100天跟着CP学PostgreSQL+AI,第9天 : 向量数据库:pgvector 如何存储和检索 AI Embedding

100天跟着CP学PostgreSQL+AI,第9天 : 向量数据库:pgvector 如何存储和检索 AI Embedding

用户8465142
发布于 2025-08-27 14:04:22
发布于 2025-08-27 14:04:22
作者介绍:崔鹏,计算机学博士,专注 AI 与大数据管理领域研究,拥有十五年数据库、操作系统及存储领域实战经验,兼具 ORACLE OCM、MySQL OCP 等国际权威认证,PostgreSQL ACE,运营技术公众号 "CP 的 PostgreSQL 厨房",持续输出数据库技术洞察与实践经验。作为全球领先专网通信公司核心技术专家,深耕数据库高可用、高性能架构设计,创新探索 AI 在数据库领域的应用落地,其技术方案有效提升企业级数据库系统稳定性与智能化水平。学术层面,已在AI方向发表2篇SCI论文,将理论研究与工程实践深度结合,形成独特的技术研发视角。
系列文章介绍
第一阶段 : 基础筑基期(第 1-30 天:PostgreSQL 与 AI 技术扫盲)
主要内容
主题:向量数据库核心:pgvector 如何存储和检索 AI Embedding
核心内容:向量相似度算法(L2 距离 / 余弦相似度)实现原理 / 索引优化(IVFFlat)
实践案例:搭建一个简单的文本语义检索系统(BERT+pgvector)
当 AI 遇到数据库:pgvector 如何让文本 “心有灵犀”?
你有没有过这样的体验?在电商平台搜索 “轻便运动鞋”,结果总能刷到 “透气跑鞋”“低帮休闲鞋”—— 这些看似不同的关键词,却能被精准关联。背后的秘密,是 AI 将文本转化为 “向量” 后,通过向量相似度计算实现的 “语义检索”。而今天要聊的主角,是让这一切高效落地的 “ PostgreSQL 神器”:pgvector。
一、为什么 AI 需要 “向量数据库”?
在 AI 时代,图片、文本、语音等非结构化数据占比超 80%。要让计算机理解这些数据,第一步是通过 ** 预训练模型(如 BERT)** 将其转化为 “向量”—— 比如一段文本经过 BERT 处理后,会变成一个 768 维的数字数组(如[0.12, -0.34, 0.56, ...]),这个数组就是数据的 “语义指纹”。
但问题来了:如何高效存储和检索这些 “指纹”?传统关系型数据库(如 MySQL)擅长处理结构化数据(如用户 ID、年龄),但面对向量这种 “高维、非结构化” 数据时,检索效率会断崖式下跌 —— 要找相似向量,只能暴力遍历所有数据计算相似度,10 万条数据可能要算几秒甚至更久。
向量数据库应运而生。它专为向量存储和快速检索设计,而 pgvector 作为 PostgreSQL 的扩展,凭借 “无需额外部署、兼容 SQL、支持事务” 等优势,成为中小团队的首选。
二、向量检索的核心:相似度算法向量检索的本质,是计算两个向量的 “相似程度”。最常用的两种算法是L2 距离(欧氏距离)和余弦相似度,我们用一个例子直观理解:1. L2 距离:空间中的 “绝对距离”L2 距离计算的是两个向量在高维空间中的直线距离,公式为:
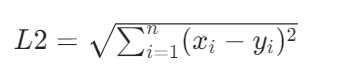
举个例子:假设 “运动鞋” 的向量是[2,3],“跑步鞋” 的向量是[3,4],“皮鞋” 的向量是[1,1],则:
运动鞋 vs 跑步鞋:L2 = √[(2-3)²+(3-4)²] = √2 ≈ 1.41
运动鞋 vs 皮鞋:L2 = √[(2-1)²+(3-1)²] = √5 ≈ 2.24
结论:L2 距离越小,向量越相似。它适合需要考虑 “向量大小” 的场景(如图像检索,像素值的绝对差异很重要)。2. 余弦相似度:方向比长度更重要余弦相似度计算的是两个向量夹角的余弦值,公式为:
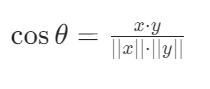
其中,分子是向量点积,分母是向量模长的乘积。结果范围在[-1,1]之间,值越大越相似。
还是用上面的例子:
运动鞋 vs 跑步鞋:点积 = 2×3+3×4=6+12=18;模长分别为√(2²+3²)=√13≈3.61,√(3²+4²)=5;余弦相似度 = 18/(3.61×5)≈0.99运动鞋 vs 皮鞋:点积 = 2×1+3×1=5;模长√(1²+1²)=√2≈1.41;余弦相似度 = 5/(3.61×1.41)≈0.98结论:余弦相似度更关注向量的 “方向”,适合文本语义检索(因为文本长度可能不同,但语义方向一致即可)。pgvector 的选择pgvector 同时支持 L2 距离(vector_l2_ops)和余弦相似度(vector_cosine_ops),创建索引时指定即可。实际应用中,文本检索常用余弦相似度,图像检索常用 L2 距离。三、从暴力检索到 IVFFlat:索引如何让检索快 100 倍?如果直接用暴力检索(全表扫描计算相似度),100 万条数据可能需要几秒到几十秒,这在实时系统(如搜索框)中完全不可接受。因此,向量数据库的核心能力是索引优化。pgvector 最常用的索引是IVFFlat(倒排文件索引),其原理分三步:
1. 预聚类:把向量 “分桶”首先,从所有向量中随机选取nlist个 “质心向量”(比如 nlist=1000),将所有向量分配到最近的质心对应的 “桶” 里。这一步就像把图书馆的书按类别分到不同书架(每个书架对应一个质心)。
2. 检索时:先找 “书架” 再找 “书”当需要检索相似向量时,先计算查询向量与所有质心的相似度,找到最接近的nprobe个质心(比如 nprobe=10),然后只在这 10 个 “书架”(桶)中暴力检索。
3. 效果:速度与精度的平衡通过 IVFFlat,检索时间从 O (N)(全量)降到 O (nprobe×(N/nlist))。假设 nlist=1000,nprobe=10,检索量直接缩小 100 倍!当然,nlist 越大(分桶越细),检索速度越快,但内存占用越高;nprobe 越大(检查的桶越多),精度越接近暴力检索,但速度越慢。四、实战:用 BERT+pgvector 搭一个文本语义检索系统现在我们动手搭建一个 “文本语义检索系统”,步骤包括:
用 BERT 生成文本 Embedding→用 pgvector 存储向量→实现相似度检索。环境准备软件:PostgreSQL 14+(需安装 pgvector 扩展)、Python 3.8+依赖库:psycopg2-binary(数据库连接)、transformers(BERT 模型)、torch(PyTorch)
步骤 1:安装 pgvector 扩展pgvector 是 PostgreSQL 的扩展,安装非常简单(以 Ubuntu 为例):
# 安装pgvector
sudo apt install postgresql-14-pgvector
# 连接PostgreSQL,创建扩展
psql -U postgres
CREATE EXTENSION vector; # 启用向量扩展步骤 2:创建存储向量的表
我们需要一张表存储文本和对应的向量,向量列类型是vector(768)(BERT 生成的是 768 维向量):
-- 创建数据库和表
CREATE DATABASE semantic_search;
\c semantic_search -- 切换到新数据库
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
text TEXT NOT NULL,
embedding vector(768) -- 存储BERT生成的768维向量
);步骤 3:用 BERT 生成文本 Embedding 使用 Hugging Face 的transformers库加载 BERT 模型,将文本转化为向量:
from transformers import BertTokenizer, BertModel
import torch
# 加载预训练模型和分词器(中文用bert-base-chinese)
model_name = "bert-base-uncased" # 英文模型,中文换"bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
def get_embedding(text):
# 分词→转ID→生成向量
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
# 取[CLS]token的输出作为文本向量(768维)
return outputs.last_hidden_state[:, 0, :].squeeze().tolist()
# 测试:生成"Hello world"的向量
text = "Hello world"
embedding = get_embedding(text)
print(f"向量维度:{len(embedding)}") # 输出:768步骤 4:将文本和向量存入 pgvector 连接数据库,插入测试数据(比如 1000 条商品标题):
import psycopg2
# 数据库连接配置
conn = psycopg2.connect(
dbname="semantic_search",
user="postgres",
password="your_password",
host="localhost",
port=5432
)
cur = conn.cursor()
# 插入示例数据
texts = [
"轻便透气运动鞋",
"防水跑步鞋男款",
"真皮商务皮鞋",
"儿童加绒棉鞋",
"透气网面休闲鞋"
]
for text in texts:
embedding = get_embedding(text)
# 注意:pgvector的向量需要转为字符串格式存储(如'{0.12, -0.34, ...}')
cur.execute(
"INSERT INTO documents (text, embedding) VALUES (%s, %s)",
(text, embedding)
)
conn.commit()步骤 5:创建 IVFFlat 索引加速检索 为了提升检索速度,给embedding列创建 IVFFlat 索引(基于余弦相似度):
-- 创建IVFFlat索引(nlist=100,根据数据量调整)
CREATE INDEX ON documents
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);步骤 6:实现语义检索功能
编写查询函数,输入文本后,返回最相似的前 3 条数据:
def search_similar(text, top_k=3):
# 生成查询向量
query_embedding = get_embedding(text)
# SQL查询:按余弦相似度排序(1 - 余弦距离)
cur.execute(
"""
SELECT text, 1 - (embedding <-> %s) AS similarity
FROM documents
ORDER BY embedding <-> %s
LIMIT %s
""",
(query_embedding, query_embedding, top_k)
)
results = cur.fetchall()
return results
# 测试:搜索"透气运动鞋"
query = "透气运动鞋"
similar_docs = search_similar(query)
for doc in similar_docs:
print(f"文本:{doc[0]},相似度:{doc[1]:.4f}")测试结果示例
输入"透气运动鞋",输出可能是:
文本:轻便透气运动鞋,相似度:0.9823
文本:透气网面休闲鞋,相似度:0.9512
文本:防水跑步鞋男款,相似度:0.8931 五、总结:pgvector 的 “取舍之道”
pgvector 不是性能最强的向量数据库(比如不如 Milvus、Pinecone),但它的优势在于 **“无缝集成”**—— 依托 PostgreSQL 的成熟生态,你可以用一条 SQL 同时操作结构化数据(如商品价格、库存)和向量数据(如商品标题 Embedding),这对需要 “业务数据 + AI 能力” 结合的场景(如电商搜索、内容推荐)非常友好。
未来,随着多模态 AI(文本 + 图像 + 视频)的普及,向量数据库会成为每个技术团队的 “基础设施”。而 pgvector,可能就是你入门向量检索的最佳起点。
小提示:实际使用中,记得根据数据量调整 IVFFlat 的nlist和nprobe参数(比如 100 万条数据,nlist=1000,nprobe=20),并定期重建索引(当数据更新频繁时)。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-02,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 CP的postgresql厨房 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号