数据建模怎么做?一文讲清数据建模全流程
原创
数据建模怎么做?一文讲清数据建模全流程
原创
帆软BI
发布于 2025-08-22 16:57:13
发布于 2025-08-22 16:57:13
在数据团队待久了,总会遇到两种让人头疼的情况:
- 业务同事说“你们做的模型太绕,我要个销售额数据都费劲”;
- 技术同事也叹气,“业务需求变得比翻书还快,模型刚弄好就得大改”。
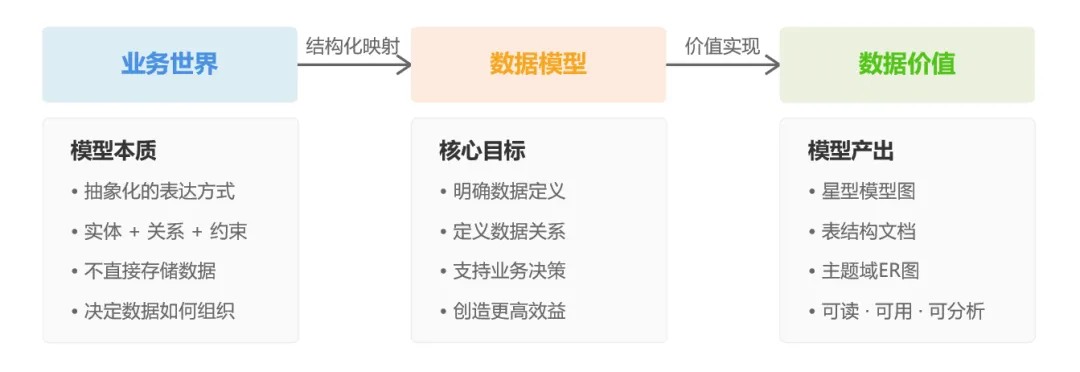
其实数据建模这事儿,就是把业务需求和技术实现连起来的那根线,看着基础,却藏着不少坑。它真不是画几张图、写几行代码那么简单,得真懂业务逻辑,还得算着技术成本,甚至得提前想到以后可能会变的地方,是个实打实的系统活儿。
今天我就不跟你扯教科书上的理论了,就从实际应用的角度,把数据建模的全流程拆解开,重点说说这四个核心问题:
- 需求该怎么接
- 模型该怎么设计
- 落地时要避开哪些坑
- 后续怎么跟着迭代
一、需求分析
数据建模第一步,80%人都会踩坑——把需求分析做成了简单记录。
业务方说:“我要用户复购率的周环比数据。”技术同学记下来,转头就从订单表里取“下单时间”“用户ID”“金额”,按周分组一算。
结果交上去的时候,业务方就问了:
“预售订单怎么没算进去?为啥用支付时间不是下单时间?怎么只算了APP端的数据?”
问题出在哪?
需求分析根本不是原样转述,而是得翻译。业务方提需求的时候,往往带着他们自己的业务语境,模糊不清是常有的事。
这时候,数据建模就得把需求拆成三个关键部分:

1. 搞清楚业务目标:这数据是要解决啥问题?
就拿复购率来说:
- 它到底是用来验证“用户生命周期价值(LTV)的短期情况”,
- 还是评估“促销活动的效果”?
目标不一样,模型里的字段设计、关联的维度,那差别可就大了:
- 要是前者,就得把用户的首单时间、以前的消费层级都关联上;
- 要是后者,就得关联活动标签、优惠券使用情况。
2. 明确数据边界:哪些数据该要,哪些不该要?
业务方说“用户行为数据”,可能在他们看来,默认就包括APP、小程序、H5三端的点击记录,但技术这边就得问清楚:
- PC端的算不算?
- 机器人的流量要不要过滤掉?
- 设备信息(比如是iOS还是Android)用不用关联?
边界要是没划清:
模型上线后,肯定就得陷入“补数据-改模型”的循环里,没完没了。
3. 弄明白使用场景:谁用这数据,怎么用?
同样是“销售额报表”:
- 给老板看的周报,得汇总到品牌、大区这个级别;
- 给运营看的日报,就得细到SKU、门店;
- 要是给算法做预测用,可能还得保留用户分群标签、时间序列特征。
说白了,使用场景决定了模型的细致程度和冗余情况——老板要的是整体情况,算法要的是细节特征,模型得跟这些场景匹配上才行。
所以跟业务方沟通需求的时候,拿着“5W1H”清单去问细节:
- Who(谁用)
- What(具体要啥指标)
- When(时间范围是啥)
- Where(数据从哪儿来)
- Why(业务上要解决啥问题)
- How(输出成啥样)
二、模型设计
需求分析清楚了,就到模型设计这一步了。这一步的核心,就是用结构化的模型语言,把业务逻辑固定成能计算的资产。
数据建模的方法不少,像维度建模、实体关系建模、数据湖建模等等。但实际干活的时候,最常用的还是维度建模,特别是星型模型和雪花模型。
为啥呢?
因为它够简单——
- 业务的人能看明白,
- 技术团队也好实现,
- 计算效率也有保障。
1. 第一步:确定业务过程
业务过程就是模型里的“核心事件”,比如:
- “用户下单”
- “商品入库”
- “优惠券核销”
它必须是能量化、能追踪的具体动作,不能是抽象的概念。比如说“用户活跃”是一种状态,它对应的业务过程应该是“用户登录”“用户点击”这些具体动作。

2. 第二步:识别维度
维度就是看业务过程的角度,用来回答“谁、何时、何地、什么条件”这些问题。比如分析“用户下单”,可能涉及的维度有:
- 时间维度(下单时间、支付时间)
- 用户维度(用户ID、性别、注册渠道、会员等级)
- 商品维度(商品ID、类目、品牌、价格带)
- 场景维度(渠道:APP/小程序;活动:大促/日常;地域:省/市)
要注意的是:
维度得“全面准确”,但别“过度设计”。也就是说维度设计得基于当前的业务需求,同时留点儿扩展的空间。
3. 第三步:确定度量
度量是业务过程的“量化结果”,必须是数值型的、能聚合的字段,像订单金额、商品销量、支付转化率这些都是。
这里有个容易被忽略的点:度量得明确“计算规则”。比如说:
- “销售额”,是指“下单金额”还是“支付金额”?
- “复购率”是“30天内购买2次及以上”还是“最近一次购买距离首单不超过30天”?
规则不统一,模型输出的指标就容易让人产生误解。
4. 第四步:选择模型类型(星型vs雪花)
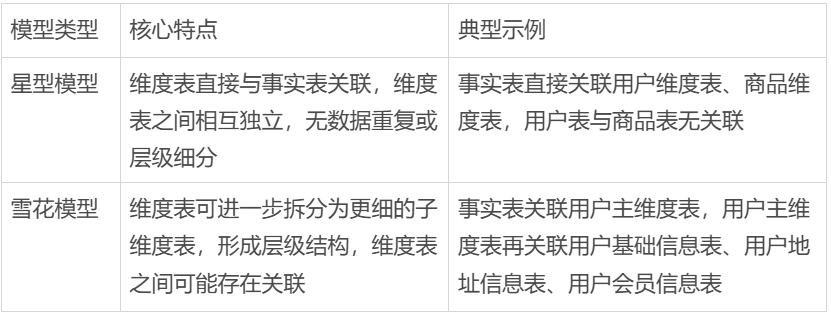
怎么选呢?
主要看查询效率:
- 星型模型减少了JOIN操作,适合经常查询的场景,比如BI报表;
- 雪花模型更规范,适合不常查询但分析复杂的场景,比如数据科学家做深度的关联分析。
用过来人的经验告诉你,优先选星型模型。在大数据的场景下,JOIN操作特别费计算资源,星型模型能明显提高查询速度。
要是维度需要细分:
可以把常用的维度字段合并到事实表里,做成“宽表”来优化,别动不动就拆成雪花结构。
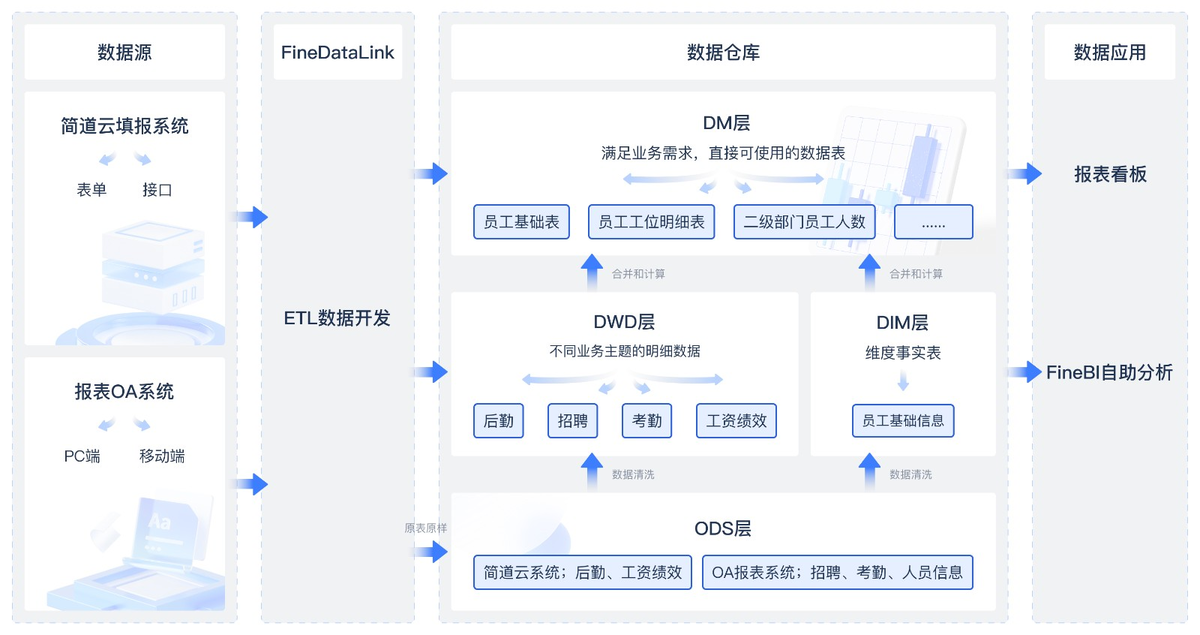
三、实施落地
模型设计好了,就该落地实施了。这一步难的不是写代码,而是在“模型够不够好”和“工程上能不能实现”之间找到平衡。
1. 数据分层:让模型好维护
数据仓库的分层设计(ODS→DWD→DWS→ADS)是实施阶段的基础。每一层的职责得明确:
- ODS(原始数据层):存着原始的日志和业务库数据,一点都不修改,用来回溯和校验;
- DWD(明细数据层):做清洗、去重、标准化的工作,比如统一时间格式、填补缺失的值;
- DWS(汇总数据层):按主题来聚合数据,比如用户主题、商品主题的日活、周销数据;
- ADS(应用数据层):直接对接业务需求,像BI报表、算法模型的输入数据都从这儿来。
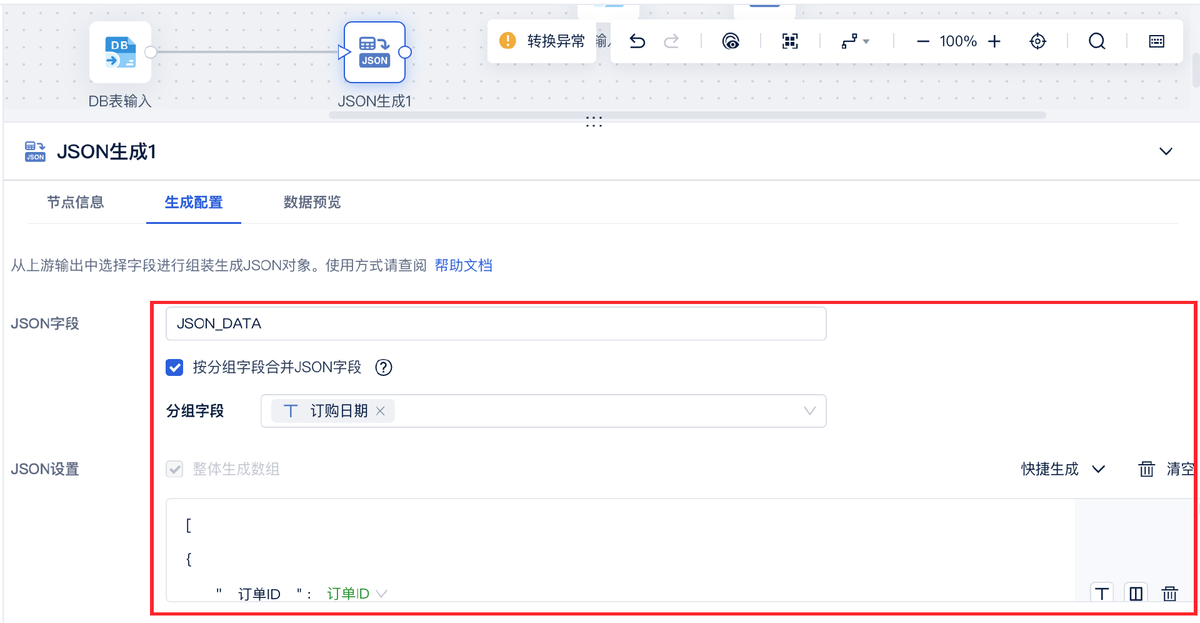
具体怎么做数据转换?
使用 API 输出,实现将 API 数据写入指定接口,将数据库或者其他形式的数据生成为 JSON 格式,以便进行数据交互。可以借助数据集成与治理一体化平台FineDataLink,使用 JSON 生成算子,生成 JSON 格式数据,满足复杂业务场景下的数据清洗、转换和同步等需求。
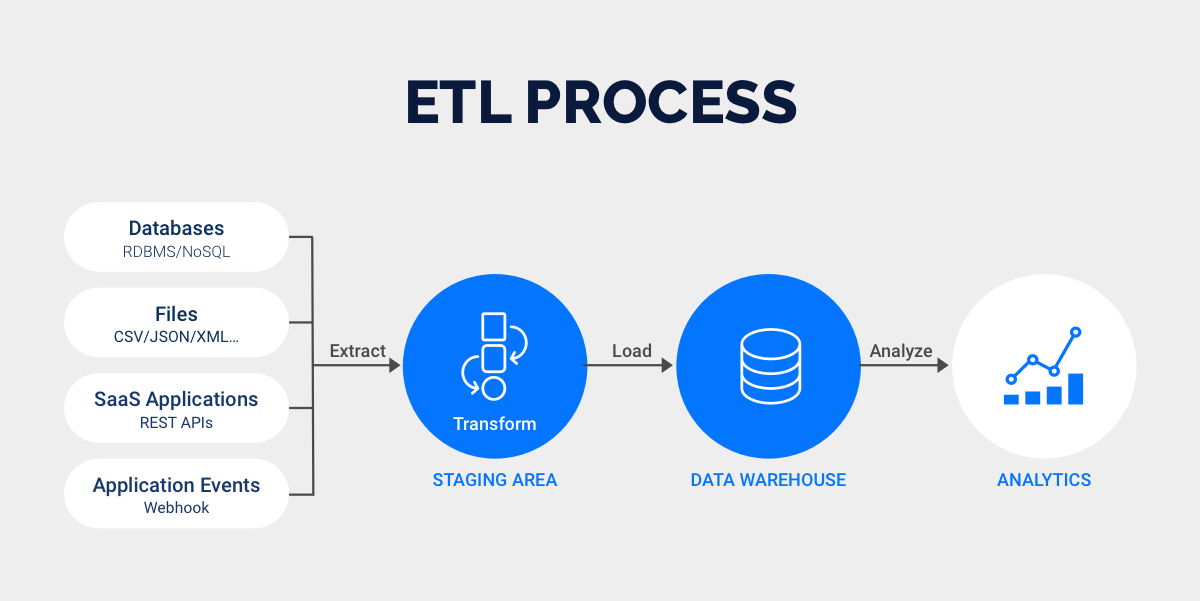
2. ETL设计:让模型能跑起来
ETL(抽取-转换-加载)是模型落地的关键。很多团队在这一步容易出问题:
- 要么是ETL的任务链太长,依赖关系复杂,导致经常失败;
- 要么是转换逻辑写死在代码里,需求一变更,就得重新开发。
正确的打开方式是:
- 用元数据管理ETL流程:借助FineDataLink把任务依赖可视化,设置重试机制和告警;
- 把转换逻辑“参数化”:像时间窗口(按天/周/月聚合)、维度过滤条件这些,用配置表来管理,别硬写到代码里;
- 保留“中间结果”:在ETL过程中输出临时表,比如清洗后的用户明细表,方便排查问题和回溯。
3. 存储选型:让模型跑得快
不同的模型场景,得用不同的存储介质:
- 经常查询的小数据集:用关系型数据库(MySQL、PostgreSQL)或者OLAP引擎(ClickHouse);
- 大规模的明细数据:用分布式存储(Hive、HBase)或者数据湖(Delta Lake、Iceberg);
- 有实时数据需求的:用流批一体存储(Flink + Kafka)。
要注意的是:
别为了用新技术而选复杂的存储方式。比如存用户画像,要是没有强一致性的需求,用MySQL加Redis的组合,可能比用HBase更简单高效。
四、迭代优化
数据模型上线了不算完,它的生命周期长着呢。随着业务发展,模型得不断迭代——这一点很多团队都容易忽略,最后往往要付出额外的成本。
1. 什么时候该迭代了?
出现这些情况,就得考虑优化模型了:
- 性能下降:以前10秒能出结果的查询,现在要1分钟,可能是数据量太大了,也可能是索引失效了;
- 满足不了新需求:业务方需要新的维度(比如“用户社交关系”)或者新的度量(比如“分享率”);
- 存储成本太高:模型冗余太多,比如雪花模型的多层维度表重复存储数据,导致存储费用飙升。
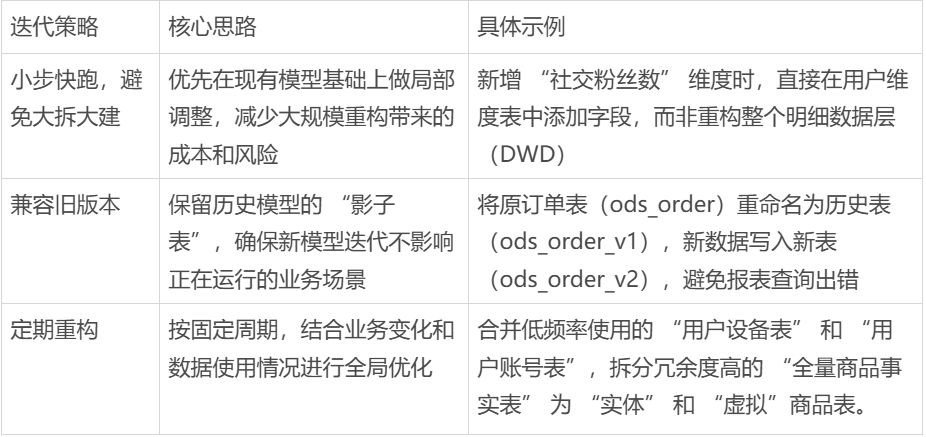
2. 迭代有啥策略?
迭代不能拍脑袋决定,得看数据反馈进行策略调整:
结语
数据建模是把业务价值和技术实现连起来的“结合点”,一个好的模型:
- 让业务的人看得懂、用着顺,
- 让技术的人改起来方便、跑起来顺畅。
还想跟你说句实在话:“先让模型能用起来,再慢慢让它变好。”别追求一开始就做出“完美模型”,在业务迭代中不断优化,这才是数据建模最实在的经验。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号