价格监控:接口请求还是模拟点击?一次性能对比分享
原创

爬虫代理
在做电商运营支持的时候,我经常被问到一个问题:
如果要监控京东上“笔记本电脑”类目的商品价格,到底是直接调接口更划算,还是用浏览器自动化工具去点页面更稳妥?
这个问题看似简单,但在真正跑到生产环境里时,差别就很大了。
瓶颈最先暴露的地方
当时我跑了两条路线:
- 直接打接口:就是用 HTTP 请求去抓取京东的搜索接口,返回的是结构化数据。
- 模拟用户点搜索:通过 Playwright 打开京东首页,输入“笔记本电脑”,点搜索按钮,等结果出来再解析。
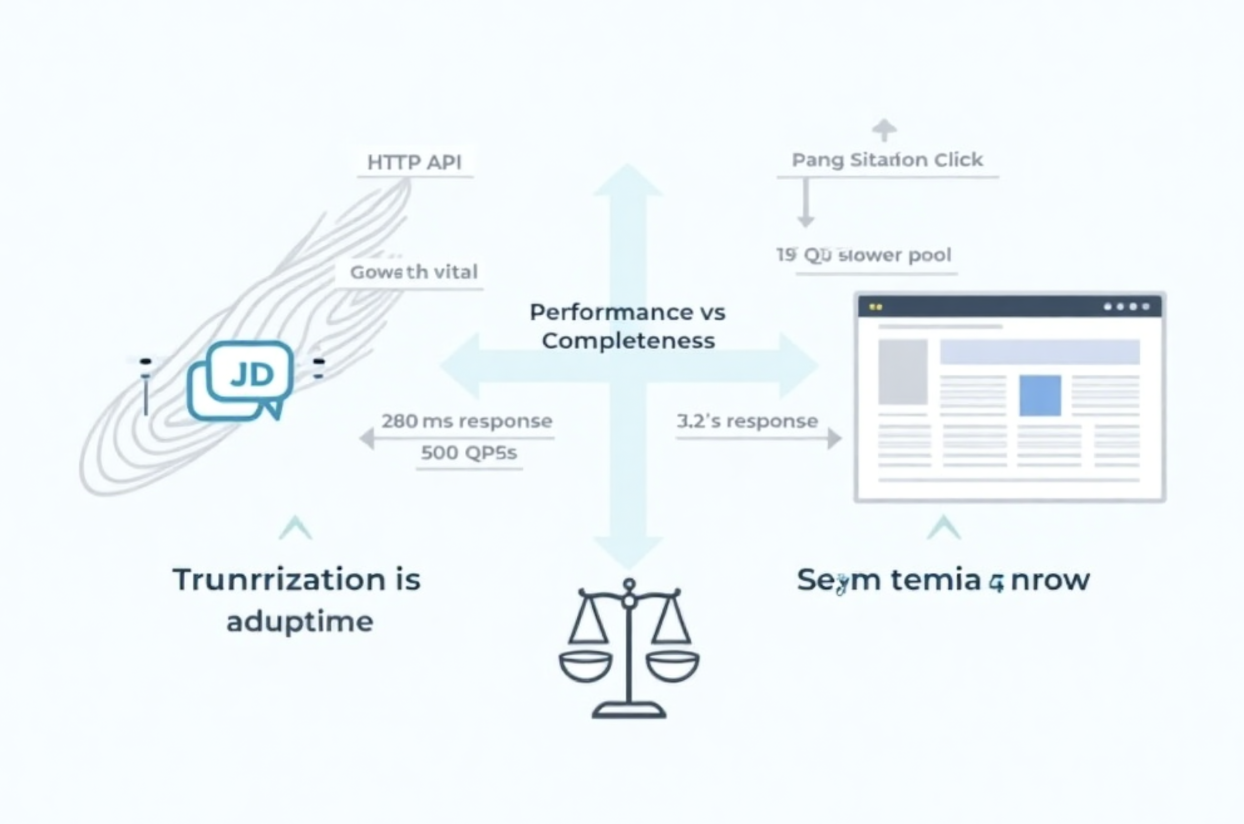
跑下来之后,最大的差别在于耗时。接口方式大概两三百毫秒能拿到一页数据,页面模拟基本要等个三四秒。并发的时候差距更明显,API 轻松上千并发,浏览器这边单机撑死几十个实例。
两种方式的差异
我就不列表格了,用几个维度来讲:
- 速度:接口明显快,页面模拟慢。
- 资源消耗:接口轻量,浏览器很吃 CPU 和内存。
- 封禁风险:接口容易触发 403 或 429,浏览器更像用户操作,通常顶得住。
- 数据完整度:接口返回的字段有限,比如一些促销标签、倒计时活动不一定有,页面模拟就比较完整。
我是怎么优化的
接口这一块,我接了一个代理池(用的是爬虫代理),加上 cookie 和 UA 模拟真实请求,错误率从 5% 降到 2%。并且我改成了异步请求,单机吞吐量能跑到 500 QPS 以上。
浏览器那边,我调成无头模式,并且做了浏览器池,不用每次都新建实例,整体效率比最初提升了 2-3 倍。虽然还是比接口慢,但至少能在需要的时候补充拿到那些动态渲染的数据。
我做的小测试
场景是抓取京东上“笔记本电脑”前 100 页商品:
- 接口方式:一千次请求,平均 280ms,错率 5%(主要是 403),加代理后错率降到 2%。
- 页面模拟:一千次搜索,平均 3.2s,错率 2%(主要是超时),优化后单机能跑到 50 QPS。
代码片段
接口方式(用了代理):
import requests
#设置爬虫代理IP 参考亿牛云示例
proxy_host = "proxy.16yun.cn"
proxy_port = "3100"
proxy_user = "16YUN"
proxy_pass = "16IP"
proxies = {
"http": f"http://{proxy_user}:{proxy_pass}@{proxy_host}:{proxy_port}",
"https": f"http://{proxy_user}:{proxy_pass}@{proxy_host}:{proxy_port}",
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/127.0 Safari/537.36",
"Cookie": "your_cookie_here"
}
url = "https://api.m.jd.com/search?keyword=笔记本电脑&page=1"
res = requests.get(url, headers=headers, proxies=proxies, timeout=10)
print(res.json())页面模拟方式:
from playwright.sync_api import sync_playwright
#设置爬虫代理IP 参考亿牛云示例
proxy_host = "proxy.16yun.cn"
proxy_port = "3100"
proxy_user = "16YUN"
proxy_pass = "16IP"
proxy_config = {
"server": f"http://{proxy_host}:{proxy_port}",
"username": proxy_user,
"password": proxy_pass
}
with sync_playwright() as p:
browser = p.chromium.launch(headless=True, proxy=proxy_config)
page = browser.new_page()
page.set_extra_http_headers({"User-Agent": "Mozilla/5.0 ..."})
page.goto("https://www.jd.com")
page.fill("input[name='keyword']", "笔记本电脑")
page.click("button[aria-label='搜索']")
page.wait_for_selector(".gl-item")
products = page.query_selector_all(".gl-item")
for product in products:
print(product.inner_text())
browser.close()最后的结论
如果是价格、评论数这种核心数据,API 是首选,速度快、能跑大规模。
但如果要拿促销活动、标签这些动态信息,页面模拟更靠谱。
所以我现在的做法是:
- 主力靠 API 抓大盘。
- 页面模拟做补充。
这样既保证性能,又能覆盖完整数据。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号