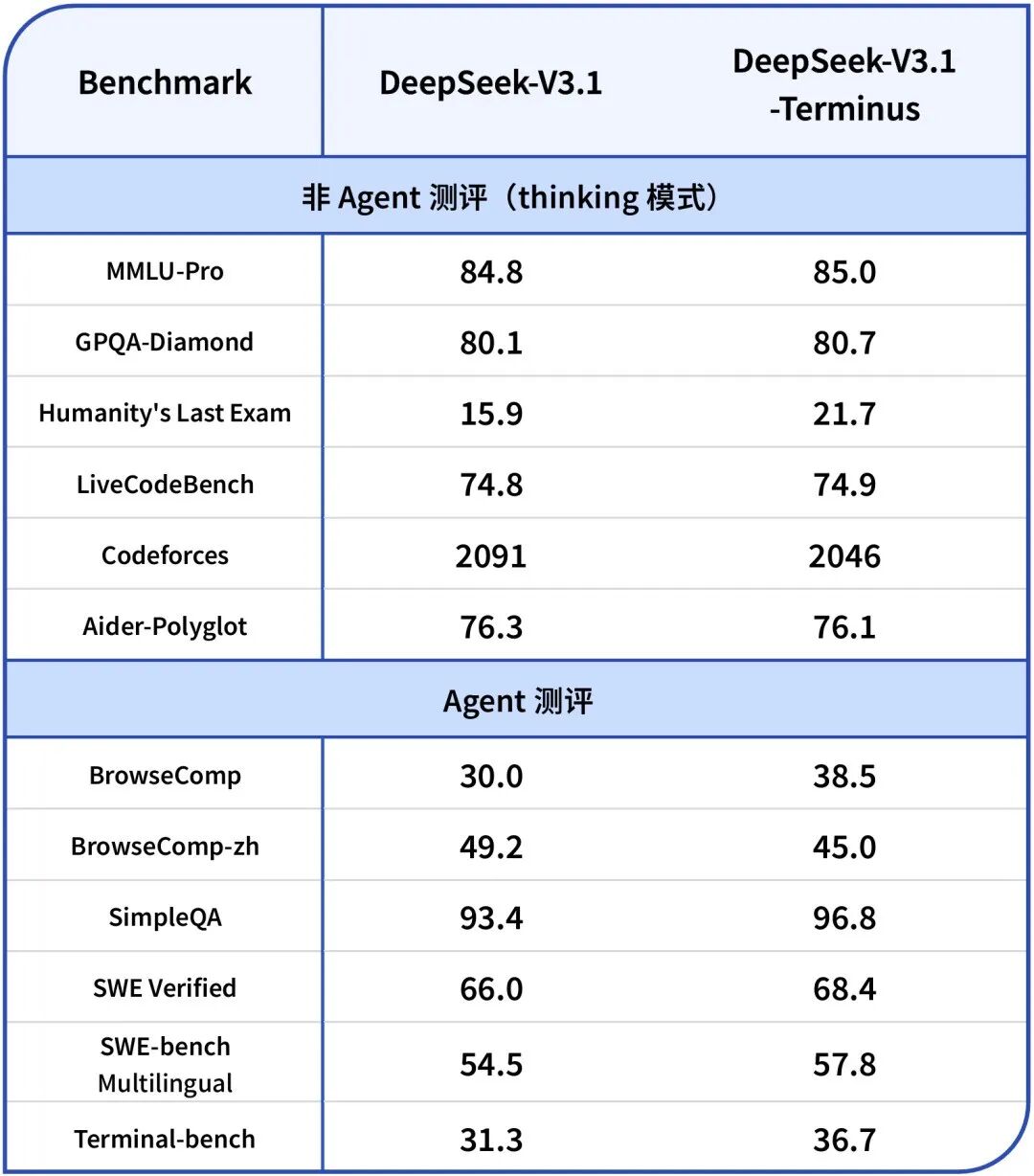
DeepSeek-V3.1-Terminus在BrowseComp任务上从30.0提升至38.5,在SWE Verified任务上从66.0提升至68.4,这些数据的改善直接反映了模型在真实应用环境中可靠性的提升。
从用户需求的演进来看,早期用户对AI系统的期望主要集中在知识问答和内容生成等基础功能上,而现在的需求已经转向更加复杂的任务执行和问题解决。这种需求变化推动了AI系统从被动的信息提供者向主动的任务执行者转变。用户不再满足于获得"看起来正确"的答案,而是需要AI系统能够真正完成具体的工作任务,并保证结果的准确性和可靠性。
从商业化的角度分析,投资者和企业客户对AI技术的价值评估标准也在发生变化。纯粹的技术演示和概念验证已经无法满足市场需求,能够在实际业务流程中创造价值的AI工具才能获得真正的商业认可。这种市场导向的变化,进一步加速了AI技术从"炫技"向"实用"的转变。
在执行力优化的具体实现上,可以观察到三个主要维度的改进。
图片
首先是输出稳定性的提升,DeepSeek-V3.1-Terminus在语言一致性方面的优化,解决了中英文混杂、异常字符等影响用户体验的问题,这种看似基础的改进实际上是AI系统从实验工具向生产工具转变的关键步骤。
其次是任务准确性的增强,在SimpleQA等评测中,新版本从93.4提升至96.8的表现,意味着在实际应用中错误率的显著降低,这对于需要高可靠性的企业应用场景具有重要意义。
最后是工具整合能力的强化,AI系统不再是孤立的智能单元,而是需要与各种外部工具、数据源和系统进行有效协同,Code Agent和Search Agent功能的优化体现了这一发展方向。
总体而言,DeepSeek-V3.1-Terminus的发布及其体现的趋势,都在说道:AI大模型正在从"智能展示"向"价值创造"开始转变。
这一转变实际效果如何...一起拭目以待吧!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号