「腾讯云NoSQL」技术之Redis篇:精准围剿rehash时延毛刺实践方案揭秘

「腾讯云NoSQL」技术之Redis篇:精准围剿rehash时延毛刺实践方案揭秘

腾讯云数据库 TencentDB
发布于 2025-10-31 11:26:27
发布于 2025-10-31 11:26:27
在互联网时代,数据存储与访问的效率直接决定着用户体验的好坏。Redis作为当今最流行的内存数据库之一,凭借其出色的性能表现,已成为支撑亿万用户在线服务的核心基础设施。然而,随着业务规模的快速增长,Redis内部的rehash机制却可能在关键时刻引发严重的时延毛刺,导致整个系统性能急剧下降,甚至引发大规模的服务故障。如何精准识别并有效解决rehash带来的性能问题,已成为云Redis产品必须面对的重要挑战。本文将通过一个真实的线上故障案例,深入剖析rehash机制的工作原理及其对时延的影响,并详细介绍腾讯云NoSQL团队针对这一问题的体系化优化实践。
作者:李鸿瑞、朱彬彬
一、 故障“案发现场”:一次惊心动魄的线上事故
这是一个寒冷的冬夜,你拖着疲惫的身躯回到家中,盛满一杯热牛奶,躺在松软的沙发上。“终于到周末啦!”,你一边庆祝着,一边郑重地打开了你最爱的娱乐软件,准备狠狠happy一波。但天有不测风云,平时能轻松登录的应用软件,今天竟然显示“登录失败”。你以为是网络问题,于是熟练地刷新页面、切换网络,但那个刺眼的提示依旧顽固地占据着屏幕,直到各种方法用尽,却依然无法登录后,你恍然大悟——应用服务崩了!

对于腾讯云NoSQL团队的工程师们来说,这个不平静的夜晚,始于监控屏幕上一条急剧拉升的曲线。这条曲线对应着负责该应用软件身份校验服务的云Redis集群——一个存储着海量用户登录凭证的关键系统。监控图上,P99延迟从稳如磐石的18ms飙升至390ms,暴涨超过20倍,平均延迟也翻了个倍!相应地,身份校验服务的成功率骤降,毫不知情的用户面对着无法登录的应用,下意识地刷新、重试。这股巨大的“重试风暴”带来了海量的建连请求,如潮水般涌向同一个Redis分片,瞬间将其CPU打满,服务近乎瘫痪。
在紧张的故障原因调查中,一个关键线索浮出水面:业务的key总量在短短半个多月内暴涨4倍。而发生故障的那天,故障分片的key数量不多不少,正好增长到了6710万,这与2的26次方十分接近。我们将时延激增的时间点与key数量增长曲线一对齐,揪出了这次事故的“幕后黑手”——Redis的rehash机制。
二、 揭秘“真凶”:rehash为何会引发时延毛刺?
在介绍rehash如何引发时延上升之前,我们需要先了解Redis rehash的基本原理。接下来,我们从Redis的基本数据结构——字典(dict)开始说起。
2.1 dict数据结构
dict的数据结构如图一所示。在Redis这样的key-value数据库中,数据都是以key-value这样的键值对形式存储的,而dict则是存储键值对的核心数据结构。dict由两个哈希表组成,在普通状态下,dict只使用table0,table1为空。当用户写入一对key-value时,Redis首先会计算key的hash值,将key-value存入hash值对应的哈希桶里。每个哈希桶都是一个链表,新来的key-value对会插入到链表的头部。以图一为例,当写入k3-v3时,Redis首先计算出k3的hash值为2,然后将k3-v3插入到2号哈希桶的链表头部。
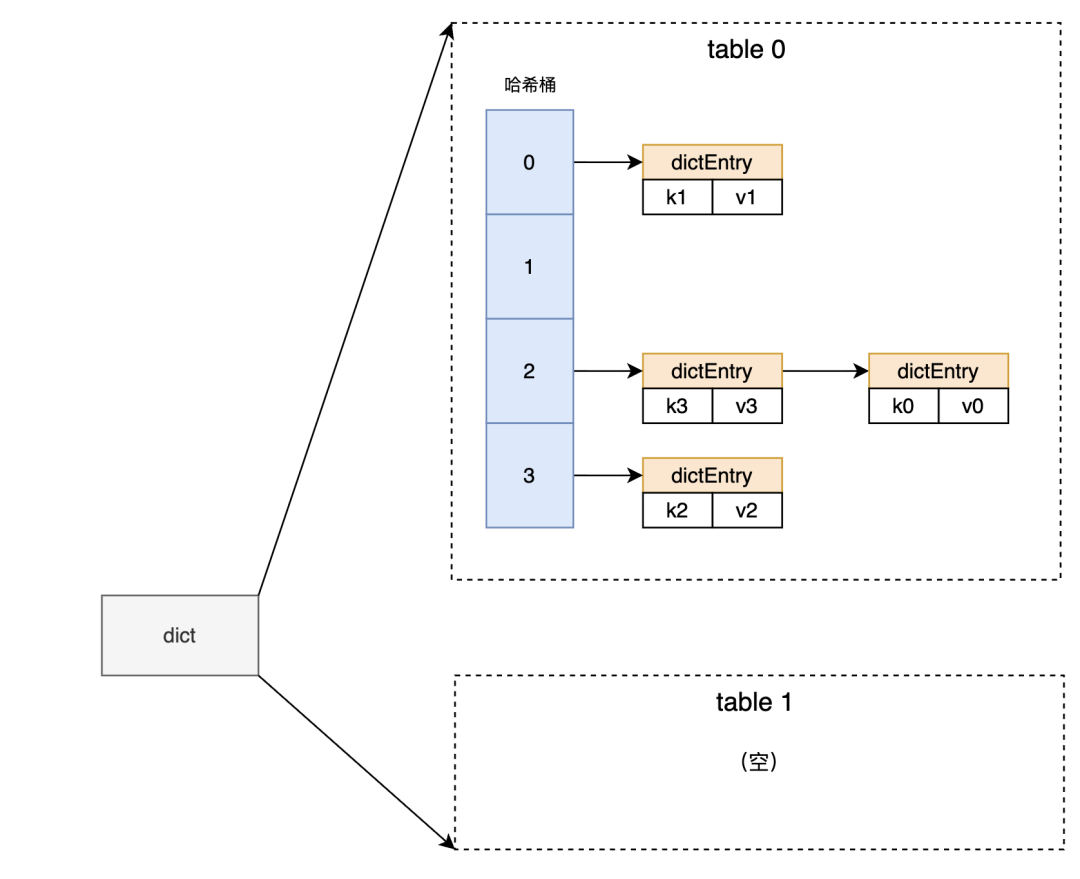
图1 dict数据结构示意图
在写数据时,数据是直接写到链表头部的,因此写数据的时间复杂度可以稳定在O(1),但读数据就没有这么幸运了。当一个哈希桶里有多对key-value时,Redis会从链表头部开始遍历,依次比较每个链表节点的key与目标key是否一致:如果不一致,则比较下一个节点;如果一致,则返回该节点的value。
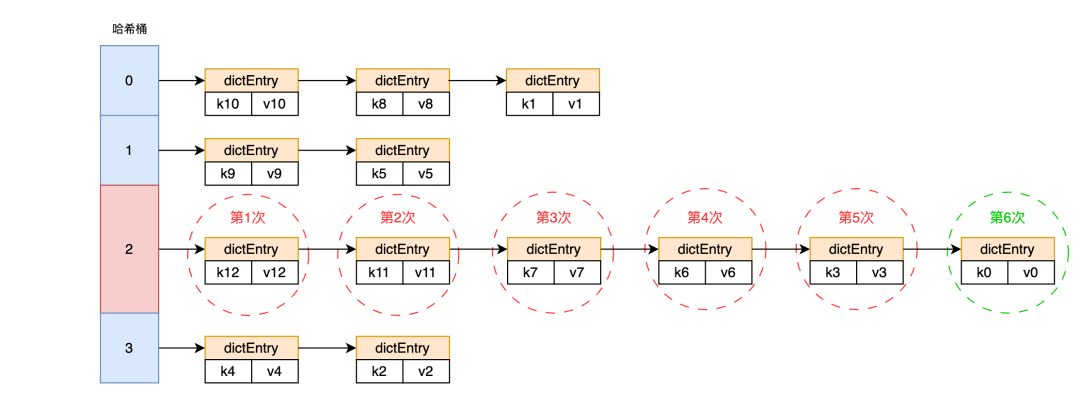
图2 过长的哈希桶链表导致读性能下降
不难想到,这样的读取方式会带来下述问题:如果哈希桶中的key-value对太多,并且我们要查询的key非常不幸地位于链表尾部,那么我们就不得不遍历链表的所有节点才能读取到目标value,本次查询就会偏慢。如图二所示,如果用户执行“GET k0”命令,那么它需要进行6次比较才能完成查询。可以想象,如果哈希表永远只有4个桶,元素个数为N,那么每个桶的平均key-value对数量为N/4,每次查询平均需要做N/8次比较。在数据量N很大时,这样的查询性能是无法接受的。如何解决以上问题呢?很简单,给哈希表分配更多的哈希桶就行了。
2.2 dict的扩容与rehash
在上一小节我们得知,当dict中的数据量较大时,为了避免读性能下降,应该给哈希表分配更多的哈希桶,这就是dict的扩容。怎样决定何时扩容呢?接着上一节的分析,记哈希表中的实际元素个数为N,哈希表的桶数为M,那么每个桶的平均链表长度为N/M。平均链表长度直接影响哈希表的读取性能,因此Redis把N/M作为决定dict何时扩容的指标,并将其称为“负载因子”(load factor)。当负载因子大于1时,dict就决定进行扩容。
扩容的时机定好了,那么扩容的大小怎么定呢?首先,Redis中dict哈希表的桶数都是2的整数次幂(初始为4)。每次扩容时,新表的桶数是“第一个大于或等于当前元素个数两倍的2的整数次幂”。例如当前哈希表的桶数为4,元素个数为4,那么再写入一个新key时,负载因子大于1,会触发扩容,扩容出的新表大小是第一个大于或等于5的2的整数次幂,也就是8。
dict扩容的机制使得当key的数量增长至2的整数次幂时,dict就会进行扩容。还记得我们在文章开头提到的定位问题的关键线索——“故障分片的key数量不多不少,正好增长到了约2的26次方”吗?现在我们便明白了,这个数字说明故障分片在当时正好进行了一次扩容,将问题指向了扩容后续的rehash。
扩容的大小也定好了,那么新表在哪里分配呢?诶,还记得第一章节图一中空出来的table 1吗?它就是新表分配的地点。
最后,将新表分配出来后,还需要将旧表的元素搬到新表中,新表才能正式生效。将元素从旧表搬迁到新表的过程就是本文的主角——rehash。当元素数量较多时,rehash是一个耗时较大的任务,但Redis的运行又是单线程的,如果等到rehash完成后才执行下一步指令,那么用户的读写等请求会长时间得不到响应,这肯定是不能接受的。对此,Redis的解决方案是渐进式rehash。
想象你是一个管理大师,正在经营一家图书馆。随着图书馆的书籍(键值对)越来越多,馆内的书架(哈希桶)变得十分拥挤,顾客们需要找很久才能在书架上找到自己想看的书(查询请求处理缓慢)。深知“用户为本”理念的你为了解决顾客的痛点,决定新建一个更大的图书馆。新馆建造完毕后,你还需要把旧图书馆的大量书籍搬到新馆(rehash)。粗暴的方式是闭馆一周,搬完所有书籍后再开放,但这势必会影响顾客体验,等到书搬完后,黄花菜都凉了。但聪明的你立马想到了一个更好的方式:新图书馆和旧图书馆同时保持开放,在此期间,所有新到的书籍都直接放入新馆,而查找书籍时则会先看旧馆,再看新馆,以确保万无一失。在图书馆开放期间,也要时不时把书从旧馆搬往新馆,当所有书都转移完毕后,关闭旧馆。
Redis的渐进式rehash就是遵循这样的思路。table 1分配出来后,同时使用table 0和table 1两个哈希表。新写入的数据直接写入table 1,查询数据则会先查询table 0,再查询table 1。在此期间将元素渐进式地从table 0转移到table 1,转移完毕后释放掉空的table 0,然后将table 1设置为新的table 0。
综上所述,可以把哈希表扩容的全流程总结为以下几个步骤:
(1)初始dict如图三所示,此时dict的负载因子已经为1,扩容一触即发。
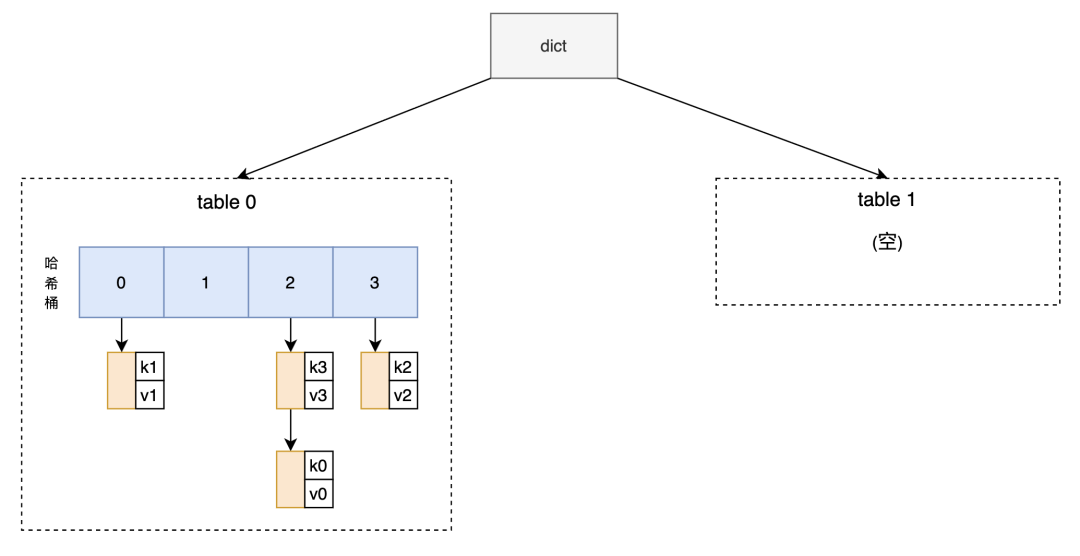
图3 即将扩容的dict
(2)用户写入新的元素k4-v4,导致负载因子大于1,扩容触发。dict在table1中创建新表,分配8个哈希桶,新到来的k4-v4直接写到table1中。如图四所示。
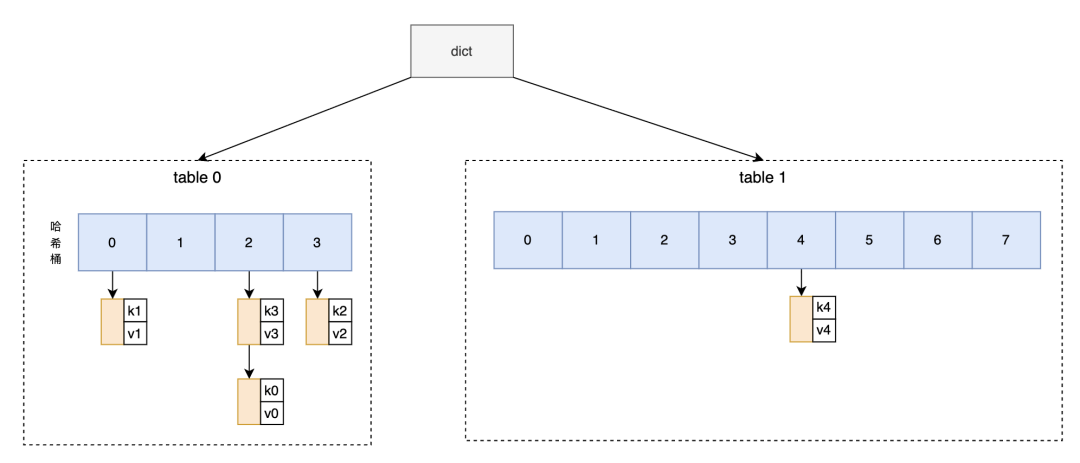
图4 分配新表
(3)开始渐进式rehash。逐渐将元素从table0搬迁到table1,期间正常处理读写请求。图五显示的是搬迁全部完成的场景,rehash期间用户还写入了新数据k5-v5,被直接插入到了table1中。
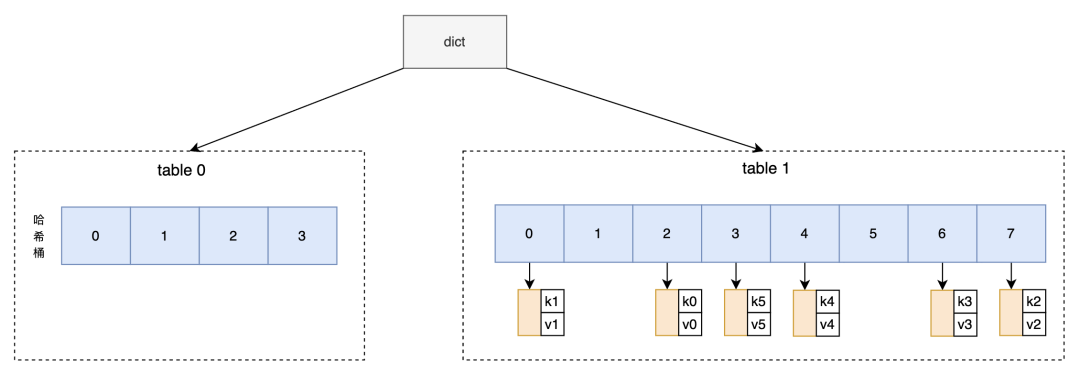
图5 rehash完成
(4)rehash完成后释放table0,把释放后的table0和拥有完整数据的table1交换一下(可以理解为交换名字),扩容完成。扩容完成后的dict如图六所示。
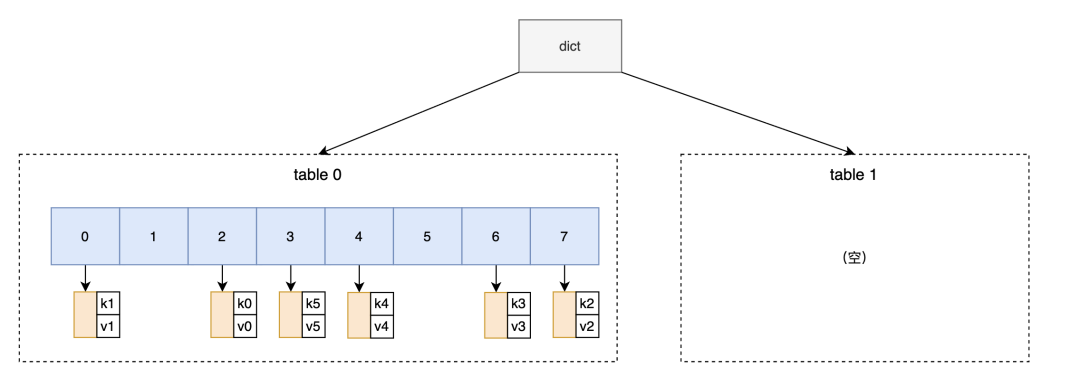
图6 释放旧表
这里做一些补充说明:Redisrehash的最小单位是一个哈希桶,一次rehash至少会把一个哈希桶里的所有元素全部搬到新表。Redis的dict维护了一个索引计数器变量rehashidx,用于记录渐进式rehash进行到了哪个位置,或者说rehashidx就是下一个要被迁移的桶的桶号。rehashidx从0开始,每次搬完一个桶后就加1。如图七所示,table0中的0号桶最先被迁移;1号桶是空桶,被跳过;目前rehash进行到了2号桶,在下一次迁移时,2号桶中的两个元素都会被迁移。
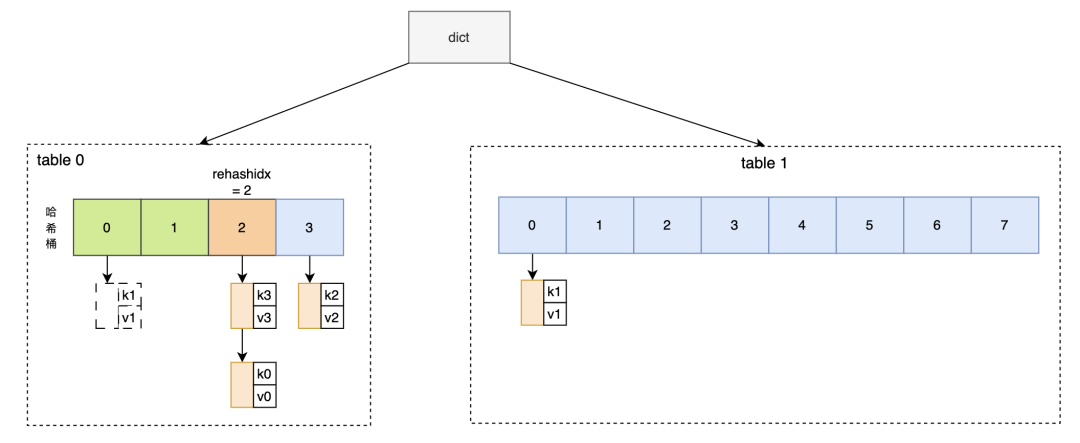
图7 单步rehash过程
2.3 渐进式rehash的进行方式
在上一小节中,我们讲到Redis的rehash不是一次性完成的,而是在正常处理读写请求时渐进完成。那么Redis具体是如何把元素从旧表搬到新表的呢?本小节将会回答这个问题。
Redis的渐进式rehash分为被动rehash和主动rehash两种方式。
2.3.1被动rehash
在rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作外,还会顺带进行单步rehash,将table0在rehashidx索引上的所有元素rehash到table1(只搬一个桶)。被动rehash巧妙地化整为零,将一个大的整体rehash分摊到多个增删查改操作上,从而避免了一次性rehash的庞大工作量。
2.3.2主动rehash
了解了被动rehash之后,我们会想,如果Redis太空闲了,长时间都没有收到增删查改的请求,那么rehash岂不是就停滞了吗?这时候就要靠主动rehash了。Redis设置了一个服务器定时任务serverCron,它会在Redis运行期间周期性执行,每次serverCron执行都会分配出1ms的时间片专门用于字典rehash。
被动和主动两种rehash方式的结合,使得整个字典的rehash是分摊到每一次对字典的读写请求中,并且在被动模式低效时(客户端读写请求少)也可以通过主动rehash最终将字典rehash完成。
2.4 Rehash对时延的影响
通过前面的分析,我们已经了解了Redis rehash的基本原理和执行方式。现在让我们回到文章开头那个惊心动魄的故障现场:P99延迟从18ms暴涨到390ms,平均延迟翻倍,海量用户无法正常使用服务。究竟是rehash过程中的哪些环节导致了如此严重的时延毛刺?让我们深入剖析rehash过程中的三个时延"杀手"。
2.4.1 被动rehash的影响
还记得被动rehash的工作原理吗?每当用户执行一次增删查改操作时,Redis不仅要完成用户请求的操作,还要"顺便"搬迁一个哈希桶的数据。这就像你去图书馆,本来只是借个书,但工作人员说:"顺便帮我们把这个书架上的书搬到我们的新馆去吧。"
这种"顺便"的代价可不小。被动rehash虽然将迁移成本分摊到每个用户请求中,但也意味着用户的每一次读写请求都会被强行增加一个额外的rehash步骤。在高QPS下,这会显著拉低系统整体的吞吐量和性能表现。正如在文章开头提到的线上事故中,Redis分片的平均时延翻倍,这其中就离不开被动rehash的“贡献”。
更糟糕的是,如果某个哈希桶中恰好存储了大量的key-value对,那么搬迁这个桶就需要花费更长的时间。如图八所示,图中的rehash正进行到了一个元素数量很多的桶,此时恰好有一个用户向Redis发送了读请求,该请求必须等待rehashidx指向的桶中所有元素完成迁移后才能继续执行,从而导致响应延迟显著增加。
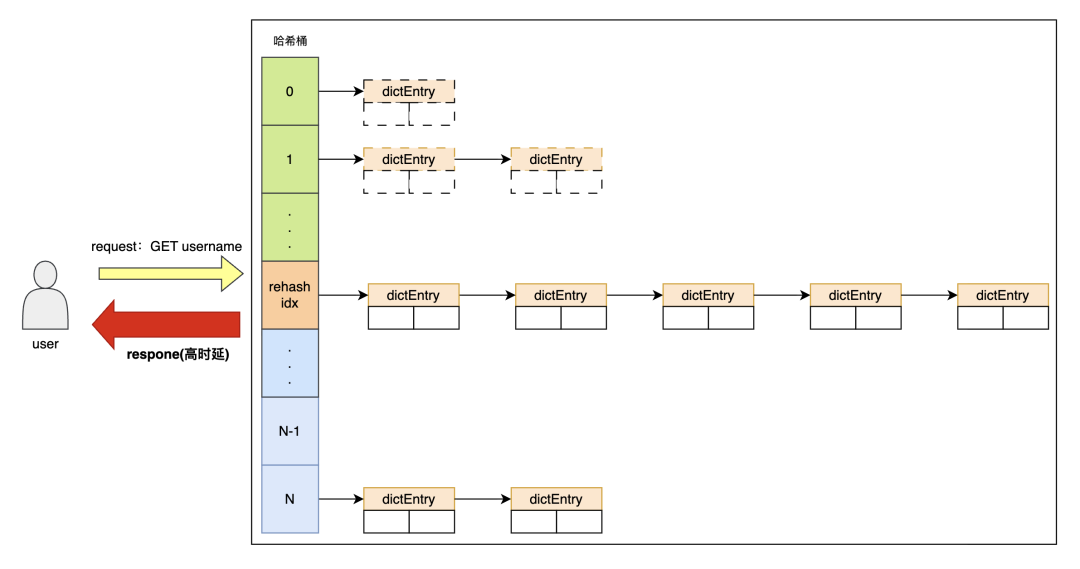
图8 被动rehash时,若搬迁到元素数量较多的桶会造成较高时延
我们无法确定某个请求“顺带”的被动rehash需要搬迁的元素数量是多还是少,从而无法控制每次被动rehash带来的额外耗时。从这个角度来看,被动rehash是不可控的,且当QPS越大时,被动rehash对整体时延的影响就会越大。
2.4.2 主动rehash的影响
主动rehash的问题在于其固定的时间分配策略。Redis的serverCron定时任务每次执行时,都会固定分配1ms的时间来进行字典rehash。这听起来似乎不多,但如果把serverCron任务的运行频率考虑在内的话,主动rehash也可能占用较大比例的CPU时间。
在Redis中,周期性任务serverCron的执行频率由系统配置server.hz决定,server.hz是serverCron在1s内的执行次数。server.hz默认配置为10,也就是说serverCron默认每秒执行10次。在默认配置下,rehash的CPU使用率是

,这的确是一个不高的值。但是,server.hz配置是可以更改的,若server.hz配置为100,那么rehash的CPU使用率就上升到了

。如果珍贵的CPU资源有10%都用于rehash,那么用于处理读写请求的CPU资源就会减少,从而不可避免地导致读写请求的响应时延上升。
2.4.3 旧表释放的“致命一击”
经过了读写请求顺带的被动rehash和serverCron定期的主动rehash后,旧表终于被搬空,只剩释放旧表这最后一步,dict扩容就大功告成了。但就是这最后一个看似不起眼的步骤,可能会给系统最致命的一击。
释放旧表实际就是释放旧表中的每个哈希桶,每个哈希桶指向的空间大小为8个byte,因此释放一个大小为的哈希表一共需要释放bytes的空间。当旧表很大时,释放内存需要花费较长的时间,在这期间Redis的主线程被完全占用,无法处理任何用户请求。
回到我们开头的故障案例,当故障分片的key数量达到6710万时触发了rehash,最后待释放空间大小将是512MB。监控数据显示,正是在旧表释放的瞬间,P99延迟从18ms暴涨到到390ms。
被动rehash、主动rehash、释放旧表这三种操作带来的影响相互交织,共同增加了rehash期间Redis的响应时间。被动rehash带来了不可控的请求延迟,主动rehash消耗了宝贵的CPU资源,而旧表释放则在关键时刻给出了"致命一击"。理解了这些问题的根源,我们就可以有针对性地制定解决方案了。
三、 驯服“怪兽”:腾讯云Redis针对rehash的体系化优化实践
针对本次故障暴露的rehash问题,腾讯云NoSQL团队从全局视角出发,成功将rehash这一不可控的"性能怪兽"纳入可控范围,实现了rehash过程的体系化管理。
3.1 被动rehash开关
在2.4.1小节中,我们讲到被动rehash会给每一个请求强加一个额外的rehash步骤,并且由于哈希桶的大小具有随机性,因此该过程实际上是不可控的。我们在想,能否仅通过主动rehash的方式去搬迁元素呢?为此,我们做了如下实验。
我们使用Redis5,在线上环境进行测试。关闭dynamic-hz使server.hz始终保持在固定的10,观察在没有读写流量的情况下,redis-server单纯依靠主动rehash时的搬迁效率。具体实验步骤如下:
# 关闭动态 hz 调整,减少变量
127.0.0.1:6379> config set dynamic-hz no
OK
# 根据测试条件调整 hz
127.0.0.1:6379> config set hz 10
OK
# 每次实验构造 33554432 个键,即 2 ** 25 个,在插入一个键之后会触发字典 rehash 扩容
127.0.0.1:6379> debug populate 33554432
OK
# 触发rehash
127.0.0.1:6379> set foo bar从实例监控图像中可以看到,触发 rehash 后,CPU 资源平均只会消耗 2% 左右。约3300W 个key搬迁耗时是 15 分钟,平均 1 分钟可以 rehash 搬迁约220W 个key。
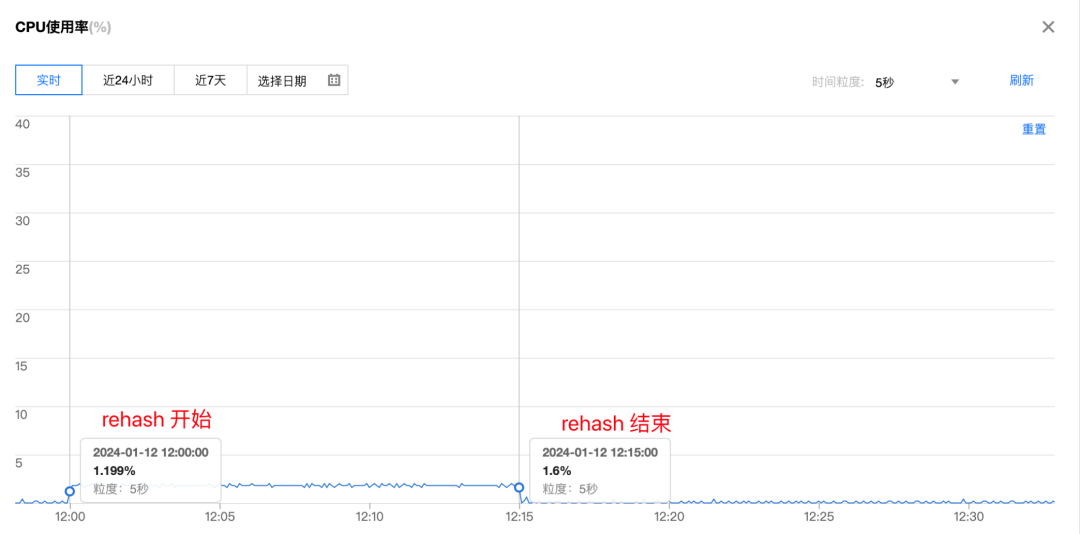
图9 主动rehash期间CPU使用率
经过上述分析,我们认为主动rehash的效率实际上已经足够了,因此我们加入了一个开关来控制被动rehash。具体而言,我们在Redis中增加了配置项passive-rehash-enabled来控制被动rehash是否开启,且该配置默认为no。
3.2 被动rehash开关
2.4.2小节中提到,主动rehash的CPU使用率会根据server.hz的变化而变化,这一点不利于rehash期间系统读写性能的稳定。为了解决这一问题,我们将Redis中每次serverCron中花费在rehash的时间,从固定的1ms更改为根据server.hz动态修正。
具体而言,我们增加了配置项active-rehash-cycle表示serverCron中用于rehash的CPU使用率,该配置默认值为1。
用于rehash的时间根据server.hz和server.active-rehash-cycle实时计算,每次用时为
微秒
例如:
● hz = 10, active-rehash-cycle = 1,上面计算结果为 1000us 即 1ms;
● hz = 10, active-rehash-cycle = 10,上面计算结果为 10000us 即 10ms;
● hz = 100, active-rehash-cycle = 1,上面计算结果为 100us 即 0.1ms。
上述方式有效地固定了主动rehash的CPU使用率,根据server.hz动态修正每次主动rehash的用时,消除了server.hz对主动rehashCPU使用率的影响,使得主动rehash期间系统读写性能更加稳定。
3.3空间异步释放
正如2.4.3小节所讲,当dict大小已经很大时,rehash结束时的旧表释放会造成非常致命的系统阻塞,所有请求需要等待旧表释放完成才可继续进行。其实这个问题的解决方法十分简单,只需要将旧表释放异步进行,使其不干扰主线程的正常运行即可。
Redis的内存分配与释放使用的是jemalloc分配器。经过我们的调研,jemalloc5已经支持在backgroundthread中异步释放内存了。因此我们消除Redis释放大块内存抖动的方式非常直接:将Redis使用的jemalloc分配器升级到版本5。
3.4 rehash维护时间窗口
从前文到许多分析中我们都能感受到,尽管我们通过各种方式将rehash控制得更加稳定,但其始终是一个成本较大的操作。rehash或多或少都会对用户请求的时延产生负面影响,尤其是在QPS较高的场景下,这一影响更加显著。
面对这一问题,我们将视角从系统内部转移至业务场景,采取了一个更加“无感”的策略——为rehash设置一个时间窗口,只有在该时间窗口内才允许dict正常扩容。
我们为Redis新增了maintence-time配置项,它的值是一个时间区间。
● 维护时间窗口内:按照社区逻辑正常走,即当添加元素时发现负载因子 >= 1 时,正常进行扩容。
● 维护时间窗口外:禁止扩容。但为了避免哈希冲突带来的性能损失,会设置一个最大负载因子。当添加元素时,若发现负载因子 >= 1.618,即使不在维护时间窗口内,dict依旧正常进行扩容。
maintence-time可以依据实际业务需求自由配置,通常设置为业务QPS较低的时间段,例如凌晨某时间段,让rehash在深夜“悄悄”进行。
总结
从文章开头的故障现场出发,我们剖析了Redis rehash引发时延毛刺的三大原因:被动rehash的额外负担、主动rehash的CPU占用不可控,以及旧表释放引起的线程阻塞。针对这些问题,腾讯云NoSQL团队构建了完整的rehash优化体系:关闭被动rehash,主动rehash时间控制让CPU使用率可控,空间异步释放消除内存释放阻塞,维护时间窗口让rehash在业务低峰期进行。这套优化体系成功驯服了Redis这头"怪兽",并持续保障线上用户体验的稳定与流畅。
TencentDB
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-28,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号