「腾讯云NoSQL」技术之向量数据库篇:腾讯云向量数据库如何实现召回不变,成本减半?

「腾讯云NoSQL」技术之向量数据库篇:腾讯云向量数据库如何实现召回不变,成本减半?

腾讯云数据库 TencentDB
发布于 2025-09-02 08:18:44
发布于 2025-09-02 08:18:44
HNSW (Hierarchical Navigable Small World) 作为向量检索的索引类型之一,因其高召回率和相对优秀的查询性能而广受青睐。然而,HNSW在实际应用中仍面临一些挑战,为满足客户对极致性能和成本效益的需求,腾讯云NoSQL的VDB团队深入研究了业界前沿的半精度技术,创新性地结合了通过SIMD指令的方式,来完成向量压缩和相似度距离的批量计算,从而在保证召回率的前提下,优化整体性能和资源利用率。
目前,该半精度优化方案已在公司内外部多个亿级规模向量的生产环境中成功落地,为客户带来了显著的成本节约和查询延迟降低。
向量检索索引:数据库的导航员
随着大模型(LLMs)、推荐系统、图像识别等前沿技术的飞速发展与普及,我们所处理的数据形态正经历着深刻的变革。传统结构化的数字和文本已不足以承载日益复杂的语义信息,取而代之的是大量高维度的“向量”数据。
这些向量是文本、图像、音频等非结构化内容经过嵌入模型转换而来的数值表示,然而,如何在海量向量数据中高效、准确地发现“相似”的向量,成为了当前数据库技术面临的一大核心挑战。
在没有索引的情况下,查找与给定查询向量最相似的数据点需要对所有向量进行逐一比对,这种暴力搜索(Brute Force)的方式在数据量庞大时将变得极其耗时且资源密集。
而索引能够通过构建特定的数据结构,大幅缩小搜索范围,从而在毫秒级时间内返回近似最近邻(Approximate Nearest Neighbor, ANN)结果。
可以想象,索引在业务场景中发挥着重要的作用,比如:
- 在推荐系统中,它能快速找出与用户兴趣或已购商品相似的其他商品,实现高度个性化的推荐;
- 在语义搜索领域,用户不再局限于关键词匹配,而是能基于查询的深层含义找到相关文档、图片或视频,极大提升了搜索的准确性和用户体验,广泛应用于智能问答、知识图谱检索;
- 在图像和视频内容理解中,可用于快速检索相似视觉内容,实现版权保护、内容审核或以图搜图功能。
客户对HNSW爱恨交织
HNSW近8年向量搜索性能No.1
为了应对海量向量数据的挑战,向量索引技术发展出了多种类型。近几年向量检索常见的索引有FLAT、IVF-SQ系列、IVF-PQ、HNSW、FastSCANN等,HNSW凭借其图搜特征脱颖而出,在ANNsearch方面具备极高的性能优势,在同等硬件条件下,其查询速度通常能比其他许多索引类型快上10倍甚至更多,同时还能保持极高的召回率。这种在查询速度和召回率之间取得的卓越平衡,使得HNSW在业界获得了广泛的认可和青睐,尤其是在对查询延迟和召回率都有严苛要求的AI应用场景中。在过去几年里,HNSW已成为许多企业和开发者在构建高性能向量检索系统时的首选方案。
HNSW索引依旧不完美
规模上涨让性价比变低
HNSW通过分层导航图,实现高效的向量检索,然而HNSW导航每一层的每个节点会存放有多条边去构建这个分层图结构,HNSWlib实现中默认是采用4字节的节点ID数组来实现的,以下是一个HNSW元素的内存示意图。

1条1024维度的向量数据本身会占用4KB,加上临接边和其他内存消耗,内存空间会达到5-6KB,100万向量会达到5-6GB,这些向量默认是放在内存中计算的(从图中可以看出如果用磁盘的方式来存储图结构,会产生大量的随机磁盘IO),当数据规模达到亿级以上,内存会达到数百GB,再叠加多个副本则会达到TB级内存,当数据规模达到百亿级时,会达到百TB级内存(128GB内存的机器需要10000台)。
这个规模的集群从物理架构和技术层面来讲,完全可以实现,但对用户而言实在是“性价比不高”,这个规模的向量服务将会付出昂贵的硬件成本,但其所产生的业务价值在很多场景下却无法与成本对齐。
所以对于向量成本的优化(性价比优化)是一个重要的方向,业界包含了诸多的技术方案,而HNSW的半精度是其中一类方案,可以在召回率下降可控的情况下,降低接近50%的内存成本,提供更高的性能。
HNSW其它问题
HNSW除上述性价比问题外,还有写入性能不稳定、读写并发度低、空间占用高(标记删除不能及时回收空间)、图连通性差(数据聚集,可能导致部分节点入度为0)等诸多问题。所有这些深层次的问题,都将在后续文章中详细阐述腾讯云向量数据库(VDB)所提供的创新性解法,及其在实际应用中展现的卓越效果。
细说HNSW向量半精度(Half Precision)
向量的半精度是什么
半精度本质是使用16个bit来表达Float32的数据,所以它的空间只有原来的1/2。通常意义上来说,半精度特指FP16(Half-precision Floating Point),本文主要从内存成本角度出发,故而将BF16(Brain Floating Point 16)也描述为“半精度”。这两种16位浮点数,具有不同的数据特征:
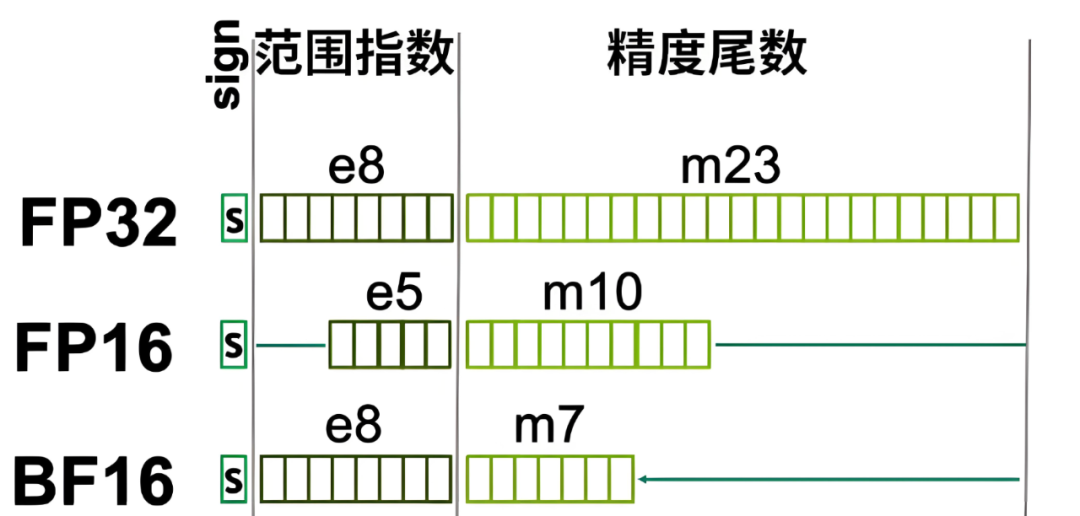
目前业界比较主流的向量精度采用FP32(Float32):8bit的范围指数,23bit的精度尾数。但实际发现用16个bit,几乎可以保证绝大部分向量数据的精度:
部分Embedding模型输出的向量结果整数位很小(乃至都是0),范围指数bit位是浪费的。
部分Embedding模型输出的向量整数位较大但小数位数很小,精度尾数bit位是浪费的。
精度越靠后的bit位对精度的影响越小,用10进制来理解精度的影响:0.1和0.11区别很小,0.11和0.111区别更小,以此类推,因此当精度靠后的bit位损失后,对向量数据的区分度影响很小,很多模型只需要小数点后面2-3位足以区分,除非模型本身输出的结果区分位在小数点后非常靠后的位置或者数据本身的区分度太低。
由于向量每个维度从float32变成了float16或bfloat16,每条数据空间只有原来的1/2,极限情况下内存占用会下降50%,由于还有额外的内存开销,内存占用下降通常在45%左右。
向量的半精度对召回的影响
同一个Embedding模型所获得结果会在一个相对稳定的空间,因此在实际的应用场景中,可以取出一些样本数据来看向量数据的分布。例如sift-128-eclidean数据集的数据小数点后几乎没有数据,就比较适合用BF16来进行半精度量化,gist-960-eclidean更多使用小数点后的精度来表达数据,就更适合使用FP16来进行半精度量化。
实验公开数据集后,证明对召回率的影响几乎趋近于0:
数据集1:sift-128-eclidean
HNSW构建参数:M=16、efc=200
目标召回是reclal@10=0.99,HNSW的searchef=128与BF16量化后的保持一致,说明BF16量化后的向量几乎不损失召回效果,FP16会增加到129达到0.99召回说明影响也很小,不过整体来讲这个数据集更适合用BF16来做。
recall@10=0.99 | searchef |
|---|---|
HNSW默认 | 128 |
HNSWFP16 | 129 |
HNSWBF16 | 128 |
查看一条sift-128-ecliean向量的数据如下,整数位在200-300之间,小数点后面5位来表达,基本符合预期的判断:

数据集2:chinese200w-768-angular
HNSW构建参数:M=16、efc=200
目标召回是reclal@10=0.99,默认情况下searchef=381的时候达到预期召回,经过FP16半精度量化后searchef=384达到预期召回说明对其精度影响非常可控,BF16量化不适合于该样本数据导致无论如何都无法达到预期召回。
recall@10=0.99 | search ef |
|---|---|
HNSW默认 | 381 |
HNSW FP16 | 384 |
HNSW BF16 | 无法达到0.99召回 |
查看该数据集下的一条样本数据如下,整数位范围很小[-10, 10],小数点精度位数偏多,所以此时用BF16精度损失会很严重,而采用FP16后精度损失很小,略微提高searchef值就可以满足召回需求:

客户业务召回
经过多家内外部客户基于真实业务场景,在512、768、1024、2048维进行业务验证,从业务侧端到端验证召回效果的对比,判断业务召回未出现下降,而成本下降45%。从理论、公开数据集、客户真实业务数据等角度确认,只要根据业务选择正确的量化方案,召回效果是可靠的,这也让vdb团队的同学更有信心。
业界的技术实现
VDB着手技术落地阶段,也调研了业界的相关实现。首先,我们调研了开源索引库Faiss,其支持了精度量化版的HNSW,但当时Faiss版本(v1.8.0)尚不支持BF16半精度类型,只支持FP16。

Faiss库在向量匹配时,会先将FP16半精度转换为FP32单精度再进行距离计算,并支持AVX2指令集加速,但未支持AVX-512指令集,整体运行效率较低。其入库/检索的主要操作如下:
- 入库时调用encode_fp16,将FP32转换为FP16 。
- 检索时先调用decode_fp16,将FP16转换为FP32,再进行相似度距离计算。

另一知名厂商的开源版本实现中,也提供了半精度浮点数量化。在实现FP16、BF16半精度向量计算时,也是先转换半精度浮点数为单精度浮点数,再进行距离运算。核心代码如下:

该实现简洁易读,但不够高效。半精度到单精度浮点数的类型转换通过函数实现,单精度浮点数之间的乘积计算效率,则被动依赖于编译器优化,但通常编译器自动优化效果相对保守,远远没有根据硬件指令集的不同,直接采用更高处理位宽的SIMD指令效率高。
TencentVDB
腾讯云VDB团队在理解业界做法后,认为业界的做法可以归纳为:
- 先将半精度浮点数转换为FP32单精度浮点数,以降低乘积和累加误差。
- 再使用单精度标量乘法进行相似度距离计算(比如,x86架构下mulss指令)。
这种运行方式显然是低效的:
- 每发起一次search请求,需要将以半精度量化存储的向量转换为FP32,再进行相似度匹配,那么随着底库规模的增大,转换过程的运算规模也将随之增大。
- 每次转换过程,默认需要通过函数中一系列的标量代码来完成转换(每一个维度均需要),代价是十分高的。

VDB优化方式:
VDB内核同学采用了通过SIMD指令的方式,来完成向量压缩和相似度距离的批量计算,虽然在实现上比起直接使用标量计算代码更为复杂且容易出错,但团队秉持着为首个版本奠定坚实性能基础的理念,坚持走了一条更具挑战性的技术路线。最终,这一决策带来了卓越的性能表现和显著的计算效率提升。下面,我们将以AVX512指令集为例,简述VDB的核心实现:
FP16
- 指令_mm512_cvtps_ph: 将FP32转换为FP16。
- 指令_mm512_cvtph_ps: 将FP16转换为FP32。
在AVX512指令集下,根据向量维度适配的FP16压缩计算方式:

AVX512指令集下,相似度距离计算方式:

BF16
- 指令_mm512_srl_epi32:将以32位整数表达的FP32右移16位,高16位零扩展。
- 指令_mm512_cvtepi32_epi16: 移除32位整数的高16位,转换为以16位整数表达的BF16。
- 指令_mm512_cvtepu16_epi32:将以16位整数表达的BF16,高16位零扩展,表达为32位整数。
- 指令_mm512_slli_epi32:将32位整数左移16位,表达为FP32。
AVX512指令集下,根据向量维度适配的BF16压缩计算方式:

AVX512指令集下,相似度距离计算方式:

下一步探索
目前AVX512扩展指令集中,已经包含对半精度浮点数直接进行点积运算,而无需额外类型转换的指令。部分用户场景可以针对性进行优化,以实现更高的计算效率。更新的AMX指令集,则能提供更高的数据位宽和计算并行度,进一步提升效率。目前受操作系统版本的限制,暂未实现,VDB也会持续这部分的动态变化,在后续适当版本会适配这部分指令以达到更好的效果。
客户效果
自腾讯云向量数据库半精度发布后,多个拥有亿级规模向量数据的客户已通过采用半精度方案获得了显著的收益。这些客户的应用场景广泛,涵盖了教育、大模型训练与推理、代码管理以及搜索推荐等多个核心业务场景,我们对客户的的收益变化进行了以下简单总结:
- 实例成本下降45%
- 同等实例规模下性能提升15%
- 召回率损失低于1%
未来目标:性价比持续升级
HNSW半精度是VDB在提升向量性价比的开始,这显然面对百亿级、千亿级规模的向量还远远不够,向量的成本也远远高于传统数据库的数十倍乃至上百倍,所以还有很长的路需要走。

VDB将根据客户的实际业务场景,结合新技术,持续不断探索高性价比方案,让向量数据库可以服务于更多更大规模的业务场景,接下来大致会从以下几个角度入手和落地:
- IVF-RabitQ/HNSW-RabitQ:
- 新的向量索引技术
- 集高召回、高性能、低成本于一身的向量六边形战士,将在近期正式服
- 磁盘方案在不同场景下的持续探索:
- 自研DISK_FLAT,用以支持RAG的海量租户场景
- 引入DISK_ANN,数倍量化内存空间,通过磁盘二次召回提升召回率
- 内存索引卸载和装载、休眠挂起和唤醒,以充分利用资源
- 稀疏向量的磁盘交换,解决稀疏向量的性价比问题
VDB也将会同时从以下几个角度进一步提升整体能力,敬请期待!
- 进一步提供丰富的业务特性(如多向量、聚合分组、排序)
- 自研索引IVF-ABQ提升性能的同时,降低同等数据规模下的计算成本
- AI数据面服务的Memory记忆、深度检索DeepSearch等能力
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号