ibd2sql v2.0 版本发布, 你没见过的船新版本
原创

导读
ibd2sql 2.0版本今天更新了. 重构了大部分代码, 性能提升很大(不开并发提升约5倍). 还支持并发功能! 使用方法和之前一样.
ibd2sql是啥呢? ibd2sql是一个解析 mysql ibd数据文件为SQL的工具, 使用python3编写, 无依赖包,使用GPL3.0协议. 主要用于数据恢复和学习.
使用场景: 由于某种原因只剩部分ibd文件, 或者不小心delete某几行数据 等均可使用ibd2sql解析数据文件提取其中的数据.
核心更新内容:
- 支持并发
- 支持解析多个数据文件
- 支持指定输出文件(可限制大小)
- 支持4种row_format
- 可查看历史DDL
try it !
下载地址
https://github.com/ddcw/ibd2sql
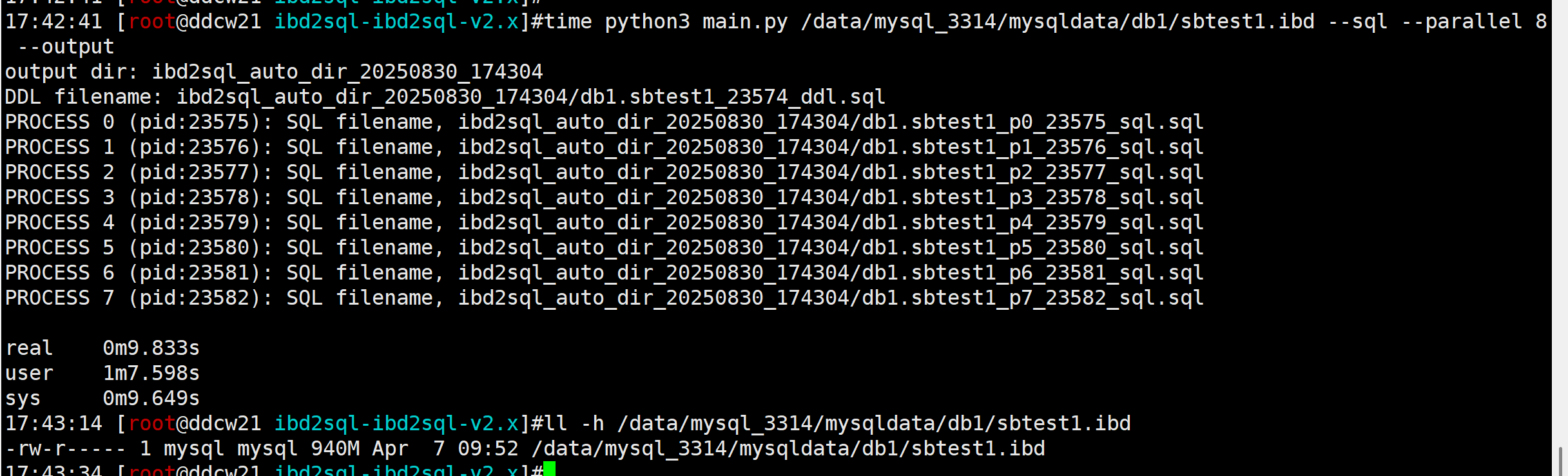
使用演示
解析940MB的文件,耗时大概9.8秒
选项说明
ibd2sql 2.x核心用法和1.x版本保持一致, 新增/移除了部分功能,也对部分功能进行了微调. 总体使用方法依然是python3 main.py FILENAME [options]
目前支持5.7, 8.0. 8.4, 9.0版本. 对于分区表和frm将自动识别元数据信息,也可以使用--sdi-table手动指定.
移除了--debug,--mysql5选项.
--help
显示帮助信息.
--version
显示版本信息
--ddl (微调)
显示相关表的DDL, 无任何其它选项时,默认依然是打印表的DDL信息. 为了方便使用, 新增了额外功能:
--ddl history: 显示DDL的历史情况, 只支持使用instant修改字段的情况, 比如:
-- create table db1.t20250830_test_ddl(id int, name varchar(200));
-- alter table db1.t20250830_test_ddl add column age int,ALGORITHM=INSTANT;
-- alter table db1.t20250830_test_ddl drop column name ,ALGORITHM=INSTANT;
<ibd2sql_2.x > python3 main.py /data/mysql_3414/mysqldata/db1/t20250830_test_ddl.ibd --ddl history
CREATE TABLE IF NOT EXISTS `db1`.`t20250830_test_ddl` (
`id` int DEFAULT NULL,
`name` varchar(200) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COLLATE=utf8mb3_general_ci;
ALTER TABLE `db1`.`t20250830_test_ddl` ADD COLUMN `age` int DEFAULT NULL;
ALTER TABLE `db1`.`t20250830_test_ddl` DROP COLUMN `name`;--ddl disable-keys: ddl中不含非主键的索引信息
--ddl keys-after: ddl中的索引将在最后以alter table add的形式添加.
--sql (微调)
--sql依然为打印sql语句的选项, 但考虑到insert的速度问题, 故新增了额外功能:
--sql data: 输出不再是sql语句,而是可以使用LOAD DATA导入数据的文件格式. 默认字段使用,隔开, 行之间使用\n隔开, 可以使用--set指定为其它字符
--delete (微调)
--delete 依然为打印被删除的数据行, 但是新增了选项功能:
--delete only: 仅打印被删除的数据, 也是--delete的默认选项
--delete with: 打印数据的同时还包含被标记为删除的数据.
--complete-insert
INSERT语句包含字段名称信息
--multi-value
按照每页为一条insert语句进行输出.
--force
若使用该选项,将强制遍历整个数据文件. (默认为按照btr+叶子节点遍历)
--replace
使用REPLACE INTO代替INSERT INTO
--table
输出的表名替换为这个选项的值. 仅适合一张表的时候
--schema
输出的表的schema替换为这个选项的值.
--sdi-table
指定表的元数据信息, 当前版本为默认识别分区表和frm元数据信息, 若未识别到则使用此选项值.
--limit
输出的数据行数(语句行数而非数据行数, 若使用了--multi-value则输出的是n页的数据)
--keyring-file
指定keyring-file
--output (新增)
指定输出目录
--output 将在当前目录下创建ibd2sql_auto_dir_开头的目录作为输出目录.
--ouput /tmp 将在tmp目录创建ibd2sql_auto_dir_开头的目录作为输出目录.
--output-filesize (新增)
输出文件若超过此选项值, 则自动进行轮转.
--print-sdi (新增)
输出表的元数据信息, 同ibd2sdi
--count
统计表的行数
--web
启用web功能, 可在浏览器上以btr+的形式查看表的数据. 原ibd2sql_web.py的功能. 支持多个数据文件
--lctn
查看/修改mysql.ibd中的lower_case_table_names选项的值.
--lctn 查看mysql.ibd中lower_case_table_names的值
--lctn 1 修改mysql.ibd中lower_case_table_names的值为1. 可选值为0,1,2
原modify_lower_case_table_names.py的功能
--parallel (新增)
指定并发度, 当解析数据时,可以使用此选项指定并发度. 对于大表来说, 使用此选项可显著增加解析速度. 并发数量建议为cpu空闲数量.
--log (新增)
输出日志
--log 将日志输出到stderr
--log xxx.log 将日志输出到xxx.log
--set (新增)
一部分不那么重要但也不错的选项,就放这里了. 使用方法为:
--set 'k1=v,k2;k3=v' --set 'k4=v'--set='hex' 输出的字段值将以16进制的形式展示.
--set='leafno=4' 指定叶子节点为4
--set='schema=db1' 对目标数据文件进行schema过滤, 若不为db1则跳过.
--set='table=t1' 对目标数据文件进行table过滤, 若不为t1则跳过
使用例子
解析数据文件,获取DDL和DML
python3 main.py /data/mysql_3314/mysqldata/db1/sbtest2.ibd --sql --ddl解析数据文件,获取DDL和DML, 使用8个进程并发解析
python3 main.py /data/mysql_3314/mysqldata/db1/sbtest2.ibd --sql --ddl --parallel 8解析数据文件,获取DDL和DML, 使用8个进程并发解析 并输出到 '/tmp'目录
python3 main.py /data/mysql_3314/mysqldata/db1/sbtest2.ibd --sql --ddl --parallel 8 --output='/tmp'强制解析目标数据文件
python3 main.py /data/mysql_3314/mysqldata/db1/sbtest2.ibd --sql --ddl --force解析多个数据文件
python3 main.py /data/mysql_3314/mysqldata/db1/sbtest* --sql --ddl 解析数据文件中被标记为删除的数据
python3 main.py /data/mysql_3314/mysqldata/db1/sbtest2.ibd --sql --delete解析数据文件并输出为data模式, 方便使用load data导入
python3 main.py /data/mysql_3314/mysqldata/db1/sbtest2.ibd --sql data查看目标文件的sdi信息
python3 main.py /data/mysql_3314/mysqldata/db1/sbtest2.ibd --print-sdi查看目标文件指定表的信息
python3 main.py /data/mysql_3314/mysqldata/mysql.ibd --set='table=user' --ddl --sql以web控制台展示
python3 main.py /data/mysql_3314/mysqldata/mysql.ibd --web查看mysql.ibd中记录的lower_case_table_names值
python3 main.py /data/mysql_3314/mysqldata/mysql.ibd --lctn原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号