AI Compass前沿速览:Jetson Thor英伟达AI计算、Gemini 2.5 Flash Image、Youtu腾讯智能体框架、Wan2.2-S2V
原创
AI Compass前沿速览:Jetson Thor英伟达AI计算、Gemini 2.5 Flash Image、Youtu腾讯智能体框架、Wan2.2-S2V
原创
汀丶人工智能
发布于 2025-08-28 22:24:33
发布于 2025-08-28 22:24:33
AI Compass前沿速览:Jetson Thor英伟达AI计算、Gemini 2.5 Flash Image、Youtu腾讯智能体框架、Wan2.2-S2V多模态视频生成、SpatialGen 3D场景生成模型
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
1.每周大新闻
AI钉钉1.0
钉钉举办十周年暨AI钉钉1.0新品发布会,发布8.0版本。钉钉CEO无招表示将为AI时代打造全新钉钉。此次发布的钉钉8.0有全新设计,实现全球化升级,推出五大AI原生产品,在客服、营销、教育等场景重构解决方案,还设有创业助理、“你的钉钉”等特色服务,同时升级应用服务市场和企业服务体系。
核心功能
- 全新设计:界面简洁高效,AI智能推荐,设“效率岛”。
- 全球化:“一个钉钉”解决出海难题,降本增效。
- AI原生产品:钉钉ONE处理消息;DingTalk A1智能听写;AI听记实现语音智能;AI搜问“一框问天下”;AI表格搭建应用平台。
- 行业场景方案:客服、营销、教育场景用AI重构。
- 创业助理:为初创企业提供一站式AI助理。
- “你的钉钉”:为中大型企业提供专属定制和AI服务。
- 应用市场升级:设严选标准,分多个市场,改变商业模式。
技术原理
- AI听记:用强大语音智能模型,经1亿小时音频学习,结合通讯录等专项训练,提升准确率。
- AI搜问:打造文本搜索引擎2.0、知识图谱搜索引擎和AI - Fusion引擎1.0,有企业级安全控制。
- AI表格:采用O - Table存算一体架构,含IVM实时增量引擎和Lightning Fusion协同引擎。
- AI客服:建立真题数据集、模型训练和效果评估工程,用大模型体系。
Jetson Thor – 英伟达推出的机器人AI计算平台

jetson.jpg
核心功能
- 高性能AI计算: 提供高达2070 FP4 TFLOPS(或超过1000 TOPS)的AI算力,是前一代AGX Orin的7.5倍,性能显著提升。
- 大容量内存: 配备128GB高速显存,支持处理大规模AI模型和复杂数据。
- 高效能比: 在40-130W的功耗范围内,提供3.5倍于AGX Orin的能效。
- 先进的I/O接口: 支持丰富的输入/输出连接,适用于各种边缘设备和传感器集成。
- 优化软件支持: 支持模型转换为TensorRT,集成DeepStream,多模型并发,以及FP8/INT8格式的性能优化。
技术原理
Jetson Thor基于英伟达最新的Blackwell GPU架构。该架构提供了强大的计算能力,特别是在FP4(四精度浮点)算力方面有显著提升。其高AI吞吐量得益于先进的GPU核心、专用的AI加速器以及高效的内存带宽。通过利用TensorRT等软件工具,可以对AI模型进行优化,进一步提高推理性能和效率。同时,它还支持硬件/软件集成,包括BSP(板级支持包)服务、设备树定制、内核调优和电源配置文件配置。
应用场景
- 高级机器人: 用于开发和部署具有复杂AI能力的机器人系统。
- 自动驾驶车辆: 为自动驾驶车辆提供强大的边缘AI推理能力。
- AI推理服务器: 作为边缘AI推理的服务器,处理大量的AI计算任务。
- 工业检测系统: 应用于工业自动化和质量控制中的AI视觉检测。
- 医疗成像设备: 支持医疗设备中的实时AI分析和诊断。
- 边缘生成式AI: 在边缘设备上部署和运行生成式AI模型。
Grok 2.5 – xAI
xAI的Grok 2.5是由埃隆·马斯克旗下xAI公司开源的人工智能模型。该模型作为早期版本,其模型权重已在Hugging Face平台发布,旨在供广大开发者和研究人员访问与使用,以促进AI社区的进一步发展。
核心功能
Grok 2.5作为一款AI聊天机器人,具备提供帮助性、安全且详细答案的能力。作为一个大型语言模型(LLM),其核心功能在于理解并响应自然语言输入,进行多轮对话,并生成高质量的文本内容。
技术原理
Grok 2.5的技术原理基于其已公开的预训练模型权重。这表明它是一个通过大规模数据训练的深度学习模型。虽然具体架构未详述,但作为先进的LLM,其底层很可能采用了Transformer等主流的神经网络结构,通过复杂的计算和参数学习实现对语言模式的掌握及文本生成能力。
应用场景
Grok 2.5的开源特性使其在以下场景中具有广泛的应用潜力:
- 对话式AI应用构建: 可作为基础模型用于开发智能客服、个人助手、问答系统以及其他交互式AI产品。
- AI模型研究与定制: 研究人员和开发者可利用其模型权重进行模型微调、性能评估、新算法验证等,以适应特定领域或任务需求。
- 内容生成与信息检索: 协助用户进行信息查询、文本摘要、创意写作等多种内容生成任务。
HuggingFace模型库:https://huggingface.co/xai-org/grok-2
Gemini 2.5 Flash Image – 谷歌推出的图像生成和编辑模型(nano-banana)
Google Gemini 2.5 Flash Image(代号“nano-banana”)是Google推出的一款领先的图像生成和编辑模型。作为Gemini 2.5系列模型的一部分,它旨在提供高效、高质量的视觉内容创作能力,并通过整合Gemini的世界知识,实现对图像内容更深层次的语义理解和更精确的控制。该模型已通过API面向开发者开放,可在Google AI Studio和Vertex AI等平台使用。

gemini2-5.png
核心功能
- 高级图像生成与编辑: 能够依据文本提示生成全新图像,并对现有图像进行精细化编辑。
- 多图融合: 支持将多张图片智能地融合为一张,实现创意合成。
- 角色一致性维持: 在多张图片生成或编辑过程中,能保持特定角色或主题的视觉一致性。
- 自然语言精准控制: 用户可通过自然语言指令对图像进行定向变换,如更改颜色、添加或删除物体等。
- 内置世界知识: 利用Gemini的广博知识库,生成和编辑的图像更符合现实逻辑,具备更强的语义理解能力。
- 低延迟处理: 相较于其他同类模型,提供更快的图像处理和生成速度。
- 数字水印: 所有通过此模型生成或编辑的图片均内嵌不可见的SynthID数字水印,以标识其AI生成来源。
技术原理
Gemini 2.5 Flash Image模型基于先进的深度学习架构,融合了Transformer网络和扩散模型(Diffusion Models)的优势。其核心在于利用大规模数据集进行训练,使其能够理解复杂的视觉概念和语言指令之间的映射关系。模型通过多模态融合技术,将图像特征与Gemini模型的知识图谱相结合,从而实现对“世界知识”的内在理解,使其不仅能生成美学上令人满意的图像,还能在语义层面把握真实世界中的物体、场景和逻辑关系。其低延迟特性表明在模型结构、计算优化或推理路径上进行了高效设计。数字水印技术则利用隐写术在像素级别嵌入数据,确保图片来源的可追溯性。
应用场景
- 创意内容生成: 艺术家、设计师和内容创作者可用于快速生成概念图、插画、广告素材或进行图像风格探索。
- 产品设计与营销: 快速生成不同角度、场景或变体的产品图像,进行虚拟试穿、家装设计预览等。
- 个性化故事创作: 通过保持角色一致性,为漫画、动画或故事板提供连贯的视觉支持。
- 视觉资产管理: 对现有图像进行批量编辑或优化,提升视觉内容生产效率。
- AI辅助设计工具: 开发者可将模型集成到各类设计软件、图片编辑应用或在线工具中,赋能用户以自然语言进行高级图像操作。
- 教育与研究: 作为理解和应用多模态AI的工具,用于学术研究或教学演示。
- 项目官网:https://developers.googleblog.com/en/introducing-gemini-2-5-flash-image/
- 体验地址:https://ai.studio/banana
2.每周项目推荐
Youtu-agent – 腾讯优图智能体框架
Youtu-agent是腾讯优图实验室推出的开源智能体框架,旨在构建、运行和评估自主智能体。该框架以其模块化和可扩展性为设计核心,支持开发者轻松创建定制化的智能体、工具和环境,并基于开源模型DeepSeek-V3实现了领先性能,致力于简化智能体开发流程。
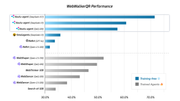
youtu.png

youtu1.png
核心功能
- 智能体构建与配置: 支持灵活的YAML配置和自动智能体生成,用于定义智能体的行为、所使用的工具和运行环境。
- 多模型与工具集成: 兼容多种模型API,并提供丰富的工具包(如网络搜索、文件操作),扩展智能体的能力范围。
- 数据分析与处理: 具备自动读取、分析CSV文件并生成数据报告的能力。
- 文件管理与组织: 辅助用户自动分类、命名和存储文件。
- 研究与内容生成: 能够自动搜索、整理文献生成综述报告,或根据需求生成网页内容、视频脚本。
- 性能评估: 提供一套全面的评估框架,用于基准测试智能体性能,包括数据管理、处理和自动化执行与判断。
技术原理
Youtu-agent 的核心架构遵循清晰的职责分离原则,主要由以下模块构成:
- AgentConfig: 智能体的配置文件,采用YAML格式,定义智能体的行为、工具集和环境参数。
- Agent: 智能体的核心逻辑单元,依据AgentConfig运行,并能执行任务,支持单一智能体(如SimpleAgent)或多智能体协同工作(如OrchestraAgent)。
- Environment: 提供智能体与外部世界交互的接口,例如
BrowserEnv支持网页操作,ShellLocalEnv支持本地文件系统访问。 - Toolkits: 智能体的能力集合,包含可调用的各种工具,如
search工具用于网络搜索,file工具用于文件操作。 - Evaluation Framework: 用于评估智能体性能的标准化框架,包含数据管理、处理和执行等管道,确保评估的准确性和可重现性。框架的设计理念是构建在底层模型(如DeepSeek-V3)之上,通过灵活的组件组合实现复杂任务。
- 项目官网:https://tencent.github.io/Youtu-agent/
- GitHub仓库:https://github.com/Tencent/Youtu-agent
Wan2.2-S2V – 阿里多模态视频生成模型
Wan2.2是由腾讯AI团队开发的一款先进的音视频生成模型,尤其以Wan2.2-S2V-14B和Wan2.2-5B模型为代表。它旨在提供高质量、高清晰度的视频生成能力,支持文本到视频(T2V)、图像到视频(I2V)以及音频驱动的电影级视频生成,并通过优化模型架构和数据训练,实现了在消费级GPU上的高效运行。

2-2.png

2-2-1.png
核心功能
- 多模态视频生成: 能够根据文本描述、图像或音频输入,生成高质量、电影级的视频内容。
- 高分辨率与帧率支持: 支持生成720P分辨率、24帧每秒(fps)的视频输出。
- 复杂运动与美学生成: 通过大量数据训练,显著增强了模型在运动、语义和美学方面的泛化能力,能够生成具有丰富细节、光影和情绪的视频。
- 高效推理: 优化了计算效率,支持在NVIDIA RTX 4090等消费级显卡上快速生成视频。
- 易于集成与部署: 提供推理代码和模型权重,并已集成到ComfyUI、ModelScope Gradio和HuggingFace Gradio等平台。
技术原理
Wan2.2在技术上进行了多项创新。核心模型如Wan2.2-S2V-14B采用了14B参数,而TI2V-5B模型则结合了先进的Wan2.2-VAE,实现了16×16×4的高压缩比,从而在保证生成质量的同时显著提升了效率并降低了计算资源需求。模型在训练阶段使用了比Wan2.1更庞大的数据集(图片和视频数量分别增加65.6%和83.2%),并特别注重对数据进行美学标签(如光照、构图、色调)的标注,使得模型能够学习和生成具有视觉吸引力的视频。此外,它可能采用了类似“专家混合”(Mixture-of-Experts)的路由机制,根据信噪比(SNR)动态切换不同的专家模型来处理视频生成的不同阶段,例如一个专家处理高噪声的早期帧,另一个处理细节添加,从而在不增加总计算量的情况下提升输出质量和连贯性。
- 官网:https://tongyi.aliyun.com/wanxiang/welcome#s2v
- Github:https://github.com/Wan-Video/Wan2.2
- 魔搭社区:https://www.modelscope.cn/models/Wan-AI/Wan2.2-S2V-14B
- HuggingFace:https://huggingface.co/Wan-AI/Wan2.2-S2V-14B
EchoMimicV3 – 蚂蚁多模态数字人视频生成框架
EchoMimicV3 是蚂蚁集团推出的一款高效的多模态、多任务数字人视频生成框架。该框架拥有13亿参数,旨在统一和简化数字人动画生成过程,能够通过音频、图像或两者结合,生成逼真的人物肖像视频。它采用了任务混合和模态混合范式,并结合了新颖的训练与推理策略,使得其生成质量可与参数量大10倍的模型媲美。
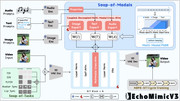
Echo-Mimic-V3.jpg

Echo-Mimic-V3-1.jpg
核心功能
EchoMimicV3 的核心功能包括:
- 统一的多任务人体动画生成: 能够处理唇形同步、音频驱动全身动画以及从起始帧到结束帧的视频生成等多种人体动画任务。
- 多模态融合能力: 支持结合文本、图像和音频等多种模态条件,以生成更丰富、更具表现力的数字人视频。
- 高效率与高质量: 尽管参数量相对较小(1.3亿),但通过优化设计和训练策略,实现了与大型模型相当的生成质量。
- 音频驱动肖像动画: 能够赋予静态图像生动的语音和表情,生成高度逼真的动态肖像视频。
技术原理
EchoMimicV3 的技术原理基于以下核心设计:
- 统一的多任务范式 (Unified Multi-Task Paradigm): 受MAE(Masked Autoencoders)启发,将不同的人体动画生成任务视为时空局部重建问题,通过仅修改输入端来适应各种生成任务。
- 多模态解耦交叉注意力模块 (Multi-Modal Decoupled Cross-Attention Module): 针对文本、图像和音频等多种模态条件,引入该模块以“分而治之”的方式融合多模态信息,有效处理不同模态间的相互作用与划分。
- SFT+奖励交替训练范式 (SFT+Reward Alternating Training Paradigm): 采用监督微调(SFT)与奖励模型交替训练的策略,通过对齐人类偏好,提升模型性能,使得小参数模型也能达到卓越的生成效果。
应用场景
EchoMimicV3 在数字人生成领域具有广泛的应用前景,包括但不限于:
- 虚拟主播/数字员工: 用于创建逼真的虚拟形象,在新闻播报、客服、教育培训等领域提供交互服务。
- 内容创作: 助力视频创作者快速生成高质量的数字人视频内容,如短视频、广告、动画片等。
- 虚拟人直播: 提供更生动、自然的数字人直播体验,降低真人出镜成本。
- 个性化营销: 生成定制化的数字人形象,用于产品宣传和品牌推广。
- 娱乐与游戏: 在虚拟偶像、游戏角色动画等方面提供技术支持,增强用户体验。
项目官网:https://antgroup.github.io/ai/echomimic_v3/
- GitHub仓库:https://github.com/antgroup/echomimic_v3
- HuggingFace模型库:https://huggingface.co/BadToBest/EchoMimicV3
- arXiv技术论文:https://arxiv.org/pdf/2507.03905
Prompt Optimizer – 开源AI提示词优化工具
AI Prompt Optimizer(AI提示词优化器)是一个专业的提示词工程工具或平台,旨在帮助用户优化AI模型的提示词(prompts),从而提升AI交互的效率和准确性,并改善大型语言模型(LLM)的输出质量。它通过智能化方法,将用户的想法转化为更精确、更有效的提示词。
核心功能
- 智能提示词优化: 利用智能优化算法,对用户输入的提示词进行分析和改进,生成更符合最佳实践的优化提示词。
- 深度推理分析: 提供对提示词的深度分析能力,帮助用户理解提示词的效果。
- 可视化调试与评估: 可能包含可视化工具,以便用户调试和评估优化后的提示词效果。
- 多模型支持: 支持优化针对不同AI模型(如GPT-4、Claude、Midjourney等)的提示词。
- 任务辅助: 通过AI辅助,将用户想法转化为精确提示,从而完成特定任务并生成高质量内容。
- 社区共享: 提供社区功能,促进用户间的提示词分享和交流。
技术原理
- 智能优化算法: 采用复杂的算法来分析和改进提示词,可能包括基于模型反馈的迭代优化。
- 深度学习与大型语言模型(LLM): 依赖于先进的LLM(如OpenAI的GPT系列或Google的Gemini)的能力,理解和生成文本。
- 提示词工程最佳实践: 结合OpenAI和Google等平台发布的提示词工程指导原则和最佳实践,例如零样本/少样本提示、添加上下文、分解提示等。
- 上下文管理与模型优化: 利用模型的大上下文窗口进行信息处理,并通过模型优化、微调等技术提升提示词的效果。
- AI辅助生成: 通过内置的辅助聊天机器人将用户非结构化的想法转化为结构化、优化的提示。
应用场景
- 提升AI模型输出质量: 适用于任何需要与LLM交互并追求更高质量、更准确输出的用户和开发者。
- 内容创作与优化: 帮助内容创作者生成更具吸引力、更精准的文案、文章或其他媒体内容。
- 自动化客服与问答: 优化AI客服机器人的提示词,提升其理解用户意图和提供准确答案的能力。
- 企业内部AI工具开发: 协助企业构建定制化的AI工具,如自动化培训、加速研究、洞察客户需求等。
- AI应用开发与调试: 为AI开发者提供高效的提示词测试、评估和部署机制,简化集成流程。
- 教育与研究: 辅助学生和研究人员更好地利用AI模型进行学习和数据分析。
- Github仓库:https://github.com/linshenkx/prompt-optimizer
VibeVoice – 微软文本转语音模型
VibeVoice是微软推出的一款前沿的开源文本到语音(TTS)模型,专为生成富有表现力、长篇幅、多说话者的对话式音频而设计。它旨在解决传统TTS系统在长音频生成、多说话者连贯性和自然对话流方面的挑战,特别适用于播客、有声读物等场景。VibeVoice目前主要用于研究目的,并已开源,提供1.5B和7B参数版本。

vibevoice.png
核心功能
- 长篇幅音频生成: 能够生成长达90分钟的对话式音频。
- 多说话者支持: 可合成多达4个不同说话者的语音,并保持其一致性。
- 高表现力与自然度: 生成的语音自然、富有情感,具有对话感。
- 跨语言合成: 支持英语和中文的语音合成。
- 开源可用性: 模型权重开源,供研究人员和开发者使用。
技术原理
VibeVoice的核心技术基于“下一词元扩散框架”(next-token diffusion framework)。它整合了一个大语言模型(LLM),例如VibeVoice-1.5B版本采用了Qwen2.5-1.5B参数的LLM,用于理解文本上下文和对话流。模型通过创新的连续语音标记化技术,即声学(Acoustic)和语义(Semantic)标记器,在超低帧率(7.5 Hz)下高效运行,从而在处理长序列时保持高音频保真度并显著提升计算效率。最后,一个扩散头(diffusion head)负责生成高保真度的声学细节。
应用场景
- 播客制作: 生成多说话者、长时间的播客内容。
- 有声读物: 自动生成或辅助制作具有自然语音和情感起伏的有声读物。
- 合成培训内容: 为教育或企业培训创建逼真的语音材料。
- 对话式AI研究: 作为研究工具,探索长篇幅、多轮对话的AI语音生成。
- 多媒体内容创作: 为视频、动画等多种形式的多媒体内容提供高质量的配音。
项目官网:https://microsoft.github.io/VibeVoice/
- GitHub仓库:https://github.com/microsoft/VibeVoice
- HuggingFace模型库:https://huggingface.co/collections/microsoft/vibevoice-68a2ef24a875c44be47b034f
- 技术论文:https://github.com/microsoft/VibeVoice/blob/main/report/TechnicalReport.pdf
Snowglobe – AI Agent测试工具 ,模拟真实用户对话
Snowglobe 是 Guardrails AI 推出的一款针对AI代理和聊天机器人的模拟测试工具。它通过模拟真实用户行为,快速生成大量多样化的对话数据,旨在帮助开发者在将AI模型部署到生产环境之前,发现并解决潜在问题,提升AI应用的性能、安全性和稳定性。
核心功能
- 模拟真实用户对话: 创建多样化的用户角色、情境、意图、语气和对抗策略,模拟真实的用户交互,发现潜在问题。
- 快速生成对话数据: 在短时间内生成覆盖多种意图、语气和交互策略的大量对话数据,实现全面的测试覆盖。
- 自动评估与标注: 对模拟对话进行自动化评估,标注其准确性、安全性等关键指标,并生成带标签的数据集用于模型优化。
- 可视化分析报告: 提供直观的报告,帮助开发者快速定位问题、分析错误模式,并优化模型性能。
- 易于集成与使用: 支持通过API或SDK与现有系统快速集成,简化测试流程,提高开发效率。
技术原理
Snowglobe 的技术原理核心在于构建一个复杂的LLM仿真环境(Simulation Environment),通过模拟真实世界的用户行为来测试AI应用的鲁棒性。这包括:
- 多角色行为建模: 模拟不同用户角色、意图、语气和对抗策略,生成高覆盖率的对话场景。
- 数据驱动的风险识别: 快速生成大量对话数据,以数据驱动的方式识别边缘案例和潜在故障。
- 自动化评估机制: 采用自动评估算法对模拟对话进行分析,标记关键性能指标(如准确性、安全性),并生成评判标签数据集。
- 借鉴自动驾驶测试方法: 部分借鉴自动驾驶汽车的测试方法,通过大规模模拟来发现和验证高风险场景。
应用场景
- 生成评估与微调数据集: 通过模拟用户对话,快速生成带有评判标签的测试数据集,以及高信号的训练数据(如偏好对和修订三元组),用于AI代理的性能评估和模型微调。
- 发布前质量检测: 在AI应用发布前,进行大规模的真实对话模拟测试,以提前发现人工测试可能遗漏的问题,确保产品质量,并进行回归测试以跟踪错误率。
- AI安全与伦理测试: 针对AI代理的安全性、公平性、偏见等方面进行模拟测试,确保其符合预期的行为规范。
- 法律风险评估: 为法律专业人士提供第三方验证,帮助其理解在AI高风险语境下可能出现的风险,辅助法律决策。
- https://snowglobe.so/
ComoRAG – 华南理工联合微信推出的认知启发式RAG框架
ComoRAG 是由华南理工大学未来技术学院、微信AI团队等机构联合推出的认知启发式检索增强生成(RAG)框架。该框架专门针对长篇叙事文本的理解和推理而设计,能够处理长文档和多文档任务,实现有状态的长期叙事推理。

comorag.png
核心功能
- 长文档与多文档问答: 能够高效地对超长文本和来自多个源文件的信息进行问答。
- 信息提取: 从复杂、冗长的文本中精准抽取出关键数据和事实。
- 知识图谱构建: 具备将非结构化文本信息转化为结构化知识图谱的能力,以支持深层次的知识表示和推理。
- 认知启发式检索增强生成: 融合认知机制来优化信息检索和文本生成过程,提升对复杂上下文的理解和响应质量。
技术原理
ComoRAG 的核心技术原理是其“认知启发式记忆组织检索增强生成”(Cognitive-Inspired Memory-Organized RAG)框架。它通过模拟人类认知过程中的记忆组织和推理机制来处理复杂信息:
- 多层次记忆机制: 旨在有效存储和管理长篇叙事中的关键信息和状态。
- 自适应检索模块: 根据推理需求动态调整检索策略,从庞大的语料库中精确召回相关上下文。
- 知识图谱推理引擎: 利用构建的知识图谱进行符号推理,揭示实体间的复杂关系和事件的逻辑链条。
- 有状态推理能力: 能够维持并利用对话或文本理解过程中的历史状态,实现连贯且深入的长期叙事推理。
- 多模态信息融合: 或许具备处理和整合不同类型信息的能力(未在链接中明确提及但为RAG前沿方向)。
- 模型兼容性: 支持与大型语言模型(LLMs)如通过OpenAI API或本地vLLM服务器进行集成。
应用场景
- 长篇阅读理解与分析: 例如对小说、历史文献、法律条文或医学报告进行深度阅读和分析,抽取关键信息或回答复杂问题。
- 多源信息整合与综合: 在商业智能、科研分析等领域,汇集并理解来自多份报告、文档或数据库的信息。
- 智能客服与虚拟助手: 部署于需要理解用户长段描述或多轮对话上下文的复杂问答场景。
- 知识管理与智能推荐系统: 辅助企业或机构构建更智能的知识库,并基于复杂文本内容提供个性化推荐。
- 内容创作辅助: 为作家、研究员或内容创作者提供基于海量资料的智能信息检索和生成辅助,提高创作效率和质量。
- GitHub仓库:https://github.com/EternityJune25/ComoRAG
- arXiv技术论文:https://arxiv.org/pdf/2508.10419
SlowFast-LLaVA-1.5 – 苹果推出的多模态长视频理解模型
SlowFast-LLaVA-1.5 是苹果公司推出的一款高效视频大语言模型 (VLLM),专为长视频理解和分析而设计。它整合了 SlowFast 网络架构与 LLaVA 1.5 视觉语言模型,旨在不进行额外训练的情况下,提升模型对视频内容的空间细节和长时间序列上下文的理解能力,从而实现视频问答、视频描述生成等多种任务。
核心功能
- 长视频理解与分析:能够处理和理解长时间跨度的视频内容,捕捉视频中的关键事件和信息。
- 视频问答 (Video QA):基于视频内容回答用户提出的自然语言问题,例如“视频中发生了什么?”或“视频中的物体是什么颜色?”。
- 视频描述生成 (Video Captioning):自动生成对视频内容的详细描述或摘要。
- 多模态交互:结合视频的视觉信息和文本的语言信息进行推理和交互。
- 无需训练的基线性能:在不进行额外微调的情况下,在多项视频理解任务上展现出强大的性能。
技术原理
SlowFast-LLaVA-1.5 的核心在于其创新的 SlowFast 输入设计,将视频输入有效地解耦为两个并行流,以捕捉不同粒度的时空信息:
- 慢速流 (Slow Pathway):以较低帧率处理视频帧,捕获视频中缓慢变化的动作和长时间的上下文信息。这有助于理解视频的整体叙事和语义。
- 快速流 (Fast Pathway):以较高帧率处理视频帧,捕获快速变化的动作和精细的空间细节。这有助于识别视频中的瞬时事件和局部特征。 这两个流的特征通过特定的融合机制结合,然后输入到 LLaVA 1.5 视觉语言模型中进行进一步的推理和语言生成。这种双流机制有效地平衡了计算效率和信息捕获的全面性,使其能够高效地处理长视频数据,并从中提取丰富的时空特征。
应用场景
- 视频内容检索与管理:帮助用户通过自然语言查询快速定位视频中的特定内容或事件。
- 智能监控与安防:自动识别监控视频中的异常行为或关键事件,提升安全响应效率。
- 教育与培训:辅助分析教学视频,生成课程摘要或进行交互式问答。
- 娱乐与媒体:自动生成电影、电视剧或短视频的摘要、字幕或描述,提升内容的可访问性。
- 智能客服与助手:支持通过视频进行问题诊断或提供操作指导,例如设备故障排查。
- GitHub仓库:https://github.com/apple/ml-slowfast-llava
- arXiv技术论文:https://arxiv.org/html/2503.18943v1
XBai o4 大模型
XBai o4 是由 MetaStone AI(问小白)开发并开源的第四代大语言模型,专注于提升复杂推理能力。该模型已在GitHub和Hugging Face上发布,旨在促进AI技术的透明度和协作。XBai o4在复杂推理任务中表现出色,其性能在某些基准测试中甚至超越了OpenAI-o3-mini和Anthropic的Claude Opus,是开源AI领域的重要进展。

image.png
核心功能
XBai o4 的核心功能在于其强大的深度推理能力和高质量推理轨迹选择。它能够同时实现深入的逻辑推理和选择最优的推理路径,从而提供更快且更高质量的响应。通过优化推理成本,特别是在策略奖励模型(PRMs)上的显著降低,XBai o4展现了卓越的效率。
技术原理
XBai o4 基于其独创的“反思性生成形式”(reflective generative form)进行训练,该形式将“长链思维强化学习”(Long-CoT Reinforcement Learning)与“过程奖励学习”(Process Reward Learning)融合到一个统一的训练框架中。此外,通过在PRMs和策略模型之间共享骨干网络,该模型显著降低了PRMs的推理成本,提升了推理效率和质量。
应用场景
XBai o4 作为一款高性能的开源推理模型,预计将在多个领域发挥重要作用。其主要应用场景包括:
- 教育与研究:为学术研究和教育领域的复杂问题提供强大的推理支持。
- 企业应用:在需要高级决策和问题解决能力的商业场景中,如智能客服、数据分析、自动化决策系统等。
- AI技术开发:作为开源基础模型,促进全球AI生态系统的创新与发展,降低AI技术应用的门槛。
- GitHub仓库:https://github.com/MetaStone-AI/XBai-o4/
- HuggingFace模型库:https://hf-mirror.com/MetaStoneTec/XBai-o4
SpatialLM 1.5 – 群核科技推出的空间语言模型
SpatialLM是由群核科技(Manycore Research)推出的一款强大的空间大语言模型,旨在将大语言模型的能力扩展到三维空间理解。它能够处理三维点云数据,理解自然语言指令,并生成包含空间结构、物体关系和物理参数的空间语言,从而实现对三维场景的结构化理解和重建。
核心功能
- 空间语言理解与生成: 能够解析自然语言指令,并以空间语言的形式输出三维场景中的结构、物体关系及物理参数。
- 三维场景结构化: 将原始三维点云数据转换为高级、结构化的三维场景理解输出,包括室内布局重建。
- 多模态点云处理: 支持处理来自多种来源的密集点云数据,例如单目视频序列、RGBD图像和LiDAR传感器。
- 零样本物体检测: 在无需额外训练的情况下,对三维场景中的物体进行检测和识别。
技术原理
SpatialLM的核心技术原理是将深度学习与三维几何处理相结合,具体包括:
- 3D大语言模型架构: 构建在大型语言模型之上,使其具备理解和生成空间信息的能力。
- 点云编码与特征提取: 利用如Sonata点云编码器等技术,高效地对原始三维点云数据进行编码和特征提取。
- SLAM技术集成: 通过整合同步定位与地图构建(SLAM)技术,例如MASt3R-SLAM,实现从动态视频流等数据中精确重建三维空间布局。
- 结构化表示转换: 将处理后的点云数据转换为易于机器理解和操作的结构化表示,实现对空间语义的高级理解。
应用场景
- 结构化室内建模: 用于快速、精确地构建和更新室内环境的三维模型。
- 机器人导航与感知: 为服务机器人、工业机器人等提供精细的空间感知和环境理解能力,实现更智能的自主导航和操作。
- 三维设计与制造: 作为三维空间生成式AI引擎,辅助建筑设计、产品设计和虚拟原型制造等领域。
- 增强现实/虚拟现实(AR/VR): 用于构建逼真、可交互的虚拟环境,提升AR/VR应用的沉浸感和实用性。
- 智能家居与空间管理: 实现对智能家居环境的空间布局理解,优化设备控制和空间利用。
- https://github.com/manycore-research/SpatialLM
SpatialGen 3D场景生成模型
SpatialGen是由Manycore Research团队开发的一个专注于三维室内场景生成的项目。它旨在通过布局引导的方式,自动化生成高质量的3D室内环境,是Manycore Research在三维空间生成式AI引擎方面的研究成果之一。

spatialgen.png
核心功能
SpatialGen的核心功能是实现布局引导下的三维室内场景生成。这意味着用户可以通过提供特定的空间布局信息,由模型自动生成符合该布局的完整3D室内场景,极大地简化了3D内容创作的流程。
技术原理
SpatialGen的技术原理基于生成式人工智能,特别是针对三维空间数据的生成。它利用深度学习模型,通过学习大量的室内场景数据,掌握空间布局、物体摆放和材质纹理等复杂关系。该系统可能集成了空间理解(Spatial Understanding)和三维设计(3D Design)的先进算法,通过一个生成式AI引擎来实现从抽象布局到具体3D场景的转化。Hugging Face上提供了其模型,暗示了其采用大规模预训练模型或类似架构。
应用场景
SpatialGen在多个领域具有广泛的应用潜力:
- 建筑与室内设计: 快速生成多样化的室内设计方案,辅助设计师进行概念验证和可视化。
- 游戏开发: 自动化生成游戏中的室内关卡和场景,提高开发效率。
- 虚拟现实(VR)/增强现实(AR): 为VR/AR应用提供丰富的3D室内环境内容。
- 电影与动画制作: 辅助制作人员快速搭建电影或动画中的室内场景。
- 房地产展示: 为房屋销售或租赁提供交互式的3D室内漫游体验。
SpatialGen的项目地址
- GitHub仓库:https://github.com/manycore-research/SpatialGen
- HuggingFace模型库:https://huggingface.co/manycore-research/SpatialGen-1.0
3. AI-Compass
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
📋 核心模块架构:
- 🧠 基础知识模块:涵盖AI导航工具、Prompt工程、LLM测评、语言模型、多模态模型等核心理论基础
- ⚙️ 技术框架模块:包含Embedding模型、训练框架、推理部署、评估框架、RLHF等技术栈
- 🚀 应用实践模块:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿应用架构
- 🛠️ 产品与工具模块:整合AI应用、AI产品、竞赛资源等实战内容
- 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale等企业级开源资源
- 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源
📚 适用人群:
- AI初学者:提供系统化的学习路径和基础知识体系,快速建立AI技术认知框架
- 技术开发者:深度技术资源和工程实践指南,提升AI项目开发和部署能力
- 产品经理:AI产品设计方法论和市场案例分析,掌握AI产品化策略
- 研究人员:前沿技术趋势和学术资源,拓展AI应用研究边界
- 企业团队:完整的AI技术选型和落地方案,加速企业AI转型进程
- 求职者:全面的面试准备资源和项目实战经验,提升AI领域竞争力
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号