KDD 2025 | 用 20% 的数据得到 105% 性能:基于平衡采样的通用时序预测语料库 BLAST

KDD 2025 | 用 20% 的数据得到 105% 性能:基于平衡采样的通用时序预测语料库 BLAST

时空探索之旅
发布于 2025-08-07 13:44:47
发布于 2025-08-07 13:44:47
论文标题:BLAST: Balanced Sampling Time Series Corpus for Universal Forecasting Models
作者:Zezhi Shao(邵泽志), Yujie Li(李雨杰), Fei Wang(王飞), Chengqing Yu(余澄庆), Yisong Fu(付屹松), Tangwen Qian(钱塘文), Bin Xu(许彬), Boyu Diao(刁博宇), Yongjun Xu(徐勇军), Xueqi Cheng(程学旗)
关键词:平衡采样,大规模时间序列数据集,通用时间序列预测
机构:中科院计算所
论文链接:https://arxiv.org/abs/2505.17871
代码:
- 使用BLAST预训练通用预测模型:https://github.com/GestaltCogTeam/BasicTS
- BLAST语料库:https://huggingface.co/datasets/ZezhiShao/BLAST
- 从头自行生成BLAST:https://github.com/GestaltCogTeam/BLAST

点击文末阅读原文跳转本文arXiv链接
Overview
近期,通用时间序列预测模型得到了越来越多的关注。这类模型通过具有大规模参数量、在大规模时序数据上预训练,能够实现跨领域的零样本预测能力。
现有的研究大多聚焦于模型架构,但本文则着重讨论通用预测能力的基石——数据。 我们发现,现有的时序预训练语料库存在显著的偏置(bias)。 通过设计更合理的采样方法,可以大幅减少对训练资源的消耗,同时提升泛化能力。 极限情况下,基于BLAST预训练只用 20% 的数据就能得到105%性能的模型。(如表 1 所示)
本文将分享我们发表于 SIGKDD 2025 的研究成果:BLAST: Balanced Sampling Time Series Corpus for Universal Forecasting Models,通过均衡采样构建了一个多样化的预训练语料库,达到了降本增效的目标:加速模型训练、提升模型泛化能力。
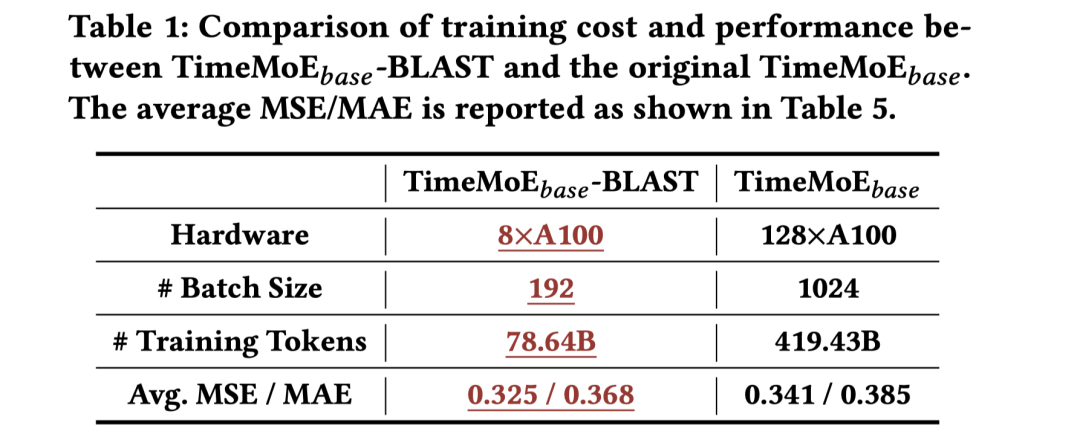
fig:
1. 通用时序预测模型
时间序列数据通常来源现实世界的时空系统(如气象、交通、电力等系统)。显然,这些系统的运行机制差异巨大。因此,时间序列数据通常呈现固有的异质性[1]。跨领域的巨大差异,使得研究人员需要针对特定领域重新训练模型,甚至重新选择和设计模型结构[2]。这无疑给时间序列预测技术的普及带来了很大的挑战:存在大量重复工作,且不同研究社区之间的沟通往往困难重重,哪怕研究的其实是同一种类型的数据[3]。
最近,受到大语言模型启发,通用时间序列预测模型成为了研究的热点,为解决上述核心问题提供了希望。很多研究者也将其称为“时序大模型”、“时间序列基础模型”、“时间序列通用模型”。但为了避免与多任务时间序列分析模型混淆,本文使用“通用时间序列预测”模型来指代这些能在多个领域实现准确零样本预测的模型。
通用时间序列预测模型通常采用大规模参数架构,通过在跨领域的大规模时间序列数据集上预训练,从而获取通用预测能力。例如,Chronos(及其变体 ChronosBolt)采用 Transformer 编码器-解码器架构、MOIRAI 采用 Transformer 编码器架构、TimeMoE 则采用 Transformer 解码器架构。他们都在大规模时间序列数据集上开展了预训练。
它们的性能逐步提升,参数量也越来越庞大,预训练数据也逐渐增多。最新的SOTA之一,TimeMoE ,使用了 128 块 A100 显卡,训练了 419.43B 个 Token(原始数据 309B)。
2. 现有的通用时序预测语料库及其采样方法
虽然这些模型越来越强,但它们的成本似乎也越来越高了,普通研究者越来越难以企及了。在这样的背景下,我们的出发点在于:这些模型训练过程中是否存在着浪费、泛化能力是否可以继续提升,能否进一步降本增效从而让更多的研究者可以负担得起。
为了实现这一目标,本文首次将目标聚焦于通用预测能力的基石:大规模时间序列预训练语料库。
上述预训练语料通常由多个子数据集构成。图 1(a) 给出了由三个子数据集组成的大规模数据集示例。对每条序列采用滑动窗口即可生成候选样本,并在此基础上进行采样就可以获得用于模型训练的数据。需要注意的是,不同子数据集之间的序列长度和序列数量可能存在显著差异。
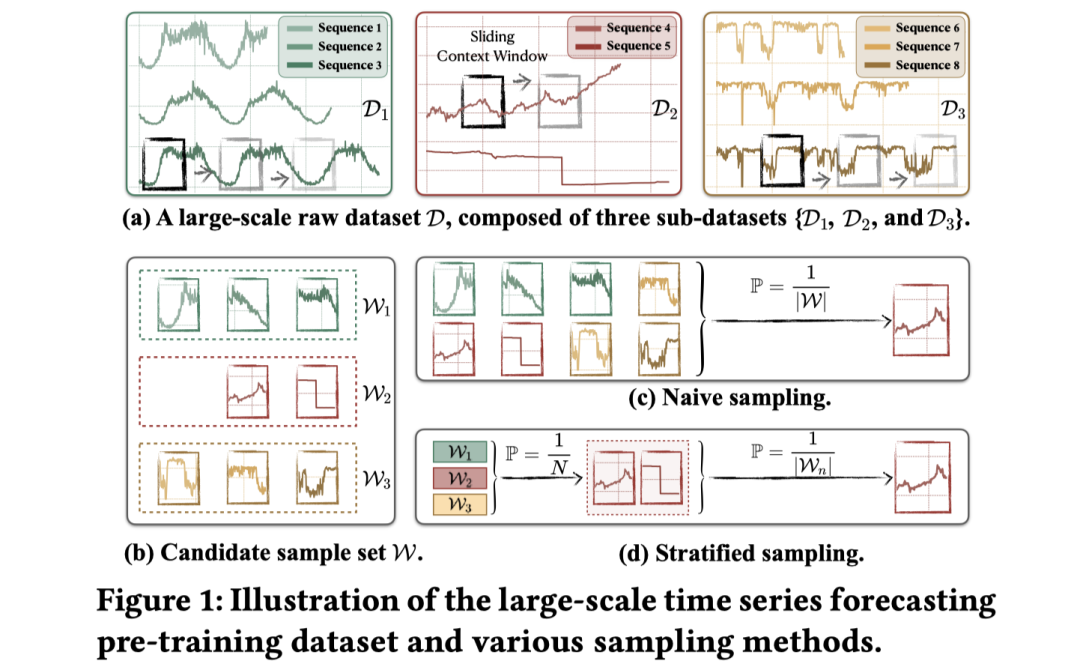
大规模时间序列预测预训练数据集,及多种采样方法的示意图
大规模时间序列预测预训练数据集,及多种采样方法的示意图
最新的研究通常把注意力放在模型架构上,而对于数据层面,通常只关心“数据量”(Scale)。例如,MOIRAI的预训练数据LOTSA超过了231B(如果考虑所有变量的话)个观测点,而TimeMoE的训练数据Time-300B则更大,达到了309B个观测值。这些大规模语料库毫无疑问地为通用时间序列的预训练模型奠定了基础。
尽管数据量在不断增大,但这些数据的“多样性”(diversity) 问题却未得到足够重视。高质量的训练数据应当覆盖广泛的模式,并确保各类样本数量均衡[4, 5, 6]。然而,大规模时间序列数据集的初始分布往往高度不均衡。如图 2(a) 所示,仅有三个数据集就占据了总数据量的 88.2%;图 2(b) 进一步凸显了序列长度的不均衡,较长序列往往贡献了不成比例的更多样本。这种偏斜分布会在原始数据中产生大量重复模式,从而削弱整体的数据多样性。因此,如何在保证模式丰富的同时实现样本的均衡采样,成为一个关键挑战。
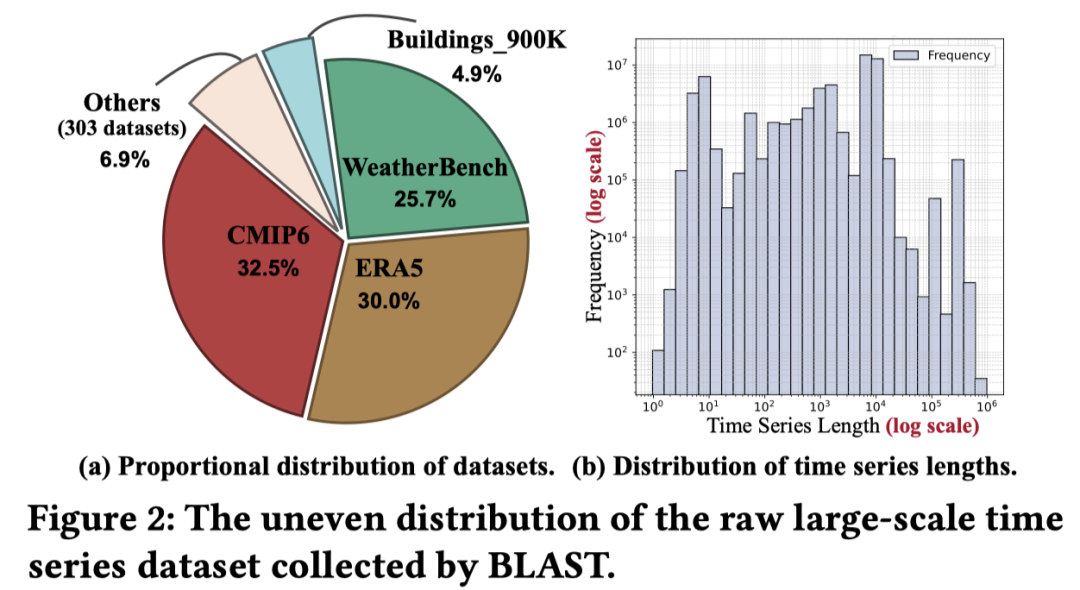
本文所收集的原始大规模时间序列数据集的不均匀分布
本文所收集的原始大规模时间序列数据集的不均匀分布
解决这一问题的核心思路,在于针对初始数据分布的设计更好的采样方法,从而获取无偏、多样的训练语料。然而,现有研究普遍忽视了这些不均衡问题,采用了朴素采样或分层采样等简单策略。前者在所有子数据集中均匀选取样本,如图 1(c);后者通常分两步进行:首先以均匀或加权的方式选取一个子数据集(或子域),然后在该子数据集中选取样本,如图 1(d)。
虽然这些采样策略直观且易于实现,但都不足以纠正大规模时间序列数据中固有的偏差。具体而言,朴素采样完全忽略了这些偏差,完全保留了原始数据的分布;分层采样虽试图缓解偏差,但常假定同一数据集或域内的数据共享相似模式——这一假设在很多情况下是合理的,却并非总是成立。例如,如图 1(a) 所示,D₁ 与 D₃ 同属交通域,却表现出截然不同的模式;同样,D₂ 内的两条时间序列也呈现出差异化的模式。
无法保证训练数据的多样性会带来显著的负面影响:模型可能对高频模式过拟合,而对低频模式欠拟合,从而削弱其泛化能力、降低训练效率。
3. BLAST:基于平衡采样的时间序列语料库
为了解决上述问题,我们提出了一种新的预训练语料——BLAST(BaLAnced Sampling Time series corpus,平衡采样时间序列语料)。
- 首先,我们整合了大量公开可得的数据集,构建出一个总计 3210 亿观测值的大规模数据集。
- 不同于以往依赖数据集或领域标签来区分时间序列模式的方法,BLAST 为每条时间序列引入了多种统计属性来进行全面表征,例如平稳性、季节性、波动性等。
- 随后,BLAST 通过离散化过程将这些异构特征融合为统一的特征向量,并投射到低维空间,从而直观揭示数据的非均匀分布。
- 接着,BLAST 在该低维空间中采用栅格采样(grid sampling)与栅格混合(grid mixup),以确保对多样模式进行均衡且具有代表性的覆盖。
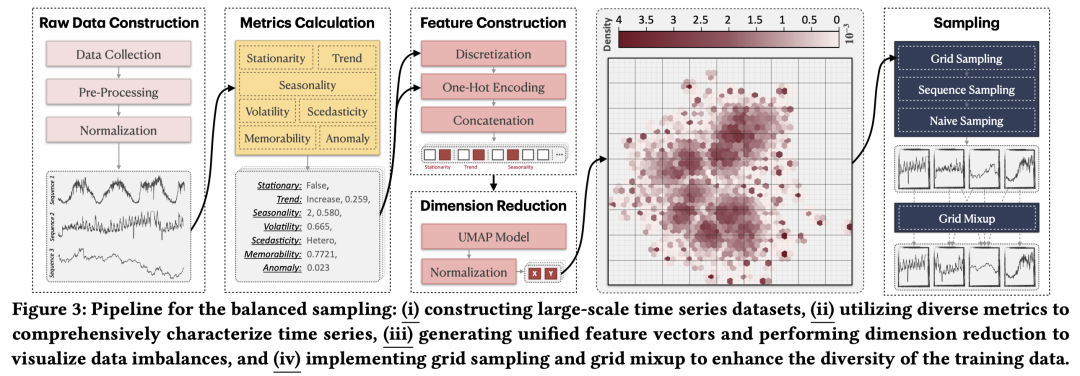
平衡采样流程:(i)构建大规模时间序列数据集,(ii)利用多种指标全面表征时间序列,(iii)生成统一的特征向量并进行降维以可视化数据不平衡性,以及(iv)实施栅格采样和栅格混合以提升训练数据的多样性
平衡采样流程:(i)构建大规模时间序列数据集,(ii)利用多种指标全面表征时间序列,(iii)生成统一的特征向量并进行降维以可视化数据不平衡性,以及(iv)实施栅格采样和栅格混合以提升训练数据的多样性
3.1 BLAST的设计思想
BLAST本质上的目的,是通过估计预训练数据的概率密度函数(PDF),从而根据该PDF采用分层抽样策略,从而无偏地选取样本。
然而,由于原始时间序列本身是高维向量,直接对其估计 PDF 在实践中不可行。
因此,BLAST使用丰富的统计指标来描述一条时间序列的模式,从而将每条时间序列压缩成一组稀疏的统计指标向量,并将这些稀疏向量投射到稠密的二维特征空间中,实现对PDF的估计。接着,它把这一平面划分为均匀的栅格单元,并在各单元内进行采样。每个栅格单元隐含地定义了一个聚类,能够捕捉一种特征模式;因此,这些栅格单元本身(而非预设的类别或领域标签)就成了分层抽样的基础。
使用深度神经网络来描述时间序列的模式或许是更加fancy的方式;然而,由于这些网络通常是需要依赖数据进行训练的,这会引起“先有鸡(无偏表征网络)还是先有蛋(无偏数据)”的问题。
3.2 原始数据构建
我们整合了大量公开可用的数据集,构建了一个总计 3210 亿个观测值的大规模数据集。我们用零填补缺失值,并过滤掉长度不足 512 的短时间序列;常用的基准数据集被排除在外。此外,我们对数据实施 z‑score 标准化,以消除不同数据集数值范围差异的影响。
3.3 指标计算
作为 BLAST 的核心组成部分,指标计算用于通过一组多样化的度量来表征时间序列的模式。对于给定的时间序列,BLAST 采用 7 个统计度量,从多个角度刻画其模式特征,包括平稳性、趋势性、周期性、波动率、方差齐性/异性、记忆性、异常度等。
关于指标选择原则、指标计算方式、实现细节以及替代方法的讨论等更多内容见论文Section 5.2以及Appendix A.2。
3.4 特征构建
总体而言,上述度量能够对时间序列进行较为全面的表征。图 4 展示了原始数据在这些度量上的分布。可以看到,这些度量本质上是异构的,既包含离散值,也包含取值范围各异的浮点值。
为缓解这种异构性,我们提出一种基于离散化的特征构建方法,将所有度量的表示统一为单一向量。对于连续型度量,我们在预设范围内采用量化技术对其取值进行离散化。形式化地,受Chronos 启发,给定度量 𝑧,将区间划分为个等距的分箱(bins),并使用量化函数 将 𝑧 映射到对应的分箱索引,其定义如下:
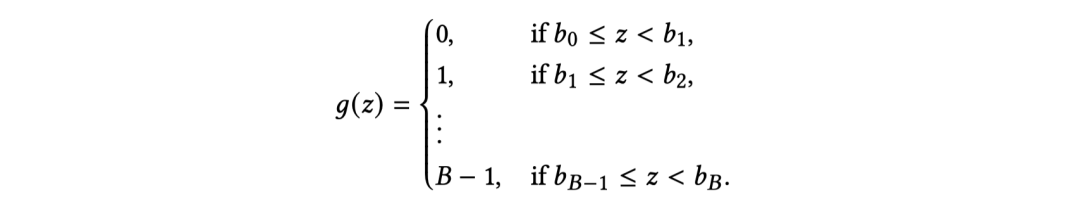
区间 之外的取值将被分配到最近的分箱(即 或 ),以应对长尾分布。
最后,连同离散型度量在内,我们对所有度量采用独热编码(one-hot encoding),并将这些向量拼接为统一表示 。该表示具有固定长度 61,从而为时间序列模式提供了标准化且全面的描述。
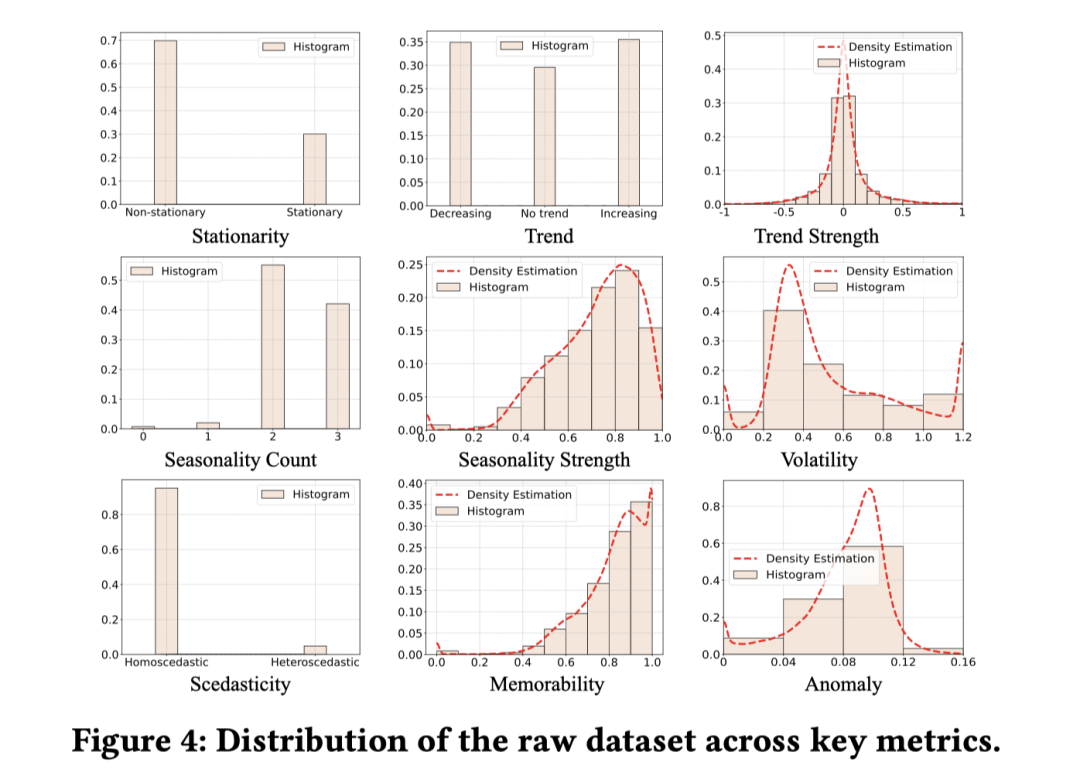
原始数据集在关键指标上的分布
原始数据集在关键指标上的分布
3.5 特征降维
为更好地理解数据分布中的偏差,我们将向量 h 降维到低维空间。BLAST 原始数据集包含约 4,000 万条原始时间序列,我们采用 UMAP模型将所有稀疏向量 h 投影到稠密的二维空间中。与 t-SNE、PCA等其他降维技术相比,UMAP 具有更高的效率,并且更好地保留数据的局部和全局结构。UMAP的参数选择和与t-SNE、PCA的超参数对比可见论文Section 6.5和Appendix A.3。
如图 3 的结果展示出了如下的特点:
- (1) 降维后的数据呈现出清晰的整体结构模式,但其分布仍然高度不均衡,这种偏斜的分布在模型训练过程中可能引入偏置。
- (2) 尽管原始数据规模庞大,但各区域之间仍存在大量空隙,这意味着原始数据中的模式仍显不足。
3.6 采样阶段
上述二维空间可以被划分为 M×M 个栅格,其中每一个栅格都包含诸多条时间序列,而每一条时间序列都可以通过滑动窗口产生许多候选样本。
BLAST的采样过程以栅格为基本采样单元:先随机采样得到一个栅格,随后从该栅格中随机采样得到一条时间序列,随后从该时间序列上随机采样得到一个样本。这样的采样过程解决了3.5中的问题1,使得采样得到的数据是均衡的。为了解决4.5中的问题2,受到Chronos中TSMixup的启发,我们引入了Grid Mixup技术。与TSMixup以“单条时间序列”为基本采样单元不同,这里将“栅格”视为最小采样单元。具体细节见论文Section 5.5。
总而言之,采样阶段所涉及的栅格采样和栅格混合策略,能有效缓解过密或过稀区域的偏差,解决大规模数据集中的不平衡问题,从而确保样本的均衡性和代表性,提升模型训练的效率与泛化性能。
4. 实验结果
4.1 实验设置
为了验证 BLAST 的有效性,本文进行了大量的实验。需要特别说明的是,BLAST 是一个预先生成的数据集,而不是在训练过程中进行采样。这种做法可以方便任意模型调用,并减少数据读取/预处理开销。
具体来说,我们选择了三个代表性的通用预测模型:TimeMoE、MOIRAI 和 Chronos。对于 TimeMoE 和 MOIRAI,我们选择了它们的 Base 和 Large 版本;对于 Chronos,我们则选择了 ChronosBolt 的 Small 和 Base 版本(官方没有 Large 版本)。
我们将上述模型在 BLAST 上重新训练(从头开始训练),并在验证数据集上进行评估。
在验证数据集的选择上,我们参考了TimeMoE的做法,选取了 ETTh1、ETTh2、ETTm1、ETTm2、Weather 和 GlobalTemp 数据集,这些数据集在 BLAST 的原始数据中并不存在或已经被剔除。此外,为了更全面地评估时序大模型的性能,我们还使用了 GIFT-Eval 数据集。对于 GIFT-Eval,我们过滤掉了在 Chronos、MOIRAI、TimeMoE 的预训练数据以及 BLAST 中已包含的数据集,最终保留下来 43 个任务(原始总计 97 个任务)。
所有实验均在 8 块 A100 40G PCIe 上进行。
4.2 实验结果
从表 5 和表 6 可以看出,使用 BLAST 重新训练的模型在大多数情况下表现更好,而且消耗的资源更少!
例如,如表 1 所示(本文开头), TimeMoE 模型原始实验使用了 128 块 A100,并以 1024 的 Batch Size 训练了 419B Token;而基于 BLAST 训练时,所需资源可以减少到 8 块 A100、192 的 Batch Size,以及 78B Token。
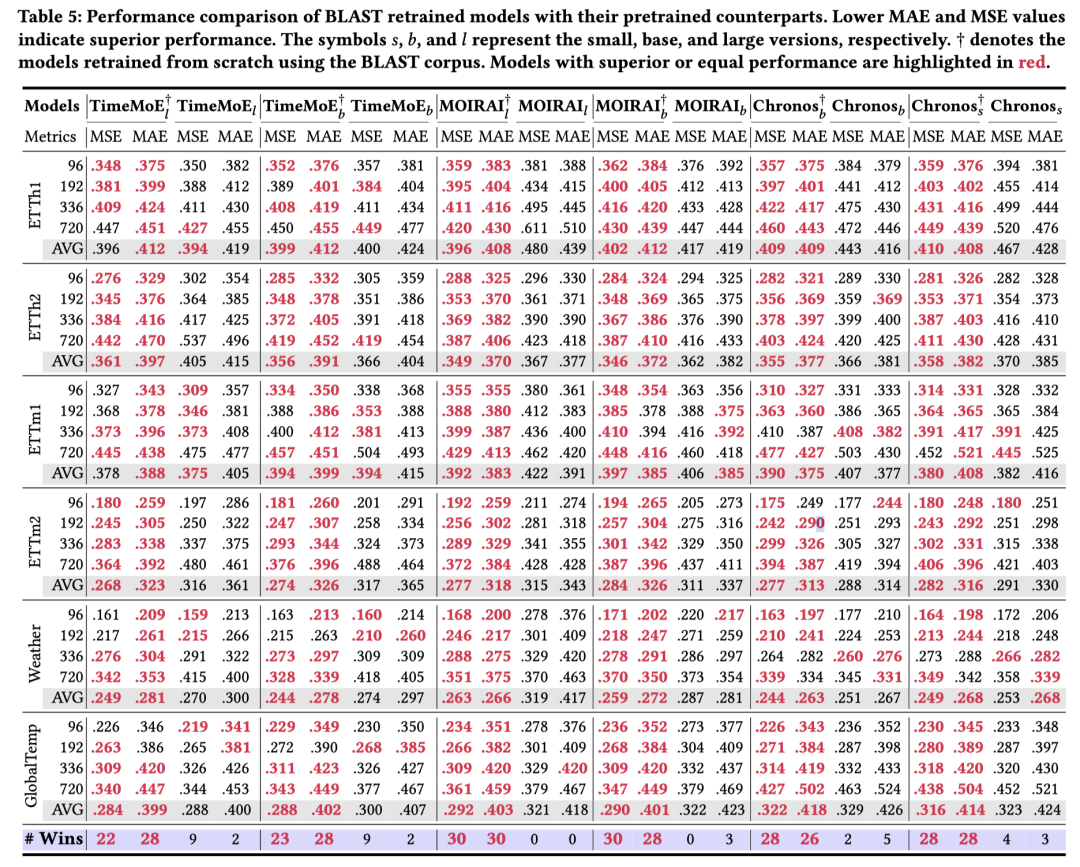
BLAST 重新训练模型与其预训练模型的性能对比。更低的 MAE 和 MSE 值表示更优的性能。符号 𝑠、𝑏 和 𝑙 分别表示小型、基础型和大型版本。† 表示使用 BLAST 语料库从头开始重新训练的模型。性能优于或等于的模型以红色标出
BLAST 重新训练模型与其预训练模型的性能对比。更低的 MAE 和 MSE 值表示更优的性能。符号 𝑠、𝑏 和 𝑙 分别表示小型、基础型和大型版本。† 表示使用 BLAST 语料库从头开始重新训练的模型。性能优于或等于的模型以红色标出

GIFT-Eval 基准上的性能对比。此前包含在 Time-300B、LOTSA 和 BLAST 中的数据已被排除。更低的 MASE 值表示更好的性能。性能更优的模型以红色标出
GIFT-Eval 基准上的性能对比。此前包含在 Time-300B、LOTSA 和 BLAST 中的数据已被排除。更低的 MASE 值表示更好的性能。性能更优的模型以红色标出
图 5 则进一步展示了 BLAST 如何降低资源消耗:通过更加均衡的数据分布,BLAST 本质上加速了模型的收敛速度。
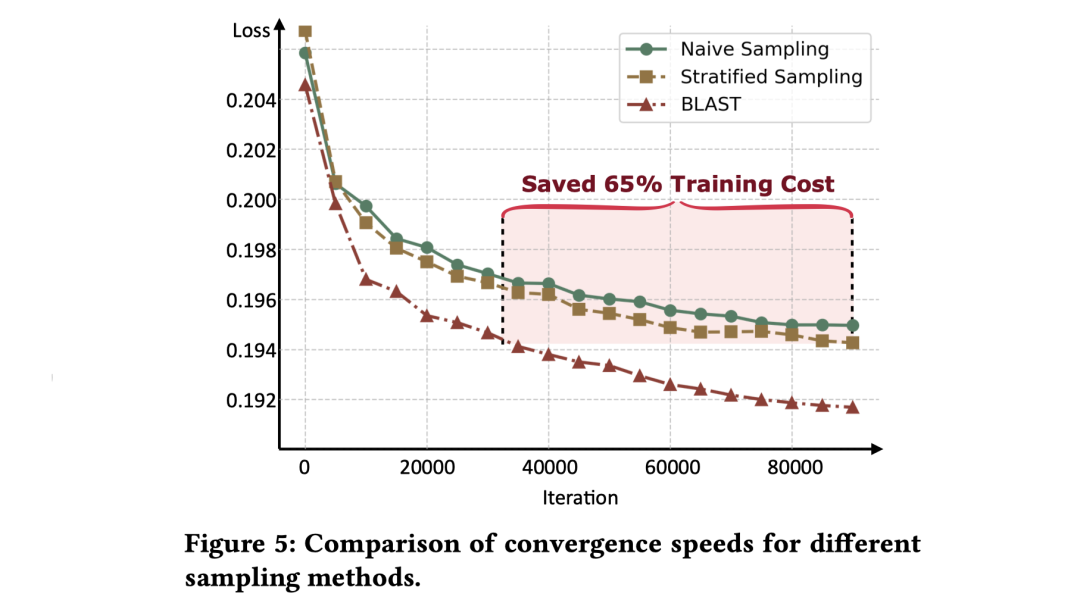
不同采样方法的收敛速度对比
不同采样方法的收敛速度对比
其他实验,如消融实验、超参数实验和降维参数选择等,详细内容可参考论文。
4.3 讨论以及未来方向
- BLAST首次指出了数据分布的不平衡问题,是限制通用预测模型泛化能力和鲁棒性的关键因素。相比于卷模型结构,或许数据本身探索的空间更大。
- BLAST本身是一种启发式的数据采样策略,在深度学习时代或许显得有点特征工程;使用神经网络来估计数据分布或许是更加fancy的做法,但这一定程度上会陷入先有鸡还是先有蛋的问题——毕竟神经网络是需要数据进行训练的。
- BLAST也可以用于无偏地训练非预测模型,例如表征模型,从而促进以数据驱动的方式估计数据分布或赋能其他下游任务。
- 虽然本文只是将BLAST用于训练语料,但BLAST的思想天然地适合构建通用预测模型的Benchmark。和预训练语料库类似,现有的Benchmark大多强调Domain多、子数据集多。然而如前文所述,Domain标签和数据集标签并不能确保数据分布的充分性和多样性。
5. 结论和贡献:
综上,本文的主要贡献如下:
- 填补数据多样性研究空白。 本研究聚焦于数据多样性在通用预测模型训练中的作用,首次系统探索了预训练数据多样性对训练效率与模型性能的影响。
- 提出以“模式”为目标的平衡采样技术。 我们将时间序列以多种统计属性进行表征,并通过基于栅格的划分对数据进行隐式聚类;随后采用栅格采样与栅格混合生成多样化的预训练数据。
- 构建高效语料 BLAST。 实验结果表明,基于 BLAST 的预训练在降低资源与数据需求的同时,取得了更优的性能。
6. References
[1] Shao Z, Wang F, Xu Y, et al. Exploring progress in multivariate time series forecasting: Comprehensive benchmarking and heterogeneity analysis[J]. IEEE Transactions on Knowledge and Data Engineering, 2024. https://arxiv.org/pdf/2310.06119
[2] Brigato L, Morand R, Strømmen K, et al. Position: There are no champions in long-term time series forecasting[J]. arXiv preprint arXiv:2502.14045, 2025.
[3] Shao Z, Qian T, Sun T, et al. Spatial-temporal large models: A super hub linking multiple scientific areas with artificial intelligence[J]. The Innovation, 2025, 6(2). https://www.cell.com/the-innovation/fulltext/S2666-6758(24)00201-7
[4] Amro Kamal Mohamed Abbas, Kushal Tirumala, Daniel Simig, Surya Ganguli, and Ari S Morcos. [n. d.]. SemDeDup: Data-efficient learning at web-scale through semantic deduplication. In ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models.
[5] Hao Miao, Ziqiao Liu, Yan Zhao, Chenjuan Guo, Bin Yang, Kai Zheng, and Christian S Jensen. 2024. Less is more: Efficient time series dataset condensation via two-fold modal matching. PVLDB 18, 2 (2024), 226–238.
[6] Yunfan Shao, Linyang Li, Zhaoye Fei, Hang Yan, Dahua Lin, and Xipeng Qiu. Balanced Data Sampling for Language Model Training with Clustering. arXiv preprint arXiv:2402.14526 (2024).
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-04,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号