ETL是搭建数仓的关键环节?如何利用ETL搭建数仓?
原创
ETL是搭建数仓的关键环节?如何利用ETL搭建数仓?
原创
IT-王大拿
修改于 2025-09-11 16:27:47
修改于 2025-09-11 16:27:47
业务系统日益复杂,传统的自定义脚本数据抽取方式不仅维护成本高,缺乏调度监控,一旦源表结构变动,整个数据流水线便濒临崩溃。构建一个稳定、可扩展的数仓,不再是选择题,而是必答题,而选择合适的专业的ETL工具,正是这条漫漫长路的重要基石。
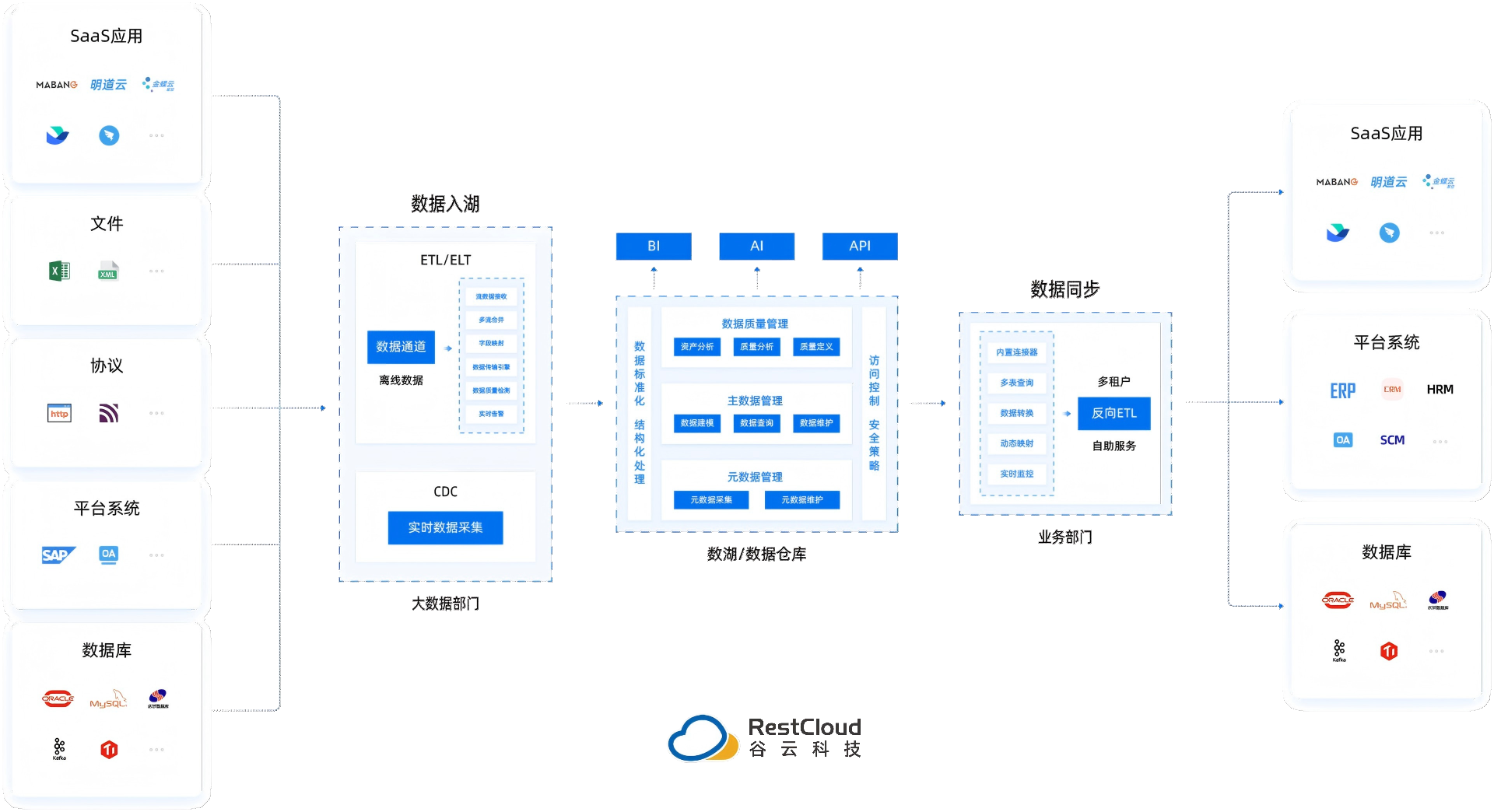
ETL,即提取(Extract)、转换(Transform)、加载(Load),是数据从源系统流向数据仓库的核心过程。你可以将其理解为一座数据加工的“超级工厂”。
提取 (Extract):从各种异构数据源(如MySQL, Oracle, API,日志文件等)中抽取数据。
转换 (Transform):这是ETL的“心脏”。在此阶段对数据进行清洗、格式化、去重、合并、计算业务指标等操作,确保数据的质量和一致性。
加载 (Load):将处理好的数据高效地加载到目标数据仓库中(如ClickHouse, StarRocks, Snowflake等)。
一个强大的ETL工具能自动化这一复杂流程,将数据工程师从繁琐、易错的脚本编写工作中解放出来,专注于更具价值的数据模型设计和业务分析工作。根据Gartner的报告,到2025年,缺乏数据管理流程的组织在实现价值的时间方面将比同行慢50%。而稳健的ETL流程正是数据管理、数据治理的基石。
搭建数仓的关键步骤与ETL的最佳实践
构建数仓是一个系统工程,ETL贯穿始终。以下5个关键步骤勾勒出了清晰的路线图:
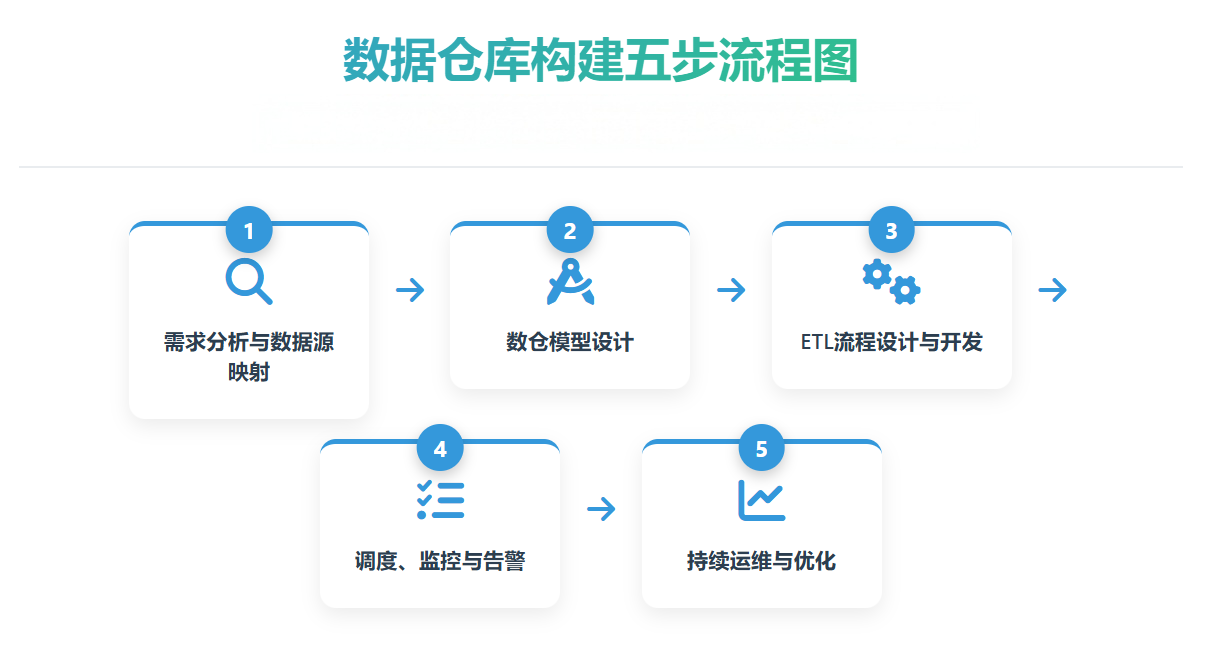
步骤1:需求分析与数据源映射
首先,与业务部门紧密沟通,明确分析需求和指标(如日活跃用户数、销售额看板等)。随后,梳理所有需要接入的数据源,明确其结构、更新频率和数据质量情况。这一步的核心产出是数据血缘地图和指标口径定义文档。
步骤2:数仓模型设计(维度建模)
这是数仓的蓝图。通常采用星型模型或雪花模型,围绕事实表(存储度量值,如销售额)和维度表(存储描述信息,如时间、产品、用户)来组织数据,以优化查询性能。
FAQ:如何保证数仓模型的可扩展性?
答:采用分层设计理念,分层设计解耦了依赖,使得任一层的变动不会严重影响其他层。通常分为:
ODS (操作数据层):直接同步源系统数据,保持原貌。
DWD (数据仓库明细层):对ODS层数据进行清洗、整合、规范化,形成高质量的一致性事实表和维度表。
DWS (数据仓库汇总层):基于DWD层,按主题域进行轻度汇总,形成宽表,供下游应用直接使用。
步骤3:ETL流程设计与开发
依据模型设计,开发具体的ETL任务。这正是ETL工具大显身手的阶段。
FAQ:在数据转换阶段,最常见的挑战是什么?如何解决?
答:挑战主要集中在数据质量和性能。例如:
问题:源系统字段值缺失或异常。
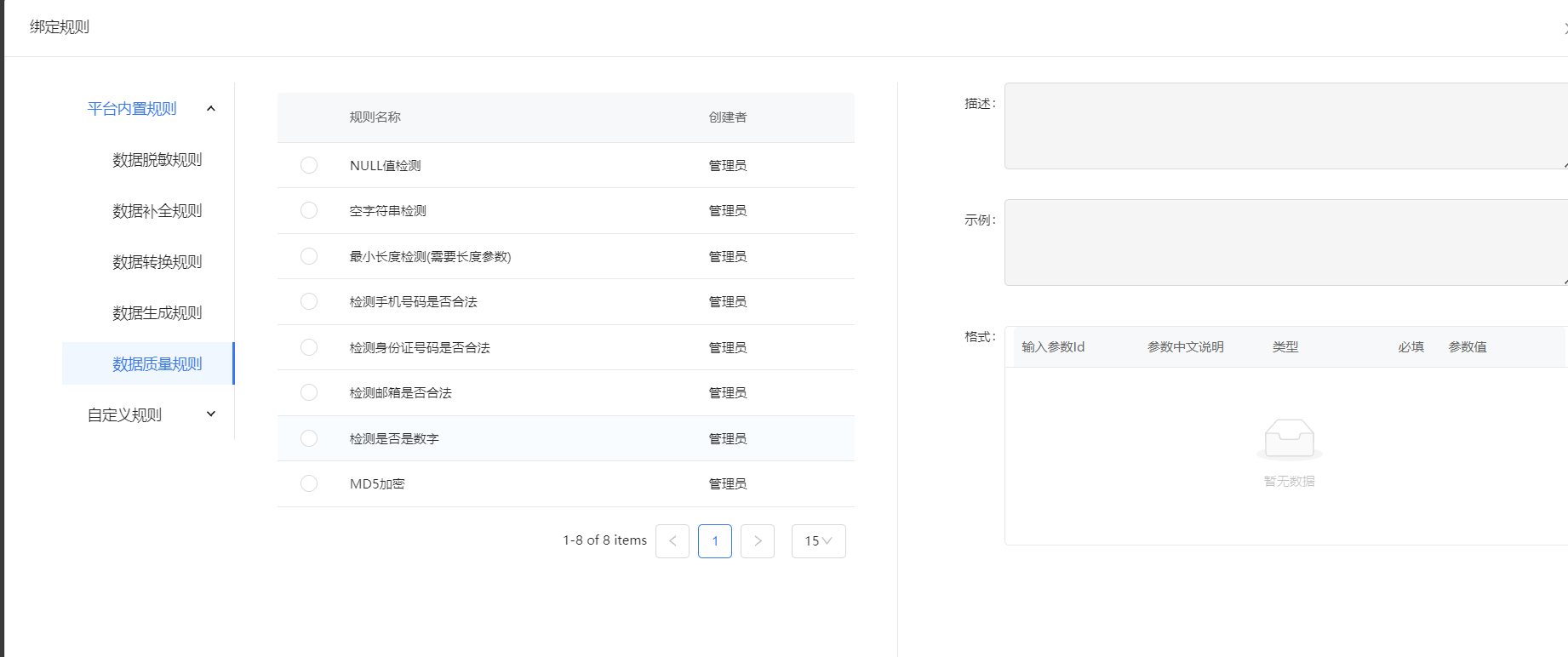
解决方案:在ETL工具中配置数据质量规则,如设置字段默认值、触发告警或将异常数据路由到特定表供人工审查。
问题:多表关联计算缓慢。
解决方案:利用ETL工具的高性能计算引擎(如基于Spark或Flink的内核)进行分布式处理,并合理使用增量同步策略而非全量同步。
步骤4:调度、监控与告警
生产环境的ETL流程必须自动化、可视化。需要设置任务依赖关系(如B任务必须在A任务成功后启动)、监控任务运行状态与速度、并对失败任务配置重试机制和多通道告警(邮件、钉钉、企业微信)。
步骤5:持续运维与优化
定期审查ETL任务的性能瓶颈,优化转换逻辑。关注数据延迟和资源消耗,伴随业务增长对流程进行扩缩容。
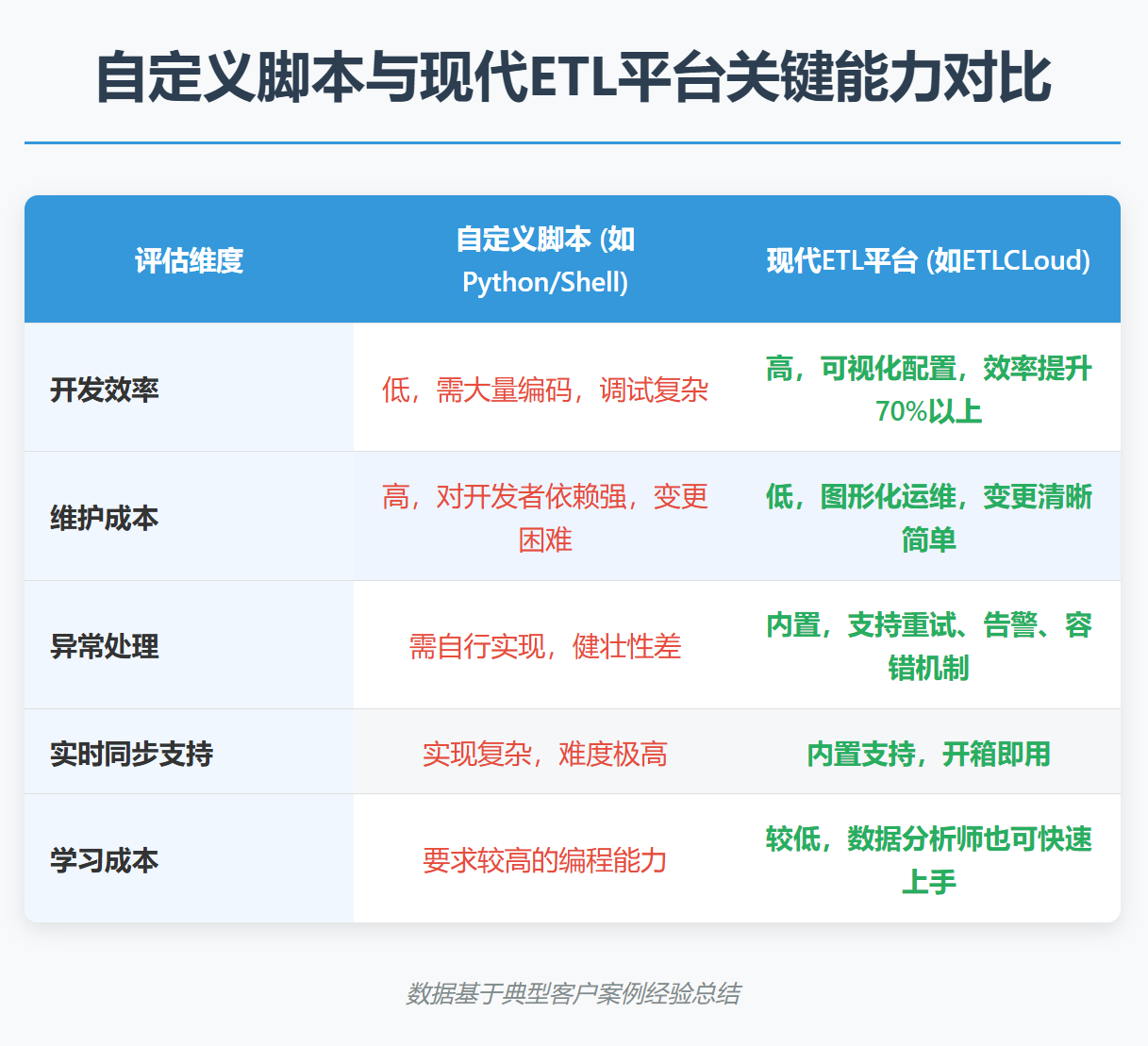
为了更直观地对比传统脚本方式与现代ETL工具平台的差异,我们来看一组量化对比:
实战推荐:如何借助ETLCLoud快速落地数仓项目
首先打开ETLCloud进入首页,选择数据源管理
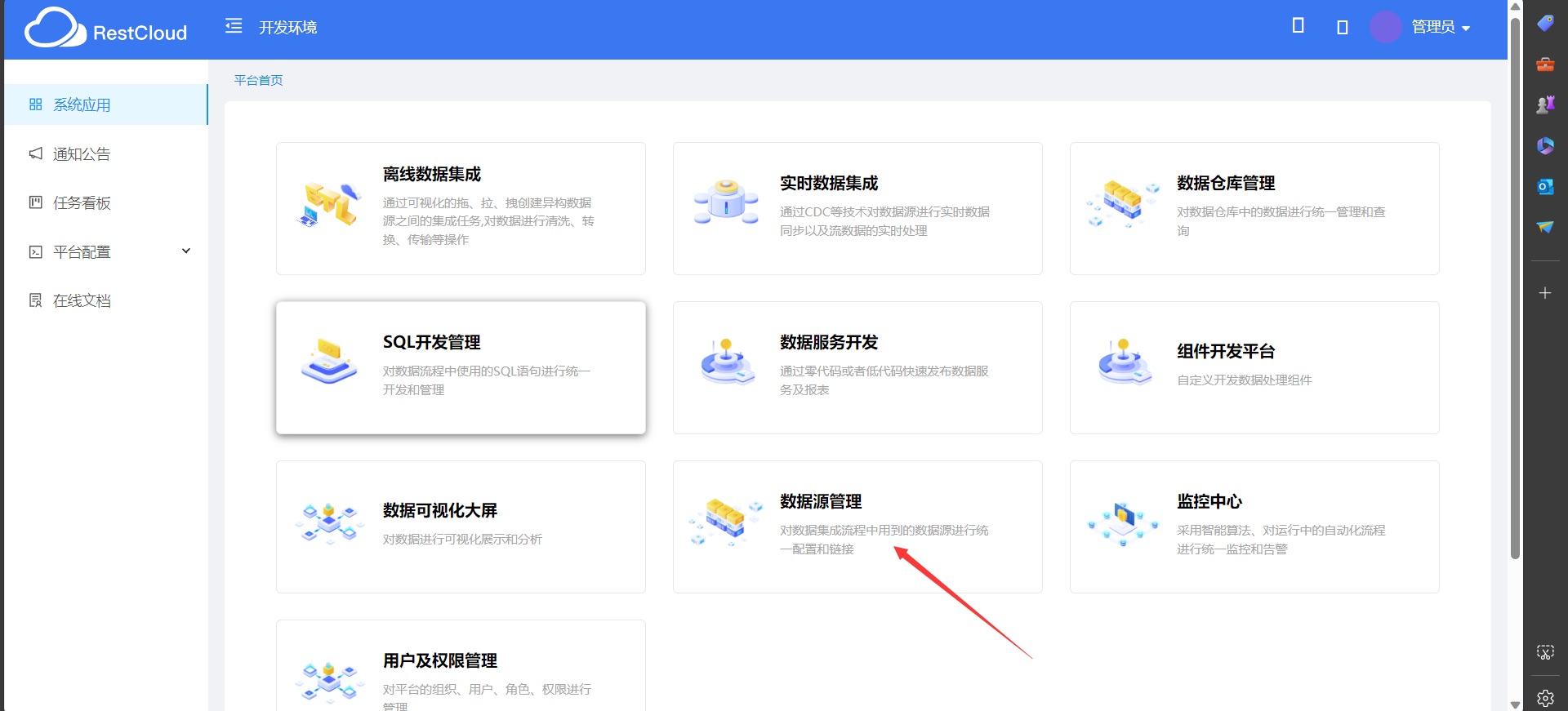
数据源管理页面
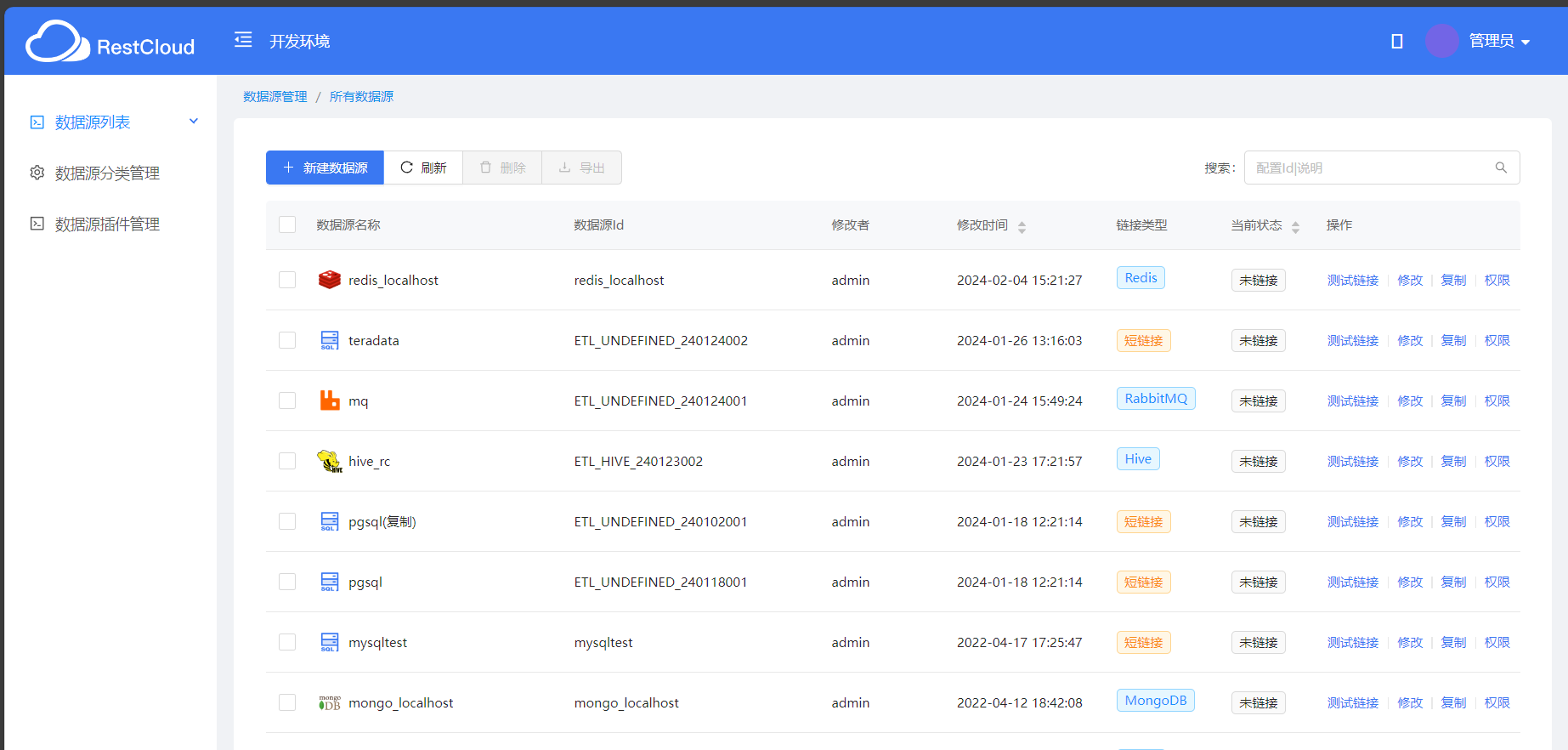
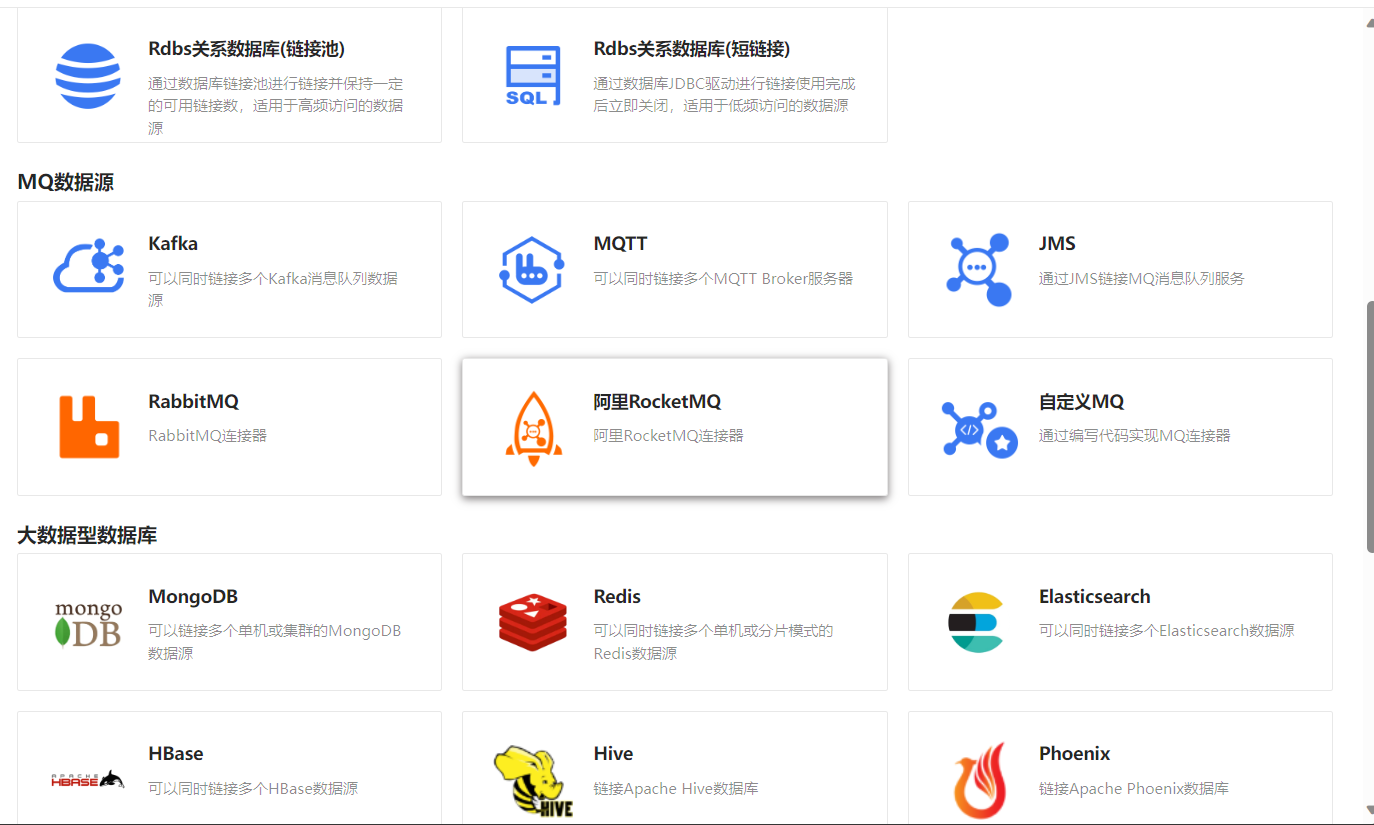
在数据源列表中,点击新建数据源,可以发现ETLCloud这款工具支持非常丰富的数据源,包括国内外主流的数据源,中间件、关系型、非关系型、时序、大数据等等数据源,这便是ETLCloud这款工具的强大之处,便于不同领域行业的人员来使用,做ETL转换,使用方式也是非常的简洁方便。


这里我们就用目前主流的关系型数据库MySQL来做案例演示,进入MySQL数据源配置页面,填写相关信息,其中驱动包所在路径可以自定义填写自己需要的驱动,利于不同用户使用不同版本驱动。
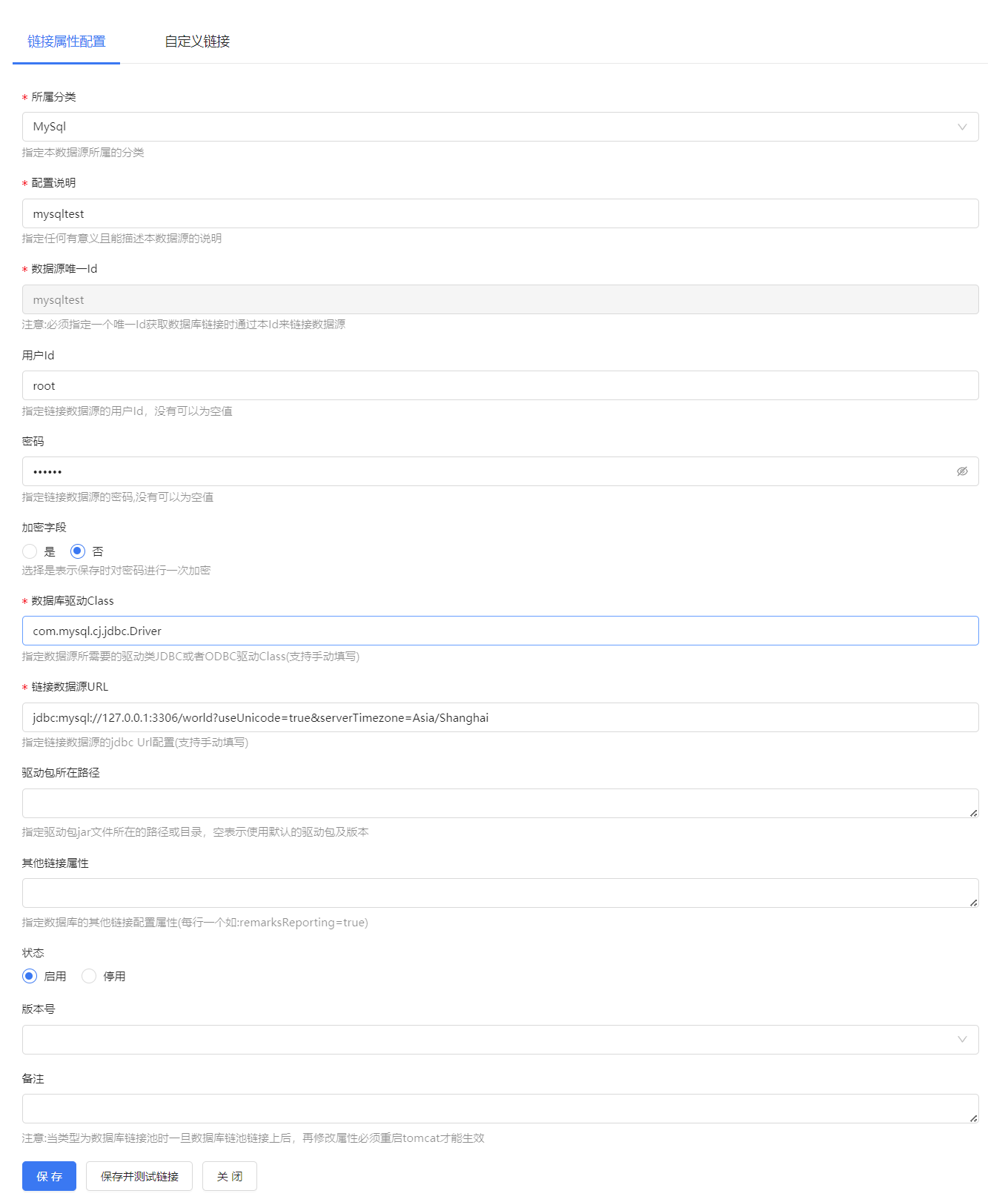
同理对于以上没有找到的数据库,只要是关系型和非关系型支持驱动的都可以用相同的方式去连接,只需要指定驱动的位置即可,配置完成后可以点保存并测试链接,成功即可关闭页面,失败需要检查配置信息是否正确。
完成以上步骤,我们便进入离线流程模块,新建流程,流程设计如下。
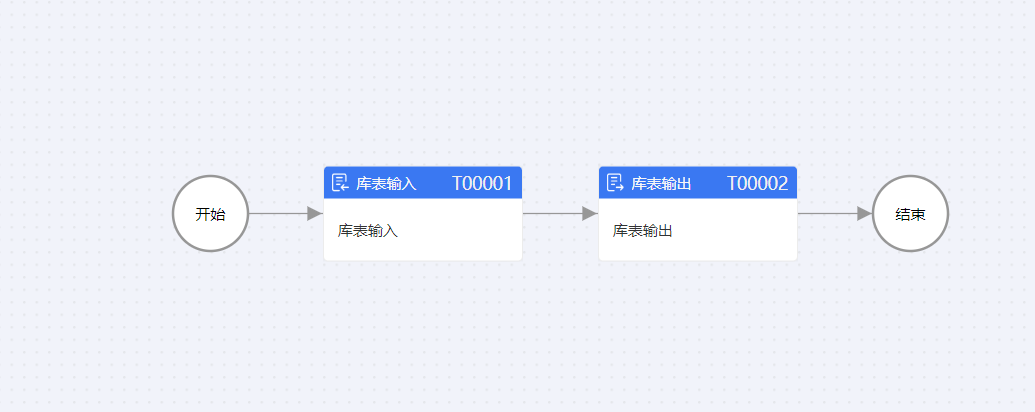
数据同步,转移是ETL最常见的场景,但会面临着几个麻烦的问题,不同数据仓库支持的数据类型不一定一致,数据表结构不一定一致,如果用程序或者手动来去实现,那会浪费较多的成本。ETLCLoud这款工具便很好的解决了这方面的问题,首先配置库表输入组件,我们只要选择我们之前配置好的数据源,加载需要的库表,即可一步完成,包括sql语句的创建(可以自定义sql),数据预览、输入字段的配置等等。
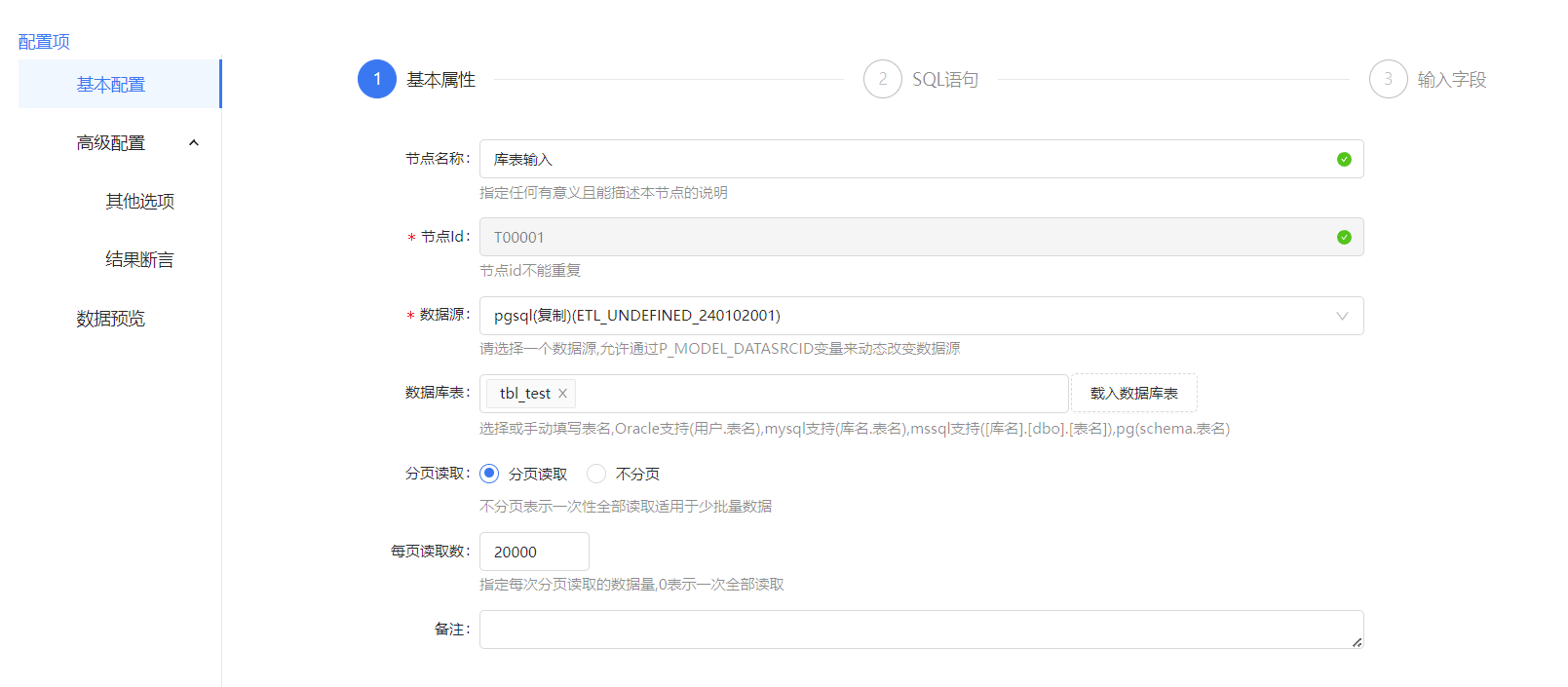
在字段配置中我们还可以,做一些常见的数据处理,配置完成后可以预览数据,确保数据可以正常读取,点击保存即可。
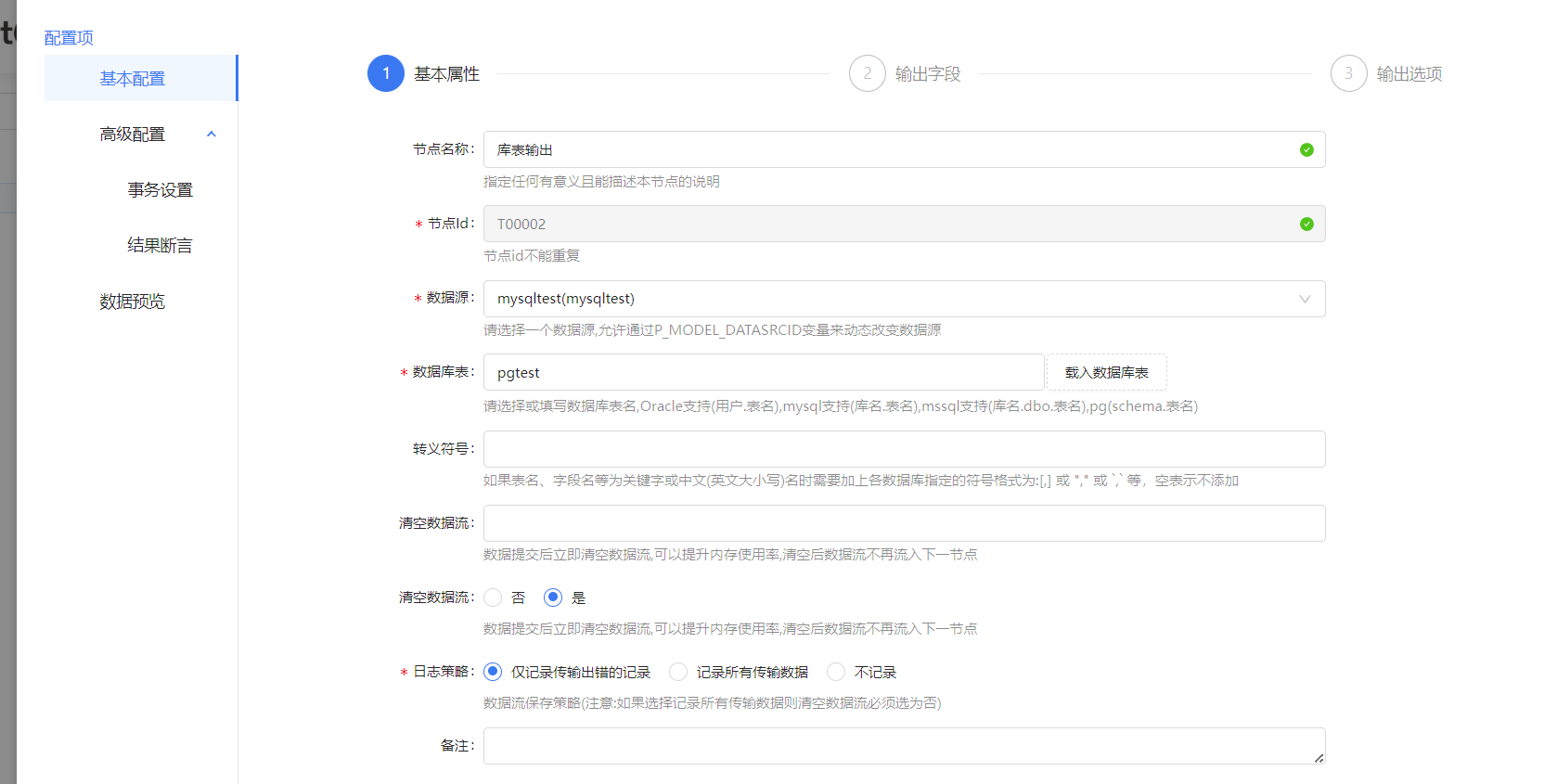
同样的,库表输出配置也是选择我们先前配置好的数据源既可以一步完成,这里的表名我们可以填写一个不存在的表,然后输出选项配置中选择自动创建表。
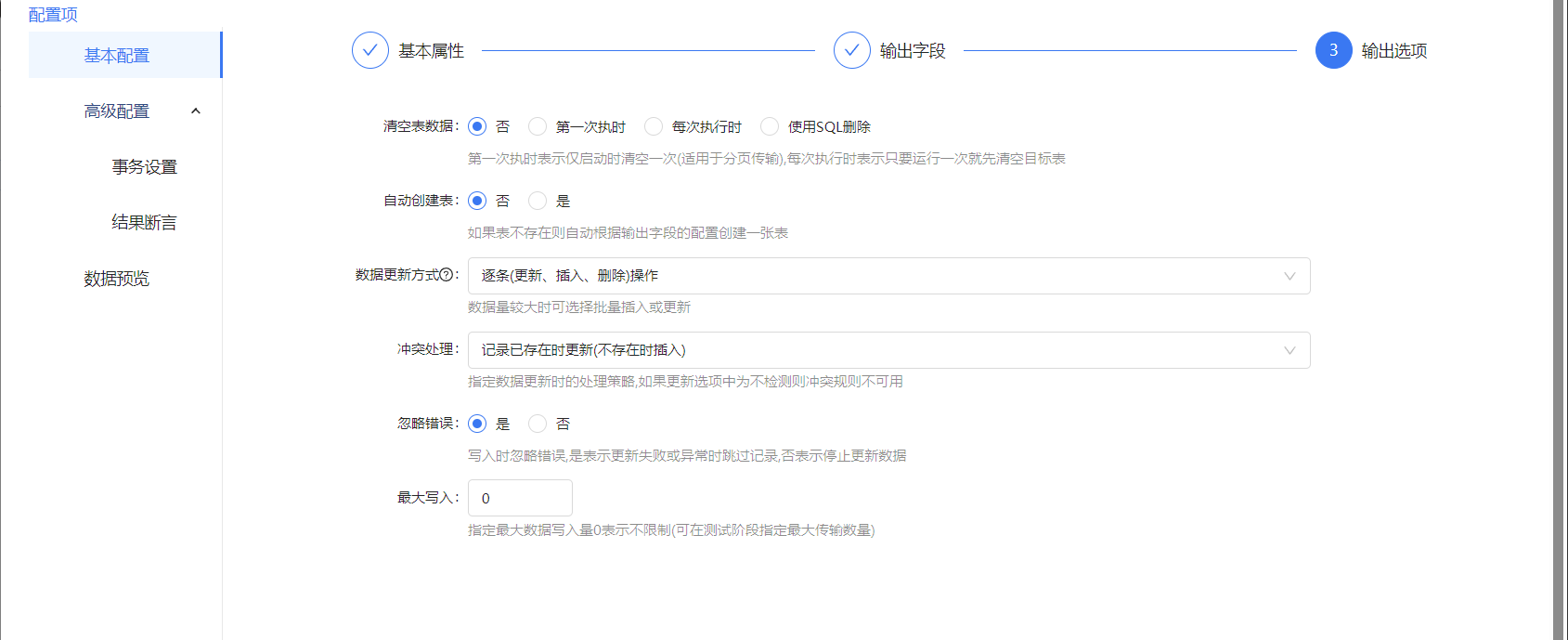
输出字段我们点击从其他节点导入,选择我们库表输入的节点,即可构建新表的字段,点击保存后运行流程。
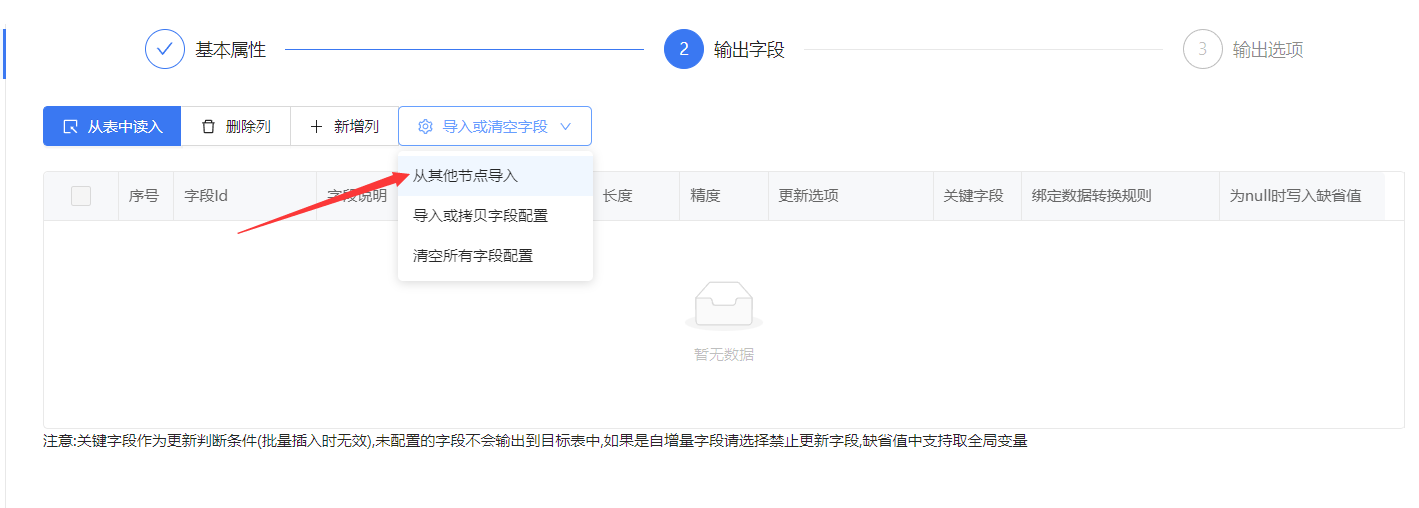
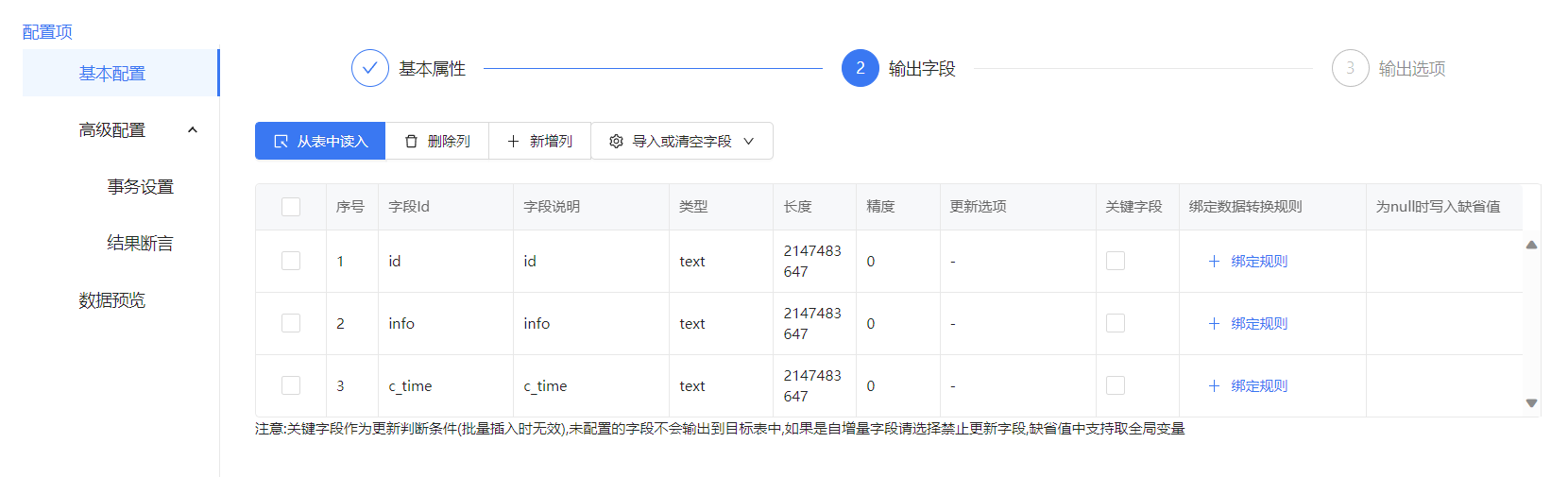
点击保存运行即可将两个数据库的数据进行同步。
————————
总而言之,利用现代ETL工具搭建数据仓库是一个系统化工程,其核心价值在于通过自动化、可视化的方式,将数据规范、高效地转化为可靠的资产,从而为决策提供坚实支撑。选择合适的工具并遵循最佳实践,是成功构建高效可扩展的现代数据仓库架构、解锁数据真正潜力的关键一步。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号