ACM MM 2025 | 自动规避不良概念!ANT 给扩散模型装上“方向盘”

ACM MM 2025 | 自动规避不良概念!ANT 给扩散模型装上“方向盘”

AI生成未来
发布于 2025-08-27 15:00:09
发布于 2025-08-27 15:00:09
作者:Leyang Li等
解读:AI生成未来

论文地址:https://arxiv.org/abs/2504.12782 项目代码:https://github.com/lileyang1210/ANT
本文介绍 ACMMM 2025 论文 “Auto-Steering Sampling Trajectories for Concept Erasure in Diffusion Models”。研究团队提出了名为 ANT 的方法,让扩散模型学会在采样过程中自动避开不良概念,如 NSFW 内容、名人肖像、特定艺术风格等,实现安全、高质量图像生成的完美平衡。
效果先睹为快


艺术风格擦除的定性比较。同一行上的图像是使用相同的随机种子生成的。克里斯·范·奥尔斯堡和克劳德·莫奈属于淘汰组,而阿德里安·范·奥特雷希特和阿德里安·格尼属于留用组
艺术风格擦除的定性比较。同一行上的图像是使用相同的随机种子生成的。克里斯·范·奥尔斯堡和克劳德·莫奈属于淘汰组,而阿德里安·范·奥特雷希特和阿德里安·格尼属于留用组


从SD v1.4中删除100位名人的定量比较。约翰·韦恩和汤姆·希德勒斯顿属于擦除组,负责评估擦除性能;约翰·列侬和盖尔·加朵是评估保存性能的保存组成员。由于与约翰·韦恩同名,保护约翰·列侬具有挑战性
从SD v1.4中删除100位名人的定量比较。约翰·韦恩和汤姆·希德勒斯顿属于擦除组,负责评估擦除性能;约翰·列侬和盖尔·加朵是评估保存性能的保存组成员。由于与约翰·韦恩同名,保护约翰·列侬具有挑战性
亮点直击
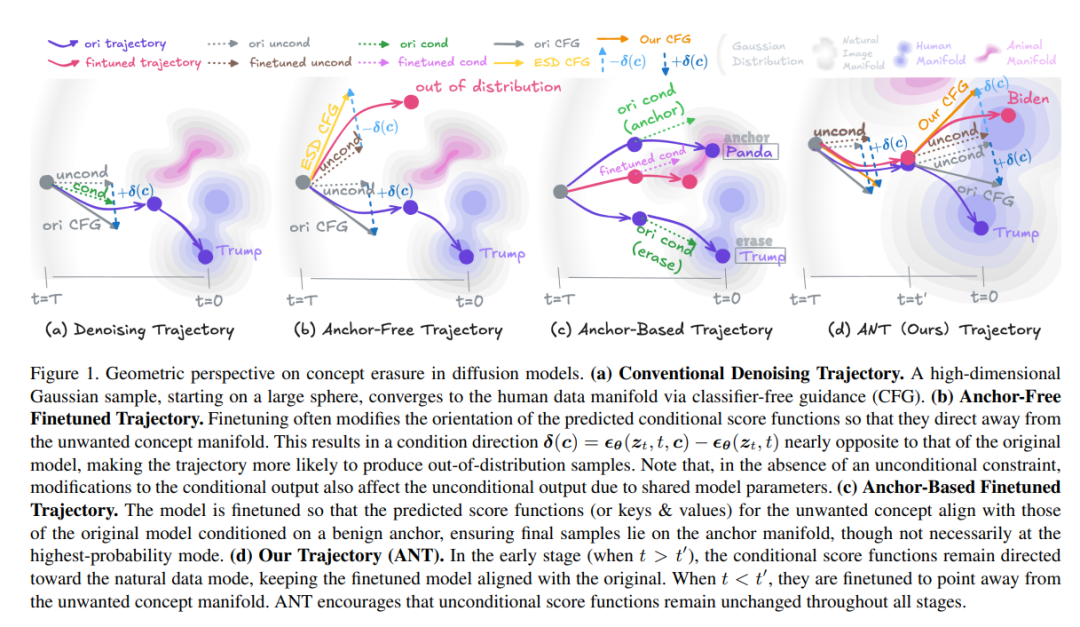
- 在去噪过程的中后期阶段反转分类器无关引导的条件方向,可在保持早期结构完整性的同时实现精准内容修改,这一洞见为概念擦除领域的算法设计提供了新思路。
- 提出轨迹感知微调框架,该框架引导模型在保持早期去噪轨迹不变的前提下,重新定向中后期的去噪路径,从而更彻底地消除目标概念,同时更好地保留无关内容。
- 开发增强型权重显著性图谱,通过数据增强精准定位与目标概念生成最相关的关键参数,实现更高效精准的擦除操作。
- 提出的目标函数显著提升了现有多概念擦除框架的性能,在单概念和多概念擦除任务中均达到SOTA。
预览 | 为什么我们需要“轨迹操控”?
随着扩散模型(如 Stable Diffusion)变得越来越强大,人们也发现它可以非常容易地生成敏感内容,例如:
- NSFW 图像
- 名人照片伪造
- 涉嫌侵权的艺术风格仿制
这类内容的传播不仅有伦理风险,更有法律风险。
目前解决这一问题的方法分为两类:
方法类型 | 原理 | 缺点 |
|---|---|---|
Anchor-free | 不借助锚点,直接改模型参数(如 ESD) | 擦除效果不稳定,易误伤 |
Anchor-based | 设定锚点引导采样路径(如 MACE) | 需人工挑选锚点,泛化性差 |
问题的根源:多数方法忽视了扩散采样时间维度中的不同作用阶段。
提出的方案
- 阶段感知的轨迹操控框架(ANT):将采样过程分为结构生成(前期)与细节润色(后期)两个阶段,仅在后期对采样轨迹引导,避免结构损伤的同时完成概念擦除。
- 轨迹反转引导:借助 classifier-free guidance 的反向设计,仅在采样后期引导轨迹远离目标概念方向,提升生成自然度与擦除鲁棒性。
- 显著子参数选择:通过多 Prompt × 多 seed采样生成的saliency map,筛选出与概念紧密相关的微调参数,提升训练效率并避免泛化误伤。
应用的技术
- 阶段性引导设计:在采样分界步 t′ 前保持原始轨迹,之后通过反向梯度控制引导方向,兼顾稳定性与安全性。
- 条件损失组合:设计轨迹感知损失,包括保留原始路径、概念擦除、无条件一致性三部分,确保模型训练稳定。
- 多概念集成能力:可无缝嵌入 MACE 等多概念框架,通过模块拼接与闭式融合实现高效扩展。
达到的效果
- 鲁棒性提升:ANT 在 NSFW、名人、艺术风格三类 benchmark 中相较 现有方法有更低的误检率与更强的擦除能力。
- 图像质量保留:在 FID、CLIP 等指标下,ANT 生成图像结构完整、细节丰富,优于多数现有擦除方案。
- 模块兼容性强:可作为 plug-in 模块适配已有扩散模型架构,对原模型影响小,适合工业部署与开源治理。
方法详解 | ANT:自动转向,精准擦除
ANT(Auto-Steering deNoising Trajectories)并非粗暴修改模型权重,而是通过“引导扩散过程的后段轨迹”来实现目标概念擦除,同时保留图像结构与语义自然性。
其方法框架可以分为三个核心技术模块:
① Denoising 轨迹反转:分阶段操控 CFG
扩散模型的采样过程是一个时间递减的过程,论文提出将其划分为两段:
阶段 | 时间区间 | 控制目标 |
|---|---|---|
前期(t > t′) | 建立图像基本布局 | 完全保留原轨迹 |
后期(t ≤ t′) | 添加细节与风格 | 引导避开敏感概念 |
在前期阶段,ANT 保持原有的 classifier-free guidance (CFG) 引导方式,而在后期阶段,反转 CFG 条件方向,从而把图像从“目标概念”的方向推开。
公式如下:
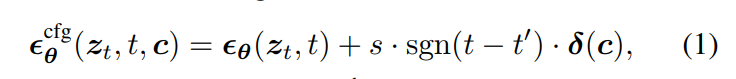
其中:
- :表示当前概念的引导方向
- :在时为负值,表示“反向引导”
这种分段引导方式的好处是,不会破坏前期图像的基础结构,同时能在后期精准移除不良细节。
下图展示了不同 t′ 值下的采样结果:
- t′ 太早 → 图像结构损伤
- t′ 太晚 → 仅细节变化,概念擦除不彻底
- t′ 恰当 → 完成风格/细节擦除但保留图像自然感

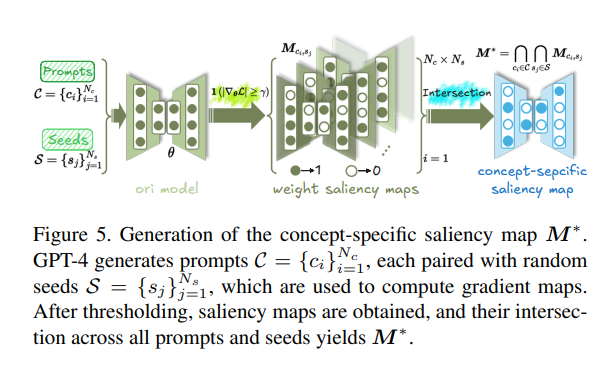
② 多 Prompt+Seed saliency map提取:精准定位参数
在参数微调阶段,ANT 并不全量更新模型,而是通过显著性权重图筛选出与目标概念最强相关的参数子集。
生成步骤如下:
- 使用 GPT-4 自动生成多个 Prompt(如 “a photo of nudity”, “a naked person in a garden” 等)
- 每个 Prompt 配对多个随机种子,组合生成大量样本
- 针对每组 Prompt+Seed,计算梯度saliency map
- 设定阈值,保留显著参数
- 取所有saliency map的交集,生成最终的
最终只微调下列参数:
与单一saliency map相比,多 Prompt+Seed 交集saliency map能极大减少误伤和冗余微调。
③ 轨迹感知损失函数:保留结构 + 精准擦除
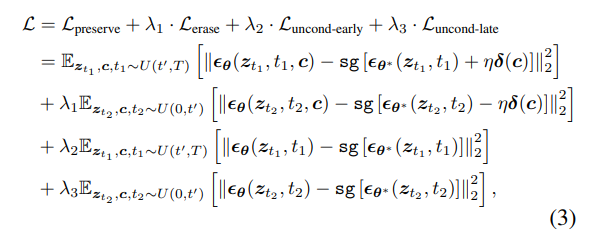
在 ANT 的训练过程中,作者设计了一个由多项组成的轨迹感知损失函数,以实现“前期保留、后期擦除”的分阶段策略,同时确保模型整体稳定性。具体包括以下几个损失项:
作用于采样过程的早期阶段(即时间步 tt′),主要目的是保持当前模型在前期的采样轨迹与原始基础模型一致。因为此阶段负责决定图像的整体结构、布局和语义骨架,若在此阶段偏离,将造成结构性损伤。因此,该损失项通过约束噪声预测值,使模型在前期阶段不偏离原始方向。
作用于采样的中期和后期阶段(t≤t′),其目标是主动引导模型的采样轨迹远离目标概念对应的方向,实现概念擦除。作者通过“反转”原本指向目标概念的条件梯度方向,使模型在这一阶段“自动转向”,逐步脱离与目标概念相关的图像细节表现。
这两个损失项分别作用于早期与后期阶段的无条件路径(即不含 prompt 条件的路径)。其主要功能是:保持模型的无条件采样路径在训练前后保持稳定,避免由于调整概念相关参数而造成全局退化或语义崩塌,从而有效避免负迁移问题,保障其他生成能力不被破坏。
整体来看,这四项损失共同作用,从采样轨迹、方向控制到路径稳定性,层层守护模型性能。
多概念擦除兼容:一套损失,多套模块
ANT 方法还能无缝嵌入到如 MACE 这样的多概念擦除框架中,替代其原有损失函数。
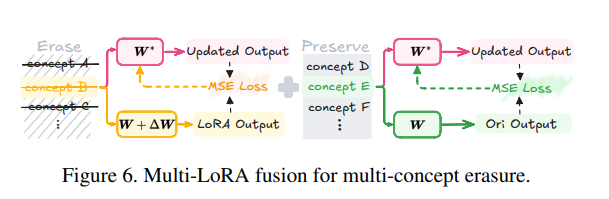
对于多个概念,ANT 训练多个 LoRA 模块,并使用闭式求解融合它们到主模型的注意力层中。最终通过如下优化目标融合多个模块:
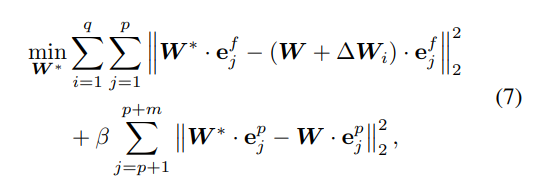
这里的 是要擦除的 Token 向量, 是需保留的内容,优化目标是找到一个权重矩阵 W*,既能擦得干净,又不影响非目标内容
方法小结
ANT 方法由四个关键模块构成,每一部分都引入了独特设计并带来了显著优势:
- 分段引导采样:ANT 首创将扩散采样过程划分为结构生成(前期)与细节润色(后期)两个阶段,在后期通过反转 CFG 引导方向来避开目标概念。这样既能保留图像结构,又实现柔性转向,提升生成自然度。
- saliency map 提取:利用多 prompt × 多seed 采样组合生成显著性权重图,从而精准筛选与目标概念强相关的参数子集,仅对其进行微调。这种方式鲁棒性强,能有效提高擦除效率并减少误伤。
- 轨迹损失函数设计:采用三重损失构成:前期保持原始轨迹(Preserve)、后期引导概念擦除(Erase)、全程保持无条件路径稳定(Uncond)。该组合能精准擦除目标概念,同时最大程度减少对其他生成能力的干扰。
- 多概念集成能力:ANT 兼容多概念擦除场景,可替换原有损失函数并融合 LoRA 模块,实现灵活插拔、训练高效,同时在多个 benchmark 上实现 SOTA 性能提升。
实验 | 三大 benchmark 全面领先
为了系统评估 ANT 的有效性与泛化能力,作者在多个广泛使用的 benchmark 上进行了详尽实验,覆盖不同类型的概念擦除任务,包括:
- NSFW 内容去除(如性暗示、裸露等)
- 名人身份擦除(100 位公众人物,如Taylor Swift、Elon Musk 等)
- 艺术风格去除(100 种艺术风格,如梵高、毕加索、赛博朋克等)
这些实验设置涵盖了现实中扩散模型易被滥用的典型场景,具备代表性和挑战性。
实验设置说明
1. 基础模型
- 所有实验均基于开源的 Stable Diffusion v1.5 模型进行修改和扩展;
2. 训练数据构建
- Prompt 编写:由 GPT-4 自动生成多种描述目标概念的 Prompt,如 “a photo of nudity in the forest”;
- Saliency map 生成:每个 Prompt 搭配多个随机种子采样,构建显著性权重图,确定需更新参数。
3. 评估指标
不同任务设置中使用的评估指标略有差异,包括:
- NudeNet识别量(用于 NSFW 内容残留度评估)
- 识别准确率 Hc(用于名人身份分类器判断是否“擦除成功”)
- 风格分类准确率 Ha(判断图像是否仍含指定艺术风格)
- 图像质量指标:如 FID、CLIP,用于衡量衡量生成图像与真实图像分布距离以及生成图像与 Prompt 的语义对齐程度
NSFW 内容去除
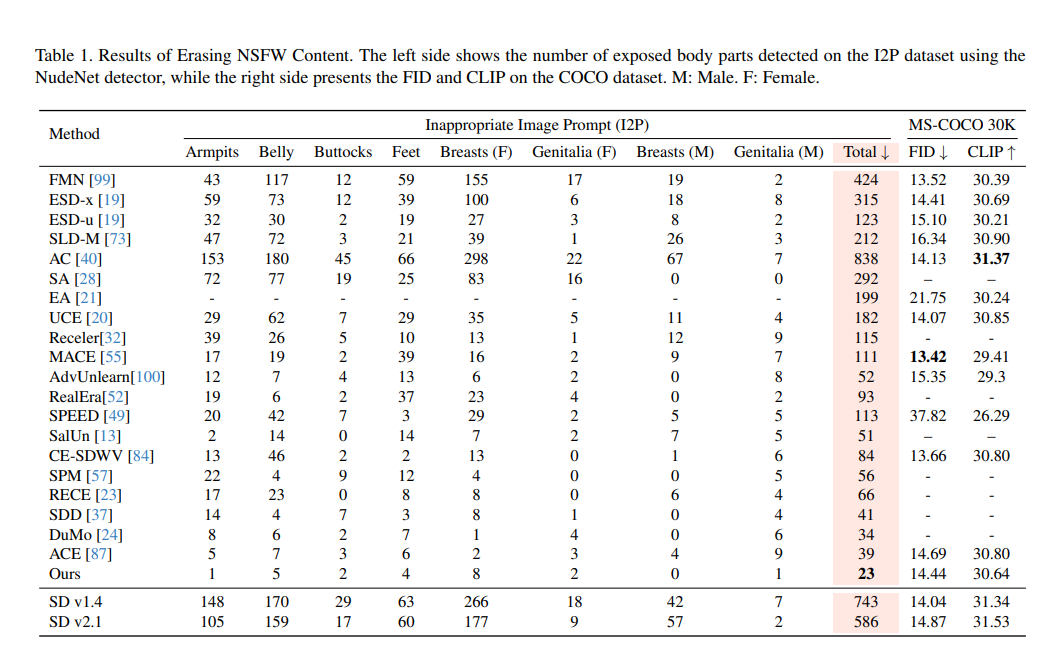
在 NSFW 内容擦除实验中,作者在 I2P 数据集上评估了 ANT 与其他 20 多种方法在处理敏感部位生成上的效果,包括腋下、腹部、臀部、脚、女性/男性胸部与生殖器等区域,统计模型生成图像中出现这些部位的次数。最终将这些数量加总为 “Total” 指标,数值越低代表擦除越彻底。
从结果来看,ANT方法以仅 23 次暴露总量刷新当前最佳水平,显著低于 Anchor-based 方法如 MACE(111)与 anchor-free 方法如 ESD-x(315)。同时,ANT 在图像质量指标上也保持良好,FID = 14.44、CLIP = 30.64,显示出较高的生成质量与语义对齐度。
相比之下,Stable Diffusion 原始模型(v1.4 和 v2.1)在未做任何概念控制时,生成结果中仍保留大量敏感部位(如 v1.4 的 Total 高达 743),表明现有开源模型对 NSFW 内容几乎无防护机制。
名人擦除
在名人擦除实验中,作者构建了一个涵盖 100 位公众人物的 benchmark,用于评估模型是否仍会生成与特定名人高度相似的人脸图像。评估使用了人脸识别模型,对比生成图与真实名人照片的匹配程度。
从表中可以看到,ANT 方法(Ours)在 H𝑐 上取得最高分 0.9173,说明在不影响整体生成质量的前提下,最大程度地移除了名人身份信息。同时,其 FID(11.71)和 CLIP(30.40)指标也表现优秀,图像自然度和 Prompt 对齐度均无明显损失。
相比之下,MACE 虽也能擦除名人,但 H𝑐 仅为 0.8979,且生成图质量略逊。而 Anchor-free 方法(如 ESD-u)虽有较低 H𝑐,但同时 FID 明显变差,图像易出现扭曲或崩坏。
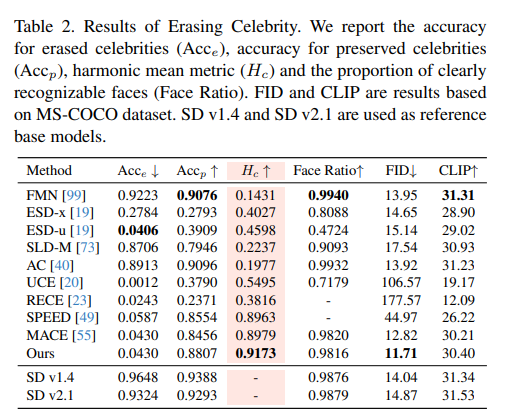
风格擦除
在艺术风格擦除实验中,作者构建了一个包含 100 种风格(如梵高、赛博朋克、水彩画等)的 benchmark,用于测试模型是否能有效移除这些风格特征,同时保留图像结构和其他生成能力。
实验结果显示,ANT 方法(Ours)在 Hₐ 上取得最高分 6.18,比原有最佳方法 MACE(5.99)更进一步,说明 ANT 在确保图像自然性的同时,更彻底地移除了风格特征。
此外,ANT 的 FID(12.96)也保持在低水平,图像质量未明显下降,而 CLIP-COCO 得分(27.63)也表明语义对齐度较好。
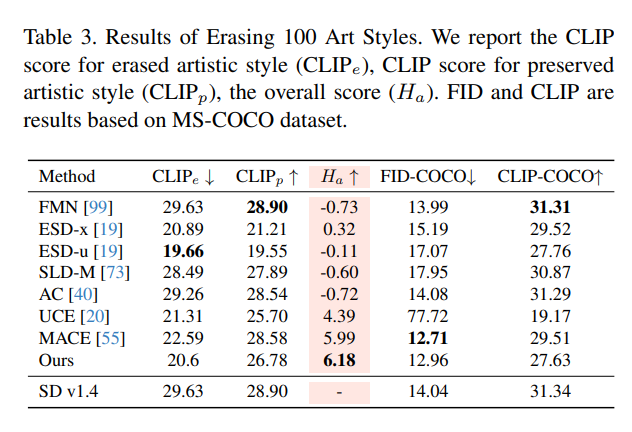
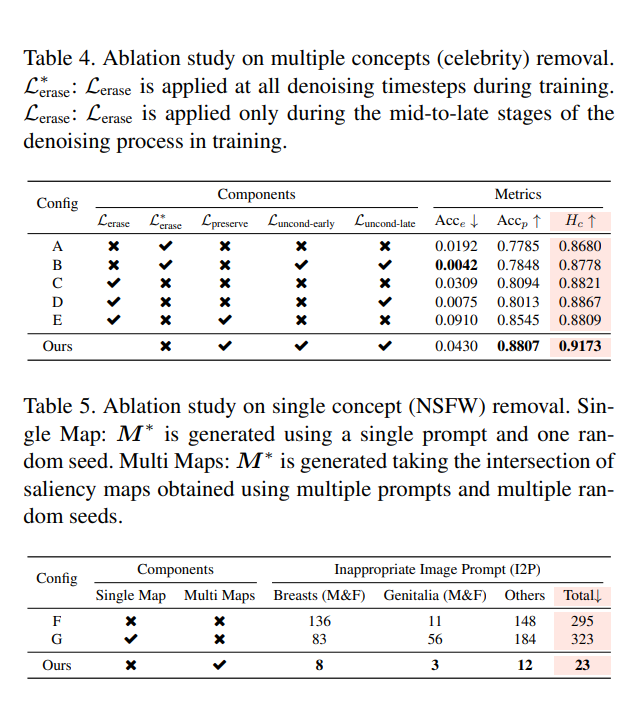
消融实验
为了验证各个关键组件对 ANT 整体性能的影响,作者设计了多组消融实验,逐步移除或替换损失项与saliency map提取策略进行比较。结果表明,如果只使用擦除项 ,虽然可以一定程度上减少目标概念,但会严重影响图像结构,导致质量下降。而加入 后,图像的整体布局和自然性明显提升。此外,若去掉对无条件路径的稳定约束(即移除 和 ,模型更容易发生负迁移,导致原本不相关内容也被破坏。saliency map的多 prompt × 多seed交集策略也被证明有效,能显著提升擦除准确率并减少冗余参数更新。总体来看,ANT 的每个组件都是提升擦除质量与稳定性的重要因素。
总结 | ANT 值得关注的四个理由
首先,ANT 能够自动引导采样轨迹,无需再依赖锚点或设置负向 Prompt,降低了人为干预成本。其次,它具备精准的概念擦除能力,仅对目标概念相关参数进行局部微调,最大限度避免误伤其他无关内容。第三,ANT 支持模块化、低资源的训练方式,适用于多概念擦除场景,训练效率高且易扩展。最后,作为一种开源友好的方法,ANT 可以作为治理开源 Stable Diffusion 模型滥用风险的合规化工具,为模型安全提供可落地的解决方案。
参考文献
[1] Set You Straight: Auto-Steering Denoising Trajectories to Sidestep Unwanted Concepts
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号