BUUCTF [UTCTF2020]spectogram 1

BUUCTF [UTCTF2020]spectogram 1

YueXuan
发布于 2025-08-18 20:17:07
发布于 2025-08-18 20:17:07
题目描述:
得到的 flag 请包上 flag{} 提交。
密文:
下载附件,得到attachment.wav

解题思路:
1、用Audacity打开attachment.wav,显示频谱图,似乎有隐藏信息。
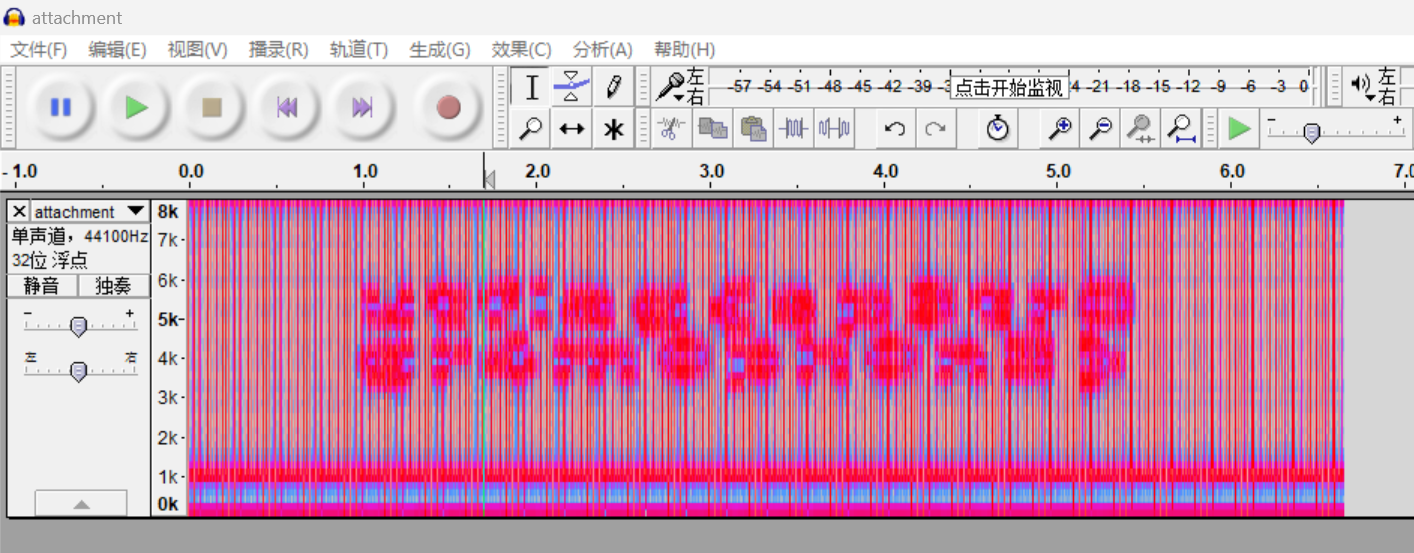
在这里插入图片描述
2、从题目spectogram了解到“语谱图”的存在,我们需要呈现音频的语谱图,目前总结三种方法。

在这里插入图片描述
方法一:
在Audacity中,“编辑”选项卡“首选项” -> “频谱图”,FFT(快速傅里叶窗口变换)窗口大小由默认的256改为1024。
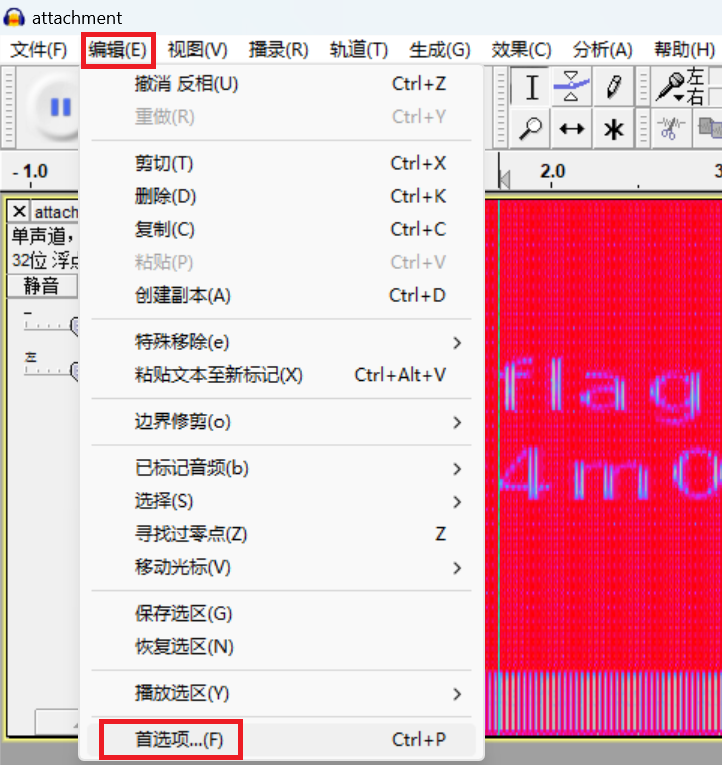
在这里插入图片描述
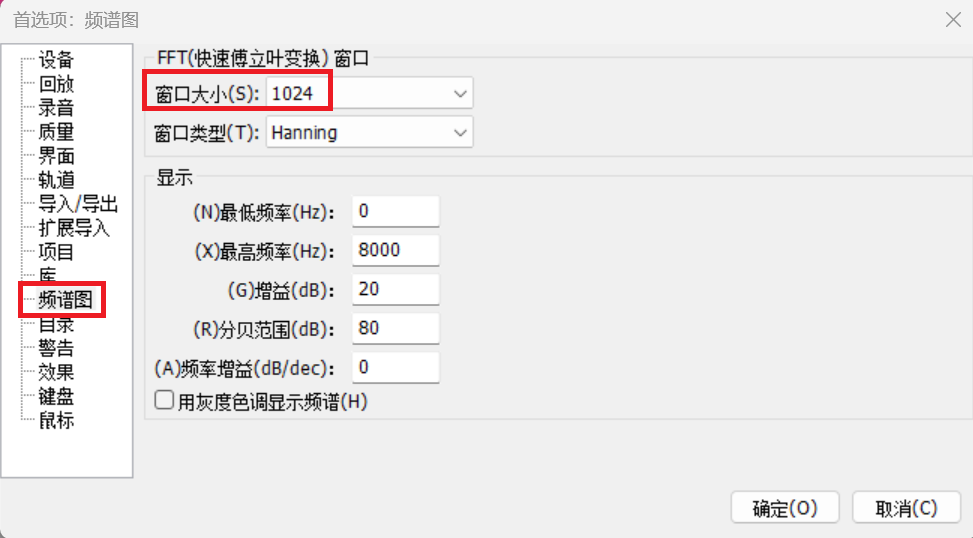
在这里插入图片描述
点击确定,将图像拉宽,得到flag:utflag{sp3tr0gr4m0ph0n3}。
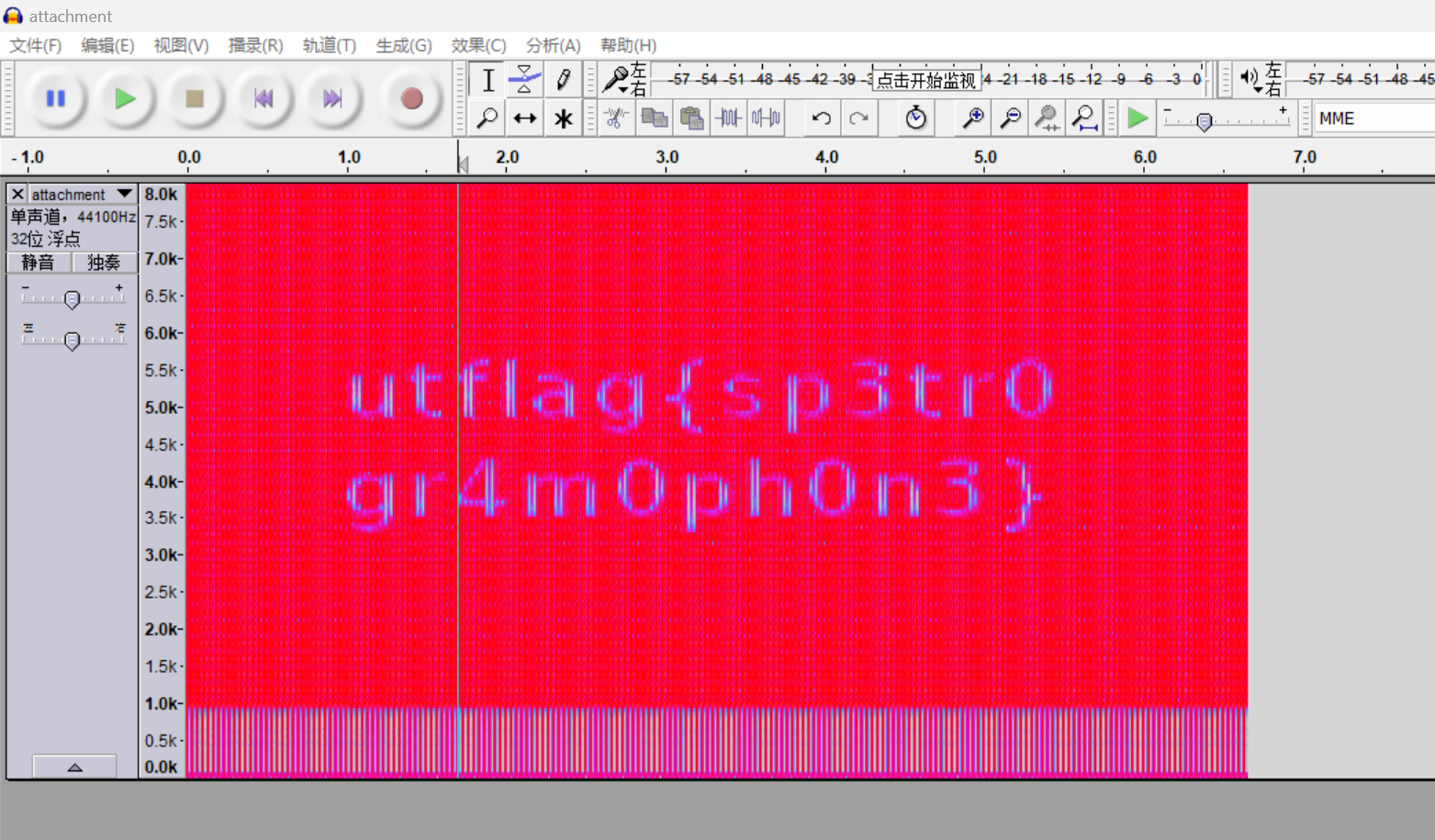
在这里插入图片描述
方法二:
使用Sonic Visualiser分析attachment.wav,得到它的语谱图。
Sonic Visualiser下载地址:https://www.sonicvisualiser.org/download.html
在这里插入图片描述
打开文件后,在Layer选项中点击Add Peak Frequency Spectrogram或者使用Shift+K,然后将右边选项调整成如下图所示,得到flag。
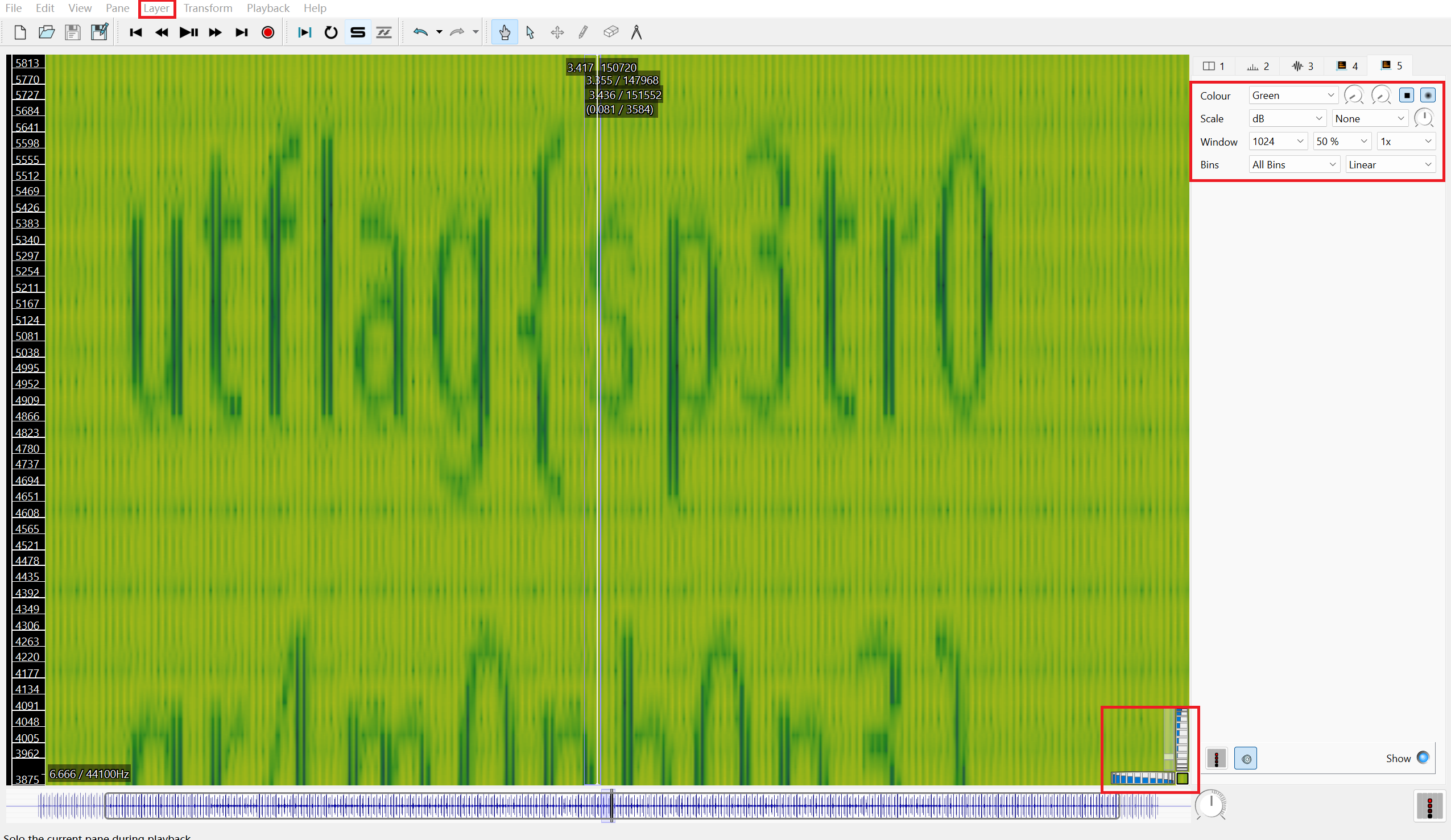
方法三:
网上找到的脚本,效果不错。
import matplotlib.pyplot as plt
import librosa
import numpy as np
import soundfile as sf
import python_speech_features as psf
import librosa
import librosa.display
# Spectrogram步骤,
# Step 1: 预加重
# Step 2: 分帧
# Step 3: 加窗
# Step 4: FFT
# Step 5: 幅值平方
# Step 6: 对数功率
def preemphasis(signal, coeff=0.95):
return np.append(signal[1], signal[1:] - coeff * signal[:-1])
def pow_spec(frames, NFFT):
complex_spec = np.fft.rfft(frames, NFFT)
return 1 / NFFT * np.square(np.abs(complex_spec))
def frame_sig(sig, frame_len, frame_step, win_func):
'''
:param sig: 输入的语音信号
:param frame_len: 帧长
:param frame_step: 帧移
:param win_func: 窗函数
:return: array of frames, num_frame * frame_len
'''
slen = len(sig)
if slen <= frame_len:
num_frames = 1
else:
# np.ceil(), 向上取整
num_frames = 1 + int(np.ceil((slen - frame_len) / frame_step))
padlen = int( (num_frames - 1) * frame_step + frame_len)
# 将信号补长,使得(slen - frame_len) /frame_step整除
zeros = np.zeros((padlen - slen,))
padSig = np.concatenate((sig, zeros))
indices = np.tile(np.arange(0, frame_len), (num_frames, 1)) + np.tile(np.arange(0, num_frames*frame_step, frame_step), (frame_len, 1)).T
indices = np.array(indices, dtype=np.int32)
frames = padSig[indices]
win = np.tile(win_func(frame_len), (num_frames, 1))
return frames * win
y, sr = sf.read('attachment.wav') # 音频文件
# 预加重
y = preemphasis(y, coeff=0.98)
# 分帧加窗
frames = frame_sig(y, frame_len=2048, frame_step=512, win_func=np.hanning)
# FFT及幅值平方
feature = pow_spec(frames, NFFT=2048)
# 对数功率及绘图.
librosa.display.specshow(librosa.power_to_db(feature.T),sr=sr, x_axis='time', y_axis='linear')
plt.title('Spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.tight_layout()
plt.show()得到的语谱图:
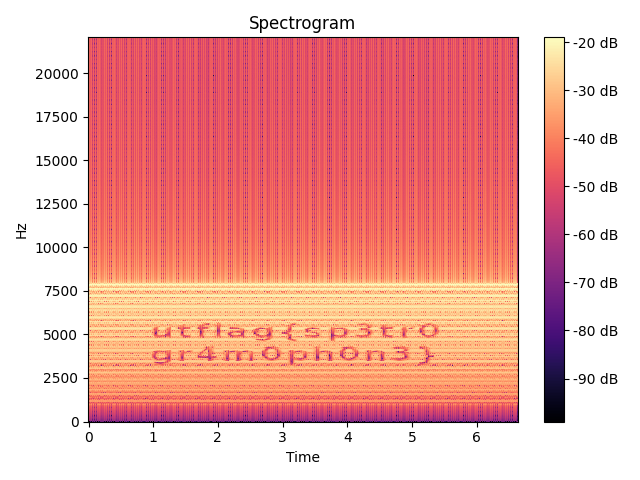
flag:
flag{sp3tr0gr4m0ph0n3}本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-02-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号