5步拆解:大模型如何将你的问题转化为准确回答
原创
5步拆解:大模型如何将你的问题转化为准确回答
原创
聚客AI
发布于 2025-09-21 17:52:38
发布于 2025-09-21 17:52:38
本文较长,建议点赞收藏,以免遗失。
你有没有想过,当我们向Deepseek提问时,为什么大模型能识别你的内容并找出你想要的答案,这个看似简单的交互背后,实际上经历着从数据预处理到深度学习推理的复杂技术流程。今天我将拆解大模型生成优质内容的技术核心,帮助大家更好的理解LLM,如果对你有所帮助,记得点赞关注。
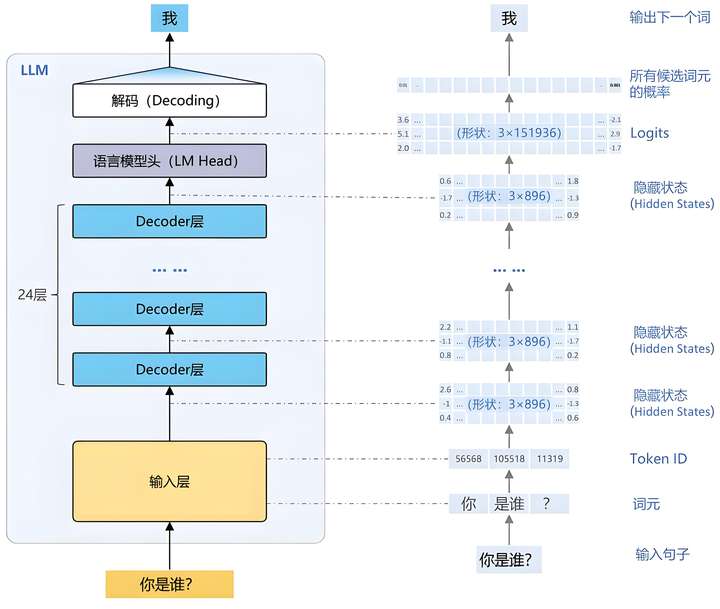
一、输入与分词(Tokenization)
用户输入如“你是谁?”的文本首先经过分词处理,被拆解为模型可识别的基本单元——词元(Token)。例如,该句可能被切分为三个Token:“你”、“是”、“谁”。每个Token会被映射为一个唯一的数字标识(Token ID),如56568、105518、11319,这些ID构成模型理解语言的基础。
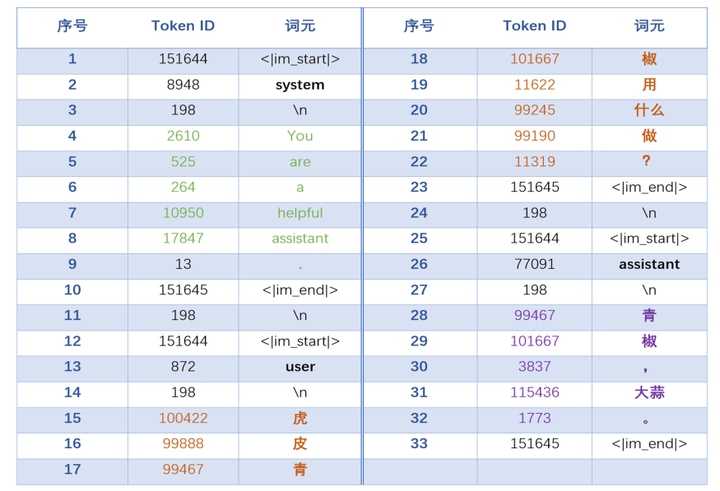
目前主流大模型支持多语言能力,其词典通常通过大规模训练获得,开发者也可直接使用已有的分词器(如Tokenizer)实现这一转换。
ps:如果你还不理解大模型中的Token是什么?以及文本转Token的具体流程,建议你看看我之前整理的技术文档:《一文读懂LLM中的Token以及其重要性》
二、词嵌入(Embedding Layer)
Token ID 随后被送入输入嵌入层(Embedding Layer)。这一层的作用是将离散的ID转化为连续的高维向量(例如896维),从而为后续神经网络提供数值形式的输入。
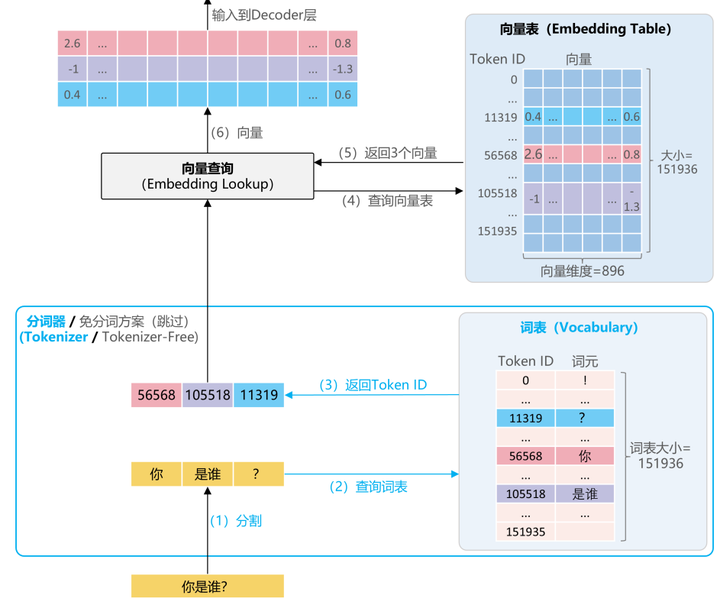
该技术称为词嵌入(Embedding),它是将自然语言转化为模型可处理数学表示的关键步骤。
ps:关于词向量,以及嵌入后如何查询,我这里还有一份更详细的技术文档,粉丝朋友自行领取:《适合初学者且全面深入的向量数据库》
三、深层语义编码:Decoder 层
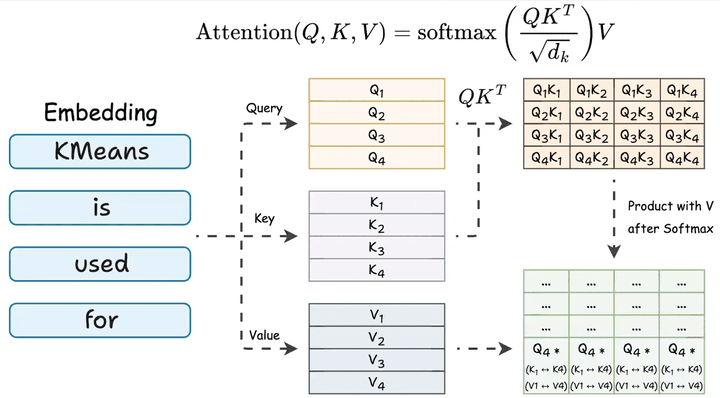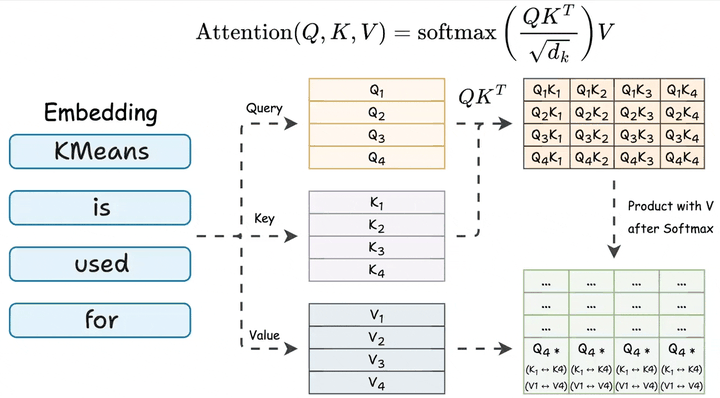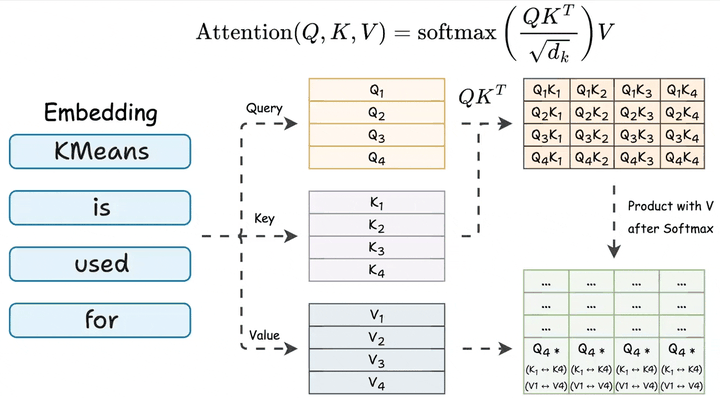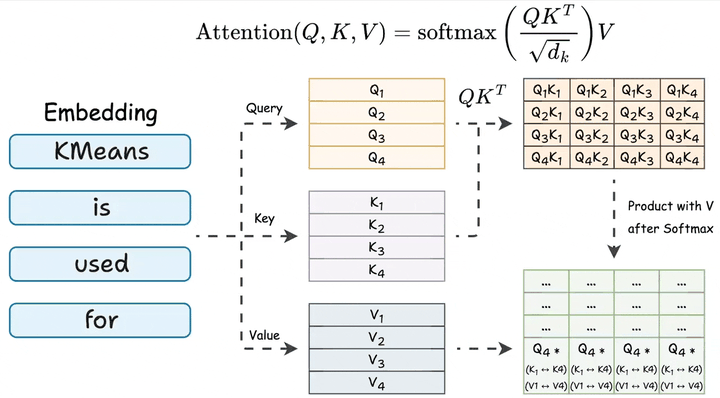
得到的向量会进一步传递至多层的Decoder结构中进行深层次语义提取与上下文建模。例如,在一个24层的Decoder模块中,每一层均会对输入进行逐步加工,逐步捕捉语义依赖和对话语境。
这一过程的核心是自注意力机制(QKV Attention),通过Query、Key、Value向量的交互,模型能够有效捕捉Token之间的关联性,实现类似人类“结合上下文理解语义”的认知过程。
四、输出转换:语言模型头(LM Head)
经过所有Decoder层处理后,顶层的语言模型头(LM Head)负责将隐藏状态映射为输出词表的逻辑值(Logits)。该向量维度与词表大小相同(如151,936维),每一维对应一个词作为下一个输出的可能性分数。
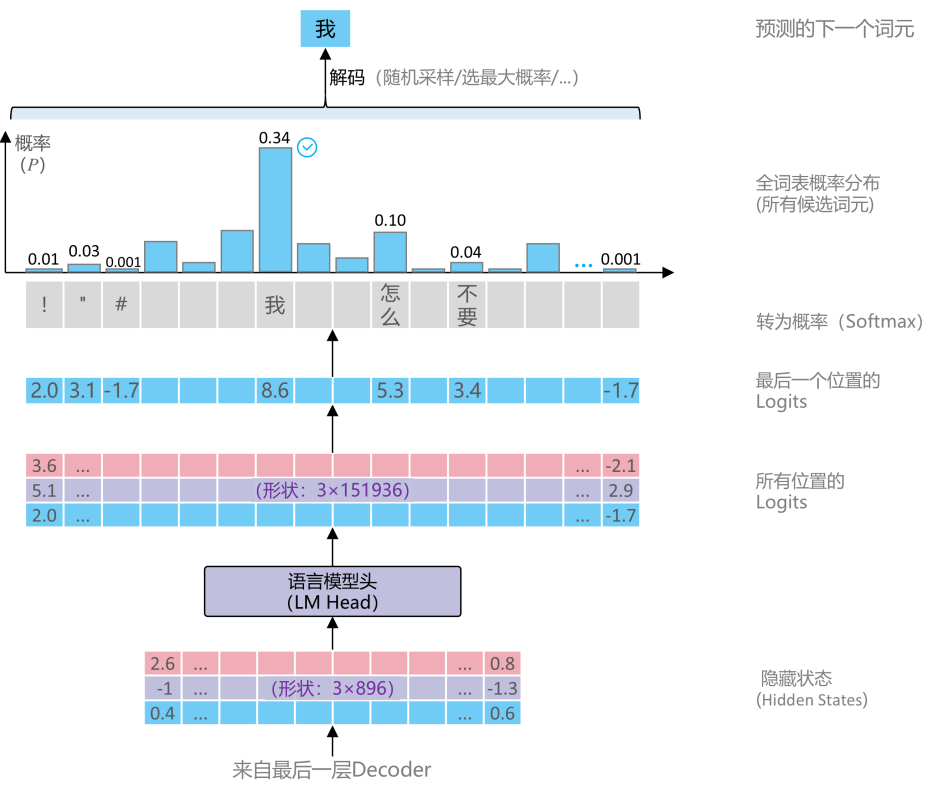
五、概率采样与词生成
Logits经过Softmax函数归一化为概率分布,模型据此执行采样,选择下一个输出的Token。例如,“我”的概率为5.1%,“他”为2.7%,模型可能选择“我”作为第一个生成词。
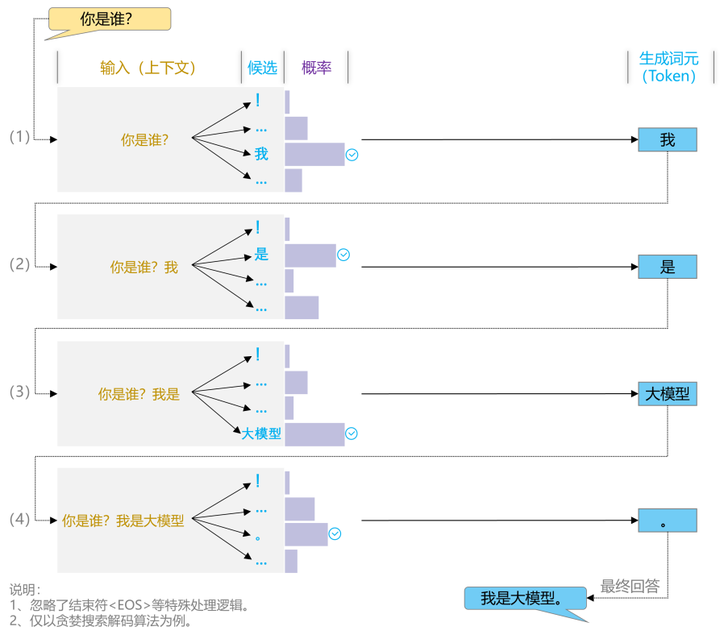
六、迭代生成完整回复
生成第一个词后,模型将已生成文本(如“你是谁?我”)重新作为输入,重复执行以上全部步骤,逐词预测,直到形成完整响应。这一自回归生成机制确保输出在语义和语法上的连贯性。
笔者总结
大模型并非真正“理解”语言,而是借助深层神经网络结构、海量训练数据与概率数学机制,通过前向传播(Forward Propagation)逐词预测,最终组合出符合语境的响应。这一过程融合了嵌入、注意力建模、概率采样等一系列关键技术,构成了当代大模型内容生成的核心技术框架。好了,今天的分享就到这里,点个小红心,我们下期见。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号