【笔记】Linux高性能网络详解之DPDK
原创
【笔记】Linux高性能网络详解之DPDK
原创
于顾而言SASE
发布于 2025-08-29 14:51:52
发布于 2025-08-29 14:51:52
在传统内核协议栈中,应用程序与网络协议栈的交互导致频繁的用户态与内核态切换,严重影响了数据收发的整体时延。而 DPDK 通过将大部分操作置于用户态执行,显著减少了内核态参与,实现了更高的网络性能。
1. 内核协议栈的收发包流程
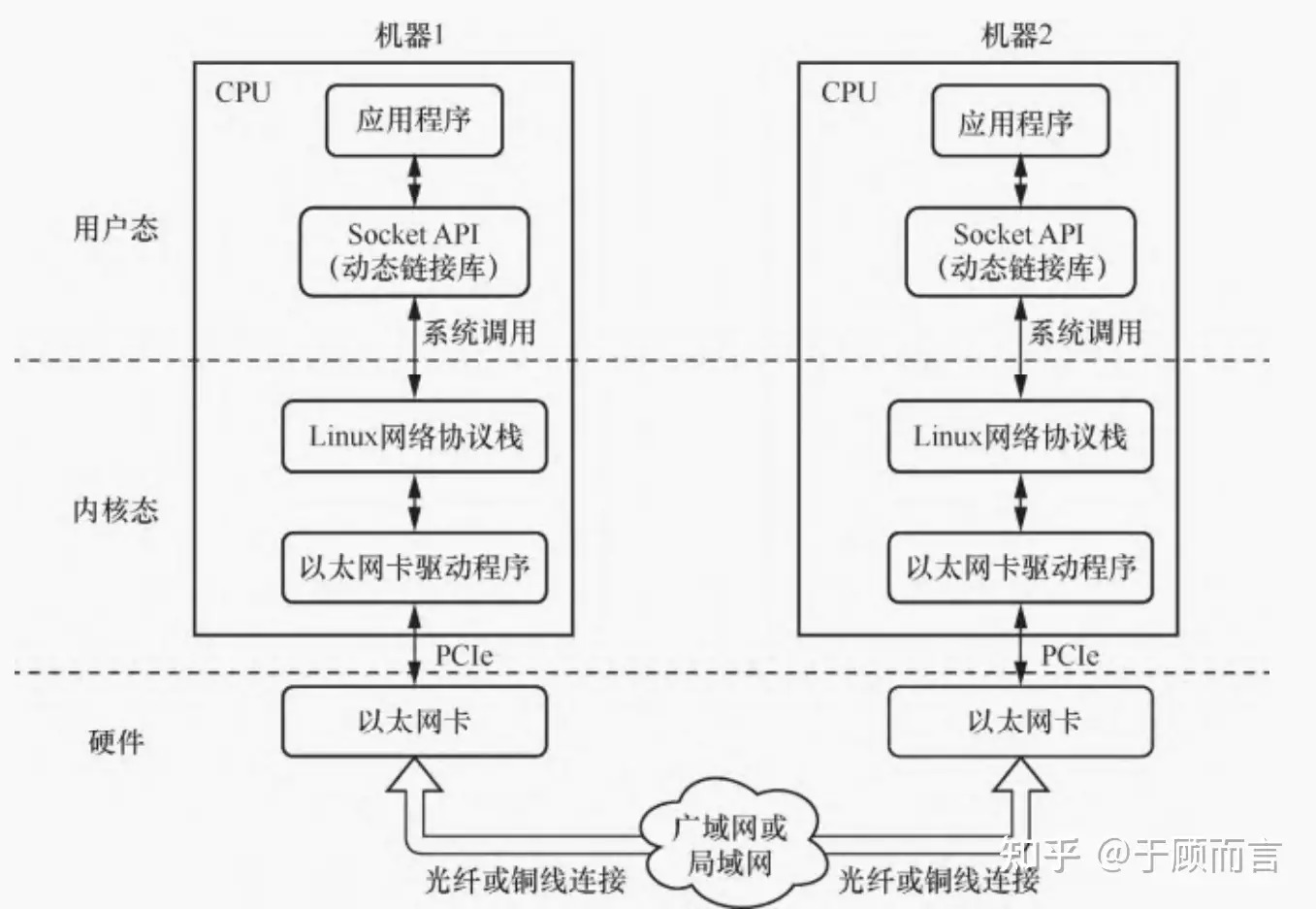
用户态:
软件部分全部运行在主机 CPU 上(数据保存在主机内存)。其中应用程序和它调用的动态链接库运行在用户态。
内核态:
Linux 网络协议栈和以太网卡驱动程序运行在内核态。Linux 网络协议栈是连接应用和驱动程序的中间层,负责按照应用程序的要求建立网络连接和封装(发送时)、解析(接收时)数据包。以太网卡驱动程序是和特定的网卡绑定的,负责操控硬件,将协议栈封装好的数据包发送到外部网络中,或将网卡从外部网络接收到的数据包转发给协议栈。
硬件:
关于硬件部分,在不考虑多设备的情况下,主机的以太网卡是和外部进行网络互连的唯一硬件设备。网卡通过光纤或铜线等物理链路连接到网络,链路的对端可能是另一台主机(这种情况称为直连),也可能是各种路由器或交换机组成的广域网或局域网。
我们来看看一次完整的业务数据发送和接收操作的步骤如下:
- 在网络通信开始前,发送端和接收端应用程序需进行一系列初始化操作。发送端通过调用
socket()系统调用创建套接字描述符(socket descriptor),指定地址族(如AF_INET或AF_INET6)、套接字类型(如SOCK_STREAM或SOCK_DGRAM)和协议类型(如IPPROTO_TCP)。接收端同样创建套接字,并调用bind()函数将套接字与特定 IP 地址和端口号绑定,随后调用listen()进入监听状态 - 对于 TCP 连接,需要通过三次握手建立连接。发送端调用
connect()时,内核协议栈构造 SYN 包并发送至接收端。接收端内核接收到 SYN 包后,回复 SYN-ACK 包,发送端再回复 ACK 包完成连接建立。此过程涉及序列号初始化、窗口大小协商等关键参数交换。连接建立后,双方应用程序在用户空间分配发送缓冲区(send buffer)和接收缓冲区(receive buffer),用于暂存待发送和待处理的应用层数据。
--------------------------------------------用户态分割线-------------------------------------------------------
3. 发送端应用程序调用 send()或 write()等系统调用,将用户空间缓冲区中的数据(包括数据指针和长度等信息)传递给内核。系统调用接口(如 sys_sendto 或 sys_write)触发软中断(software interrupt),进入内核态(kernel mode)。内核根据文件描述符查找对应的套接字对象(socket object),该对象包含了通信所需的元数据,如目标地址、端口号和协议类型等。
4. 内核协议栈的传输层(transport layer)根据套接字类型进行数据处理。
对于 TCP 协议,内核执行以下操作:
- 分段处理:根据 MSS(Maximum Segment Size,最大分段大小)将应用数据分割成适合网络传输的段。
- 添加 TCP 头部:包括源端口、目标端口、序列号、确认号、窗口大小、校验和等字段。
- 流量和拥塞控制:实施拥塞避免算法(如 Tahoe、Reno 或 CUBIC)和流量控制机制(滑动窗口协议)。
对于 UDP 协议,处理较为简单:
- 添加 UDP 头部(源端口、目标端口、长度和校验和)。
- 计算校验和后直接传递给网络层。
5. 网络层(network layer,IP 层)接收传输层数据后,执行以下操作:
- 路由查找:根据目标 IP 地址查询路由表(routing table),确定下一跳的 IP 地址和出口网络接口(outgoing interface)
- IP 头部封装:添加 IP 头部,包括源 IP 地址、目标 IP 地址、协议类型(如 TCP 为 6,UDP 为 17)、生存时间(TTL,Time To Live)和头部校验和等字段
- 分片处理:若数据包大小超过出口网络的 MTU(Maximum Transmission Unit,最大传输单元),IP 层会对数据包进行分片(fragmentation),每个分片携带相同的标识符但不同的偏移量
- Netfilter 处理:数据包经过 netfilter 框架的 OUTPUT 和 POSTROUTING 链,可在此处执行 NAT(Network Address Translation)、过滤或修改等操作
6. 数据链路层(data link layer)接收网络层数据包后,执行以下操作:
- ARP 解析:若下一跳 IP 地址的 MAC 地址未知,则通过 ARP(Address Resolution Protocol)协议解析其 MAC 地址。系统首先查询 ARP 缓存,若不存在则发送 ARP 请求并等待响应
- 帧封装:添加数据链路层头部(如以太网头部),包括目标 MAC 地址、源 MAC 地址和协议类型(如 0x0800 表示 IPv4)
- 流量控制:数据包进入 QDisc(排队规则,queueing discipline)队列,根据配置的算法(如 FIFO、SFQ 或 HTB)进行排队和调度,实现带宽限制和优先级控制
7. 网卡驱动(NIC driver)将内核中的 sk_buff 结构数据转换为网卡可理解的格式,填充到 发送环缓冲区(Tx Ring Buffer)的描述符中。随后,网卡通过 DMA(Direct Memory Access,直接内存访问)引擎直接从内存中读取数据包,无需 CPU 参与。网卡可能在此阶段执行硬件加速操作,如 TSO(TCP Segmentation Offload,TCP 分段卸载)或 GSO(Generic Segmentation Offload,通用分段卸载),将大块数据分割成适当大小的数据包,减轻 CPU 负担
--------------------------------------------内核态分割线-------------------------------------------------------
8. 网卡将数字信号转换为适当的电信号(如以太网铜缆)或光信号(如光纤),通过物理介质发送数据帧。数据包经过网络设备(如交换机和路由器)转发:
- 交换机(二层设备)根据目标 MAC 地址查找 MAC 地址表,决定转发端口。若地址未知,则广播 ARP 请求学习地址
- 路由器(三层设备)解析数据包的 IP 头部,根据路由表决定下一跳,并修改数据帧的 MAC 头部(替换源和目标 MAC 地址)
发送完成后,网卡触发硬件中断(hardware interrupt),通知 CPU 数据已发送完成。驱动程序处理中断,释放已发送的 sk_buff 结构
9. 接收端网卡监听物理介质,捕获电信号/光信号并将其转换为数字数据。网卡通过 DMA 将数据直接写入内核预先分配的接收环缓冲区(Rx Ring Buffer),该缓冲区由驱动程序和网卡共享。网卡随后触发硬件中断,通知 CPU 有数据包到达。
--------------------------------------------硬件分割线----------------------------------------------------------
10. CPU 响应中断,执行中断处理程序(interrupt handler):禁用网卡中断(防止重复触发),触发 NET_RX_SOFTIRQ 软中断,并将后续处理交给 ksoftirqd 内核线程。中断处理程序运行时间极短,确保快速释放 CPU 资源。
11. ksoftirqd 线程在软中断上下文中轮询接收环缓冲区,将数据包从环缓冲区中取出,组装成 sk_buff 结构,并开始协议栈的层层处理
- 数据链路层处理:
- 帧校验:通过 CRC(Cyclic Redundancy Check,循环冗余校验)验证帧完整性,损坏的帧被丢弃
- MAC 过滤:检查目的 MAC 地址是否与本机 MAC 地址、广播地址或多播地址匹配,否则丢弃(除非开启混杂模式)
- 协议识别:根据 MAC 头部的协议类型字段(如 0x0800 表示 IPv4),将数据包传递给相应的网络层协议处理程序
- 网络层处理:
- IP 验证:检查 IP 头部校验和、TTL 值等,无效数据包被丢弃,可能触发 ICMP 错误消息
- 路由判断:根据目的 IP 地址决定数据包是交付本地系统还是转发(若主机配置为路由器)
- 分片重组:若数据包是分片,IP 层等待所有分片到达后重组为完整 IP 数据包
- Netfilter 处理:数据包经过 PREROUTING 和 INPUT 链,可在此处执行过滤或 NAT 等操作
- 传输层处理:
- TCP/UDP 分发:根据 IP 头部的协议类型字段,将数据包传递给 TCP 或 UDP 处理程序
- TCP 特定处理:检查序列号、确认数据(发送 ACK)、处理重传(RTO 或快速重传)和拥塞控制。数据按序列号排序后放入套接字的接收缓冲区
- UDP 特定处理:检查校验和后,直接将数据包交付给监听特定端口的应用程序
--------------------------------------------内核态分割线---------------------------------------------------------
12. 接收端应用程序提前调用 recv()或 read()等系统调用,进入阻塞状态等待数据。当数据到达套接字的接收缓冲区后,内核将数据从内核空间的缓冲区复制到应用程序在用户空间指定的缓冲区。复制完成后,系统调用返回实际读取的数据长度,应用程序被唤醒并开始处理数据。内核可能在此阶段采用零拷贝技术(如 sendfile()),避免数据在内核与用户空间间的多次拷贝,提升性能
--------------------------------------------用户态分割线---------------------------------------------------------
2. 内核协议栈方案的缺点
- 应用程序和网络协议栈的交互过程中存在用户态和内核态的频繁切换,操作系统在执 行类似行为时,会涉及当前进程上下文(包括程序调用栈、寄存器等)的保存和恢复工作;TLB(页表的缓存)也会被频繁更新,导致 MMU 需要经常访问页表。这些都影响了数据收发的整体时延。
- 存在用户空间缓存和内核空间缓存之间的数据复制行为,消耗了大量时间。从整个过程中可以看出,包括网卡间的数据传递,数据的复制行为共进行了 5 次。第 1 次和第 5 次数据复制是在主机内存芯片内部进行的,在理论上是可以避免的。
- 尽管引入了 NAPI/
poll机制在高速场景下采用轮询来批量收包以减少中断,但协议栈本身对数据包的处理(如 TCP 状态机维护、拥塞控制、校验和计算等)仍然是逐包进行的。这意味着每个数据包都需要经历协议栈各层的处理流程,无法充分实现批量化操作,限制了单核处理能力 - 内核协议栈对数据包的各种封装和解析也会消耗 CPU 时钟。
- 一个数据包可能被网卡中断在一个 CPU 核上处理,但其对应的应用程序却运行在另一个 CPU 核上。这种跨核交互会导致 CPU 缓存频繁失效,即所谓的“缓存抖动”(Cache Thrashing),在 NUMA 架构中,跨 NUMA 节点的内存访问延迟更高
3. DPDK 的收发包流程
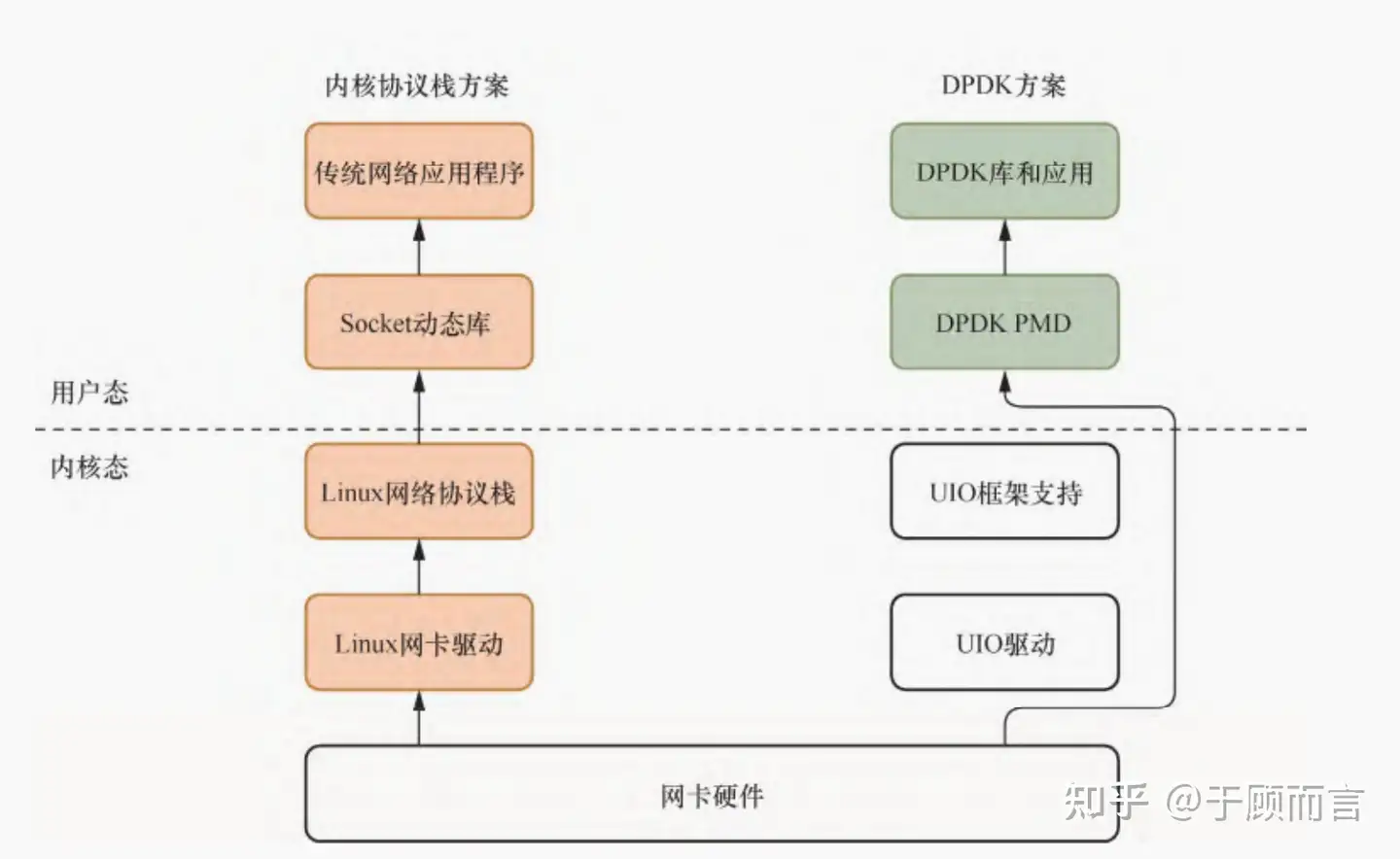
在深入细节之前,我们先掌握 3 个核心概念,这是 DPDK 收发包的基石:
- 描述符 (Descriptor): 一个存储在内存中的数据结构,可以被网卡(通过 DMA) 和 CPU(驱动) 共同访问和修改。它本质上是一个“工单”,包含了数据包存储的物理地址(DMA 地址) 和包的状态信息(如长度、校验和、状态位等)。网卡通过读取描述符知道该把数据包放在哪里,驱动通过检查描述符知道网卡的操作是否完成。
- Mbuf (Memory Buffer): DPDK 中管理数据包内存的核心结构。它存储了数据包的虚拟地址、元数据(如包长度、端口号、VLAN 信息等)以及指向实际数据包内容的指针。驱动操作的是
mbuf。 - DMA (直接内存访问): 允许网卡等外设在不消耗 CPU 周期的情况下,直接与系统主内存进行数据读写。CPU 只需初始化好描述符和缓冲区,后续的数据搬运工作就由网卡上的 DMA 引擎自行完成,极大解放了 CPU
简单来说,驱动负责准备 mbuf 并将其对应的物理地址填写到描述符中,然后告知网卡。网卡的 DMA 引擎读取描述符,根据其中的物理地址,直接将数据包写入或读出内存,最后更新描述符中的状态位。驱动通过轮询状态位来判断数据包是否就绪或发送完成。
- DPDK 应用启动时,会通过
rte_eth_rx_queue_setup()函数为指定的网卡端口和队列分配接收队列所需的内存资源:
rx_ring: 硬件描述符环,存储的是描述符(包含数据包缓冲区的物理地址/DMA 地址),此环由网卡硬件直接访问。sw_ring: 软件环,存储的是对应rx_ring中每个描述符所对应的rte_mbuf结构的指针(虚拟地址),此环供驱动软件使用- 驱动会从内存池 (
rte_mempool) 中预先分配一批mbuf,将每个mbuf数据缓冲区的物理地址 (buf_iova) 填入rx_ring的描述符中,并将mbuf的虚拟地址指针存入sw_ring的对应位置。同时,将描述符的状态位(如 DD 位)清零,表示描述符所有权移交给了网卡,网卡可以使用它来存放新数据包
------------------------------------------数据包接收详细流程 (RX)--------------------------------------------
2. 数据包从网络到达网卡, 网卡先将数据包暂存到其内部的 RX_FIFO 接收缓冲区。网卡的 DMA 引擎 从 rx_ring 中获取下一个可用的描述符,读取其中的物理地址。DMA 引擎通过 PCIe 总线,不经过 CPU,直接将数据包从 RX_FIFO 搬运到该物理地址指向的系统内存中(即 mbuf 的数据缓冲区)
3. DMA 写入完成后,网卡 DMA 引擎会回写描述符,更新其中的状态信息(如数据包长度、校验和、错误状态等),并将状态位(如 DD 位)置为 1,表示该描述符对应的数据包已就绪,所有权归还给驱动.
4. DPDK 的 PMD(Poll Mode Driver)驱动在一个紧密的循环中轮询(Poll)rx_ring 中的描述符状态,检查 DD 位是否为 1,而不是依赖中断通知。这避免了中断开销,是高性能的关键
5. 当驱动通过轮询发现某个描述符的 DD 位为 1,它就知道一个新的数据包已经到了。驱动通过描述符的索引,从 sw_ring 中找到对应的 mbuf 指针。驱动根据描述符中的信息更新 mbuf 的元数据(如包长度、端口、RSS 哈希值、VLAN、校验和状态等)。这个包含数据的 mbuf 就被传递给上层的应用进行处理。
6. 驱动在取走数据包后,必须立即为这个描述符重新准备一个新的空 mbuf,以便网卡可以持续接收后续的数据包。驱动从内存池 (rte_mempool) 中分配一个新的 mbuf。将新 mbuf 数据区的物理地址回填到 rx_ring 的当前描述符中,并将其虚拟地址指针存入 sw_ring。将描述符的状态位(DD 位)清零,再次将描述符的所有权交还给网卡硬件。这个过程常被称为“狸猫换太子”
7. 驱动会维护一个本地计数器,记录已补充的描述符数量。只有当已补充的数量达到一个预设的阈值 (rx_free_thresh) 或一批数据包处理完毕时,驱动才通过写网卡的 RDT (Receive Descriptor Tail) 寄存器来一次性通知网卡:有一批新的描述符可用了。网卡会根据 RDT 寄存器知道描述符环的可用范围。
--------------------------------------------数据包发送详细流程 (TX)-------------------------------------------
8. 应用程序准备好要发送的数据,并分配一个 mbuf 或将复用的 mbuf 填充好发送数据。应用调用 rte_eth_tx_burst()函数,将一批要发送的数据包的 mbuf 指针提交到指定的发送队列。
9. 驱动从发送队列的 tx_ring 中获取一个可用的描述符。驱动将待发送数据的 mbuf 数据缓冲区的物理地址填入描述符中。同时设置描述符中的控制位,如包结束 (EOP)、校验和卸载、VLAN 插入等指令信息。将描述符的状态位(如 DD 位)清零,表示描述符所有权移交给了网卡,网卡可以读取它并发送数据包。
10. 网卡的 DMA 引擎读取 tx_ring 中下一个所有权属于自己的描述符(状态位为 0)。DMA 引擎根据描述符中的物理地址,通过 PCIe 总线,不经过 CPU,直接从系统内存中读取数据包内容到网卡内部的 TX_FIFO 发送缓冲区。
11. 网卡的 MAC(媒体访问控制)层从 TX_FIFO 中取出数据,加上帧头、CRC,最终通过物理线路发送出去。数据成功发送后,网卡的 DMA 引擎会回写描述符,更新状态(如发送成功或错误),并将状态位(如 DD 位)置为 1,表示该描述符对应的数据包已发送完成,所有权归还给驱动.
12. DPDK 的 PMD 发送驱动同样通过轮询检查 tx_ring 中描述符的 DD。当驱动发现某个描述符的 DD 位为 1,就知道该数据包已发送完成。驱动会将该描述符对应的 mbuf 释放回内存池,以便重复使用。驱动将描述符状态清零,并将其重新标记为可用。
可见,dpdk 收发包,大部分都在硬件和用户态执行,只有少量的内核态参与。
少量的内核态操作如下:
- 网卡硬件中断(如链路状态变化、错误告警)需由内核处理,因为硬件中断只能在内核响应。DPDK 通过 UIO 或 VFIO 驱动在内核注册精简的中断处理程序,仅负责通知用户态进程(例如通过
/dev/uioX的read()感知中断) - 当 DPDK 需将数据包送回内核协议栈(如处理 TCP 连接或 ICMP),需通过 KNI 内核模块转发数据,涉及内核态协议栈处理
- DPDK 依赖的巨页(HugePage)需通过内核系统调用(如
mmap)预先分配,并在启动时由 EAL(环境抽象层)锁定物理内存 - 网卡寄存器空间需通过内核驱动(如 VFIO)映射到用户态,使 DPDK 能直接操作硬件寄存器
大量的用户态操作如下:
- 用户态 PMD 直接轮询网卡描述符环(Descriptor Ring),检测新数据包到达(通过 DD 状态位),无需中断或内核参与
- 网卡通过 DMA 将数据包直接写入用户态预分配的
rte_mbuf内存池,应用通过虚拟地址直接解析和修改数据 - 用户态程序自行解析以太网/IP/TCP 头部,并执行转发逻辑(如 L2/L3 转发)
- 驱动更新接收/发送描述符(如填充新
mbuf地址或释放已发送描述符),均在用户态完成 rte_mbuf的分配与释放由用户态内存池管理,避免动态内存分配的内核调用- 将 PMD 线程绑定到专属 CPU 核,避免内核调度器介
- 使用 SIMD 指令(如 AVX2)批量处理数据包,或通过
rte_ring无锁队列传递数据指针
4. DPDK 优化网络数据包的核心技术
4.1. UIO
dpdk 可以在用户态直接访问硬件设备,其实这并不是魔法,而是 Linux 操作系统原生支持的一种技术,名为 UIO(userspace I/O)。 这是一个通用的内核驱动程序,可以帮助开发人员编写能够访问设备寄存器和处理中断的用户空间驱动程序。DPDK 也是 UIO 的使用者。
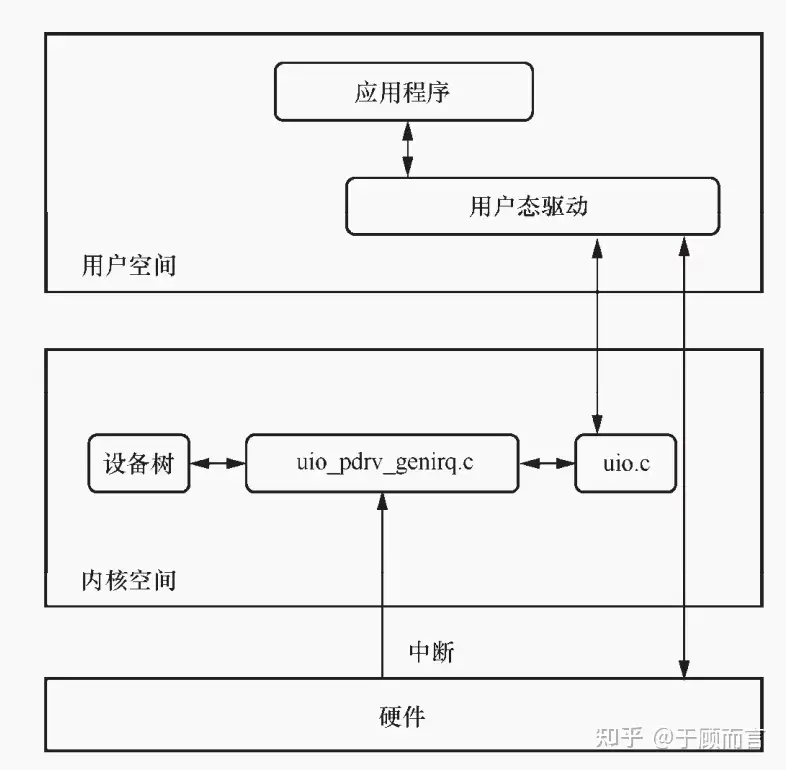
UIO 核心驱动程序(uio.C)
- 负责在 sysfs 中创建描述 UIO 设备的属性文件。
- 提供 mmap 函数将设备内存/寄存器的物理地址映射到进程中的虚拟地址。
- 和 UIO 设备驱动程序一起搭建 UIO 框架。设备驱动程序包括处理通用中断的 UIO 平台设备驱动程序 uio_pdrv_genirq.C、PCI 设备驱动程序 uio_pci_generic.C 或用户提供的专有设备驱动程序。uio.C 中包含了这些设备驱动程序调用的常用接口(比如注册 UIO 设备的 API)。
UIO 平台设备驱动程序 (uio_pdrv_genirq.C)
- 为 UIO 框架提供了通用的平台型驱动程序,以支持中断处理。
- 调用 uio.C 提供的 API 注册 UIO 设备,向用户呈现设备文件/dev/uioX。
- UIO 平台设备驱动程序的配置来源于设备树(dts,x86 体系结构不支持)或加载驱动程序时的选项。
用户态的应用程序如何使用 UIO:
- 应用程序通过一个设备文件和几个 sysfs 属性文件访问每个 UIO 设备。第一个设备的设 备文件名为/dev/uio0,后续设备的设备文件名为/dev/uio1、/dev/uio2;以此类推。
- 内核中的 UIO 驱动程序在 sys 文件系统中创建描述 UIO 设备的属性文件。/sys/class/uio/ 是所有属性文件的根目录。在目录/sys/class/uio/下,有每个 UIO 设备的单独编号的目录结构, 第一个 UIO 设备的目录是/sys/class/uio/uio0。再进到下一级目录时,每个 UIO 设备的目录下 的内容就不完全一样了。
- 具体有哪些文件和文件夹取决于加载的 UIO 设备驱动程序类型。一般典型的内容如下:
- /sys/class/uio/uioX/name 文件的内容为此设备对应的 UIO 设备驱动程序的名字,比如 uio_pci_generic.C。
- 如果是 PCI 设备,即加载了 uio_pci_generic.C 驱动程序,/sys/class/uio/uio0/device/resource
- 文件的内容是 PCI 设备的每个 BAR 空间的地址和长度。
- /sys/class/uio/uio0/maps 目录下包含设备的所有内存地址范围。
- 每个 UIO 设备可以为一个或多个内存(或寄存器)区域提供地址映射。每个内存区域的映射在 sysfs 中都有自己的目录,第一个映射对应目录/sys/class/uio/uioX/maps/map0/。 后续映射会创建同级目录 map1/、map2/等。注意,只有当映射的地址空间大小不是 0 时, 这些目录才会出现。每个/sys/class/uio/uioX/maps/mapX/目录包含 4 个只读文件,描述内存区域的属性,这 4 个文件如下。
- 应用程序通过读取文件/dev/uioX 获取中断。一旦发生中断,程序之前访问文件/dev/uioX 时调用且被阻塞的 read/select 函数就会返回。从/dev/uioX 读取到的整数值表示总共发生的中断的计数,应用程序可以用这个数字来判断是否错过了一些中断。
- 应用程序还可以以/dev/uioX 为文件句柄,调用 mmap 函数(间接调用 UIO 驱动程序中 uio_mmap 函数),将设备内存/寄存器映射到进程的虚拟地址空间。
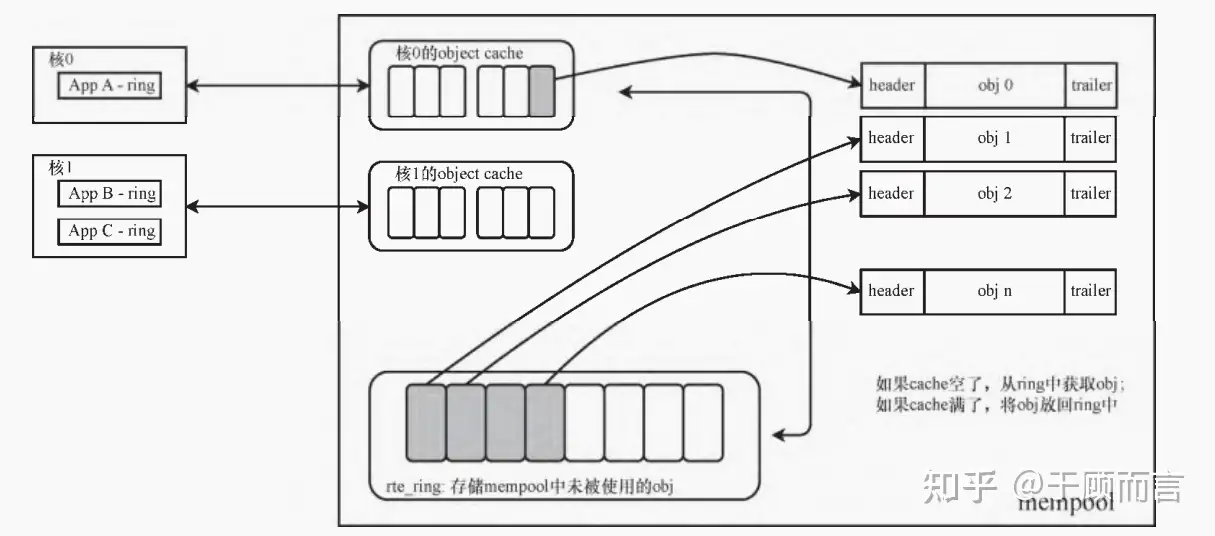
4.2. 无锁环形队列
环形管理器(ring manager)使用环形队列,在有限大小的表中,提供了无锁的多生产者、 多消费者的先进先出队列(FIFO)以及操作队列的 API。与普通无锁队列相比,它有一些优势,比如易实现、适合批量操作、速度快等。内存池管理器就使用了此模块提供的机制。另 外,环形队列还可用作逻辑核间或单个逻辑核上连接在一起的执行块之间的通用通信机制。
4.3. PMD
轮询模式驱动程序(poll mode driver,PMD)需要提供一系列 API,用于配置设备、创建队列、发送数据包、接收数据包等。PMD 直接访问接收队列和发送队列的描述符以及寄存 器,无须处理任何中断(除了链路状态更改中断),即可在用户态的应用程序中快速接收、 处理和发送数据包。
4.4. 内存优化
- 使所有数据结构按照 Cache Line 对齐,为每个核分配单独的内存段
- TLB miss 问题,采用大页
对于 4MB 内存的程序,传统 4KB 页面,TLB 中至少需要缓存 1024 个表项才能保证不会 出现 TLB miss。而 TLB 的大小是非常有限的,如果采用 2MB 的大页,对于同样占用 4MB 内存的程序,TLB 中只需要缓存 2 个表项(前提是这 4MB 内存被分配在了两 个内存页内),就可以保证不出现 TLB miss。对于消耗更多内存(以 GB 为单位)的大型程序,可以采用 1GB 的大页,进一步减少 TLB miss。
3. 采用 DDIO 技术,使网卡和 CPU 通过 LLC Cache 交换数据, 绕过内存
4. 多通道内存并行访问:假设现在单个 CPU 芯片有两个通道,每个通道上有 4 个 rank。我们可以在两个数据包所占用的地址间加入填充(padding),使得两个数据包的起始地址属于不同通道的不同 rank,这样 CPU 上不同的核/线程就可以同时处理这两个数据包了。
5. 缓存的分配和释放消耗时间的问题:提前从“堆”中申请一大块内存 ,作为内存池,再从内存池中快速获取缓存:
对于需要频繁分配/释放的数据结构,最典型的就是管理和保存数据包的数据结构,可以采用内存池的方式预先动态分配一整块内存区域,然后统一进行管理并提供更快速的分配和 回收,从而免除频繁地动态分配/释放过程,既提高了性能,也减少了内存碎片的产生。这就是 DPDK 中 mempool 机制出现的原因。DPDK 中,数据包的内存操作对象被抽象为 mbuf,其对应的 struct rte_mbuf 数据结构对象存储在内存池中。DPDK 以环形队列(ring)的形式组织内存池中空闲或被占用的内存。此外还考虑了地址和 Cache Line 对齐等因素,以提升性能。
4.5. CPU 亲和性
DPDK 可以将不同的处理线程(lcore)绑定到特定的 CPU 核上,避免了线程在核间迁移带来的缓存失效问题,保证了数据处理的局部性和稳定性。
5. 如何使用 DPDK 接管网卡进行测试
5.1. 编译 DPDK
DPDK 官方网站提供了 DPDK 的下载,读者可访问该网站下载最新版本的 DPDK 并学习其使用方法。
下载 DPDK 源代码压缩包后,首先解压压缩包,进入其根目录,先后运行以下两条命令编译 DPDK。
//生成配置文件,并要求编译 examples 目录下的所有示例
meson -Dexamples=all build
//编译 DPDK
ninja -C build
//如果要把 DPDK 安装到系统中, 需要把第二条命令改为如下命令(或者再运行一次):
//编译并安装 DPDK
sudo ninja -C build install
// 然后运行如下命令:
//使新安装的动态库在系统中生效
ldconfig5.2. 不使用轮询模式驱动程序(PMD)的情况下运行
DPDK 应用程序可以在不使用轮询模式驱动程序(PMD)的情况下运行,此时,其使用 的是 Linux 内核中的网卡驱动程序。
sudo build/app/dpdk-testpmd -c7 --vdev=net_pcap0,iface=ens2f0 --vdev=net_pcap1, iface=ens2f1 --
-i --nb-cores=2 --nb-ports=2iface=ens2f0 和 iface=ens2f1 指定了两个目标网络接口,其中的 ens2fX 就是执行 ifconfig 命令看到的操作系统中抽象的两个网络接口的名称,分别对应 I350 网卡的两个物理接口。这也意味着此次使用的是 Linux 内核中的网卡驱动程序。
-c7 选项指定本次运行使用的 CPU 核(逻辑核)。其中的 7,用 8 位二进制数表示为 0b00000111,它的低 3 位为 1,表示本次运行将使用编号最小的 3 个核,即核 0、核 1 和核 2。具体执行时,DPDK 应用程序会使用核 0 运行主线程,负责初始化和管理,其他两个核负责转发数据包。
--nb-cores=2 表示本次运行使用 2 个核负责接收和发送数据包。如果没有指定其他参数,DPDK 会把 2 个核按照编号依次分配给两个接口,分别负责接收两个接口的数据包,并从另一个接口发送出去。
--nb-ports=2 表示本次测试使用两个网络接口。
5.3. 使用轮询模式驱动程序运行 dpdk-testpmd
- 配置 1GB 大页
编辑 /etc/default/grub 文件,在 GRUB_CMDLINE_LINUX 变量中添加内核启动参数:
default_hugepagesz=1G hugepagesz=1G hugepages=8,这里的 hugepages=8 表示预留 8 个 1GB 大页,总计 8GB 内存。
2. 运行 sudo grub2-mkconfig -o /boot/grub2/grub.cfg 使配置生效
3. 重启系统:sudo reboot。
4. 系统重启后,使用以下命令验证:
# 查看概要信息
grep Huge /proc/meminfo
# 在 NUMA 系统中,可查看每个节点的详细分配
cat /sys/devices/system/node/node0/hugepages/hugepages-1048576kB/nr_hugepages
cat /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/nr_hugepages5. 挂载大页文件系统:
mkdir -p /mnt/huge
mount -t hugetlbfs nodev /mnt/huge -o pagesize=1G若想永久挂载,可将下面这行添加到 /etc/fstab 中
nodev /mnt/huge hugetlbfs pagesize=1G 0 06. 配置 2MB 大页
2MB 大页支持动态配置,无需重启系统
# 为每个 NUMA 节点预留 1024 个 2MB 大页(共约 2GB/节点)
echo 1024 | sudo tee /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages
echo 1024 | sudo tee /sys/devices/system/node/node1/hugepages/hugepages-2048kB/nr_hugepages- 启动时配置(永久生效):同样可修改 GRUB 参数
default_hugepagesz=2M hugepagesz=2M hugepages=2048,然后更新 GRUB 并重启 - 为 2MB 大页创建独立的挂载点:
mkdir -p /mnt/huge_2m
mount -t hugetlbfs nodev /mnt/huge_2m -o pagesize=2MB
永久挂载则在 /etc/fstab 中添加:
nodev /mnt/huge_2m hugetlbfs pagesize=2MB 0 07. 配置后,可通过以下命令监控大页使用情况:
# 查看大页总体使用情况
cat /proc/meminfo | grep Huge
# 查看特定进程的大页使用情况(将 PID 替换为实际进程 ID)
grep -i huge /proc/<PID>/smaps
# 监控 TLB 性能,评估大页带来的性能提升(需安装 perf)
perf stat -e dTLB-loads,dTLB-load-misses -p <PID>8. 禁用网络接口
sudo ifconfig ens2f0 down
sudo ifconfig ens2f1 down9. 加载 UIO 驱动程序
sudo modprobe uio_pci_generic10. 识别网卡 PCI 地址
lspci | grep I350
// 输出示例:
02:00.0 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01)
02:00.1 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01)11. 绑定网卡到 UIO 驱动
sudo ./usertools/dpdk-devbind.py --bind=uio_pci_generic 02:00.0
sudo ./usertools/dpdk-devbind.py --bind=uio_pci_generic 02:00.112. 验证驱动绑定状态
./usertools/dpdk-devbind.py --status-dev net
// 输出示例:
Network devices using DPDK-compatible driver
============================================
0000:02:00.0 『I350 Gigabit Network Connection 1521』 drv=uio_pci_generic unused=igb,vfio-pci
0000:02:00.1 『I350 Gigabit Network Connection 1521』 drv=uio_pci_generic unused=igb,vfio-pci13. 启动 DPDK 测试工具
sudo build/app/dpdk-testpmd -c7 -- -i --nb-cores=2 --nb-ports=2参数说明配置值-c7CPU 核心掩码 (二进制 111)使用 3 个 CPU 核心-- -i交互模式启用命令行接口--nb-cores数据处理核心数 2--nb-ports绑定网卡端口数
参数 | 说明 | 配置值 |
|---|---|---|
-c7 | CPU核心掩码 (二进制 111) | 使用3个CPU核心 |
-- -i | 交互模式 | 启用命令行接口 |
--nb-cores | 数据处理核心数 | 2 |
--nb-ports | 绑定网卡端口数 | 2 |
2
6. 如何编写适配特定网卡的 DPDK 驱动
实现 DPDK 驱动需要注意以下几点:
- 正确配置硬件资源:包括巨页内存、PCI 设备绑定和中断处理
- 遵循 DPDK 框架规范:实现必要的回调函数和数据结构
- 优化数据路径性能:减少不必要的操作,使用批量处理和缓存优化
- 确保数据一致性:正确使用内存屏障和 volatile 关键字
- 提供完善的调试支持:实现日志记录和性能统计功能
6.1. 驱动注册机制
DPDK 驱动通过宏注册到框架中,以下是 Corundum 网卡驱动的注册示例
RTE_PMD_REGISTER_PCI(net_mqnic_igb, rte_mqnic_pmd);
RTE_PMD_REGISTER_PCI_TABLE(net_mqnic_igb, pci_id_mqnic_map);
RTE_PMD_REGISTER_KMOD_DEP(net_mqnic_igb, 「uio_pci_generic」);这些宏分别完成以下功能:
RTE_PMD_REGISTER_PCI: 注册 PCI 驱动程序主体
RTE_PMD_REGISTER_PCI_TABLE: 注册驱动支持的设备 ID 表
RTE_PMD_REGISTER_KMOD_DEP: 声明依赖的内核模块
6.2. PCI 设备标识
驱动需要定义支持的设备 ID 表,用于匹配硬件设备
static const struct rte_pci_id pci_id_mqnic_map[] = {
{ RTE_PCI_DEVICE(MQNIC_INTEL_VENDOR_ID, MQNIC_DEV_ID) },
{ .vendor_id = 0, }, /* 结束标记 */
};
#define MQNIC_INTEL_VENDOR_ID 0x1234
#define MQNIC_DEV_ID 0x10016.3. 驱动结构体定义
PCI 驱动核心结构体包含了驱动的主要信息
static struct rte_pci_driver rte_mqnic_pmd = {
.id_table = pci_id_mqnic_map,
.drv_flags = RTE_PCI_DRV_NEED_MAPPING,
.probe = eth_mqnic_pci_probe,
.remove = eth_mqnic_pci_remove,
};其中:
id_table 用于设备匹配
drv_flags 设置驱动标志(如需要地址映射)
probe 是设备检测回调函数
remove 是设备移除回调函数
6.4. 设备探测与初始化
当 DPDK 检测到匹配的 PCI 设备时,会调用 probe 函数:
static int eth_mqnic_pci_probe(struct rte_pci_driver *pci_drv,
struct rte_pci_device *pci_dev)
{
return rte_eth_dev_pci_generic_probe(pci_dev,
sizeof(struct mqnic_adapter), eth_mqnic_dev_init);
}probe 函数通常调用通用辅助函数 rte_eth_dev_pci_generic_probe,该函数会创建以太网设备并调用设备特定的初始化函数。
6.5. 设备初始化函数
设备初始化函数 eth_mqnic_dev_init 负责设置设备的基本操作函数和数据结构
static int eth_mqnic_dev_init(struct rte_eth_dev *eth_dev)
{
// 注册操作函数集
eth_dev->dev_ops = ð_mqnic_ops;
eth_dev->rx_pkt_burst = ð_mqnic_recv_pkts;
eth_dev->tx_pkt_burst = ð_mqnic_xmit_pkts;
// 获取 PCI 设备信息
struct rte_pci_device *pci_dev = RTE_ETH_DEV_TO_PCI(eth_dev);
// 映射硬件寄存器空间
hw->hw_addr = (void *)pci_dev->mem_resource[0].addr;
hw->hw_regs_size = pci_dev->mem_resource[0].len;
// 识别硬件和获取基本信息
mqnic_identify_hardware(eth_dev, pci_dev);
mqnic_get_basic_info_from_hw(hw);
// 获取 MAC 地址
if (mqnic_read_mac_addr(hw) != 0) {
PMD_INIT_LOG(ERR, 「EEPROM error while reading MAC address」);
return -EIO;
}
// 其他初始化操作...
return 0;
}6.6. 设备操作函数集
DPDK 驱动通过 eth_dev_ops 结构体注册各种操作回调函数
static const struct eth_dev_ops eth_mqnic_ops = {
.dev_configure = eth_mqnic_configure,
.dev_start = eth_mqnic_start,
.dev_stop = eth_mqnic_stop,
.dev_close = eth_mqnic_close,
.dev_reset = eth_mqnic_reset,
.promiscuous_enable = eth_mqnic_promiscuous_enable,
.promiscuous_disable = eth_mqnic_promiscuous_disable,
.link_update = eth_mqnic_link_update,
.stats_get = eth_mqnic_stats_get,
.stats_reset = eth_mqnic_stats_reset,
.dev_infos_get = eth_mqnic_infos_get,
.rx_queue_setup = eth_mqnic_rx_queue_setup,
.rx_queue_release = eth_mqnic_rx_queue_release,
.tx_queue_setup = eth_mqnic_tx_queue_setup,
.tx_queue_release = eth_mqnic_tx_queue_release,
// ... 其他操作函数
};6.7. 队列创建与配置
int eth_mqnic_tx_queue_setup(struct rte_eth_dev *dev, uint16_t queue_idx,
uint16_t nb_desc, unsigned int socket_id,
const struct rte_eth_txconf *tx_conf)
{
// 验证描述符数量
if (nb_desc % IGB_TXD_ALIGN != 0 ||
nb_desc > MQNIC_MAX_RING_DESC ||
nb_desc < MQNIC_MIN_RING_DESC) {
PMD_INIT_LOG(INFO, 「nb_desc(%d) must > %d and < %d.」,
nb_desc, MQNIC_MIN_RING_DESC, MQNIC_MAX_RING_DESC);
return -EINVAL;
}
// 分配队列数据结构内存
struct mqnic_tx_queue *txq = rte_zmalloc(「ethdev TX queue」,
sizeof(struct mqnic_tx_queue), RTE_CACHE_LINE_SIZE);
// 设置队列参数
txq->size = roundup_pow_of_two(nb_desc);
txq->size_mask = txq->size - 1;
txq->buf_size = txq->size * txq->stride;
// 分配 DMA 内存区域
const struct rte_memzone *tz = rte_eth_dma_zone_reserve(dev, 「tx_ring」,
queue_idx, txq->buf_size, MQNIC_ALIGN, socket_id);
txq->tx_ring_phys_addr = tz->iova; // 物理地址
txq->tx_ring = (struct mqnic_desc *) tz->addr; // 虚拟地址
// 分配软件环
txq->sw_ring = rte_zmalloc(「txq->sw_ring」,
sizeof(struct mqnic_tx_entry) * txq->nb_tx_desc,
RTE_CACHE_LINE_SIZE);
// 计算硬件寄存器地址
txq->hw_addr = priv->hw_addr + priv->tx_queue_offset +
queue_idx * MQNIC_QUEUE_STRIDE;
// 初始化队列
mqnic_reset_tx_queue(txq, dev);
dev->data->tx_queues[queue_idx] = txq;
return 0;
}
int eth_mqnic_rx_queue_setup(struct rte_eth_dev *dev, uint16_t queue_idx,
uint16_t nb_desc, unsigned int socket_id,
const struct rte_eth_rxconf *rx_conf,
struct rte_mempool *mb_pool)
{
// 大部分逻辑与发送队列类似...
// 额外保存 mbuf 池指针
rxq->mb_pool = mb_pool;
// 接收队列需要预先分配 mbuf
for (i = 0; i < rxq->nb_rx_desc; i++) {
struct rte_mbuf *mbuf = rte_mbuf_raw_alloc(rxq->mb_pool);
if (mbuf == NULL) {
PMD_INIT_LOG(ERR, 「RX mbuf alloc failed queue_id=%hu」,
rxq->queue_id);
return -ENOMEM;
}
// 设置描述符地址
dma_addr = rte_cpu_to_le_64(rte_mbuf_data_iova_default(mbuf));
rxd = &rxq->rx_ring[i];
rxd->addr = dma_addr;
rxd->len = mbuf->buf_len;
// 保存 mbuf 指针到软件环
rxe[i].mbuf = mbuf;
}
return 0;
}6.8. 数据包处理
uint16_t eth_mqnic_recv_pkts(void *rx_queue, struct rte_mbuf **rx_pkts,
uint16_t nb_pkts)
{
struct mqnic_rx_queue *rxq = rx_queue;
uint16_t nb_rx = 0;
while (nb_rx < nb_pkts) {
// 检查是否有新数据包到达
if (mqnic_is_rx_queue_empty(rxq))
break;
// 获取描述符和对应的 mbuf
volatile struct mqnic_desc *rxd = &rxq->rx_ring[rxq->tail_ptr];
struct rte_mbuf *rxm = rxq->sw_ring[rxq->tail_ptr].mbuf;
// 确保数据已由硬件 DMA 完成
rte_rmb();
// 验证数据包长度
if (unlikely(rxd->len == 0 || rxd->len > rxq->max_pkt_len)) {
// 错误处理
continue;
}
// 设置 mbuf 参数
rxm->data_off = RTE_PKTMBUF_HEADROOM;
rxm->nb_segs = 1;
rxm->next = NULL;
rxm->pkt_len = rxd->len;
rxm->data_len = rxd->len;
rxm->port = rxq->port_id;
// 存储接收时间戳(如果有硬件支持)
if (rxq->hw_timestamp_en)
rxm->timestamp = mqnic_get_rx_timestamp(rxq);
// 将 mbuf 返回给应用程序
rx_pkts[nb_rx] = rxm;
nb_rx++;
// 分配新的 mbuf 替换已使用的
struct rte_mbuf *nmb = rte_mbuf_raw_alloc(rxq->mb_pool);
if (unlikely(nmb == NULL)) {
// 处理分配失败
break;
}
// 更新描述符
dma_addr = rte_cpu_to_le_64(rte_mbuf_data_iova_default(nmb));
rxd->addr = dma_addr;
rxd->len = nmb->buf_len;
// 更新软件环
rxq->sw_ring[rxq->tail_ptr].mbuf = nmb;
// 移动尾指针
rxq->tail_ptr = (rxq->tail_ptr + 1) & rxq->size_mask;
}
// 更新硬件尾指针,告知硬件已处理的描述符
MQNIC_DIRECT_WRITE_REG(rxq->hw_tail_ptr, 0,
rxq->tail_ptr & rxq->hw_ptr_mask);
return nb_rx;
}6.9. 内存屏障的正确使用
// 写屏障:确保所有先前的写操作在之后的写操作之前完成
rte_wmb();
// 读屏障:确保所有先前的读操作在之后的读操作之前完成
rte_rmb();
// 全屏障:确保所有先前的内存操作在之后的内存操作之前完成
rte_mb();
在以下位置需要使用内存屏障:
•更新描述符后,通知硬件之前
•读取硬件状态寄存器之前
•多核间共享数据访问时6.10. volatile 关键字的使用
// 正确使用 volatile 访问硬件寄存器
#define MQNIC_DIRECT_READ_REG(addr) (*(volatile uint32_t *)(addr))
// 错误示例:编译器可能优化掉「冗余」的读取操作
uint32_t read_status(void) {
uint32_t status = *reg_addr;
// 编译器可能认为第二次读取是冗余的
status = *reg_addr;
return status;
}6.11. 避免耗时操作在关键路径
// 错误做法:在快速路径中检查完成情况
for (i = 0; i < nb_pkts; i++) {
mqnic_check_tx_cpl(txq); // 耗时操作
// 处理数据包...
}
// 正确做法:批量检查完成情况
mqnic_check_tx_cpl(txq); // 一次检查所有
for (i = 0; i < nb_pkts; i++) {
// 处理数据包...
}6.12. 缓存预取优化
// 预取下一个描述符
rte_prefetch0(&txr[tx_id + 1]);
// 预取 mbuf 数据
RTE_MBUF_PREFETCH_TO_FREE(txe->mbuf[0]);6.13. 批量处理优化
// 单包处理:高开销
for (i = 0; i < nb_pkts; i++) {
process_one_packet(pkts[i]);
}
// 批量处理:低开销
process_batch_of_packets(pkts, nb_pkts);6.14. 日志记录
// 定义驱动日志类型
RTE_LOG_REGISTER(mqnic_logtype, PMD_DRV_LOG_LEVEL);
// 记录不同级别的日志
PMD_INIT_LOG(DEBUG, 「Initializing mqnic device」);
PMD_INIT_LOG(INFO, 「Device configured with %u queues」, num_queues);
PMD_INIT_LOG(ERR, 「Failed to allocate memory for queue」);6.15. 性能统计
// 在驱动结构体中定义统计信息
struct mqnic_stats {
uint64_t opackets;
uint64_t obytes;
uint64_t ipackets;
uint64_t ibytes;
uint64_t ierrors;
uint64_t oerrors;
};
// 实现统计回调函数
static int eth_mqnic_stats_get(struct rte_eth_dev *dev,
struct rte_eth_stats *stats)
{
struct mqnic_priv *priv = dev->data->dev_private;
stats->ipackets = priv->stats.ipackets;
stats->opackets = priv->stats.opackets;
stats->ibytes = priv->stats.ibytes;
stats->obytes = priv->stats.obytes;
stats->ierrors = priv->stats.ierrors;
stats->oerrors = priv->stats.oerrors;
return 0;
}7. Reference
Linux 高性能网络详解:从 DPDK、RDMA 到 XDP
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号