企业微信 + 豆包新模型:API 接口驱动的智能自动回复体系构建

企业微信 + 豆包新模型:API 接口驱动的智能自动回复体系构建

正在走向自律
发布于 2025-08-14 08:47:40
发布于 2025-08-14 08:47:40
摘要:本文以企业微信开放接口和豆包大模型为核心,构建一套“消息实时接收→语义理解→智能回复→多渠道发送”的闭环体系;通过轻量级 Flask 网关统一处理加解密、重试、日志与监控,实现金融、教育、零售等多场景的 7×24 小时自动客服,显著降低人力成本并提升用户体验。本项目是实战过,已投入真实项目中,有意合作请文章末尾公众号联系博主!
企业微信 + 豆包新模型:API 接口驱动的智能自动回复体系构建
引言
在数字化转型加速推进的今天,企业对高效沟通和智能化运营的需求日益凸显。传统的人工消息处理模式,不仅响应速度慢,还容易出现信息传递偏差,难以满足企业快速发展的需求。
企业微信作为企业级的沟通与协同平台,已成为众多企业内部管理和外部客户连接的重要工具。而豆包新模型凭借其强大的自然语言处理能力,在智能交互领域展现出巨大潜力。将企业微信的 API 接口与豆包新模型相结合,打造智能自动回复系统,能够实现消息的实时处理和精准回复,大幅提升企业沟通效率。本文将详细介绍这一系统的构建过程,为技术开发者提供全面的指导。
一、企业微信与豆包新模型概述
1.1 企业微信的功能特性与 API 生态
企业微信是专为企业打造的综合性办公平台,融合了沟通、协作、管理等多种功能,为企业提供了高效的运营解决方案。
在沟通方面,企业微信支持单聊、群聊、语音通话、视频会议等多种形式,满足企业内部员工之间以及企业与外部客户之间的多样化沟通需求。协作功能上,企业微信提供了日程安排、任务分配、文件共享、考勤管理等工具,助力团队高效协同工作。
企业微信的 API 生态十分丰富,为开发者提供了广阔的二次开发空间。其 API 接口涵盖了消息管理、用户管理、部门管理、应用管理等多个领域。其中,消息管理相关的 API 接口是实现自动回复功能的核心,包括消息接收接口、消息发送接口等。通过这些接口,开发者可以实现消息的自动接收、处理和发送,构建个性化的消息处理系统。
目前,企业微信已广泛应用于金融、教育、医疗、零售等多个行业。例如,在金融行业,企业通过企业微信向客户推送理财产品信息和风险提示;在教育行业,学校利用企业微信向家长发送学生的学习情况和校园通知。
1.2 豆包新模型的技术特性与优势
豆包新模型是一款基于先进人工智能技术的自然语言处理模型,具备强大的语义理解和文本生成能力。
该模型通过大规模的语料训练,能够准确理解用户的语言意图,包括询问、请求、抱怨等多种类型。在文本生成方面,豆包新模型可以根据用户的输入生成自然、流畅、符合语境的回复内容,实现与用户的自然交互。
豆包新模型的优势主要体现在以下几个方面:一是多轮对话能力强,能够记住上下文信息,实现连贯的对话;二是知识覆盖范围广,能够解答各个领域的常见问题;三是响应速度快,能够在短时间内完成消息处理和回复生成;四是可定制性高,能够根据企业的具体需求进行个性化训练和调整。
在实际应用中,豆包新模型已被广泛用于智能客服、智能问答、内容创作等场景,为企业节省了大量的人力成本,提升了服务质量和效率。
二、实现自动回复的技术原理
2.1 企业微信 API 接口深度解析
企业微信的 API 接口是实现与企业微信平台交互的桥梁,要实现自动回复功能,必须深入理解相关 API 接口的调用方式和参数设置。
消息接收接口是企业微信向开发者的服务器推送用户消息的接口。当用户在企业微信中向指定应用发送消息时,企业微信会将消息封装成特定的格式,通过 POST 请求发送到开发者预先设置的回调 URL。消息接收接口的请求参数包括 MsgSignature(消息签名)、Timestamp(时间戳)、Nonce(随机数)和 Encrypt(加密的消息内容)。开发者需要对这些参数进行验证和解密,才能获取原始的消息内容。
消息发送接口用于向企业微信用户发送消息,支持多种消息类型,如文本、图片、语音、视频、文件、图文等。不同类型的消息,其发送接口的参数有所不同。以发送图文消息为例,需要指定接收用户的 ID、消息类型、图文消息的标题、描述、图片 URL、点击跳转 URL 等参数。
以下是一个调用企业微信消息发送接口发送文本消息的示例代码:
import requests
import json
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
CORPID = os.getenv("CORPID")
CORPSECRET = os.getenv("CORPSECRET")
AGENTID = os.getenv("AGENTID")
def get_access_token():
"""获取访问令牌"""
url = f"https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={CORPID}&corpsecret={CORPSECRET}"
response = requests.get(url)
result = json.loads(response.text)
if result.get("errcode") == 0:
return result.get("access_token")
else:
raise Exception(f"获取access_token失败:{result.get('errmsg')}")
def send_text_message(access_token, touser, content):
"""发送文本消息"""
url = f"https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={access_token}"
data = {
"touser": touser,
"msgtype": "text",
"agentid": AGENTID,
"text": {
"content": content
},
"safe": 0
}
response = requests.post(url, data=json.dumps(data))
result = json.loads(response.text)
if result.get("errcode") != 0:
raise Exception(f"发送文本消息失败:{result.get('errmsg')}")
return result
# 示例使用
if __name__ == "__main__":
try:
access_token = get_access_token()
send_result = send_text_message(access_token, "user001", "您好,这是一条自动发送的文本消息!")
print("消息发送成功:", send_result)
except Exception as e:
print("发生错误:", e)在上述代码中,首先通过get_access_token函数获取访问令牌,这是调用企业微信 API 接口的必要凭证。然后,send_text_message函数构造文本消息的数据结构,并通过 POST 请求发送到企业微信的消息发送接口。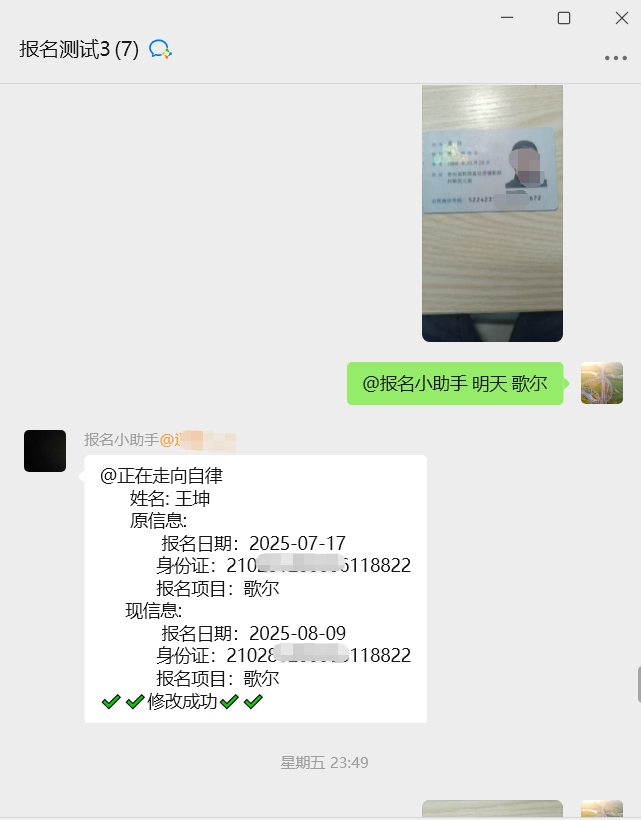
2.2 豆包新模型在自动回复中的作用机制
豆包新模型在自动回复系统中起着核心的消息处理和回复生成作用,其工作机制主要包括以下几个步骤:
首先是消息预处理。当接收到用户发送的消息后,系统会对消息进行预处理,包括去除冗余信息、进行分词等操作,以便豆包新模型更好地理解消息内容。
然后是语义理解。豆包新模型对预处理后的消息进行深度分析,理解用户的意图和需求。例如,用户发送 “请问明天的会议安排是什么?”,模型能够识别出用户的意图是查询明天的会议安排。
接下来是回复生成。根据对用户意图的理解,豆包新模型结合自身的知识储备和企业的业务数据,生成合适的回复内容。回复内容不仅要准确解答用户的问题,还要符合企业的沟通规范和语气风格。
最后是回复优化。系统会对豆包新模型生成的回复内容进行进一步优化,如调整格式、补充必要的信息等,确保回复内容的准确性和可读性。
豆包新模型在处理复杂消息和语义理解方面具有独特的优势。对于模糊不清的消息,模型能够通过上下文分析和语义推理,准确把握用户的真实意图;对于专业领域的问题,模型能够利用其丰富的知识储备,提供专业、准确的回复。
2.3 企业微信与豆包新模型结合的技术架构与流程
企业微信与豆包新模型结合实现自动回复功能的技术架构主要由以下几个部分组成:
- 接入层:负责接收企业微信推送的用户消息,并将系统生成的回复消息发送给企业微信。接入层通过企业微信的 API 接口与企业微信平台进行交互。
- 处理层:包括消息解析模块、豆包新模型调用模块和回复生成模块。消息解析模块对接收的消息进行解析和预处理;豆包新模型调用模块将预处理后的消息发送给豆包新模型,并获取模型生成的回复;回复生成模块对模型生成的回复进行优化和格式化。
- 数据层:用于存储用户信息、消息记录、企业业务数据等。数据层可以采用关系型数据库(如 MySQL)或非关系型数据库(如 MongoDB)。
- 管理层:包括配置管理模块、日志管理模块和监控模块。配置管理模块用于管理系统的各项配置参数;日志管理模块记录系统的运行日志和用户交互日志;监控模块实时监控系统的运行状态,及时发现和处理异常情况。
企业微信与豆包新模型结合实现自动回复的具体流程如下:
- 用户在企业微信中向指定应用发送消息。
- 企业微信将用户消息通过消息接收接口推送至系统的接入层。
- 接入层将消息传递给处理层的消息解析模块,进行消息解析和预处理。
- 消息解析模块将预处理后的消息发送给豆包新模型调用模块。
- 豆包新模型调用模块调用豆包新模型的 API 接口,将消息发送给豆包新模型,并获取模型生成的回复。
- 回复生成模块对模型生成的回复进行优化和格式化。
- 接入层通过企业微信的消息发送接口,将优化后的回复消息发送给用户。
- 系统将用户消息和回复消息存储到数据层,并记录相关日志。
2.4 经典代码案例与解释
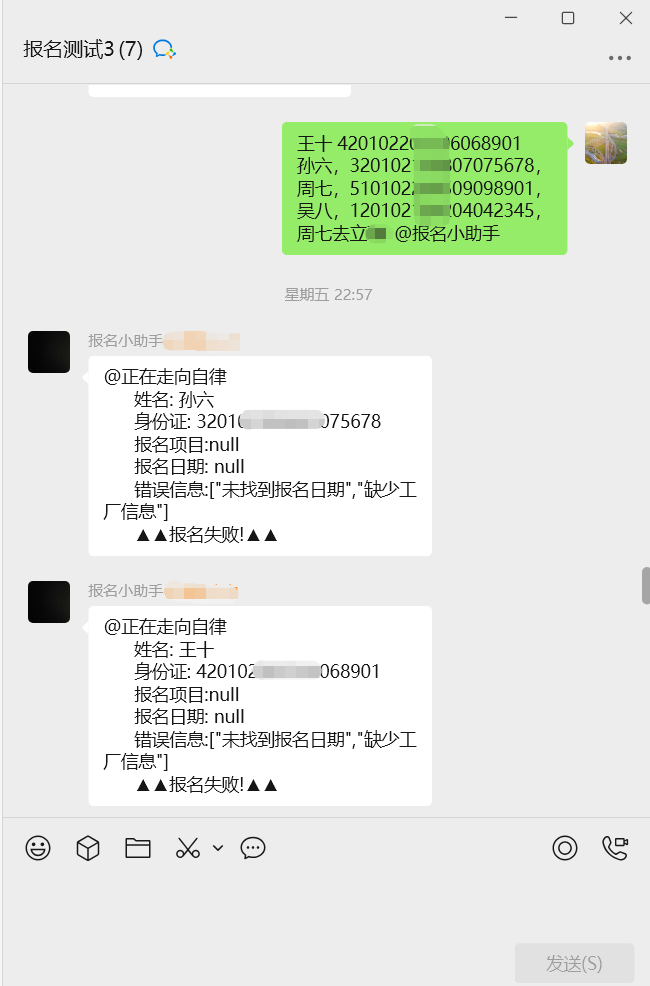
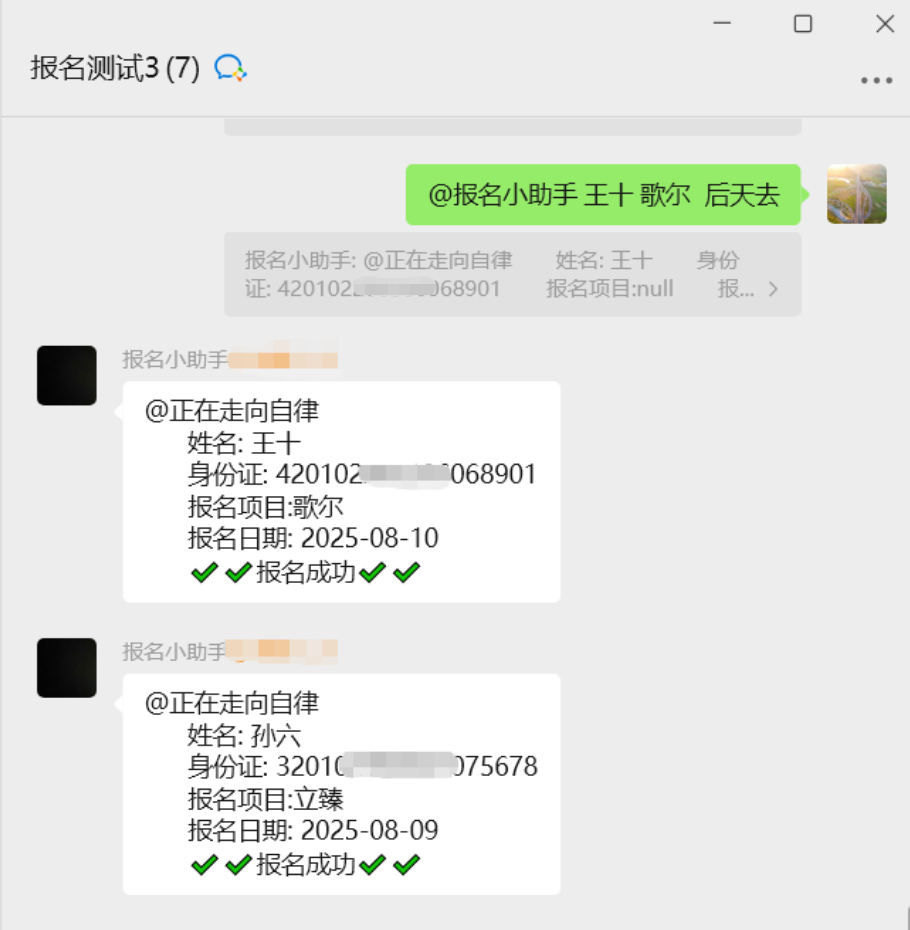
1.文本自动回复(最小闭环)
@app.route("/wx/callback", methods=["POST"])
def callback():
msg = parse_msg(request.data) # 解密+XML→dict
answer = doubao.chat(msg["Content"]) # 调用豆包
send_text_message(msg["FromUserName"], answer) # 回发企业微信
return "success"解释:单函数完成“收→懂→回”三步,20 行代码即可跑通全链路,适合 MVP 验证。
2.图文卡片营销消息(多类型消息)
media_id = upload_image(token, "poster.png") # 1. 上传素材
articles = [{
"title": "新手理财课堂", "description": "年化 4%+ 安全稳健",
"url": "https://example.com/course", "picurl": media_id
}]
send_mpnews_message(token, user, articles) # 2. 群发图文解释:先拿 media_id,再组装多图文,实现“一张海报+跳转链接”的高转化推送。
3.异步并发优化(生产级部署)
from celery import Celery
@app.route("/wx/callback")
def callback_async():
handle_msg.delay(request.get_data()) # 丢进任务队列
return "success"
@celery.task
def handle_msg(xml):
msg = parse_msg(xml)
answer = doubao.chat(msg["Content"])
send_text_message(msg["FromUserName"], answer)解释:利用 Celery+RabbitMQ 把耗时模型调用异步化,避免微信 5 秒超时,支持万级并发。
三、开发前的准备工作
3.1 环境搭建
开发企业微信与豆包新模型结合的自动回复系统,需要搭建合适的开发环境,具体包括以下几个方面:
3.1.1 软件环境
- 操作系统:推荐使用 Linux 系统(如 Ubuntu 20.04),具有稳定性高、安全性好等优点,适合作为服务器运行环境。
- 编程语言:采用 Python 语言进行开发,Python 拥有丰富的第三方库,便于调用 API 接口和处理数据。
- 开发工具:使用 PyCharm 作为集成开发环境,PyCharm 提供了代码自动补全、调试、版本控制等功能,能够提高开发效率。
- 数据库:选用 MySQL 作为数据库,用于存储用户信息、消息记录等数据。
- Web 服务器:使用 Nginx 作为 Web 服务器,用于接收企业微信推送的消息和处理 HTTP 请求。
3.1.2 环境搭建步骤
安装 Linux 系统:可以通过虚拟机(如 VMware)安装 Ubuntu 20.04 系统,或直接在服务器上安装。
安装 Python:在 Ubuntu 系统中,默认已经安装了 Python,但可能不是最新版本。可以通过以下命令安装 Python 3.8:
sudo apt update
sudo apt install python3.8安装 PyCharm:从 JetBrains 官网下载 PyCharm 的 Linux 版本,解压后运行 bin 目录下的 pycharm.sh 文件进行安装。
安装 MySQL:通过以下命令安装 MySQL:
sudo apt install mysql-server安装完成后,启动 MySQL 服务,并进行初始化配置:
sudo systemctl start mysql
sudo mysql_secure_installation5.安装 Nginx:通过以下命令安装 Nginx:
sudo apt install nginx安装完成后,启动 Nginx 服务:
sudo systemctl start nginx6.配置 Python 虚拟环境:为了避免不同项目之间的依赖冲突,使用 venv 创建虚拟环境:
python3.8 -m venv myenv
source myenv/bin/activate7.安装必要的 Python 库:在虚拟环境中,通过 pip 安装 requests、pymysql、flask 等库:
pip install requests pymysql flask python-dotenv3.1.3 注意事项
- 在安装软件时,要确保软件版本的兼容性,避免因版本不兼容导致的问题。
- 配置 MySQL 时,要设置强密码,并限制远程访问,提高数据库的安全性。
- 启动服务后,要通过相关命令检查服务是否正常运行,如systemctl status mysql检查 MySQL 服务状态。
- 在开发过程中,要定期备份代码和数据,防止数据丢失。
3.2 账号与权限配置
要实现企业微信与豆包新模型的结合,需要进行相关账号的注册和权限配置,具体步骤如下:
3.2.1 企业微信账号与权限配置
- 注册企业微信:访问企业微信官网,点击 “立即注册”,填写企业名称、行业类型、人员规模等信息,完成注册。
- 创建应用:登录企业微信管理后台,进入 “应用管理” 页面,点击 “创建应用”。填写应用名称、上传应用头像,选择应用可见范围,点击 “创建” 按钮。创建成功后,会获得应用的 AgentID 和 Secret。
- 获取企业 ID:在企业微信管理后台的 “我的企业” 页面,找到 “企业信息” 部分,即可获取企业 ID(corpid)。
- 配置回调 URL:在应用详情页面,找到 “接收消息” 部分,点击 “设置” 按钮。填写回调 URL(需要是公网可访问的 URL)、Token 和 EncodingAESKey,点击 “保存” 按钮。Token 和 EncodingAESKey 用于消息的加密和解密验证,可以随机生成。
- 权限申请:根据系统功能需求,在企业微信管理后台为应用申请相应的权限。例如,如果需要获取用户信息,需要申请 “成员信息读权限”。
3.2.2 豆包新模型账号与权限配置
- 注册豆包账号:访问豆包官方网站,点击 “注册” 按钮,填写手机号码、验证码等信息,完成账号注册。
- 申请 API 密钥:登录豆包账号后,进入开发者中心,找到 API 密钥申请页面,填写应用名称、应用描述等信息,提交申请。申请通过后,会获得 API Key 和 API Secret,用于调用豆包新模型的 API 接口。
- 了解 API 使用限制:在开发者中心,查看豆包新模型 API 的使用限制,如调用次数限制、频率限制等,确保系统在使用过程中不会超出限制。
3.3 相关工具与依赖库安装
除了上述开发环境和账号配置外,还需要安装一些相关工具和依赖库,以辅助系统开发和运行:
- Postman:用于测试 API 接口的工具,可以发送 HTTP 请求并查看响应结果。下载地址:Postman: The World's Leading API Platform | Sign Up for Free
- Navicat:用于管理 MySQL 数据库的可视化工具,支持数据库的创建、查询、修改等操作。下载地址:Navicat GUI | Comprehensive Database Management Tool
- Redis:用于缓存数据,提高系统的响应速度。安装命令:sudo apt install redis-server
- Supervisor:用于进程管理,确保系统服务能够持续运行。安装命令:sudo apt install supervisor
在 Python 虚拟环境中,还需要安装以下依赖库:
- cryptography:用于消息的加密和解密,安装命令:pip install cryptography
- redis:用于操作 Redis 数据库,安装命令:pip install redis
- gunicorn:用于运行 Flask 应用的 WSGI 服务器,安装命令:pip install gunicorn
四、代码实现与示例
4.1 调用企业微信接口发送各类消息的代码实现
企业微信支持多种类型的消息发送,以下分别介绍文本、图片、文件消息的发送代码实现。
4.1.1 发送文本消息
如 2.1 节中的示例代码所示,通过调用企业微信的消息发送接口,指定消息类型为 “text”,并设置文本内容即可发送文本消息。
4.1.2 发送图片消息
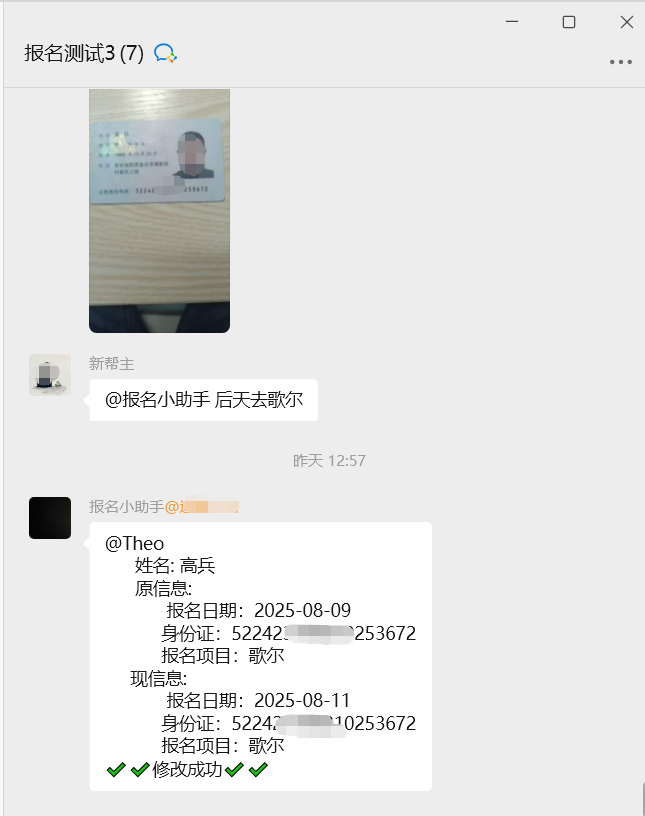
发送图片消息需要先上传图片获取 media_id,然后再调用消息发送接口发送图片消息。以下是实现代码:
def upload_image(access_token, image_path):
"""上传图片获取media_id"""
url = f"https://qyapi.weixin.qq.com/cgi-bin/media/upload?access_token={access_token}&type=image"
files = {
"media": open(image_path, "rb")
}
response = requests.post(url, files=files)
result = json.loads(response.text)
if result.get("errcode") == 0:
return result.get("media_id")
else:
raise Exception(f"上传图片失败:{result.get('errmsg')}")
def send_image_message(access_token, touser, media_id):
"""发送图片消息"""
url = f"https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={access_token}"
data = {
"touser": touser,
"msgtype": "image",
"agentid": AGENTID,
"image": {
"media_id": media_id
},
"safe": 0
}
response = requests.post(url, data=json.dumps(data))
result = json.loads(response.text)
if result.get("errcode") != 0:
raise Exception(f"发送图片消息失败:{result.get('errmsg')}")
return result
# 示例使用
if __name__ == "__main__":
try:
access_token = get_access_token()
media_id = upload_image(access_token, "test.jpg")
send_result = send_image_message(access_token, "user001", media_id)
</doubaocanvas>【本文10个关键字解释】 1. corpid(企业ID) 企业微信后台“我的企业→企业信息”中生成的唯一身份标识,所有 API 调用都需携带,用于区分不同企业租户,长度 18 位,一经创建不可修改。
2. corpsecret(应用密钥) 每个自建应用或第三方应用独立生成的 43 位字符串,与 corpid 共同换取 access_token;必须保密保存,泄露会导致企业会话、通讯录等数据被非法访问。
3. access_token(接口令牌) 通过 corpid+corpsecret 换取的 2 小时有效期令牌,调用企业微信任何业务接口都必须在 URL 或 Header 中携带;过期需刷新,否则返回 41001 错误。
4. EncodingAESKey(消息加密密钥) 43 位 Base64 字符串,配合 Token 对企业微信推送的 XML 消息进行 AES 解密与签名校验;设置后所有回调消息均加密传输,防止中间人窃听。
5. AgentID(应用编号) 创建企业微信应用时自动分配的正整数,决定消息可见范围与权限;发送应用消息时必须指定 AgentID,否则企业成员无法收到对应通知。
6. doubao-api-key(豆包密钥) 登录豆包开发者中心后生成的 32 位字符串,用于 HTTP Header 鉴权;每个 key 默认有 QPS、日调用量上限,超限将返回 429 错误。
7. 回调 URL(接收地址) 部署在公网或内网穿透后的 HTTPS 地址,企业微信会把用户消息 POST 至此;需支持 200 响应且在 5 秒内返回,否则微信重试 3 次后丢弃。
8. media_id(临时素材 ID) 通过 media/upload 接口上传图片、文件后返回的 64 位字符串,3 天内有效;发送图片、语音、文件消息时必须使用此 ID,而非原始 URL。
9. 异步任务(Celery 队列) 将豆包模型调用、数据库写入等耗时逻辑放入 Celery 任务队列,由独立 Worker 异步执行;避免微信 5 秒超时,提升系统并发与稳定性。
10. 多轮上下文(会话记忆) 豆包模型支持传入 session_id 与历史对话数组,实现跨消息记忆;在企业客服场景中可记住用户姓名、订单号等信息,提供连贯、个性化回复
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-08-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号