Java 面试题【MySQL 篇 二】


为什么 MySQL 选择使用 B+ 树作为索引结构?
参考链接:为什么 MySQL 选择使用 B+ 树作为索引结构? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
B+ 树在数据库系统中具有以下几个显著优势:
1)高效的查找性能:
B+ 树是一种自平衡树,每个叶子节点到根节点的路径长度相同,查找、插入、删除等操作的时间复杂度为 O(log n),能够保证在大数据量情况下也能有较快的响应时间。
2)树的高度增长不会过快,使得查询磁盘的 I/O 次数减少:
B+树是一个多叉树,在相同数据的情况下,B+树的层级更低,层级低就减少了磁盘的IO次数,非叶子节点仅保存主键或索引值和页面指针,使得每一页能容纳更多的记录,因此内存中就能存放更多索引,容易命中缓存,使得查询磁盘的 I/O 次数减少。
3)范围查询能力强:
B+ 树特别适合范围查询。因为叶子节点通过链表链接,从根节点定位到叶子节点查找到范围的起点之后,只需要顺序扫描链表即可遍历后续的数据,非常高效。
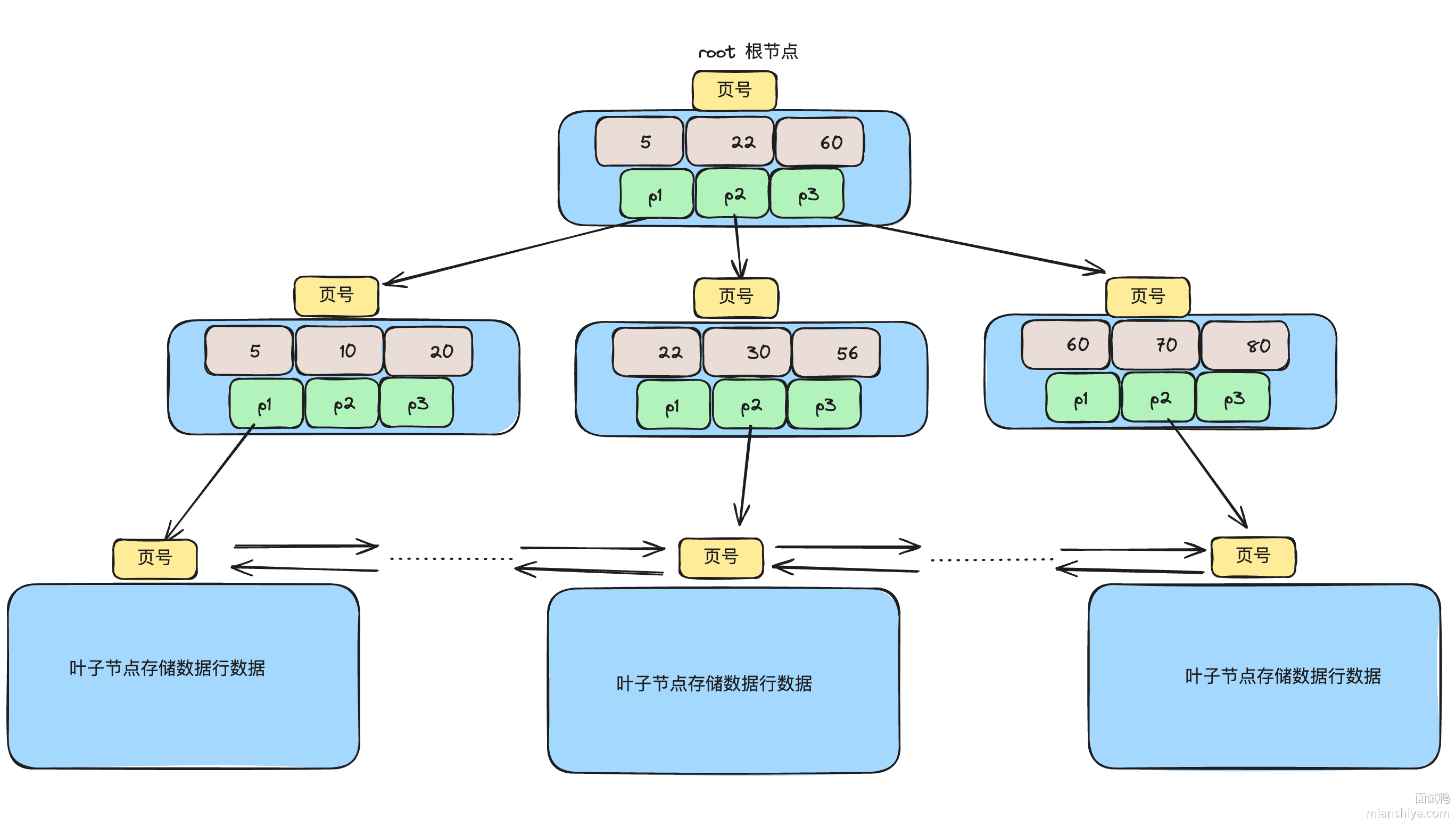
B+ 树和 B 树区别
1)B 树每个节点都存储了完整的数据,而 B+ 树非叶子节点仅存储 key 和指针,完整数据存储在叶子节点。这使得 B+ 树可以在内存中存放更多索引页,减少磁盘查询次数。
2)B+ 树节点之间组成了链表,便于区间查找,而 B 树只能每一层遍历查找。
3)B+ 树查询时间更平均、稳定,都需要从根节点扫描到叶子节点。而 B 树则在非叶子节点就可能找到对应的数据返回。
MySQL 是如何实现事务的?
参考链接:MySQL 是如何实现事务的? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
MySQL 主要是通过:锁、Redo Log 、Undo Log、MVCC 来实现事务。
1)MySQL 利用锁(行锁、间隙锁等等)机制,使用数据并发修改的控制,满足事务的隔离性。
2)Redo Log(重做日志),它会记录事务对数据库的所有修改,在崩溃时恢复未提交的更改,用来满足事务的持久性。
3)Undo Log(回滚日志),它会记录事务的反向操作,简单地说就是保存数据的历史版本,用于事务的回滚,使得事务执行失败之后可以恢复之前的样子。实现原子性和隔离性
4)MVCC(多版本并发控制),满足了非锁定读的需求,提高了并发度,实现了读已提交和可重复读两种隔离级别,实现了事务的隔离性。【在 READ UNCOMMITTED 级别下,因为允许脏读,所以不使用 MVCC;在 SERIALIZABLE 级别下,则更多地依赖于锁定机制来保证最高级别的隔离】
MySQL 中的 MVCC 是什么?
参考链接:MySQL 中的 MVCC 是什么? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
MVCC(Multi-Version Concurrency Control,多版本并发控制)就是同一份数据保留多个版本的一种方式,进而实现并发控制,允许多个事务同时读取和写入数据库,而无需互相等待,从而提高数据库的并发性能。
读取数据方式有当前读(实时读取数据库的状态,会对读取的记录进行加锁), 快照读(使用快照(snapshot)来读取数据的一种方式),而 MVCC 就是 mysql 实现快照读的方式,MVCC 由 版本链 和readView 实现的。
版本链是一种存储多个版本行记录的链表结构,readView 就是一个快照,保存着数据库某个时刻的数据信息,其中包含的信息有活跃的事务id,最小事务id,待分配的事务id还有创建这个 readView 的事务id,在查询的时候,通过 readView 从版本链找到当前可见的记录。
不同隔离级别获取 readView 的时机不同,可重复读隔离级别在一个事务范围内,第一次 select 时更新这个read_view,以后不会再更新,已提交读隔离级别每次执行 select 都会创建新的 readView。

MySQL 中长事务可能会导致哪些问题?
参考链接:MySQL 中长事务可能会导致哪些问题? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
MySQL中的长事务指的是长时间未提交的事务
1)长时间的锁竞争,阻塞资源:
- 长事务持有锁的时间较长,容易导致其他事务在尝试获取相同锁时发生阻塞,从而增加系统的等待时间和降低并发性能。
- 业务线程也会因为长时间的数据库请求等待而阻塞,部分业务的阻塞可能还会影响到别的服务,导致产生雪崩,最终使得服务全面崩盘,导致非常严重的线上事故。
2)死锁风险:长事务更容易产生死锁,因为多个事务可能在互相等待对方释放锁,导致系统无法继续执行。
3)主从延迟:主库需要长时间执行,然后传输给从库,从库又要重放好久,期间可能有很长一段时间数据是不同步的。
4)回滚导致时间浪费:如果长事务执行很长一段时间,中间突发状况导致抛错,使得事务回滚了,之前做的执行都浪费了。
MySQL 中的事务隔离级别有哪些?
参考链接:MySQL 中的事务隔离级别有哪些? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
- Serializable (串行化):事务串行执行,即每个事务都会等待前一个事务执行完毕才会开始执行。这可以避免所有的并发问题,从而解决幻读问题。
- Repeatable read (可重复读):MySQL的默认事务隔离级别,确保在一个事务中的多个查询返回的结果是一致的,解决了不可重复读的问题。
- Read committed (读已提交):一个事务只能看见已经提交事务所做的改变。可避免脏读的发生。
- Read uncommitted (读未提交):一个事务可以看到另一个事务尚未提交的数据修改。
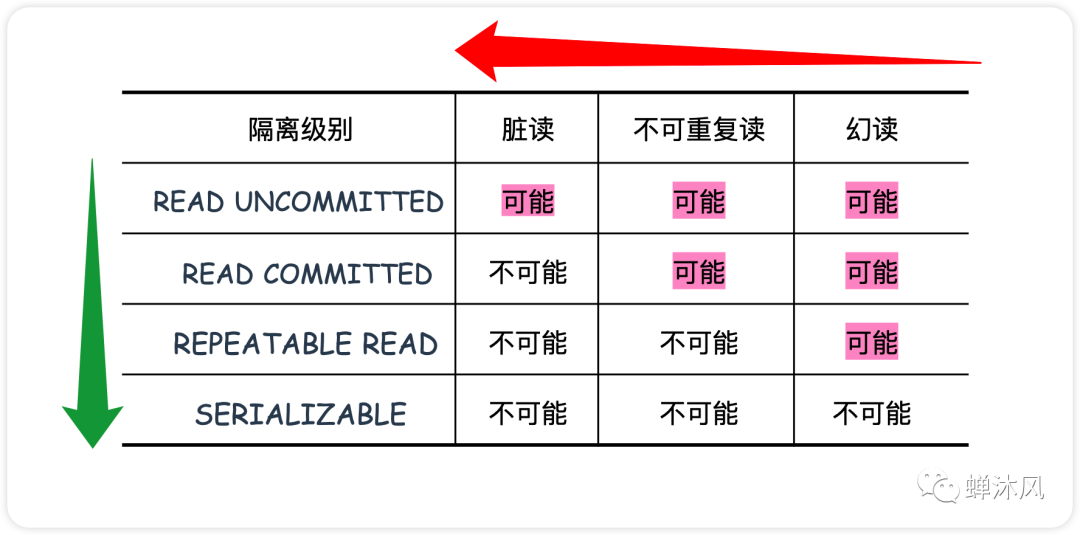
隔离级别的影响
较低的隔离级别(如读未提交)提高了并发性,但可能导致数据不一致;较高的隔离级别(如串行化)保证数据一致性,但降低了并发性。因此,在设计应用时,需要在性能和数据一致性之间找到平衡。
MySQL 默认的事务隔离级别是什么?为什么选择这个级别?
参考链接:MySQL 默认的事务隔离级别是什么?为什么选择这个级别? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
MySQL 默认的隔离级别是可重复读( Repeatable Read ),即 RR。
原因是为了兼容早期 binlog 的 statement 格式问题,如果是使用读已提交、读未提交等隔离级别,使用了 statement 格式的 binlog 会导致主从(备)数据库数据不一致问题。
数据库的脏读、不可重复读和幻读分别是什么?
参考链接:事务的隔离级别与MVCC
1)脏读(Dirty Read):一个事务读到另一个事务还没有提交的数据
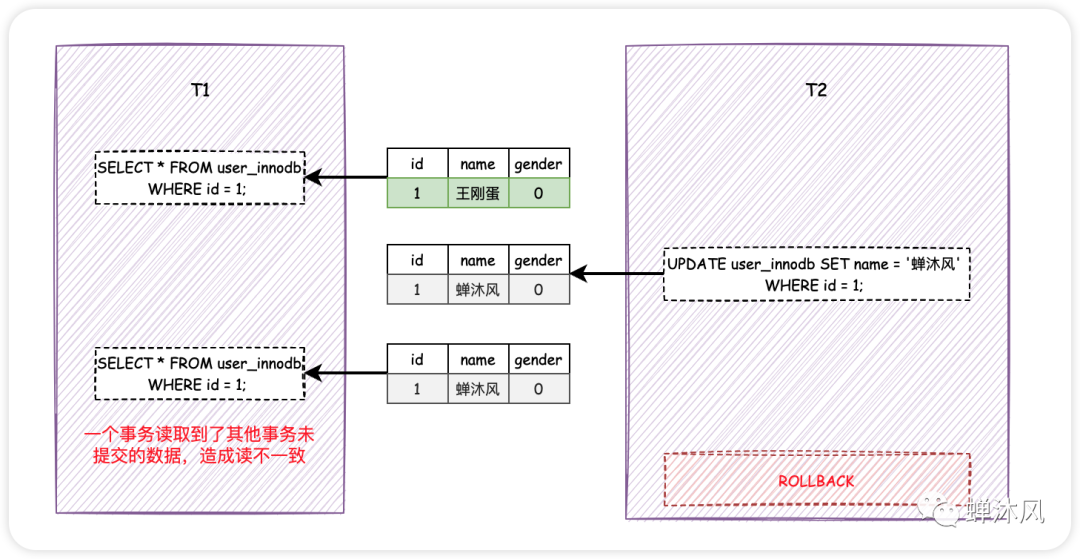
2)不可重复读(Non-repeatable Read):一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读

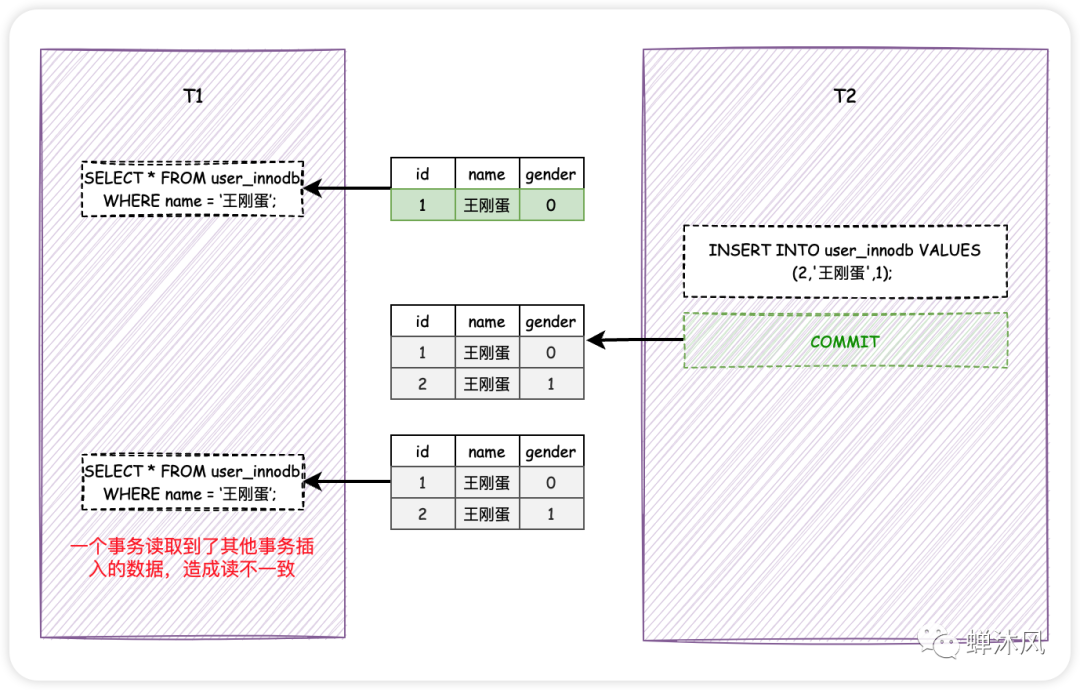
3)幻读(Phantom Read):一个事务多次读取某个结果集的数据,数据的数量发生了变化
MySQL 中有哪些锁类型?
参考链接:MySQL 面试题
MySQL 中有哪些锁类型? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
- 锁的粒度划分:行锁、表锁、页锁
- 锁的区间划分:记录锁、间隙锁、临键锁
- 锁的级别划分:共享锁、排他锁、意向锁
锁的粒度划分
行锁的锁定粒度最细,但加锁的开销也大;表锁锁定粒度最大,加锁的开销小;页锁是 MySQL 中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢
1)行锁:仅对特定的行加锁,允许其他事务并发访问不同的行,适用于高并发场景
2)表锁:对整个表加锁,其他事务无法对该表进行任何读写操作,适用于需要保证完整性的小型表
3)页锁:一次锁定相邻的一组记录
锁的区间划分
1)记录锁(Record Lock):也就是仅仅把一条记录锁上
2)间隙锁(Gap Lock):锁定一个范围,但是不包含记录本身
3)临键锁(Next-Key Lock):Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身
锁的级别划分
1)共享锁(Shared Lock):允许多个事务并发读取同一资源,但不允许修改。只有在释放共享锁后,其他事务才能获得排它锁
2)排他锁(Exclusive Lock):只允许一个事务对资源进行读写,其他事务在获得排它锁之前无法访问该资源
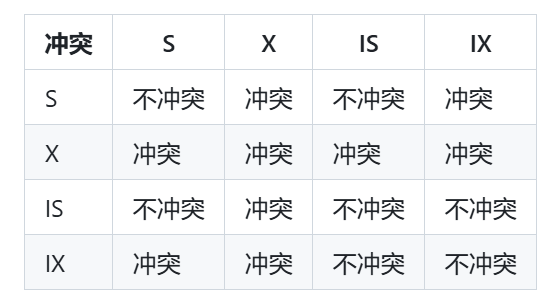
3)意向锁:分为 IS(Intention Shared Lock),共享意向锁、IX(Intention Exclusive Lock),独占意向锁,IS 和 IX 的作用就是在上表级锁的时候,可以快速判断是否可以上锁,而不需要遍历表中的所有记录
MySQL 的乐观锁和悲观锁是什么?
参考链接:MySQL 的乐观锁和悲观锁是什么? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
悲观锁(Pessimistic Locking):
- 假设会发生冲突,因此在操作数据之前就对数据加锁,确保其他事务无法访问该数据。常见于对数据一致性要求较高的场景。
- 实现方式:使用行级锁或表级锁,例如可以使用
SELECT ... FOR UPDATE或LOCK IN SHARE MODE语句来加锁。
-- 读取数据并加锁
SELECT id, name FROM users WHERE id = 1 FOR UPDATE;
-- 执行更新操作
UPDATE users SET name = 'new_name' WHERE id = 1;乐观锁(Optimistic Locking):
- 假设不会发生冲突,因此在操作数据时不加锁,而是在更新数据时进行版本控制或校验。如果发现数据被其他事务修改,则会拒绝当前事务的修改,需重新尝试。
- 实现方式:通常通过版本号或时间戳来实现,每次更新时检查版本号或时间戳是否一致。
-- 假设有一张用户表 users,包含 id、name 和 version 字段
-- 读取数据
SELECT id, name, version FROM users WHERE id = 1;
-- 更新数据时检查版本号
UPDATE users
SET name = 'new_name', version = version + 1
WHERE id = 1 AND version = current_version;MySQL 中如果发生死锁应该如何解决?
参考链接:MySQL 中如果发生死锁应该如何解决? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
自动检测与回滚:
- MySQL 自带死锁检测机制(innodb_deadlock_detect),当检测到死锁时,数据库会自动回滚其中一个事务,以解除死锁。通常会回滚事务中持有最少资源的那个。
- 也有锁等待超时的参数(innodb_lock_wait_timeout),当获取锁的等待时间超过阈值时,就释放锁进行回滚。
手动 kill 发生死锁的语句:
- 可以通过命令,手动快速地找出被阻塞的事务及其线程 ID,然后手动 kill 它,及时释放资源。
如何使用 MySQL 的 EXPLAIN 语句进行查询分析?
参考链接:如何使用 MySQL 的 EXPLAIN 语句进行查询分析? - MySQL 面试题 - 面试鸭 - 程序员求职面试刷题神器
explain 主要用来 SQL 分析
explain 主要属性
id:查询的执行顺序的标识符,值越大优先级越高。简单查询的 id 通常为 1,复杂查询(如包含子查询或 UNION)的 id 会有多个select_type(重要):查询的类型,如 SIMPLE(简单查询)、PRIMARY(主查询)、SUBQUERY(子查询)等table:查询的数据表type(重要):访问类型,如 ALL(全表扫描)、index(索引扫描)、range(范围扫描)等。一般来说,性能从好到差的顺序是:const > eq_ref > ref > range > index > ALLpossible_keys:可能用到的索引key(重要):实际用到的索引key_len:用到索引的长度ref:显示索引的哪一列被使用rows(重要):估计要读取的行数,值越小越好filtered:显示查询条件过滤掉的行的百分比。一个高百分比表示查询条件的选择性好Extra(重要):额外信息,如Using index(表示使用覆盖索引)、Using where(表示使用 WHERE 条件进行过滤)、Using temporary(表示使用临时表)、Using filesort(表示需要额外的排序步骤)
type 属性详解
- system:表示查询的表只有一行(系统表)。这是一个特殊的情况,不常见。
- const:表示查询的表最多只有一行匹配结果。这通常发生在查询条件是主键或唯一索引,并且是常量比较。
- eq_ref:表示对于每个来自前一张表的行,MySQL 仅访问一次这个表。这通常发生在连接查询中使用主键或唯一索引的情况下。
- ref:MySQL 使用非唯一索引扫描来查找行。查询条件使用的索引是非唯一的(如普通索引)。
- range:表示 MySQL 会扫描表的一部分,而不是全部行。范围扫描通常出现在使用索引的范围查询中(如
BETWEEN、>,<,>=,<=)。 - index:表示 MySQL 扫描索引中的所有行,而不是表中的所有行。即使索引列的值覆盖查询,也需要扫描整个索引。
- all(性能最差):表示 MySQL 需要扫描表中的所有行,即全表扫描。通常出现在没有索引的查询条件中。
使用例子
create table user(
id int primary key auto_increment,
name varchar(20) not null,
phone varchar(20) not null,
age int not null
);
# 创建联合索引
create index name_phone_index on user(name,phone);
explain select * from user where name = '张三' and phone = '134***';
正在找工作或者想要提升技术的程序员都可以去试试这款刷题神器【面试鸭】。你能想到的各种题目都被整理得明明白白,再也不用自己到处找七零八落的资料。8000多道超全题库+高频题+大厂面试官原创题解+真实面经,绝对的求职秘密武器,扫码即可体验⬇️
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-10-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号