视频换脸革命!清华等发布CanonSwap「运动分离术」:告别僵硬脸,完美同步表情动作!

视频换脸革命!清华等发布CanonSwap「运动分离术」:告别僵硬脸,完美同步表情动作!

AI生成未来
发布于 2025-08-27 14:52:08
发布于 2025-08-27 14:52:08
作者:Xiangyang Luo等
解读:AI生成未来

文章链接:https://arxiv.org/pdf/2507.02691 项目链接:https://luoxyhappy.github.io/CanonSwap/
亮点直击
- 提出CanonSwap,一种基于规范空间变换的框架,通过解耦面部运动与面部外观,实现高质量身份交换和稳定的时序一致性结果。
- 设计PIM模块,通过局部自适应权重调整,在精准迁移身份至面部区域的同时,保留非目标区域不受影响。
- 提出一套专为视频换脸设计的细粒度评估指标,涵盖同步性、眼部动态及时序一致性的详细分析。
- 实验结果表明,本方法在视觉质量、时序一致性和身份保留方面均优于现有方法。
总结速览
解决的问题
- 身份迁移与动态属性保留的耦合问题:现有视频换脸方法在实现高质量身份迁移时,难以保持目标脸部的动态属性(如头部姿态、表情、唇部同步等),导致结果不一致。 - 时序一致性与真实感不足:传统方法(如GAN或扩散模型)在视频中易出现闪烁、伪影,且计算开销大,难以平衡生成质量与动态保留。
- 缺乏细粒度评估标准:现有视频换脸任务缺少针对动态属性(如视线、眼部运动)和时序一致性的综合评估指标。
提出的方案
- CanonSwap框架:
- 运动与外观解耦:通过将目标视频映射到统一规范空间(canonical space)分离运动信息,在规范空间内完成身份迁移后,再投影回原视频空间以保留动态属性。
- Partial Identity Modulation (PIM)模块:
- 自适应身份融合:通过空间掩码限制身份特征仅修改面部区域,避免非面部区域的干扰,提升细节真实感。
- 新评估指标:
- 引入细粒度同步指标(如视线方向、眼部动态)和时序一致性评估,全面衡量换脸效果。
应用的技术
- 规范空间映射:基于形变的方法(warping-based)将视频帧映射到解耦的规范空间。
- 自适应特征调制:PIM模块结合空间掩码和身份特征自适应融合技术。
- 视频动态恢复:通过逆映射将换脸结果重新嵌入原视频运动轨迹。
达到的效果
- 高质量身份迁移:在保留目标视频动态属性的同时,实现高保真身份转移,减少伪影。
- 时序一致性:生成的视频帧间过渡自然,避免闪烁和抖动。
- 评估领先性:实验表明,该方法在视觉质量、时序一致性和身份保留上显著优于现有方法。
方法
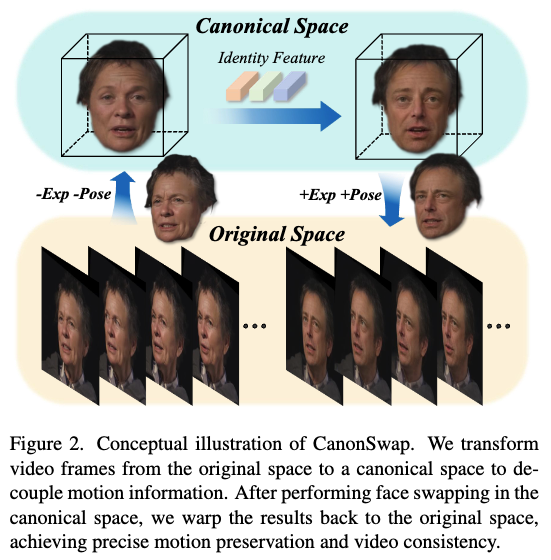
现有的人脸交换方法直接在目标图像或视频的原始空间中进行换脸。由于运动与外观高度耦合,修改人脸时往往会无意中改变运动信息,从而导致视频换脸中出现抖动并降低整体真实感。因此,有必要将运动信息与外观解耦,以确保运动一致性的同时有效迁移身份信息。
本文的方法概念如下图2所示。给定输入视频,我们首先将其从原始空间变形(warp)至规范空间(canonical space)。在规范空间中,人脸仅保留外观信息,并固定为一致的姿态。随后,我们在该规范空间内执行换脸,并将结果变形回原始空间。得益于运动与外观的解耦,CanonSwap可在视频帧间实现高度一致且稳定的换脸结果。
如下图3(a)所示,本文的方法包含两部分:
- 规范交换空间(Canonical Swap Space):描述如何构建消除运动信息的规范换脸空间,并如何将换脸结果一致地映射回原始空间。
- 局部身份调制(Partial Identity Modulation, PIM):精准高效地将源身份信息转换为目标外观特征,实现在规范空间内的换脸。
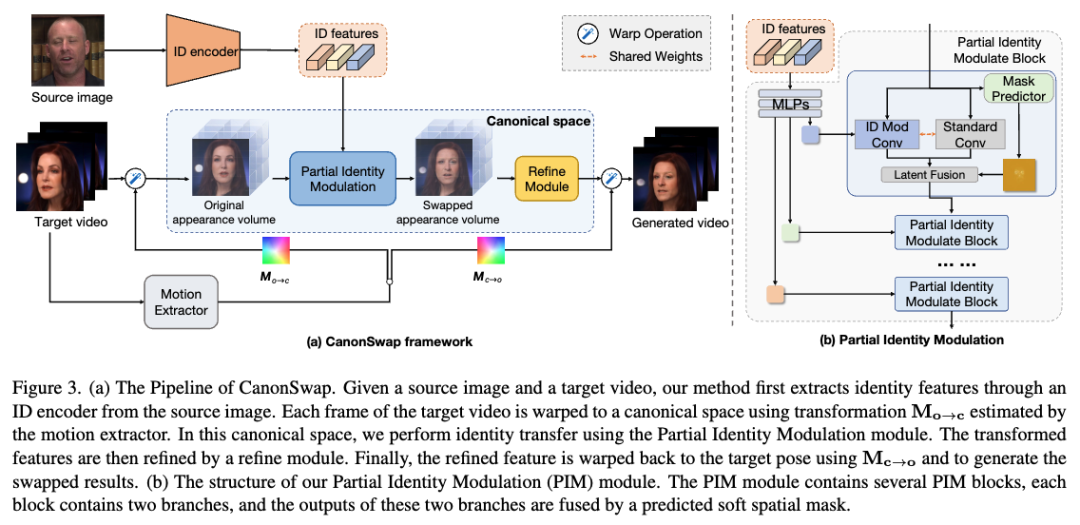
规范交换空间
直接在原始空间换脸通常会因外观与运动的耦合导致意外的外观和运动变化。为解决此问题,我们提出构建一个解耦运动与外观的规范交换空间,并在该空间内进行换脸。换脸结果随后被变形回原始空间,从而保留动态属性并确保一致性。
受[46]启发,规范交换空间可通过运动引导的变形构建。我们使用运动提取器(详见附录)估计目标视频帧的运动,得到运动变换 和 。利用 ,可将外观编码器预测的原始外观体积变形至规范空间的外观体积。在规范空间完成换脸后,交换后的外观体积通过 变形回原始空间,并解码生成最终结果。
需要注意的是,经过两次连续的变形步骤后,外观体积可能出现偏差,导致最终结果出现伪影。因此,我们提出一个轻量级3D U-Net结构作为优化模块,在将外观体积变形回原始空间前对其进行优化。
局部身份调制
基于上述规范空间,通过对规范外观特征进行调制实现换脸。许多基于GAN的方法使用AdaIN进行换脸并取得良好效果,但AdaIN作用于整个特征图,灵活性不足且可能导致训练不稳定。受[24]启发,进一步提出局部身份调制(PIM)模块,仅选择性调制面部区域,同时保留其余部分。通过将调制限制在面部区域,本文的方法缓解了训练中的对抗效应并增强稳定性,而灵活的调制机制进一步提升了换脸性能的上限(附录D证明本方法可更快收敛并有效缓解训练中的对抗现象)。
如前面图3(b)所示,PIM模块包含多个块,每个块包含两条并行分支,并通过空间掩码 自适应结合分支输出,表达式为:
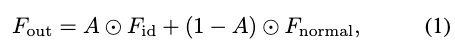
其中 表示逐元素相乘, 和 是由两个分支生成的特征。这种融合机制实现了跨不同空间区域的选择性特征调制。
首先通过一系列 MLP 从 ID 编码器 聚合身份特征,以获得身份编码 。随后,两个并行分支按以下方式处理输入特征:
- 标准卷积分支:
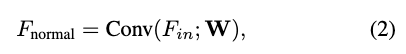
其中 表示卷积权重,该分支在不进行任何身份特定变换的情况下处理输入特征图 。 2) 调制卷积分支:我们首先用身份编码 调制原始卷积权重 ,随后通过解调稳定所得权重。该统一过程可表述为:
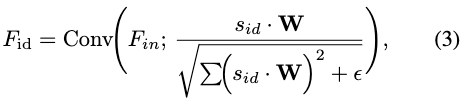
其中 是确保数值稳定性的小常数。在该公式中,卷积权重首先通过 进行缩放以注入身份特定特征,随后通过其 范数归一化以防止过大的方差偏移。空间掩码 由掩码预测器 生成,可表示为:

该掩码确保身份调制主要影响面部区域(如眼睛、鼻子和嘴巴),同时保留其他无关区域的原始内容。
总体而言,PIM提供了对面部区域的细粒度控制,避免过度修改并保留目标属性的自然外观。这种选择性策略显著减少了复杂场景(如复杂背景或大角度姿态)下的伪影,产生更真实和鲁棒的结果。
训练与损失函数
本文的变形框架采用的方法,并以端到端方式训练PIM模块和优化网络。在训练过程中,同时对规范空间和原始空间的交换结果进行监督。规范空间的结果Ics→t通过解码规范换脸特征获得,而原始空间的结果Ios→t则是将规范交换特征变形回原始空间后解码得到。
为确保准确的身份迁移,在规范空间和原始空间都采用了身份损失。该损失利用预训练的人脸识别模型来衡量交换后的人脸与源身份之间的相似度:
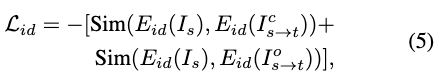
其中 表示预训练的人脸识别模型, 表示两个特征向量之间的余弦相似度。
为保持结构一致性,引入了感知损失,用于衡量交换人脸与目标人脸在特征层面的相似性[53]。
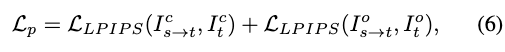
其中 表示规范空间中的目标人脸,可通过解码规范特征 获得。
为保持姿态和表情准确性,引入运动损失,其公式为:
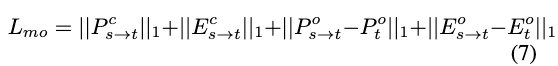
其中表情参数 和姿态参数 由运动提取器提取。
重建损失 用于确保当源图像和目标图像属于同一身份时的保真度。在训练过程中,以0.3的概率随机采样具有相同身份的源-目标对。重建损失公式为:
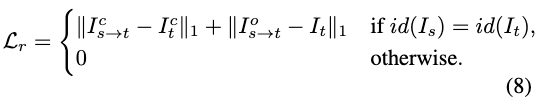
其中 表示输入图像的身份。
为提高生成图像的视觉质量和真实感,采用对抗损失:
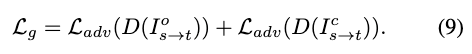
其中 表示判别器。
虽然上述损失函数能够有效实现混合区域的无监督学习(网络可自动确定人脸交换的适当边界),但观察到过度锐利的过渡可能会在这些边界处引入伪影。因此,引入额外的正则化损失来确保交换区域之间的平滑准确混合:
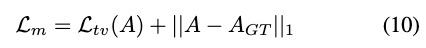
其中 表示预测的掩码, 表示可用的真实掩码。总变分损失 计算水平和垂直方向上相邻像素间绝对差值的总和,以促进预测掩码的空间平滑性。
整体训练目标将这些损失与精心调整的权重相结合:
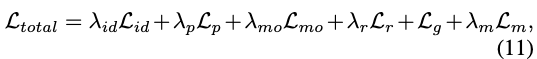
其中 ,,。这一综合损失函数使我们的模型能够实现具有运动一致性和清晰身份迁移的高质量换脸效果。
视频换脸评估指标
传统换脸评估通常依赖ID相似度、ID检索、表情准确度、姿态准确度和FID等指标。虽然这些指标对基于图像的换脸有效,但无法捕捉视频换脸特有的挑战(如时序一致性和唇音同步)。为此,提出一组专为视频换脸设计的细粒度评估指标。
我们在常规指标基础上扩展了针对眼部与唇部区域的额外测量:
- 眼部:除常用的视线估计外,引入眼部纵横比(EAR) 以更精准评估眨眼模式;
- 唇部:采用说话头合成任务中的唇同步误差-距离(LSE-D)和唇同步误差-置信度(LSE-C),量化唇部运动与音频的匹配程度。LSE-D计算唇部关键点与真实值的平均偏差,LSE-C衡量唇部同步预测的置信度。
为支持全面评估,本文提出新基准VFS(视频换脸基准),包含从VFHQ数据集随机采样的100对源-目标视频。每个目标视频含前100帧及4秒对应音频,用于综合评估视觉保真度与唇音同步性。
实验
实验设置
数据集
模型训练采用VGGFace数据集,经人脸检测后过滤宽度小于130像素的图像,最终使用93万张图像(分辨率调整为512×512)。评估使用FaceForensics++(FF++)数据集和VFS基准。
对比方法
与以下方法对比:
- GAN基方法:SimSwap、FSGAN、E4S;
- 扩散基方法:DiffSwap、REFace、Face Adapter。
定量评估
整体指标
本文使用两个不同的测试集评估本文的方法:FF++数据集和我们的VFS基准测试。在FF++上,遵循常规的人脸交换评估协议,采用五个既定指标:ID检索、ID相似度、姿态准确度、表情准确度和Fr ́echet Inception距离(FID)。ID检索和相似度使用人脸识别模型通过余弦相似度计算。姿态准确度通过估计姿态与真实姿态的欧氏距离衡量,而表情准确度则通过对应表情嵌入的L2距离计算。
对于我们的视频基准测试,采用Fr ́echet视频距离(FVD)代替FID,以更好地评估时间一致性。通过比较源视频和交换视频之间的光流场实现运动抖动分析(时间一致性,简称TC),以量化不自然的面部运动。还采用了前面中的细粒度指标:从面部标志点计算的眼球注视和EAR,以及使用SyncNet测量的LSE-D和LSE-C。
定性评估
评估结果
VFS基准测试和FF++数据集的评估结果如下表1和表2所示。定量结果表明,本文的方法在多个指标上 consistently 优于现有的基于GAN的方法和基于扩散的方法。在身份保留方面,本文的方法在两个数据集上均取得了最高的ID相似度得分和ID检索准确率,相较于两类方法均有显著提升。此外,本文的方法在姿态指标上误差最低,在表情指标上表现 competitive,表明与现有方法相比,本文的方法与目标视频运动的对齐最为精确。
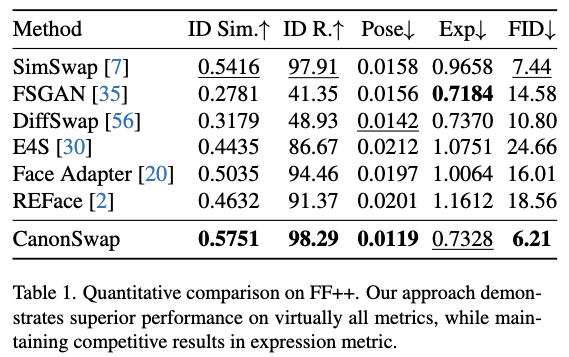
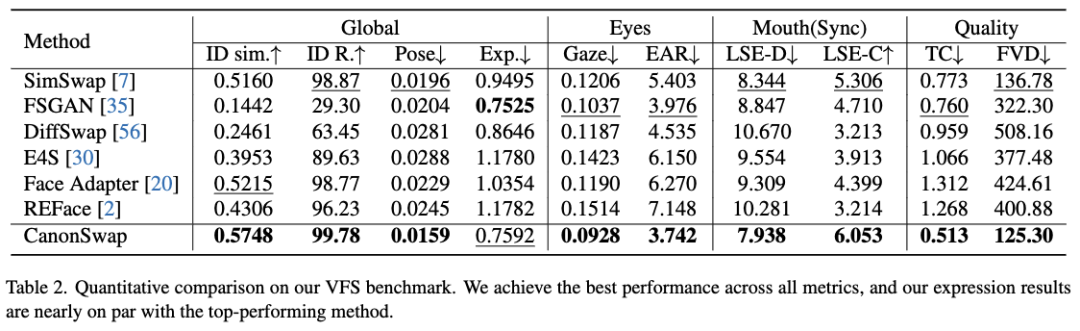
在嘴部同步指标上也有显著改进,本文的方法在LSE-D和LSE-C上分别达到7.938和6.053,超越了基于GAN和基于扩散的方法。这种卓越的唇部同步能力也体现在质量指标上,本文方法取得了最佳的FID和FVD分数,显著优于其他方法,展示了在保持时间一致性的同时更好的合成质量。这些结果表明,解耦外观和运动对于视频人脸交换至关重要。
为进一步评估CanonSwap的有效性,在FF++和VFS基准测试上进行了定性比较,如下图4和图5所示。结果表明,本文的方法不仅实现了准确的身份转移,还保持了精确的运动对齐。


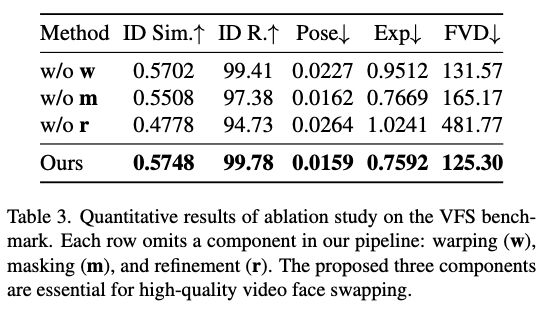
消融实验
在VFS基准测试上进行了消融实验,以评估管道中每个模块的影响(见下表3和图6)。具体而言,分别移除了三个组件:(1) 无w(w/o w)省略了变形步骤,直接在原始空间进行人脸交换;(2) 无m(w/o m)移除了软空间掩码,导致整个特征图的全局调制;(3) 无r(w/o r)排除了在变形回之前增强规范空间特征的细化模块。如表3所示,移除任一组件均会导致多个指标的性能下降。图6进一步定性展示了这些问题:w/o w无法准确对齐姿态和表情,w/o m引入了更多不希望的纹理,而w/o r则导致模糊或不一致的身份细节。这些结果表明,所有三个模块对于实现视频人脸交换中的准确身份转移、精确姿态对齐和无伪影结果至关重要。

人脸交换与动画
在CanonSwap中,输入图像被解耦为两个部分:外观和运动(即姿态和表情)。因此,除了改变外观外,CanonSwap还支持修改表情和姿态。具体而言,在变形回的过程中,目标的表情可以被替换为源的表情,从而实现身份和表情的同时转移。这一能力使得人脸交换和面部动画可以在同一框架内实现。如下图7所示,CanonSwap不仅能进行人脸交换,还能对目标图像进行动画处理,使其模仿源的表情和动作,从而拓宽了其潜在应用场景。

结论
本文提出了一种新颖的视频人脸交换框架,通过在规范空间解耦姿态变化与身份转移,解决了时间不稳定性问题。本文的部分身份调制模块实现了精确的交换控制,同时保持了时间一致性。引入了细粒度的同步指标进行评估。大量实验表明,本文的方法在稳定且逼真的视频人脸交换方面取得了显著进展,能够适应各种姿态和表情变化。
参考文献
[1] CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号