LDA 是一位“文字炼金术士”,能从文档的混沌词海中提炼出隐藏的主题金矿,并揭示每个文档的「配方秘方」(主题比例)和每个主题的「元素组成」(关键词分布)

LDA 是一位“文字炼金术士”,能从文档的混沌词海中提炼出隐藏的主题金矿,并揭示每个文档的「配方秘方」(主题比例)和每个主题的「元素组成」(关键词分布)

紫风
发布于 2025-10-14 15:06:11
发布于 2025-10-14 15:06:11
🌟 一句话定义
LDA 是一位“文字炼金术士”,能从文档的混沌词海中提炼出隐藏的主题金矿,并揭示每个文档的「配方秘方」(主题比例)和每个主题的「元素组成」(关键词分布)。
🧠 核心思想
- 三层贝叶斯模型
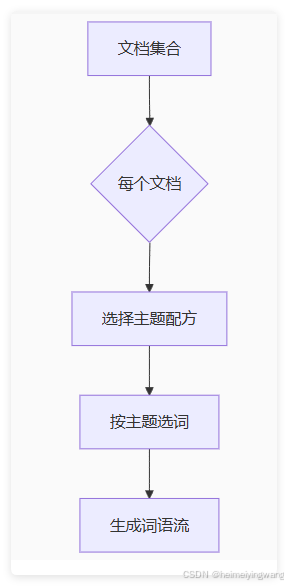
- 双重概率分布
- 文档-主题分布:每篇文档像一杯混合咖啡,由多个主题按比例调配
- 主题-词语分布:每个主题如调味配方,定义词语出现概率
- 生成过程逆向工程 通过观察词语的出现模式,反推生成这些文档的「主题厨房」运作机制
⚡ Java示例(简化版,使用Mallet库)
import cc.mallet.topics.*;
import cc.mallet.types.*;
public class LDADemo {
public static void main(String[] args) throws Exception {
// 创建语料容器
InstanceList instances = new InstanceList(
new TokenSequencePipe());
// 加载文档(示例数据)
String[] docs = {
"apple banana fruit salad",
"car bus train vehicle",
"apple car vehicle fruit"
};
for (String doc : docs) {
instances.addThruPipe(new Instance(
doc, null, "demo", null));
}
// 配置LDA参数
ParallelTopicModel lda = new ParallelTopicModel(
2, // 主题数
5.0,// α参数(主题稀疏性)
0.1 // β参数(词语稀疏性)
);
lda.addInstances(instances);
lda.setNumIterations(1000); // 迭代次数
// 训练模型
lda.estimate();
// 输出主题结果
Alphabet vocab = instances.getDataAlphabet();
for (int topic=0; topic<2; topic++) {
System.out.println("主题"+topic+":");
lda.getSortedWords(topic).forEach(feature ->
System.out.println(vocab.lookupObject(feature.getID()));
}
}
}⏱️ 复杂度分析
维度 | 吉布斯采样法 | 变分推断法 |
|---|---|---|
时间复杂度 | O(K×D×N×iter) | O(K×D×(N+V)×iter) |
空间复杂度 | O(K×D + K×V) | O(K×(D+V)) |
K=主题数,D=文档数,N=总词数,V=词表大小,iter=迭代次数
📚 典型应用场景
- 新闻聚合:自动发现热点事件主题
- 产品评论分析:挖掘用户关注维度
- 学术文献管理:研究领域演化追踪
- 推荐系统:基于内容主题的跨领域推荐
🧑🏫 学习路线指南
新手启航:
基础概念三步走:
参数调优实验:
// 关键参数示例
lda.setAlpha(0.1); // 控制文档主题集中度
lda.setBeta(0.01); // 控制主题词语集中度
lda.setTopicDisplay(50, 10); // 展示top10词高手突破方向:
- 动态主题模型:建模主题的时间演化
- 跨语言主题发现:多语种联合建模
- 层级主题扩展:构建主题树状结构
💡 创新应用思路
- 基因序列分析:将DNA片段视为"文档",碱基视为"词语"
- 社交网络挖掘:用户行为流作为"文档",行为类型作为"词语"
- 故障日志分析:系统日志流主题建模实现异常检测
- 艺术风格解析:画作像素分布主题提取
🚀 性能调优技巧
// 内存优化:稀疏矩阵存储
SparseFeatureSequence tokens = new SparseFeatureSequence(alphabet);
// 并行加速:多链协同训练
ParallelTopicModel parallelModel = new ParallelTopicModel(
4, // 线程数
RandomSequenceGenerator.generateRandomSequence()
);最佳实践:当处理百万级文档时,采用「在线学习」策略分块训练,如同美食家分餐品鉴而非暴饮暴食!预处理阶段务必进行词干提取和停用词过滤,这是保证主题纯净度的关键工序。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-05-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号