Sentieon | 鸡全基因组(WGS)分析流程
原创
Sentieon | 鸡全基因组(WGS)分析流程
原创
INSVAST
发布于 2025-11-11 10:40:55
发布于 2025-11-11 10:40:55
今天给大家介绍的是基于 Sentieon 软件开发的用于鸡全基因组测序数据的自动化流程脚本。该流程实现了从原始测序数据(FASTQ)到变异检测结果(GVCF)以及joint calling的完整分析流程,支持多个测序平台和输出格式。
脚本支持原始测序数据(raw_fastq)、过滤后的测序数据(clean_fastq),进行质控、比对、排序、标记重复、生成质量评估指标,最终通过Haplotyper 算法进行变异检测输出 gVCF 文件,通过joint calling输出VCF文件。
测试鸡样本测序深度55.26X,从FASTQ到VCF全流程分析最快用时29.21分钟,大幅缩短了鸡的全基因组WGS分析时间,有效加快畜禽的分子育种进程。
感谢Ampere Computing LLC 和比亚迪服务器部门对本次测试的大力支持!!!
1. 环境设置与参数解析
1.1 Sentieon环境配置
1.1.1 下载地址
软件地址链接
- https://insvast-download.oss-cn-shanghai.aliyuncs.com/Sentieon/release/sentieon-genomics-202503.01.tar.gz(适配X86架构CPU服务器,例如Intel、 AMD、 曙光)
- https://insvast-download.oss-cn-shanghai.aliyuncs.com/Sentieon/release/arm-sentieon-genomics-202503.01.tar.gz(适配ARM架构CPU服务器, 例如华为鲲鹏、 阿⾥倚天、 Ampere)
模型下载链接
- https://github.com/Sentieon/sentieon-models
1.2 变量定义与参数解析
#!/bin/bash
echo $0 \$SAMPLEID \$WORKDIR \$FASTQ_1 \$FASTQ_2 \$FASTA \$SUFFIX \$DATATYPE \$KEEP_CLEAN \$KEEP_BAM \$PLOIDY
set -euxo pipefailecho:打印脚本名及输入参数占位符,方便调试时确认参数顺序。
set -euxo pipefail:设置脚本执行规则,增强健壮性。
export SAMPLEID=$1
export WORKDIR=$2
export FASTQ_1=$3
export FASTQ_2=$4
export FASTA=$5
BSUFFIX=$6
TYPE=${7:-"raw"}
KEEP_CLEAN=${8:-keep}
KEEP_BAM=${9:-keep}
PLOIDY=${10:-2}
LOGFILE=$SAMPLEID.run.log
export root=/Path/sentieon/202503/sentieon-genomics-202503/bin/从命令行读取参数,包括样本 ID、工作目录、输入文件路径等。
部分参数设置默认值。
LOGFILE:定义日志文件名(样本 ID+.run.log)。
root:sentieon工具(基因组分析软件)的安装路径。
更详细的参数表格,如下表所示:
参数 | 含义 | 默认值 | |
|---|---|---|---|
$1 | SAMPLEID | 样本ID | |
$2 | WORKDIR | 工作目录 | |
$3 | FASTQ_1 | FASTQ R1文件 | |
$4 | FASTQ_2 | FASTQ R2文件 | |
$5 | FASTA | 参考基因组 fasta 文件 | |
$6 | BSUFFIX | 输出格式:bam/cram/空格 | 无默认 |
$7 | TYPE | 数据类型:"raw" 或 "clean" | "raw" |
$8 | KEEP_CLEAN | 是否保留质控后的 fastq | "keep" |
$9 | KEEP_BAM | 是否保留去重后的 bam/cram | "keep" |
$10 | PLOIDY | 样本倍性(根据实际调整) | 2 |
1.3 输入文件有效性检查
if [ "$BSUFFIX" = "bam" ] || [ "$BSUFFIX" = "cram" ] || [ "$BSUFFIX" = " " ]; then
echo "$BSUFFIX check"
else
die "Error: check 6th blank, BSUFFIX must be 'bam' or 'cram' or space"
fi检查BSUFFIX,只能是bam(二进制比对格式)、cram(压缩比对格式)或空格,否则报错退出。
1.4 测序平台判断
if [ -e $LOGFILE ];then
export PLATFORM=$(awk '/Platform/{print $NF;exit}'$LOGFILE)
else
export count=$(zcat $FASTQ_1|head -n 1|awk '{print NF}')
if [ $count -eq 1 ];then
export PLATFORM="DNBSEQ"
elif [ $count == 2 ];then
export PLATFORM="ILLUMINA"
elif [ $count == 3 ];then
export PLATFORM="ILLUMINA"
else
echo"Unrecognized platform"
export PLATFORM="ILLUMINA"
fi
fi若日志文件已存在,从日志中提取测序平台(Platform字段)。
若日志不存在,通过 FASTQ 文件首行的字段数判断平台。
1.5 输出文件格式确定
FAI=$FASTA.fai
if [ "$BSUFFIX" = "bam" ] || [ "$BSUFFIX" = "cram" ];then
export SUFFIX=$(awk -v preset=$BSUFFIX 'BEGIN{max=0}{if($2>max)max=$2}END{if(max>536870911){print "cram"}else{print preset}}' $FAI)
else
export SUFFIX=$(awk 'BEGIN{max=0}{if($2>max)max=$2}END{if(max>536870911){print "cram"}else{print "bam"}}' $FAI)
fi根据参考基因组索引文件($FASTA.fai)中最长序列的长度决定输出比对文件格式:
- 若最长序列长度 > 536870911(约 512MB),强制使用cram(更适合大基因组压缩)。
- 否则根据BSUFFIX或默认bam。
补充说明:对于单个染色体长度 > 536870911(约 512MB)的物种,Sentieon软件可以切换至cram,不用因BAM 文件索引 (.bai) 的格式限制切割染色体。
1.6 环境与目录配置
export TMPDIR=$WORKDIR
export THREADS=$(nproc)
[ -e $WORKDIR ]||mkdir -p $WORKDIR
cd $WORKDIR
exec >>$LOGFILE 2>&1
echo "SampleID:" $SAMPLEID
echo "DataType:" $TYPE
……配置临时目录、线程数,确保工作目录存在,并将所有输出写入日志文件。
1.7 设置计时函数(可选)
timer(){
start_time=$(date +%s)
eval $2 && touch $3
end_time=$(date +%s)
cost_time=$[ $end_time-$start_time ]
echo -e "TIMER: $1\t$(($cost_time/60)) min $(($cost_time%60)) s"
}用于记录每个分析步骤的开始/结束时间、耗时,并通过创建标记文件(如qc.ok)标记步骤完成,避免重复执行。
2. 数据质控(Raw2clean)
- 双端测序质控脚本:
raw2clean(){
cmd="fastp -w 16 -i $FASTQ_1 -I $FASTQ_2 -o $clean1 -O $clean2 -j $SAMPLEID.qc.json -h $SAMPLEID.qc.html&&rm $FASTQ_1 $FASTQ_2"
timer raw2clean "$cmd" qc.ok
}- 单端测序质控脚本:
raw2clean(){
cmd="fastp -w 16 -i $FASTQ_1 -o $clean1 -j $SAMPLEID.qc.json -h $SAMPLEID.qc.html&&rm $FASTQ_1"
timer raw2clean "$cmd" qc.ok
}使用fastp工具对原始 FASTQ 数据进行质控(过滤低质量 reads、接头等),输出过滤后的 FASTQ 文件及质控报告文件(JSON/HTML)。
成功后创建qc.ok标记文件。
3. 序列比对与排序(Alignment)
- 双端测序比对脚本:
alignment(){
tag="@RG\tID:rg_$SAMPLEID\tSM:$SAMPLEID\tPL:$PLATFORM"
cmd="sentieon bwa mem -R \"$tag\" -t $THREADS -K 10000000 -x $ML_MODEL/bwa.model $FASTA $clean1 $clean2|sentieon util sort --temp_dir $TMPDIR -r $FASTA -o $SAMPLEID.sorted.$SUFFIX -t $THREADS --sam2bam -i -"
echo $cmd
timer alignment "$cmd" align.ok
}- 单端测序比对脚本:
alignment(){
tag="@RG\tID:rg_$SAMPLEID\tSM:$SAMPLEID\tPL:$PLATFORM"
cmd="$root/sentieon bwa mem -R \"$tag\" -t $THREADS -K 10000000 $FASTA -x $ML_MODEL/bwa.model $clean1 |$root/sentieon util sort --temp_dir $TMPDIR -r $FASTA -o $SAMPLEID.sorted.$SUFFIX -t $THREADS --sam2bam -i -"
echo $cmd
timer alignment "$cmd" align.ok
}使用sentieon bwa mem进行序列比对(基于BWA算法),添加Read Group信息(用于后续变异分析),并通过sentieon util sort对结果排序,输出sorted.bam或sorted.cram。
基于测序平台选择不同的机器学习模型($ML_MODEL)优化比对。
成功后创建align.ok标记文件。
4. 生成质量评估指标(Metrics)
metrics(){
cmd="sentieon driver --temp_dir $TMPDIR -r $FASTA -t $THREADS -i $SAMPLEID.sorted.$SUFFIX --algo WgsMetricsAlgo $SAMPLEID.WGS_METRICS.txt --algo MeanQualityByCycle $SAMPLEID.mq_metrics.txt --algo QualDistribution $SAMPLEID.qd_metrics.txt --algo GCBias --summary $SAMPLEID.gc_summary.txt $SAMPLEID.gc_metrics.txt --algo AlignmentStat $SAMPLEID.aln_metrics.txt --algo BaseDistributionByCycle $SAMPLEID.bd_metrics.txt --algo QualityYield $SAMPLEID.qy_metrics.txt --algo InsertSizeMetricAlgo $SAMPLEID.is_metrics.txt"
timer metrics "$cmd" metrics.ok
}使用sentieon driver计算多种测序质量指标,包括:
- 全基因组测序指标(WgsMetricsAlgo)。
- 碱基质量分布、GC 偏差、插入片段长度等。
结果输出到多个质量指标的.txt文件,成功后创建metrics.ok。
5. 标记重复序列(Dedup)
dedup(){
cmd="sentieon driver -r $FASTA --temp_dir $TMPDIR -t $THREADS -i $SAMPLEID.sorted.$SUFFIX --algo LocusCollector --fun score_info $SAMPLEID.score.txt&&sentieon driver -r $FASTA -t $THREADS -i $SAMPLEID.sorted.$SUFFIX --algo Dedup --score_info $SAMPLEID.score.txt --metrics $SAMPLEID.dedup_metrics.txt $SAMPLEID.deduped.$SUFFIX&&rm $SAMPLEID.sorted.$SUFFIX* $SAMPLEID.score.txt*"
timer markdup "$cmd" markdup.ok
}标记重复序列分两步:
LocusCollector:收集位点质量分数信息。Dedup:基于分数标记并去除 PCR 重复序列。
完成后删除中间文件(排序后的比对文件),创建markdup.ok。
6. 碱基质量重校正(BQSR可选)
bqsr(){
sentieon driver -t $THREADS -r $FASTA -i $SAMPLEID.deduped.$SUFFIX --algo QualCal -k $KNOWN_SITES $SAMPLEID.RECAL_DATA.TABLE
sentieon driver -t $THREADS -r $FASTA -i $SAMPLEID.deduped.$SUFFIX -q $SAMPLEID.RECAL_DATA.TABLE --algo QualCal -k $KNOWN_SITES $SAMPLEID.RECAL_DATA.TABLE.POST --algo ReadWriter $SAMPLEID.deduped.RECALIBRATED.$SUFFIX
timer markdup "$cmd" markdup.ok
}- 此过程分为两个主要部分:首先创建一个校正模型(生成 .TABLE 文件),然后应用该模型生成报告和碱基质量重校正后的bam。
--algo QualCal: 指定运行的算法是 QualCal(质量校正算法)。KNOWN_SITES:已知变异数据库的VCF文件路径。RECAL_DATA.TABLE:重校准表的位置和文件名。RECAL_DATA.TABLE.POST: 临时性的后重校准表的位置和文件名。--algo ReadWriter:这一步为可选的。Sentieon® 变异检测可以在运行时使用校正前的 BAM 加上重校准表来即时执行重校正。便可以不输出巨大的BAM文件,节省磁盘的空间。- 若选择执行这一步,第七部分变异检测中请将
$SAMPLEID.deduped.RECALIBRATED.$SUFFIX设为输入文件。
7. 变异检测(DNAseq)
dnaseq(){
cmd="sentieon driver --temp_dir $TMPDIR -r $FASTA -t $THREADS -i $SAMPLEID.deduped.$SUFFIX --algo Haplotyper --emit_conf=30 --call_conf=30 --emit_mode gvcf --ploidy $PLOIDY $SAMPLEID.hc.gvcf.gz && md5sum $SAMPLEID.hc.gvcf.gz > $SAMPLEID.hc.gvcf.gz.md5"
timer Haplotyper "$cmd" hc.ok
}使用Haplotyper算法进行单倍型分析,生成 GVCF 文件。
计算 GVCF 文件的 MD5 ,确保文件完整性,成功后创建hc.ok。
8. Joint Calling
8.1 参数检查与使用说明
#!/bin/bash
[ $# -eq 0 ]&&echo Usage: $(basename $0) \$FASTA \$GVCF_LIST \$NUM \$DATADIR&&exit
start_time=$(date +%s)如果脚本没有传入任何参数,则打印使用说明并退出。
使用方式:脚本名 FASTA文件 GVCF列表文件 NUM 数据目录。
记录脚本开始执行的时间。
8.2 设置错误处理
set -euo pipefail-e: 任何命令失败则退出脚本。
-u: 使用未定义的变量时报错。
-o pipefail: 管道中任何一个命令失败则整个管道失败。
8.3 参数赋值
DATADIR=$4
FASTA=$1 #"$FASTA_DIR/genomeEN_split.fa"
GVCF_LIST=$2
NUM=$3$1: 参考基因组 FASTA 文件路径。
$2: 包含所有样本 GVCF 文件路径的列表文件。
$3: 用于命名输出文件的数字标识(如批次号)。
$4: 数据目录,用于存放输出文件。
8.4 设置线程数、工作目录和日志文件
NT=$(nproc) #number of threads to use in computation, set to number of cores in the server
WORKDIR="$DATADIR/JointCall-${NUM}"
[ -e $WORKDIR ]||mkdir -p $WORKDIR
#[ -e $file ]&&exit 0
cd $WORKDIR
LOGFILE=$WORKDIR/joint-call${NUM}_run.log
exec >$LOGFILE 2>&1NT: 获取当前系统的 CPU 核心数。
WORKDIR: 根据 NUM 创建唯一的工作目录。
如果目录不存在则创建,并进入该目录。
将所有标准输出和标准错误重定向到日志文件。
8.5 执行联合变异检测
root=/APP/u22/x86_com/sentieon/202503/sentieon-genomics-202503
cat $GVCF_LIST|$root/bin/sentieon driver -r $FASTA --algo GVCFtyper \
$WORKDIR/output${NUM}-jc.vcf.gz - || { echo echo "GVCFtyper failed"; exit 1; }cat $GVCF_LIST: 读取 GVCF 文件列表。
sentieon driver: 调用 Sentieon 驱动程序。
-r $FASTA: 指定参考基因组。
--algo GVCFtyper: 使用 GVCFtyper 算法进行联合变异检测。
output${NUM}-jc.vcf.gz: 输出的压缩 VCF 文件。
如果命令失败,输出错误信息并退出。
8.6 计算并输出运行时间(可选)
end_time=$(date +%s)
cost_time=$[ $end_time-$start_time ]
echo "joint calling time is $(($cost_time/60))min $(($cost_time%60))s"
echo "the Joint-calling done at `date +%H:%M:%S` !!!"计算脚本运行的总时间,并以“分:秒”格式输出。最后输出完成时间。
9. 总结
该脚本实现了 DNA 测序数据从原始 FASTQ 到 GVCF 的全自动化分析流程,支持 Illumina/DNBSEQ 平台,可配置输出格式(BAM/CRAM)和中间文件保留策略,通过标记文件和日志确保流程可进行追溯,适用于大规模基因组变异检测场景。特点包括:
- 参数化:通过命令行参数灵活控制输入、输出和流程选项。
- 自动化:自动检测测序平台和参考基因组以决定最佳分析策略。
- 稳健性:使用 set -euxo pipefail和标记文件实现错误处理和断点续跑。
- 模块化:将每个分析步骤封装成函数。
- 高效性:使用商业优化的sentieon工具替代金标准GATK/BWA,速度更快。
- 可追溯性:详细的日志记录和 MD5 校验确保结果可重现。
要运行此脚本,需要预先安装好 sentieon、fastp等软件,并准备好对应的模型文件 bundle。
10. 脚本应用示例
使用上述脚本对鸡全基因组测序数据分析的测序结果,具体样本信息如下表所示:
类别 | 详情 |
|---|---|
物种ID | Gallus_gallus |
物种名和倍性 | 鸡(二倍体) |
参考基因组 | GCF_016699485.2_bGalGal1.mat.broiler.GRCg7b_genomic.fna |
参考基因组大小(G) | 1.07 |
测试数据来源 | 自有数据 |
系统版本 | Ubuntu 24.04/Kernel 6.8 |
cpu型号 | AmpereOne A192-32X |
分析软件 | sentieon-genomics-202503 |
raw_reads | 395785930 |
raw_data(G) | 59.13 |
测序深度(X) | 55.26 |
数据下载
参考基因组下载:
方法一
wget -c
https://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/016/699/485/GCF_016699485.2_bGalGal1.mat.broiler.GRCg7b/GCF_016699485.2_bGalGal1.mat.broiler.GRCg7b_genomic.fna.gz方法二
curl -C - -O --progress-bar
https://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/016/699/485/GCF_016699485.2_bGalGal1.mat.broiler.GRCg7b/GCF_016699485.2_bGalGal1.mat.broiler.GRCg7b_genomic.fna.gz解压:
gunzip GCF_016699485.2_bGalGal1.mat.broiler.GRCg7b_genomic.fna.gz - 测试硬件配置
- CPU为单颗AmpereOne A192-32X
- 内存为512GB DDR5
- 系统为Ubuntu 24.04/Kernel 6.8
- 测试结果
使用本文流程对鸡全基因组测序数据进行变异检测分析,下表为不同CPU核数下的计算时间和资源调用情况:
128核 | 96核 | 64核 | 32核 | 16核 | |
|---|---|---|---|---|---|
比对时间(min) | 22.72 | 21.51 | 27.28 | 56.15 | 119.37 |
比对内存峰值(G) | 49.44 | 43.61 | 47.64 | 52.43 | 51.02 |
度量指标内存时间(min) | 1.25 | 1.40 | 1.90 | 3.49 | 6.68 |
度量指标内存(G) | 3.46 | 3.13 | 3.08 | 2.70 | 1.26 |
去重时间(min) | 1.04 | 1.28 | 1.27 | 2.42 | 4.22 |
去重内存(G) | 12.26 | 7.38 | 4.43 | 2.29 | 1.75 |
变异检测时间(min) | 4.20 | 5.71 | 8.57 | 14.58 | 31.82 |
变异检测内存(G) | 12.61 | 9.18 | 6.89 | 3.99 | 2.74 |
总时间(min) | 29.21 | 29.90 | 39.02 | 76.64 | 162.08 |
本次测试在不同的线程数上进行性能的比较。从数据中可以明显看出,随着线程数的增加,变异检测的整体效率显著提升。从FastQ到VCF全流程分析最快用时29.21分钟,大幅缩短了鸡的全基因组WGS分析时间,有效加快畜禽的分子育种进程。
Sentieon在不断地优化算法的运行效率,为科研工作者提供更快速、更经济的基因检测方案。若您刚好有需要检测的数据,不妨来申请试用Sentieon吧!
Sentieon软件介绍
Sentieon为完整的纯软件基因变异检测二级分析方案,其分析流程完全忠于BWA、GATK、MuTect2、STAR、Minimap2、Fgbio、picard等金标准的数学模型。在匹配开源流程分析结果的前提下,大幅提升WGS、WES、Panel、UMI、ctDNA、RNA等测序数据的分析效率和检出精度,并匹配目前全部第二代、三代测序平台。
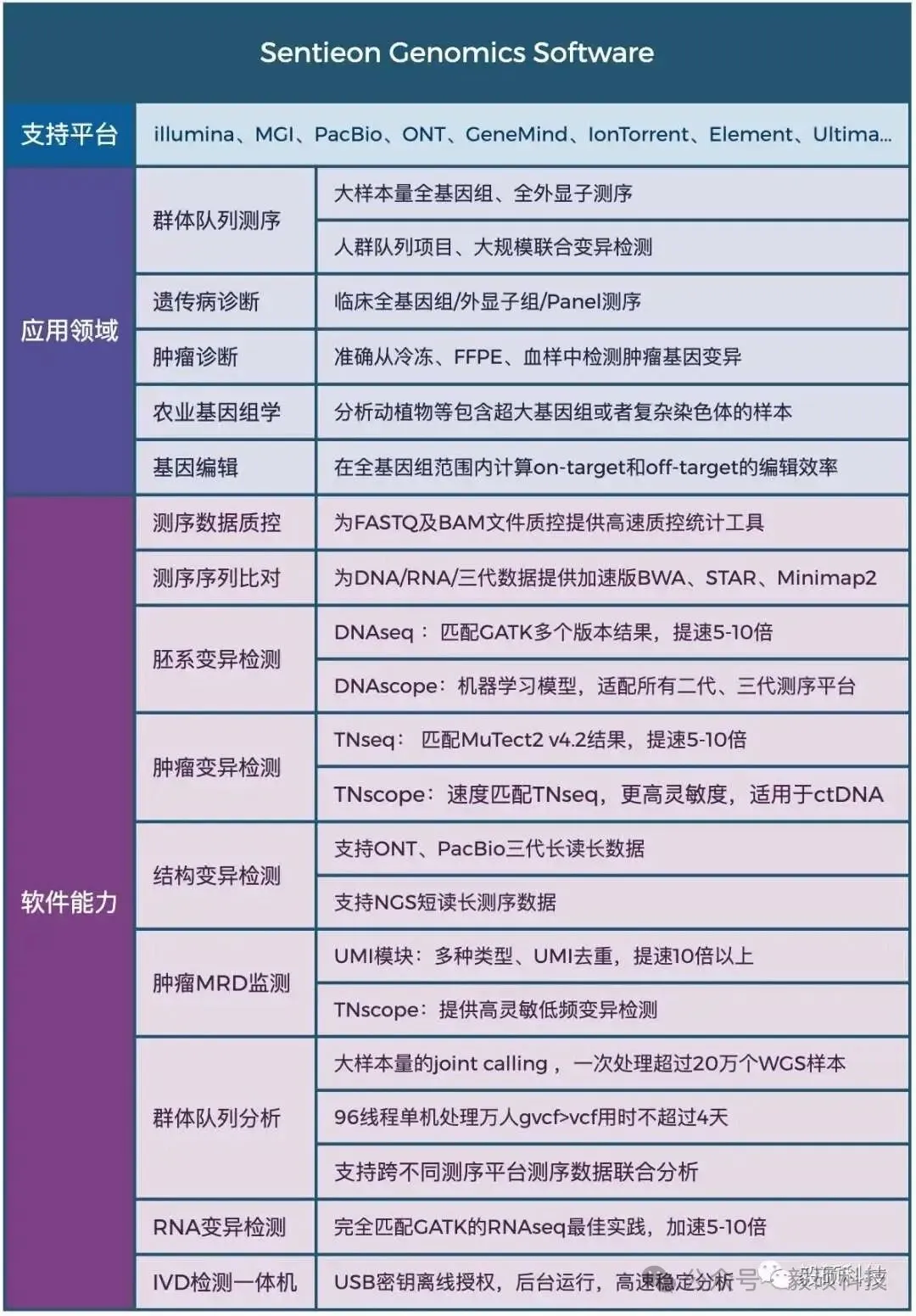
图片
Sentieon软件团队拥有丰富的软件开发及算法优化工程经验,致力于解决生物数据分析中的速度与准确度瓶颈,为来自于分子诊断、药物研发、临床医疗、人群队列、动植物等多个领域的合作伙伴提供高效精准的软件解决方案,共同推动基因技术的发展。
截至2025年7月份,Sentieon已经在全球范围内为1860+用户提供服务,用户处理超过4980+PB数据量,被世界一级影响因子刊物如NEJM、Cell、Nature等广泛引用,引用次数超过1500篇。此外,Sentieon连续数年摘得了Precision FDA、Dream Challenges等多个权威评比的桂冠,在业内获得广泛认可。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号